Multi-Cloud Disaster Recovery
If this topic sounds confusing, we get it. With our experts’ advice, we hope to temper your apprehensions – while also raising some important considerations for your organisation before or after going multi-cloud. Planning for disaster recovery is a common point of confusion for companies employing cloud computing, especially when it involves multiple cloud providers.
It’s taxing enough to ensure data protection and disaster recovery (DR) when all data is located on-premises. But today many companies have data on-premises as well as with multiple cloud providers, a hybrid strategy that may make good business sense but can create challenges for those tasked with data protection. Before we delve into the details, let’s define the key terms.
What is multi-cloud?
Multi-cloud is the utilization of two or more cloud providers to serve an organization’s IT services and infrastructure. A multi-cloud approach typically consists of a combination of major public cloud providers, namely Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.
Organizations choose the best services from each cloud provider based on costs, technical requirements, geographic availability, and other factors. This may mean that a company uses Google Cloud for development/test, while using AWS for disaster recovery, and Microsoft Azure to process business analytics data.
Multi-cloud differs from hybrid cloud which refers to computing environments that mix on-premises infrastructure, private cloud services, and a public cloud.
Who uses multiple clouds?
- Regulated industries – Many organizations run different business operations in different cloud environments. This may be a deliberate strategy of optimizing their IT environments based on the strengths of individual cloud providers or simply the product of a decentralized IT organization.
- Media and Entertainment – Today’s media and entertainment landscape is increasingly composed of relatively small and specialized studios that meet the swelling content-production needs of the largest players, like Netflix and Hulu. Multi-cloud solutions enable these teams to work together on the same projects, access their preferred production tools from various public clouds, and streamline approvals without the delays associated with moving large media files from one site to another.
- Transportation and Autonomous Driving – Connected car and autonomous driving projects generate immense amounts of data from a variety of sensors. Car manufacturers, public transportation agencies, and rideshare companies are among those motivated to take advantage of multi-cloud innovation, blending both accessibility of data across multiple clouds without the risks of significant egress charges and slow transfers, while maintaining the freedom to leverage the optimal public cloud services for each project.
- Energy Sector – Multi-cloud adoption can help lower the significant costs associated with finding and drilling for resources. Engineers and data scientists can use machine learning (ML) analytics to identify places that merit more resources to prospect for oil, to gauge environmental risks of new projects, and to improve safety.
Multi-cloud disaster recovery pain points:
- Not reading before you sign. Customers may face issues if they fail to read the fine print in their cloud agreements. The cloud provider is responsible for its computer infrastructure, but customers are responsible for protecting their applications and data. There are many reasons for application downtime that are not covered under cloud SLAs. Business critical workloads need high availability and disaster recovery protection software as well.
- Developing a centralized protection policy. A centralized protection policy must be created to cover all data, no matter where it lives. Each cloud provider has its unique way of accessing, creating, moving and storing data, with different storage tiers. It can be cumbersome to create a disaster recovery plan that covers data across different clouds.
- Reporting. This is important for ensuring protection of data in accordance with the service-level agreements that govern it. Given how quickly users can spin up cloud resources, it can be challenging to make sure you’re protecting each resource appropriately and identifying all data that needs to be incorporated into your DR plan.
- Test your DR plan. Customers must fully screen and test their DR strategy. A multi cloud strategy compounds the need for testing. Some providers may charge customers for testing, which reinforces the need to read the fine print of the contract.
- Resource skill sets. Finding an expert in one cloud can be challenging; with multi-cloud you will either need to find expertise in each cloud, or the rare individual with significance in multiple clouds.
Overcoming the multi-cloud DR challenge
Meeting these challenges requires companies to develop a data protection and recovery strategy that covers numerous issues. Try asking yourself the following strategic questions:
- Have you defined the level of criticality for all applications and data? How much money will a few minutes of downtime for critical applications cost your organization in end user productivity, customer satisfaction, and IT labor?
- Will data protection and recovery be handled by IT or application owners and creators in a self-service model?
- Did you plan for data optimization, using a variety of cloud- and premises-based options?
- How do you plan to recover data? Restoring data to cloud-based virtual machines or using a backup image as the source of recovery?
Obtain the right multi-cloud DR solution
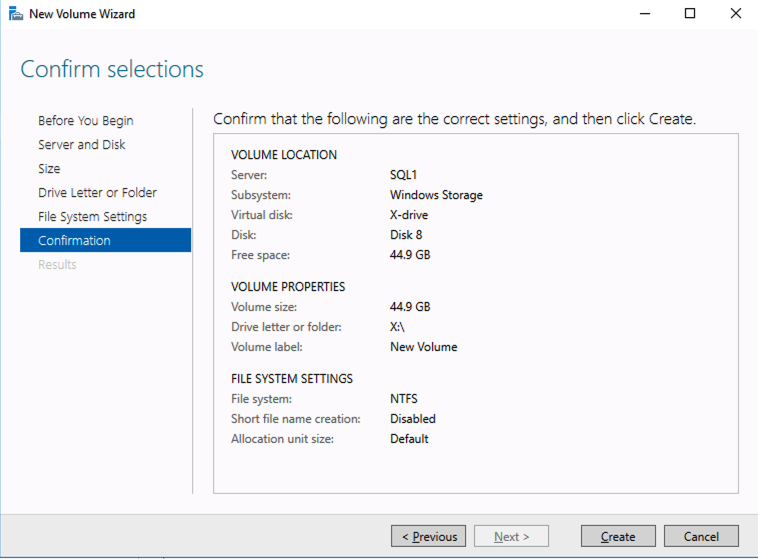
The biggest key to success in data protection and recovery in a multi-cloud scenario is ensuring you have visibility into all of your data, no matter how it’s stored. Tools from companies enable you to define which data and applications should be recovered in a disaster scenario and how to do it – whether from a backup image or by moving data to a newly created VM in the cloud, for example.
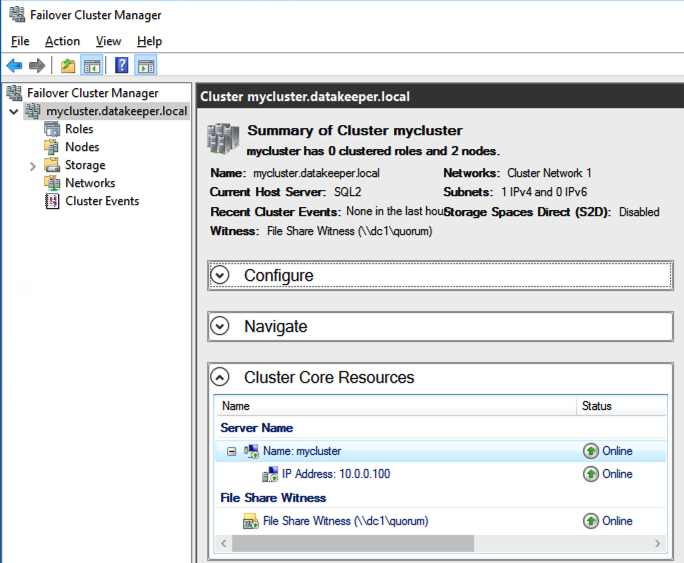
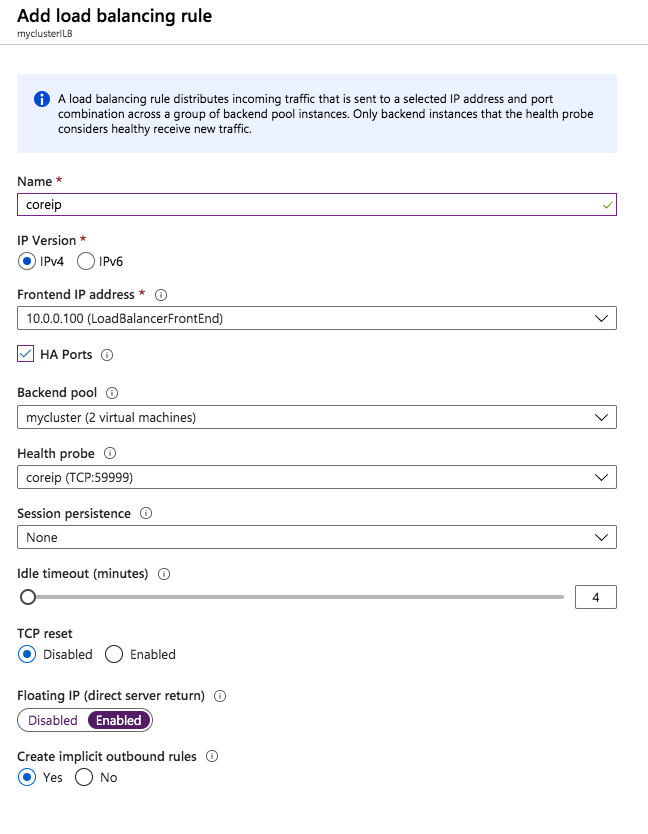
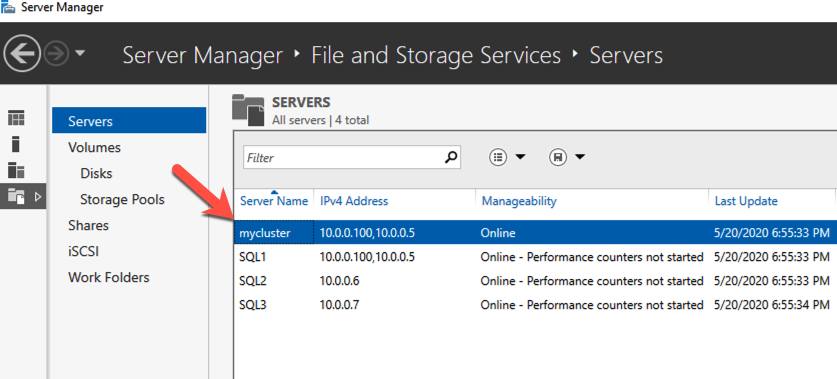
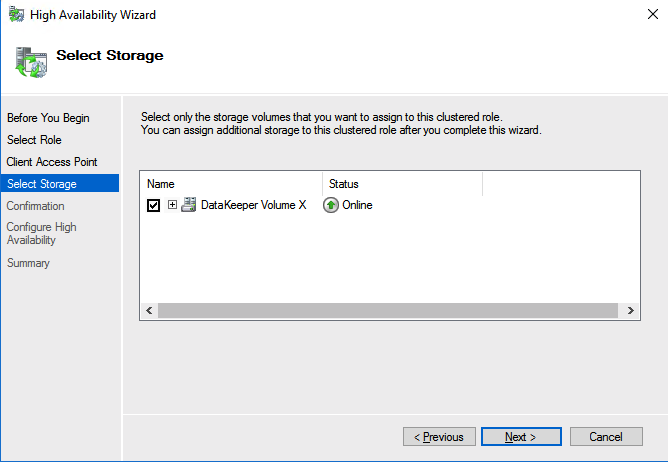
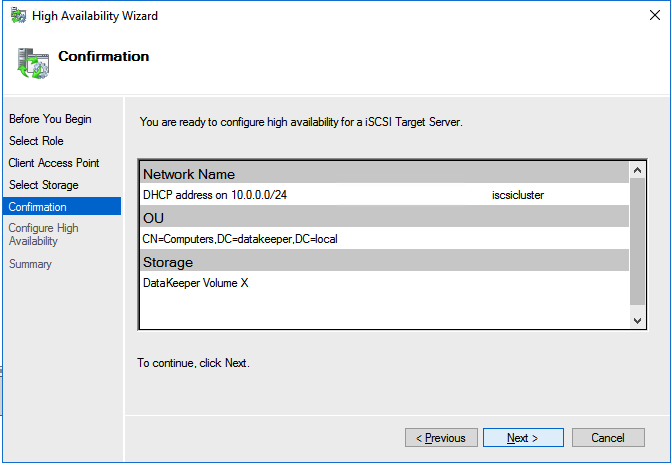
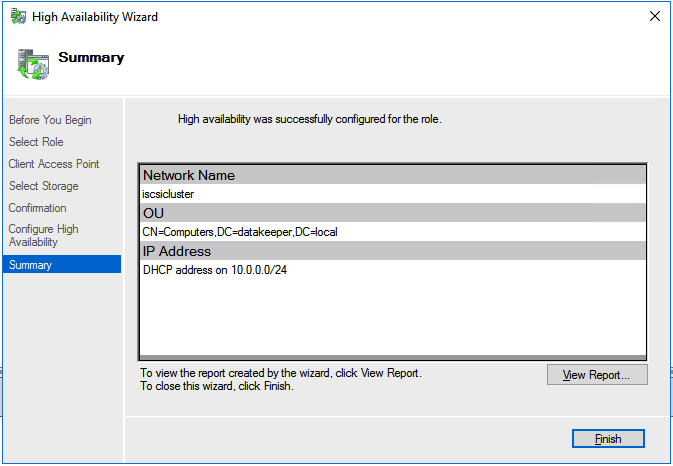
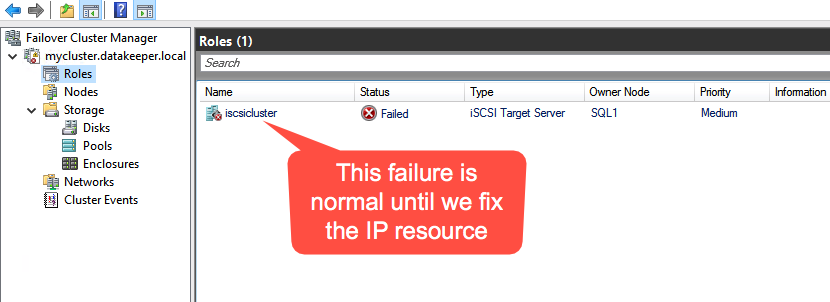
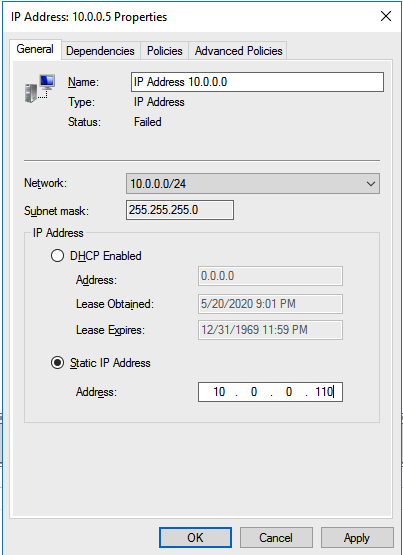
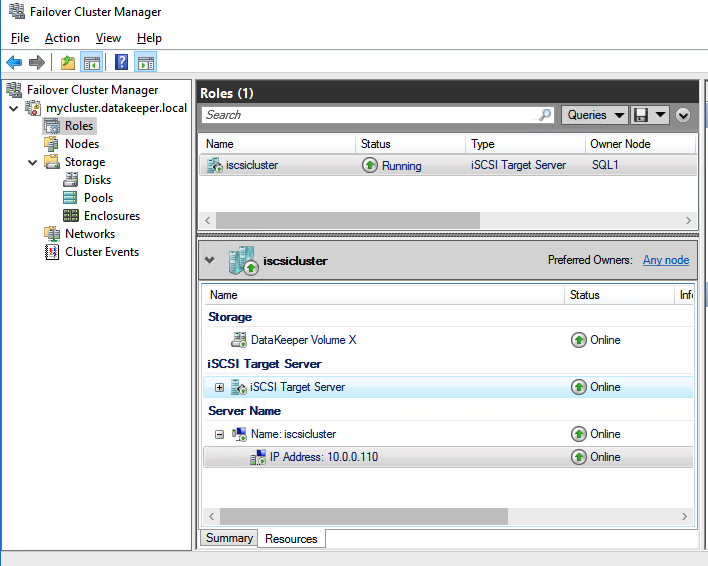
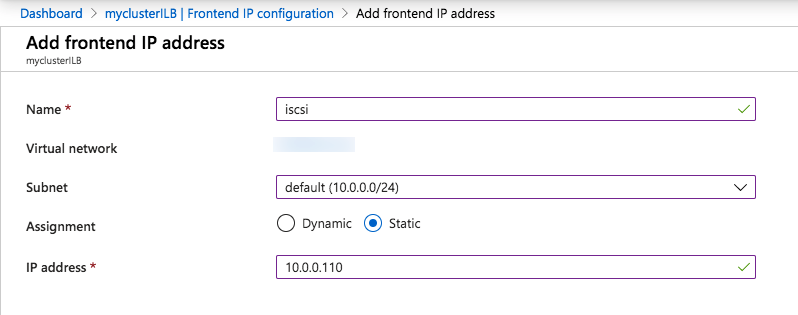
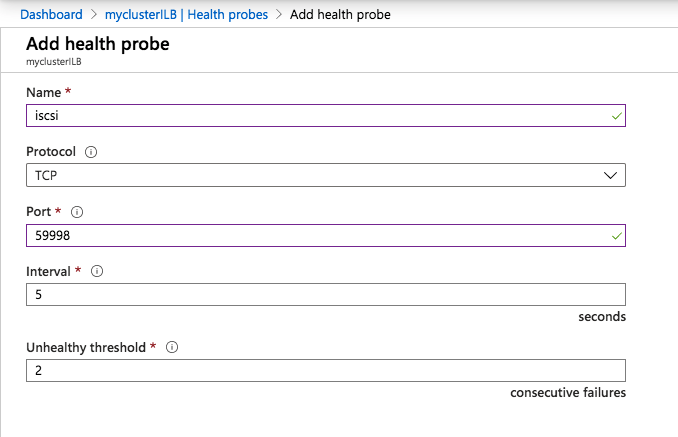
The tool should help you orchestrate the recovery scenario and, importantly, test it. If the tool is well integrated with your data backup tool, it can also allow you to use backups as a source of recovery data, even if the data is stored in different locations – like multiple clouds. Our most recent SIOS webinar discusses this same point; watch it here if you’re interested. SIOS Datakeeper lets you run your business-critical applications in a flexible, scalable cloud environment, such as Amazon Web Services (AWS), Azure, and Google Cloud Platform without sacrificing performance, high availability or disaster protection. SIOS DataKeeper is available in the AWS Marketplace and the only Azure certified high availability software for WSFC offered in the Azure Marketplace.