ดูคุณลักษณะใหม่ของ Hyper-V Replica
นี่คือวิดีโอที่น่าสนใจซึ่งแสดงให้เห็นถึง "Hyper-V Replica" ซึ่งเป็นคุณลักษณะใหม่ที่มาใน Windows เวอร์ชันถัดไป ข้ามไปที่ป้ายบอกเวลา 39 นาทีเพื่อดูการสาธิต
http://digitalwpc.com/Videos/AllVideos/Permalink/3cb3788c-5c47-4b9e-987c-0dec4194058b/#fbid=slfi0dmNMqP
ดูเหมือนว่าคุณลักษณะที่น่ายินดีอย่างยิ่งที่จะทำให้ Hyper-V สามารถแข่งขันได้มากกว่าเมื่อเทียบกับชุดคุณลักษณะเทียบกับราคาระหว่าง vSphere และ Hyper-V โดยเฉพาะอย่างยิ่งกับราคาใหม่ที่ประกาศโดย VMware
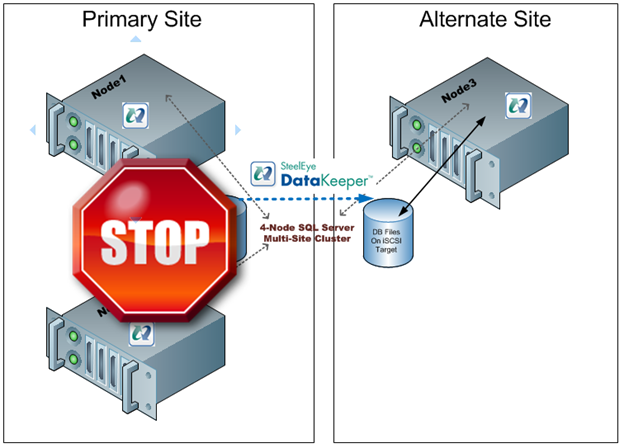
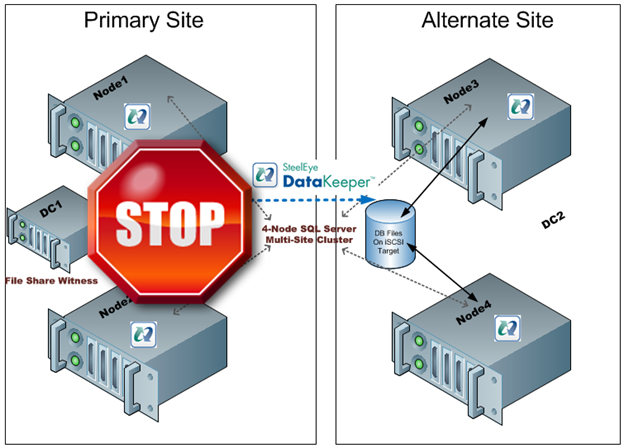
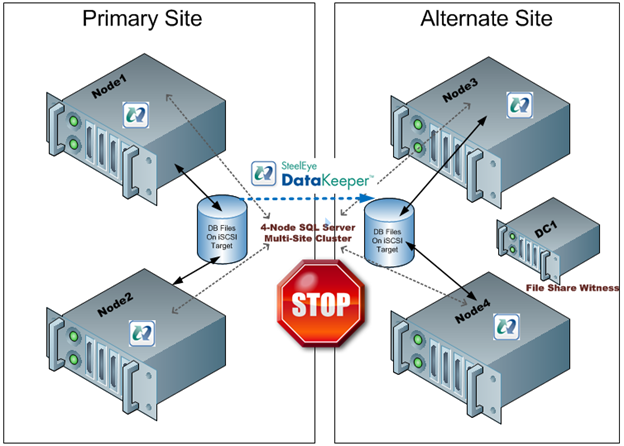
ฉันจะอยากรู้มากทีเดียวว่าการทำงานร่วมกับ Windows Server Failover Clustering เพื่อให้คุณสามารถสร้างกลุ่มที่ไม่มีการแชร์ได้เท่าที่คุณสามารถทำได้ในวันนี้ด้วยซอฟต์แวร์การจำลองแบบของ บริษัท อื่นซึ่งได้แสดงให้เห็นถึงการใช้ SteelEye DataKeeper Cluster Edition ในโพสต์บล็อกก่อนหน้านี้
ทำซ้ำโดยได้รับอนุญาตจาก https://clusteringformeremortals.com/2011/07/21/hyper-v-replica-coming-in-windows-server-%E2%80%9Cnext%E2%80%9D/