Date: พฤศจิกายน 18, 2021
ป้ายกำกับ:SIOS

ข้อมูลเบื้องต้นเกี่ยวกับคลัสเตอร์ – ตอนที่ 1
การจัดกลุ่มในตอนแรกคืออะไร?
เทคโนโลยีการจัดกลุ่มเป็นเทคโนโลยีที่ช่วยให้คุณสามารถเชื่อมต่อเซิร์ฟเวอร์หลายเครื่องเพื่อทำหน้าที่เป็นหน่วยการทำงานเดียว
ประเภทของการจัดกลุ่ม
คุณสามารถ กลุ่ม เซิร์ฟเวอร์เพื่อวัตถุประสงค์หลายประการ ตัวอย่างเช่น คุณสามารถรวมพลังการประมวลผลของเซิร์ฟเวอร์ขนาดเล็กหลายเครื่องเข้าด้วยกันเพื่อประสิทธิภาพสูง คุณยังสามารถกระจายงานการประมวลผลไปยังหลาย ๆ โหนดได้โดยใช้ตัวโหลดบาลานซ์เพื่อเพิ่มประสิทธิภาพ
การทำคลัสเตอร์ความพร้อมใช้งานสูง (HA) เป็นกระบวนการของการรวมโหนดเซิร์ฟเวอร์เพื่อปกป้องแอปพลิเคชันที่สำคัญจากการหยุดทำงานและการสูญหายของข้อมูล
HA คลัสเตอร์
การจัดกลุ่มความพร้อมใช้งานสูง (HA) เป็นกลไกที่ช่วยลดเวลาหยุดทำงานโดยกำจัดจุดความล้มเหลวเพียงจุดเดียว (SPOF) ในคลัสเตอร์ HA แอปพลิเคชันที่สำคัญจะรันบนโหนดหลักที่เชื่อมต่อกับโหนดรองหรือโหนดระยะไกลอย่างน้อยหนึ่งโหนดในคลัสเตอร์ ซอฟต์แวร์คลัสเตอร์จะตรวจสอบความสมบูรณ์ของแอปพลิเคชัน เซิร์ฟเวอร์ และเครือข่าย ในกรณีที่เกิดความล้มเหลวบนโหนดหลัก โหนดหลักจะย้ายการดำเนินการของแอปพลิเคชันไปยังโหนดรองในกระบวนการที่เรียกว่าเฟลโอเวอร์ โดยที่การดำเนินการจะดำเนินต่อไป
ความพร้อมใช้งานสูง
ความพร้อมใช้งานสูงของแอปพลิเคชันคือการวัดระยะเวลาที่แอปพลิเคชันพร้อมใช้งานและใช้งานได้ในปีที่กำหนด โดยทั่วไปแล้ว HA คลัสเตอร์ ให้ความพร้อมใช้งาน 99.99% (สี่เก้า) หรือเวลาหยุดทำงานมากกว่า 52 นาทีเล็กน้อยตลอดทั้งปีที่กำหนด
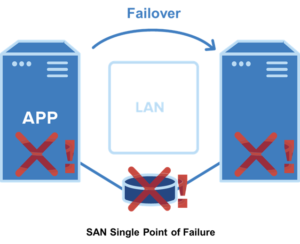
เป็นสิ่งสำคัญที่จะต้องทราบว่าในคลัสเตอร์ HA แบบดั้งเดิม โหนดคลัสเตอร์ทั้งหมดจะเชื่อมต่อกับที่เก็บข้อมูลที่ใช้ร่วมกันเดียวกัน ซึ่งโดยทั่วไปคือ SAN ด้วยวิธีนี้ หลังจากเกิดข้อผิดพลาด โหนดรองจะเข้าถึงข้อมูลเดียวกันกับโหนดหลักและการดำเนินการสามารถดำเนินต่อไปได้
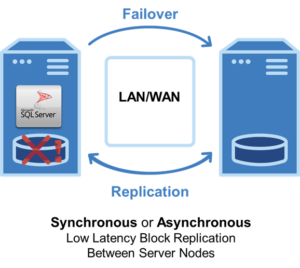
SANless Clusters
อย่างไรก็ตาม หลายบริษัทต้องการใช้คลัสเตอร์ SANless ด้วยเหตุผลหลายประการ ประการแรก พื้นที่เก็บข้อมูลที่ใช้ร่วมกันแสดงถึงจุดล้มเหลวจุดเดียวที่สำคัญ ประการที่สอง พื้นที่จัดเก็บข้อมูลที่ใช้ร่วมกันมักไม่ใช่ตัวเลือกในสภาพแวดล้อมคลาวด์สาธารณะ ประการที่สาม SAN อาจขัดขวางประสิทธิภาพของแอปพลิเคชันฐานข้อมูล เช่น SQL Server, Oracle และ SAP
แทนที่จะใช้พื้นที่เก็บข้อมูลที่ใช้ร่วมกัน บริษัทเหล่านี้ใช้การจำลองแบบระดับบล็อกที่มีประสิทธิภาพ อิงโฮสต์ เพื่อซิงโครไนซ์ที่เก็บข้อมูลในเครื่องบนโหนดคลัสเตอร์ทั้งหมด ในกรณีเกิดเฟลโอเวอร์ โหนดรองจะเชื่อมต่อกับที่จัดเก็บในตัวเครื่องโดยมีสำเนาที่เหมือนกันของที่เก็บข้อมูลหลัก ซึ่งไม่เพียงแต่ช่วยขจัดความเสี่ยง SAN SPOF เท่านั้น แต่ยังช่วยให้เพิ่มดิสก์ด่วน (SSD) ลงในที่จัดเก็บข้อมูลภายในองค์กรเพื่อประสิทธิภาพสูงที่คุ้มค่า การทำคลัสเตอร์ SANless ยังช่วยให้บริษัทต่างๆ สามารถโยกย้ายสภาพแวดล้อม HA ในสถานที่ไปยังคลาวด์ได้โดยใช้ความพยายามเพียงเล็กน้อยหรือการหยุดชะงักของกระบวนการทางธุรกิจที่กำลังดำเนินอยู่
สืบพันธุ์จาก SIOS