| March 18, 2024 |
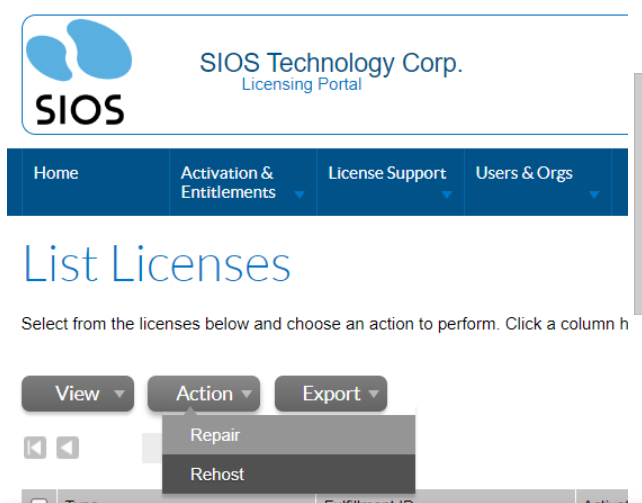
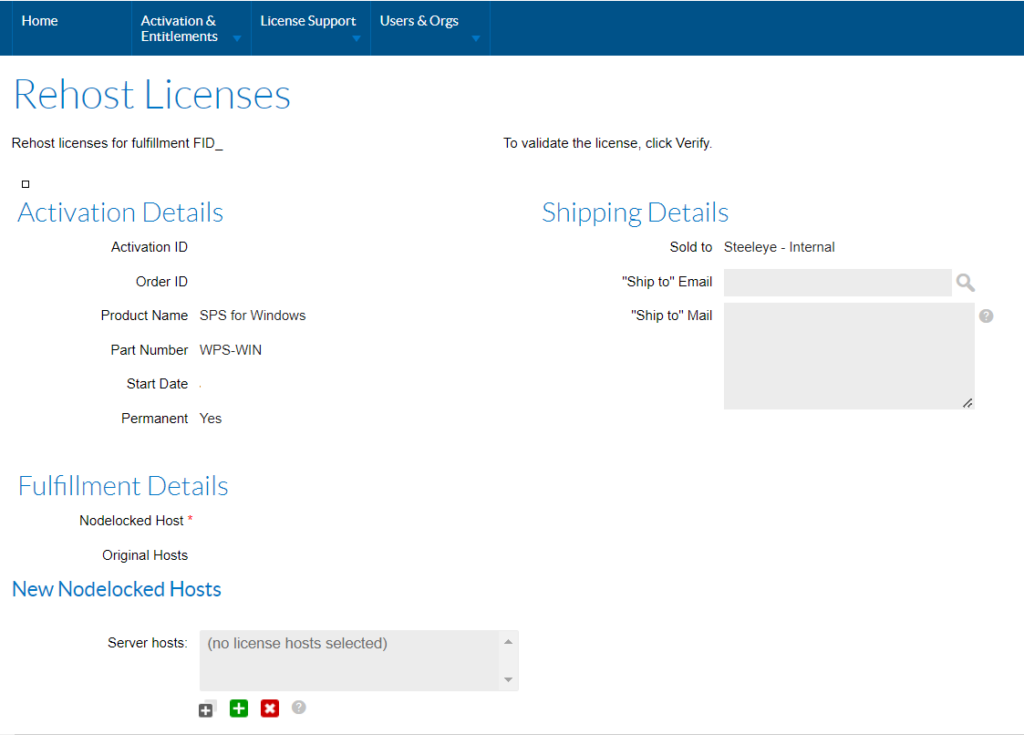
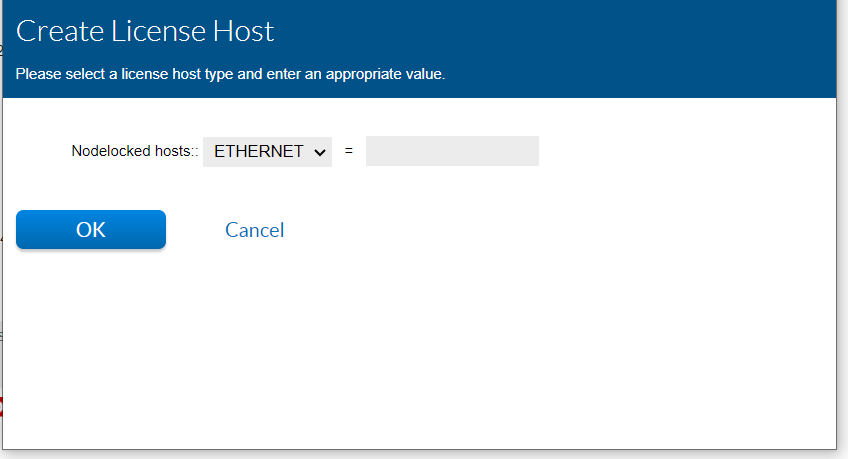
What is a License Rehost? |
| March 8, 2024 |
Ensuring HA for Building Management Systems |
| February 17, 2024 |
Video: Minimize downtime for your edge computing with SIOS Technology Video: Minimize downtime for your edge computing with SIOS TechnologySIOS Technology specializes in providing high availability (HA) and disaster recovery (DR) solutions that are often deployed to support edge devices or the edge devices themselves. The company also focuses on real-time data replication and automatic failover to ensure no disruption to applications’ performance in the case of a failure. Dave Bermingham, Director of Customer Success at SIOS Technology, says, “The businesses need to invest more in robust HA solutions and strategies to minimize downtime and maintain continuous operations.” In this video, Bermingham talks about the importance of high availability for edge devices and how organizations can leverage SIOS Technology’s solutions to help them. Reproduced with permission from SIOS
|
White Paper: Protecting SAP & SAP S/4HANA in Amazon EC2 with SIOS Protection Suite |
|
| February 13, 2024 |
The Challenges of Using Amazon EBS Multi-Attach for Microsoft Failover Clusters |