Webinar: Uninterrupted Transactions: Achieving High Availability for Financial Services on AWS
The financial services industry requires constant uptime and reliability to meet the demands of its customers. Even a few minutes of downtime can result in significant financial loss and reputational damage.
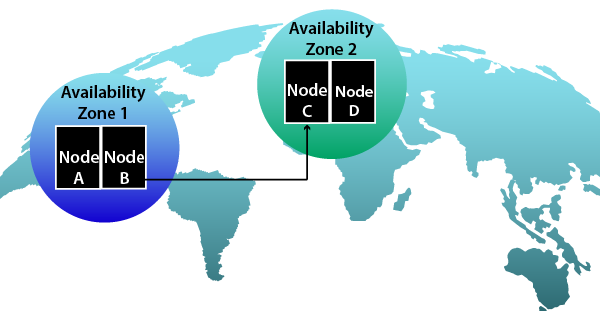
This webinar provides cost-efficient best practices to ensure that transactional, processing, and administrative financial systems in Windows environments remain protected and continue to operate through hardware failures, administrator errors, routine maintenance, and site-wide disasters.
Watch this webinar on-demand to learn about the tools and techniques available on AWS to achieve high availability and gain valuable insights on how to implement a robust and resilient infrastructure that can meet the demanding requirements of the financial services industry.
Reproduced with permission from SIOS