เว็บสัมมนา: การรับประกันความพร้อมใช้งานสูงในสภาพแวดล้อมมัลติคลาวด์: บทเรียนจากการหยุดให้บริการของ CrowdStrike
ลงทะเบียนเข้าร่วมสัมมนาออนไลน์แบบ On-Demand
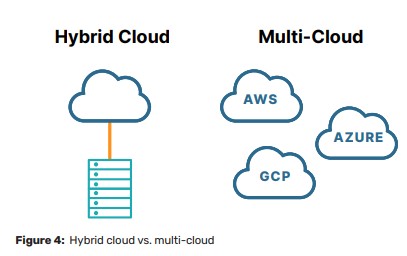
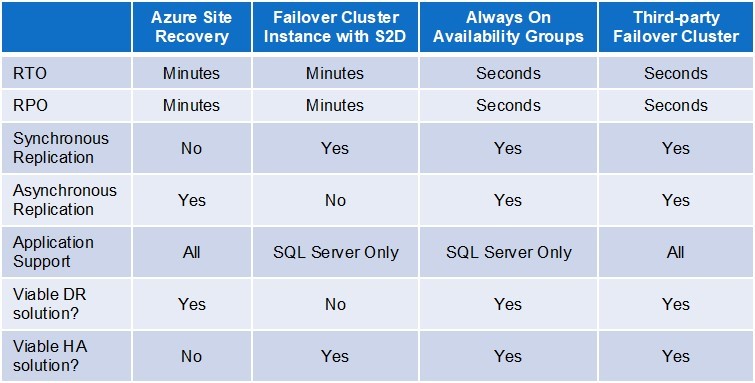
ธุรกิจต่าง ๆ หันมาใช้ผู้ให้บริการระบบคลาวด์หลายรายมากขึ้นเพื่อรักษาความยืดหยุ่นและความสามารถในการปรับขนาด อย่างไรก็ตาม เหตุการณ์ล่าสุด เช่น การหยุดให้บริการของ CrowdStrike แสดงให้เห็นว่าแม้แต่ระบบชั้นนำก็อาจประสบปัญหาได้ โดยเฉพาะอย่างยิ่งกับการอัปเดตและแพตช์ความปลอดภัย เว็บสัมมนาครั้งนี้จะกล่าวถึงแนวทางปฏิบัติที่ดีที่สุดในการนำโซลูชันความพร้อมใช้งานสูง (HA) แบบมัลติคลาวด์มาใช้เพื่อให้แอปพลิเคชันที่สำคัญต่อภารกิจของคุณทำงานได้แม้ในกรณีที่เกิดการหยุดชะงักโดยไม่คาดคิด นอกจากนี้ ยังครอบคลุมถึงกลยุทธ์ต่าง ๆ เพื่อป้องกันไม่ให้ระบบหยุดทำงานเนื่องจากการกำหนดค่าระบบผิดพลาดหรือแพตช์ที่มีปัญหา เพื่อให้แน่ใจว่าคุณสามารถจัดการโครงสร้างพื้นฐานระบบคลาวด์ของคุณได้อย่างมีประสิทธิภาพ
รับชมเว็บสัมมนาแบบตามต้องการเพื่อค้นพบวิธีการบรรลุ HA ในสภาพแวดล้อมของคุณและลดเวลาหยุดทำงานที่ป้องกันได้ให้เหลือน้อยที่สุด
พิมพ์ซ้ำโดยได้รับอนุญาตจากSIOS