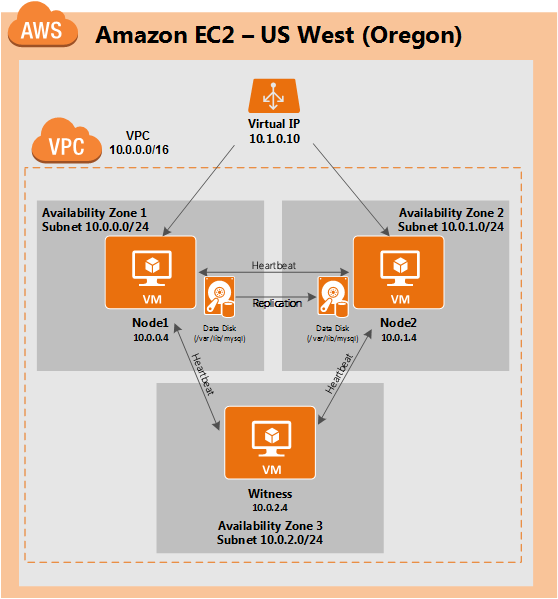
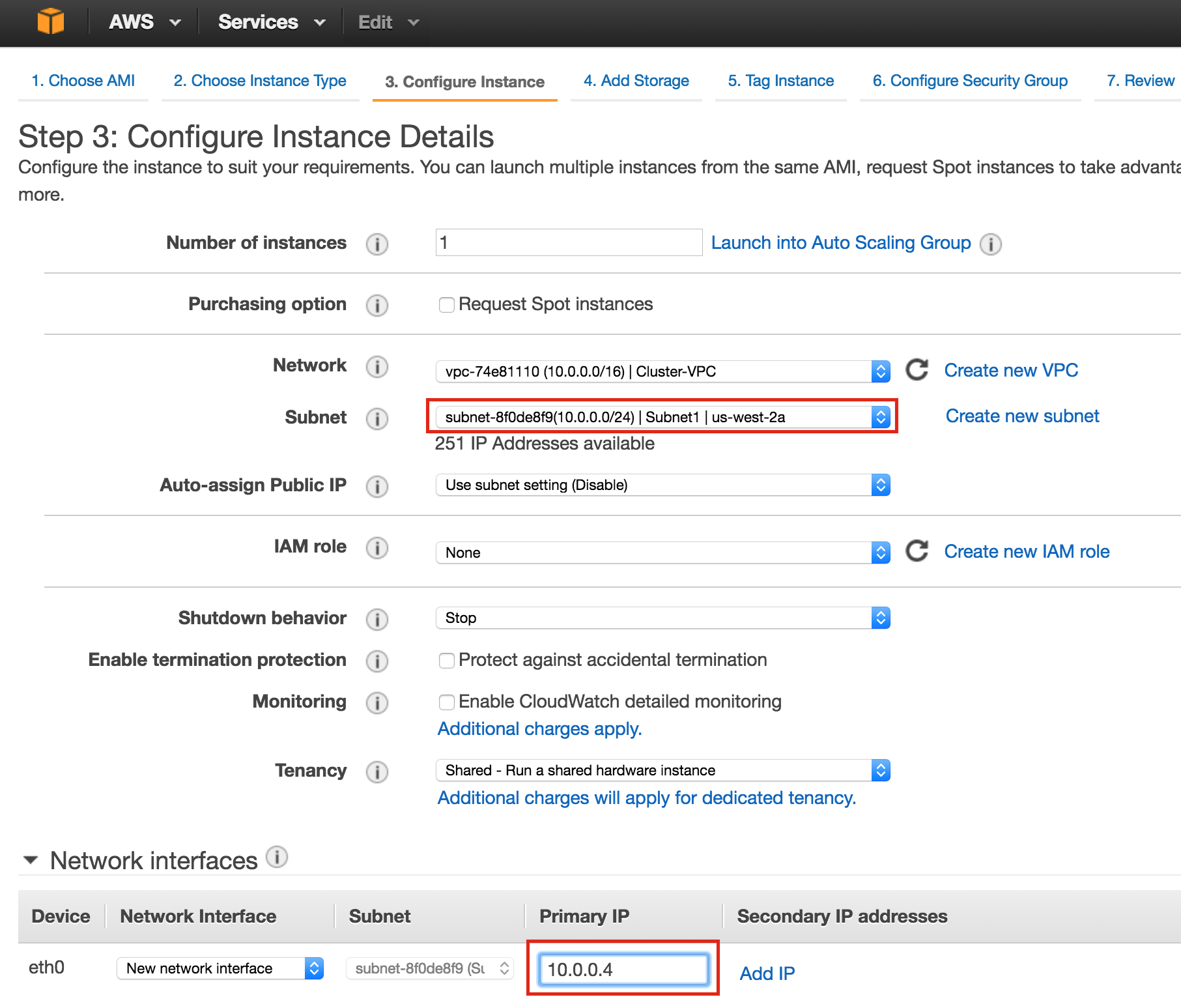
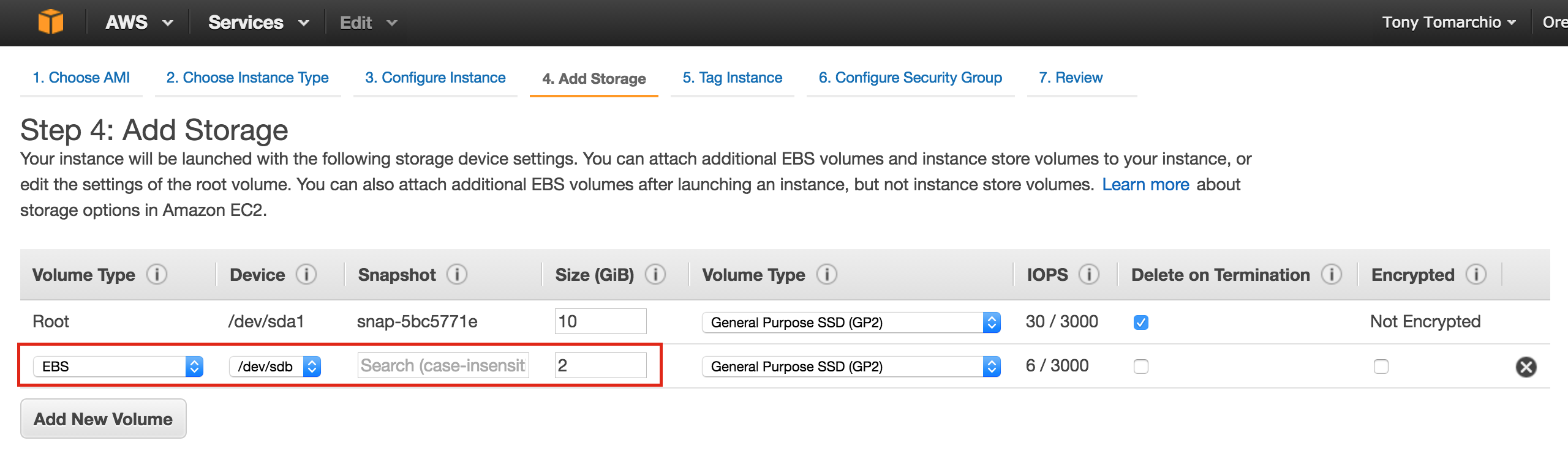
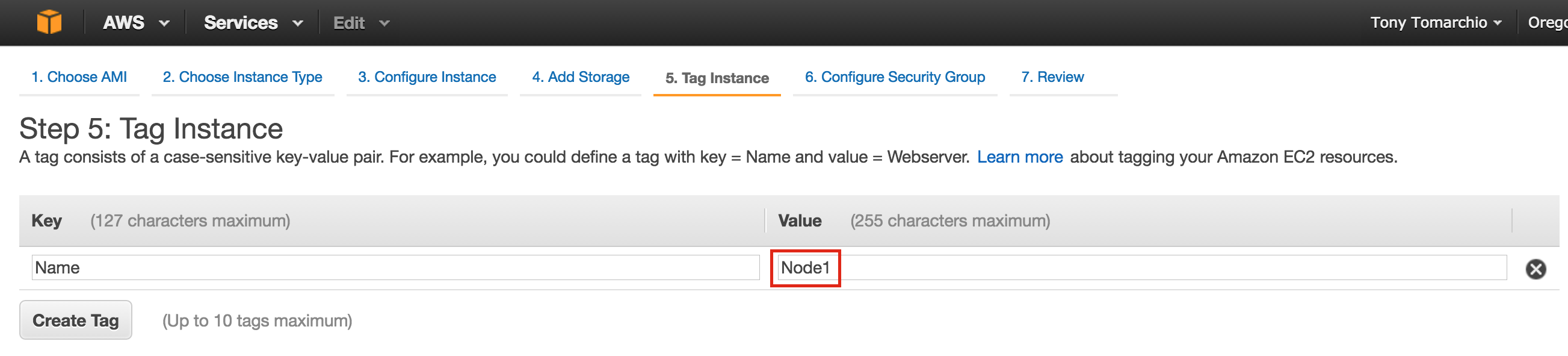
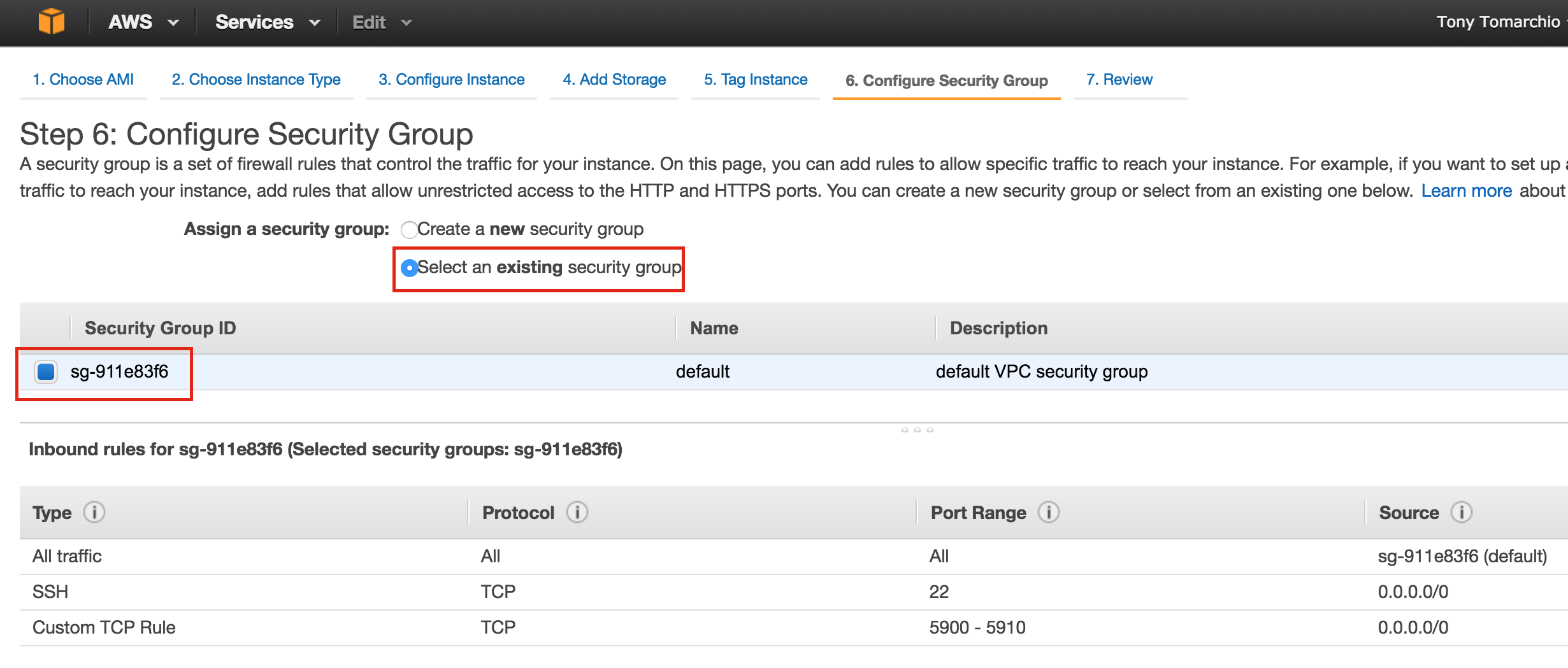
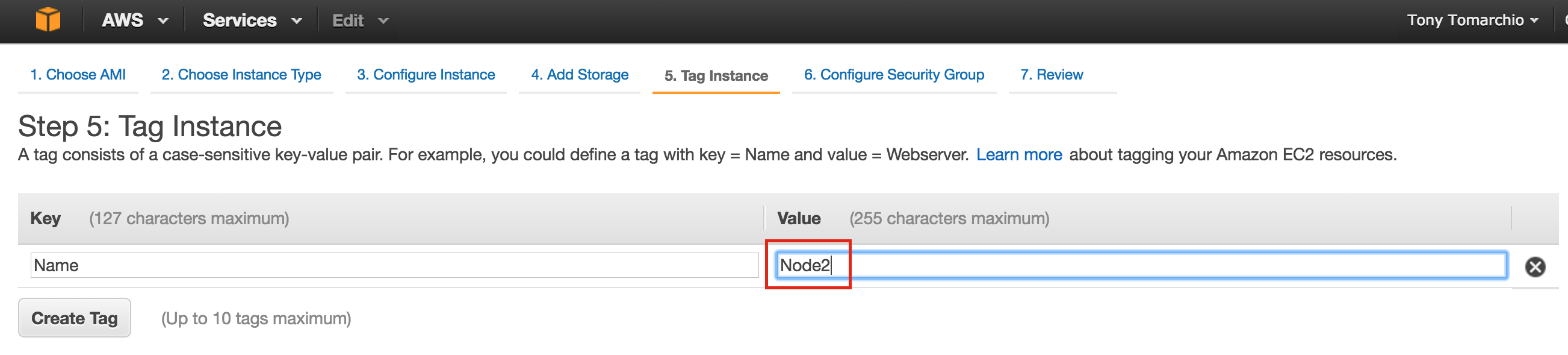
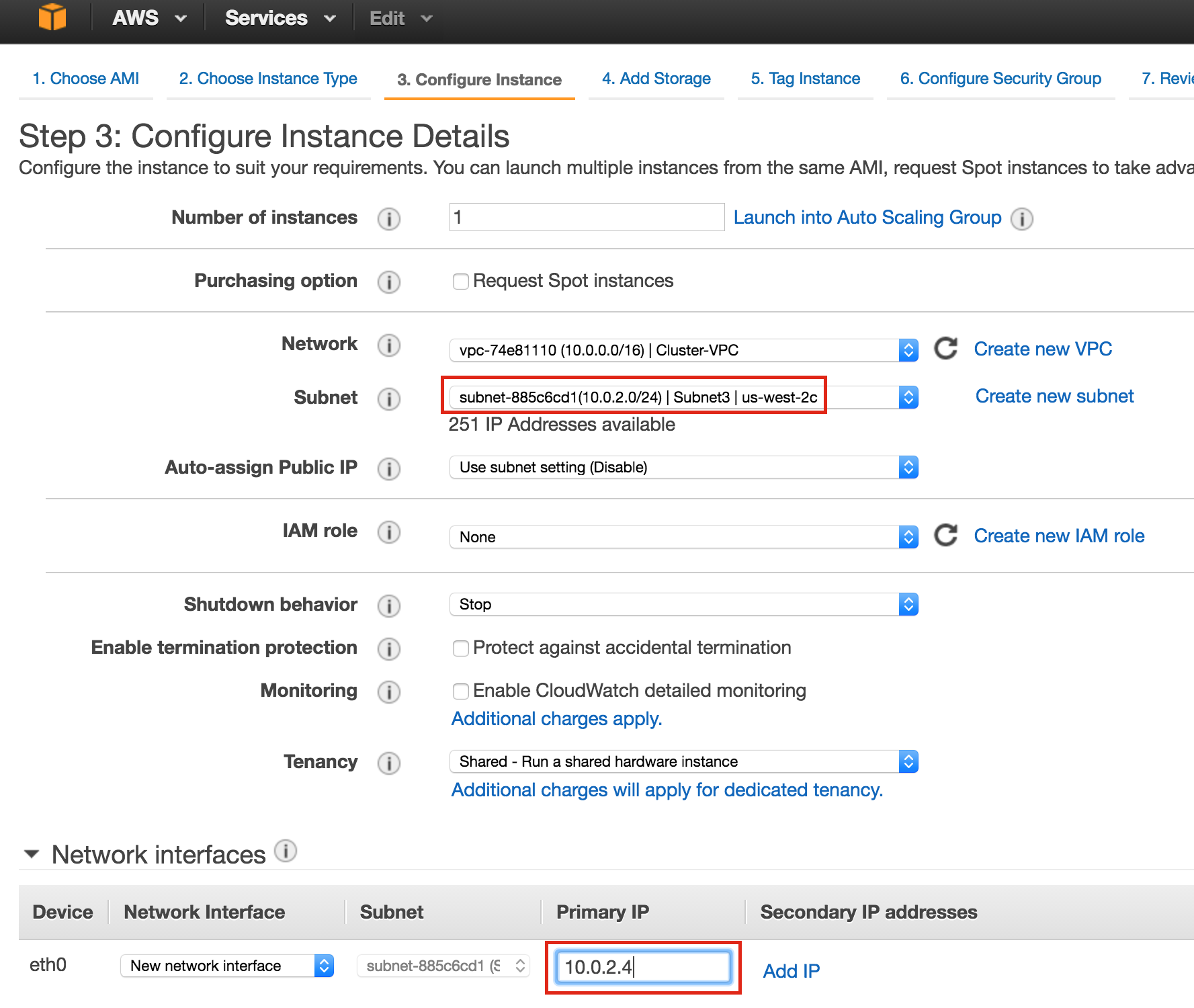
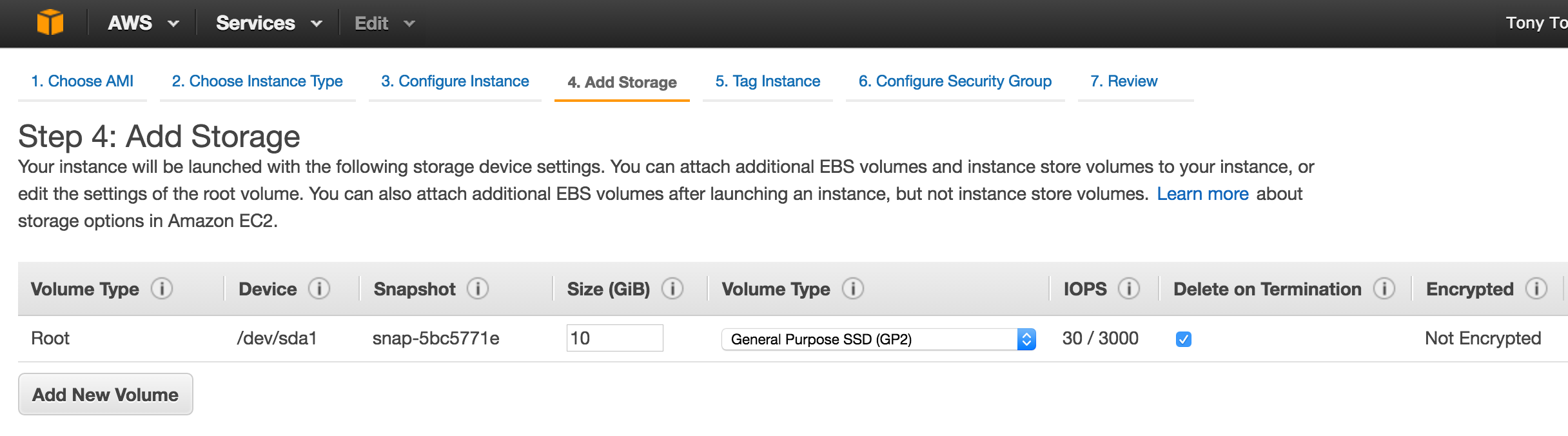
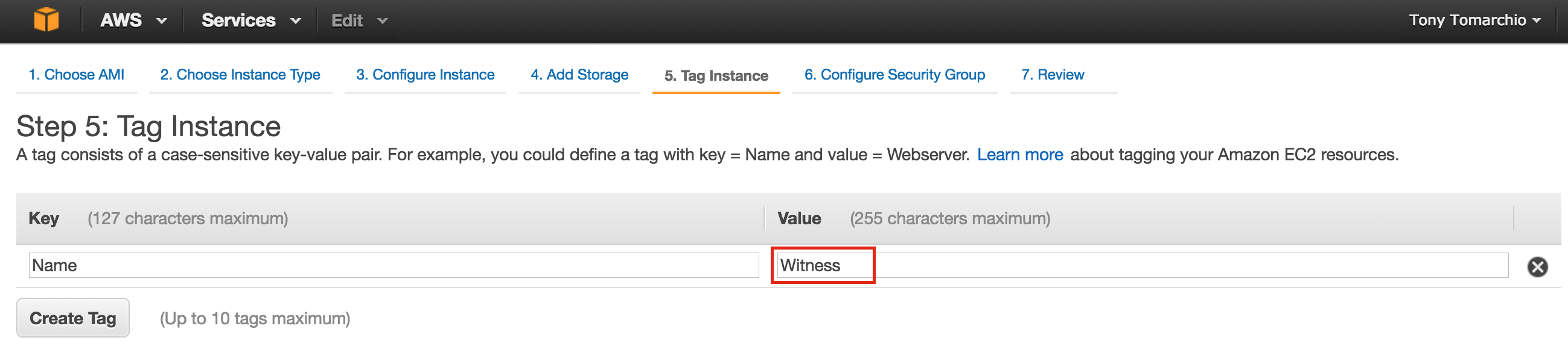
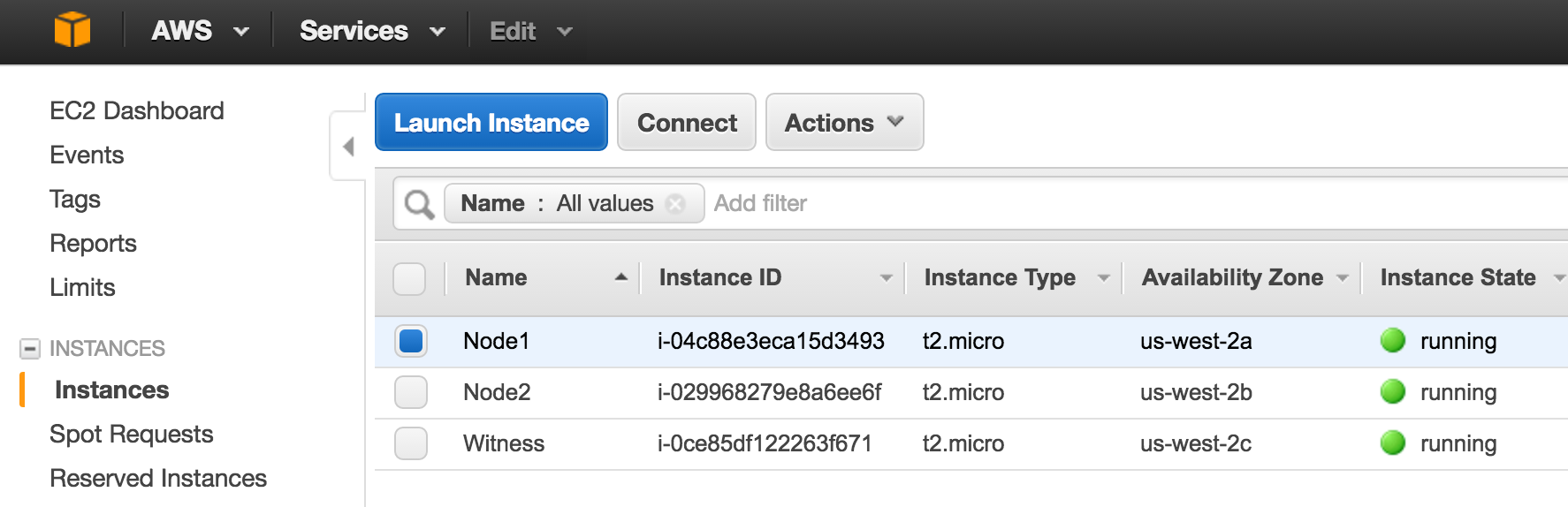
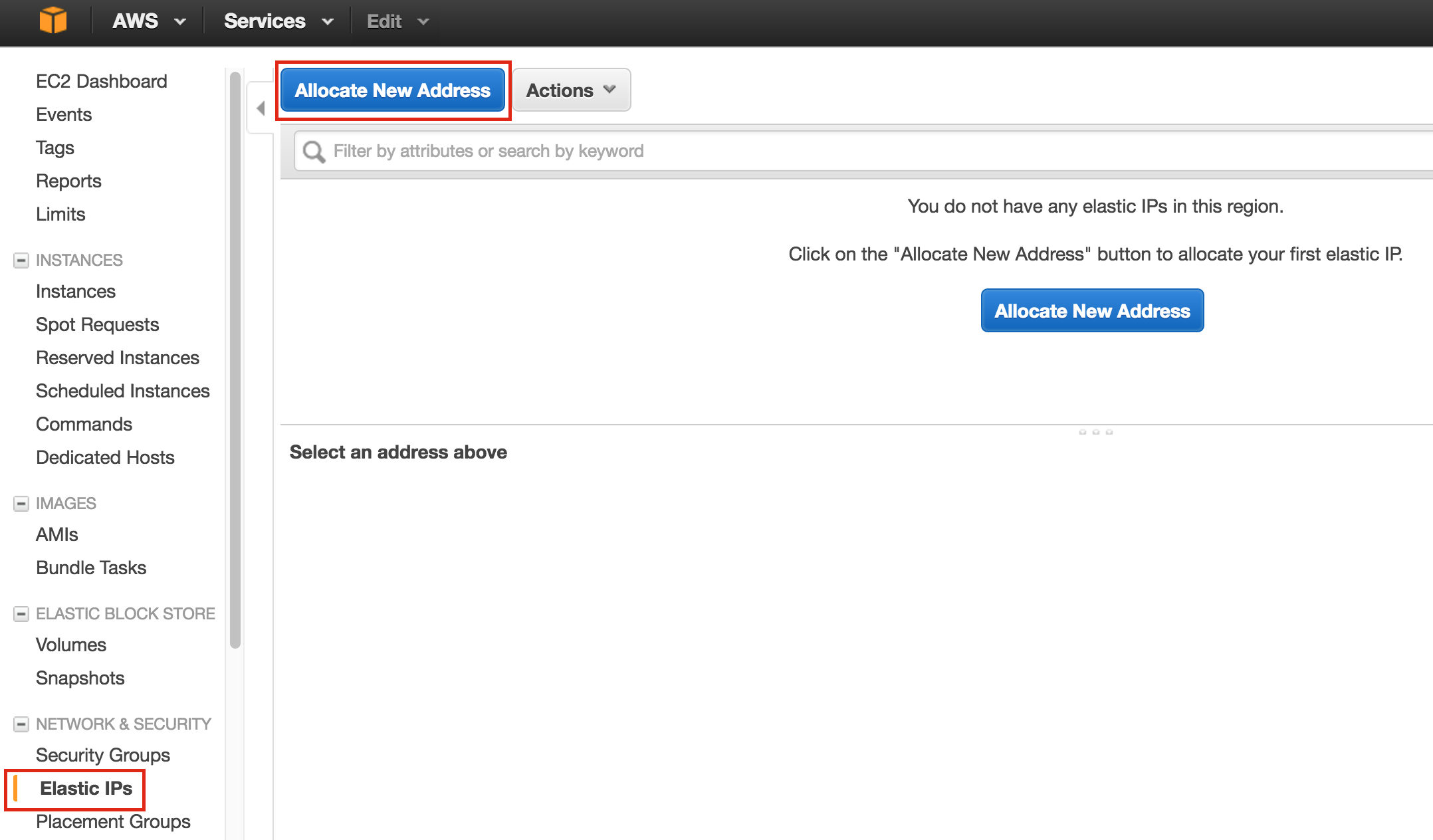
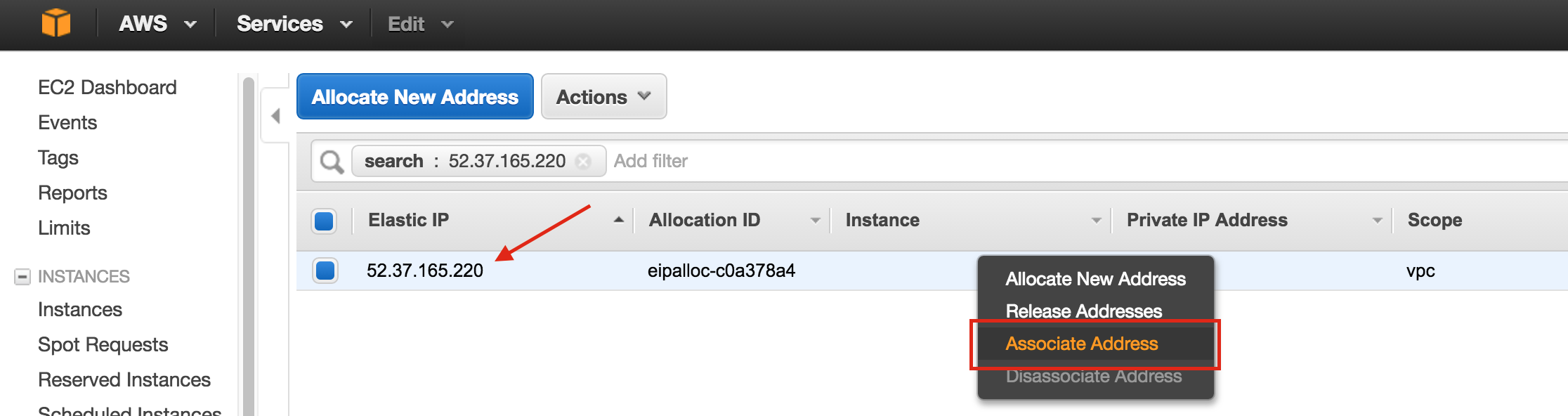
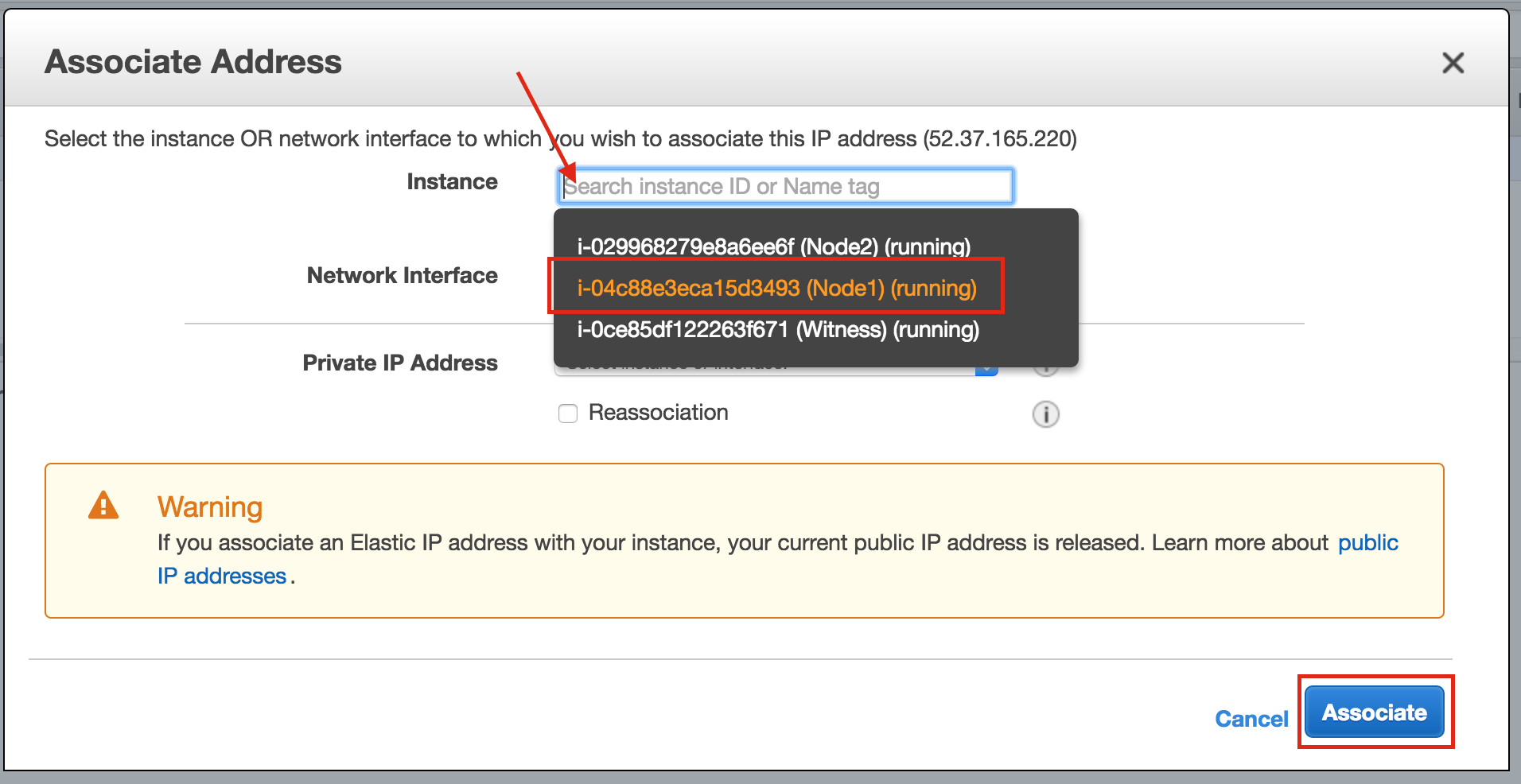
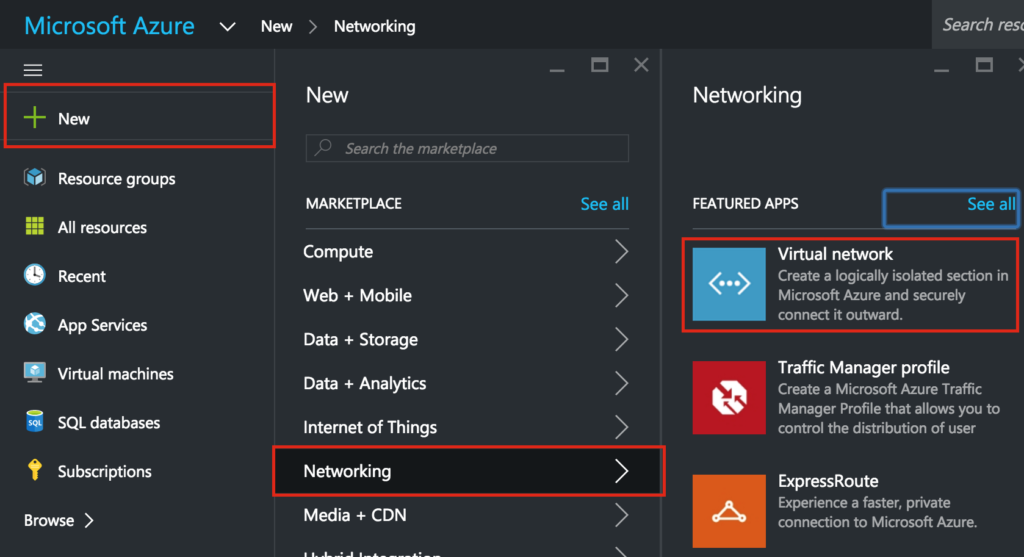
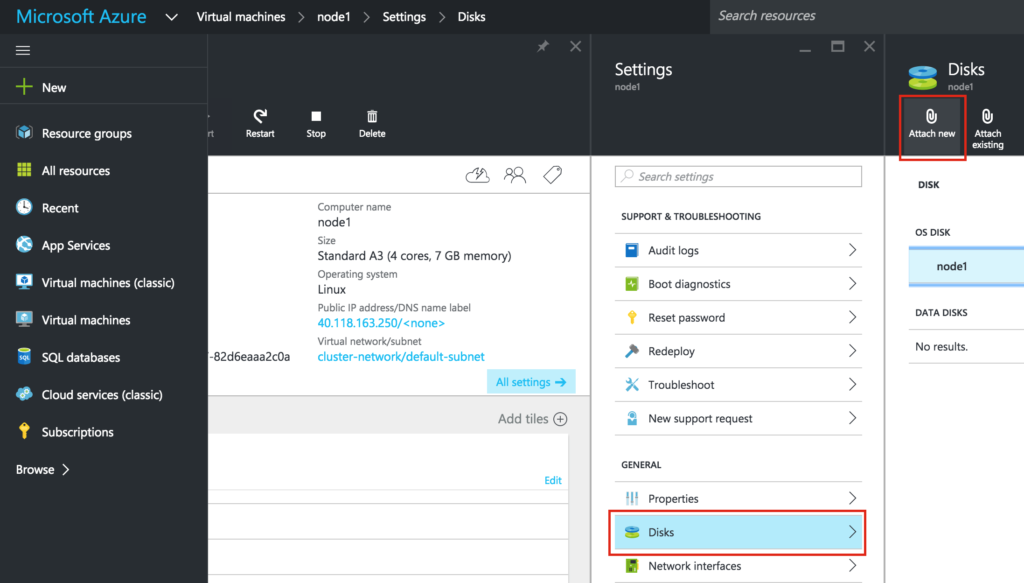
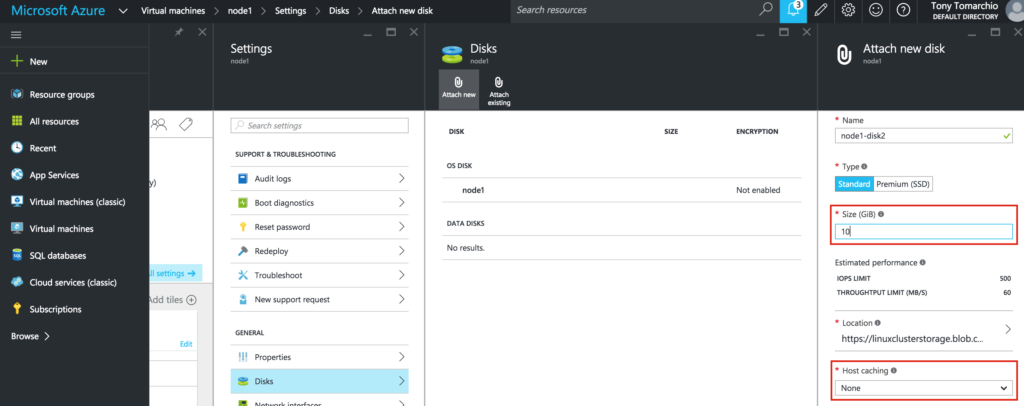
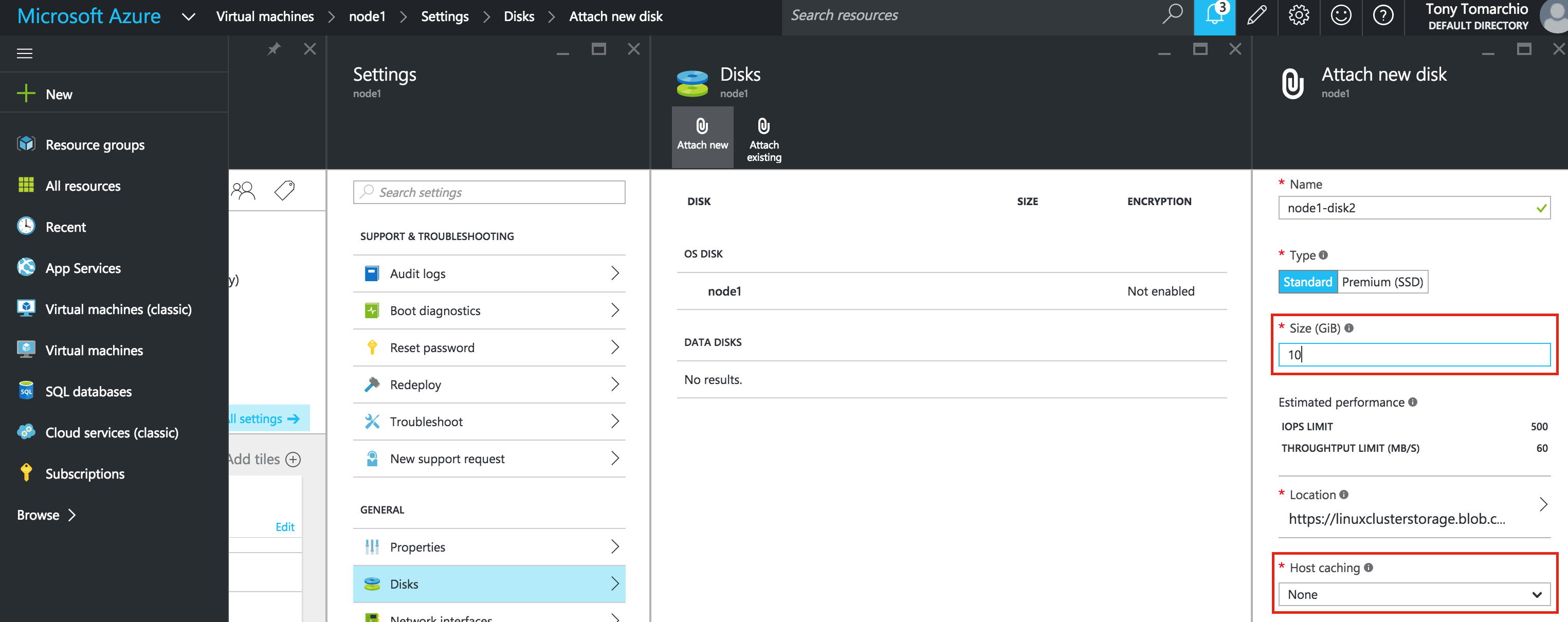
SQL Server for Linux – Public Preview Now Available
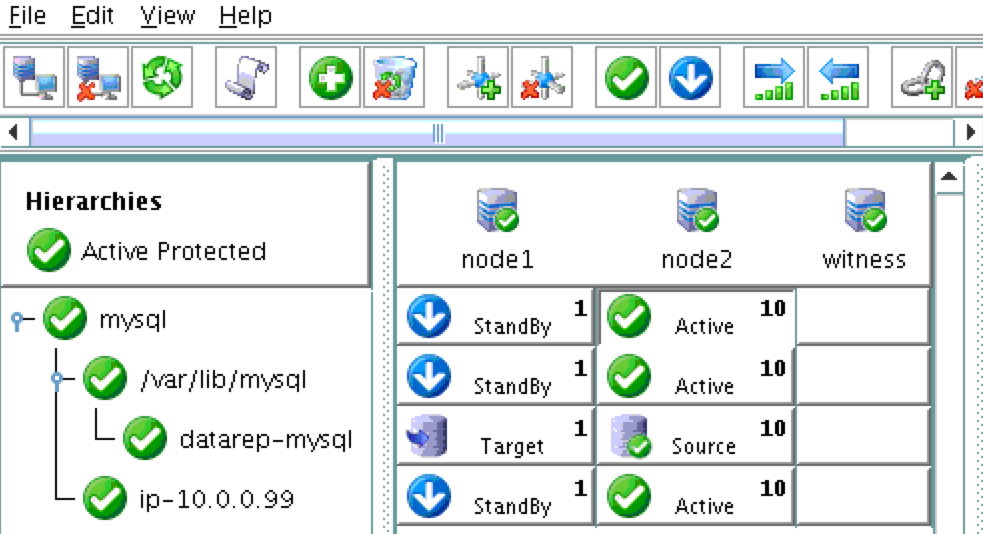
The public preview for SQL Server v.Next is now available. Microsoft has finally added support for Linux. Check out the link below for more information. I’ll be downloading and looking at the high availability features shortly. Stay tuned!
SQL Server v.Next Public Preview:
https://www.microsoft.com/en-us/sql-server/sql-server-vnext-including-Linux
Original SQL Server Linux announcement:
https://blogs.microsoft.com/blog/2016/03/07/announcing-sql-server-on-linux/
Reproduced with permission from Linuxclustering

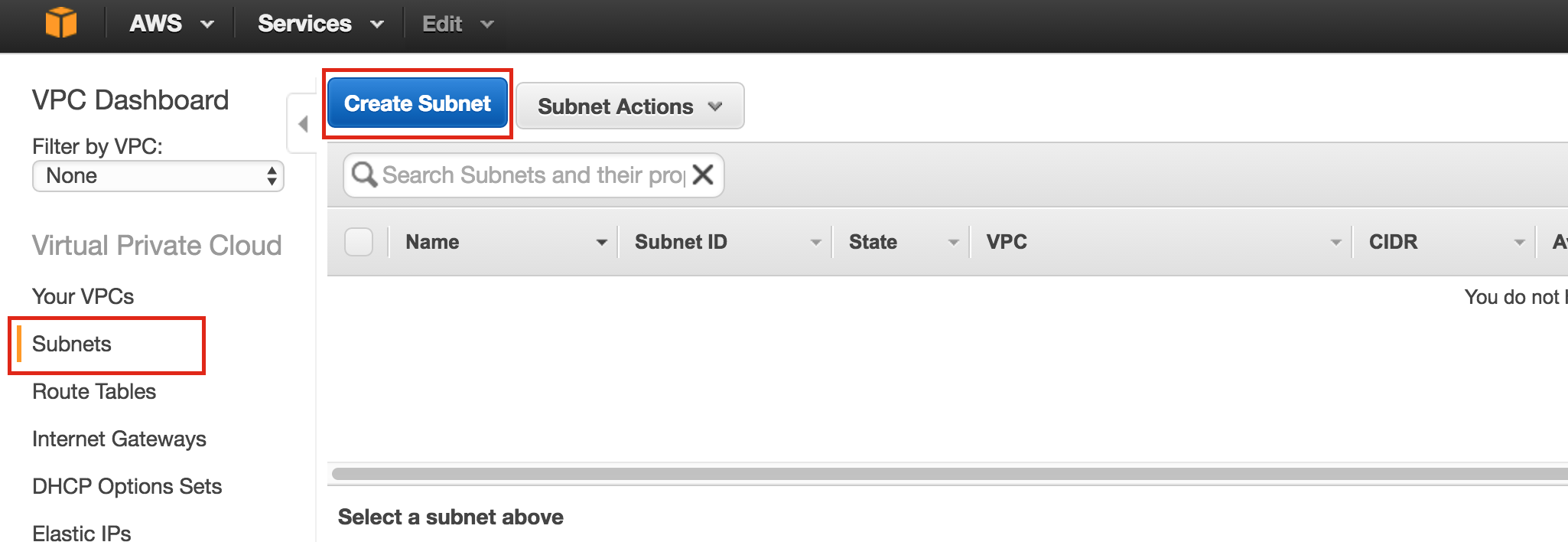
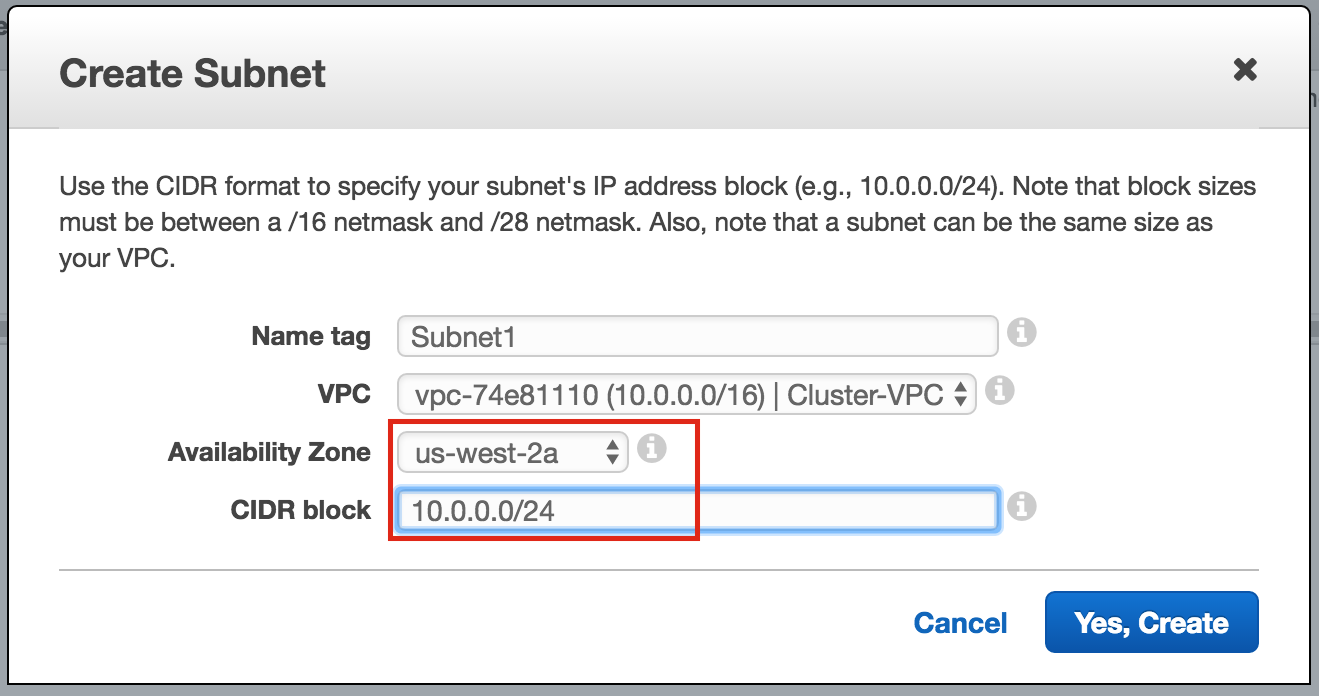
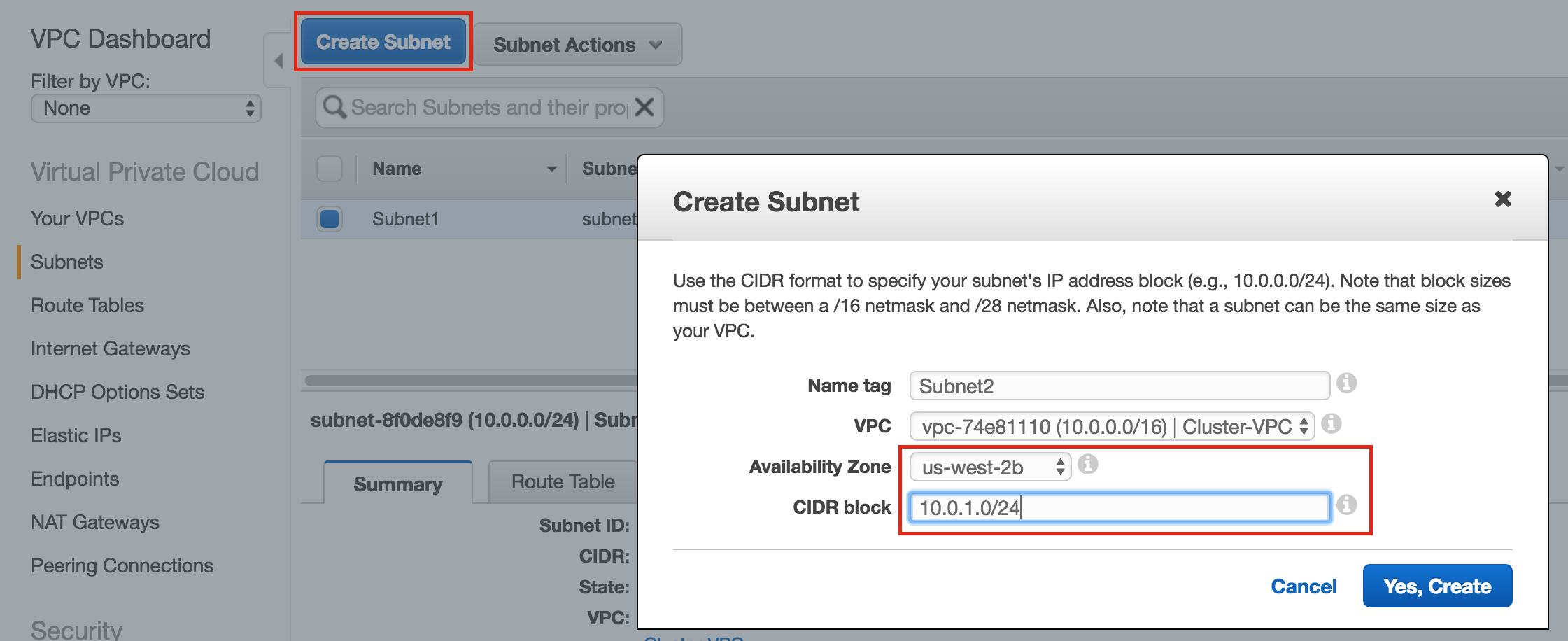
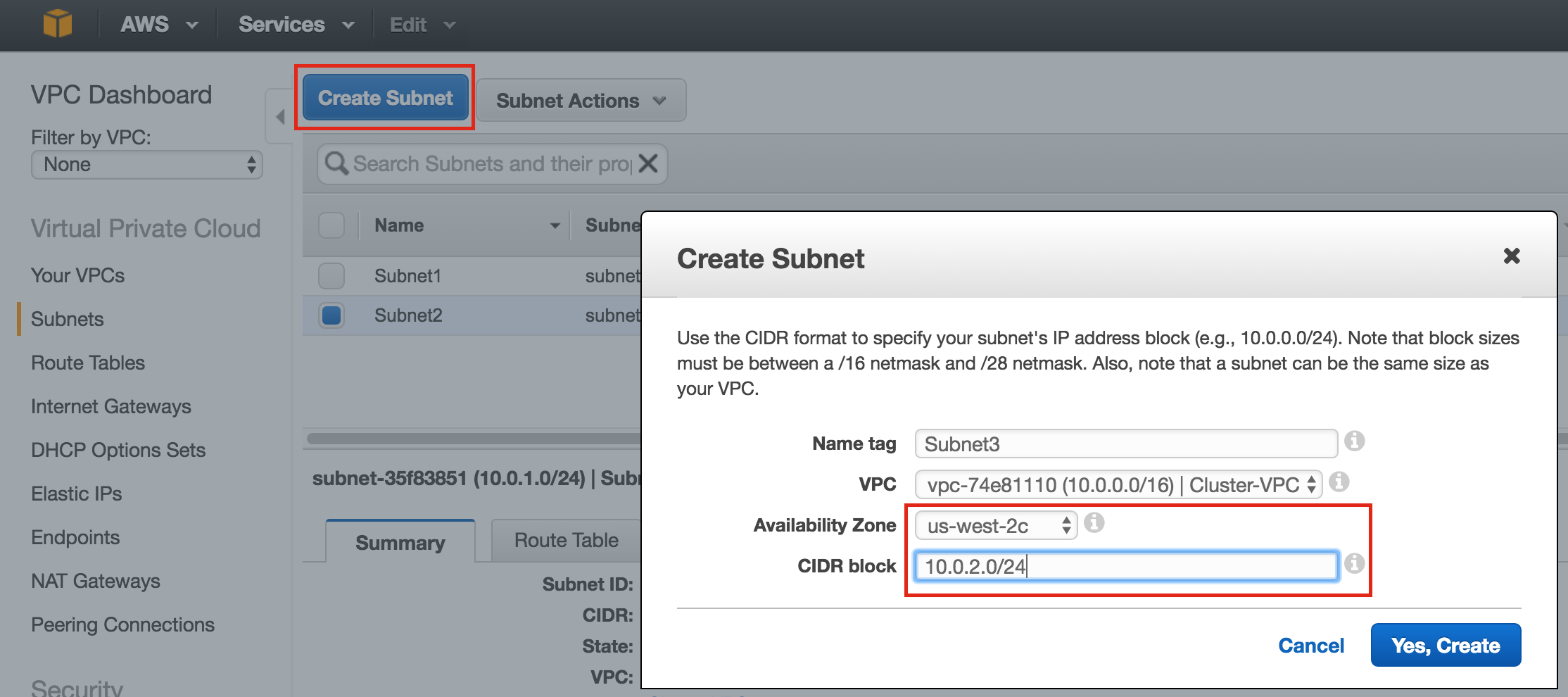
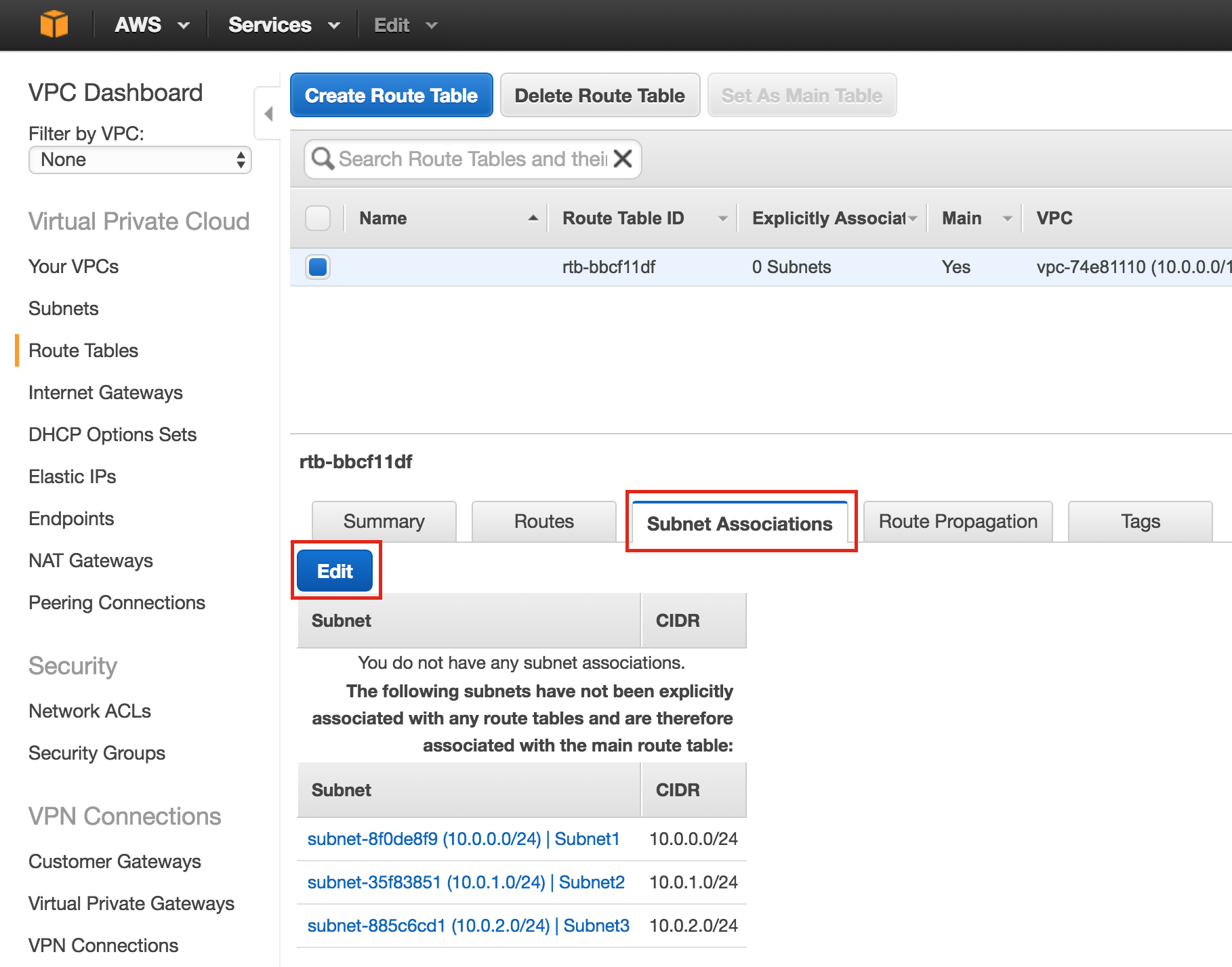
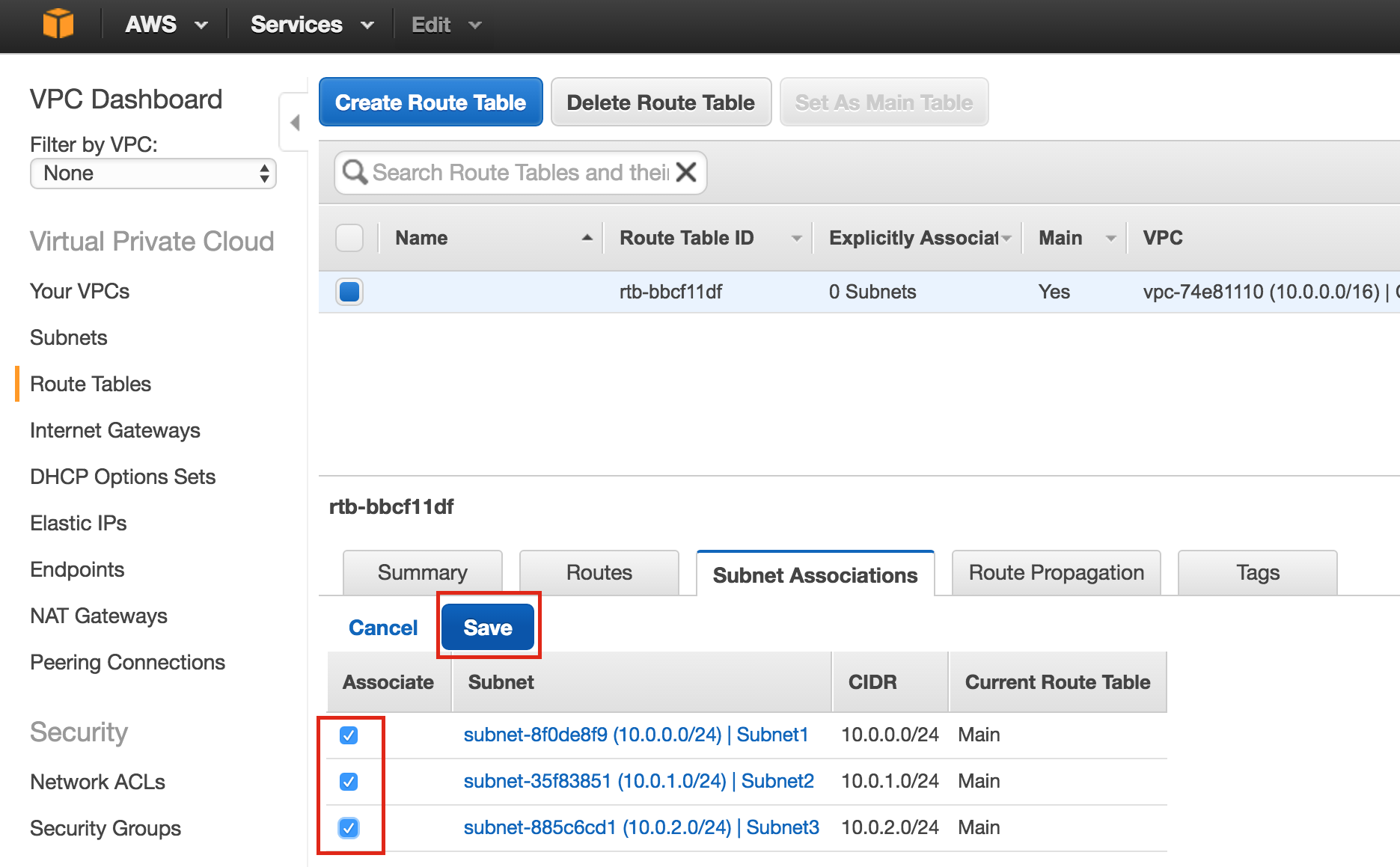

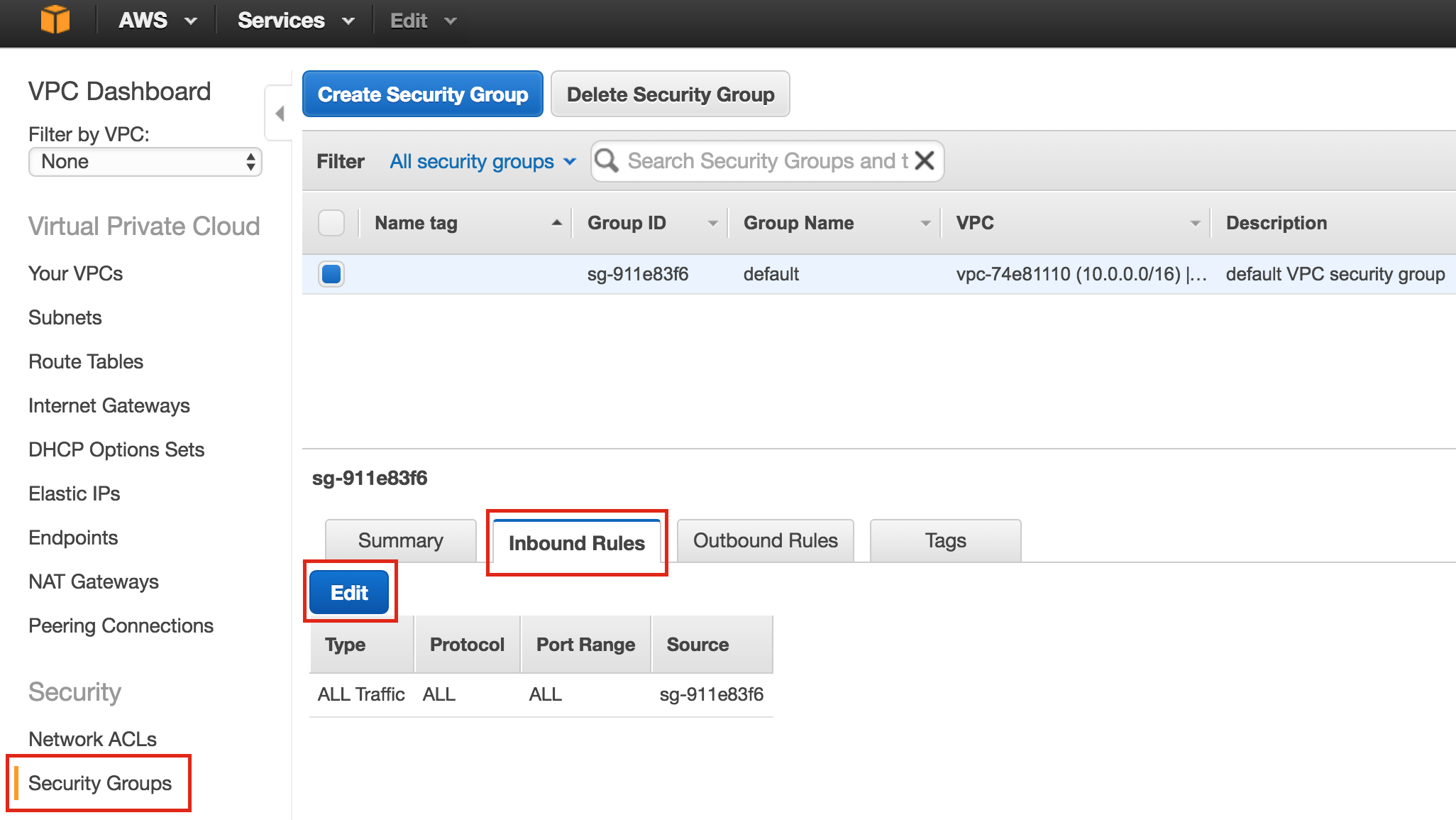
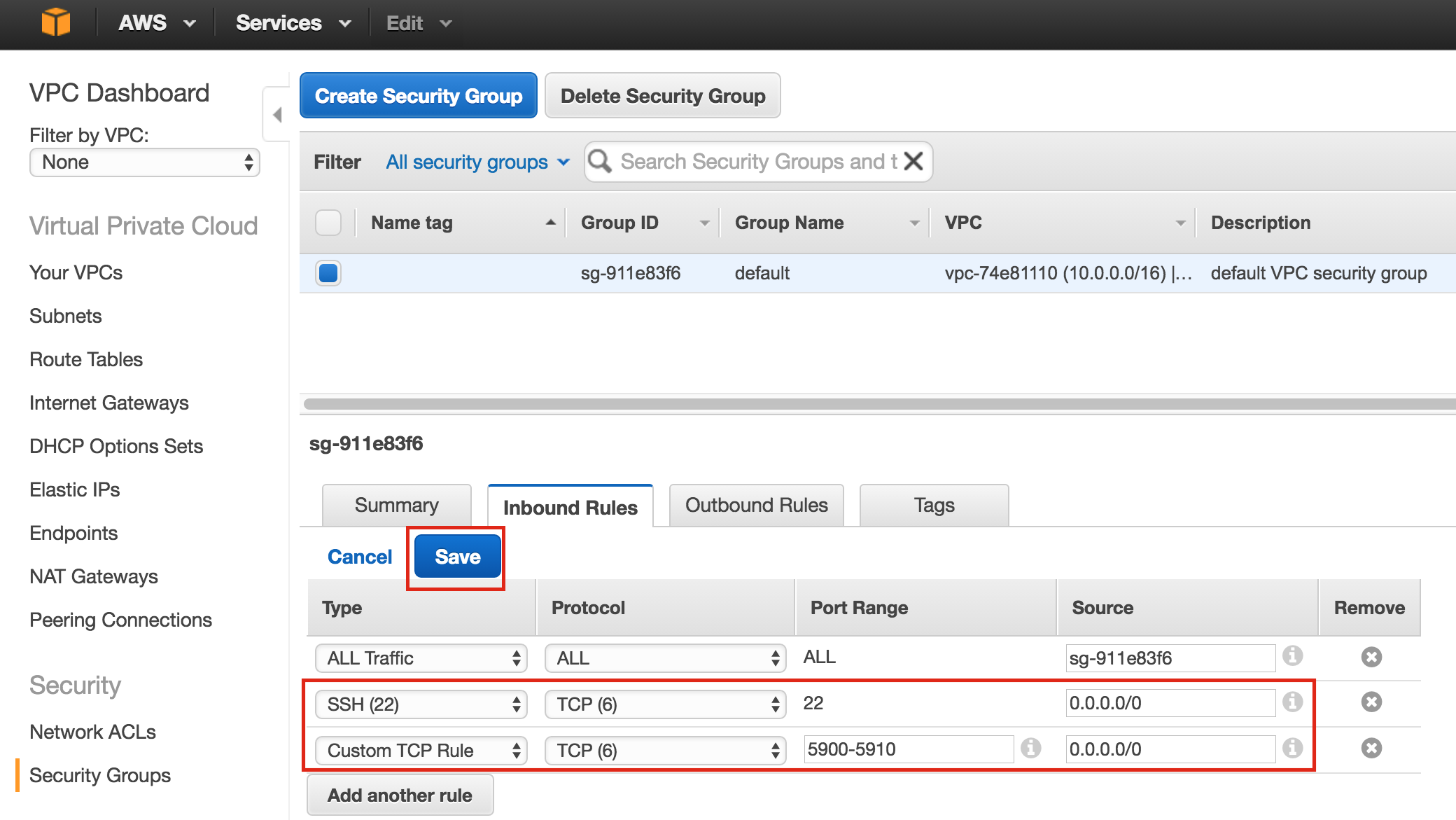
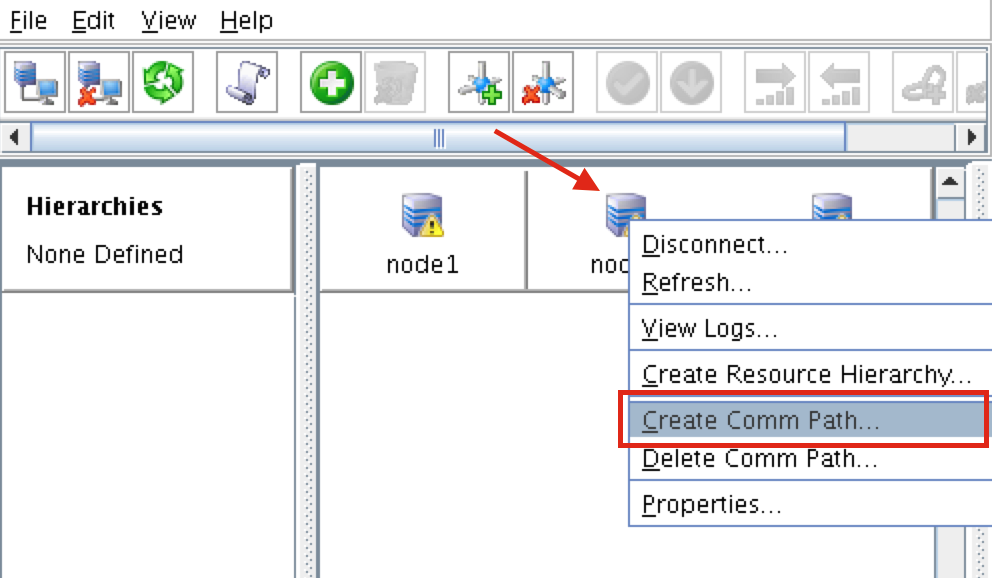
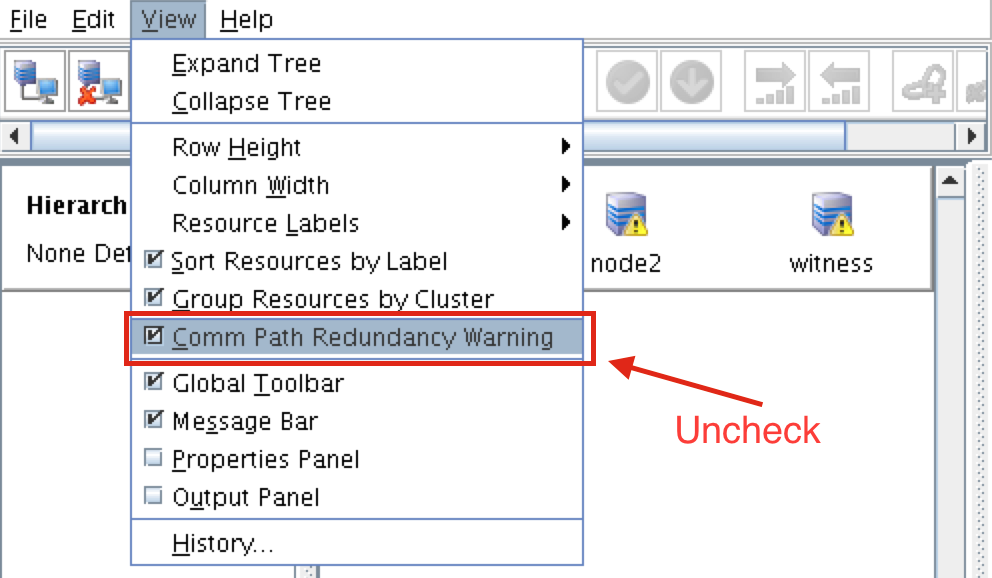
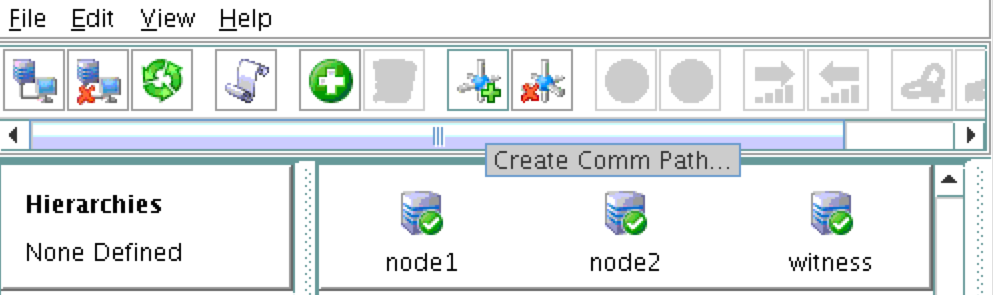
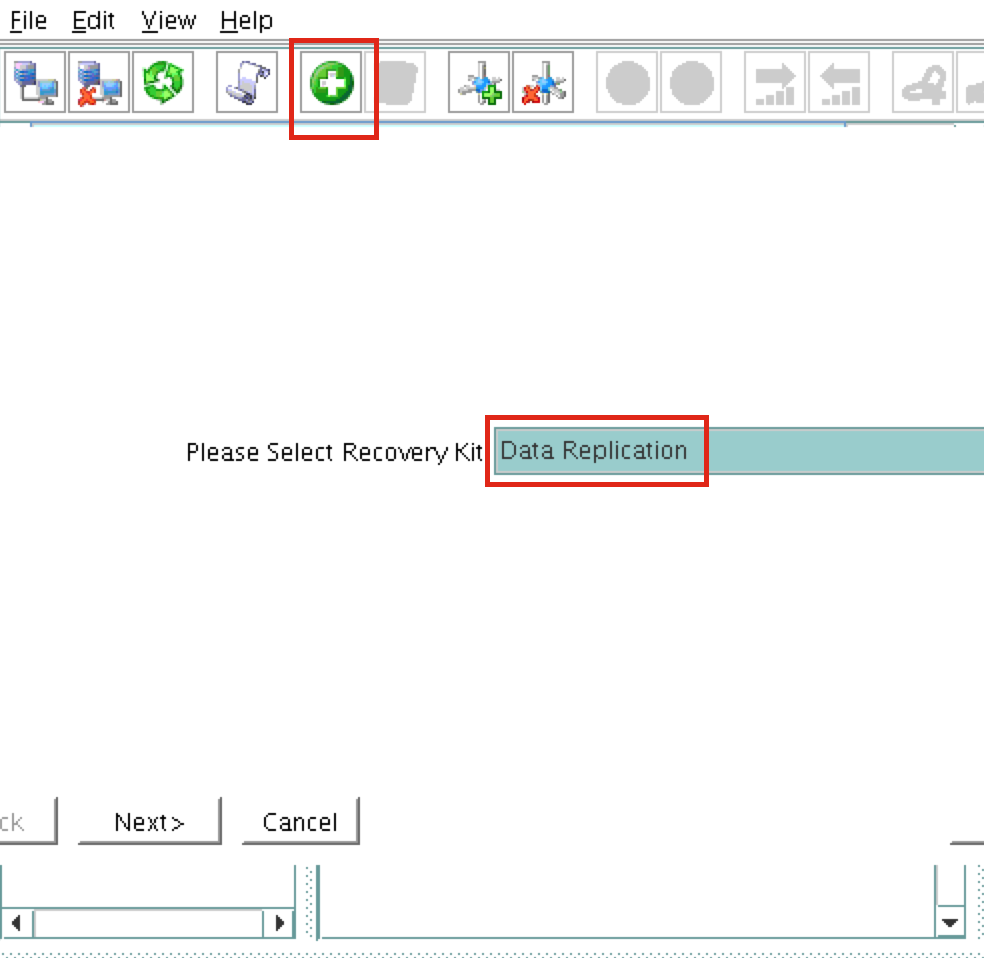
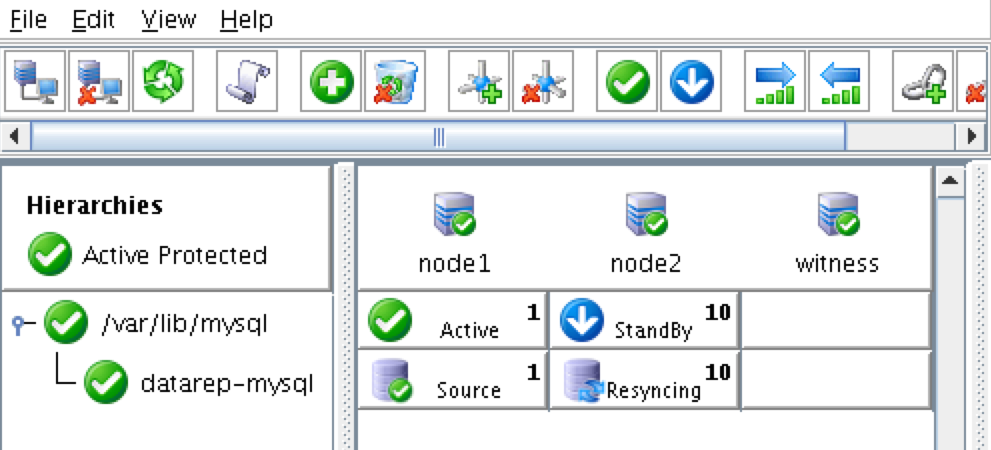
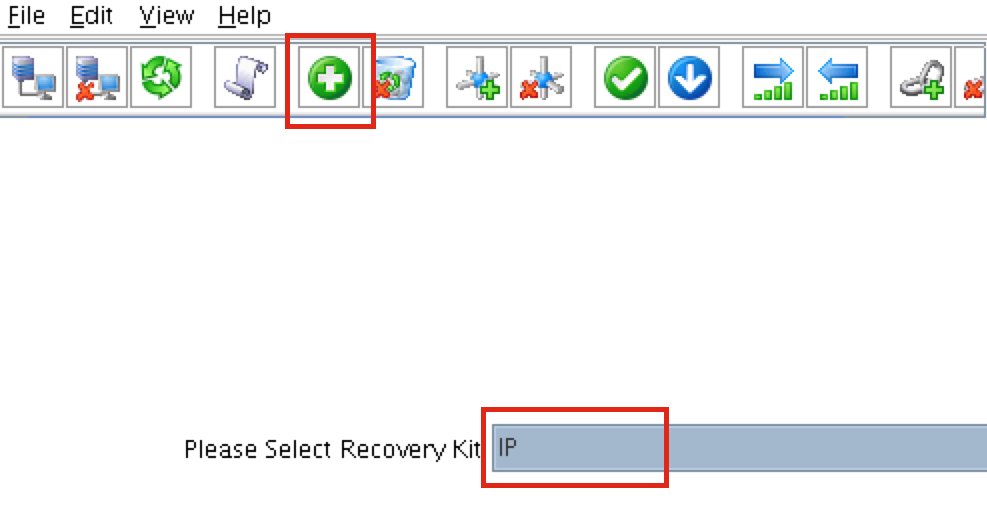
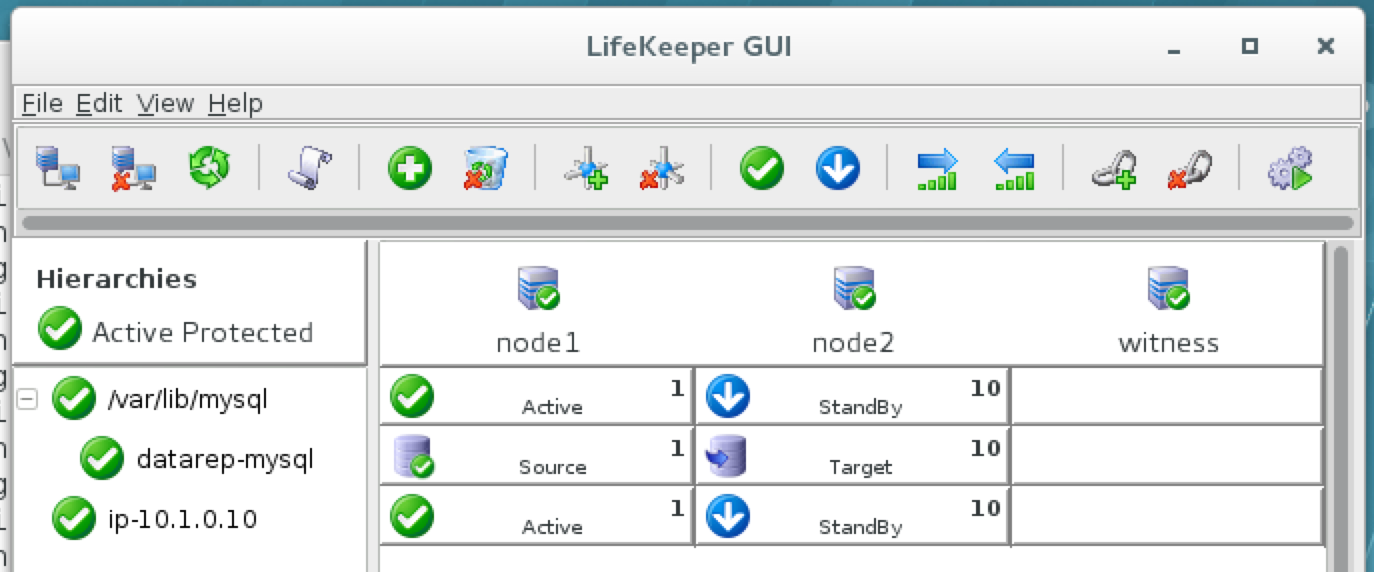
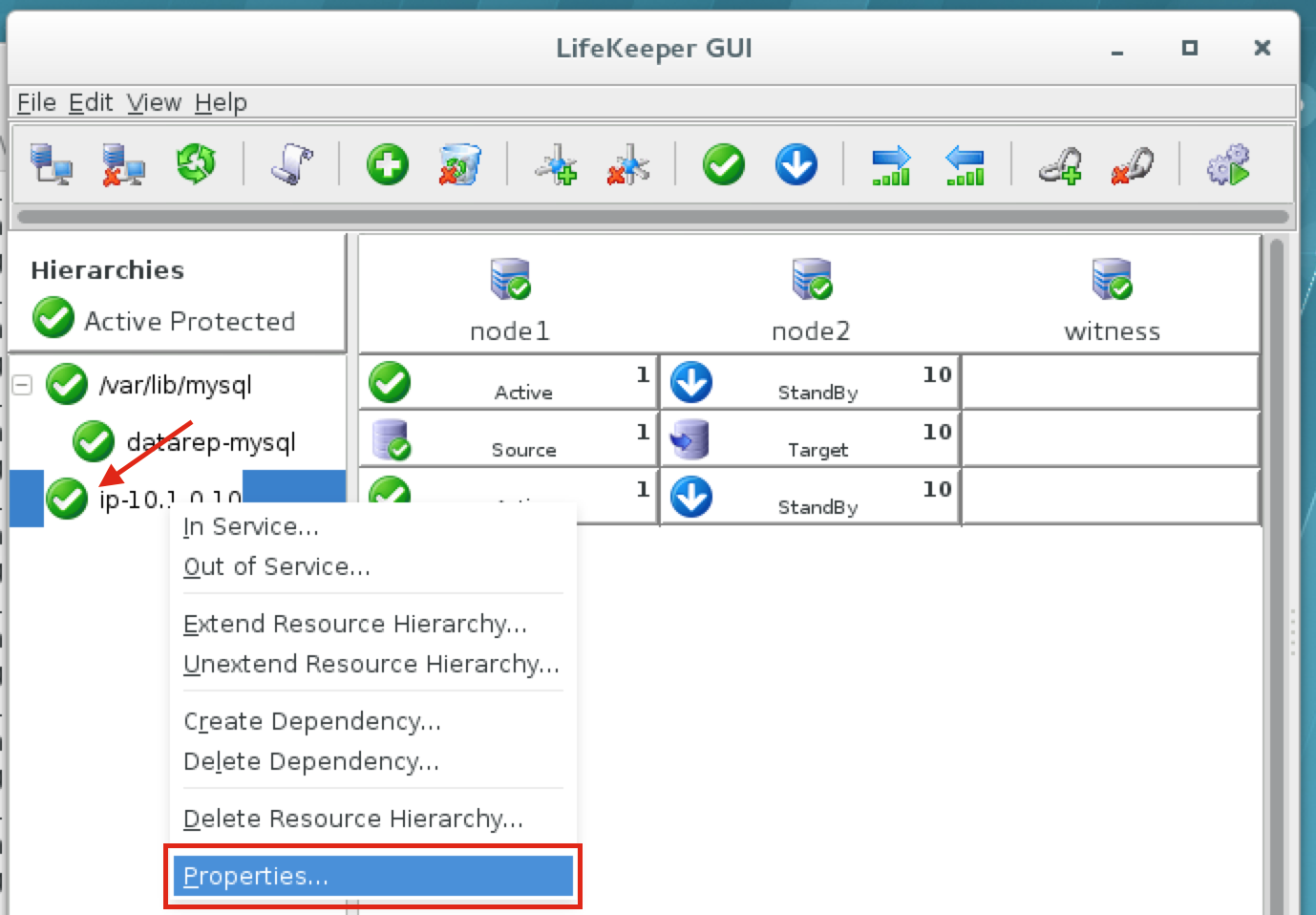
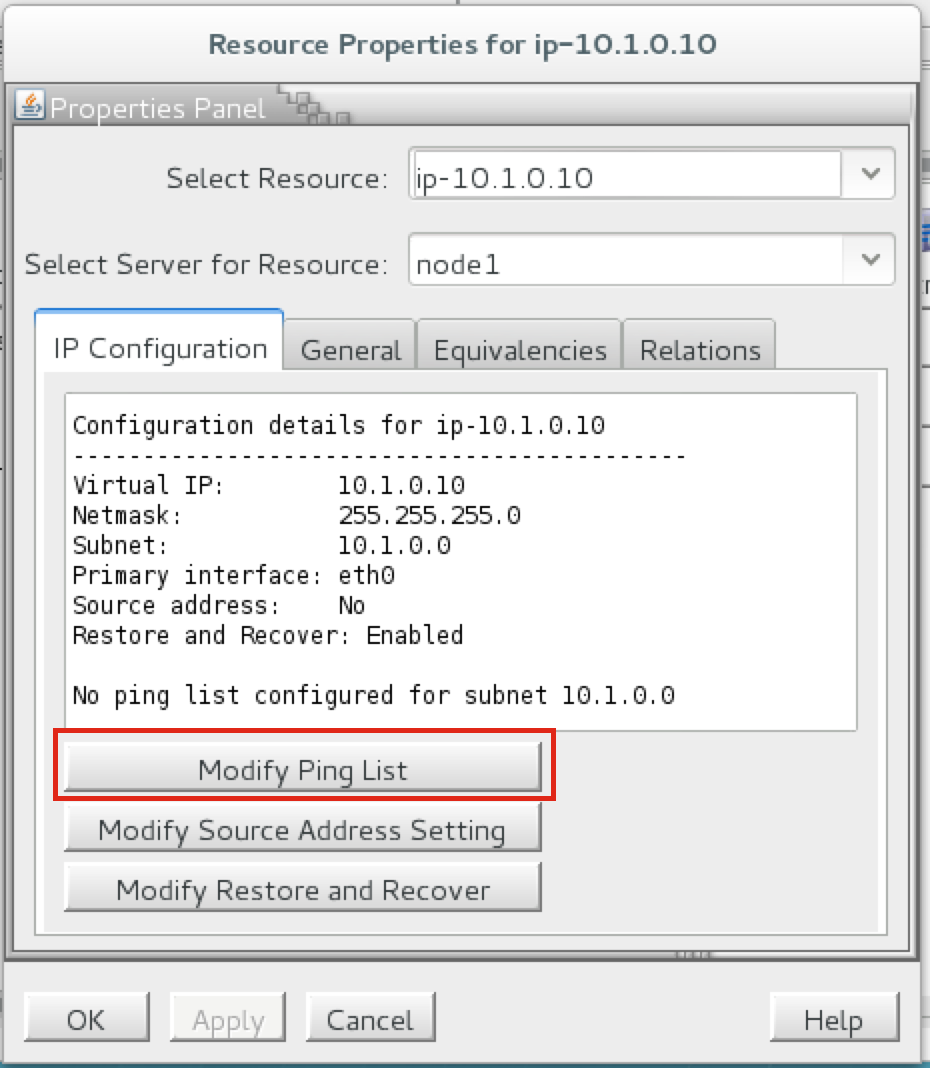
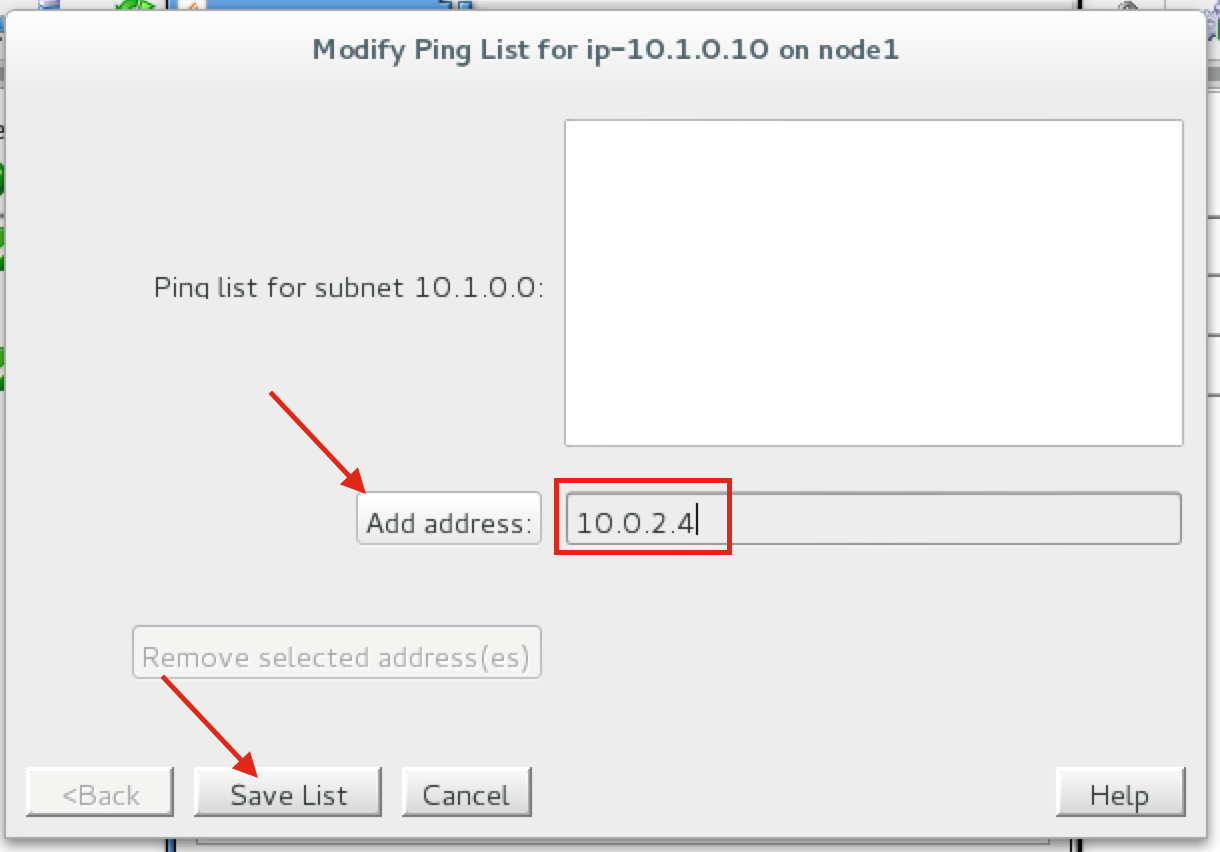
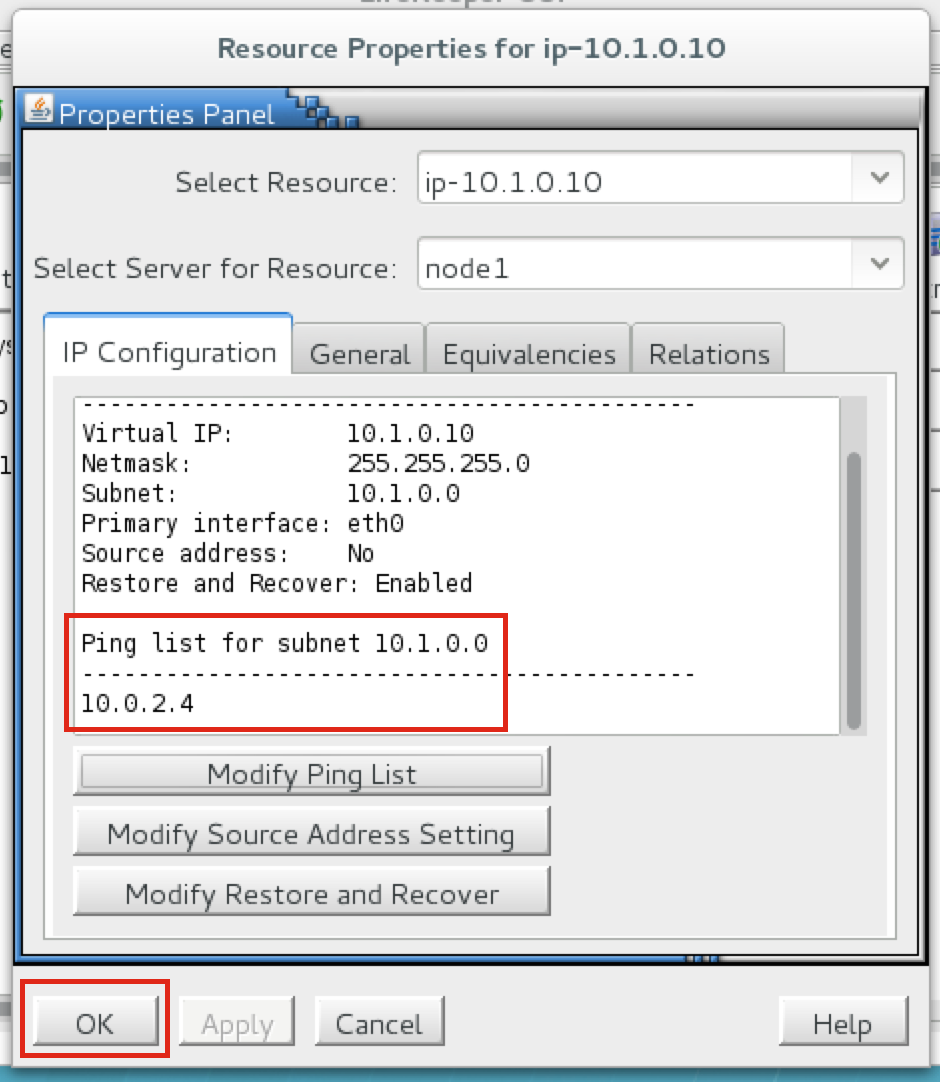
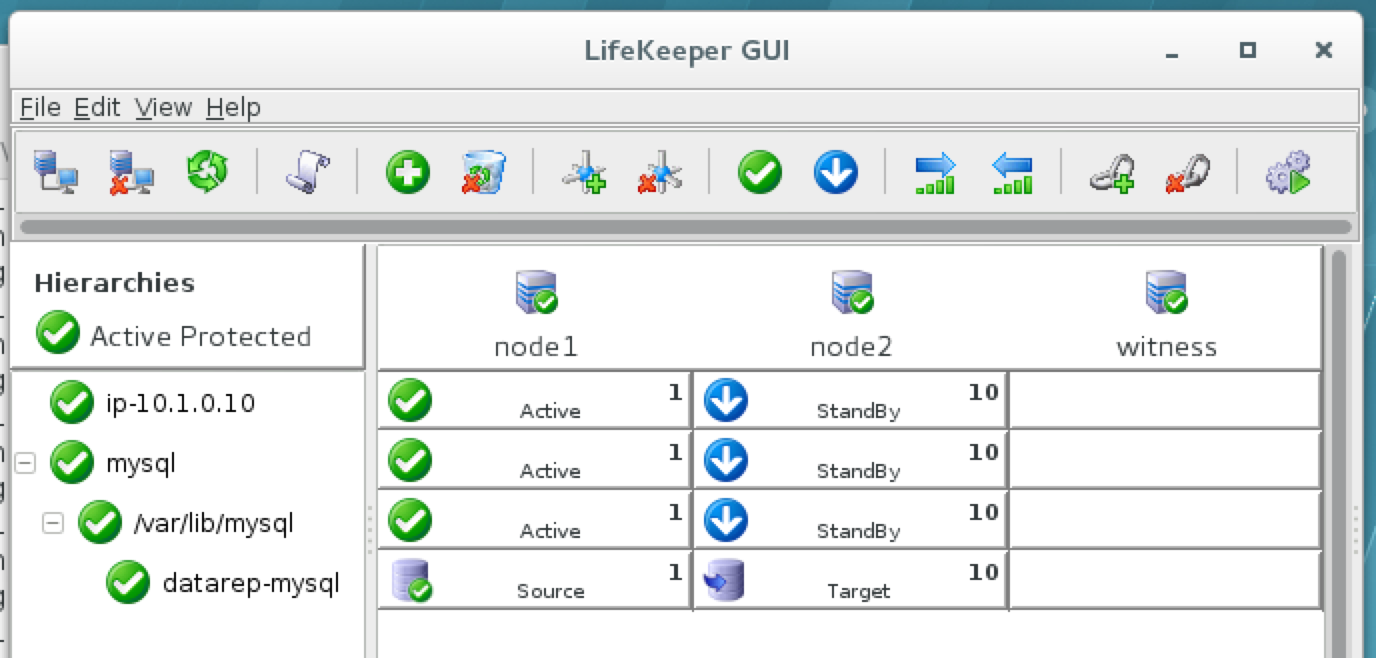
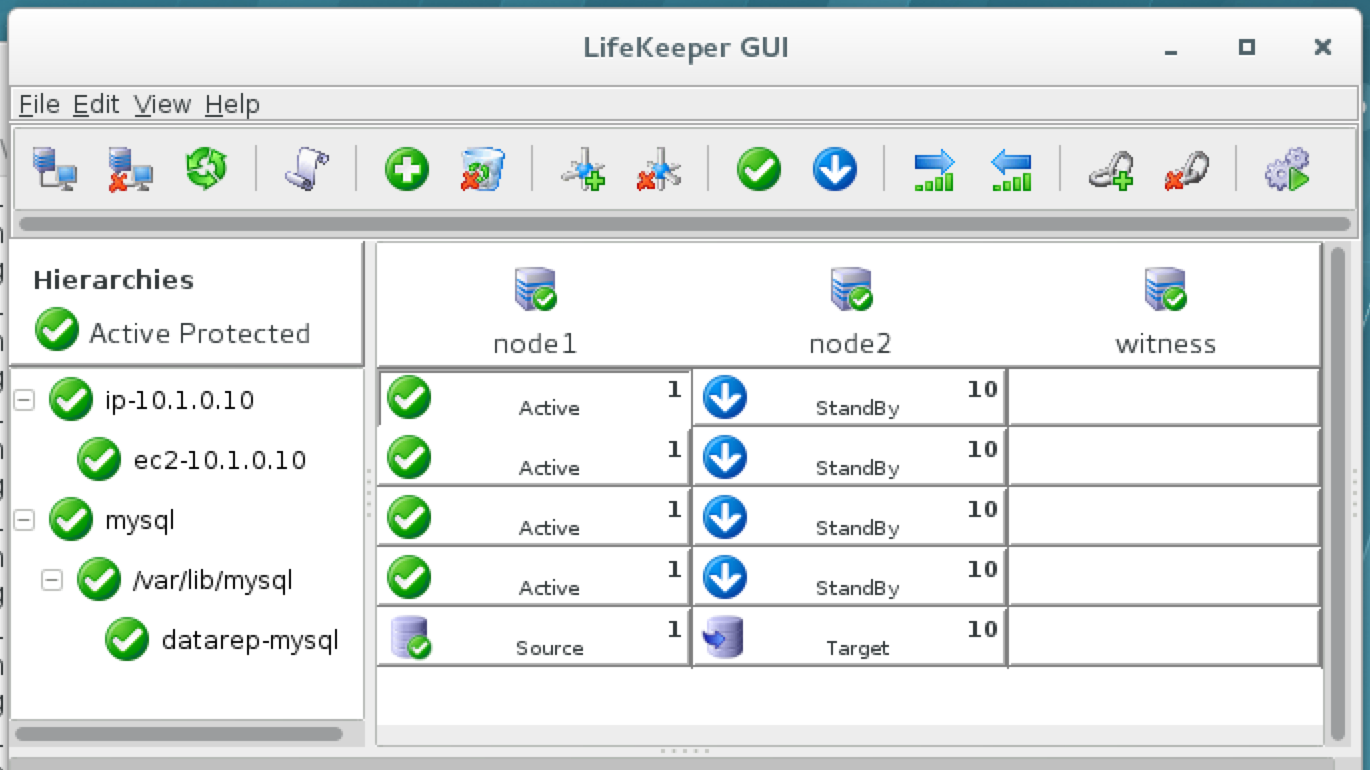
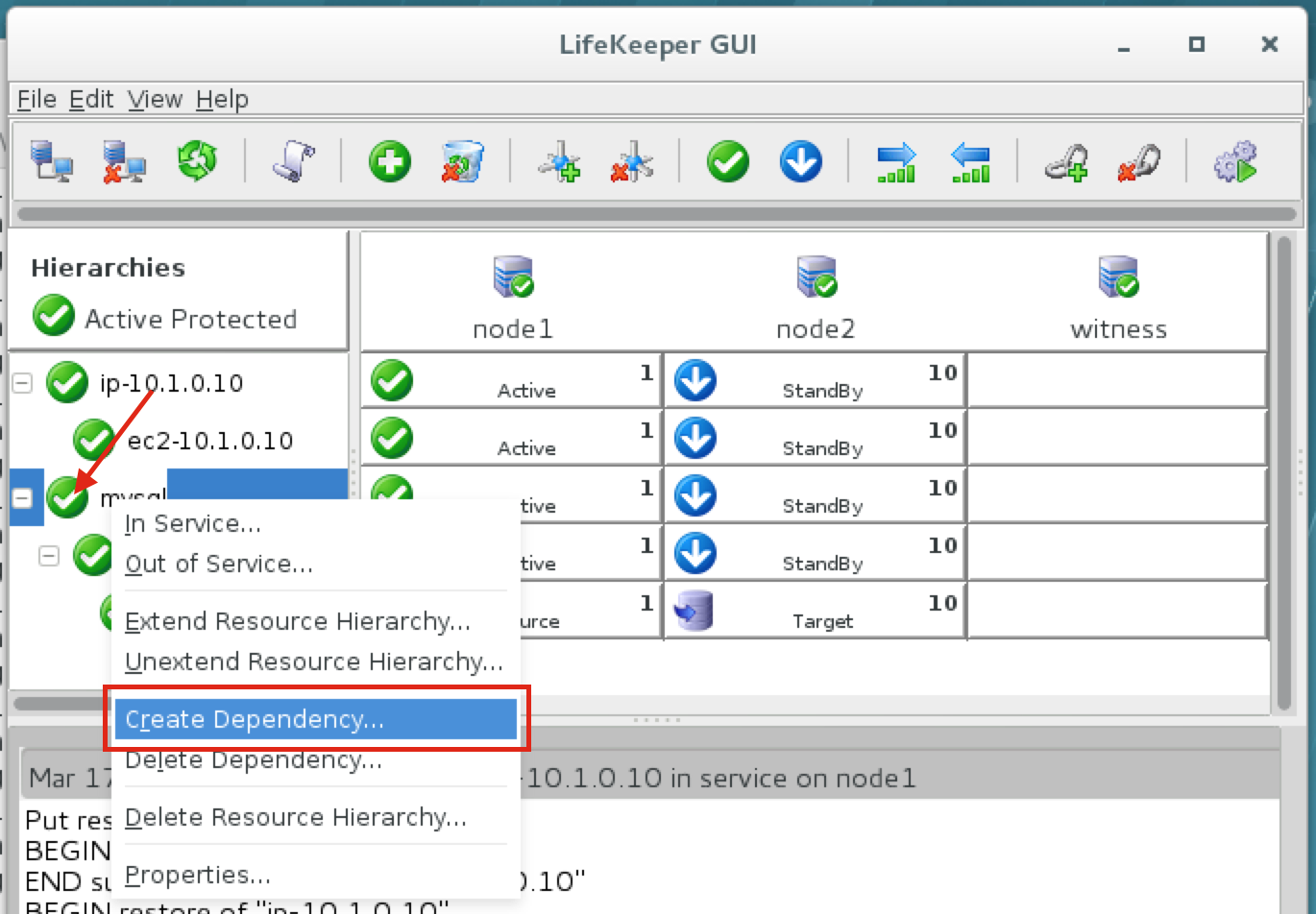
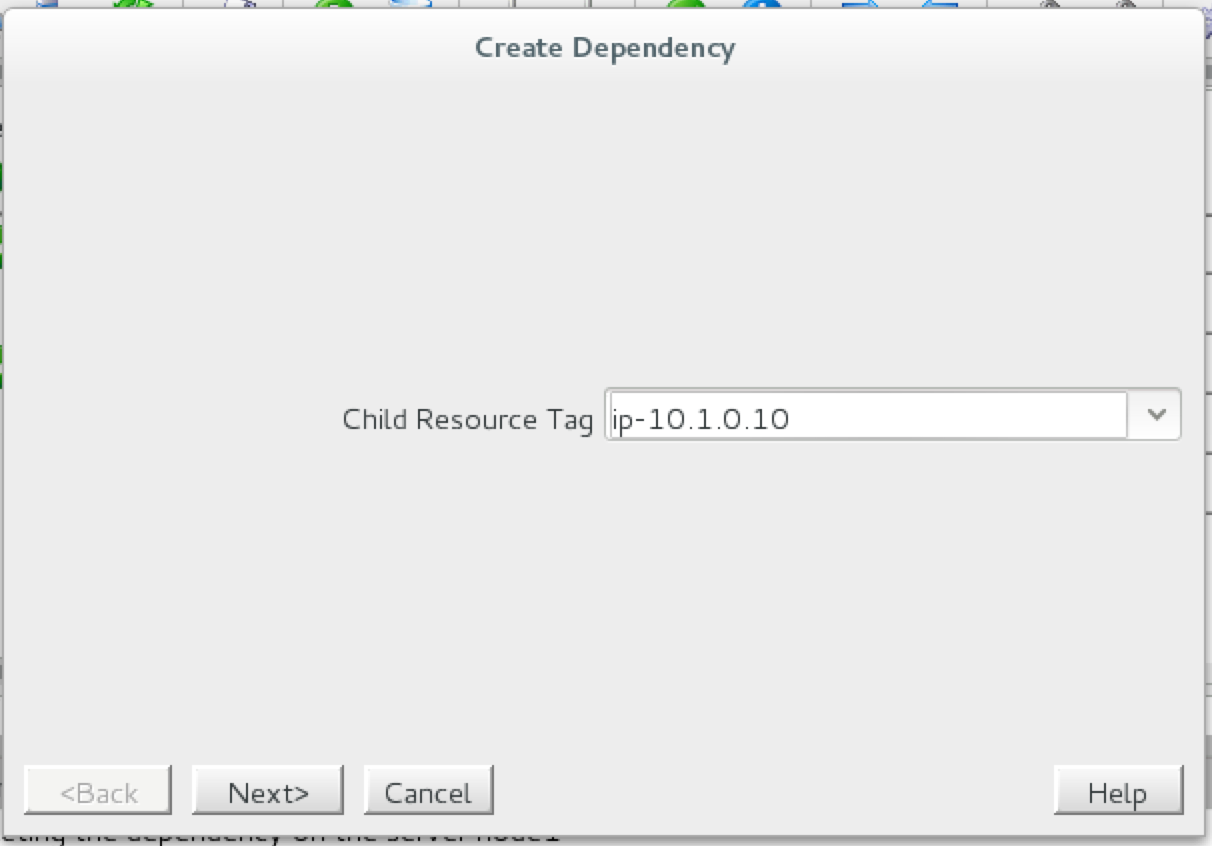
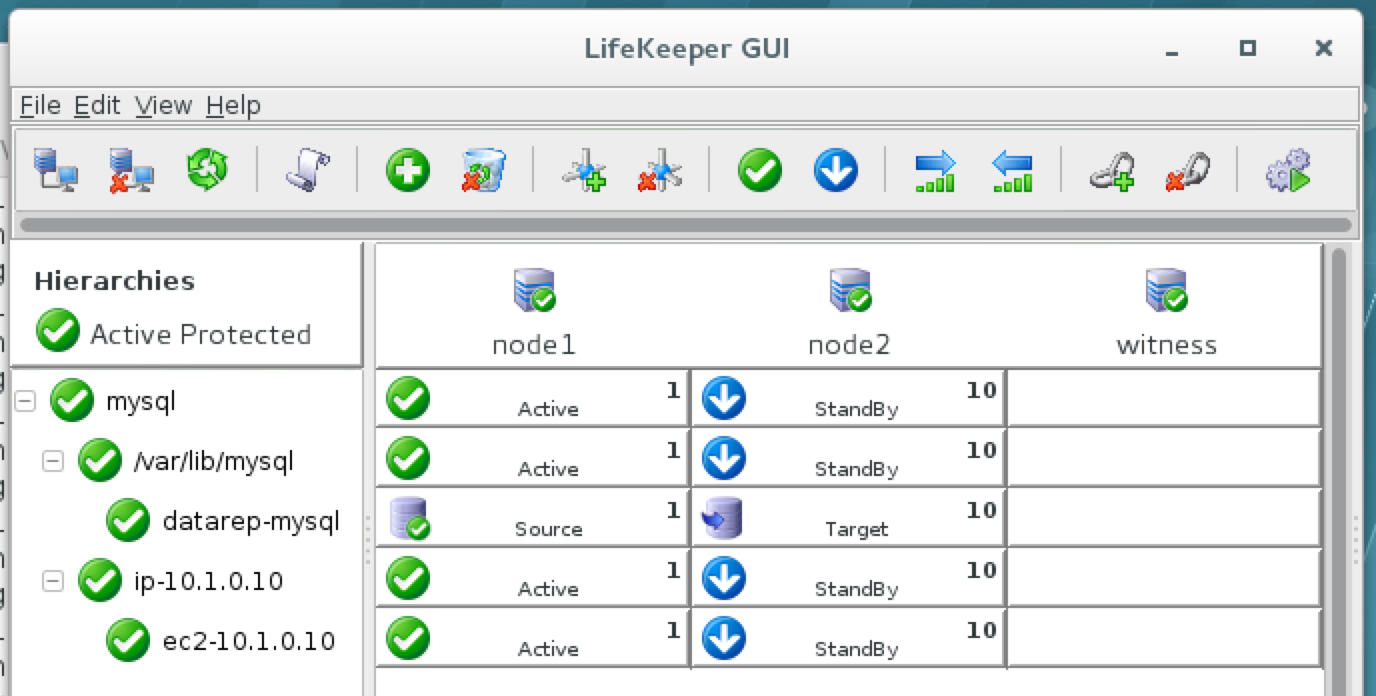
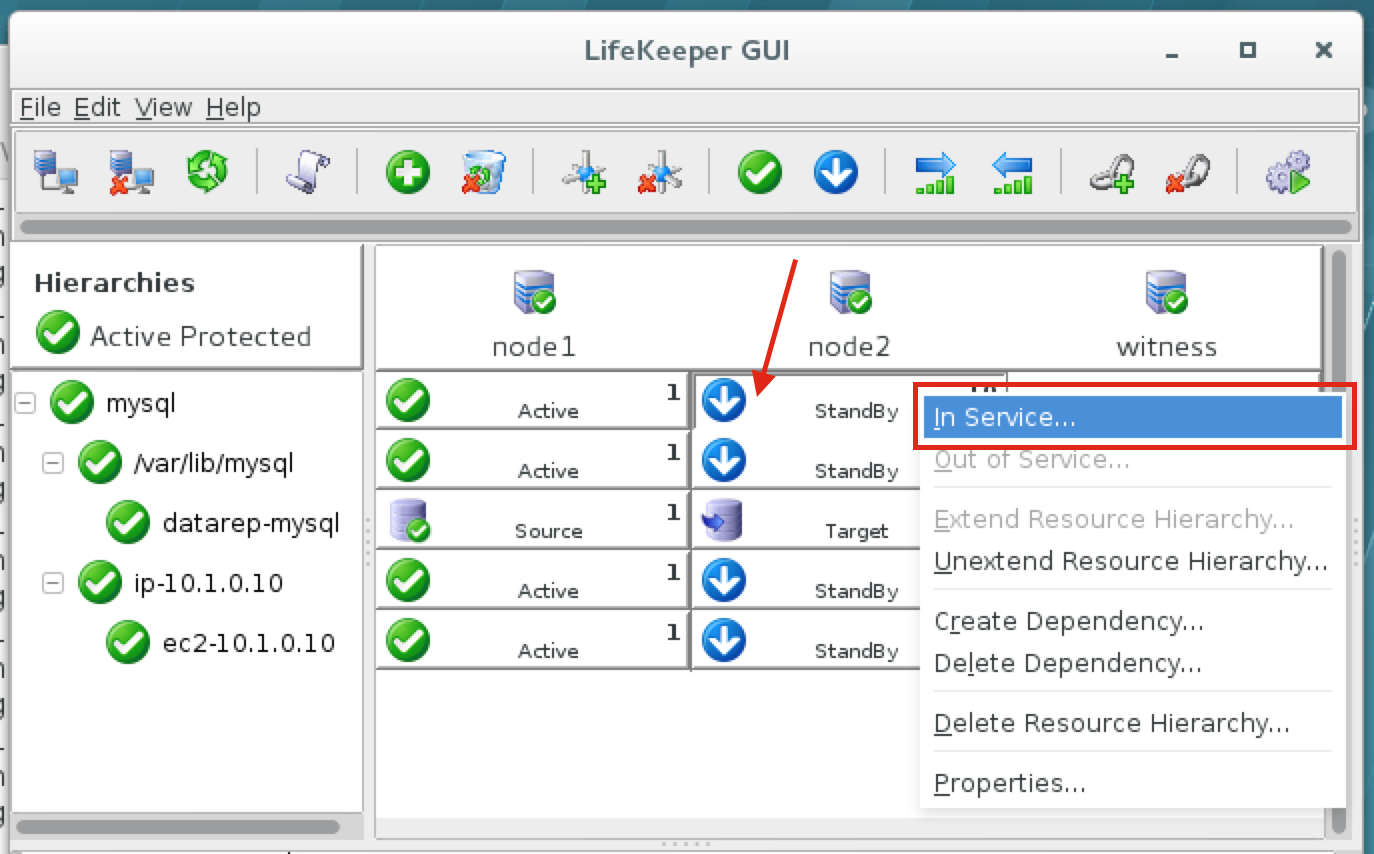
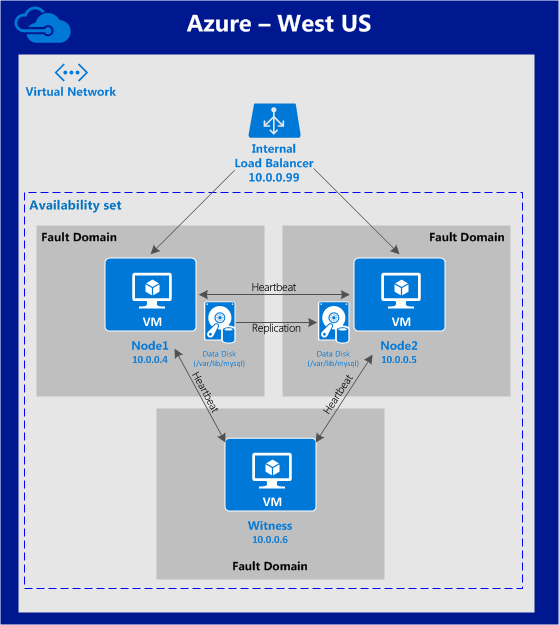
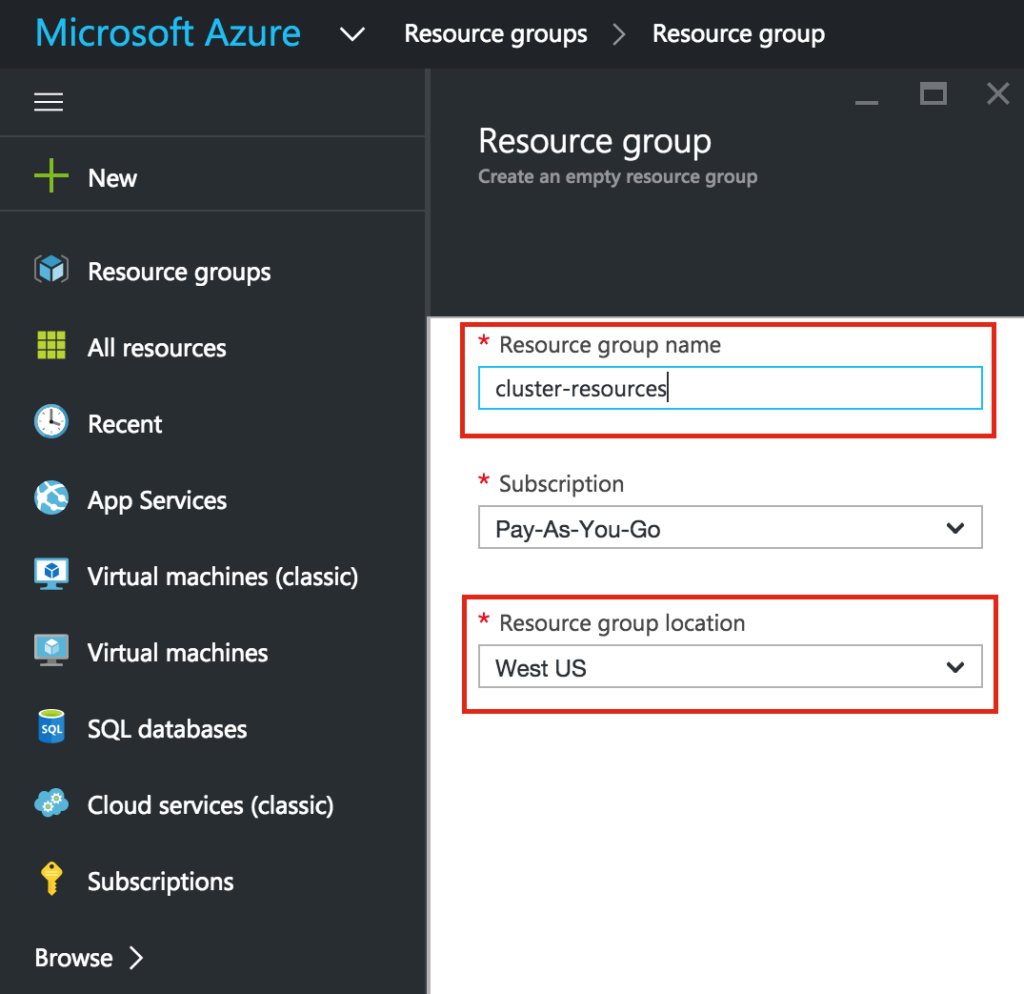
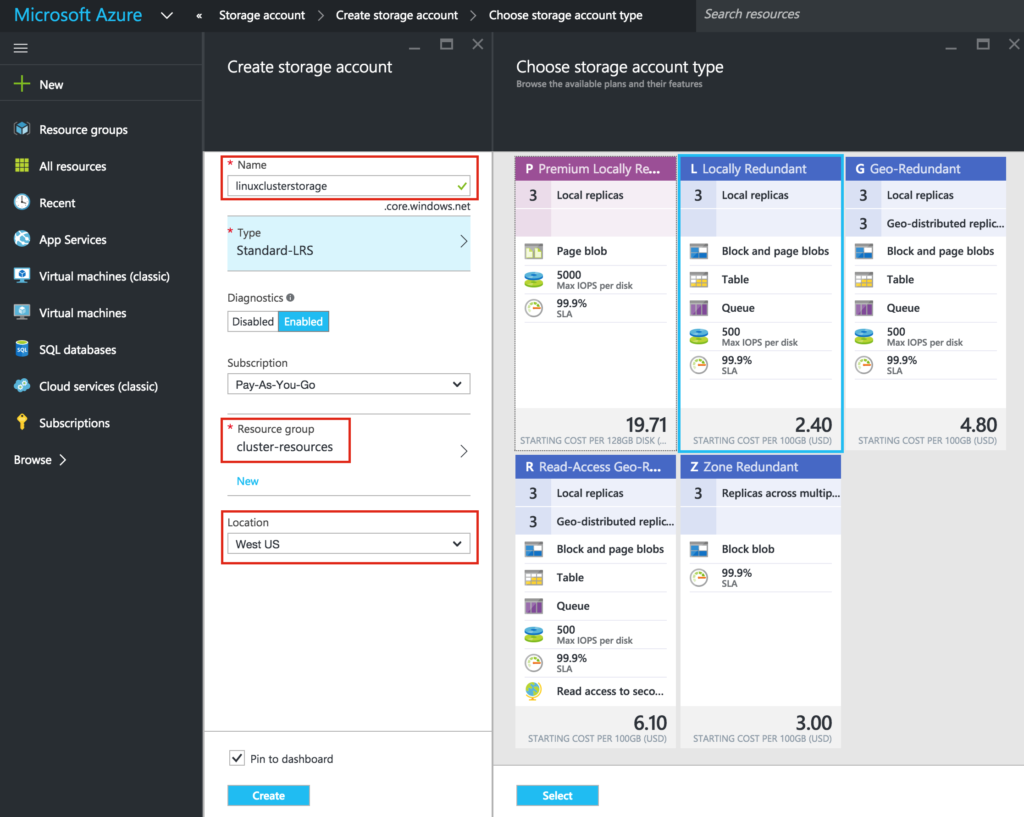
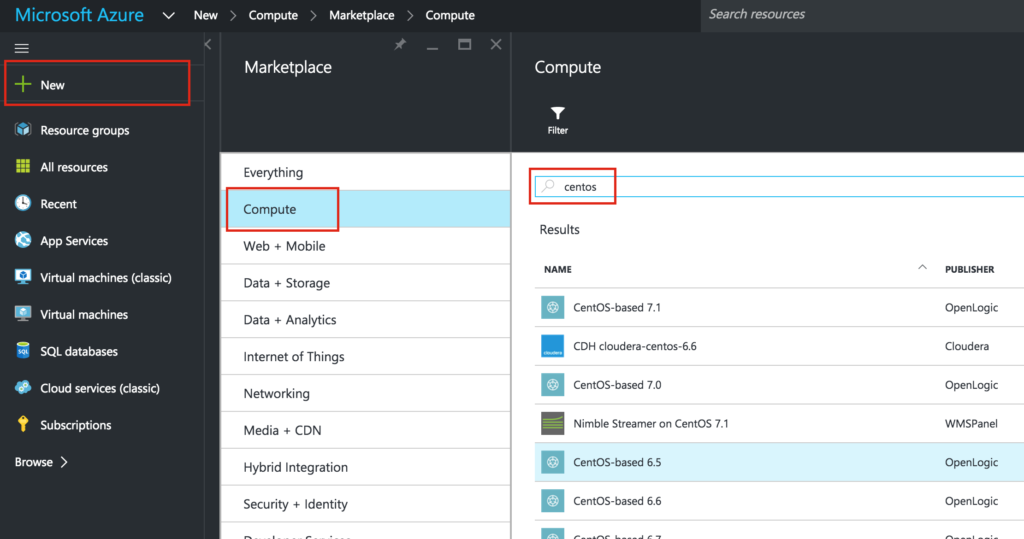
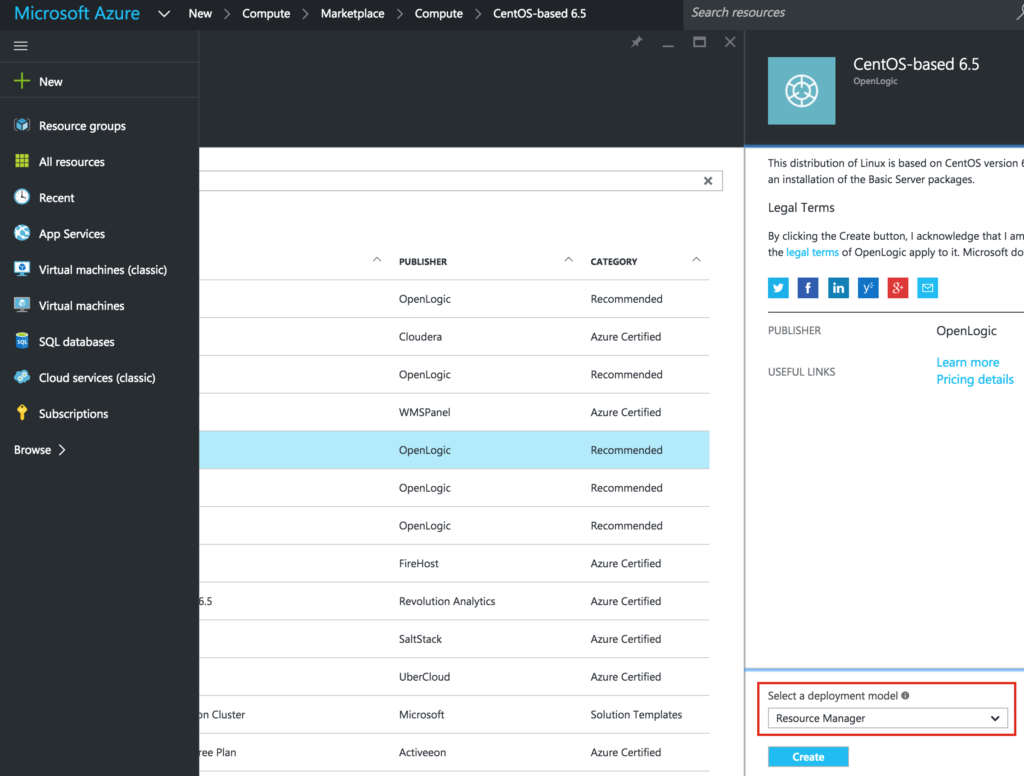
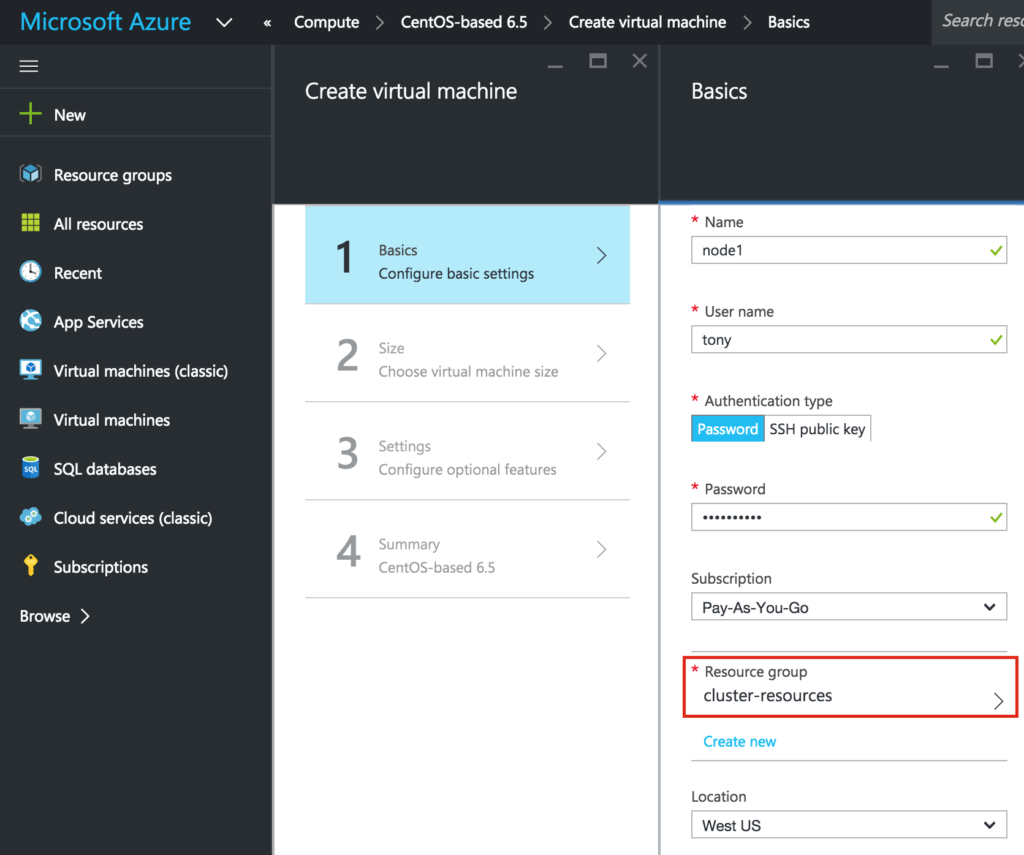
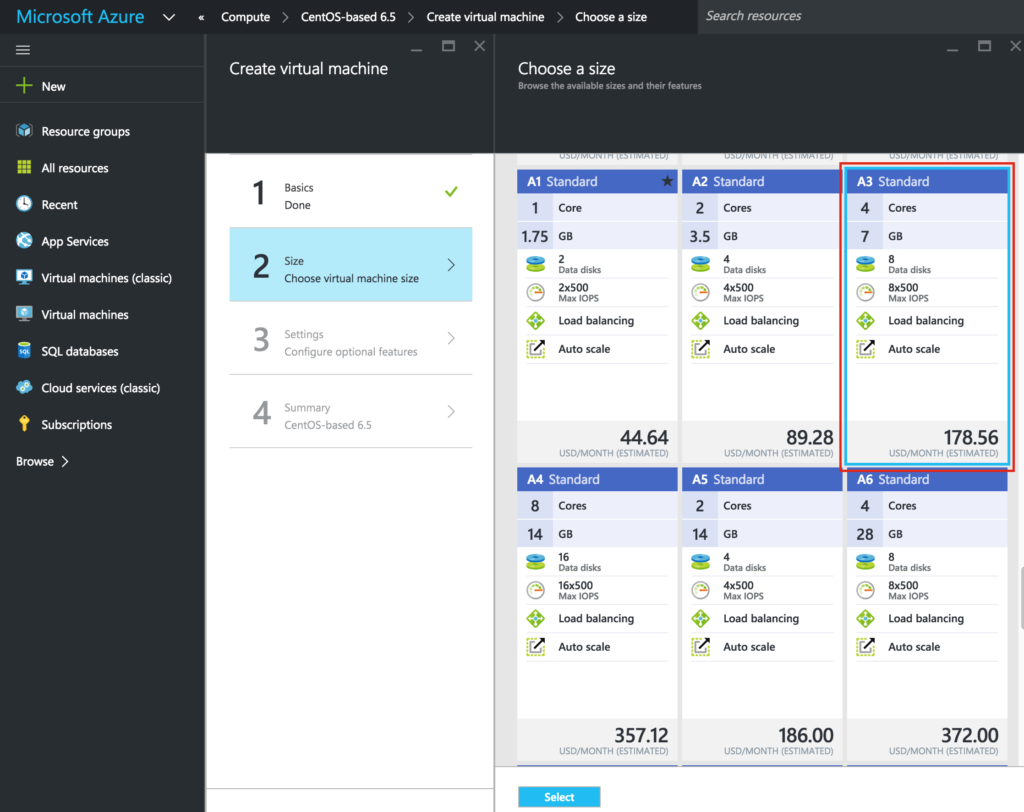
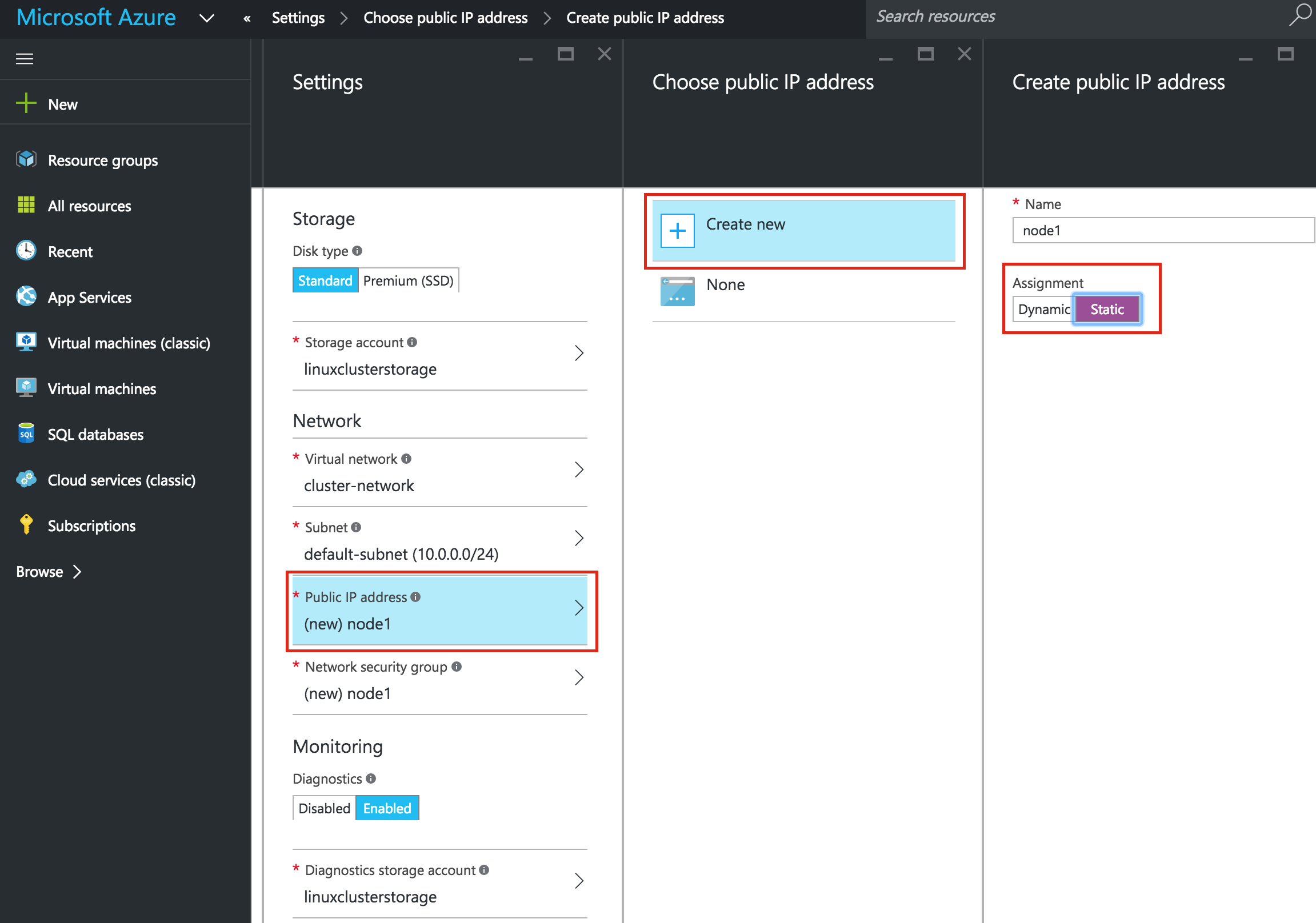
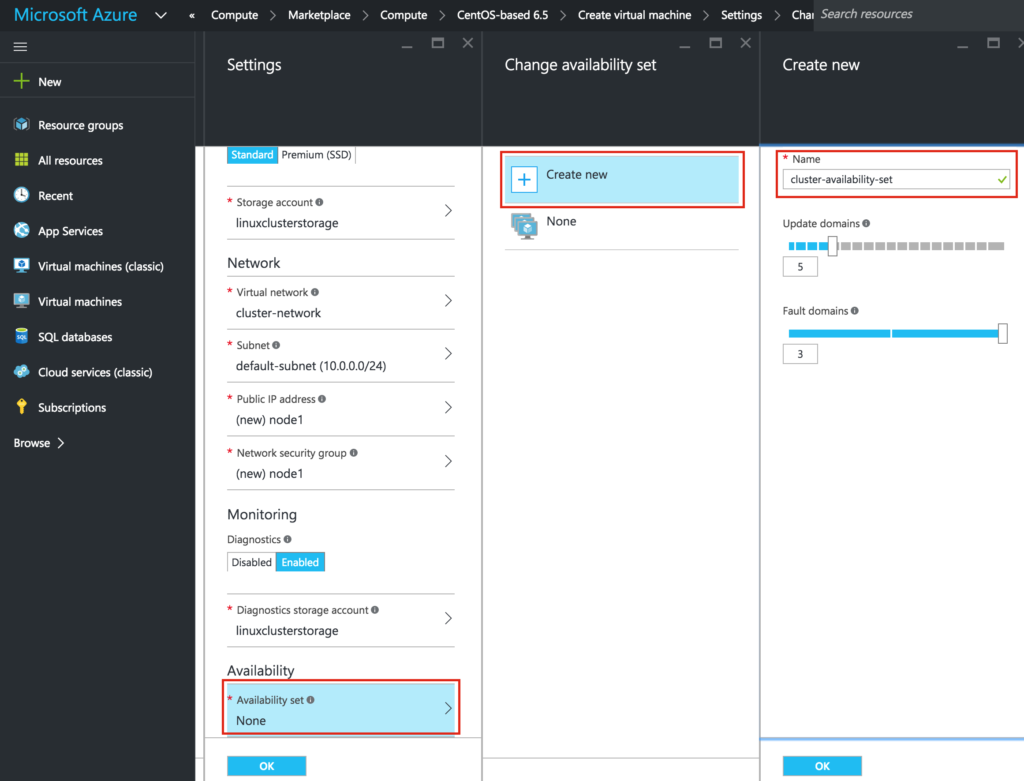
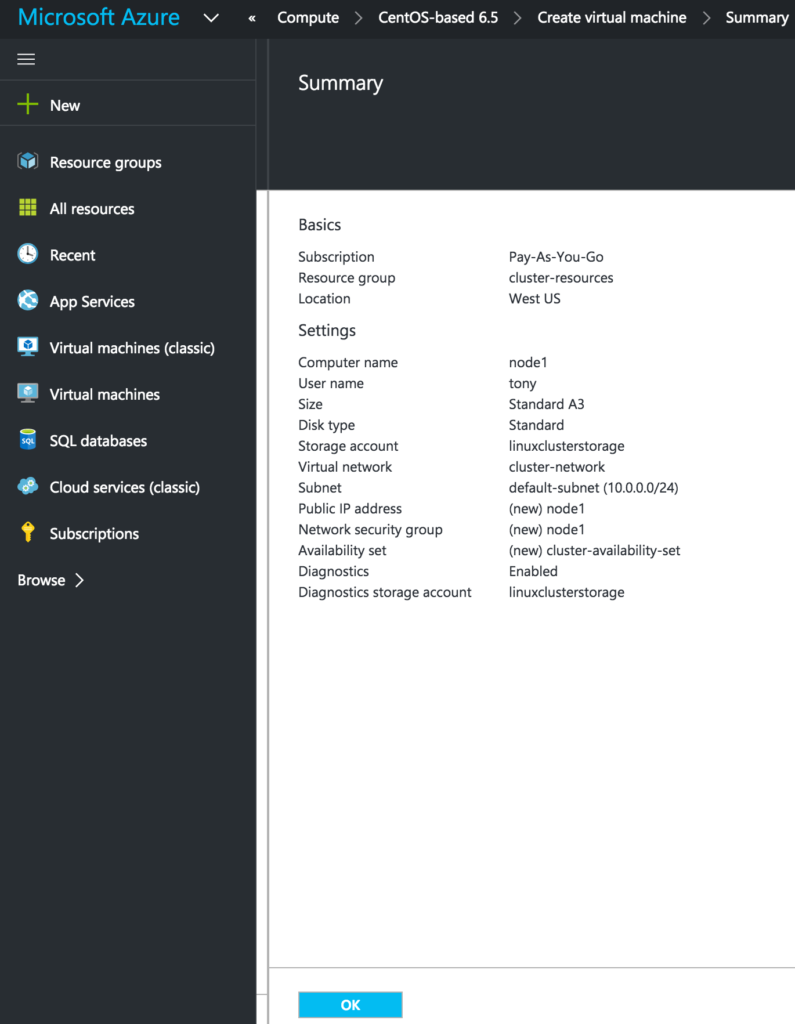
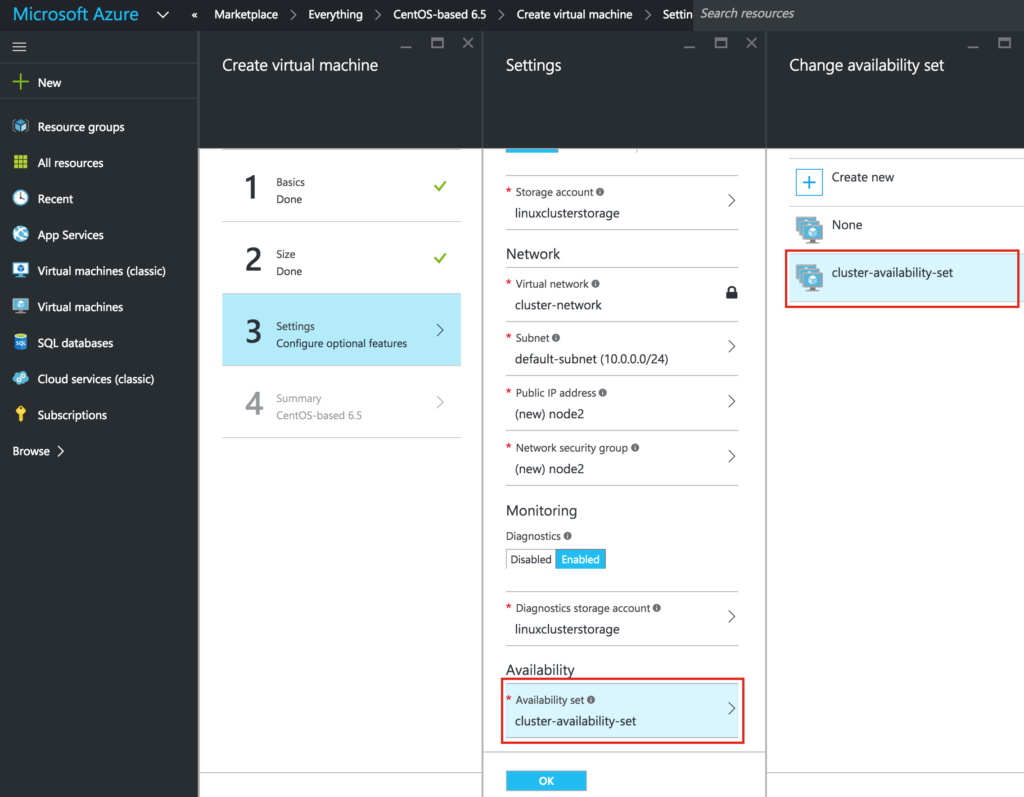
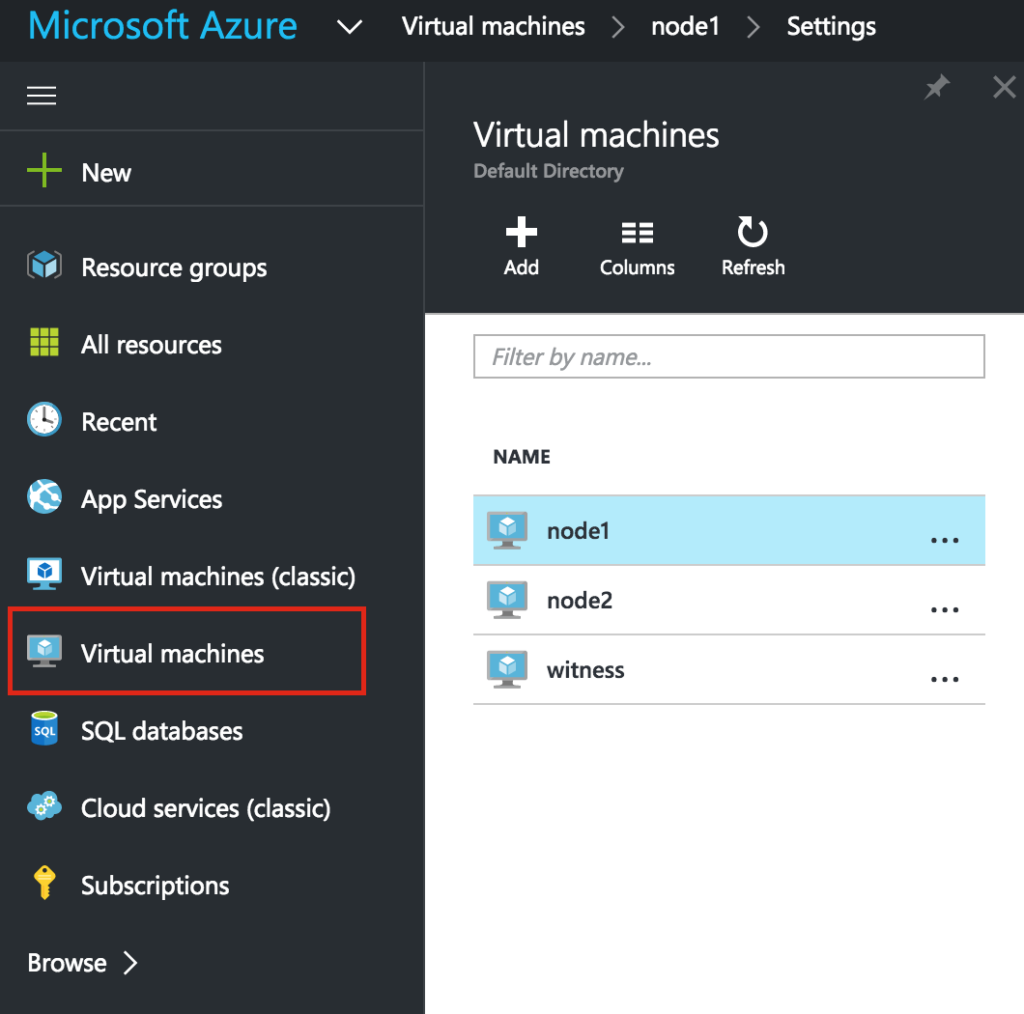
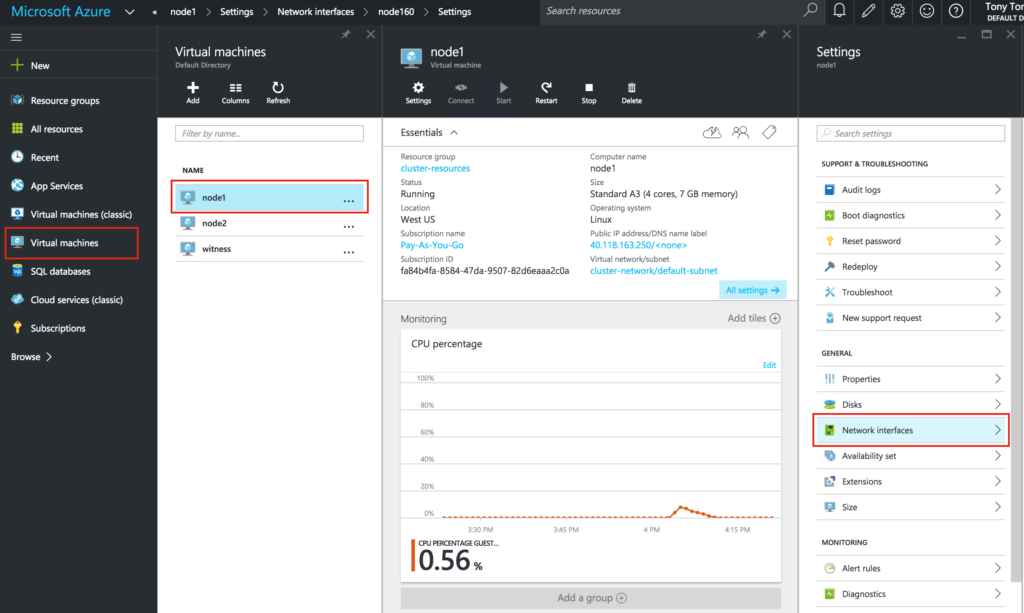
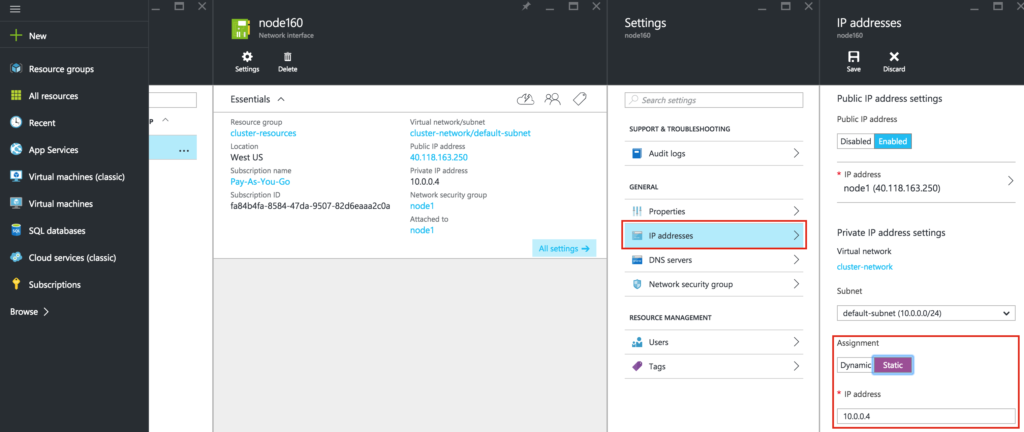
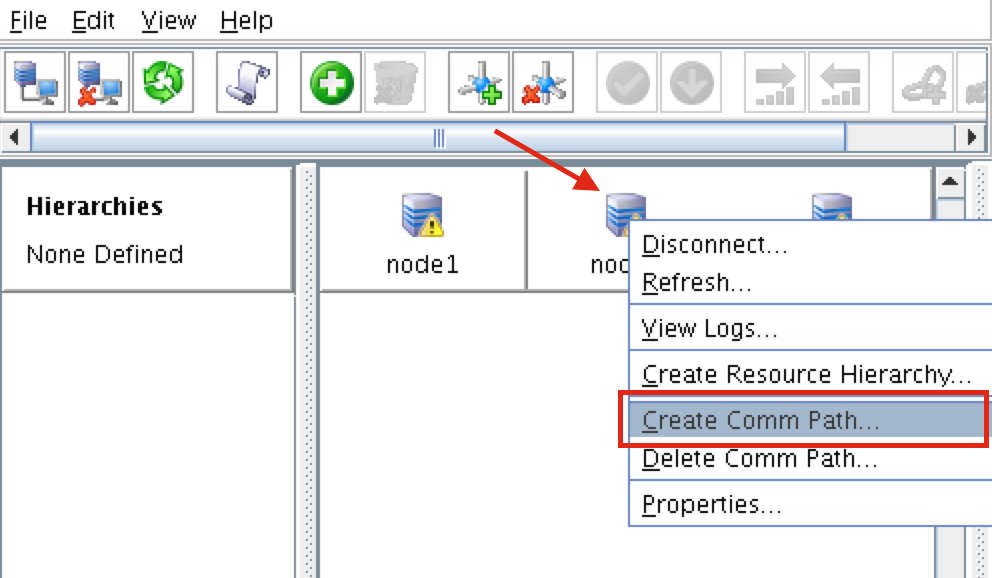
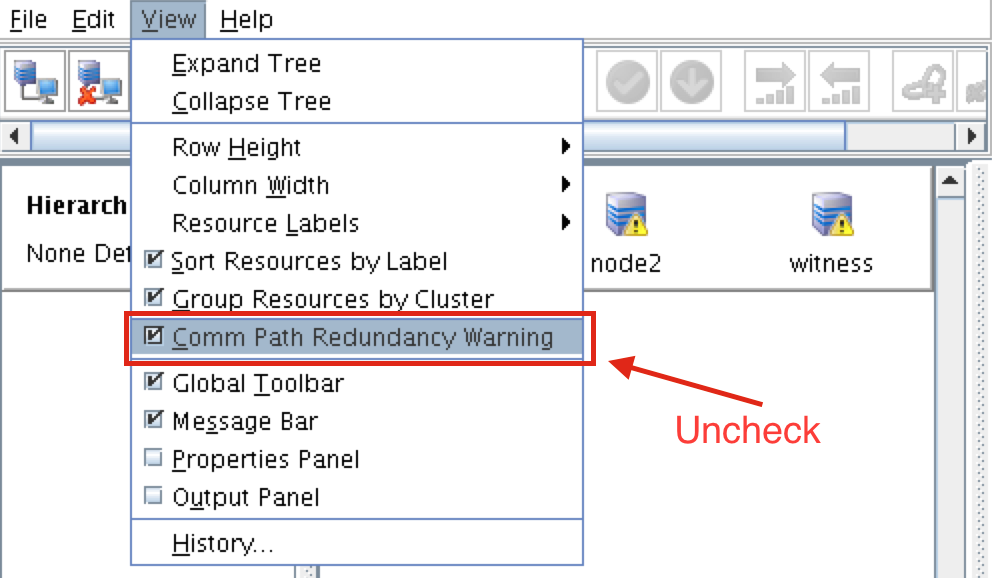
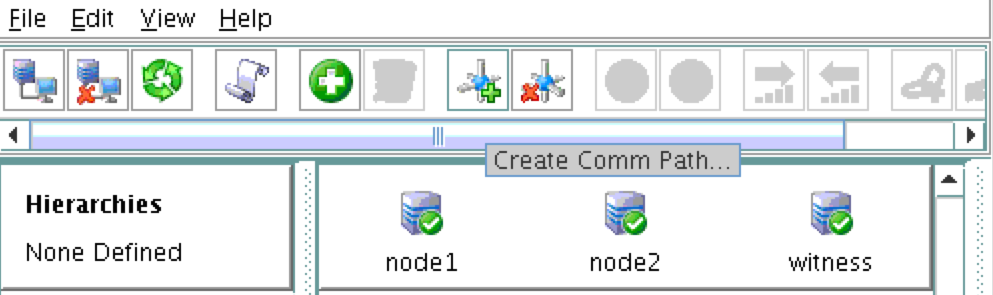
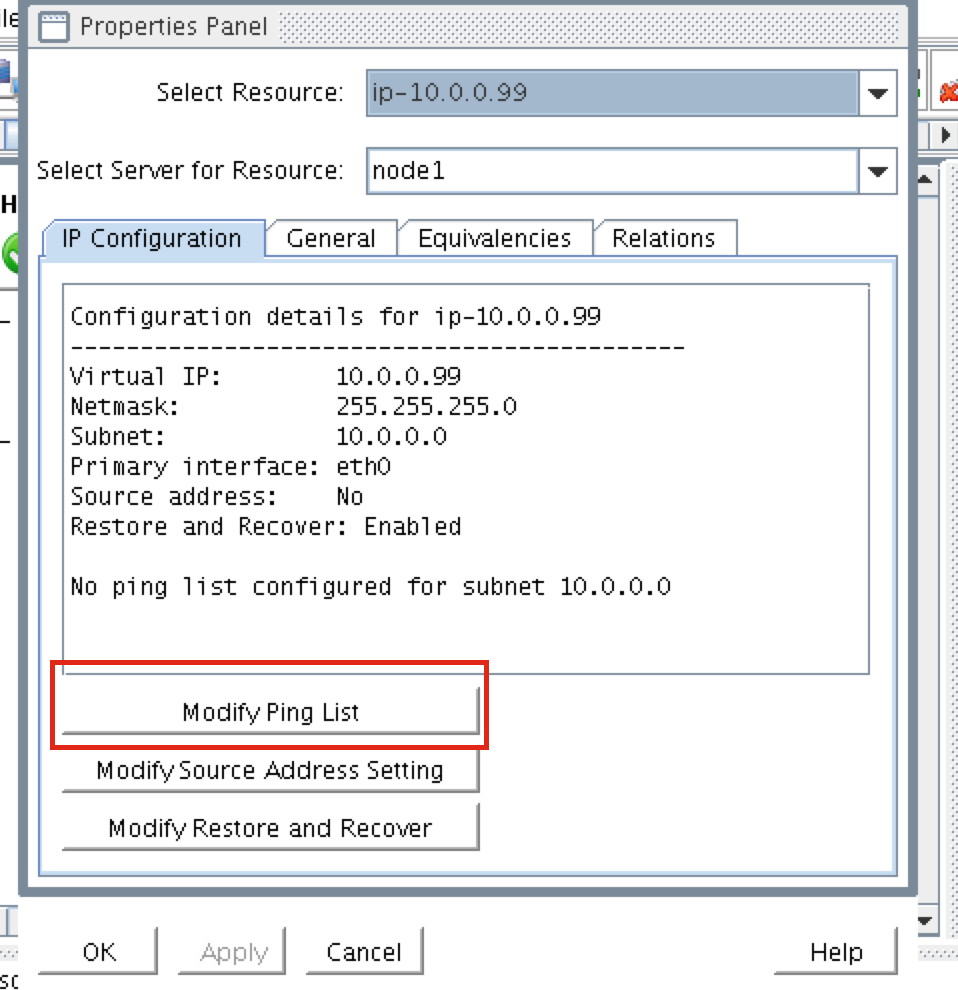
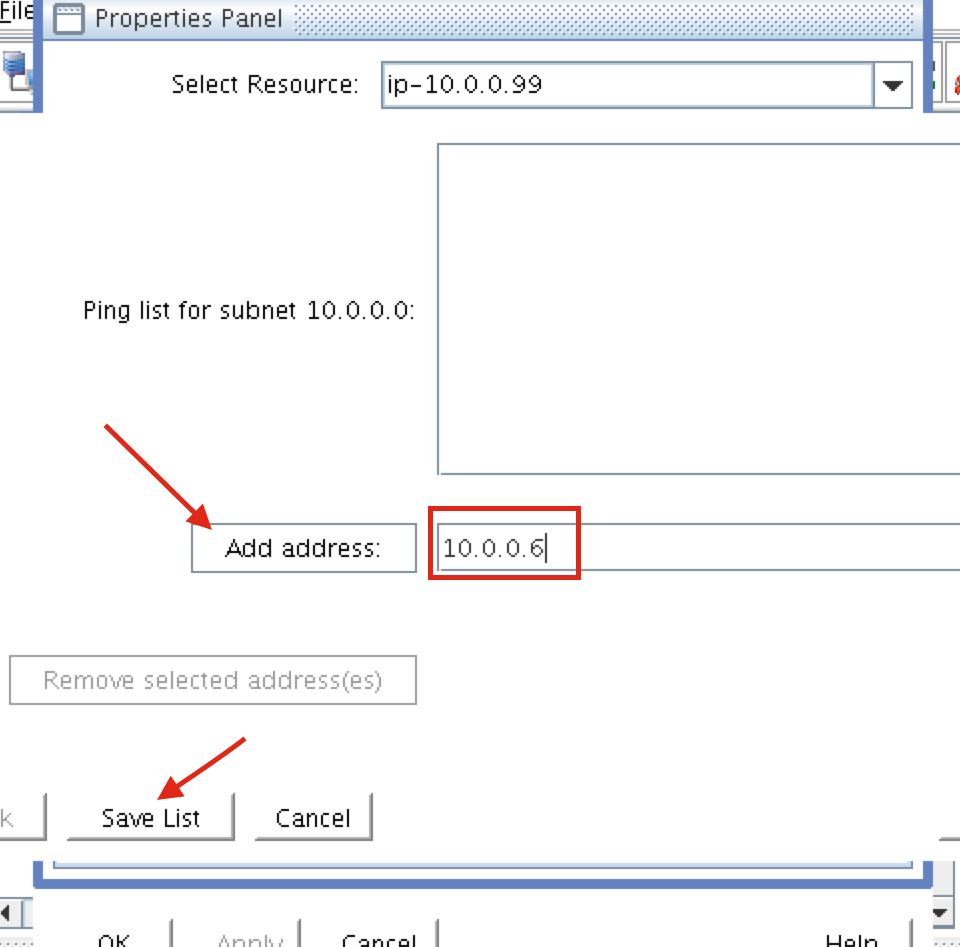
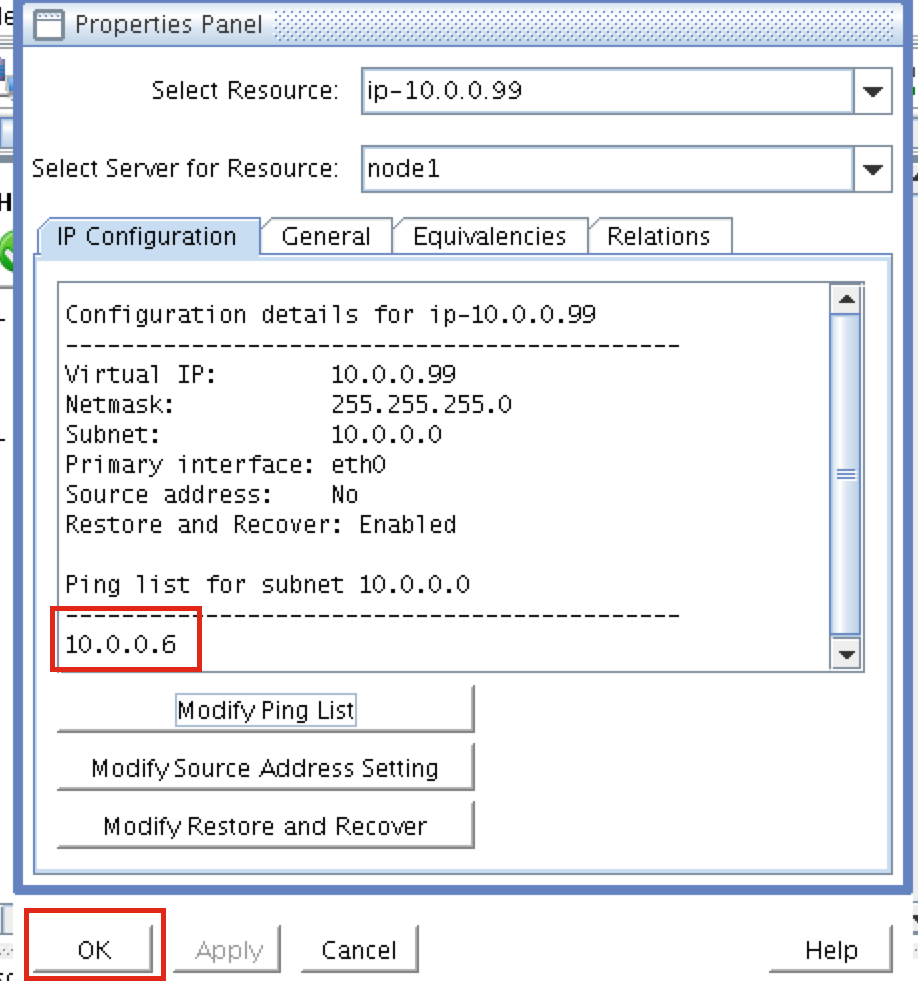
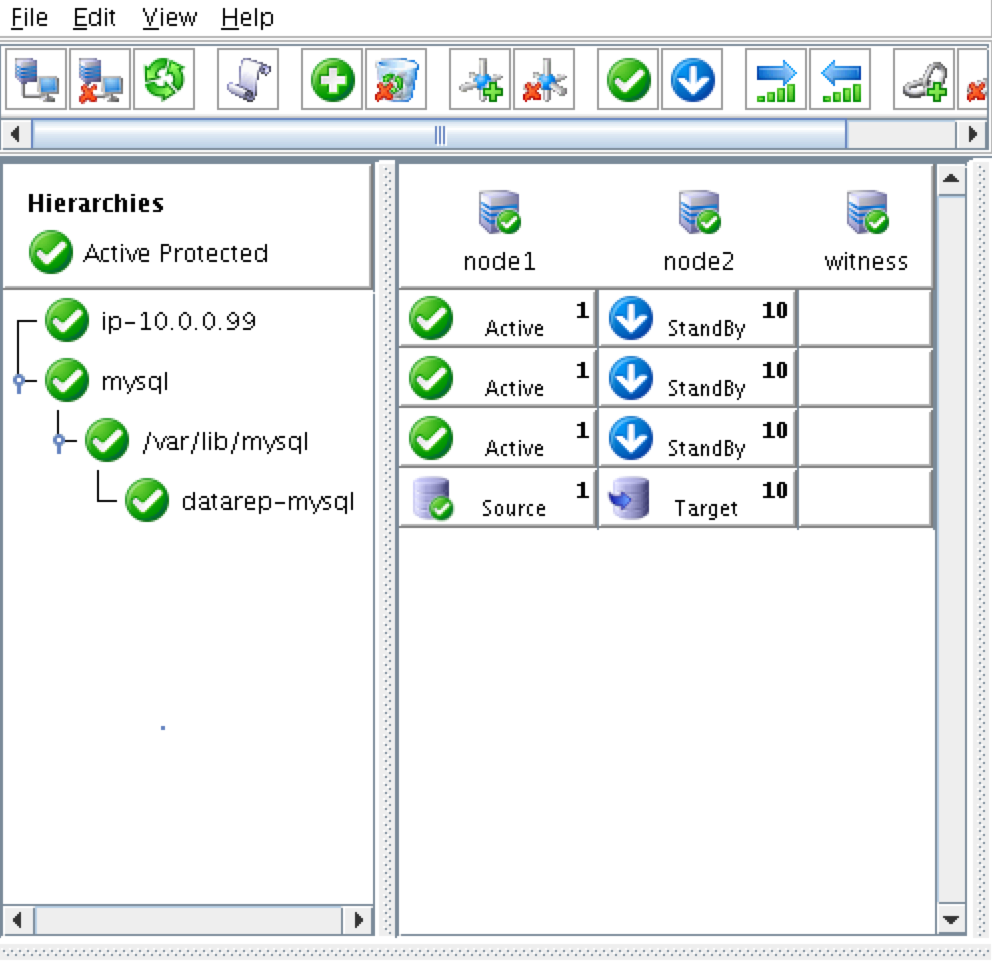
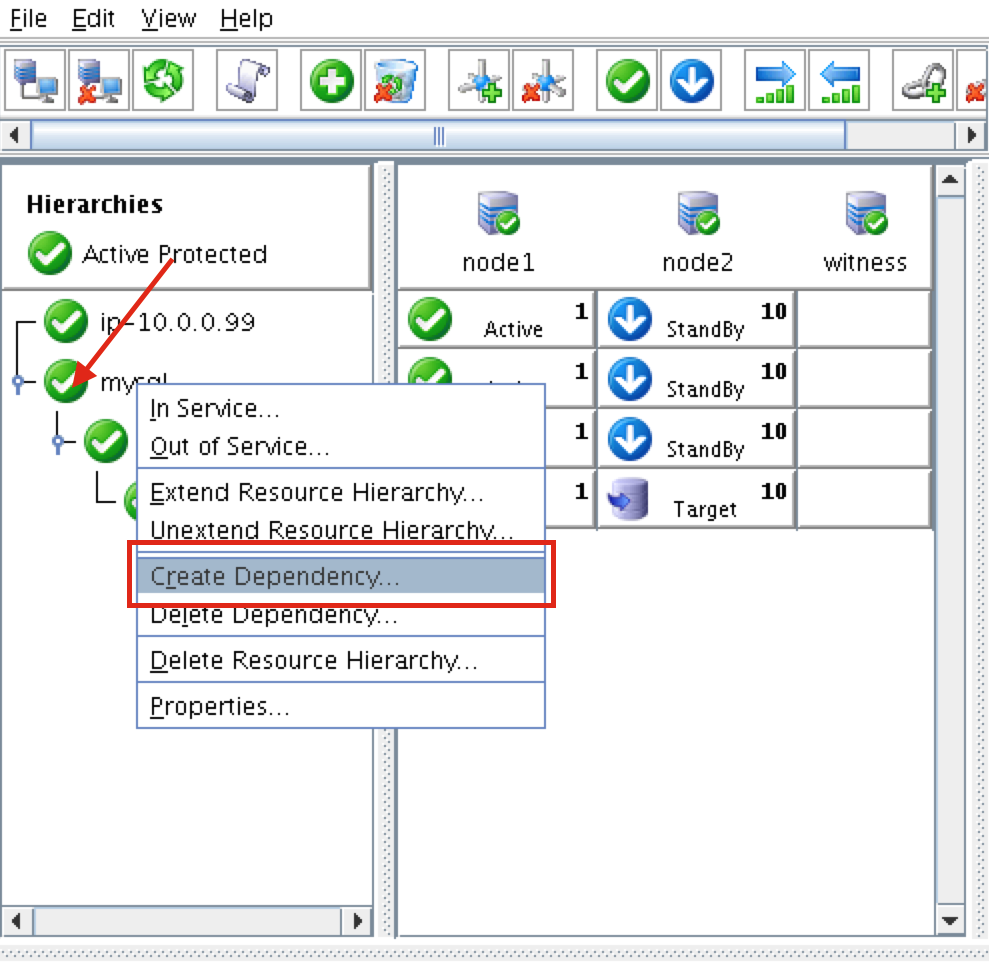
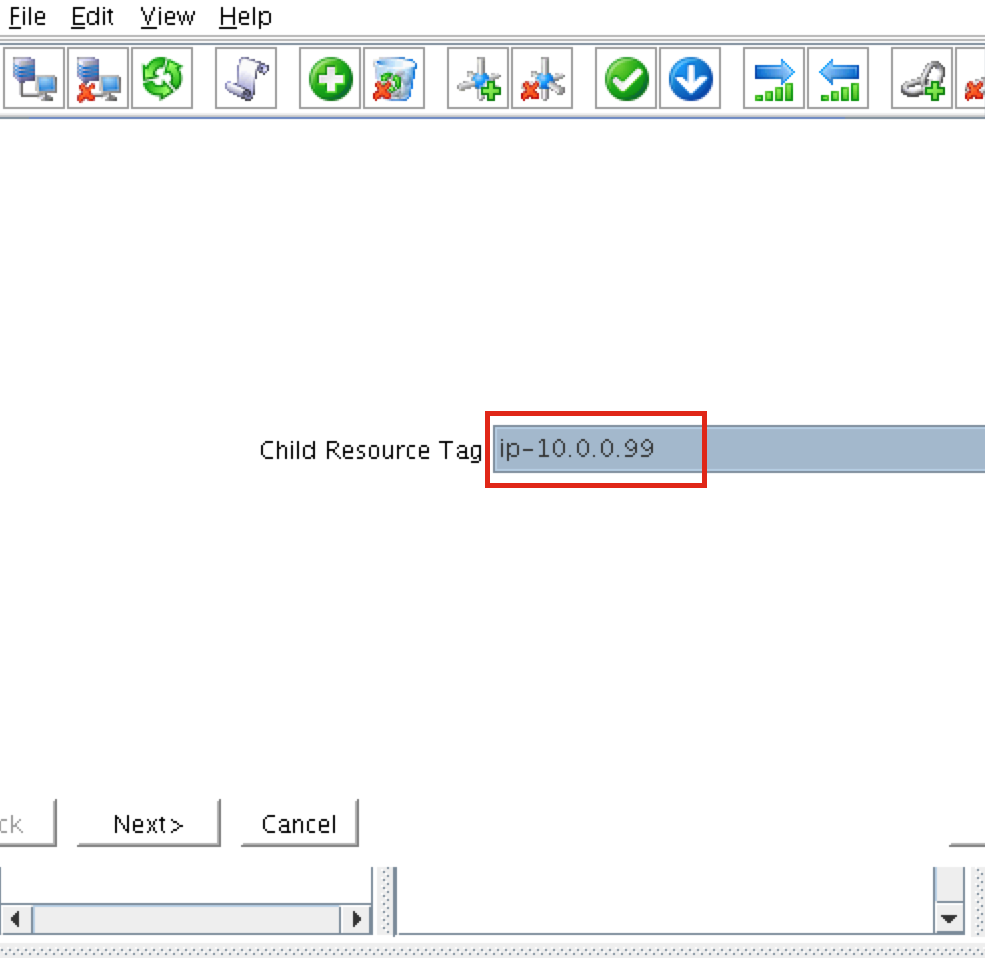
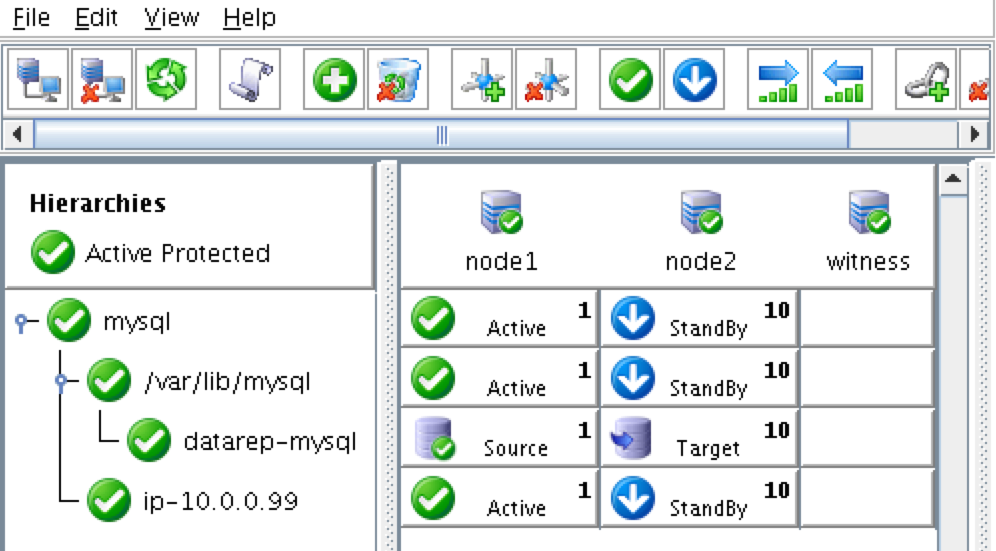
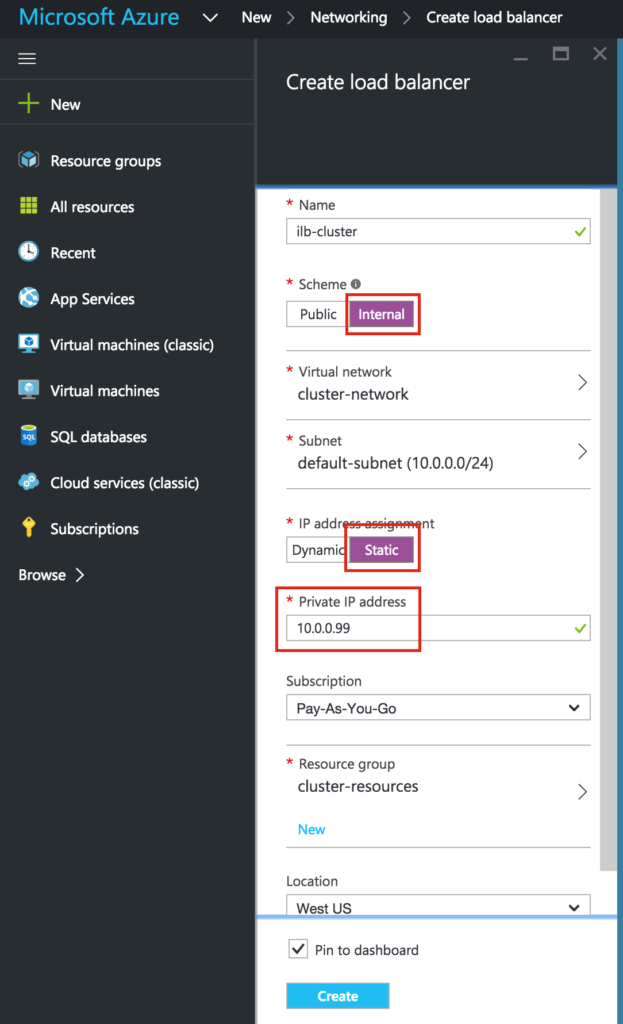
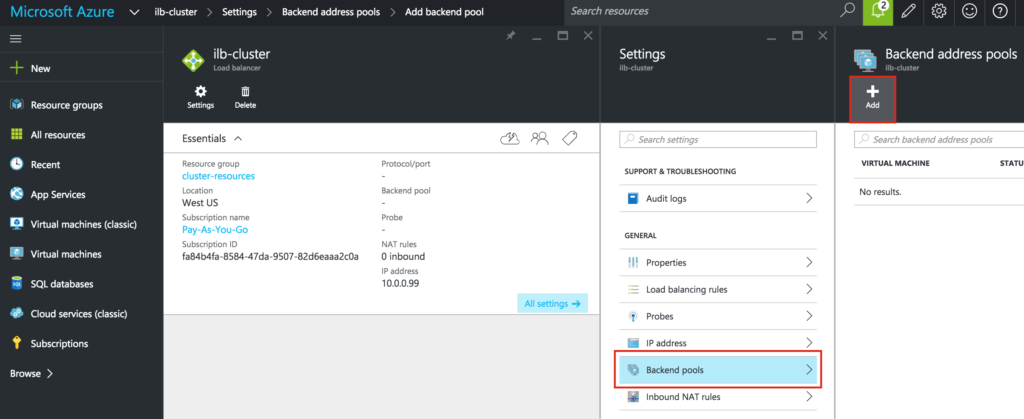
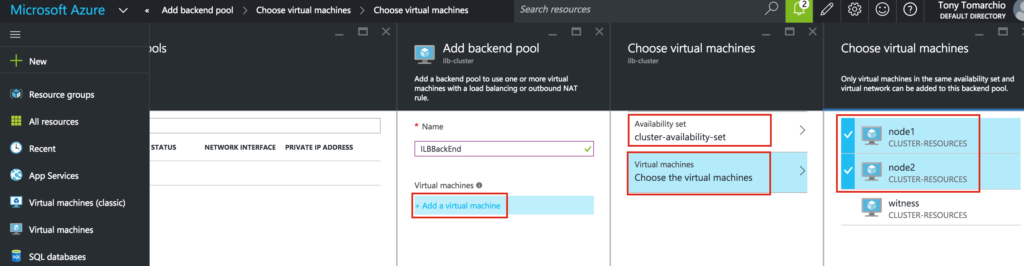
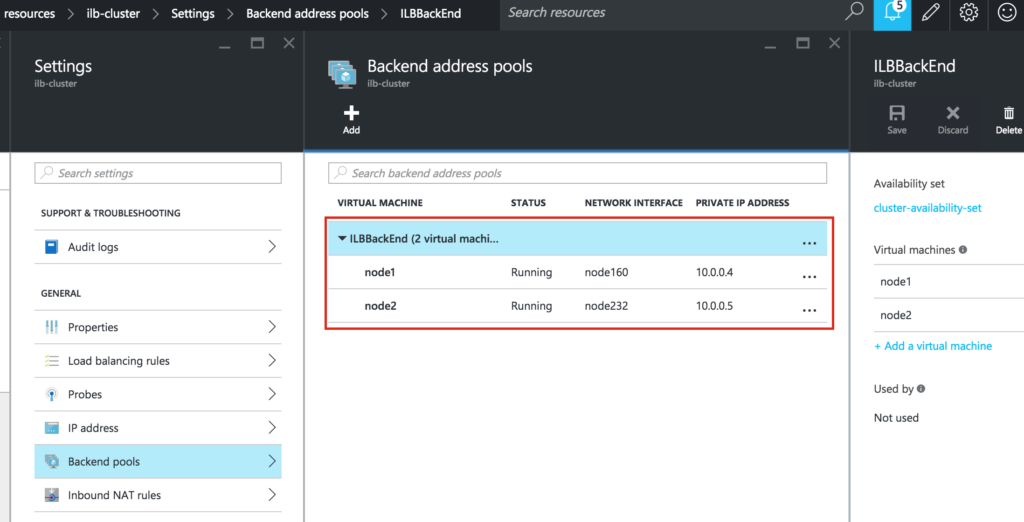
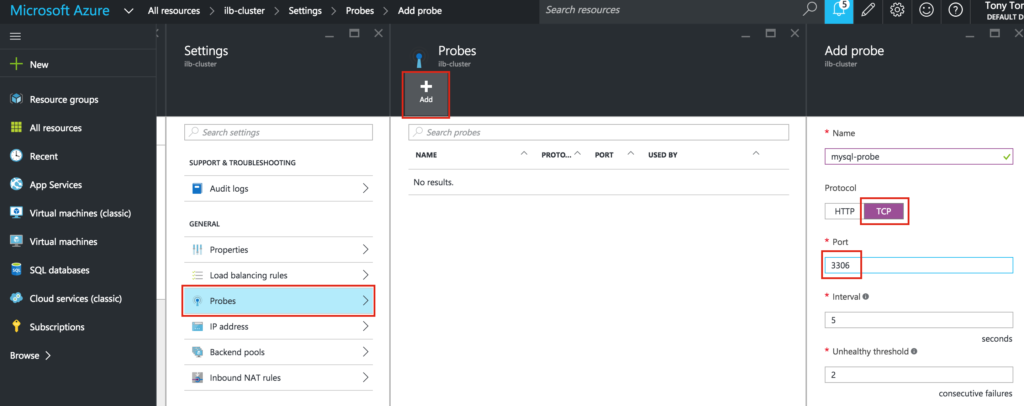
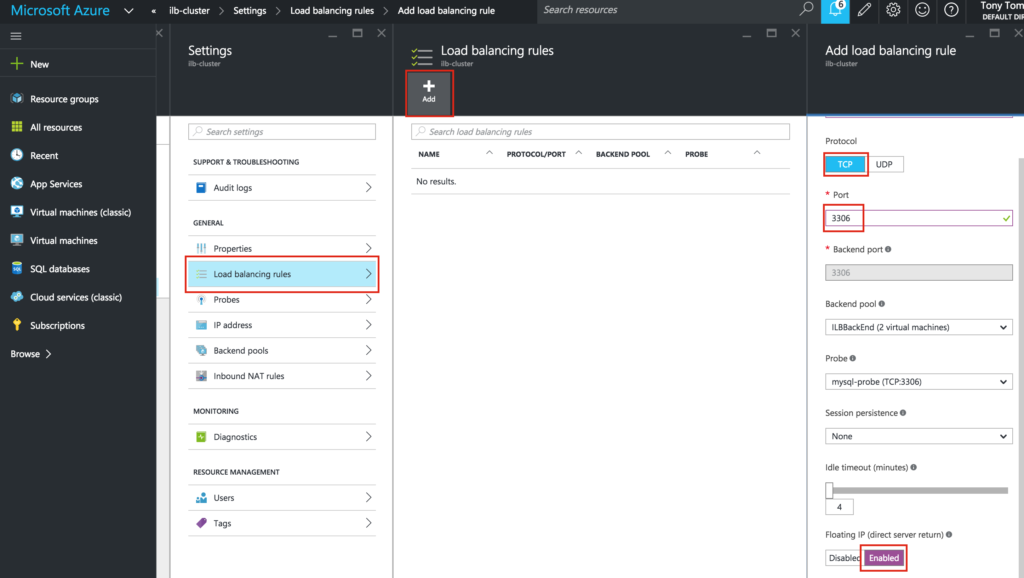
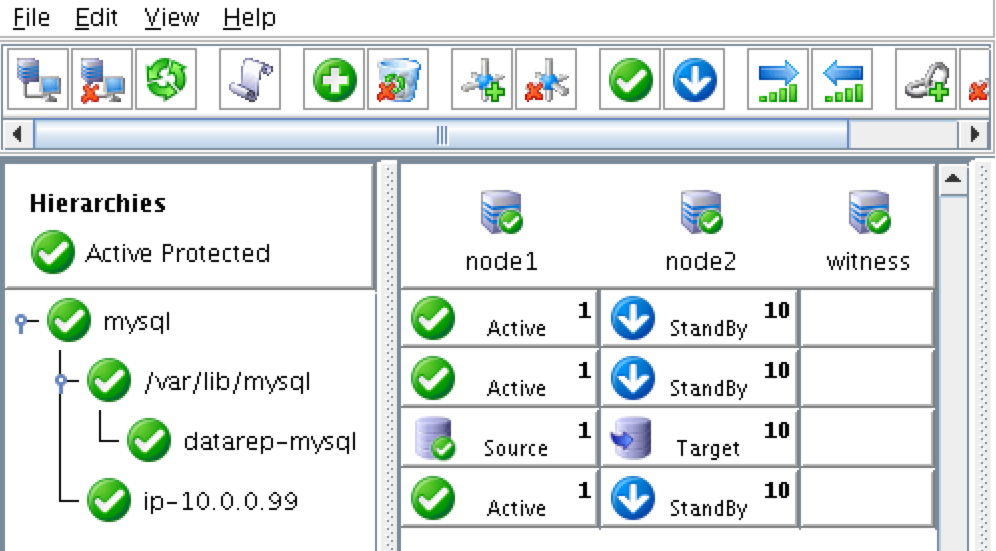
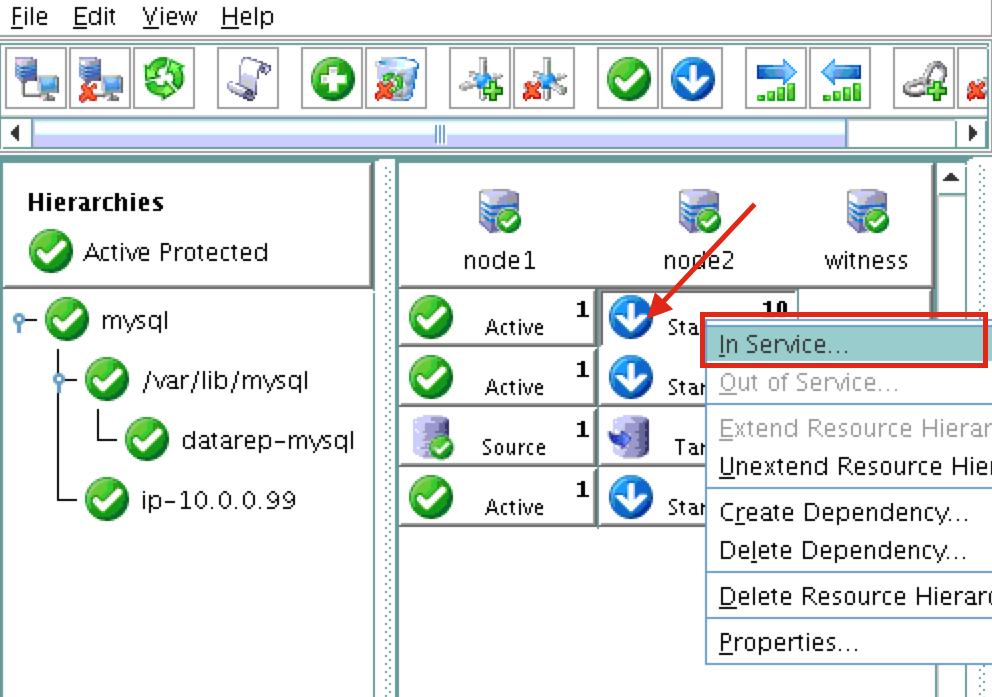

{kind=link}