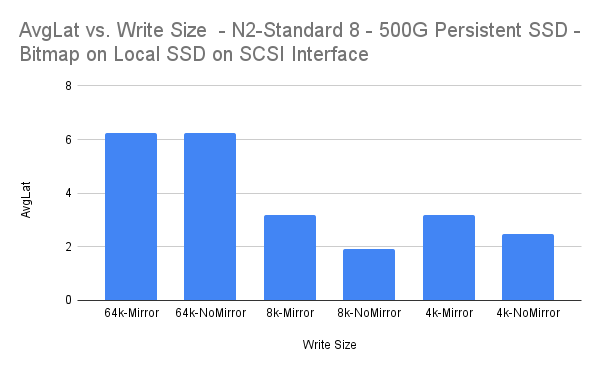
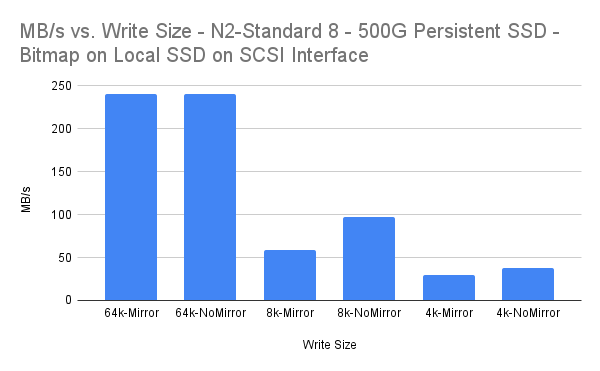
How to Achieve High Availability in the Cloud Using WSFC
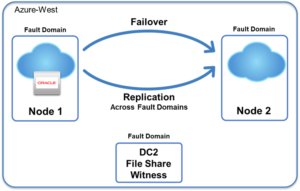
Microsoft Windows Server includes Windows Server Failover Clustering (WSFC) software to ensure the availability of critical applications. In an on-premises environment, primary and standby nodes in the cluster are connected to the same shared storage. However, this infrastructure cannot be taken directly to the cloud. Shared storage that spans both primary and standby systems is essential in WSFC, but shared storage cannot be used with public cloud services such as IaaS (Infrastructure as a Service) in AWS, Azure, or Google Cloud.
Geographically Separated Shared Storage for WSFC is Not Available in the Cloud
When migrating on-premises applications to the cloud, companies prefer to move their entire infrastructure to the cloud, including WSFC, without changing the on-premises operation process. This allows them to minimize disruption by applying the same WSFC skills and know-how in the cloud.
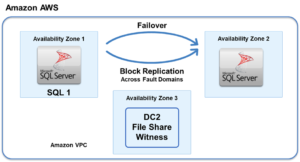
The servers that make up the cluster are divided into the primary node – where the application runs – and standby node(s). WSFC software monitors the application and server node to ensure they are operational. If WSFC detects something wrong with the primary node, it switches operation of the application to the standby node in a process called “failover”.
In a WSFC environment, the primary server and the standby server are connected to shared storage – typically storage called SAN (Storage Area Network) or iSCSI-SAN storage.
To failover operations from the primary server to the standby server, the network link must be switched so the standby server can read from and write to the SAN that normally reads from and writes to the primary server. In this way, it is possible to restart the service in a short time, allowing the standby server to access the same data as the primary node and meet low Recovery Point Objectives (RPOs).
See related content: Disaster Recovery Fundamentals.
However, when migrating WSFC to the cloud, there is no SAN available. For example, you cannot link Amazon Web Services (AWS) and Microsoft Azure to multiple nodes (servers) to use as shared storage. The same applies to IaaS for other cloud services.
It is possible to build an HA cluster configuration based on WSFC without shared storage, but it requires extremely advanced skills, such as creating your own program to recover data on the standby node. The operation is complicated and it is not easy to verify when an incident occurs.
Data Replication Software Solves the Problem
To rectify this problem, you can install data replication software that is specialized for HA clusters – such as SIOS DataKeeper Cluster Edition – and synchronize storage among local servers. Data on the local disks of the primary and standby nodes are synchronized in real-time using host-based, block-level replication. With this method, you do not need shared storage. Instead, you can build an HA cluster configuration using familiar WSFC without disrupting established processes.
With DataKeeper, synchronized nodes appear as a SAN in the WSFC management screen (Failover Cluster Management). If your operations managers have used WSFC, they will require little to no training with this approach.
High Availability in the Cloud Surpasses On-Premises HA with SIOS DataKeeper and WSFC
DataKeeper Cluster Edition is a software add-on that seamlessly integrates with Windows Server Failover Clustering (WSFC) to add performance-optimized host-based synchronous or asynchronous replication. In the unlikely event that the HA cluster malfunctions, WSFC will orchestrate the failover of operations to the standby node(s) and access shared storage as if it is shared storage. This simple mechanism makes it possible to move to AWS without changing the operations of the existing system.
Without compromising familiar WSFC operations, it is possible to guarantee high availability in the cloud using DataKeeper that is equivalent to or better than on-premises high availability. The advantage of this cluster configuration is that it is very simple and can be easily applied to any cloud environment.
Seamless Integration with WSFC
SIOS DataKeeper Cluster Edition seamlessly integrates with and extends Windows Server Failover Clustering (WSFC) by providing a performance-optimized, host-based data replication mechanism. While WSFC manages the software cluster, SIOS performs the data replication to enable disaster protection and ensure zero data loss in cases where shared storage clusters are impossible or impractical, such as in cloud, virtual, and high-performance storage environments.
Reproduced with permission from SIOS

 In a normal cluster environment, the protected application is running on the primary node in the cluster. In the event of an application failure of that primary node, the clustering software moves the application operation to a secondary or remote node, which assumes the role of primary. At any given time, there is only one primary node.
In a normal cluster environment, the protected application is running on the primary node in the cluster. In the event of an application failure of that primary node, the clustering software moves the application operation to a secondary or remote node, which assumes the role of primary. At any given time, there is only one primary node.