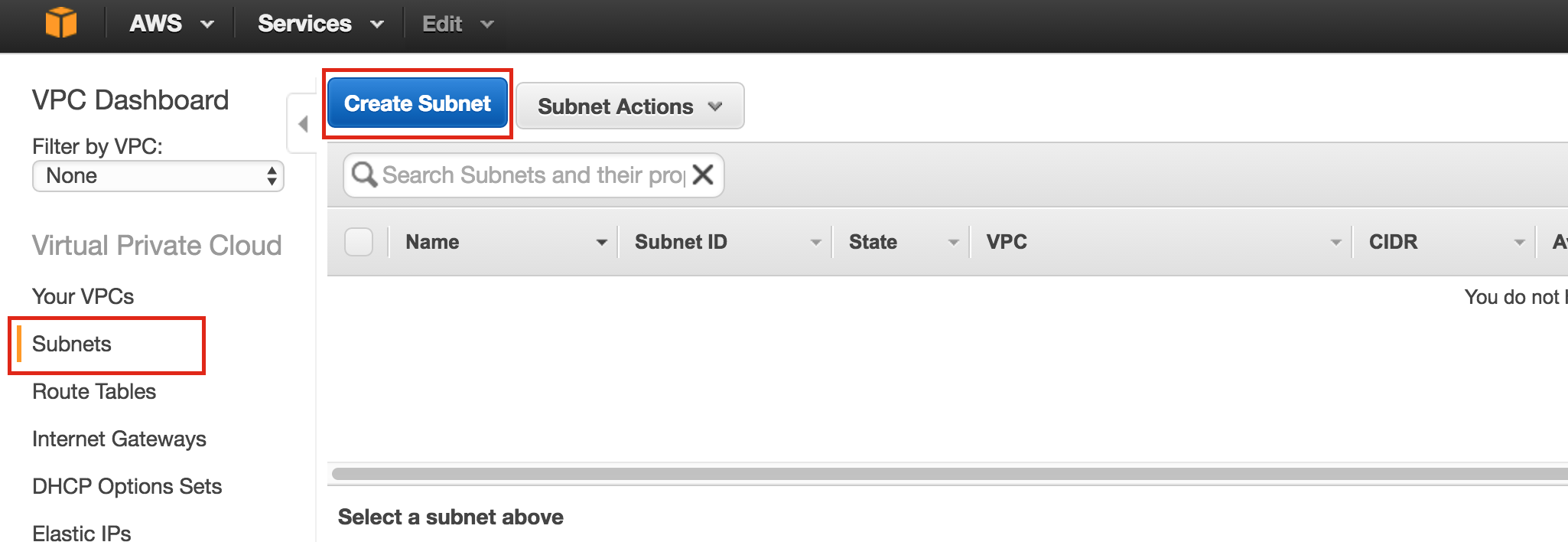
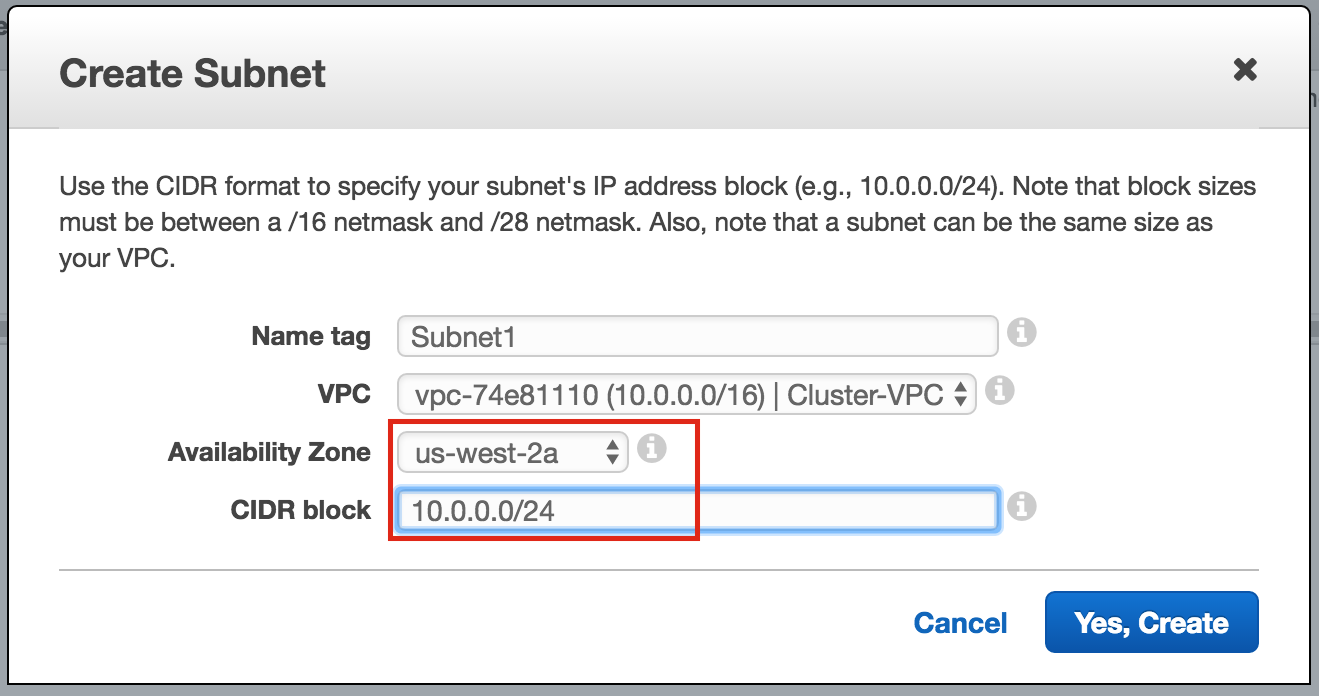
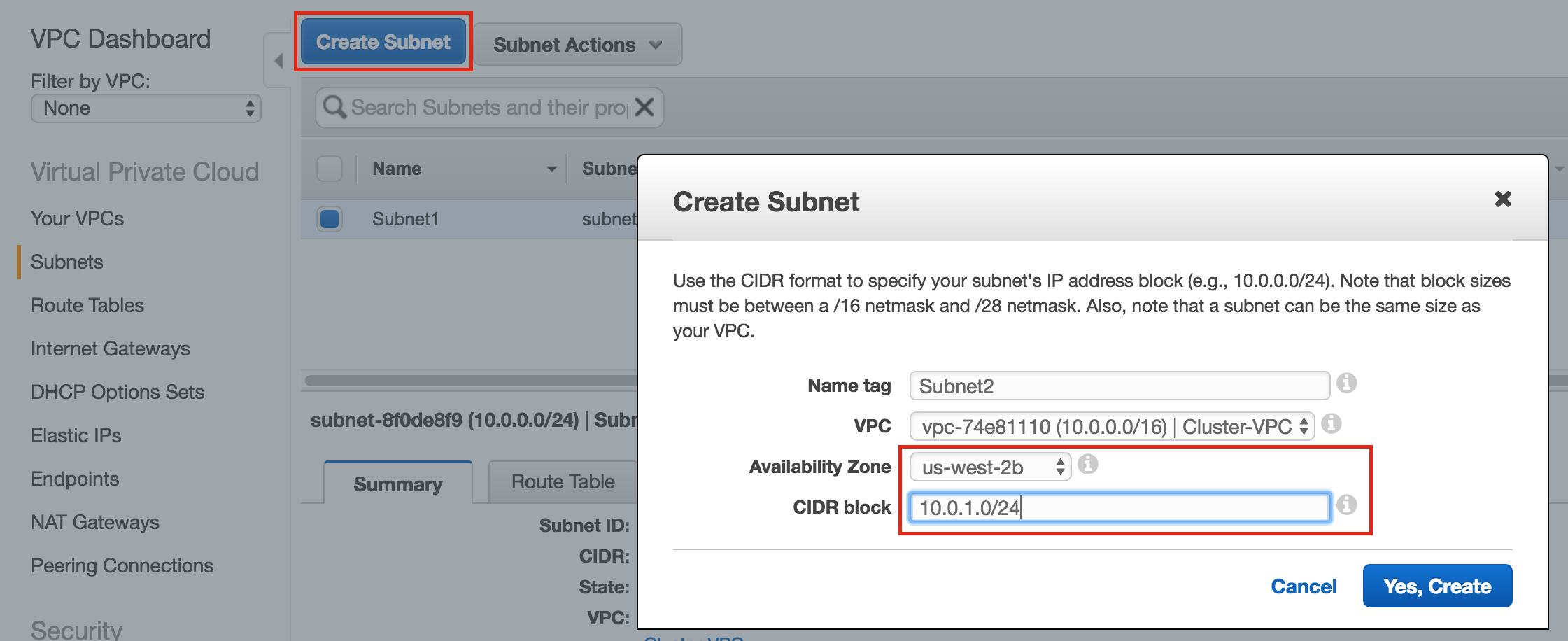
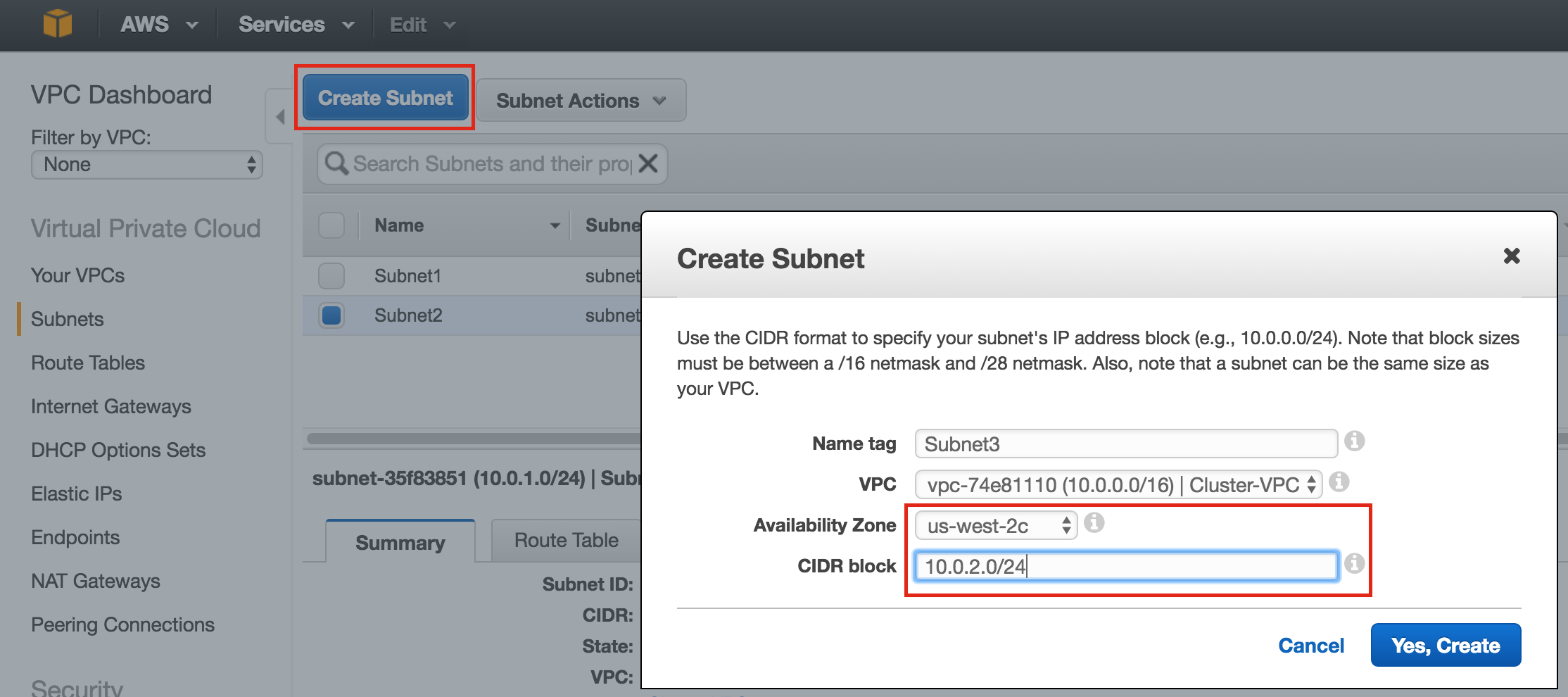
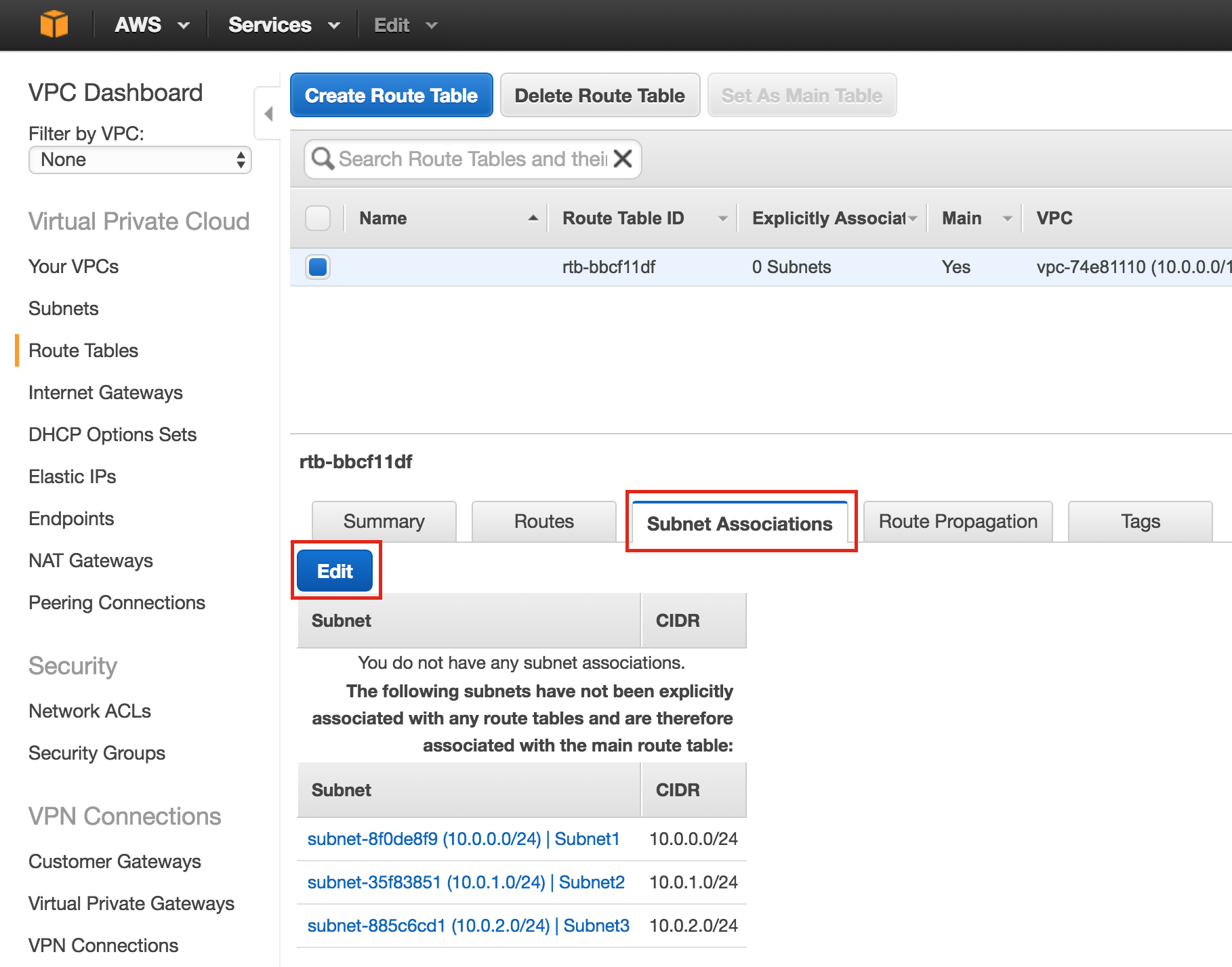
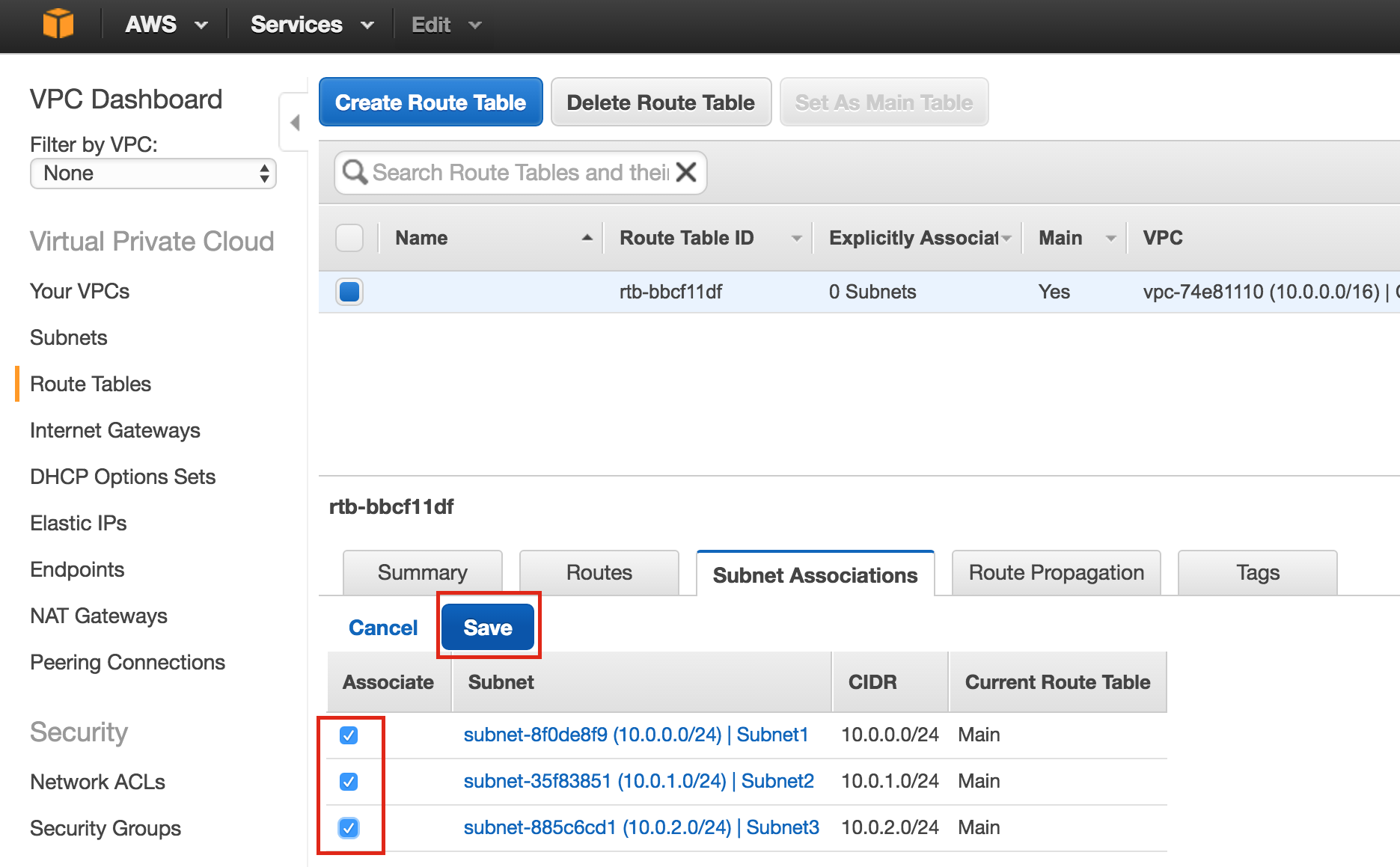
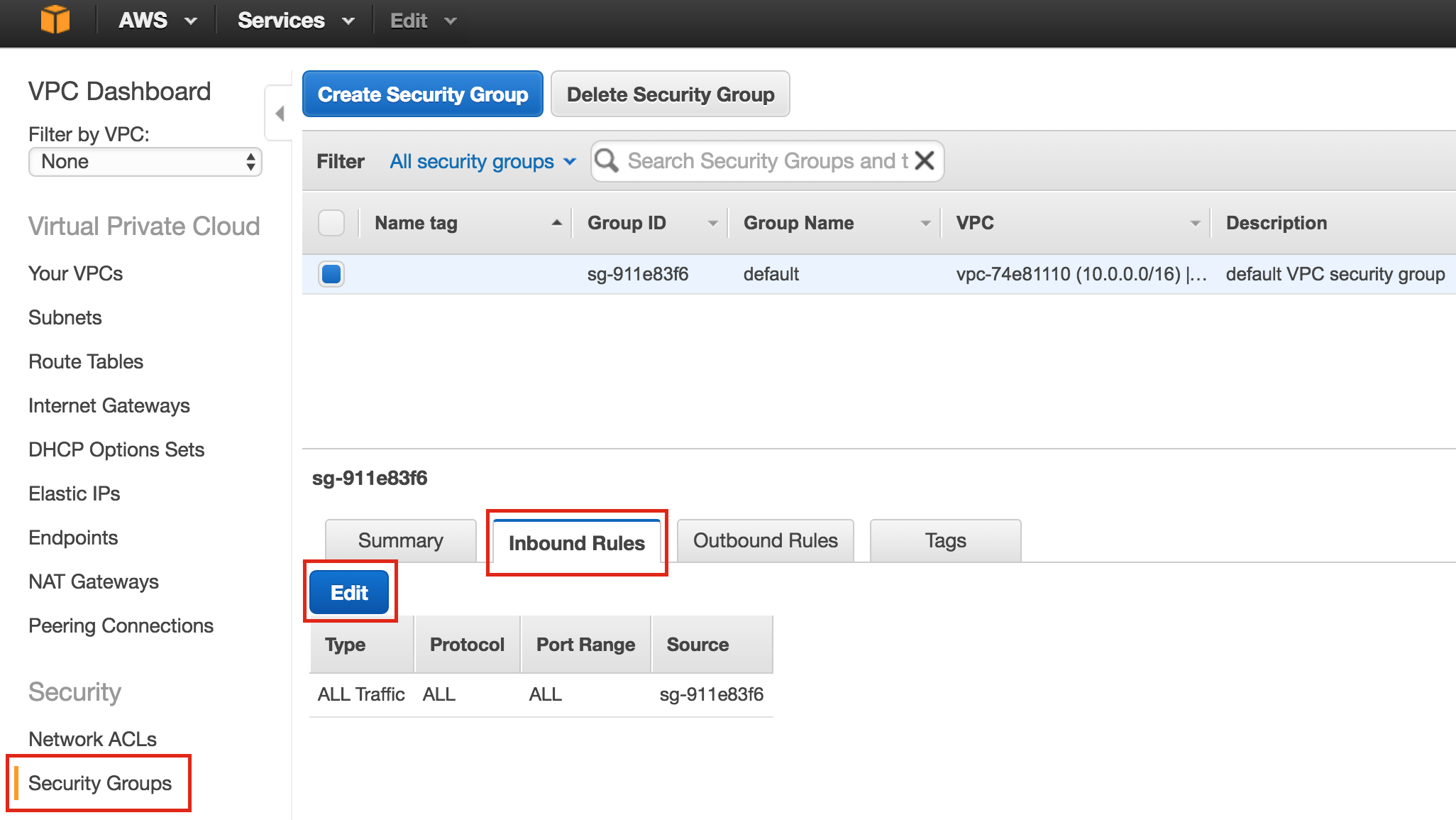
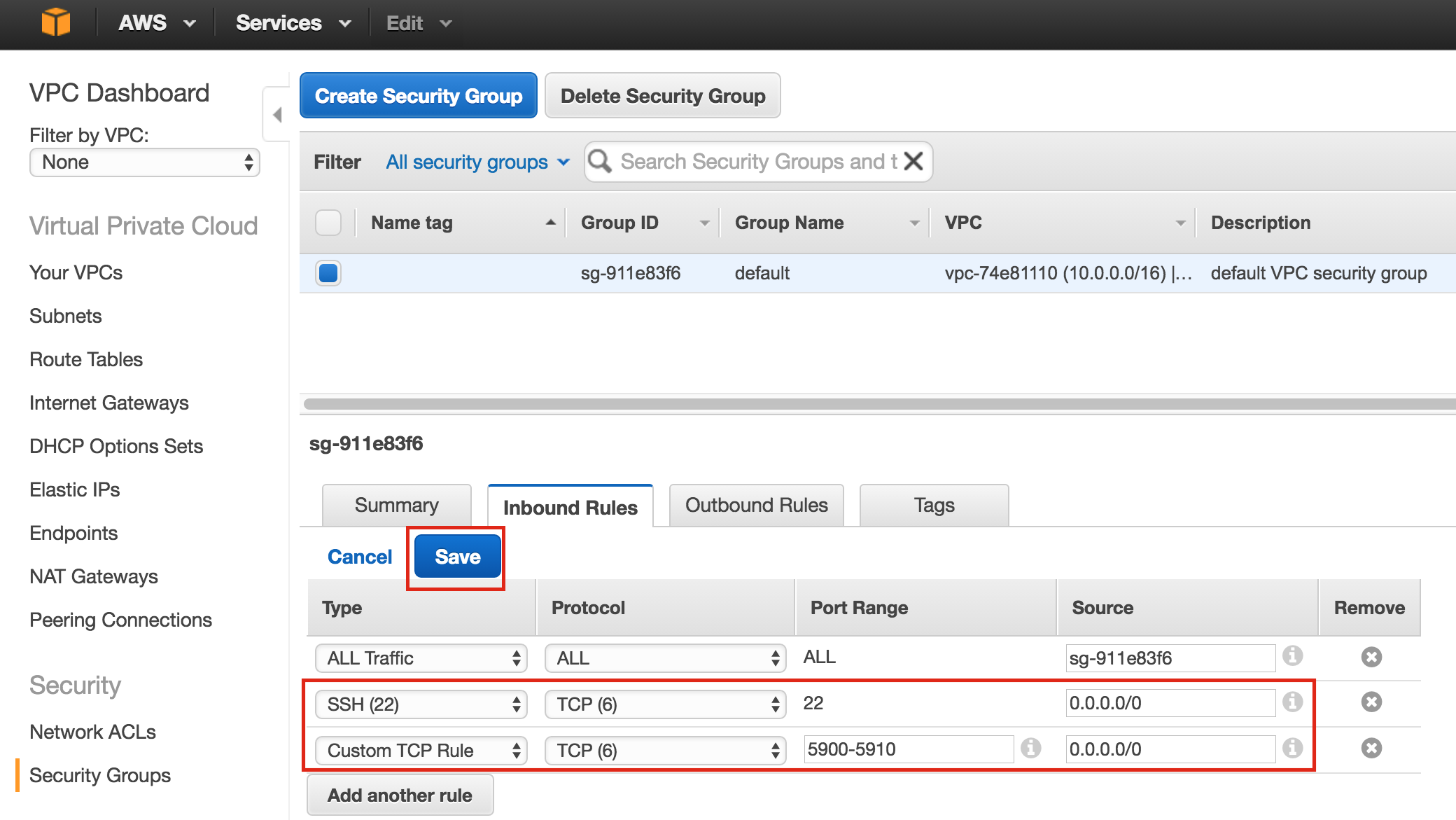
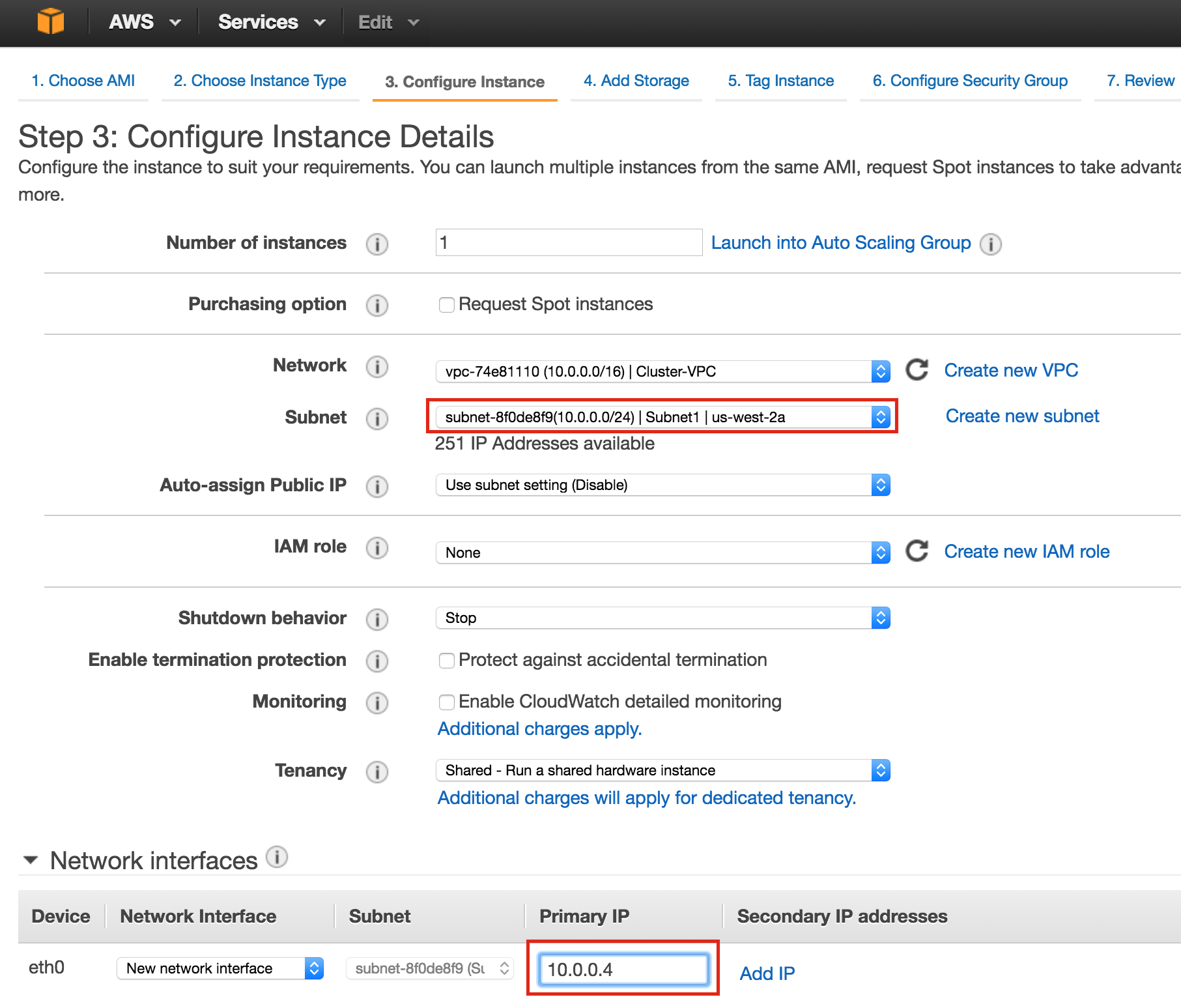
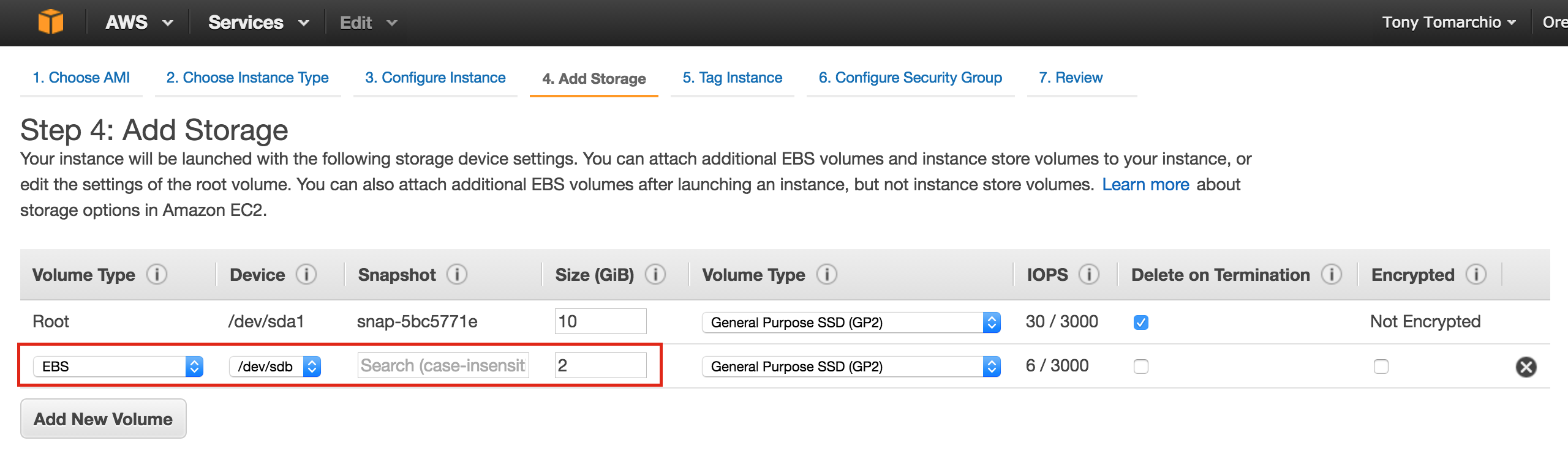
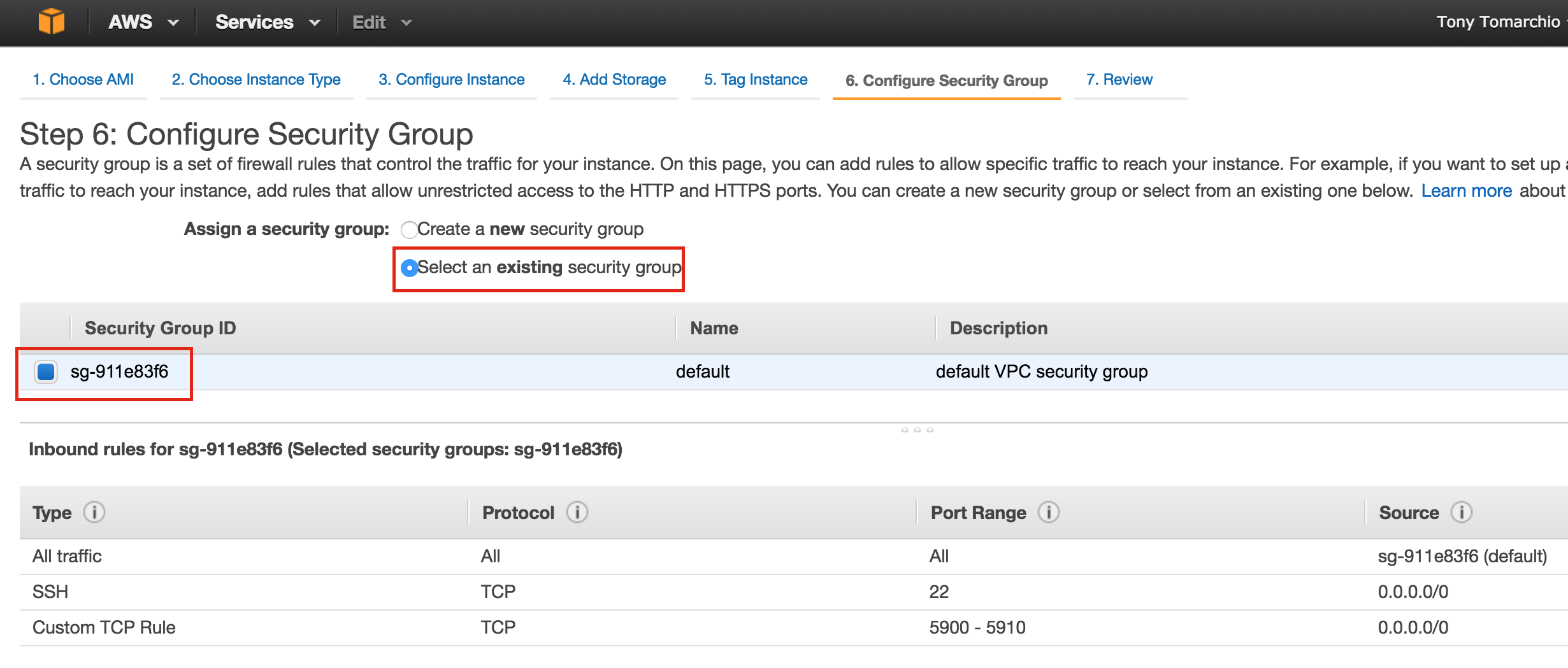
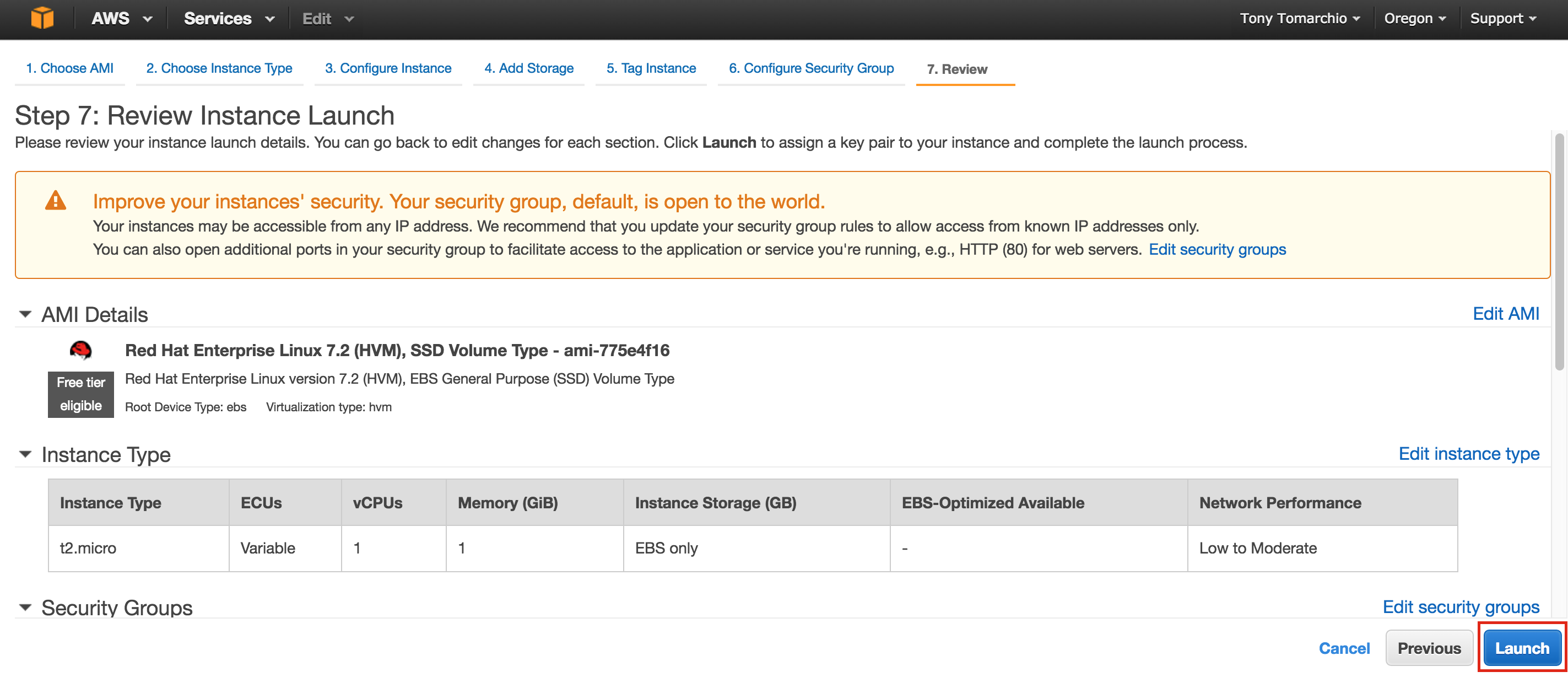
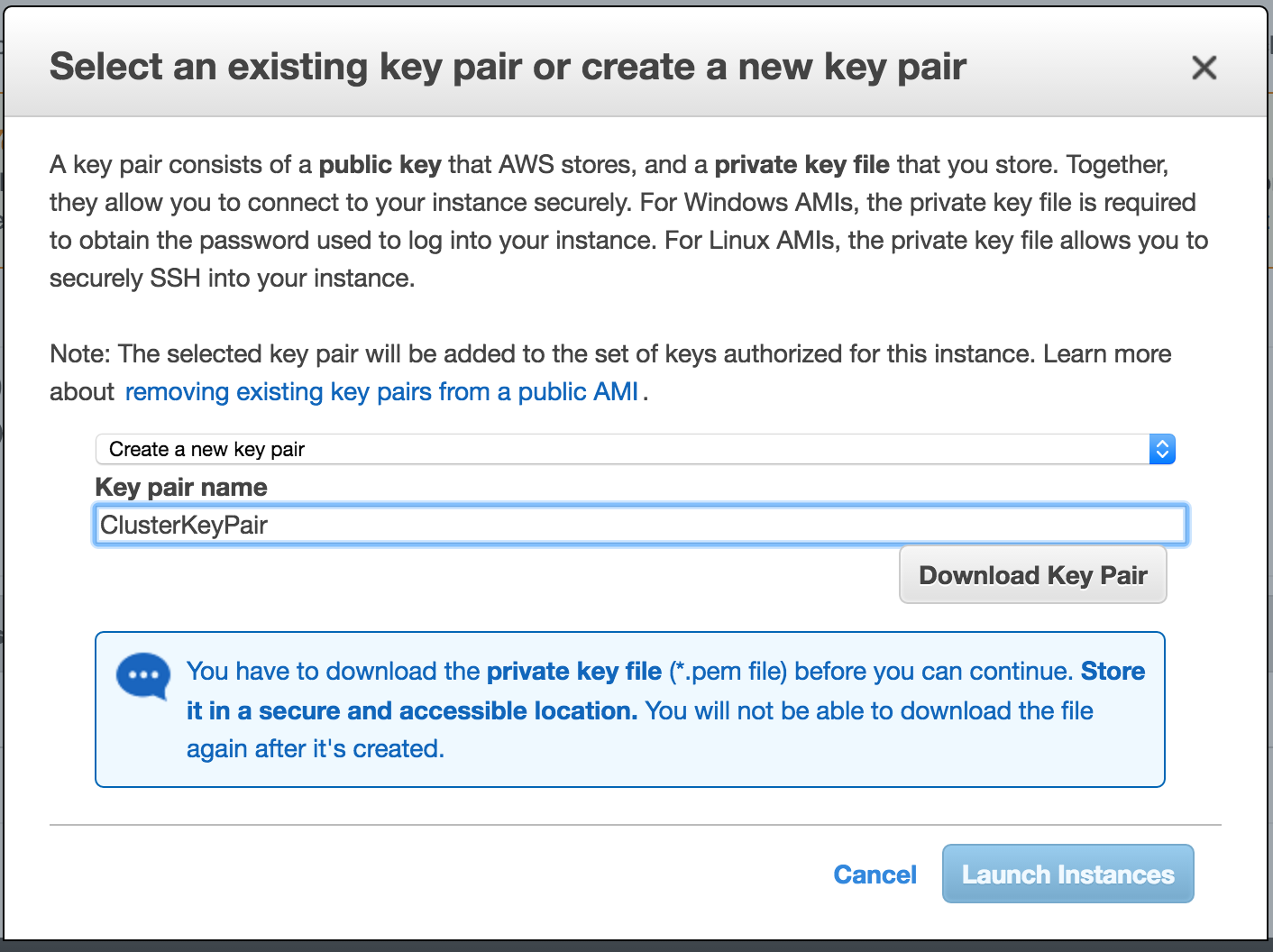
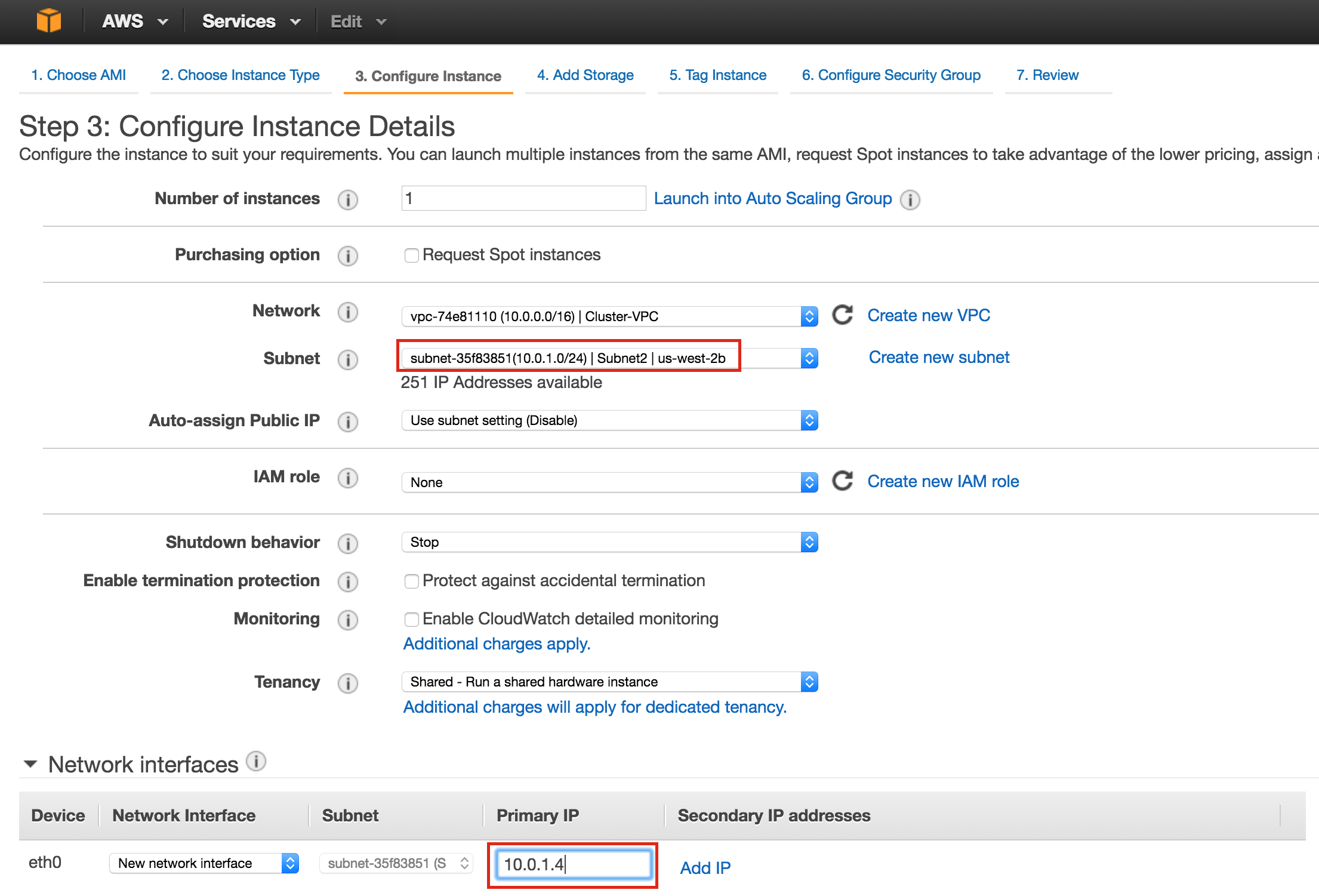
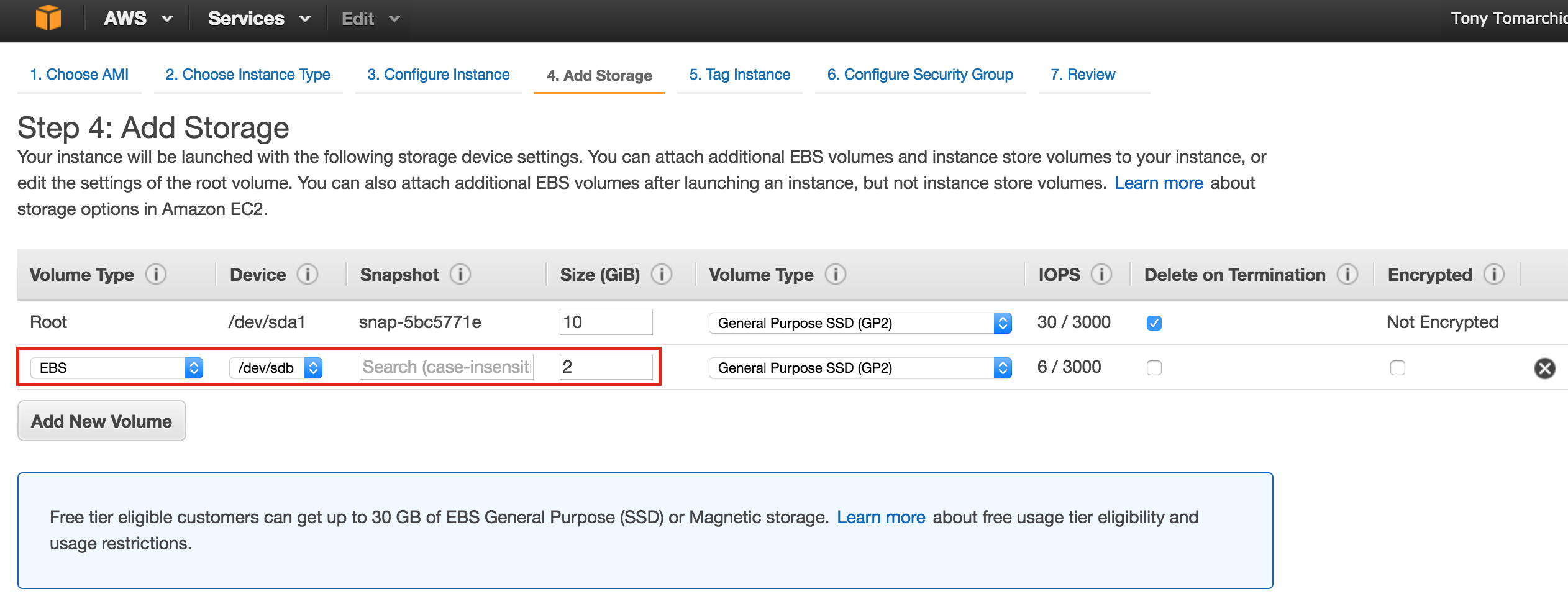
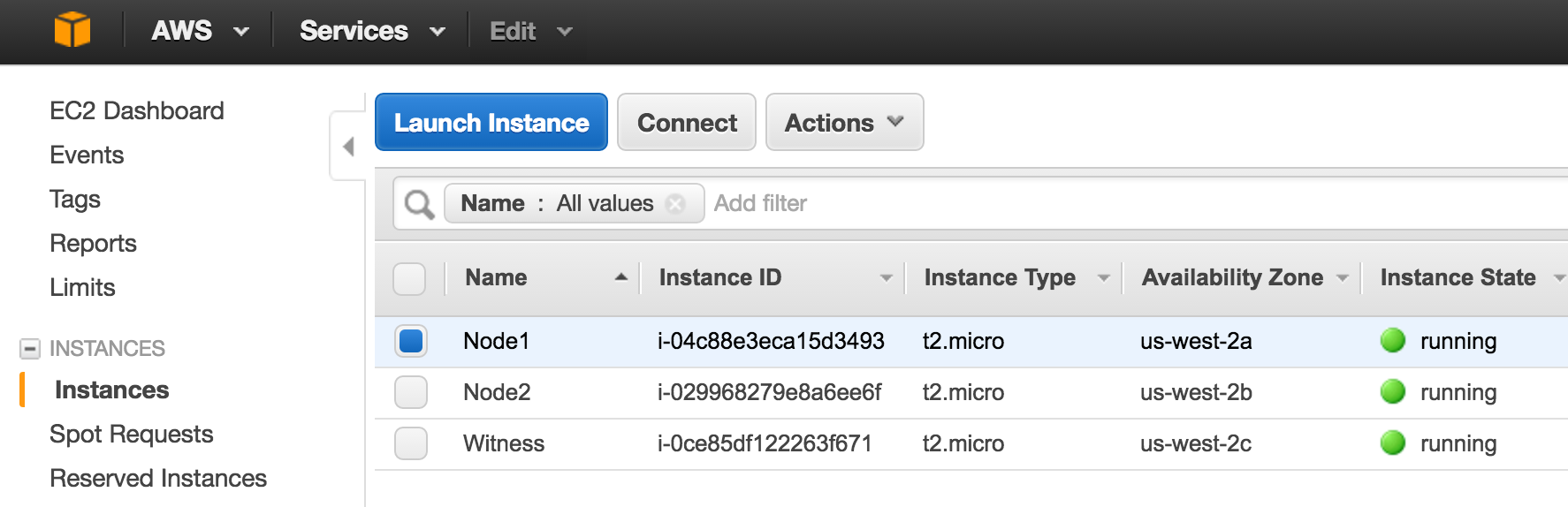
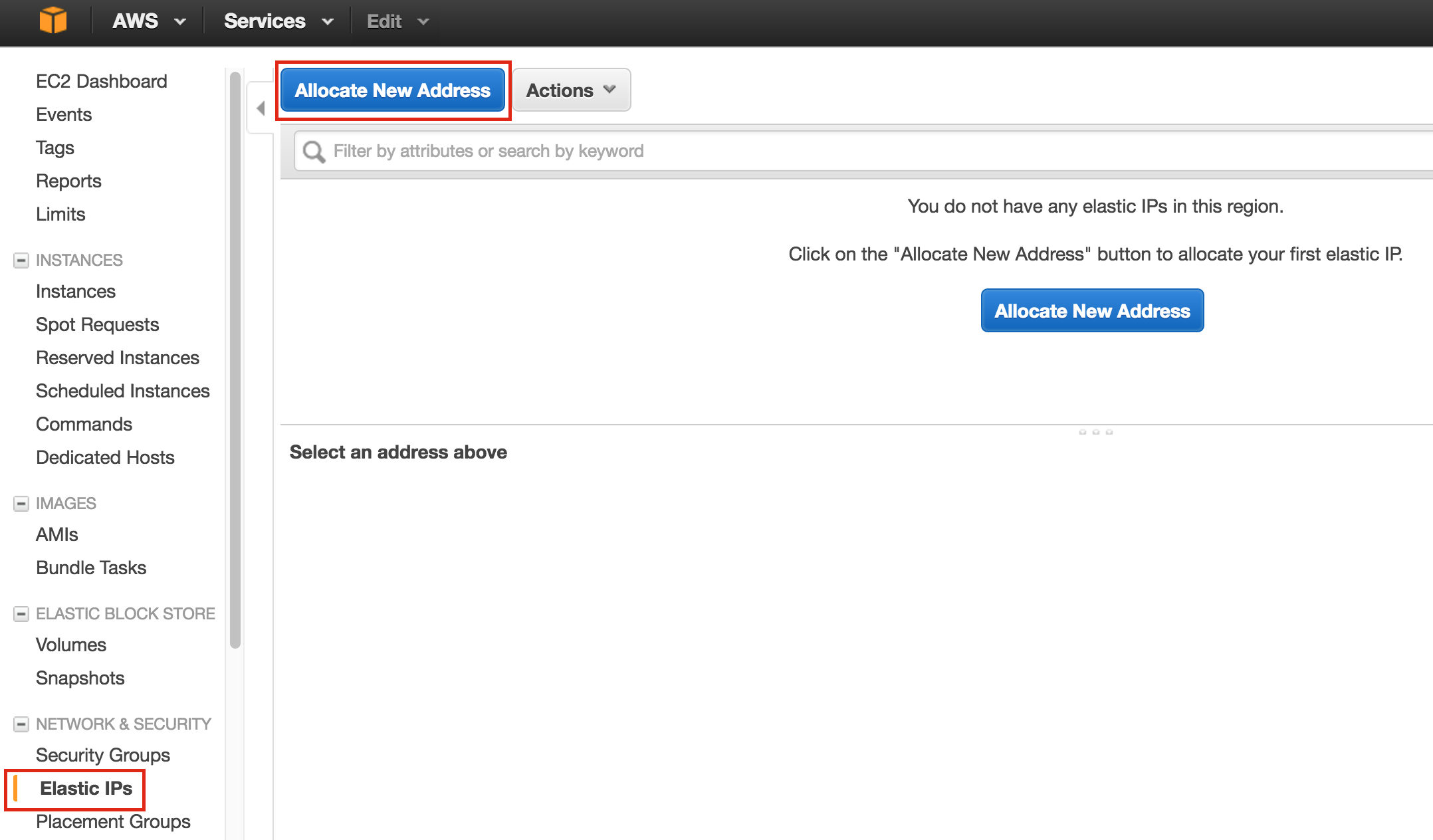
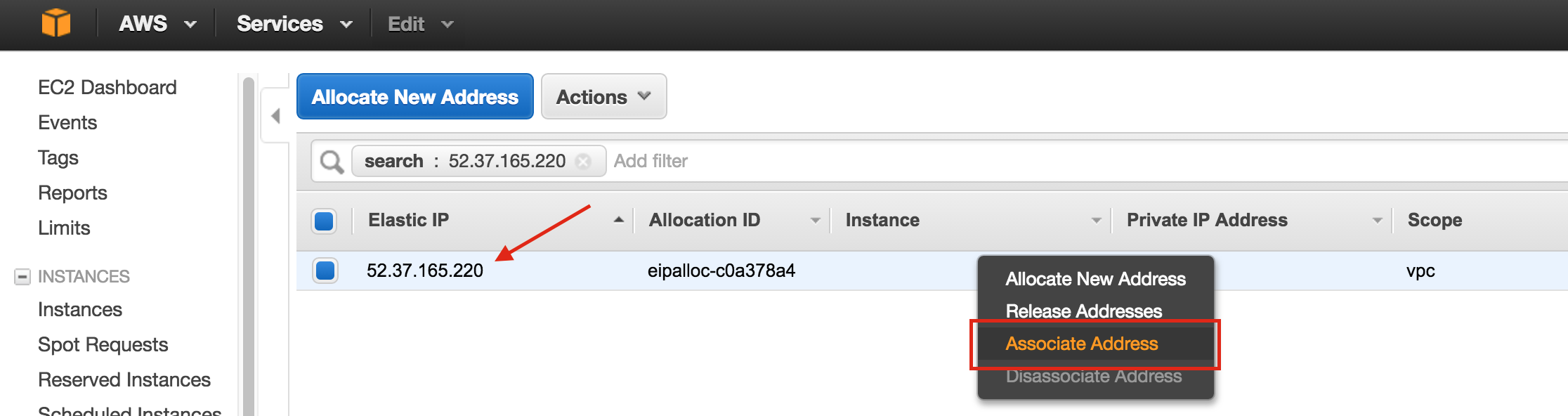
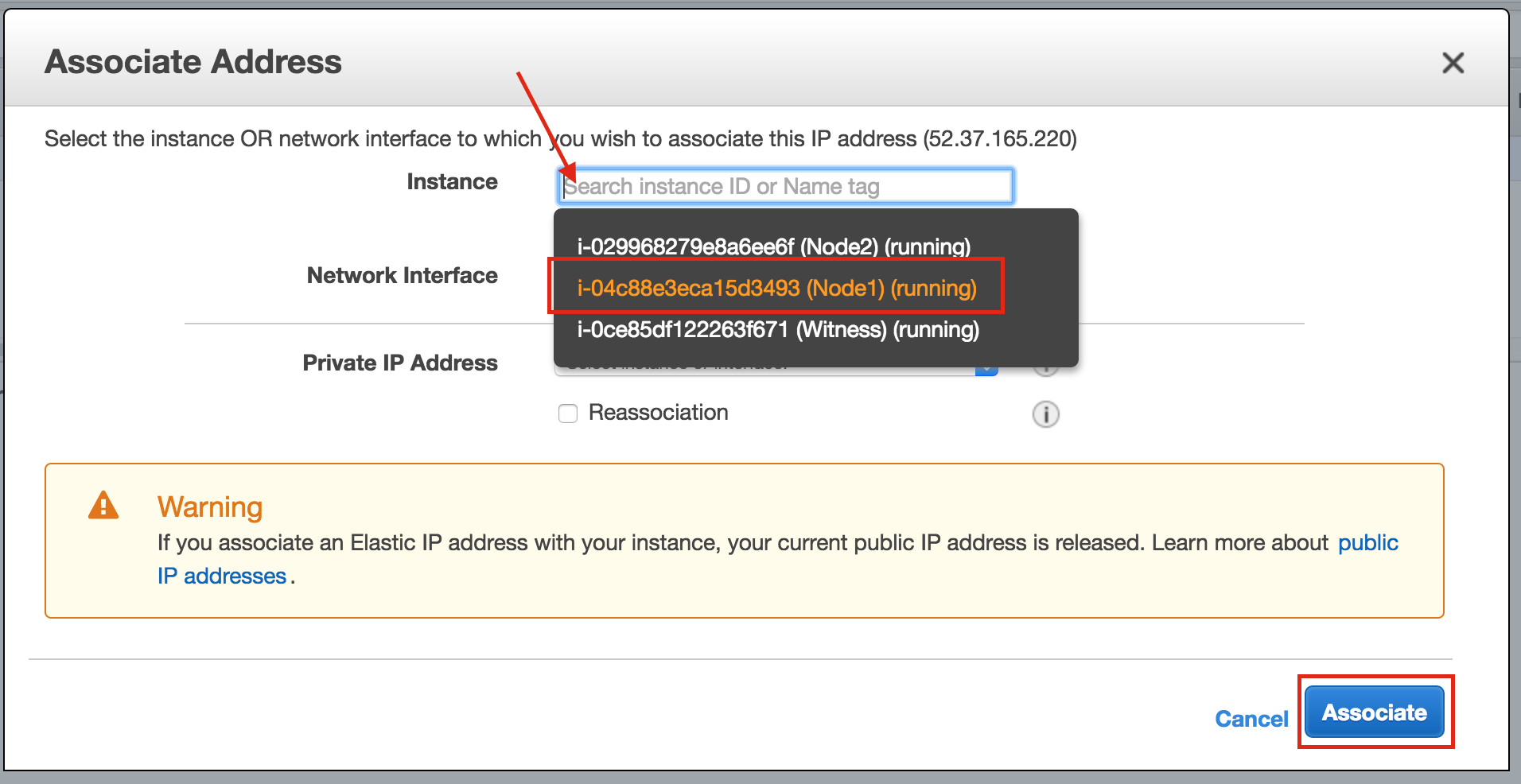
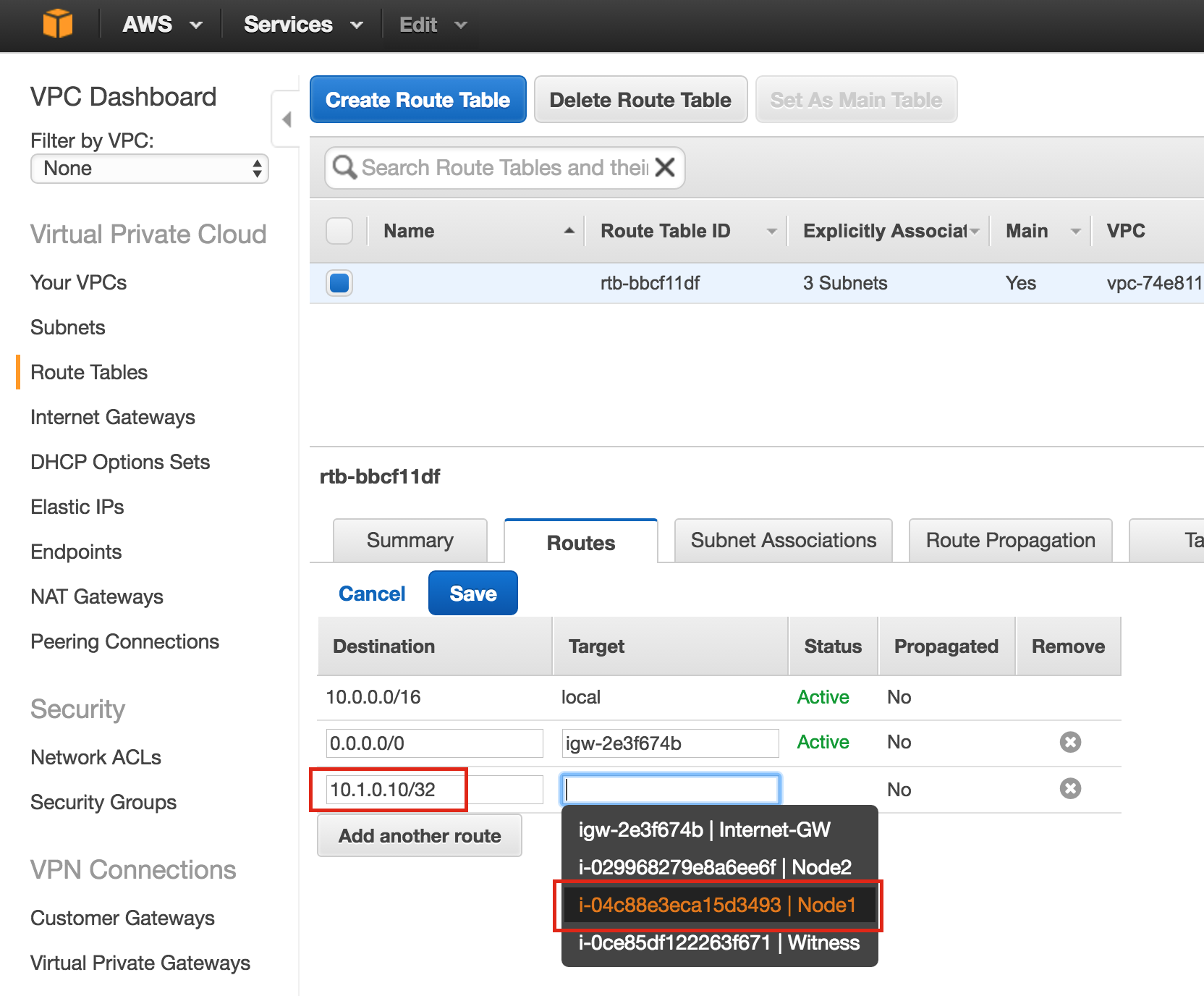
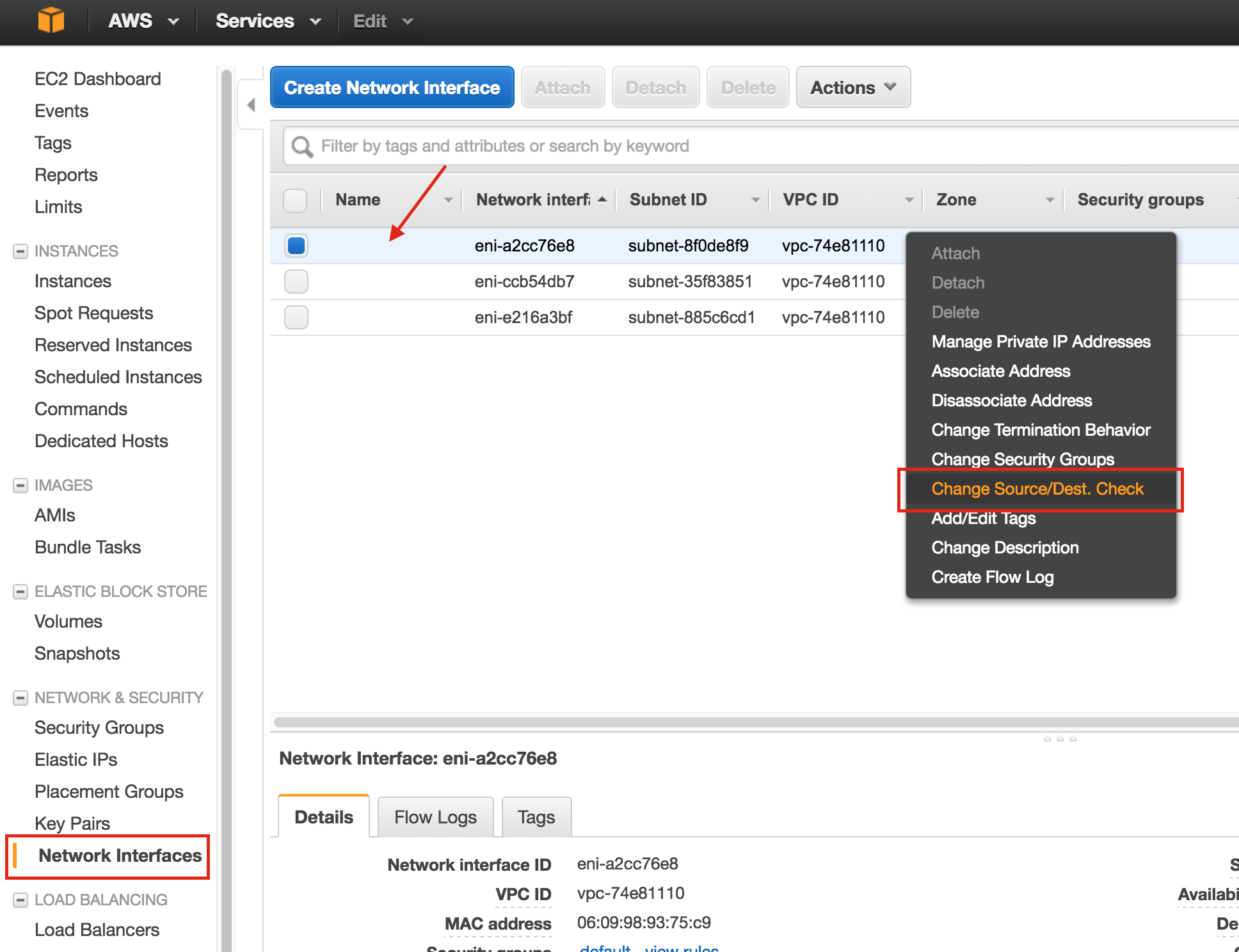
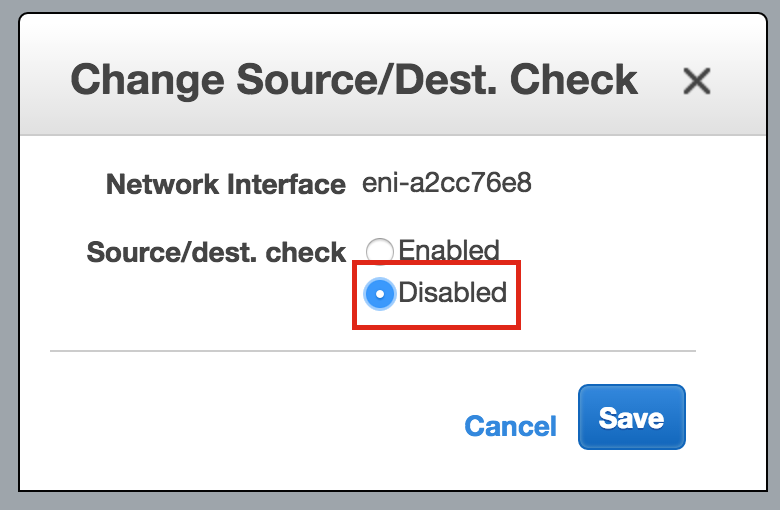
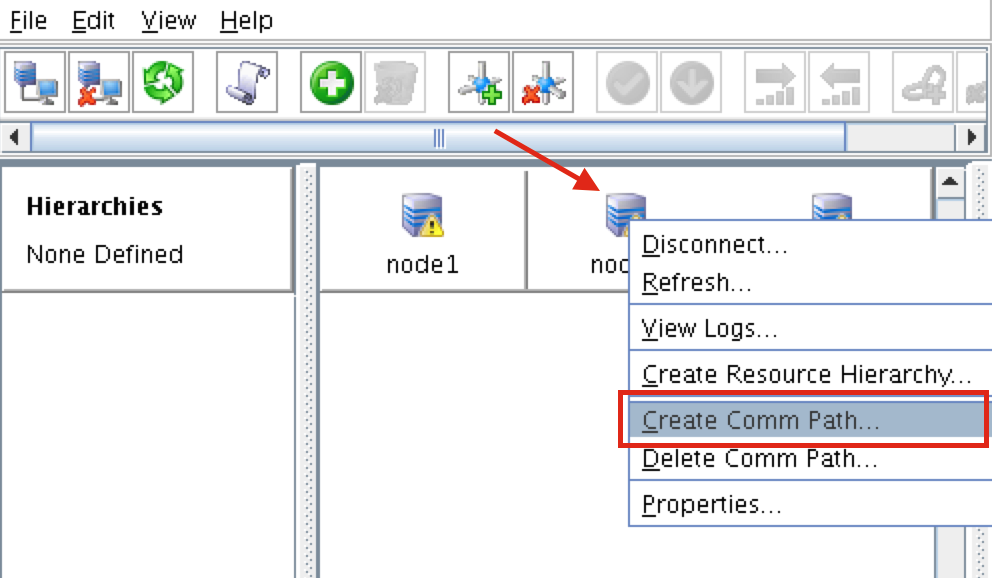
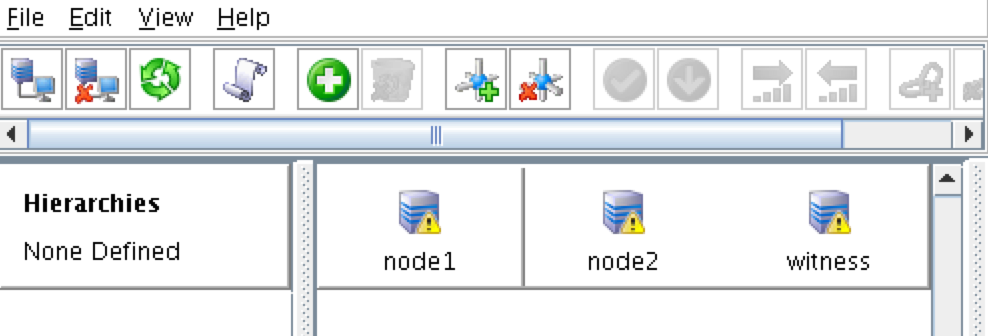
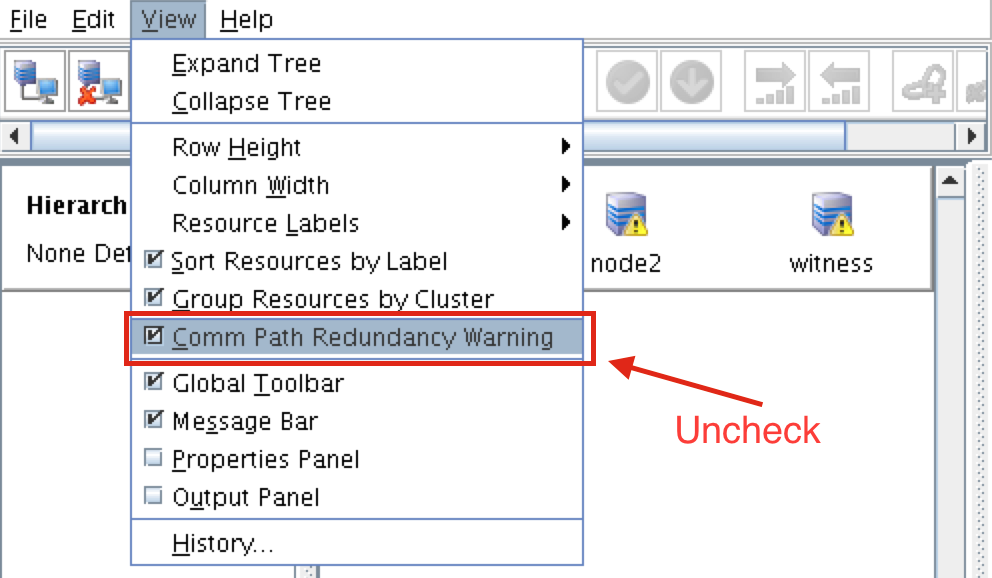
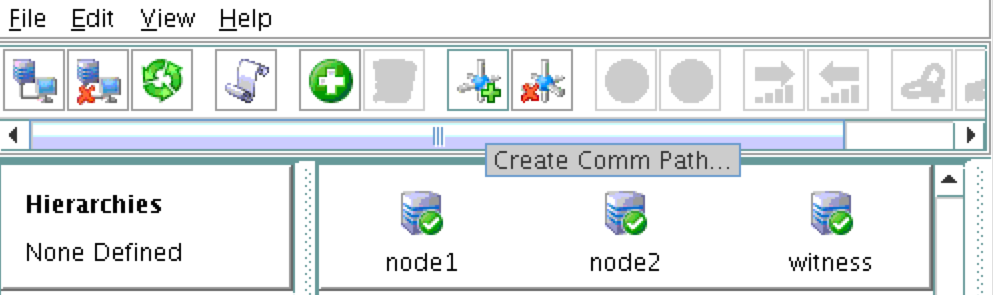
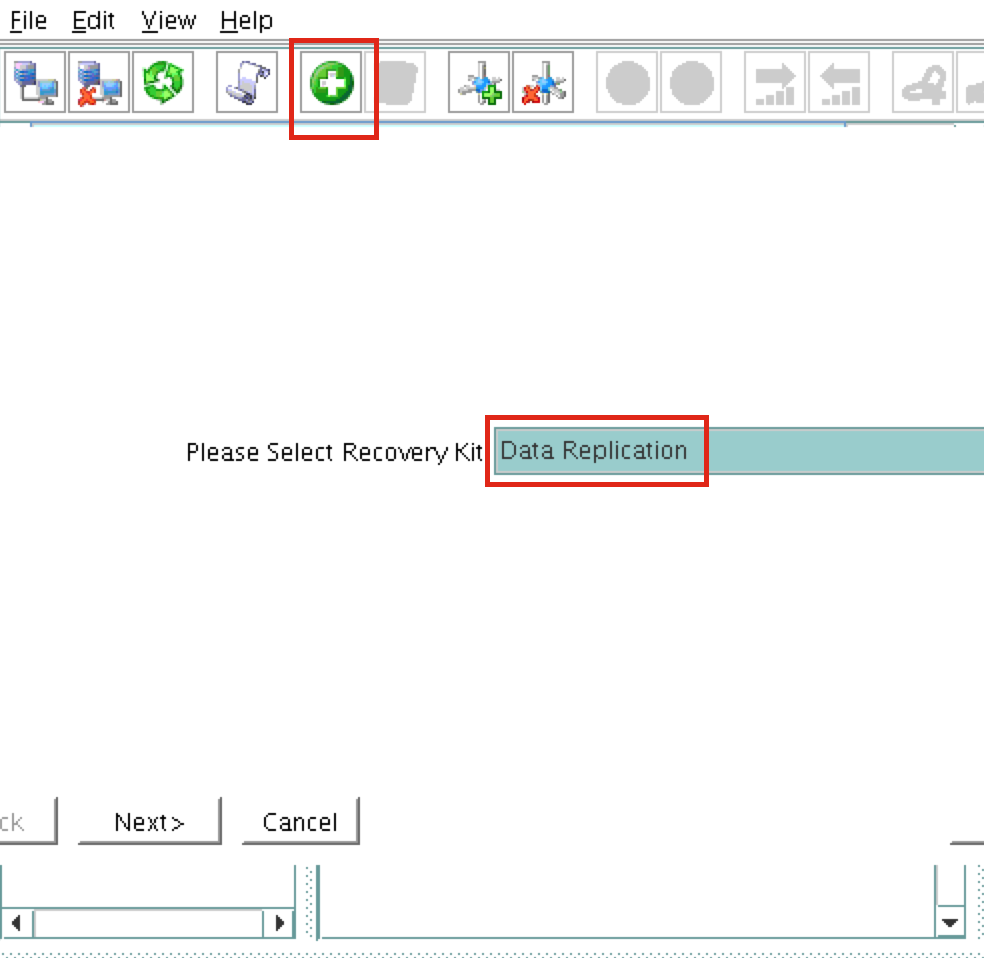
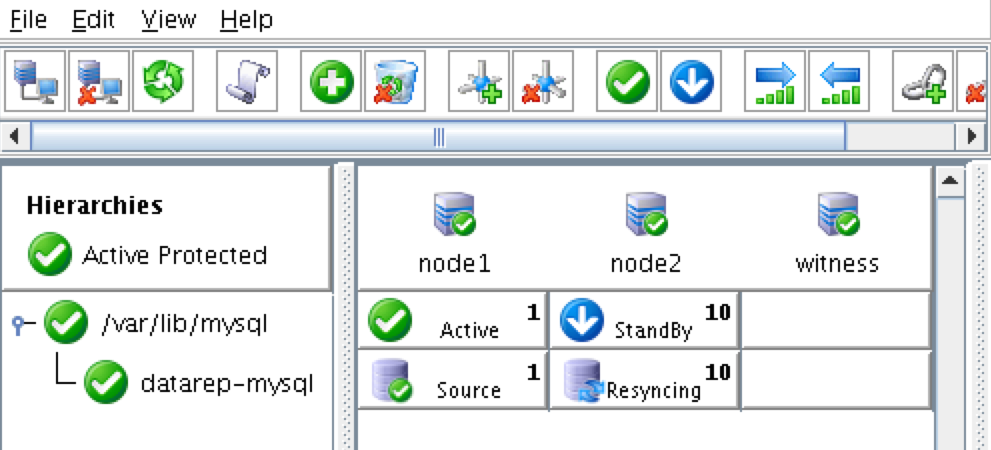
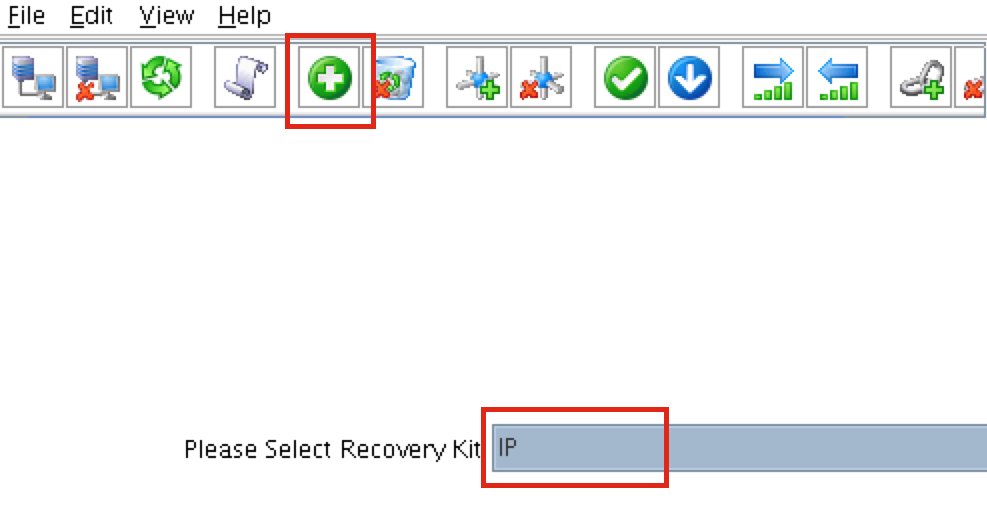
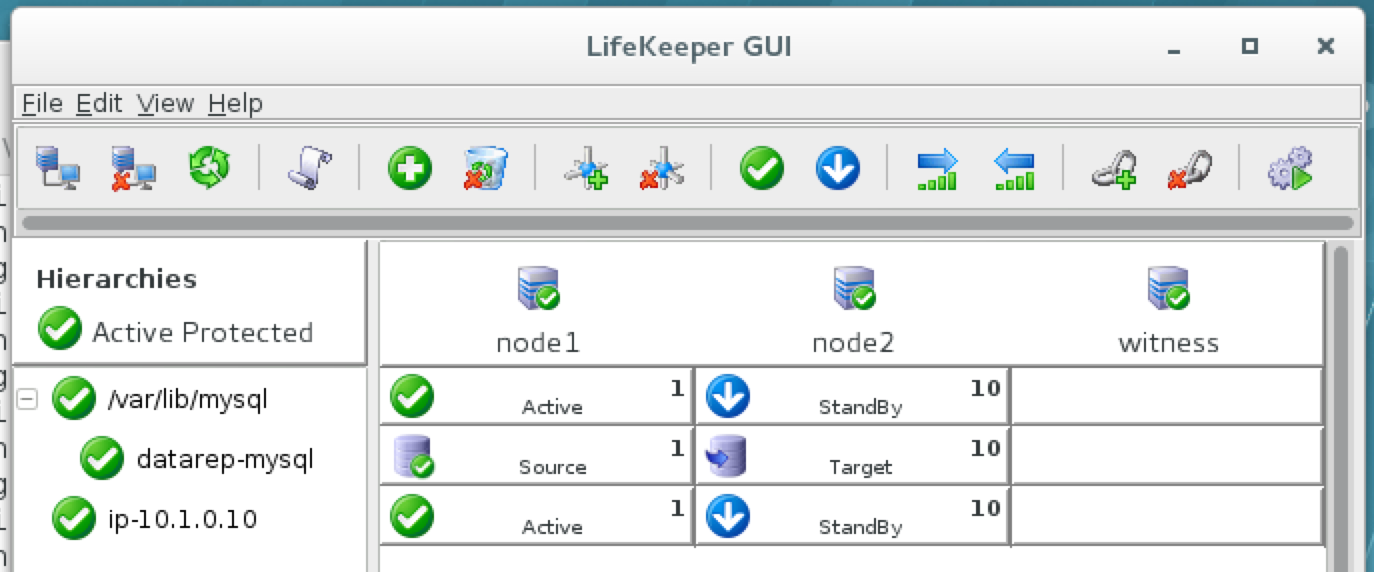
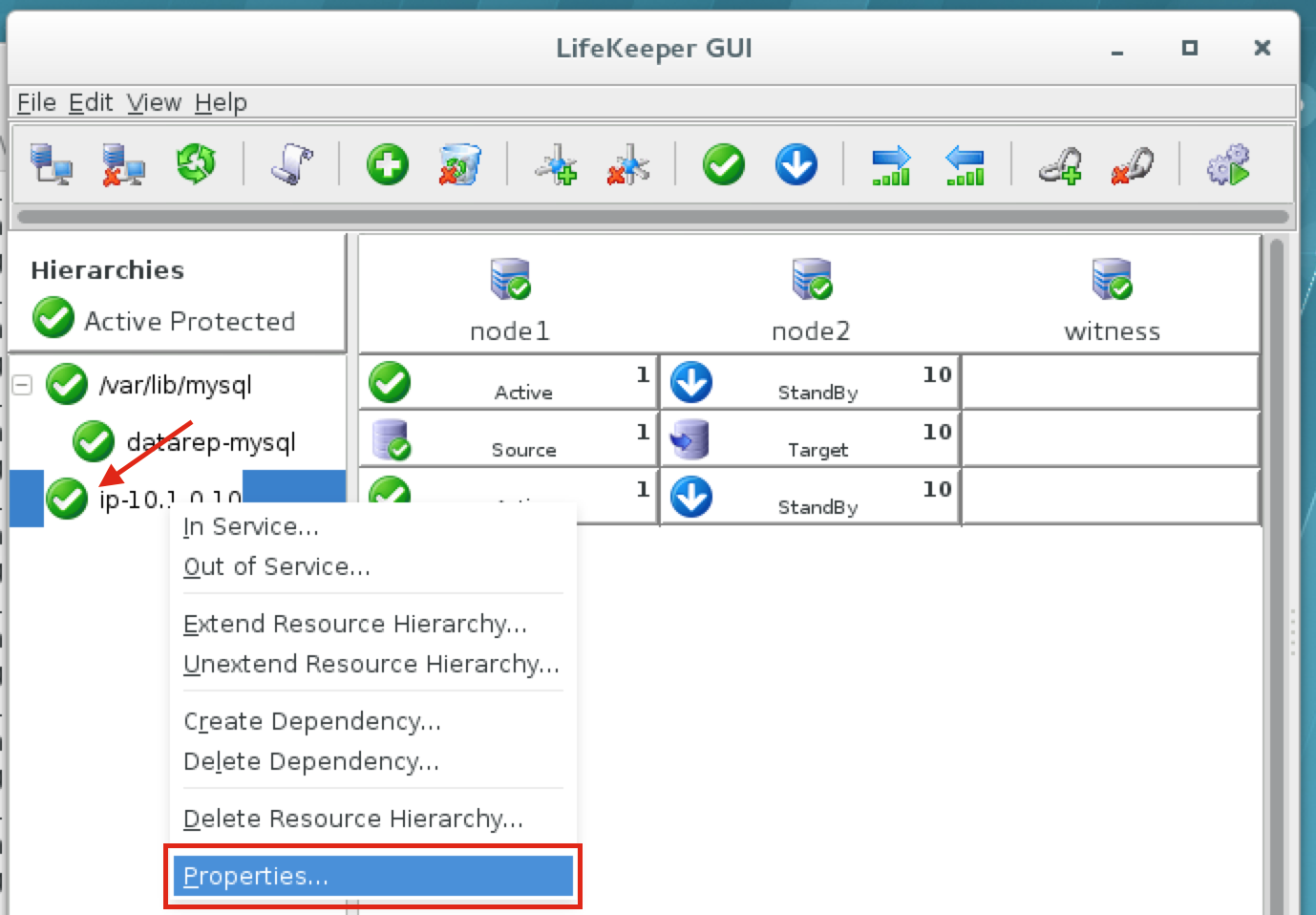
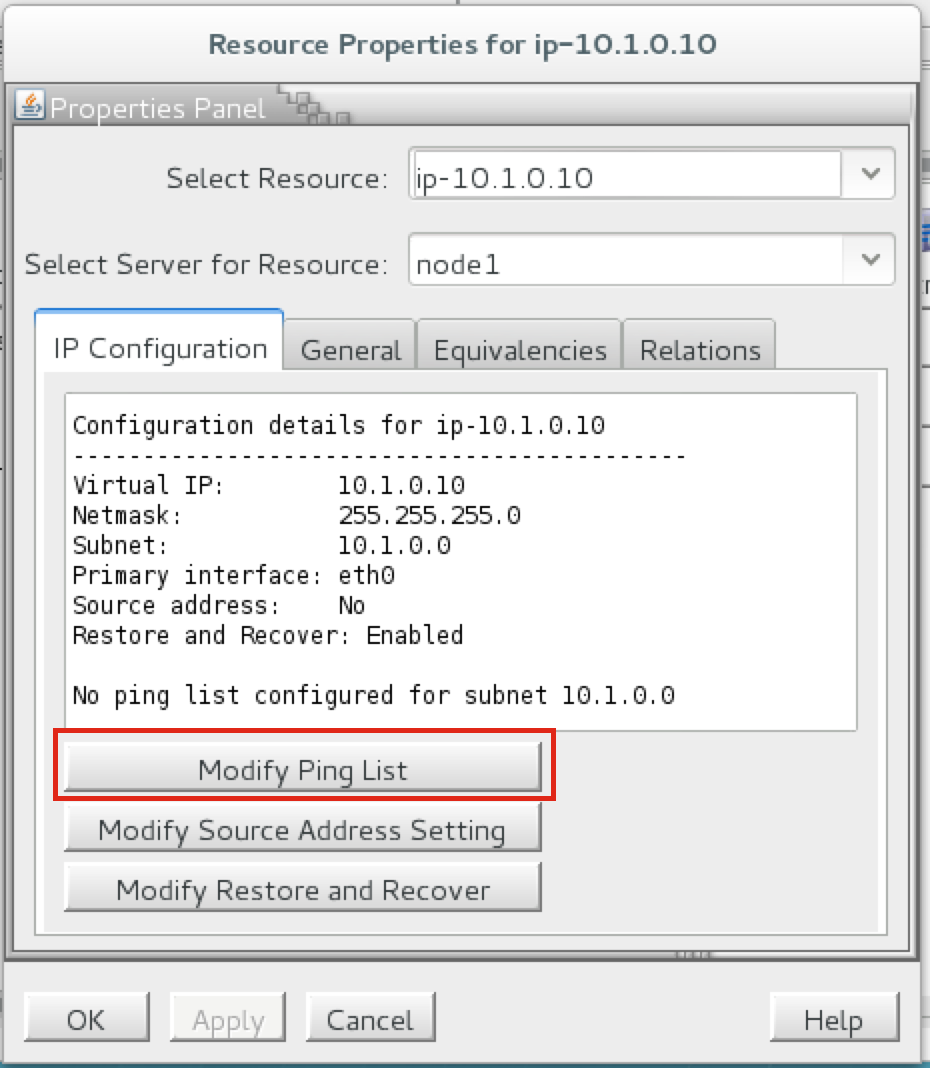
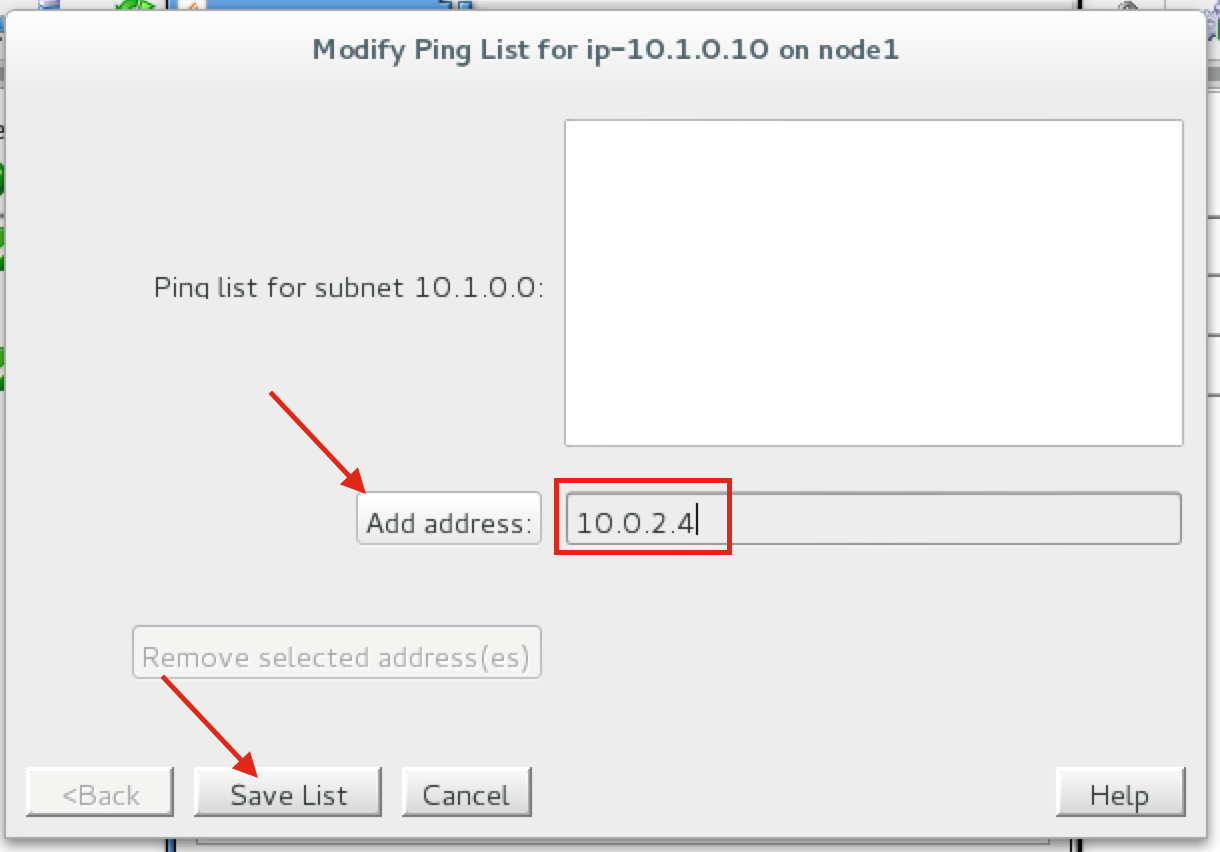
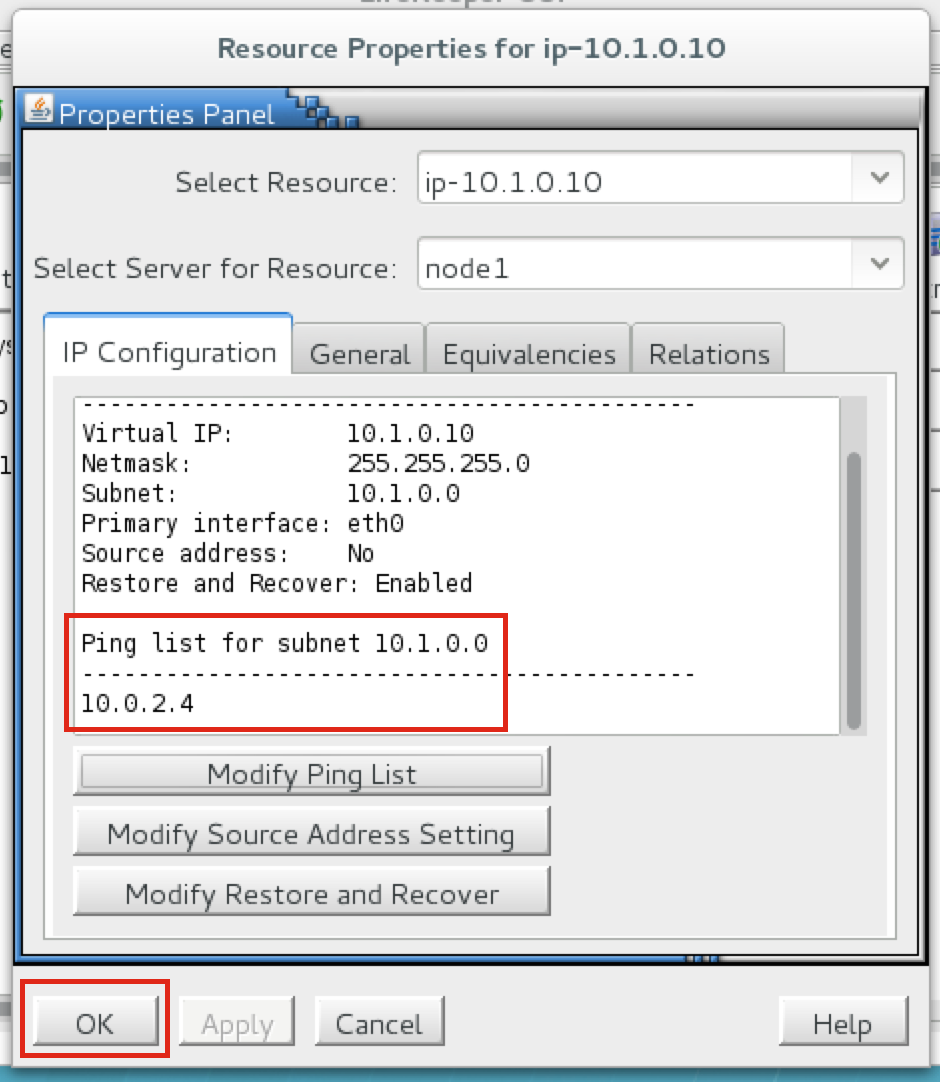
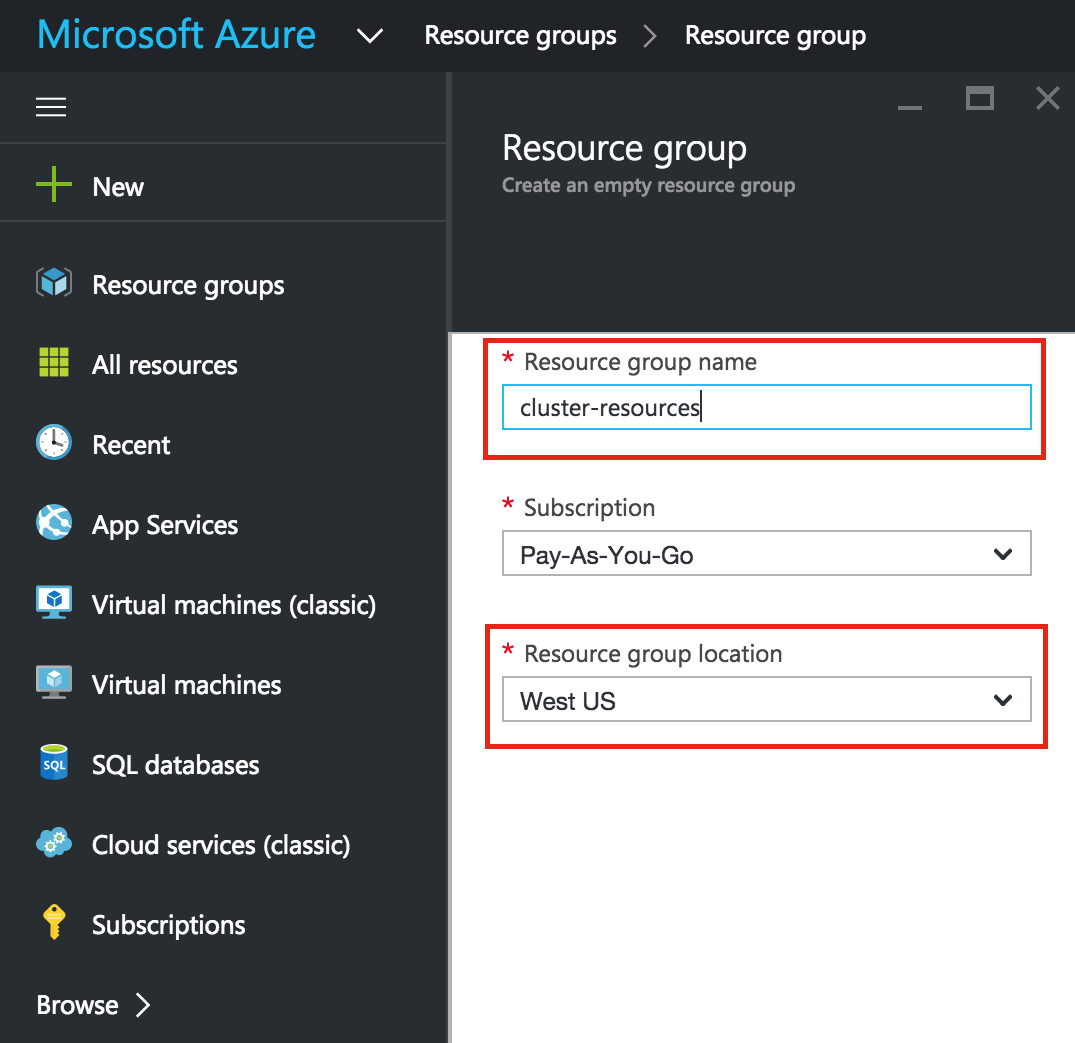
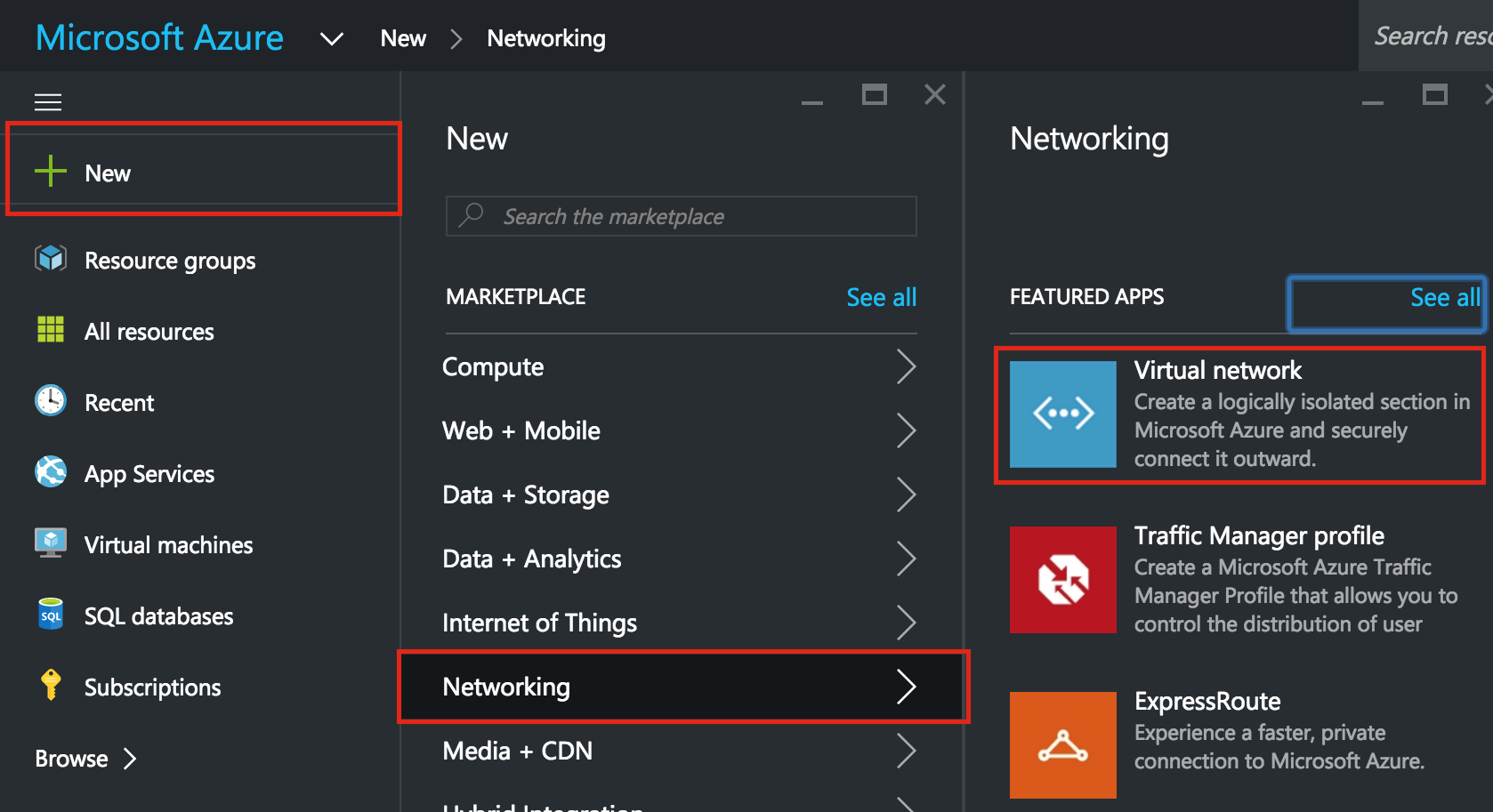
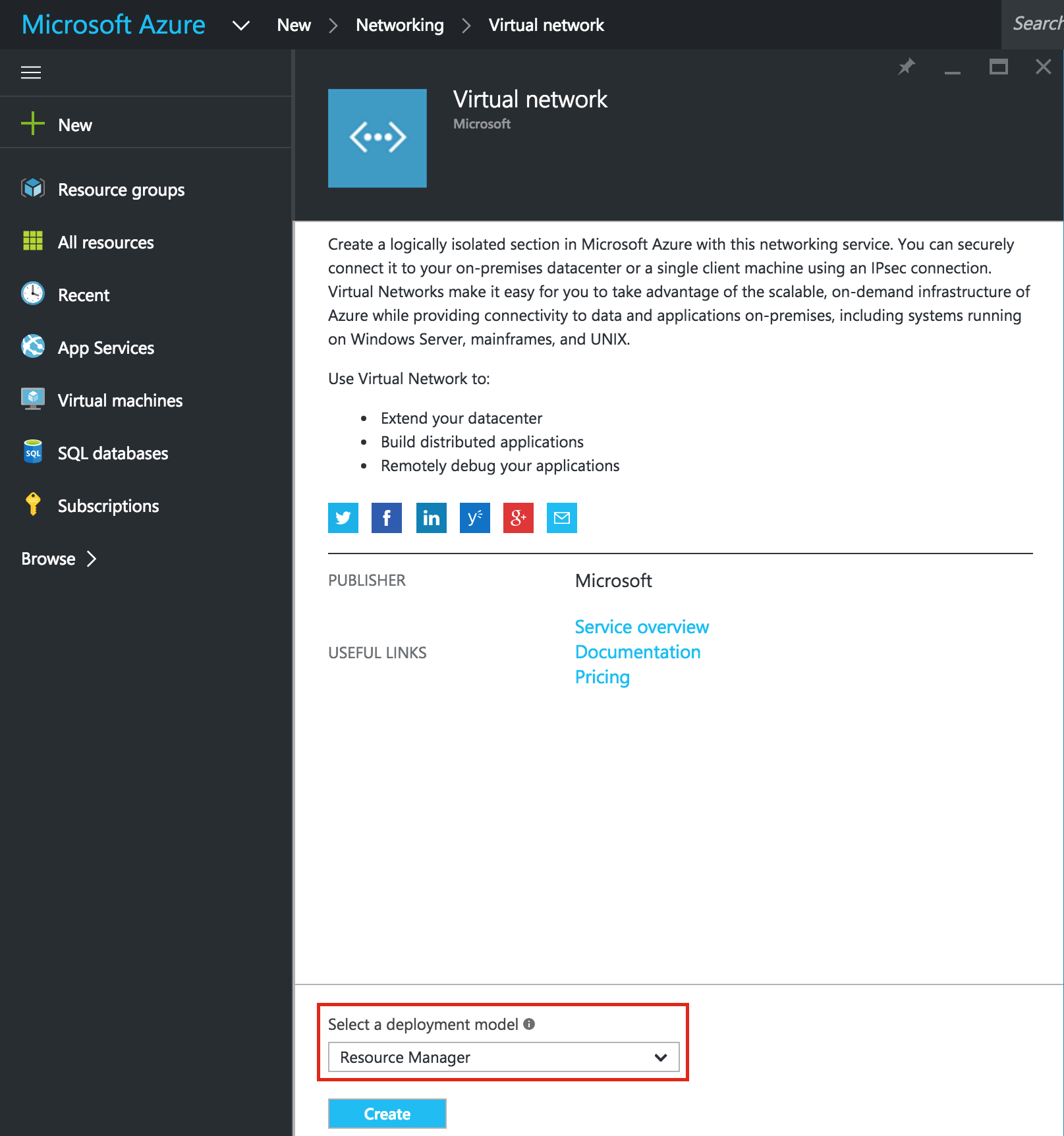
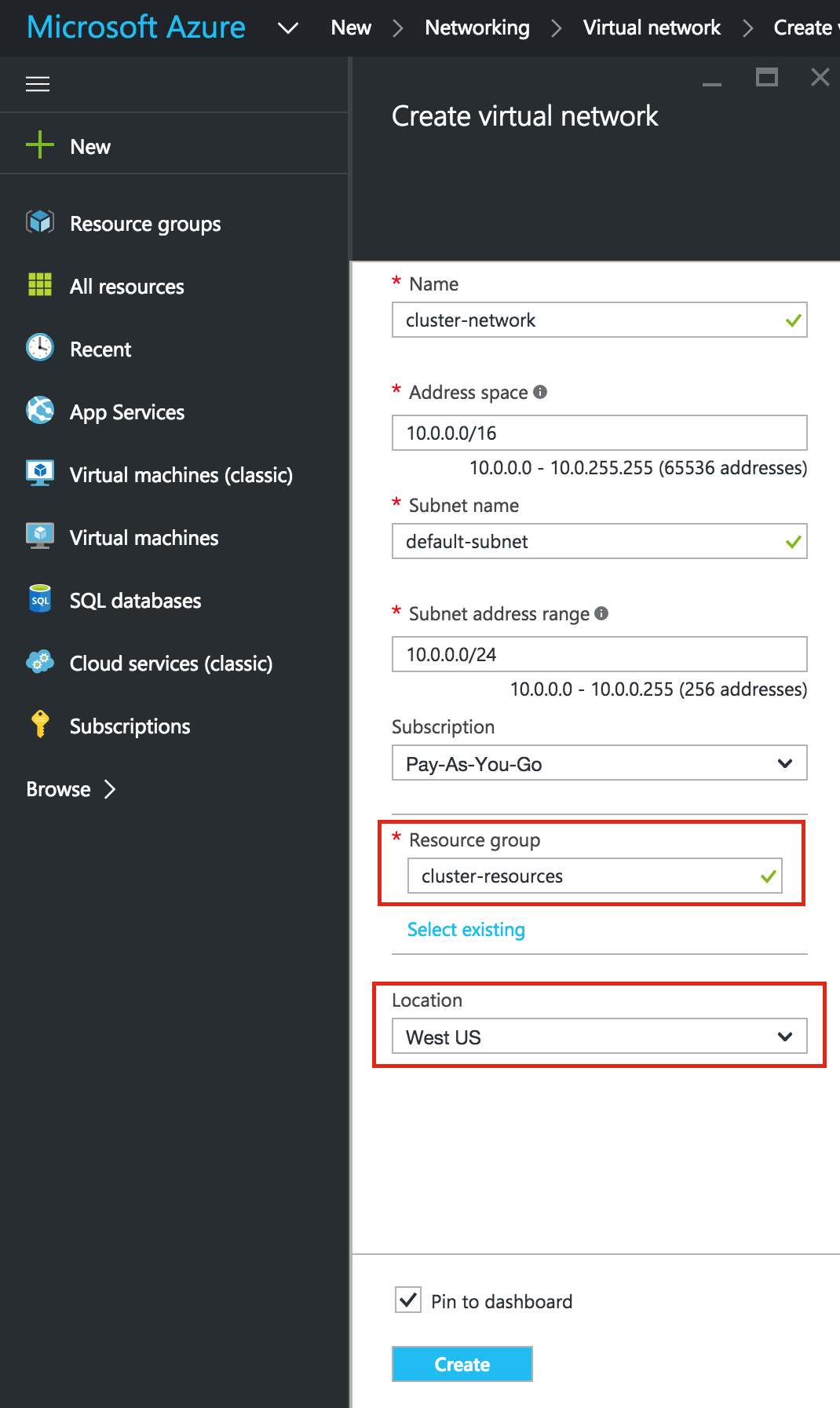
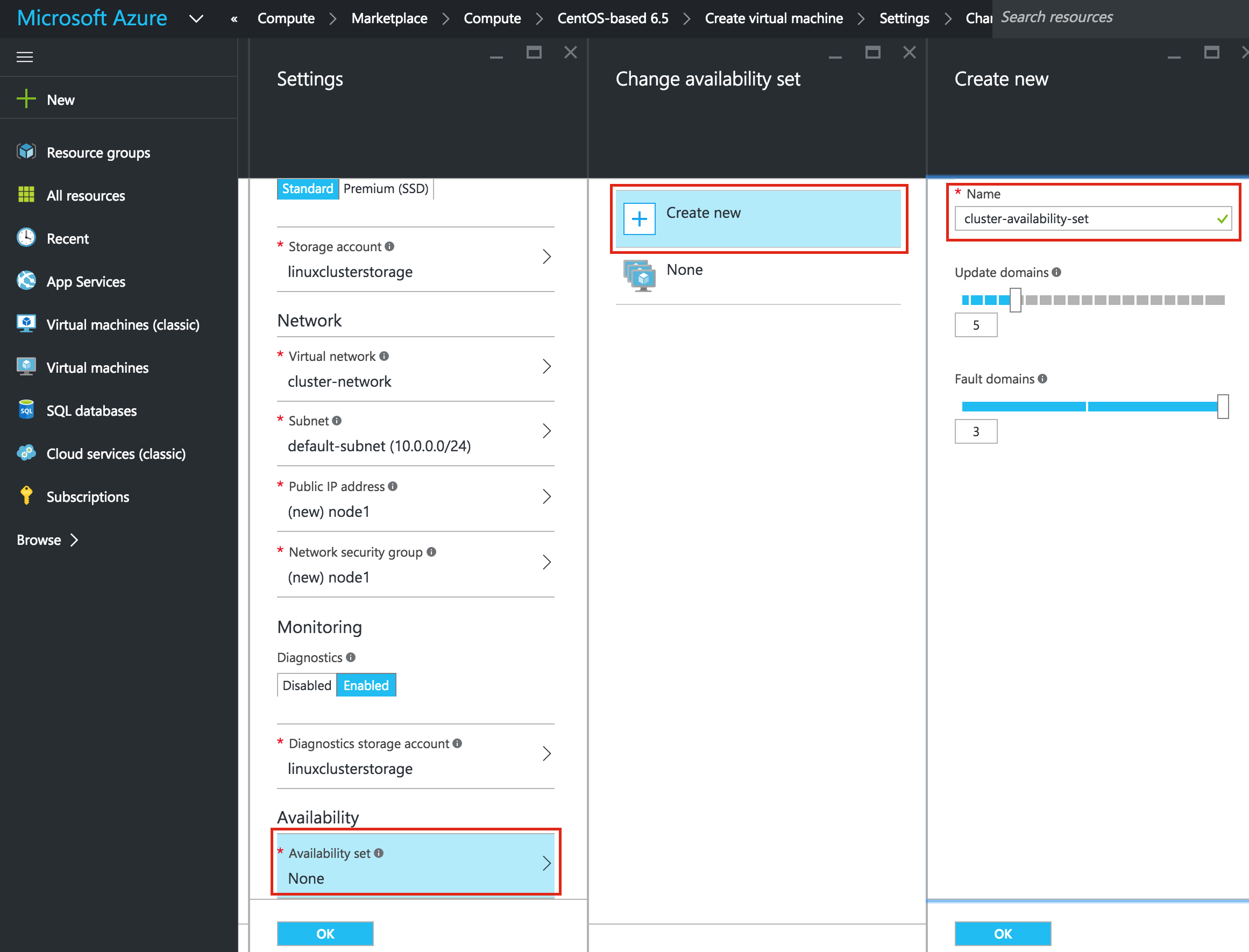
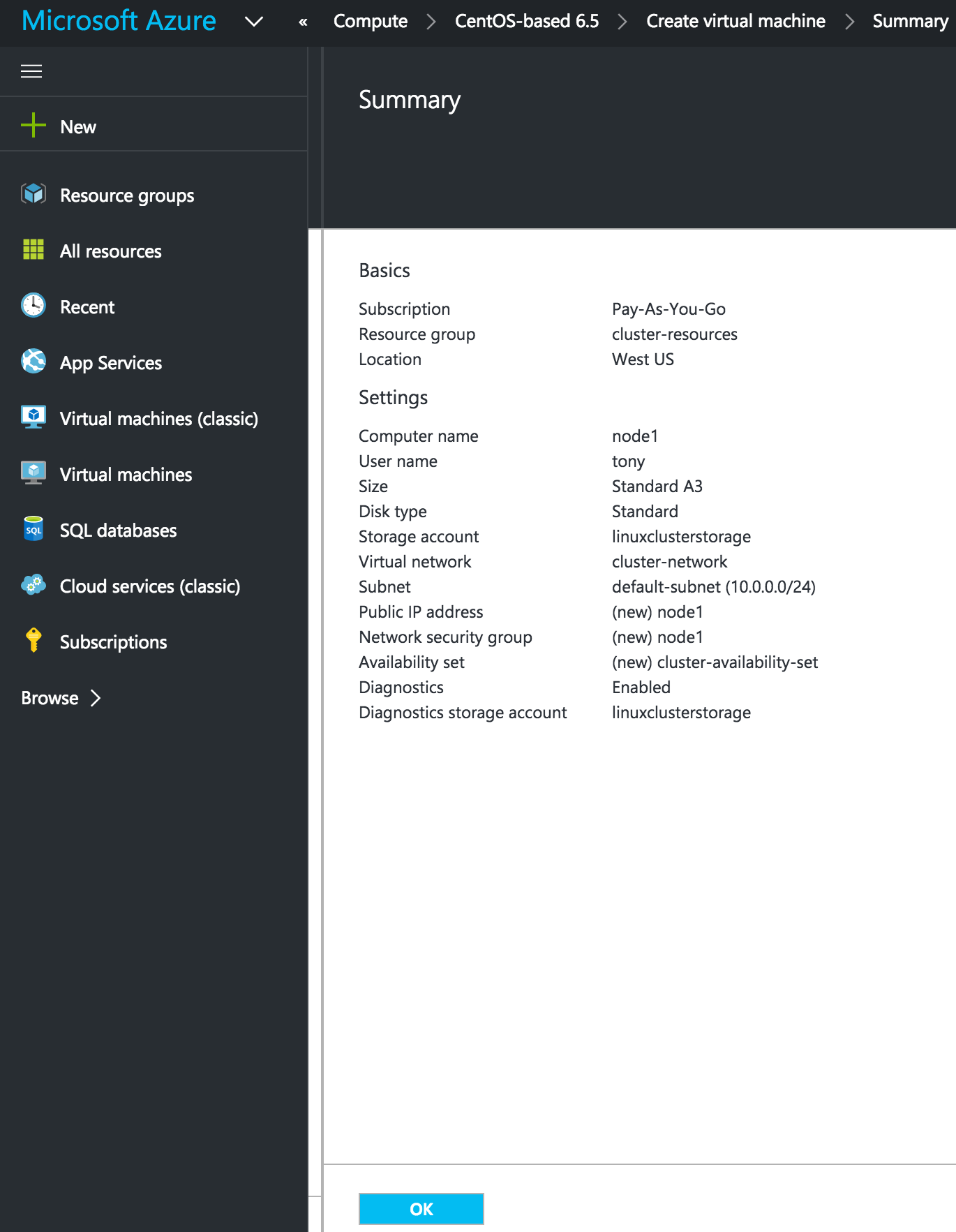
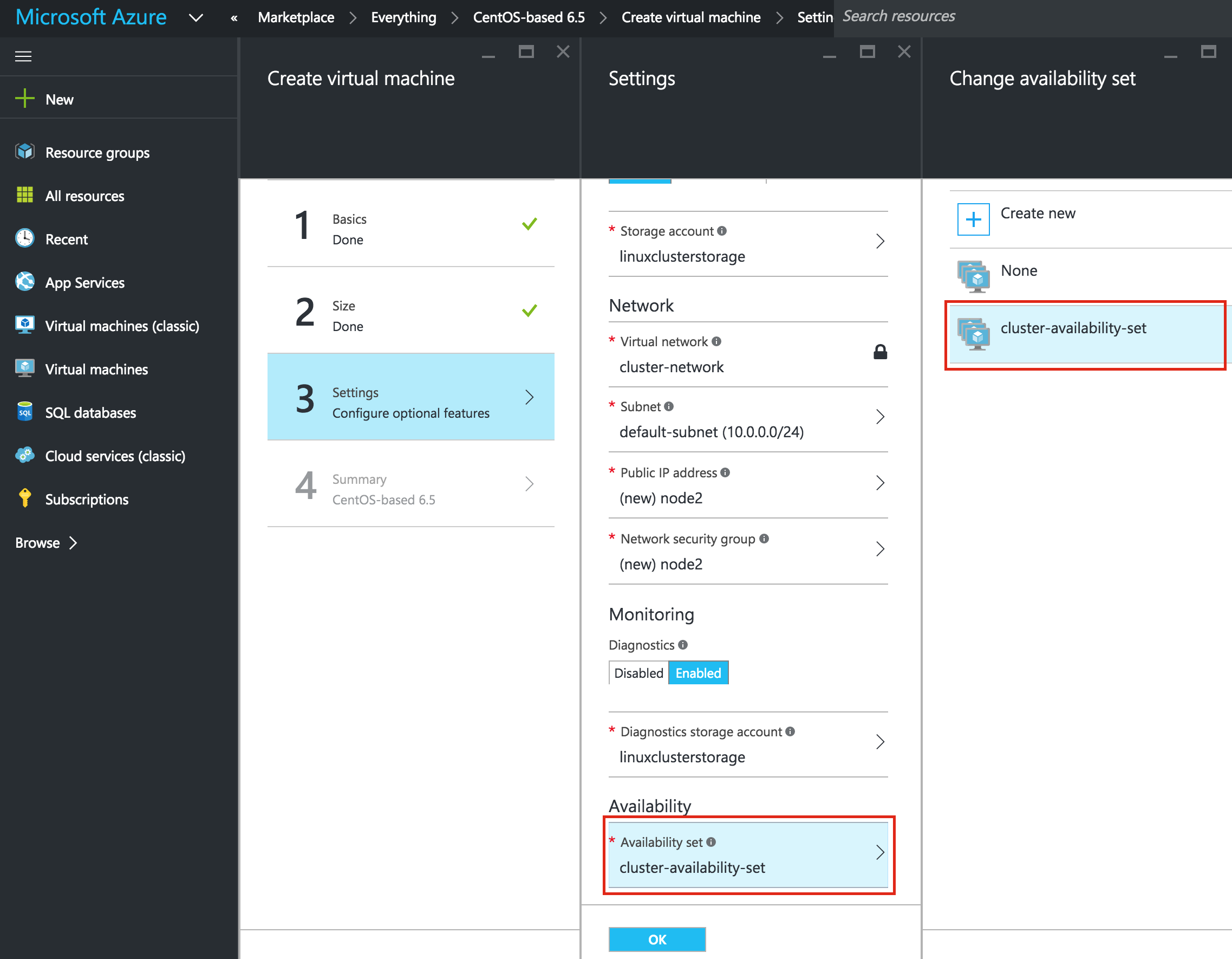
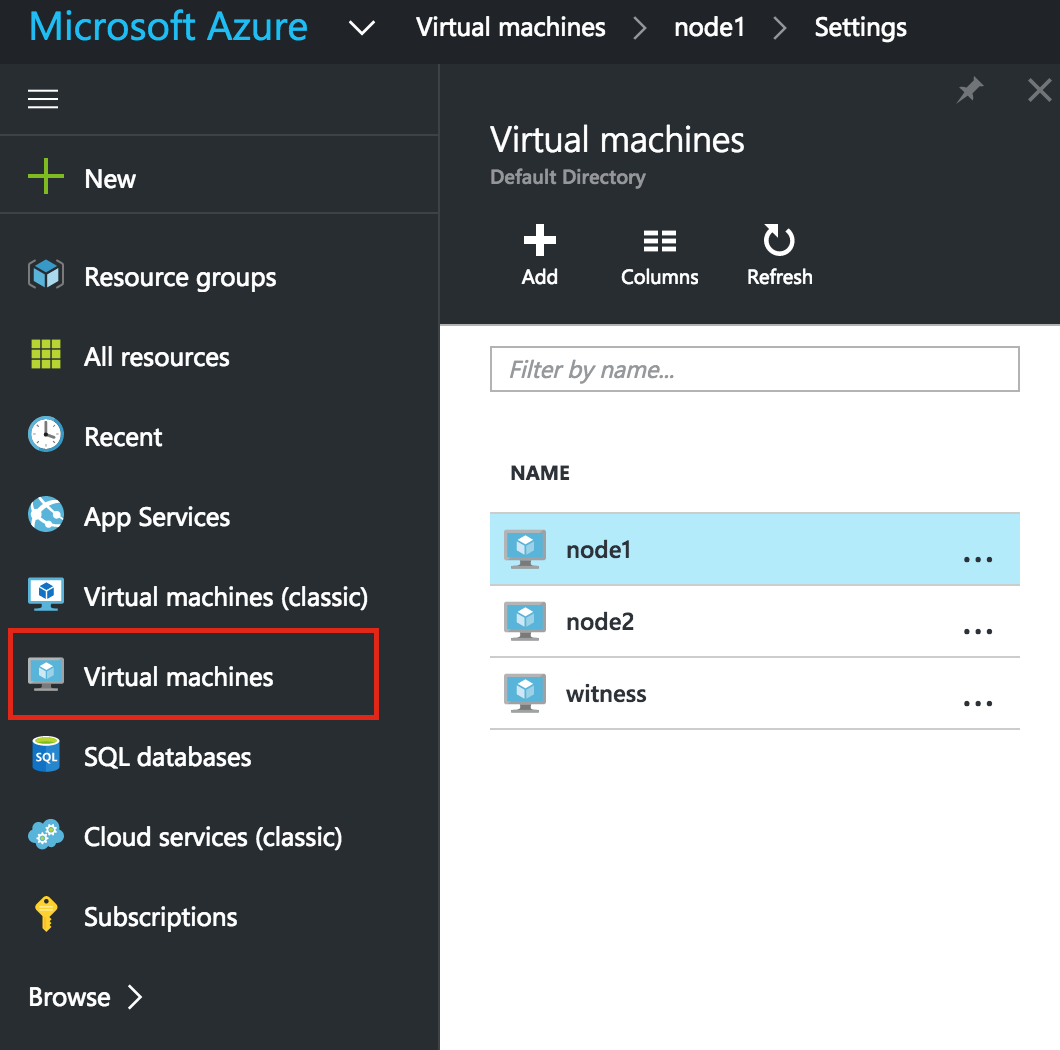
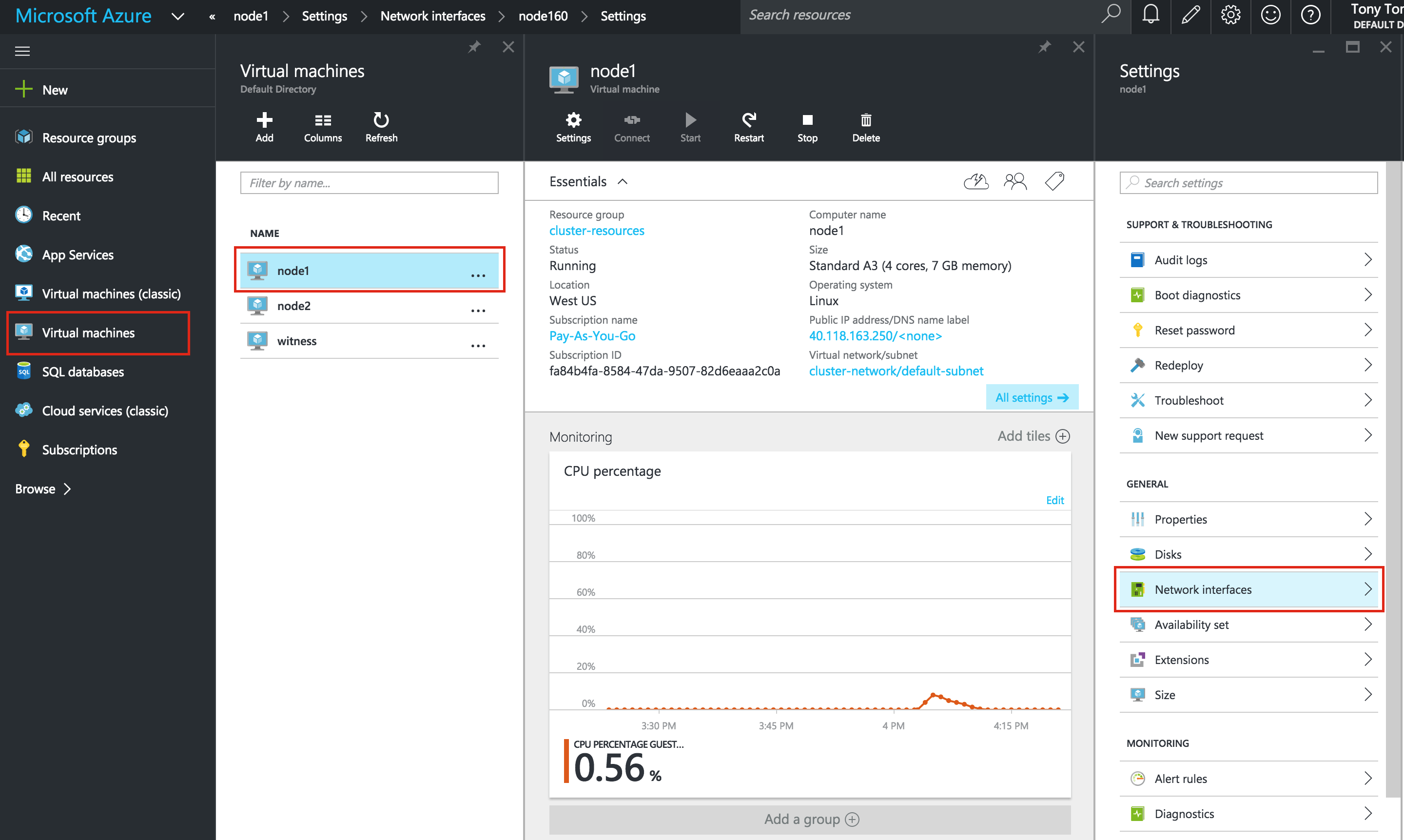
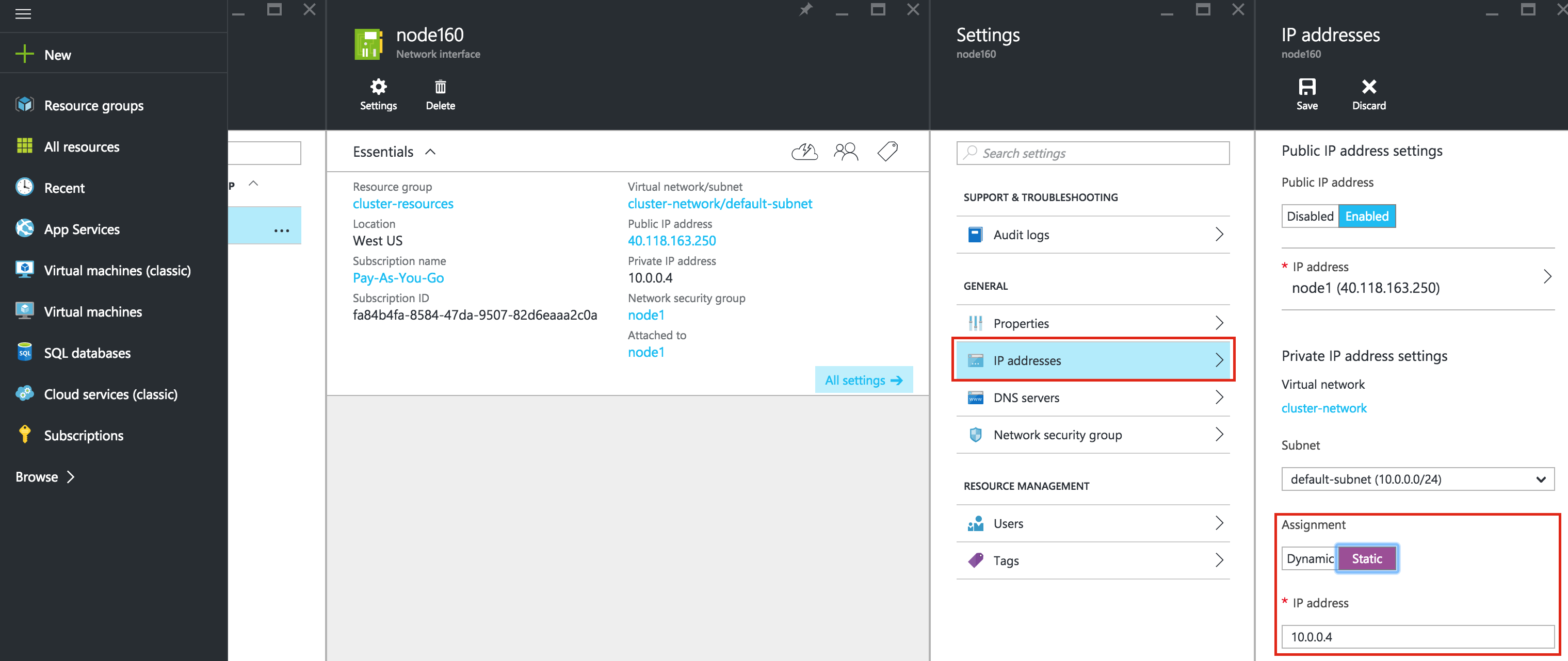
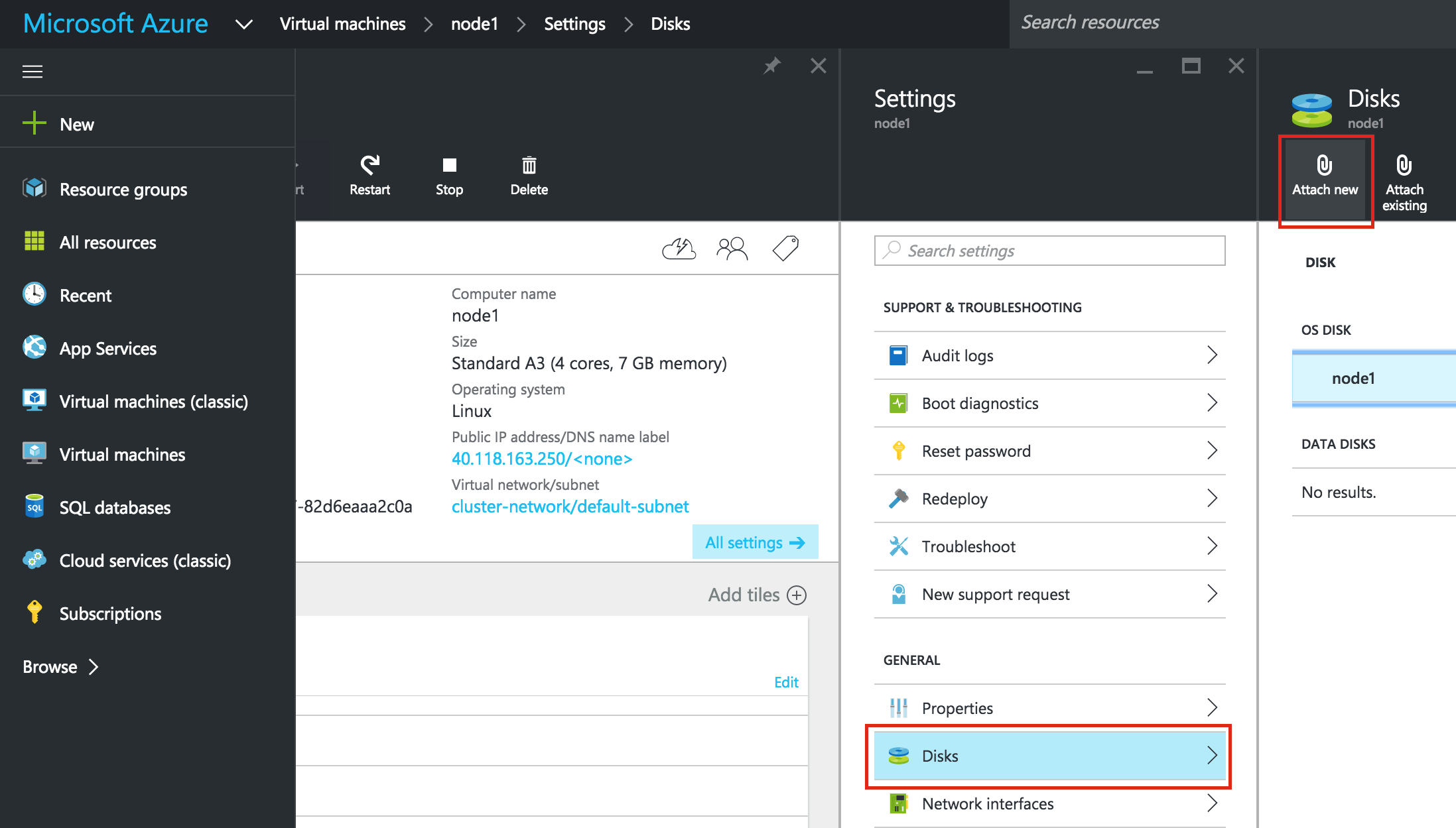
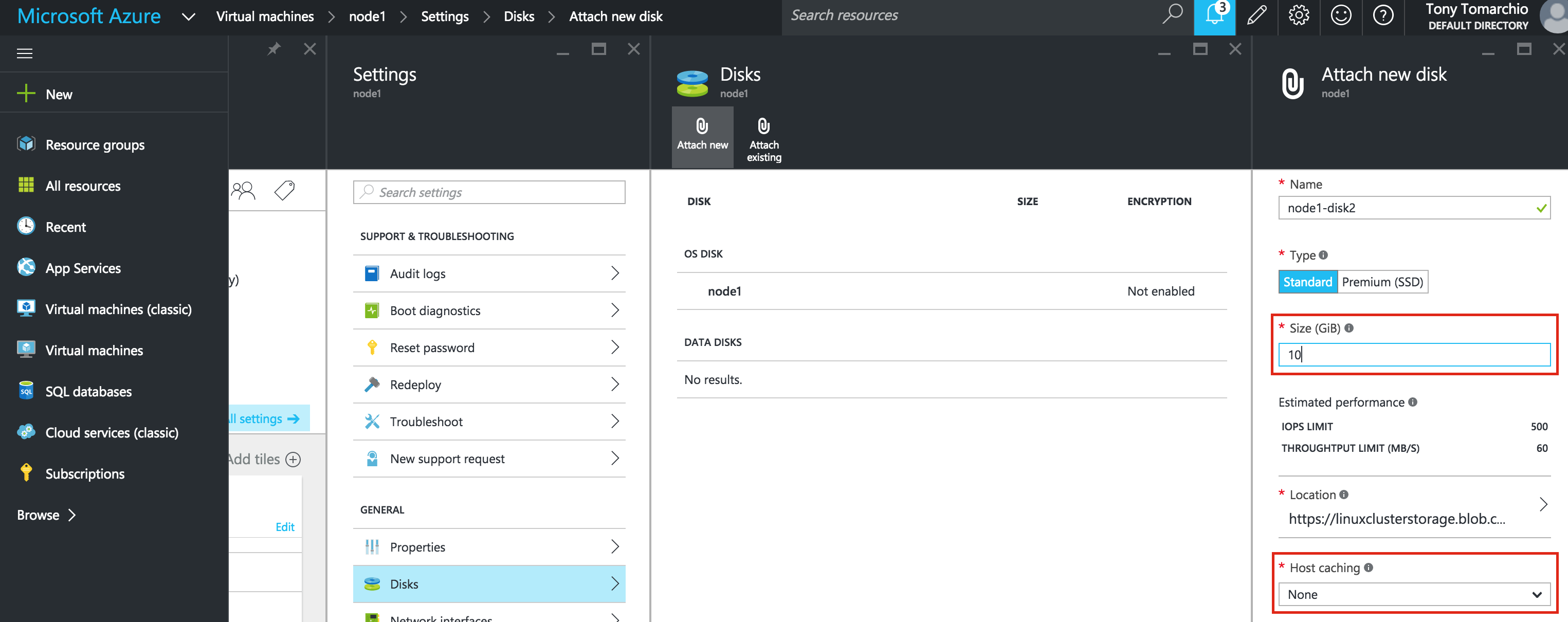
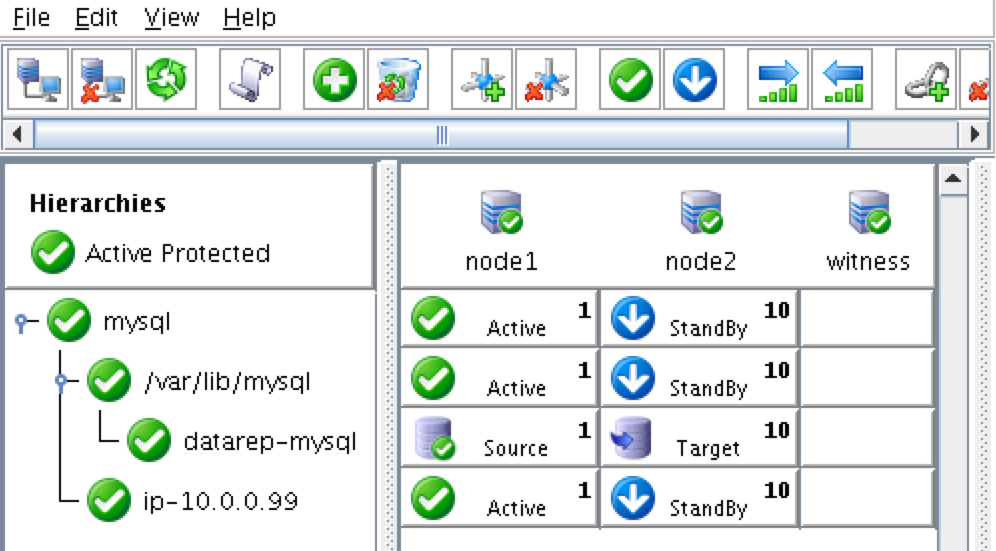
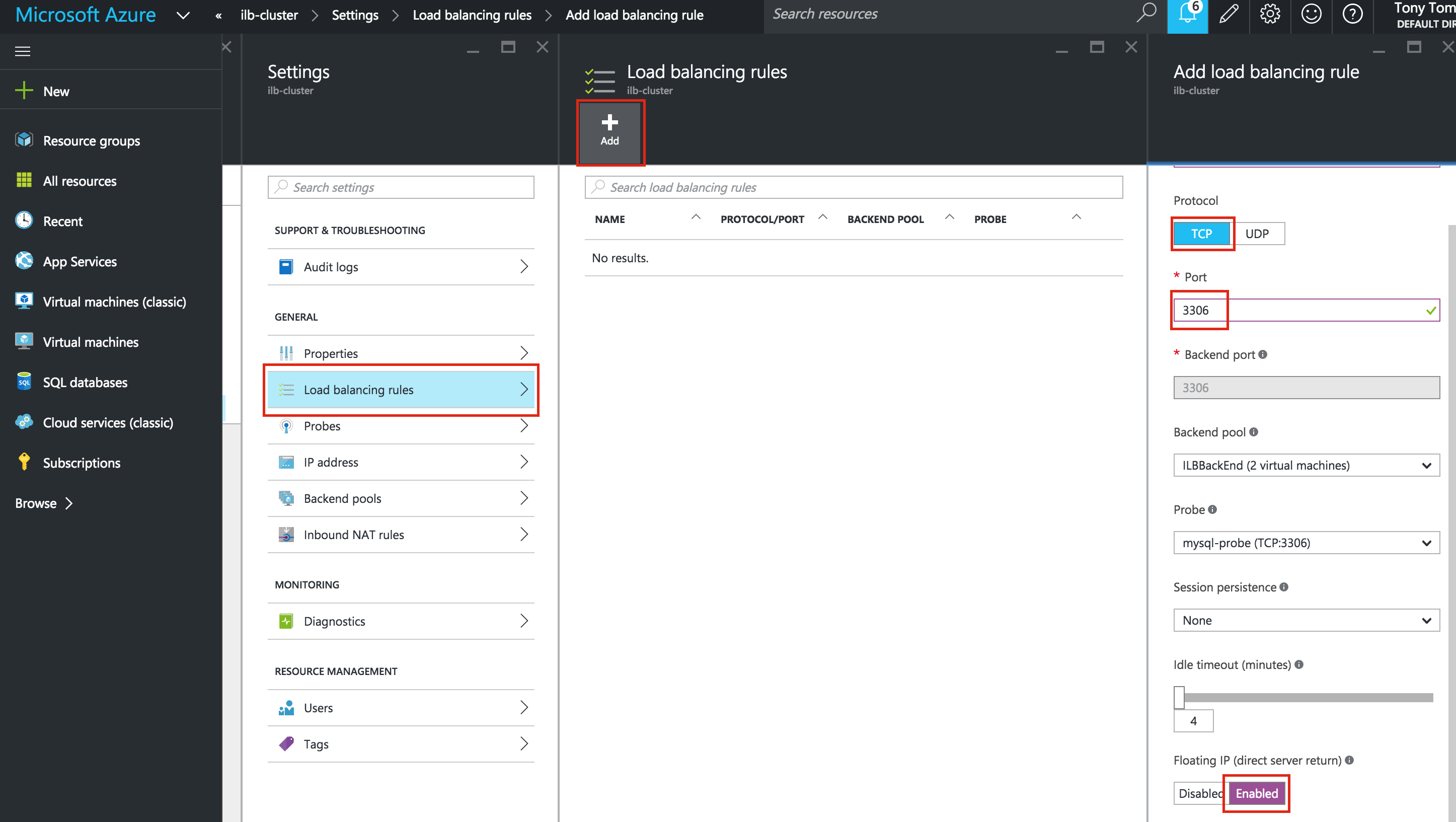
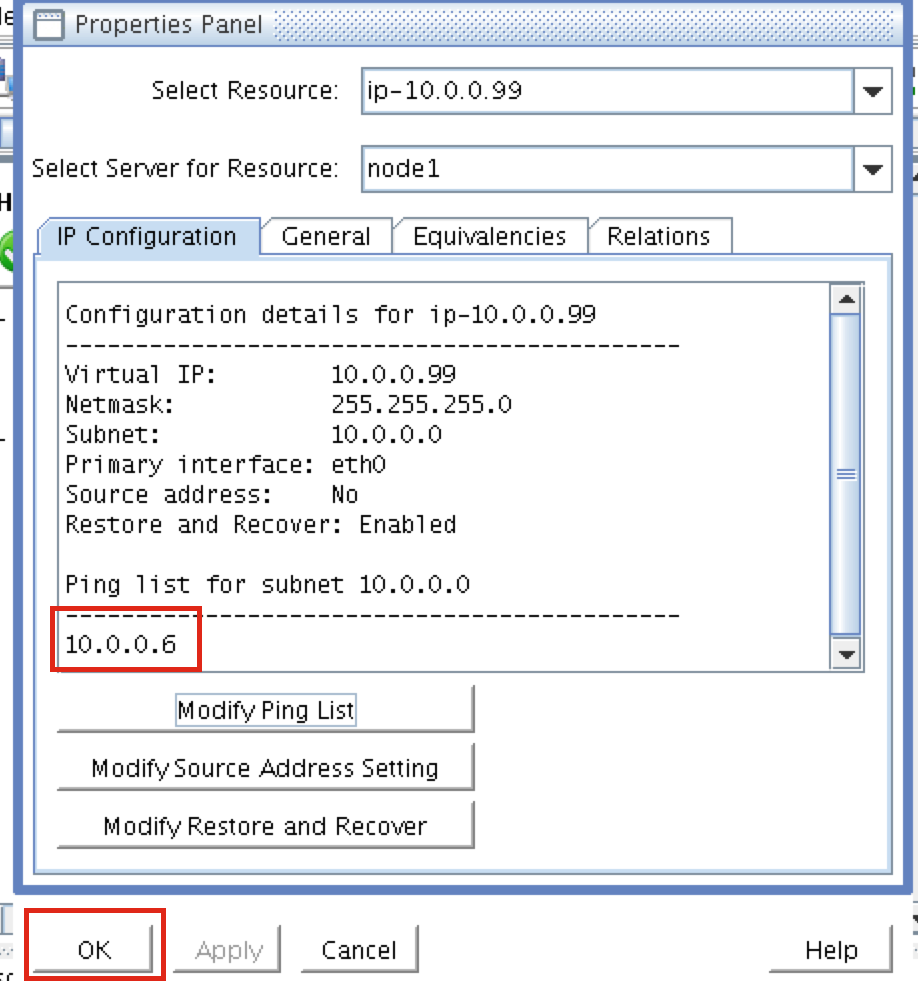
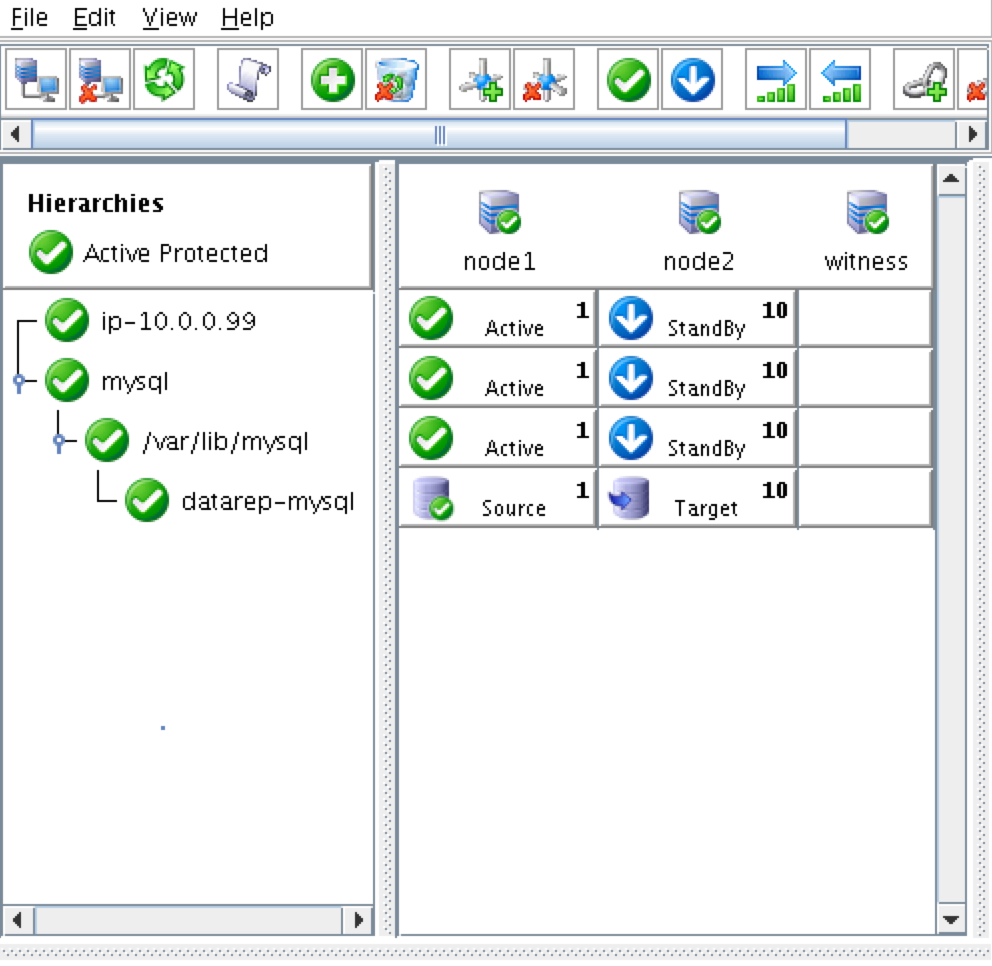
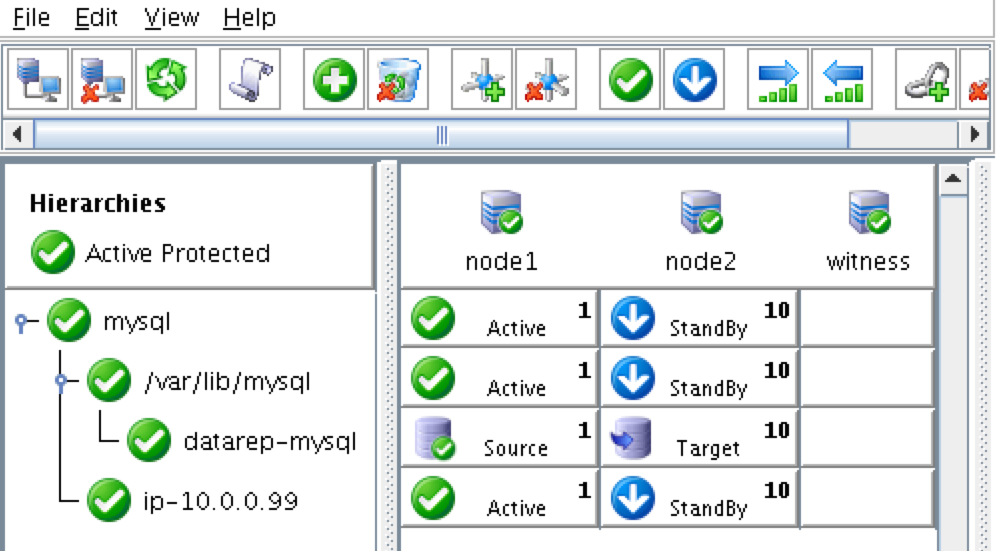
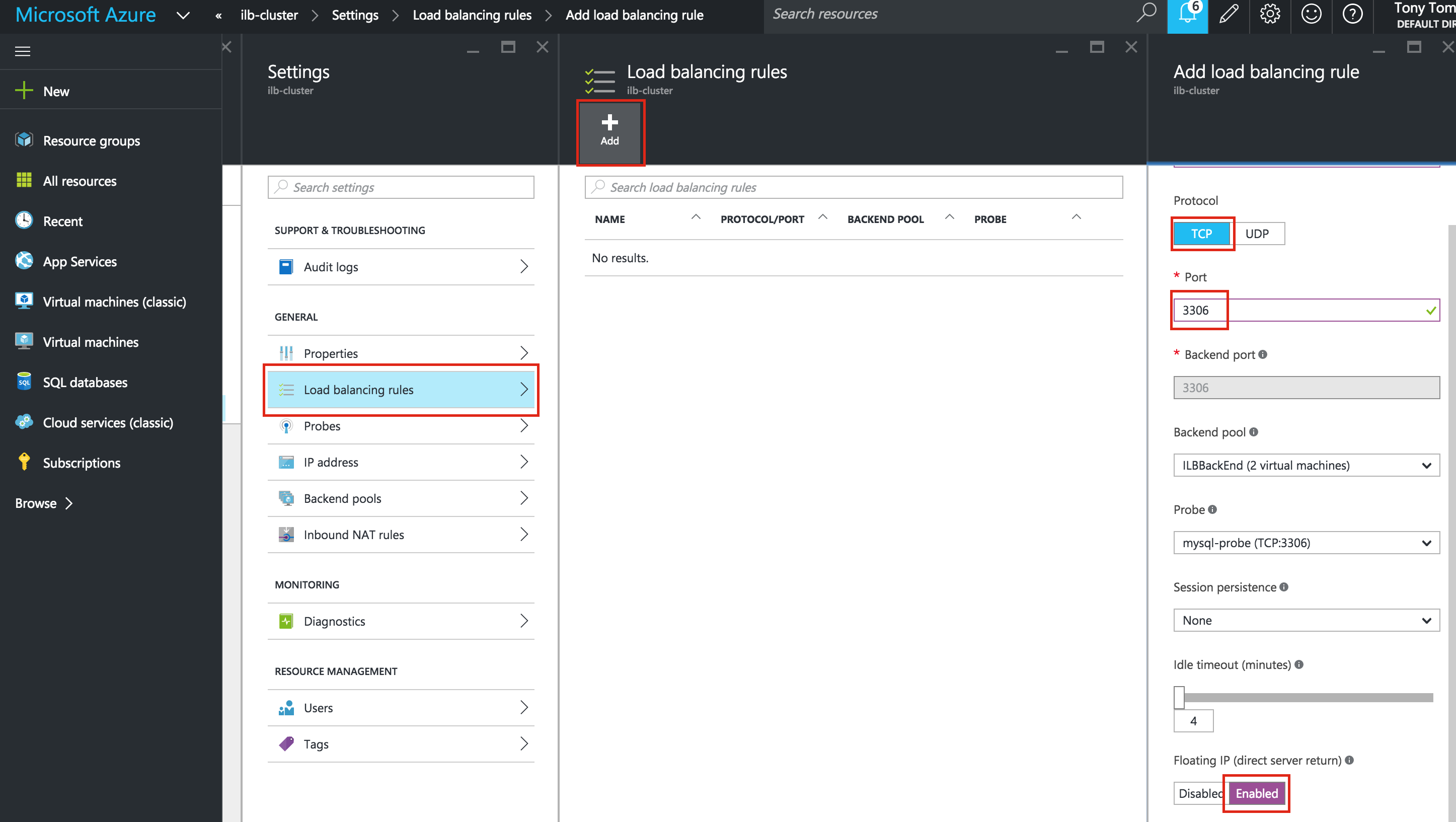
SQL Server for Linux – ตัวอย่างสาธารณะพร้อมใช้งานแล้ว
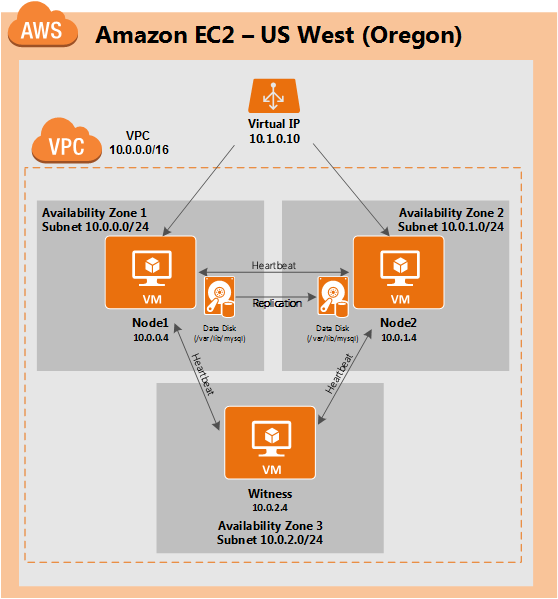
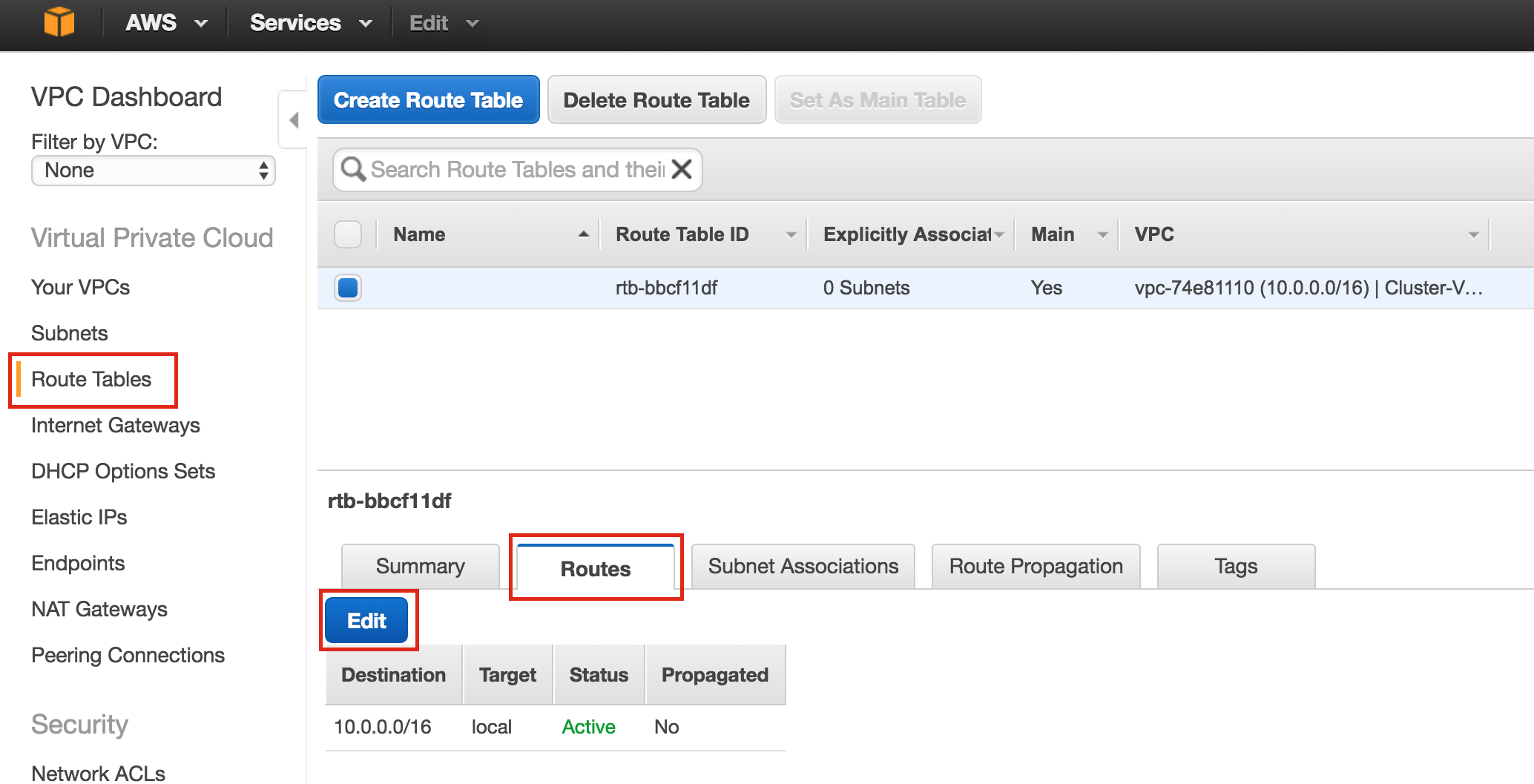
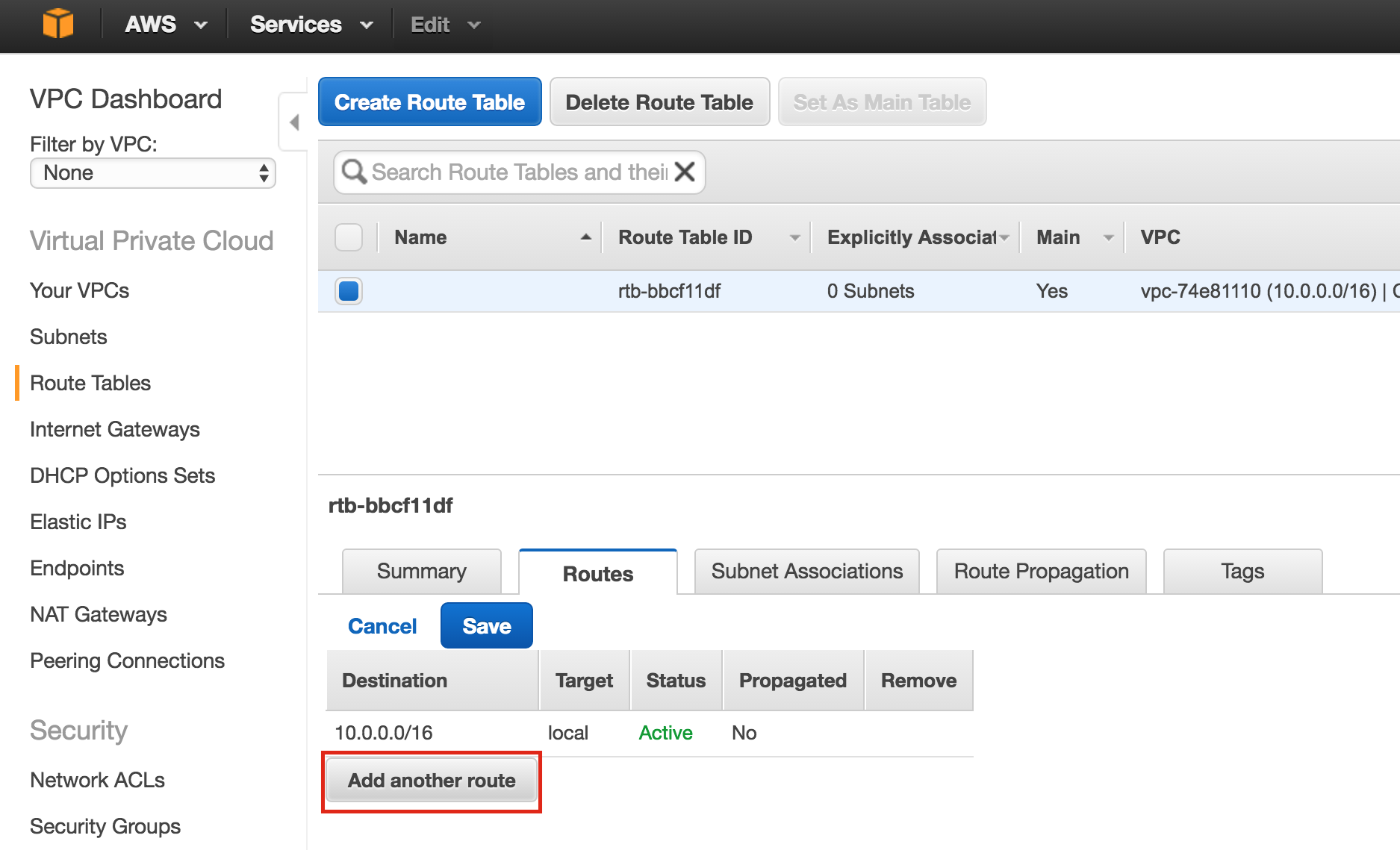
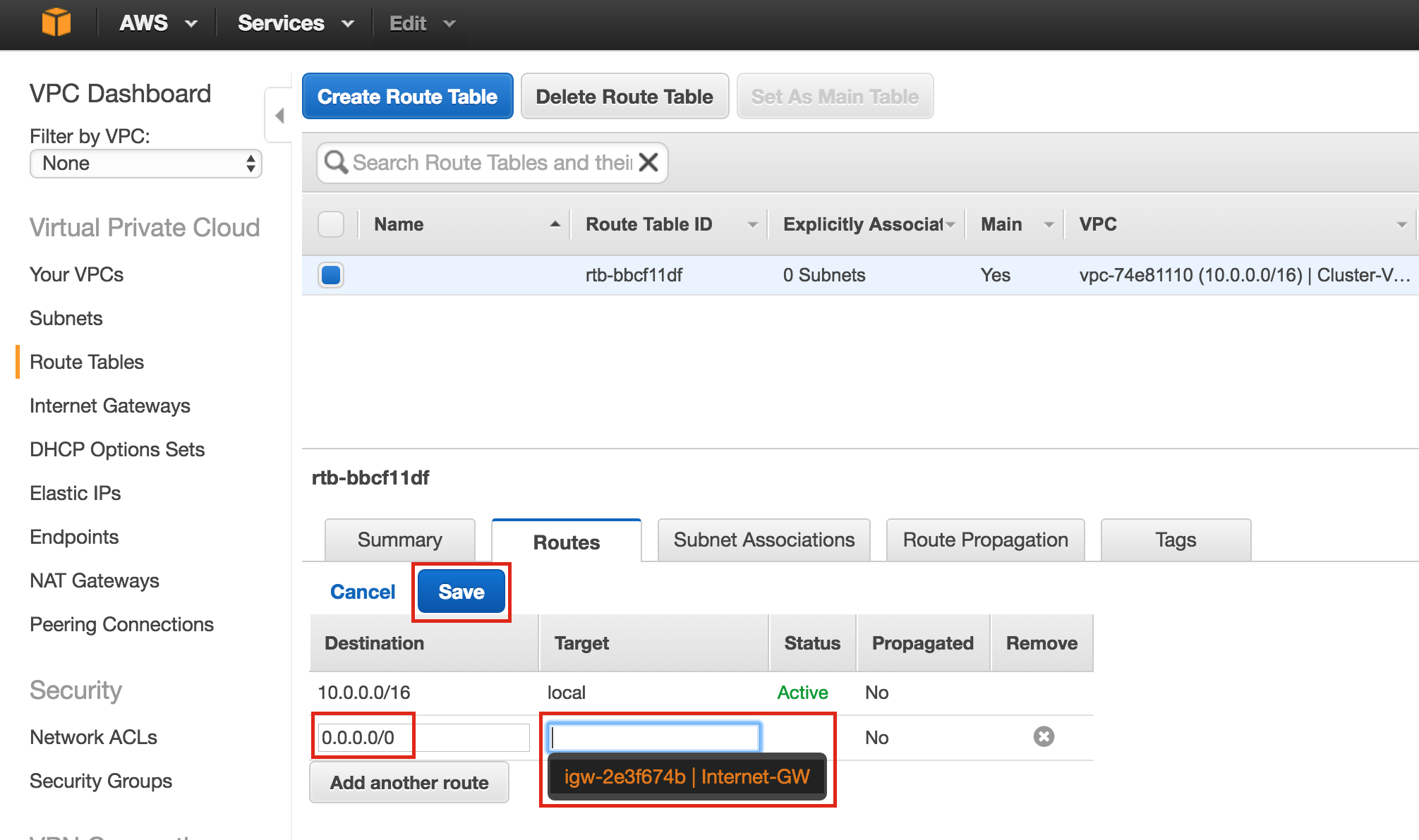
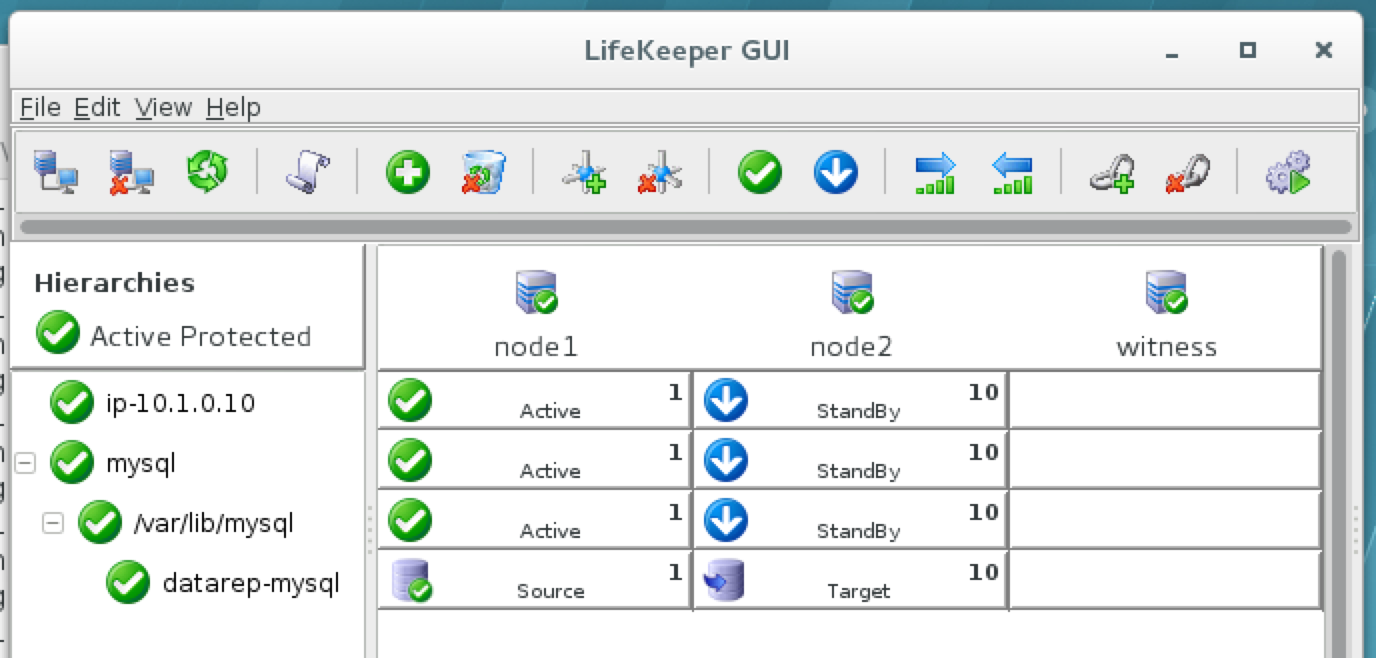
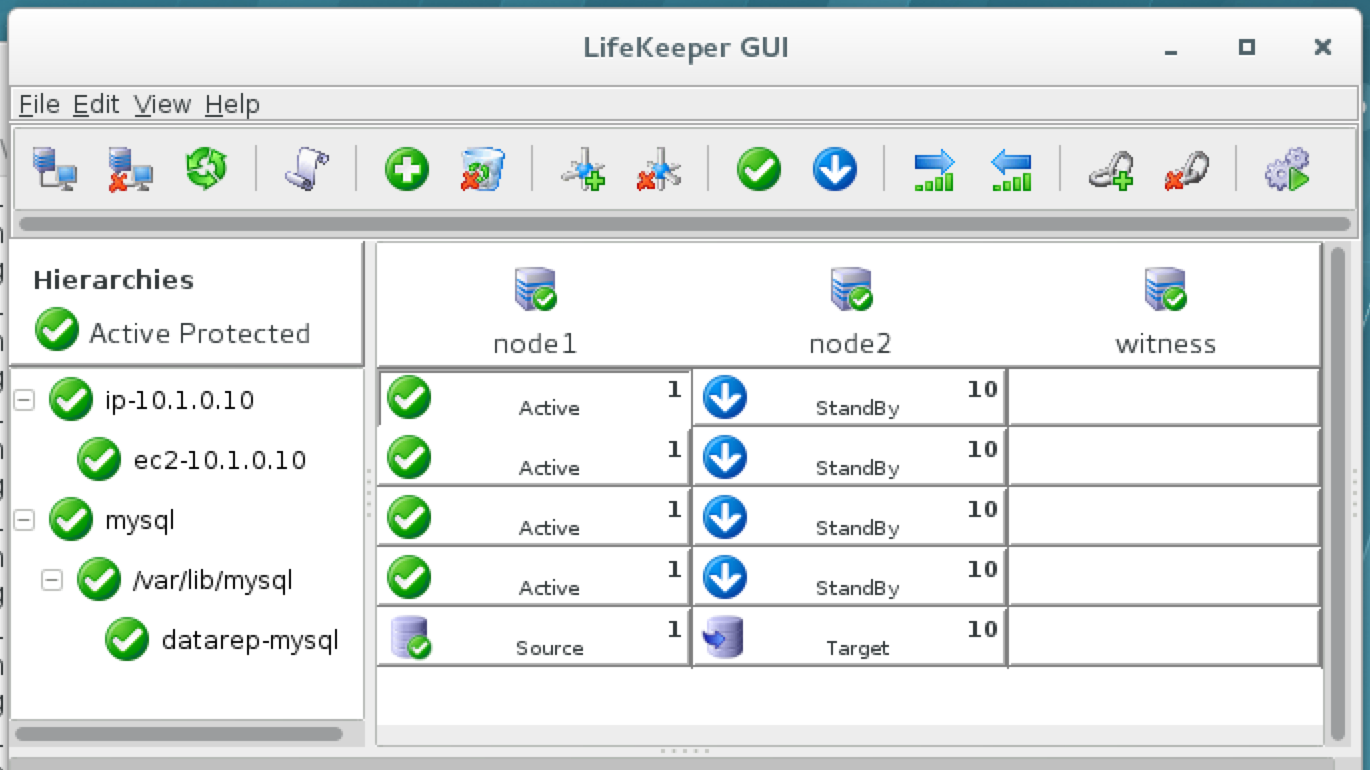
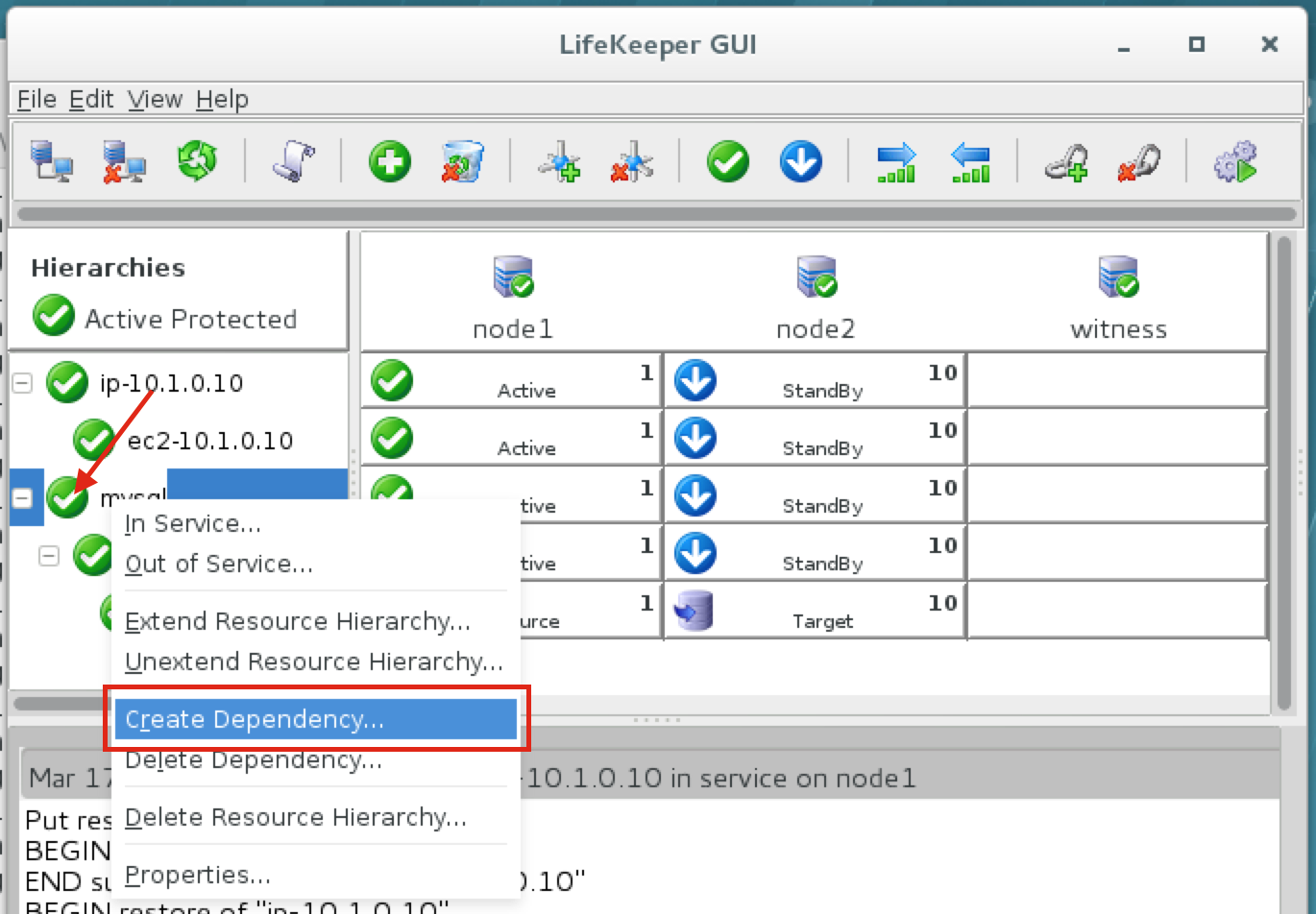
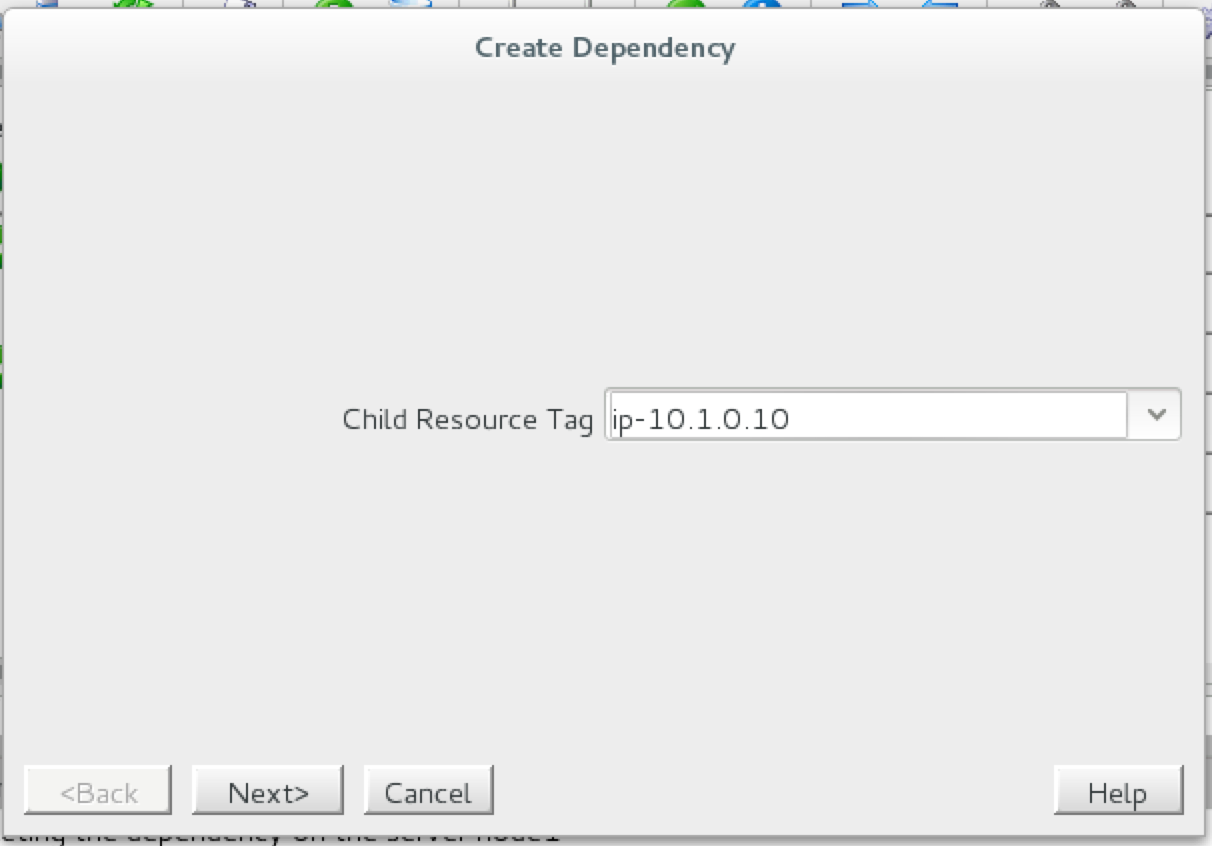
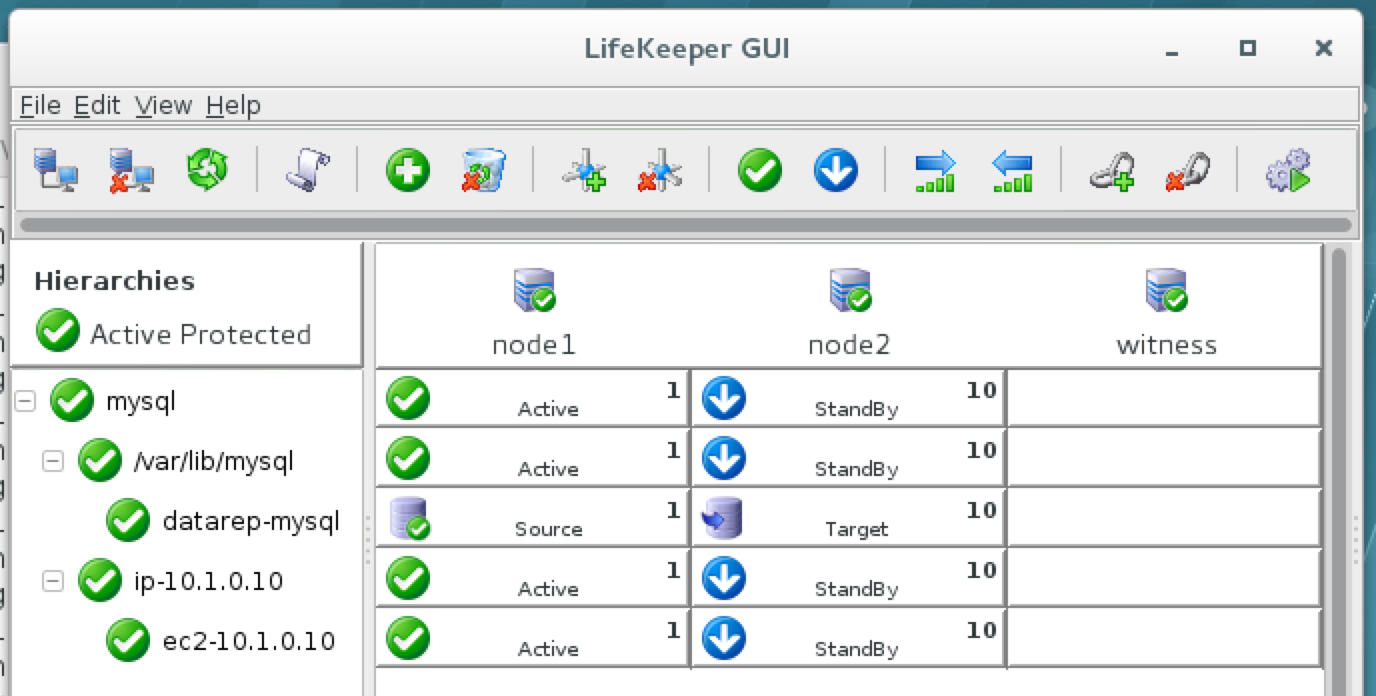
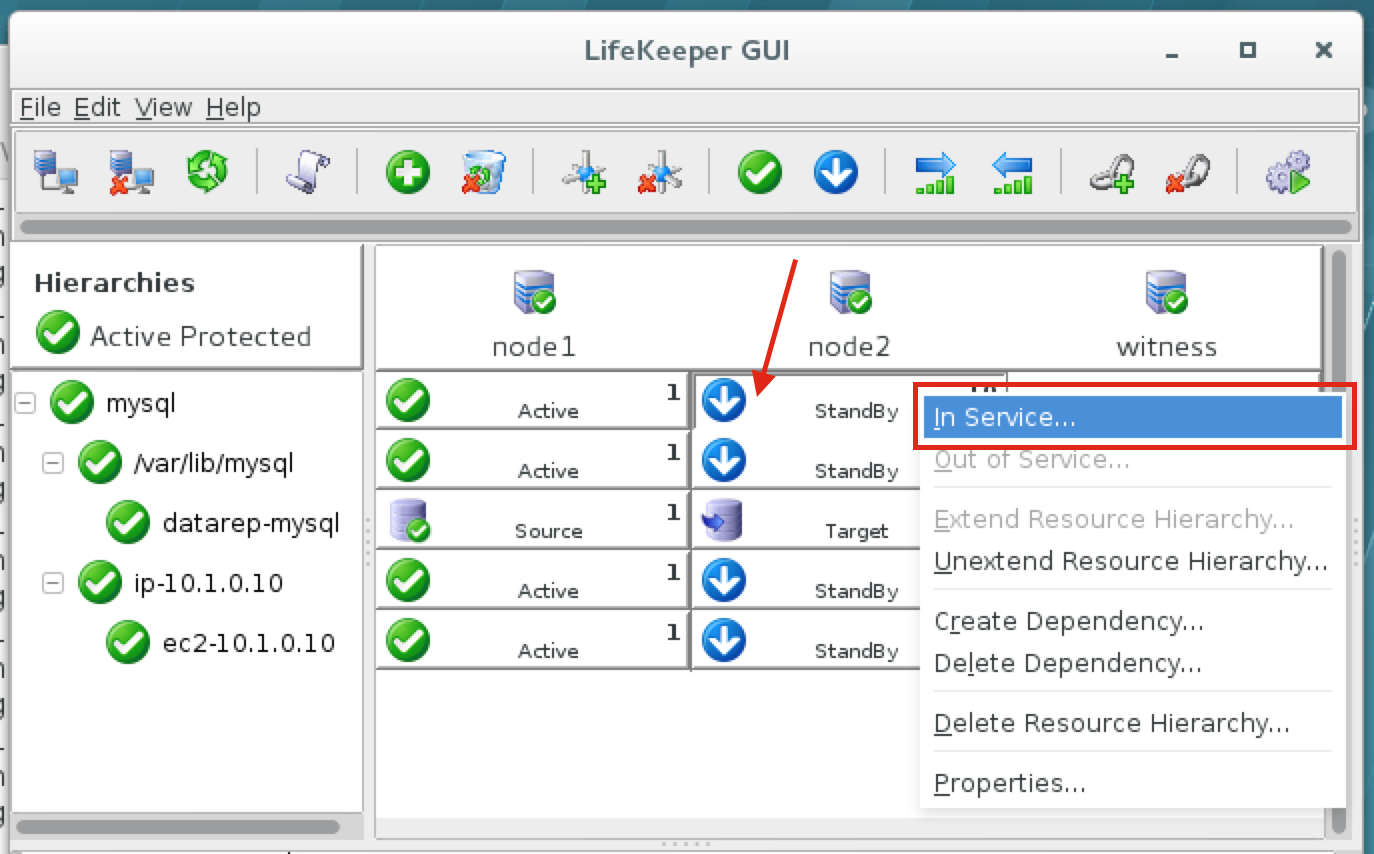
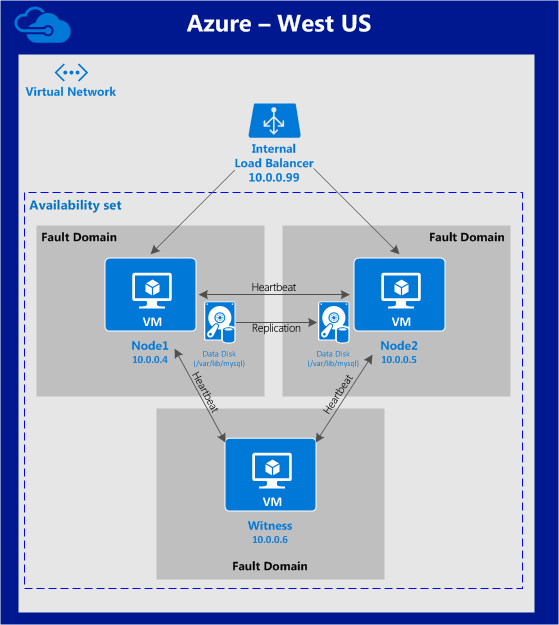
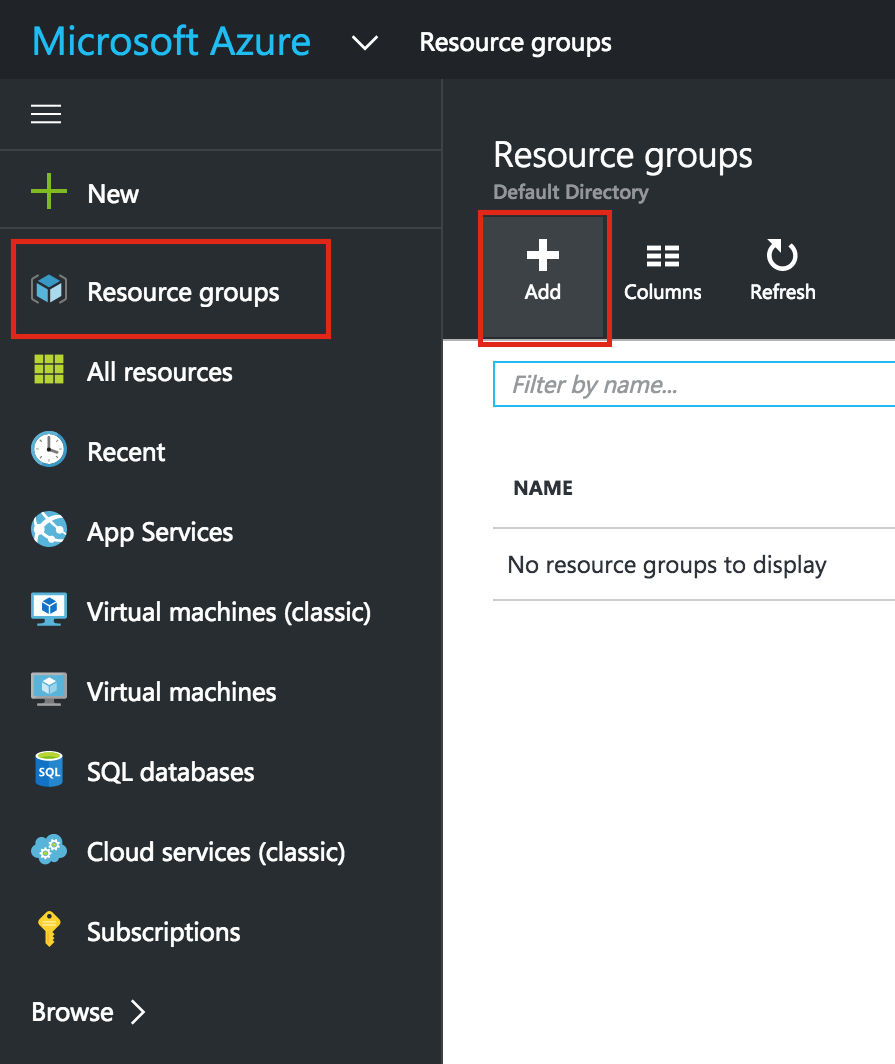
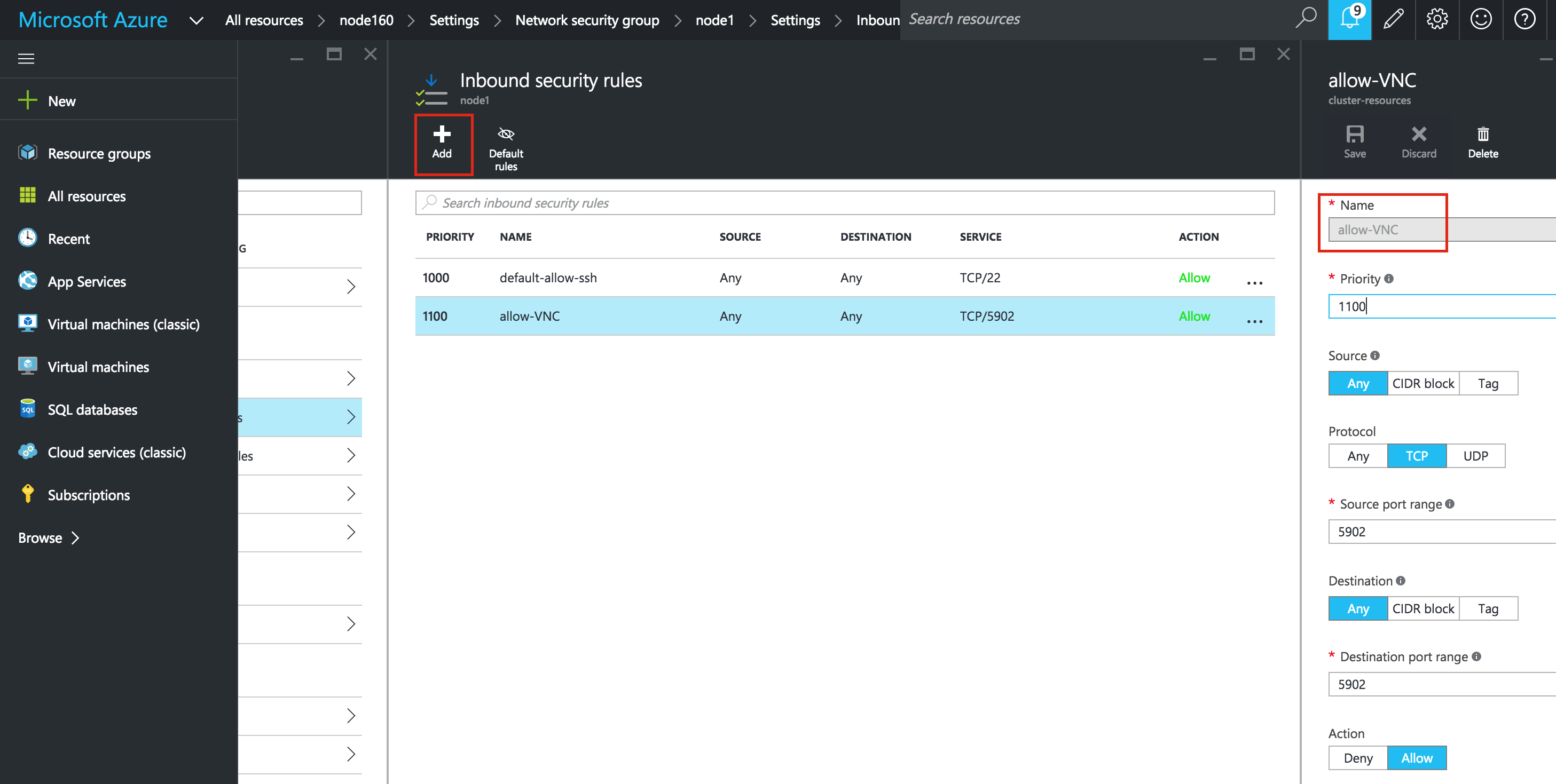
มีการดูตัวอย่างสาธารณะสำหรับ SQL Server v.Next ในขณะนี้แล้ว Microsoft ได้เพิ่มการสนับสนุนลีนุกซ์แล้ว ดูลิงก์ด้านล่างสำหรับข้อมูลเพิ่มเติม ฉันจะดาวน์โหลดและมองหาคุณลักษณะการมีอยู่สูงในไม่ช้า คอยติดตาม!
SQL Server v.Next Public Preview: https://www.microsoft.com/en-us/sql-server/sql-server-vnext-including-Linux ข้อความประกาศ SQL Server Linux ต้นฉบับ: https://blogs.microsoft.com / blog / 2016/03/07 / announcing-sql-server-on-linux / ทำซ้ำได้รับอนุญาตจาก Linuxclustering