ความพร้อมใช้งานสูงแบบมัลติคลาวด์สำหรับแอปพลิเคชันที่สำคัญต่อธุรกิจ
การประมวลผลแบบคลาวด์แพร่หลายไปทั่วในช่วงทศวรรษที่ผ่านมา โดย 99% ขององค์กรใช้ระบบคลาวด์สาธารณะหรือส่วนตัวอย่างน้อยหนึ่งระบบตามรายงาน Flexera 2021 State of the Cloud ในขณะที่ AWS, Microsoft Azure และ GCP เป็นผู้ให้บริการคลาวด์สาธารณะสามอันดับแรกในปัจจุบัน หลายๆ องค์กร—ไม่ว่าจะโดยการออกแบบหรือโดยบังเอิญ—ได้นำกลยุทธ์มัลติคลาวด์มาใช้ ซึ่งช่วยให้พวกเขาสามารถเลือกบริการคลาวด์ใดที่น่าสนใจและเหมาะสมที่สุด ตามความต้องการทางธุรกิจเฉพาะของพวกเขา ตามรายงานของ Flexera 92% ขององค์กรในปัจจุบันมีกลยุทธ์มัลติคลาวด์และใช้คลาวด์สาธารณะเฉลี่ย 2.6 และ 2.7 ไพรเวทคลาวด์ ซึ่งรวมถึง Software-as-a-Service (SaaS), Platform-as-a-Service (PaaS) และข้อเสนอ Infrastructure-as-a-Service (IaaS)
มัลติคลาวด์คืออะไร?
มัลติคลาวด์เป็นเพียงสภาพแวดล้อมที่ประกอบด้วยคลาวด์สาธารณะและ/หรือไพรเวทคลาวด์ตั้งแต่ 2 ก้อนขึ้นไป (รวมถึง SaaS, PaaS และ IaaS) บริการที่แตกต่างกันในสภาพแวดล้อมแบบมัลติคลาวด์อาจทำงานร่วมกัน (ในกรณีนี้อาจเป็นคลาวด์แบบไฮบริด) หรืออาจไม่จำเป็นต้องทำงานร่วมกัน (โดยพื้นฐานแล้วทำงานเป็นไซโลคลาวด์แยกต่างหาก) โปรดจำไว้ว่า แม้ว่าไฮบริดคลาวด์ทั้งหมดจะเป็นมัลติคลาวด์ แต่มัลติคลาวด์ไม่ใช่ทั้งหมดที่เป็นไฮบริดคลาวด์
วิวัฒนาการ (และการยอมรับในวงกว้าง) ของมัลติคลาวด์เป็นกลยุทธ์
สภาพแวดล้อมแบบมัลติคลาวด์ประกอบด้วยการรวมกันของข้อเสนอคลาวด์สาธารณะหรือส่วนตัวอย่างน้อยสองรายการ รวมถึง SaaS, PaaS และ IaaS ดังนั้น กลยุทธ์มัลติคลาวด์ขององค์กรอาจประกอบด้วยปริมาณงานขององค์กรที่ทำงานบน Amazon Elastic Cloud Compute (EC2) และการใช้ Microsoft 365 สำหรับแอปพลิเคชันอีเมลและแบ็คออฟฟิศ หรือองค์กรอาจเชื่อมต่อฐานข้อมูลแบบกำหนดเองที่โฮสต์ในระบบคลาวด์ส่วนตัวกับ Salesforce ซึ่งเป็นข้อเสนอ SaaS บนคลาวด์สาธารณะ
สภาพแวดล้อมคลาวด์แบบไฮบริดประกอบด้วยการผสมผสานระหว่างสภาพแวดล้อมแบบ on-premises, private cloud และ public cloud ตามรายงานของ Flexera องค์กร 80% มีกลยุทธ์ไฮบริดคลาวด์ (ดูรูปที่ 4) สภาพแวดล้อมแบบมัลติคลาวด์มักพัฒนาขึ้นจากระบบไอทีเงา ซึ่งแผนกต่างๆ จัดหาบริการคลาวด์เพื่อตอบสนองความต้องการส่วนบุคคลโดยไม่จำเป็นต้องปรึกษาแผนกไอทีส่วนกลาง ตัวอย่างเช่น ทีมการตลาดของคุณอาจเริ่มใช้ Salesforce นานก่อนที่ฝ่าย IT จะปรับใช้ปริมาณงานแรกใน AWS ในขณะที่แผนกทรัพยากรบุคคลและการเงินของคุณยุ่งอยู่กับการเพิ่ม Workday และ Concur ให้กับแอปพลิเคชัน SaaS ที่องค์กรของคุณพึ่งพาอยู่ในขณะนี้ หรือบางทีคุณอาจมีทีมพัฒนาแอปพลิเคชันที่ทำงานในโครงการต่างๆ ทั่วโลก ทีมพัฒนาทีมหนึ่งอาจชอบ Azure DevOps ในขณะที่อีกทีมอาจชอบเครื่องมือโอเพ่นซอร์สใน AWS ดังนั้น กลยุทธ์มัลติคลาวด์ของคุณอาจพัฒนาขึ้นโดยบังเอิญเท่านั้น ซึ่งไม่จำเป็นต้องเป็นเรื่องเลวร้ายเสมอไป
แผนกต่างๆ ของคุณมีอำนาจในการเลือกโซลูชันที่ดีที่สุดเพื่อตอบสนองความต้องการของพวกเขา ในขณะที่ทีมพัฒนาแอปของคุณสามารถเพิ่มประสิทธิภาพการทำงานสูงสุดและลดเวลาในการทำงานสู่ตลาดในสภาพแวดล้อมการพัฒนาที่พวกเขาต้องการ
สภาพแวดล้อมแบบมัลติคลาวด์ยังพัฒนาไปตามการออกแบบ เช่น เนื่องจากข้อกำหนดด้านกฎระเบียบ การควบรวมกิจการ หรือการใช้กลยุทธ์ความพร้อมใช้งานสูงและการกู้คืนระบบ
ภาษาข้อบังคับอาจคลุมเครือและสับสน ตัวอย่างเช่น ระเบียบข้อบังคับของ Financial Conduct Authority (FCA) เกี่ยวกับการว่าจ้างไอทีจากภายนอกระบุว่าบริษัทต้องสามารถ "รู้ว่าพวกเขาจะเปลี่ยนไปใช้ผู้ให้บริการทางเลือกและรักษาความต่อเนื่องทางธุรกิจได้อย่างไร" ข้อความนี้บอกเป็นนัยว่าบริษัทที่ได้รับการควบคุมอย่างน้อยต้องวางแผนสำหรับสภาพแวดล้อมคลาวด์สำรองเป็นอย่างน้อย จากลักษณะที่ไม่ชอบความเสี่ยงของบริษัทที่มีการกำกับดูแลอย่างเข้มงวด ปัญหาประเภทนี้ทำให้หลายบริษัทหันมาใช้กลยุทธ์มัลติคลาวด์
การรวมระบบไอทีและการรวมศูนย์ข้อมูลและสภาพแวดล้อมคลาวด์หลังจากการควบรวมหรือซื้อกิจการเป็นความท้าทายที่สำคัญ มีหลายปัจจัยที่อาจทำให้ความท้าทายนี้ซับซ้อน รวมถึงสัญญาที่มีอยู่กับผู้ให้บริการระบบคลาวด์หรือผู้ให้บริการตำแหน่งร่วม เช่นเดียวกับการรวมศูนย์ข้อมูลทางกายภาพ การรวมปริมาณงานบนคลาวด์อาจเป็นความพยายามหลักที่ไม่ได้สร้างมูลค่าทางธุรกิจอย่างมีนัยสำคัญ ดังนั้นจึงมักเกิดความล่าช้าสำหรับโครงการที่มีลำดับความสำคัญสูงกว่า
ประการสุดท้าย กลยุทธ์มัลติคลาวด์มักจะถูกนำมาใช้เพื่อรองรับความพร้อมใช้งานสูงและความต้องการในการกู้คืนระบบ ในการประเมินการหยุดทำงานของคลาวด์สาธารณะที่สำคัญใน AWS และ Azure โดยทั่วไปแล้วการหยุดทำงานส่วนใหญ่จะจำกัดอยู่ที่ภูมิภาคคลาวด์เดียวในแต่ละครั้ง (และโดยทั่วไปมักเกี่ยวข้องกับซอฟต์แวร์)
องค์กรจำนวนมากขึ้นเรื่อยๆ (34% ตามรายงานของ Flexera) ได้ดำเนินการเพิ่มขั้นตอนในการปรับใช้ภาระงานที่มีความสำคัญต่อภารกิจในผู้ให้บริการคลาวด์สาธารณะหลายราย ซึ่งสามารถทำได้ง่ายกว่ามากสำหรับเวิร์กโหลดแบบคงที่ เช่น เว็บไซต์และแอปพลิเคชันที่สามารถทำงานแยกจากกัน สำหรับระบบแบบกระจาย เช่น ฐานข้อมูลและบริการไดเร็กทอรี (เช่น Active Directory) การกู้คืนจากภัยพิบัติแบบมัลติคลาวด์อาจเป็นเรื่องที่ท้าทายกว่ามาก
ทำความเข้าใจกับความท้าทายที่ไม่เหมือนใครในสภาพแวดล้อมแบบมัลติคลาวด์
สภาพแวดล้อมแบบมัลติคลาวด์นั้นซับซ้อนกว่าและมีความท้าทายในการจัดการมากกว่าการปรับใช้คลาวด์เดียว ความท้าทายที่ไม่เหมือนใครในสภาพแวดล้อมแบบมัลติคลาวด์ ได้แก่: • การมองเห็นแบบ end-to-end: การตรวจสอบการมองเห็นที่สมบูรณ์เป็นสิ่งที่ท้าทายในสภาพแวดล้อมด้านไอทีใดๆ และมีความซับซ้อนและท้าทายมากขึ้นเป็นทวีคูณในสภาพแวดล้อมแบบมัลติคลาวด์ที่มีไดนามิกสูง อย่างไรก็ตาม การมองเห็นแบบ end-to-end มีความสำคัญอย่างยิ่งต่อการแก้ไขปัญหาด้านประสิทธิภาพและปัญหาคอขวด การรักษาความปลอดภัยรอยเท้าดิจิทัลของคุณ และการระบุจุดที่ล้มเหลวเพียงจุดเดียวในระบบและแอปพลิเคชันที่มีความสำคัญต่อภารกิจ
• การจัดการความปลอดภัยและข้อมูลประจำตัว: แรนซัมแวร์และภัยคุกคามความปลอดภัยทางไซเบอร์อื่นๆ เป็นสิ่งที่ผู้นำด้านไอทีทุกคนนึกถึงในปัจจุบัน ในขณะที่การย้ายไปยังแพลตฟอร์มคลาวด์สาธารณะโดยทั่วไปจะช่วยปรับปรุงท่าทางการรักษาความปลอดภัยขององค์กรโดยการเปลี่ยนความรับผิดชอบด้านความปลอดภัยบางอย่าง (เช่น ศูนย์ข้อมูลและความปลอดภัยทางกายภาพ) ไปยังผู้ให้บริการคลาวด์สาธารณะและให้การเข้าถึงบริการตามต้องการ เช่น การเข้ารหัสและการแบ่งส่วนเครือข่าย มันสามารถ ยังทำให้ง่ายต่อการทำผิดพลาดที่มีราคาแพง ตัวอย่างเช่น การกำหนดค่าเครือข่ายผิดพลาดอาจเป็นเรื่องปกติ—การละเมิดข้อมูลหลายพันรายการเกิดจากบัคเก็ตพื้นที่จัดเก็บ AWS S3 ที่กำหนดค่าไม่ถูกต้อง การจัดการข้อมูลประจำตัวเป็นอีกหนึ่งความท้าทาย ตัวอย่างเช่น Azure Active Directory อาจค่อนข้างคุ้นเคยสำหรับองค์กรที่เคยใช้ Active Directory ในสภาพแวดล้อมภายในองค์กร แต่ขยายการจัดการข้อมูลประจำตัวนอกเหนือจาก Azure ไปยังข้อเสนอ AWS, GCP และ SaaS (เช่น Salesforce, ServiceNow, Workday และอื่นๆ ) สามารถนำเสนอความท้าทายใหม่ๆ
• แอพพลิเคชั่นและการพกพาข้อมูล: ความสามารถในการย้ายแอปพลิเคชันและข้อมูลแบบไดนามิกข้ามแพลตฟอร์มคลาวด์สาธารณะต่างๆ ในสภาพแวดล้อมแบบไฮบริด (มัลติคลาวด์) เป็นกุญแจสำคัญในกลยุทธ์มัลติคลาวด์จำนวนมาก แม้ว่าผู้ให้บริการคลาวด์สาธารณะไม่จำเป็นต้องสร้างบริการของตนเพื่อจำกัดความสามารถในการพกพาแอปพลิเคชันและข้อมูล แต่ก็ไม่จำเป็นต้องทำงานร่วมกันเพื่ออำนวยความสะดวกในความสามารถนี้ และอาจมีค่าใช้จ่ายที่เกี่ยวข้อง ผู้ให้บริการระบบคลาวด์ที่แตกต่างกันยังใช้เทคโนโลยีที่แตกต่างกันสำหรับข้อเสนอบริการต่างๆ
• ไซโลมัลติคลาวด์: หากองค์กรไม่วางแผนและออกแบบการปรับใช้มัลติคลาวด์สำหรับแอปพลิเคชันและความสามารถในการพกพาข้อมูล พวกเขาอาจลงเอยด้วยแอปพลิเคชันและพื้นที่เก็บข้อมูลแบบแยก ซึ่งโดยพื้นฐานแล้วจะสร้างปัญหาทั่วไปขึ้นใหม่ในสภาพแวดล้อมศูนย์ข้อมูลแบบดั้งเดิมในองค์กรบนแพลตฟอร์มคลาวด์ที่หลากหลาย อย่างน้อยที่สุด องค์กรต่างๆ จำเป็นต้องมีเครื่องมือรักษาความปลอดภัยและการจัดการแบบมัลติคลาวด์ที่ช่วยให้สามารถจัดการความเสี่ยงและการใช้งาน/ค่าใช้จ่ายบนแพลตฟอร์มคลาวด์ต่างๆ ได้อย่างมีประสิทธิภาพ
ตามรายงาน Flexera 2021 State of the Cloud 81% ขององค์กรระบุว่าการรักษาความปลอดภัยเป็นความท้าทายสูงสุดในการปรับใช้ระบบคลาวด์ ตามมาด้วยการจัดการค่าใช้จ่ายระบบคลาวด์ (79%) มีองค์กรเพียง 42% เท่านั้นที่ใช้เครื่องมือการจัดการต้นทุนแบบมัลติคลาวด์ และเพียง 38% เท่านั้นที่ใช้เครื่องมือรักษาความปลอดภัยแบบมัลติคลาวด์
จัดการกับความพร้อมใช้งานสูงและการกู้คืนความเสียหายในสภาพแวดล้อมแบบมัลติคลาวด์
แม้ว่าการปรับใช้มัลติคลาวด์จะมีความท้าทายมากมาย แต่ก็สามารถมอบความพร้อมใช้งานเพิ่มเติมได้ โดยเฉพาะอย่างยิ่งในกรณีที่ระบบคลาวด์หยุดทำงานครั้งใหญ่ และการกู้คืนระบบเมื่อเกิดภัยพิบัติ หากองค์กรของคุณดำเนินกลยุทธ์มัลติคลาวด์ คุณควรทำงานร่วมกับพันธมิตรที่เชื่อถือได้และไม่เชื่อเรื่องพระเจ้าบนคลาวด์เพื่อช่วยคุณออกแบบและปรับใช้การปรับใช้มัลติคลาวด์โดยใช้แนวทางแบบองค์รวม
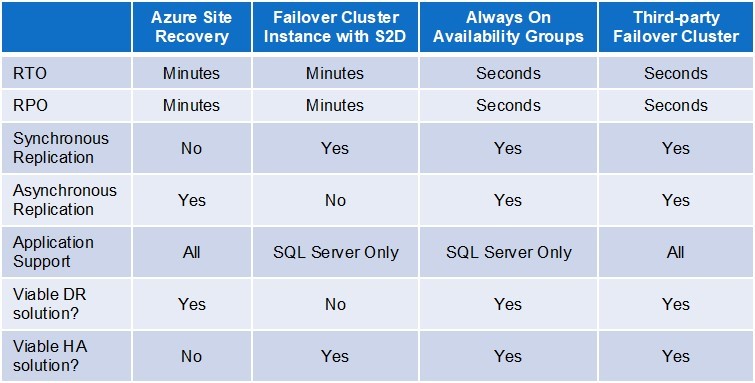
สำหรับ ความพร้อมใช้งานสูง และการกู้คืนความเสียหาย คุณยังต้องการโซลูชันเทคโนโลยีที่ไม่เชื่อเรื่องพระเจ้าบนคลาวด์ ซึ่งครอบคลุมสภาพแวดล้อมมัลติคลาวด์ของคุณ โดยไม่คำนึงถึงแพลตฟอร์มคลาวด์ที่คุณใช้ คุณต้องการหลีกเลี่ยงสถานการณ์ที่โซลูชันความพร้อมใช้งานสูงของคุณทำให้เกิดการหยุดทำงานในสภาพแวดล้อมของคุณมากกว่าโซลูชันแบบสแตนด์อโลนเสมอ การทำคลัสเตอร์ SQL Server เวอร์ชันก่อนหน้านำเสนอปริศนานี้ เพื่อเพิ่มพื้นที่ดิสก์ คุณต้องมีเวลาหยุดทำงานซึ่งจะไม่เกิดขึ้นในโซลูชันแบบสแตนด์อโลน แม้ว่าการล้มเหลวในบางอย่างเช่นเว็บไซต์แบบสแตติกอาจเป็นเรื่องเล็กน้อย การย้ายแอปพลิเคชันสแต็กหลายชั้นนั้นซับซ้อนมากในแง่ของการสร้างเครือข่ายและการซิงโครไนซ์ข้อมูล คุณต้องหลีกเลี่ยงการล้มเหลวไปยังสภาพแวดล้อมคลาวด์ที่ปลอดภัยน้อยกว่าซึ่งอาจได้รับการกำหนดค่าผิดเนื่องจากขาดความเข้าใจความแตกต่างระหว่างโซลูชันการรักษาความปลอดภัยที่แตกต่างกันในผู้ให้บริการคลาวด์
ฉันควรทำอย่างไร?
ประการสุดท้าย ในระบบคลาวด์สาธารณะทุกแห่ง มีบริการจำนวนหนึ่งที่สามารถเพิ่มต้นทุนได้อย่างรวดเร็ว บริการเหล่านี้จะถูกเรียกเก็บเงินตามราคาตามการใช้งาน และอาจหมายถึงค่าใช้จ่ายที่เพิ่มขึ้นอย่างมากหลังจากผ่านไปเพียงไม่กี่วัน วิธีหนึ่งในการลดความเสี่ยงนี้คือการทำให้แน่ใจว่าคุณกำลังใช้ประโยชน์จากบริการตรวจสอบค่าใช้จ่ายและการแจ้งเตือนที่อยู่ในแต่ละแพลตฟอร์มระบบคลาวด์ของคุณ
แม้ว่าการปรับใช้มัลติคลาวด์อาจไม่ใช่สำหรับทุกองค์กร แต่หลายๆ องค์กรก็จะเดินไปตามเส้นทางนี้ การทำความเข้าใจระบบเครือข่ายและความปลอดภัยเป็นหนึ่งในอุปสรรคทางเทคนิคที่ใหญ่ที่สุดของคุณ และการจัดการด้านธรรมาภิบาลและต้นทุนถือเป็นความท้าทายในการทำงานที่สำคัญ การทดสอบเป็นสิ่งสำคัญเพื่อให้แน่ใจว่าโซลูชันคลัสเตอร์มัลติคลาวด์ของคุณใช้งานได้ สิ่งสำคัญคือต้องใช้โซลูชันการทำคลัสเตอร์ที่มีความพร้อมใช้งานสูงซึ่งเปิดใช้งานการสลับและสลับกลับอย่างง่าย และเพื่อทำความเข้าใจว่าแต่ละแอปพลิเคชันของคุณจะทำงานอย่างไร ล้มเหลว และที่สำคัญที่สุดคือการทดสอบความล้มเหลวอย่างสม่ำเสมอเพื่อทำความเข้าใจเครือข่ายหรืออุปสรรคด้านข้อมูล
ทำซ้ำโดยได้รับอนุญาตจาก SIOS