Date: มกราคม 29, 2022

ลดการหยุดทำงานด้วยความพร้อมใช้งานสูง
เวลาหยุดทำงานมีราคาแพงกว่าที่เคยเป็นมาสำหรับธุรกิจสมัยใหม่ การสำรวจค่าใช้จ่ายรายชั่วโมงของการหยุดทำงานของ ITIC 2021 พบว่า 91% ขององค์กร การหยุดทำงานหนึ่งชั่วโมงในระบบ ฐานข้อมูล หรือแอปพลิเคชันที่สำคัญต่อธุรกิจมีค่าใช้จ่ายเฉลี่ยมากกว่า 300,000 ดอลลาร์ และสำหรับองค์กรขนาดใหญ่ 18% ต้นทุนของ เวลาหยุดทำงานหนึ่งชั่วโมงเกิน 5 ล้านเหรียญ
ความพร้อมใช้งานสูง (HA) เป็นคุณลักษณะของระบบ ฐานข้อมูล หรือแอปพลิเคชันที่ออกแบบมาให้ทำงานอย่างต่อเนื่องและเชื่อถือได้เป็นระยะเวลานาน เป้าหมายของ HA คือการลดหรือขจัดการหยุดทำงานโดยไม่ได้วางแผนไว้สำหรับแอปพลิเคชันที่สำคัญ ซึ่งทำได้โดยการกำจัดจุดล้มเหลวเพียงจุดเดียวด้วยการผสมผสานส่วนประกอบที่ซ้ำซ้อนและเทคโนโลยีอื่นๆ เข้ากับการออกแบบระบบ ฐานข้อมูล หรือแอปพลิเคชันที่มีความสำคัญต่อธุรกิจ
ตัวชี้วัด SLA และ HA
ข้อตกลงระดับบริการ (SLA) ถูกใช้โดยผู้ให้บริการเพื่อรับประกันว่าระบบ ฐานข้อมูล หรือแอปพลิเคชันที่มีความสำคัญต่อธุรกิจของลูกค้าจะพร้อมใช้งานเมื่อธุรกิจต้องการ
IDC ได้สร้างแบบจำลอง SLA ที่กำหนดความต้องการเวลาทำงานที่ห้าระดับดังนี้:
- AL4 (ความพร้อมใช้งานอย่างต่อเนื่อง – ความคลาดเคลื่อนของระบบ): ไม่เกิน 5 นาที 15 วินาทีของการหยุดทำงานตามแผนและโดยไม่ได้วางแผนต่อปี (ความพร้อมใช้งาน 99.999% หรือ "ห้าเก้า")
- AL3 (ความพร้อมใช้งานสูง – การทำคลัสเตอร์แบบดั้งเดิม): ไม่เกิน 52 นาที 35 วินาทีของการหยุดทำงานตามแผนและโดยไม่ได้วางแผนต่อปี (ความพร้อมใช้งาน 99.99% หรือ "สี่เก้า")
- AL2 (การกู้คืน – การจำลองและสำรองข้อมูล): ไม่เกิน 8 ชั่วโมง 45 นาทีและ 56 วินาทีของการหยุดทำงานตามแผนและไม่ได้วางแผนต่อปี (ความพร้อมใช้งาน 99.9% หรือ "สามเก้า")
- AL1 (ความน่าเชื่อถือ – ส่วนประกอบแบบถอดเปลี่ยนได้): ไม่เกิน 87 ชั่วโมง 39 นาทีและ 29 วินาทีของการหยุดทำงานตามแผนและไม่ได้วางแผนต่อปี (ความพร้อมใช้งาน 99% หรือ "สองเก้า")
- AL0 (เซิร์ฟเวอร์ที่ไม่มีการป้องกัน): ไม่มีการรับประกันความพร้อมใช้งานหรือเวลาทำงาน
จากข้อมูลของ ITIC 89% ขององค์กรที่ทำการสำรวจต้องการความพร้อมใช้งาน "สี่เก้า" สำหรับระบบ ฐานข้อมูล และแอปพลิเคชันที่มีความสำคัญต่อธุรกิจของพวกเขา และ 35% ขององค์กรเหล่านั้นพยายามที่จะบรรลุความพร้อมใช้งาน "ห้าเก้า"
นอกจากเวลาทำงานและความพร้อมใช้งานแล้ว ตัวชี้วัด HA ที่สำคัญอีกสองรายการคือ วัตถุประสงค์เวลาพักฟื้น (RTO) และ วัตถุประสงค์ของจุดพักฟื้น (RPO) RTO คือระยะเวลาสูงสุดที่ยอมรับได้ของการหยุดทำงาน และ RPO คือจำนวนการสูญเสียข้อมูลสูงสุดที่สามารถยอมรับได้เมื่อเกิดความล้มเหลวขึ้น ไม่เหมือนกับตัววัด RTO และ RPO สำหรับการกู้คืนจากความเสียหายซึ่งโดยทั่วไปกำหนดไว้เป็นชั่วโมงและวัน ตัววัด RTO และ RPO สำหรับระบบ ฐานข้อมูล และแอปพลิเคชันที่มีความสำคัญต่อธุรกิจมักใช้เวลาเพียงไม่กี่วินาที (RTO) และศูนย์ (RPO)
HA คลัสเตอร์
การทำคลัสเตอร์ HA โดยทั่วไปประกอบด้วยโหนดเซิร์ฟเวอร์ ที่เก็บข้อมูล และซอฟต์แวร์การทำคลัสเตอร์
การจัดกลุ่มแบบดั้งเดิม
คลัสเตอร์ HA ภายในองค์กรแบบดั้งเดิมคือกลุ่มของโหนดเซิร์ฟเวอร์ตั้งแต่สองโหนดขึ้นไปที่เชื่อมต่อกับที่เก็บข้อมูลที่ใช้ร่วมกัน (โดยทั่วไปคือ เครือข่ายพื้นที่จัดเก็บ หรือ SAN) ที่ได้รับการกำหนดค่าด้วยระบบปฏิบัติการ ฐานข้อมูล และแอปพลิเคชันเดียวกัน (ดู รูปที่ 1 ).
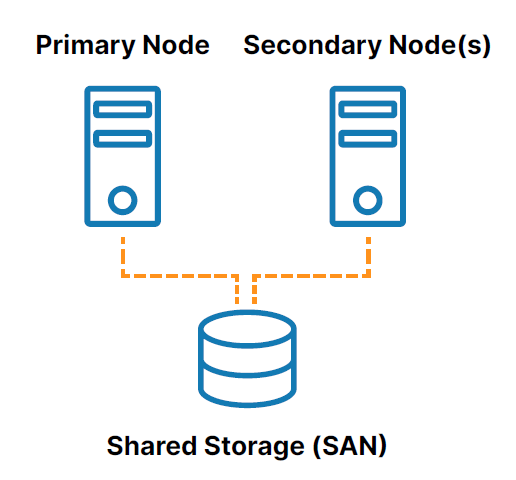
โหนดหนึ่งถูกกำหนดให้เป็นโหนดหลัก (หรือแอ็คทีฟ) และโหนดอื่น ๆ ถูกกำหนดให้เป็นโหนดรอง (หรือสแตนด์บาย) หากโหนดหลักล้มเหลว การทำคลัสเตอร์จะช่วยให้ระบบ ฐานข้อมูล หรือแอปพลิเคชันสามารถข้ามไปยังโหนดรองอย่างน้อยหนึ่งโหนดได้โดยอัตโนมัติ และทำงานต่อไปโดยมีการหยุดชะงักน้อยที่สุด เนื่องจากโหนดรองเชื่อมต่อกับที่เก็บข้อมูลเดียวกัน การดำเนินการจึงดำเนินต่อไปโดยที่ข้อมูลสูญหายเป็นศูนย์
อย่างไรก็ตาม การใช้พื้นที่จัดเก็บแบบแบ่งใช้ในรูปแบบการทำคลัสเตอร์แบบเดิมสร้างความท้าทายหลายประการ ได้แก่:
- ที่เก็บข้อมูลแบบแบ่งใช้เป็นจุดความล้มเหลวเพียงจุดเดียวที่อาจทำให้โหนดที่เชื่อมต่อทั้งหมดในคลัสเตอร์ออฟไลน์ได้
- พื้นที่จัดเก็บ SAN อาจมีราคาแพงและซับซ้อนในการเป็นเจ้าของและจัดการ
- การจัดเก็บข้อมูลที่ใช้ร่วมกันในระบบคลาวด์สามารถเพิ่มค่าใช้จ่ายและความซับซ้อนที่ไม่จำเป็นได้อย่างมาก และผู้ให้บริการระบบคลาวด์บางรายไม่ได้เสนอตัวเลือกพื้นที่จัดเก็บข้อมูลที่ใช้ร่วมกัน
การทำคลัสเตอร์แบบไม่ใช้ SAN
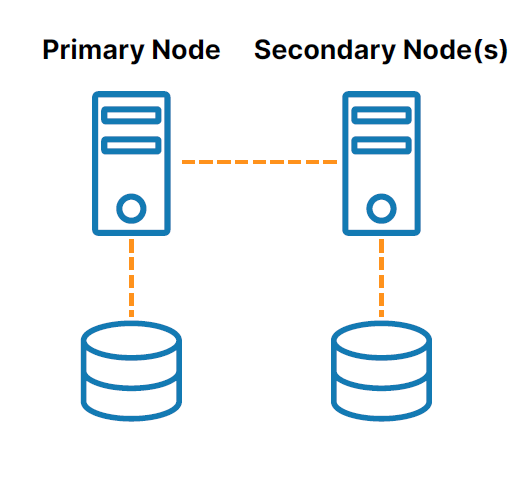
SANless หรือคลัสเตอร์ "ไม่แชร์อะไร" (ดู รูปที่ 2 ) จัดการกับความท้าทายที่เกี่ยวข้องกับการจัดเก็บข้อมูลที่ใช้ร่วมกัน ในการกำหนดค่าเหล่านี้ ทุกโหนดคลัสเตอร์มีที่เก็บข้อมูลในเครื่องของตัวเอง การจำลองแบบระดับบล็อกตามโฮสต์ที่มีประสิทธิภาพใช้เพื่อซิงโครไนซ์หน่วยเก็บข้อมูลบนโหนดคลัสเตอร์ โดยคงไว้ซึ่งความเหมือนกัน ในกรณีเกิดเฟลโอเวอร์ โหนดรองจะเข้าถึงสำเนาที่เหมือนกันของหน่วยเก็บข้อมูลที่ใช้โดยโหนดหลัก
ซอฟต์แวร์คลัสเตอร์
ซอฟต์แวร์การทำคลัสเตอร์ช่วยให้คุณกำหนดค่าเซิร์ฟเวอร์ของคุณเป็นคลัสเตอร์เพื่อให้เซิร์ฟเวอร์หลายเครื่องสามารถทำงานร่วมกันเพื่อจัดหา HA และป้องกันการสูญหายของข้อมูล โซลูชันซอฟต์แวร์การทำคลัสเตอร์ที่หลากหลายพร้อมใช้งานสำหรับ Windows, Linux distribution และ virtual machine hypervisors ต่างๆ อย่างไรก็ตาม โซลูชันแต่ละอย่างจำกัดความยืดหยุ่นและตัวเลือกการปรับใช้ของคุณ และนำเสนอความท้าทายต่างๆ เช่น ความซับซ้อนทางเทคนิคและการให้สิทธิ์ใช้งานที่มีราคาแพง
อย่ารอให้เกิดภัยพิบัติ
HA มีความสำคัญต่อระบบ ฐานข้อมูล และแอปพลิเคชันที่มีความสำคัญต่อธุรกิจ แต่ด้วยแพลตฟอร์มที่มีอยู่มากมาย ความซับซ้อนก็เพิ่มขึ้นอย่างมาก นั่นเป็นเหตุผลที่โซลูชันที่รับรู้แอปพลิเคชันนั้นสมเหตุสมผลมาก สิ่งที่คุณต้องการคือพันธมิตรที่เชื่อถือได้ซึ่งมีความเชี่ยวชาญอย่างกว้างขวางในด้านความพร้อมใช้งานสูง—พันธมิตรเช่น SIOS ซึ่งมีความรู้ทางเทคโนโลยีเพื่อให้แน่ใจว่าธุรกิจของคุณจะดำเนินต่อไป
อย่ารอให้ไฟดับหรือภัยพิบัติเพื่อดูว่าคุณมีความยืดหยุ่นที่ธุรกิจของคุณต้องการหรือไม่ กำหนดเวลาการสาธิตส่วนบุคคลวันนี้ที่ https://us.sios.com เพื่อดูว่า SIOS สามารถทำอะไรกับธุรกิจของคุณได้บ้าง
สืบพันธุ์จาก SIOS