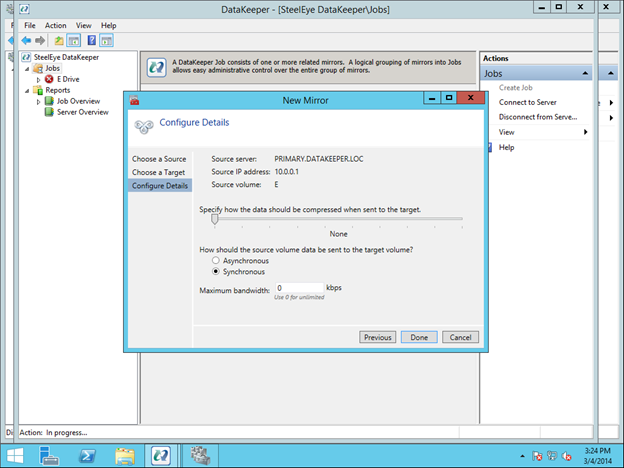
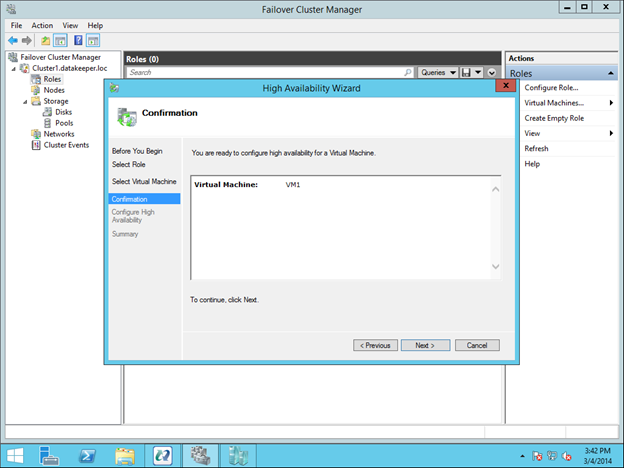
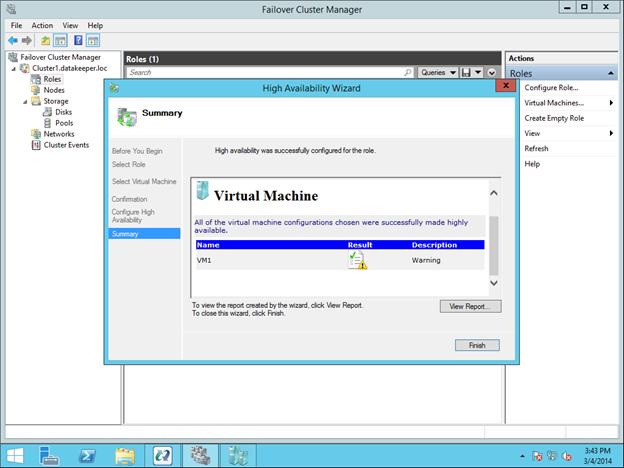
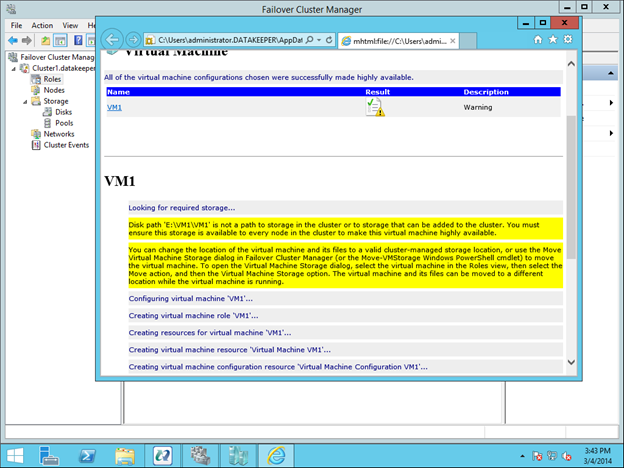
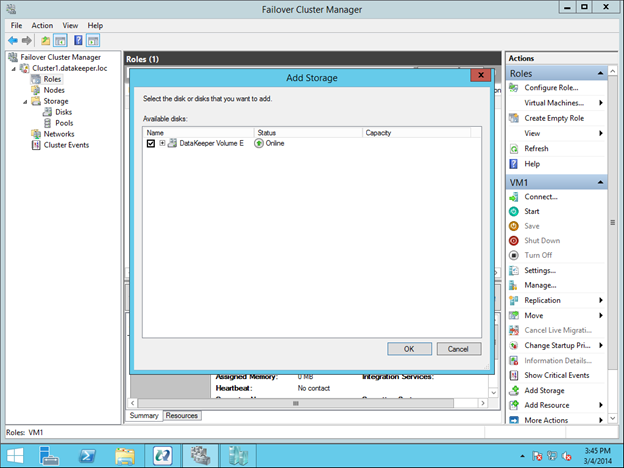
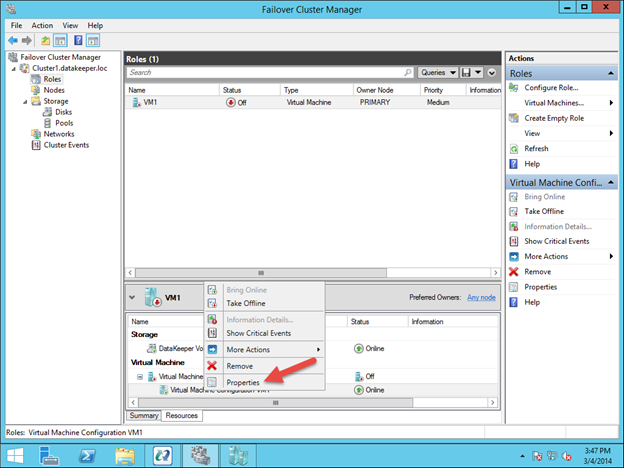
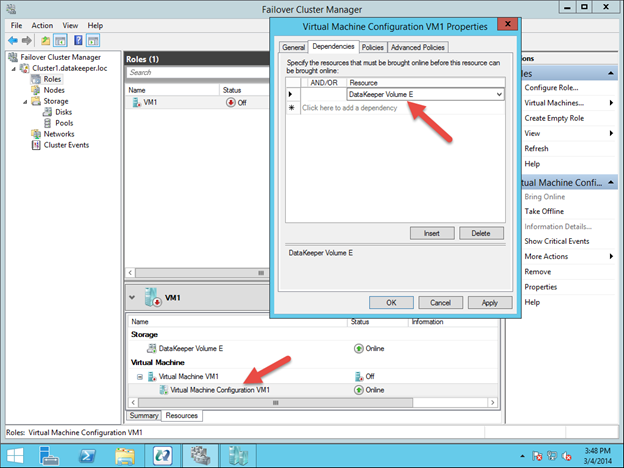
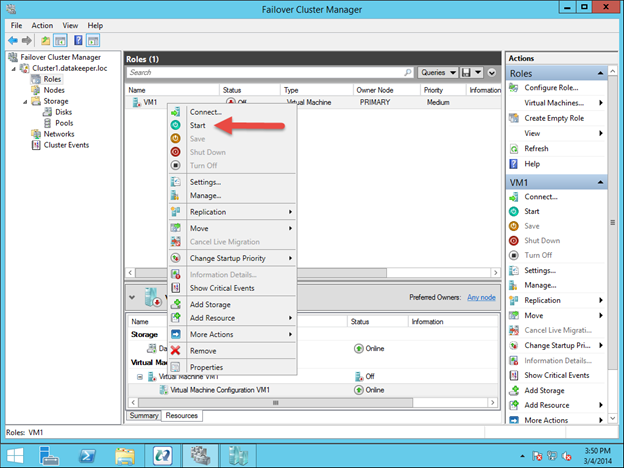
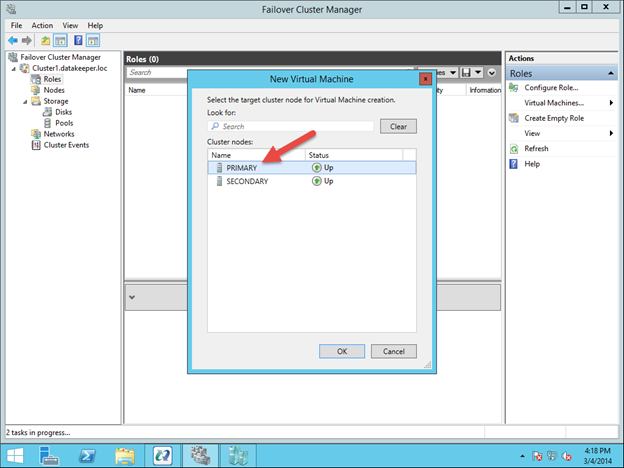
Reserve Your Static IP in Azure
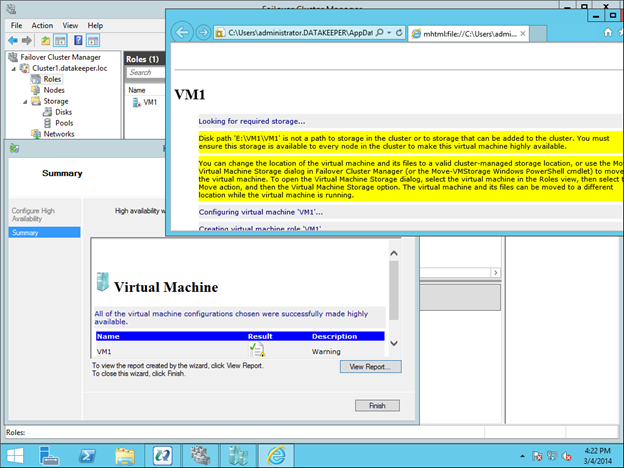
You now can reserve a static public IP for your cloud service in Azure. Usually, your static IP would release when you stopped all VMs in your cloud service. This way, you would be issued a new one the next time you started your VMs. You had to keep at least one VM running in each cloud service all the time, probably for the demos to work properly without a bunch of rework each time.
The Best Bit? It’s Free!
And even better news, the 1st five static IP addresses you reserve are FREE. Now I can turn off all of my VMs and sleep easy at night knowing that my addresses won’t change, breaking my SQL Server Failover Cluster demo. Most of all, I can be sure that I won’t exceed my $200 MSDN Azure credit, which is always a good thing.
http://msdn.microsoft.com/en-us/library/azure/dn690120.aspx
Reproduced with permission from https://clusteringformeremortals.com/2014/06/19/static-ip-in-azure-now-available/