* การปฏิเสธความรับผิด: แม้ว่าข้อมูลต่อไปนี้จะครอบคลุมส่วนความพร้อมใช้งานสูงภายในขอบเขตของผลิตภัณฑ์ของเราอย่างสมบูรณ์ แต่นี่เป็น “คู่มือ” ในการตั้งค่าเท่านั้นและควรปรับให้เข้ากับการกำหนดค่าของคุณเอง
ภาพรวม HUAWEI Cloud เป็นผู้ให้บริการคลาวด์ชั้นนำที่ไม่เพียงแต่ในประเทศจีนเท่านั้น แต่ยังมีพื้นที่ทั่วโลกด้วยศูนย์ข้อมูลหลายแห่งทั่วโลก พวกเขานำความเชี่ยวชาญกว่า 30 ปีของ Huawei มารวมกันในผลิตภัณฑ์และโซลูชันโครงสร้างพื้นฐาน ICT และมุ่งมั่นที่จะให้บริการคลาวด์ที่เชื่อถือได้ ปลอดภัย และคุ้มค่า เพื่อเพิ่มขีดความสามารถของแอปพลิเคชัน ควบคุมพลังของข้อมูล และช่วยให้องค์กรทุกขนาดเติบโตในยุคปัจจุบัน โลกที่ชาญฉลาด HUAWEI CLOUD มุ่งมั่นที่จะนำเสนอบริการคลาวด์และ AI ที่มีราคาไม่แพง มีประสิทธิภาพ และเชื่อถือได้ผ่านนวัตกรรมทางเทคโนโลยี
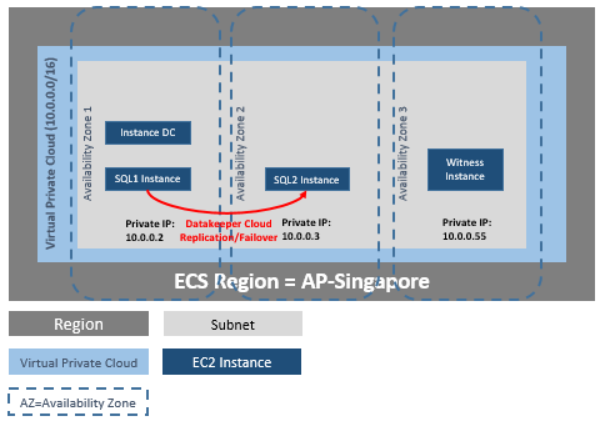
DataKeeper Cluster Edition ให้การจำลองแบบในระบบคลาวด์ส่วนตัวเสมือน (VPC) ภายในภูมิภาคเดียวในโซนความพร้อมใช้งานสำหรับคลาวด์ของ Huawei ในตัวอย่างการทำคลัสเตอร์ SQL Server นี้ เราจะเปิดใช้อินสแตนซ์สี่อินสแตนซ์ (อินสแตนซ์ตัวควบคุมโดเมนหนึ่งอินสแตนซ์ อินสแตนซ์ SQL Server สองอินสแตนซ์ และอินสแตนซ์องค์ประชุม/อินสแตนซ์) ในโซนความพร้อมใช้งานสามโซน
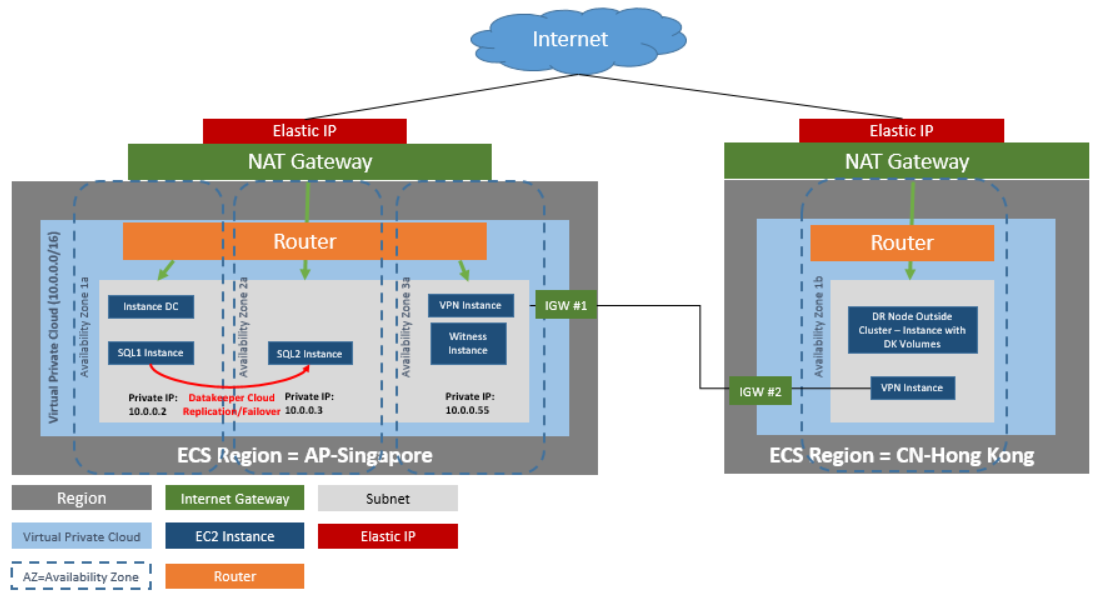
DataKeeper Cluster Edition ให้การสนับสนุนโหนดการจำลองข้อมูลภายนอกคลัสเตอร์ที่มีโหนดทั้งหมดในคลาวด์ของ Huawei ในตัวอย่างการทำคลัสเตอร์ SQL Server โดยเฉพาะนี้ อินสแตนซ์สี่ตัวถูกเปิดใช้ (อินสแตนซ์ตัวควบคุมโดเมนหนึ่งอินสแตนซ์ อินสแตนซ์ SQL Server สองอินสแตนซ์ และอินสแตนซ์องค์ประชุม/อินสแตนซ์) ในโซนความพร้อมใช้งานสามโซน จากนั้นจะมีการเปิดตัวอินสแตนซ์ DataKeeper เพิ่มเติมในภูมิภาคที่สอง รวมถึงอินสแตนซ์ VPN ในทั้งสองภูมิภาค โปรดมอง การกำหนดค่าการจำลองข้อมูลจากโหนดคลัสเตอร์ไปยังไซต์ DR ภายนอก สำหรับข้อมูลเพิ่มเติม. สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการใช้หลายภูมิภาค โปรดดูที่ การเชื่อมต่อ VPC สองเครื่องในภูมิภาคต่างๆ .
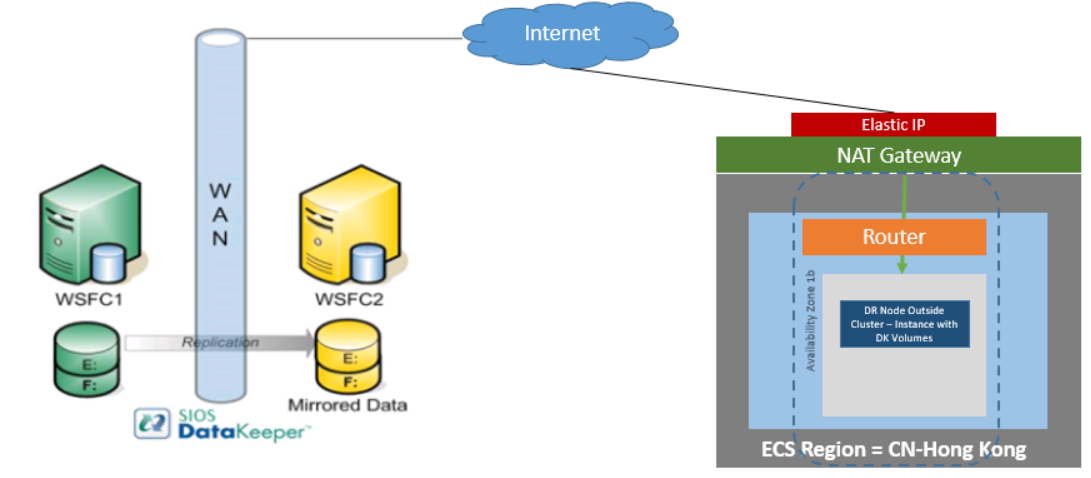
DataKeeper Cluster Edition ยังรองรับโหนดการจำลองข้อมูลภายนอกคลัสเตอร์ที่มีเฉพาะโหนดภายนอกคลัสเตอร์ใน Huawei Cloud ในตัวอย่างการทำคลัสเตอร์ SQL Server โดยเฉพาะ WSFC1 และ WSFC2 อยู่ในคลัสเตอร์ในไซต์ที่จำลองแบบไปยังอินสแตนซ์ Huawei Cloud จากนั้นจะมีการเปิดตัวอินสแตนซ์ DataKeeper เพิ่มเติมในภูมิภาคใน Huawei Cloud โปรดมอง การกำหนดค่าการจำลองข้อมูลจากโหนดคลัสเตอร์ไปยังไซต์ DR ภายนอก สำหรับข้อมูลเพิ่มเติม.
ความต้องการ
| คำอธิบาย | ความต้องการ |
| คลาวด์ส่วนตัวเสมือน | ในภูมิภาคเดียวที่มีสามโซนความพร้อมใช้งาน |
| ประเภทอินสแตนซ์ | ประเภทอินสแตนซ์ที่แนะนำขั้นต่ำ: s3.large.2 |
| ระบบปฏิบัติการ | ดูเมทริกซ์การสนับสนุน DKCE |
| IP ยืดหยุ่น | ที่อยู่ IP แบบยืดหยุ่นหนึ่งรายการเชื่อมต่อกับตัวควบคุมโดเมน |
| สี่กรณี | หนึ่งอินสแตนซ์ตัวควบคุมโดเมน สองอินสแตนซ์ของ SQL Server และหนึ่งองค์ประชุม/อินสแตนซ์ของพยาน |
| SQL Server แต่ละตัว | ENI (Elastic Network Interface) ที่มี 4 IP · ENI IP หลักที่กำหนดไว้แบบคงที่ใน Windows และใช้โดย DataKeeper Cluster Edition · IP สามรายการที่ดูแลโดย ECS ในขณะที่ใช้โดย Windows Failover Clustering , DTC และ SQLFC |
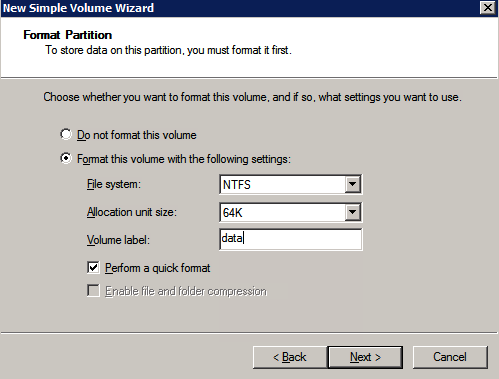
| ปริมาณ | สามวอลุ่ม (EBS และ NTFS เท่านั้น) · หนึ่งวอลุ่มหลัก (ไดรฟ์ C) · สองวอลุ่มเพิ่มเติม o หนึ่งสำหรับการทำคลัสเตอร์ล้มเหลว o หนึ่งสำหรับ MSDTC |
บันทึกประจำรุ่น ก่อนจะเริ่ม อย่าลืมอ่าน บันทึกประจำรุ่น DataKeeper Cluster Edition สำหรับข้อมูลล่าสุด ขอแนะนำให้อ่านและทำความเข้าใจ คู่มือการติดตั้ง DataKeeper Cluster Edition .
สร้าง Virtual Private Cloud (VPC) คลาวด์ส่วนตัวเสมือนเป็นอ็อบเจ็กต์แรกที่คุณสร้างเมื่อใช้ DataKeeper Cluster Edition
* Virtual Private Cloud (VPC) คือไพรเวทคลาวด์แบบแยกส่วน ซึ่งประกอบด้วยพูลทรัพยากรการประมวลผลที่ใช้ร่วมกันที่กำหนดค่าได้ในระบบคลาวด์สาธารณะ
- ใช้อีเมลและรหัสผ่านที่ระบุตอนสมัคร Huawei Cloud , ลงชื่อเข้าใช้ Huawei Cloud Management Console .
- จาก บริการ ดรอปดาวน์ เลือก คลาวด์ส่วนตัวเสมือน .
- ที่ด้านขวาของหน้าจอ ให้คลิกที่ สร้าง VPC และเลือกภูมิภาคที่คุณต้องการใช้
- ป้อนชื่อที่คุณต้องการใช้สำหรับ VPC
- กำหนดซับเน็ตคลาวด์ส่วนตัวเสมือนของคุณโดยป้อน your CIDR (การกำหนดเส้นทางระหว่างโดเมนแบบไม่มีคลาส) ตามที่อธิบายไว้ด้านล่าง
- ป้อนชื่อซับเน็ต จากนั้นคลิก สร้างตอนนี้ .
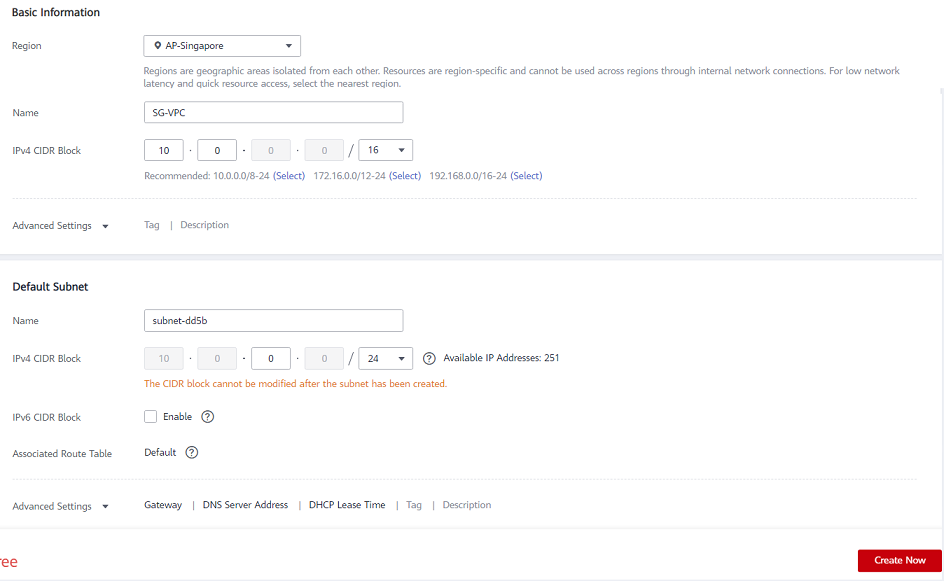
* ตารางเส้นทางจะถูกสร้างขึ้นโดยอัตโนมัติด้วยการเชื่อมโยง “หลัก” กับ VPC ใหม่ คุณสามารถใช้ในภายหลังหรือสร้างตารางเส้นทางอื่น
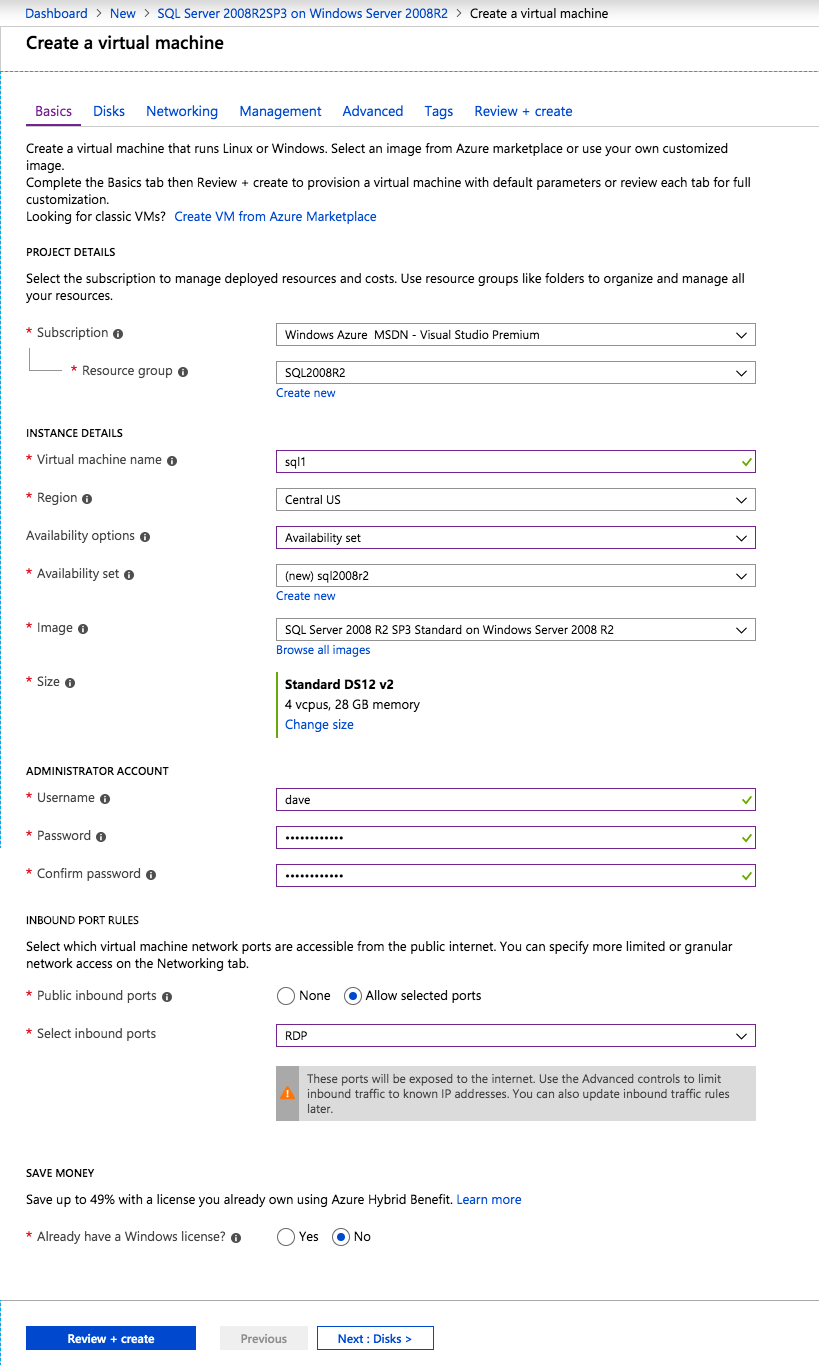
* ลิงค์ที่เป็นประโยชน์: Huawei’s การสร้าง Virtual Private Cloud (VPC) เปิดตัวอินสแตนซ์ ข้อมูลต่อไปนี้จะแนะนำคุณเกี่ยวกับการเปิดใช้อินสแตนซ์ในซับเน็ตของคุณ คุณจะต้องเปิดใช้อินสแตนซ์สองอินสแตนซ์ในโซนความพร้อมใช้งานเดียว อินสแตนซ์หนึ่งสำหรับอินสแตนซ์ตัวควบคุมโดเมน และอีกรายการสำหรับอินสแตนซ์ SQL ของคุณ จากนั้น คุณจะเปิดใช้อินสแตนซ์ SQL อื่นในโซนความพร้อมใช้งานอื่น และอินสแตนซ์ขององค์ประชุมในโซนความพร้อมใช้งานอื่น
* ลิงก์ที่มีประโยชน์: อินสแตนซ์ Huawei Cloud ECS
- ใช้อีเมลและรหัสผ่านที่ระบุตอนสมัคร Huawei Cloud , ลงชื่อเข้าใช้ Huawei Cloud Management Console .
- จาก รายการบริการ ดรอปดาวน์ เลือก เซิร์ฟเวอร์คลาวด์ยืดหยุ่น .

- เลือก ซื้อ ECS และเลือกโหมดการเรียกเก็บเงิน ภูมิภาค และ AZ (Availability Zone) เพื่อปรับใช้ Instance
- เลือกประเภทอินสแตนซ์ของคุณ ( บันทึก: เลือก s3.large.2 หรือใหญ่กว่า)
- เลือกรูปภาพ ภายใต้ รูปภาพสาธารณะ ให้เลือก Windows Server 2019 Datacenter 64bit ภาษาอังกฤษ ภาพ
- สำหรับ กำหนดค่าเครือข่าย เลือก VPC ของคุณ
- สำหรับ ซับเน็ต , เลือก Subnet ที่คุณต้องการใช้ เลือก ที่อยู่ IP ที่ระบุด้วยตนเอง และป้อนที่อยู่ IP ที่คุณต้องการใช้
- เลือก กลุ่มรักษาความปลอดภัย เพื่อใช้หรือแก้ไขและเลือกที่มีอยู่
- กำหนด EIP หากคุณต้องการอินสแตนซ์ ECS เพื่อเข้าถึงอินเทอร์เน็ต
- คลิก กำหนดการตั้งค่าขั้นสูง และตั้งชื่อให้ ECS ใช้ รหัสผ่าน สำหรับ โหมดเข้าสู่ระบบ และระบุรหัสผ่านที่ปลอดภัยสำหรับการเข้าสู่ระบบของผู้ดูแลระบบ
- คลิก กำหนดค่าตอนนี้ บน ตัวเลือกขั้นสูง เพิ่ม แท็ก เพื่อตั้งชื่ออินสแตนซ์ของคุณและคลิกที่ ยืนยัน
- ดำเนินการตรวจสอบอินสแตนซ์ขั้นสุดท้ายแล้วคลิก ส่ง .
* สำคัญ: จดบันทึกรหัสผ่านผู้ดูแลระบบเริ่มต้นนี้ จำเป็นต้องเข้าสู่ระบบอินสแตนซ์ของคุณ
ทำซ้ำขั้นตอนข้างต้นสำหรับอินสแตนซ์ทั้งหมด
เชื่อมต่อกับอินสแตนซ์ คุณสามารถเชื่อมต่อกับอินสแตนซ์ตัวควบคุมโดเมนของคุณผ่าน เข้าสู่ระบบระยะไกล จากบานหน้าต่าง ECS
เข้าสู่ระบบในฐานะผู้ดูแลระบบและป้อนของคุณ รหัสผ่านผู้ดูแลระบบ .
* ปฏิบัติที่ดีที่สุด: เมื่อเข้าสู่ระบบแล้ว ควรเปลี่ยนรหัสผ่านของคุณ
กำหนดค่าอินสแตนซ์ตัวควบคุมโดเมน เมื่อสร้างอินสแตนซ์แล้ว เราเริ่มต้นด้วยการตั้งค่าอินสแตนซ์บริการโดเมน
คู่มือนี้ไม่ใช่บทช่วยสอนเกี่ยวกับวิธีตั้งค่าอินสแตนซ์เซิร์ฟเวอร์ Active Domain เราแนะนำให้อ่าน บทความ เกี่ยวกับวิธีการตั้งค่าและกำหนดค่าเซิร์ฟเวอร์ Active Directory สิ่งสำคัญคือต้องเข้าใจว่าแม้ว่าอินสแตนซ์จะทำงานในคลาวด์ของ Huawei แต่นี่เป็นการติดตั้ง Active Directory เป็นประจำ
ที่อยู่ IP แบบคงที่ กำหนดค่าที่อยู่ IP แบบคงที่สำหรับอินสแตนซ์ของคุณ
- เชื่อมต่อกับอินสแตนซ์ตัวควบคุมโดเมนของคุณ
- คลิก เริ่ม / แผงควบคุม .
- คลิก ศูนย์เครือข่ายและการแบ่งปัน .
- เลือกอินเทอร์เฟซเครือข่ายของคุณ
- คลิก คุณสมบัติ .
- คลิก อินเทอร์เน็ตโปรโตคอลเวอร์ชัน 4 (TCP/IPv4) , แล้ว คุณสมบัติ .
- รับปัจจุบันของคุณ ที่อยู่ IPv4 , เกตเวย์เริ่มต้น และ เซิร์ฟเวอร์ DNS สำหรับอินเทอร์เฟซเครือข่ายจาก อเมซอน .
- ใน คุณสมบัติอินเทอร์เน็ตโปรโตคอลเวอร์ชัน 4 (TCP/IPv4) กล่องโต้ตอบ ภายใต้ ใช้ที่อยู่ IP ต่อไปนี้ , ใส่ของคุณ ที่อยู่ IPv4 .
- ใน ซับเน็ตมาสก์ ให้พิมพ์ซับเน็ตมาสก์ที่เชื่อมโยงกับซับเน็ตคลาวด์ส่วนตัวเสมือนของคุณ
- ใน เกตเวย์เริ่มต้น กล่อง พิมพ์ ที่อยู่ IP ของเกตเวย์เริ่มต้นแล้วคลิก ตกลง .
- สำหรับ เซิร์ฟเวอร์ DNS ที่ต้องการ , ป้อน ที่อยู่ IP หลักของตัวควบคุมโดเมนของคุณ (เช่น 15.0.1.72)
- คลิก ตกลง จากนั้นเลือก ปิด I . ทางออก ศูนย์เครือข่ายและการแบ่งปัน .
- ทำซ้ำขั้นตอนข้างต้นกับอินสแตนซ์อื่นๆ ของคุณ
เข้าร่วมสองอินสแตนซ์ SQL และอินสแตนซ์พยานในโดเมน * ก่อนที่จะพยายามเข้าร่วมโดเมน ให้ทำการปรับเครือข่ายเหล่านี้ บนอะแดปเตอร์เครือข่ายของคุณ เพิ่ม/เปลี่ยนเซิร์ฟเวอร์ DNS ที่ต้องการเป็นที่อยู่ Domain Controller ใหม่และเซิร์ฟเวอร์ DNS ใช้ ipconfig /flushdns เพื่อรีเฟรชรายการค้นหา DNS หลังจากการเปลี่ยนแปลงนี้ ทำสิ่งนี้ก่อนพยายามเข้าร่วมโดเมน
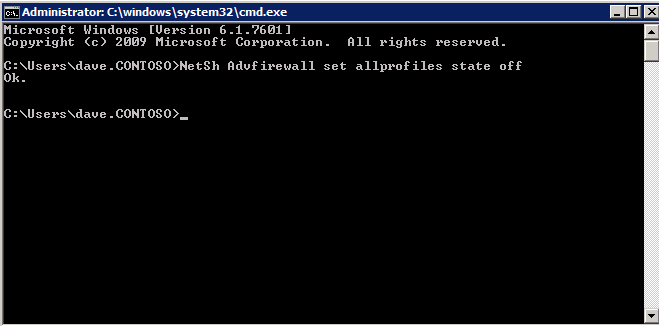
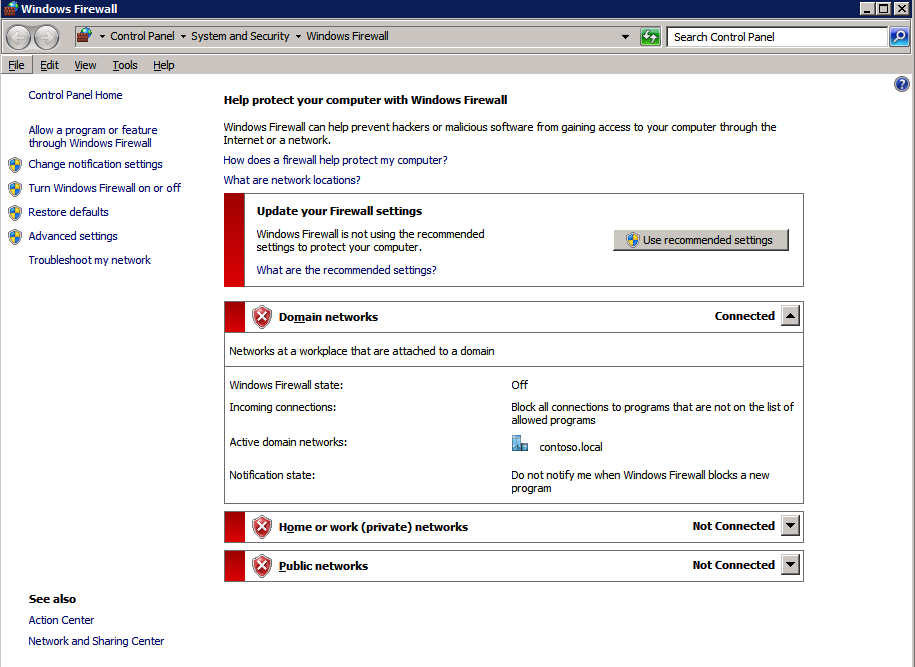
* รับรองว่า เครือข่ายหลัก และ การแชร์ไฟล์และเครื่องพิมพ์ ตัวเลือกได้รับอนุญาตในไฟร์วอลล์ Windows
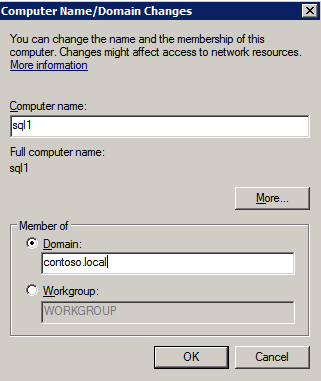
- ในแต่ละกรณี คลิก เริ่ม จากนั้นคลิกขวา คอมพิวเตอร์ และเลือก คุณสมบัติ .
- ที่ด้านขวาสุด เลือก เปลี่ยนการตั้งค่า .
- คลิกที่ เปลี่ยน .
- ใส่ใหม่ ชื่อคอมพิวเตอร์ .
- เลือก โดเมน .
- เข้า ชื่อโดเมน – (เช่น docs.huawei.com)
- คลิก นำมาใช้ .
* ใช้ แผงควบคุม เพื่อให้แน่ใจว่าอินสแตนซ์ทั้งหมดใช้เขตเวลาที่ถูกต้องสำหรับตำแหน่งของคุณ
* ปฏิบัติที่ดีที่สุด: ขอแนะนำให้ตั้งค่าไฟล์หน้าระบบเป็น ระบบจัดการ (ไม่อัตโนมัติ) และใช้ไดรฟ์ C: เสมอ
แผงควบคุม > การตั้งค่าระบบขั้นสูง > ประสิทธิภาพ > การตั้งค่า > ขั้นสูง > หน่วยความจำเสมือน เลือก ขนาดที่จัดการโดยระบบ , ปริมาณ C: เท่านั้น จากนั้นเลือก ชุด เพื่อบันทึก.
กำหนด IP ส่วนตัวรองให้กับอินสแตนซ์ SQL สองอินสแตนซ์ นอกจาก IP หลักแล้ว คุณจะต้องเพิ่ม IP เพิ่มเติมสามตัว (IP รอง) ให้กับอินเทอร์เฟซเครือข่ายแบบยืดหยุ่นสำหรับอินสแตนซ์ SQL แต่ละรายการ
- จาก รายการบริการ ดรอปดาวน์ เลือก เซิร์ฟเวอร์คลาวด์ยืดหยุ่น .
- คลิกอินสแตนซ์ที่คุณต้องการเพิ่มที่อยู่ IP ส่วนตัวสำรอง
- เลือก NIC > จัดการที่อยู่ IP เสมือน .
- คลิกที่ กำหนดที่อยู่ IP เสมือน และเลือก คู่มือ ป้อนที่อยู่ IP ที่อยู่ภายในช่วงซับเน็ตสำหรับอินสแตนซ์ (เช่น สำหรับ 15.0.1.25 ให้ป้อน 15.0.1.26) คลิก ตกลง .
- คลิกที่ มากกว่า ดรอปดาวน์บนแถวที่อยู่ IP แล้วเลือก ผูกกับเซิร์ฟเวอร์ เลือกเซิร์ฟเวอร์ที่จะผูกที่อยู่ IP และการ์ด NIC
- คลิก ตกลง เพื่อบันทึกงานของคุณ
- ดำเนินการด้านบนบน ทั้งอินสแตนซ์ SQL .
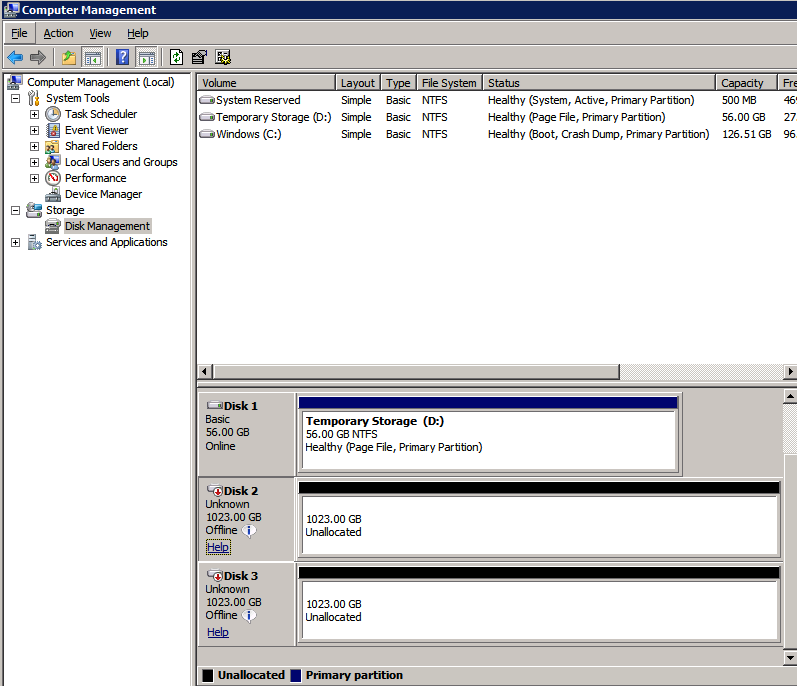
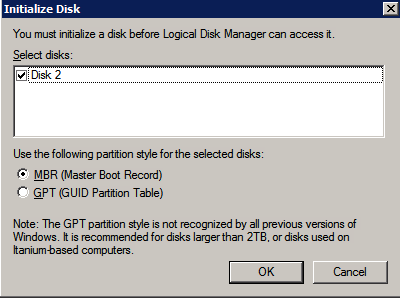
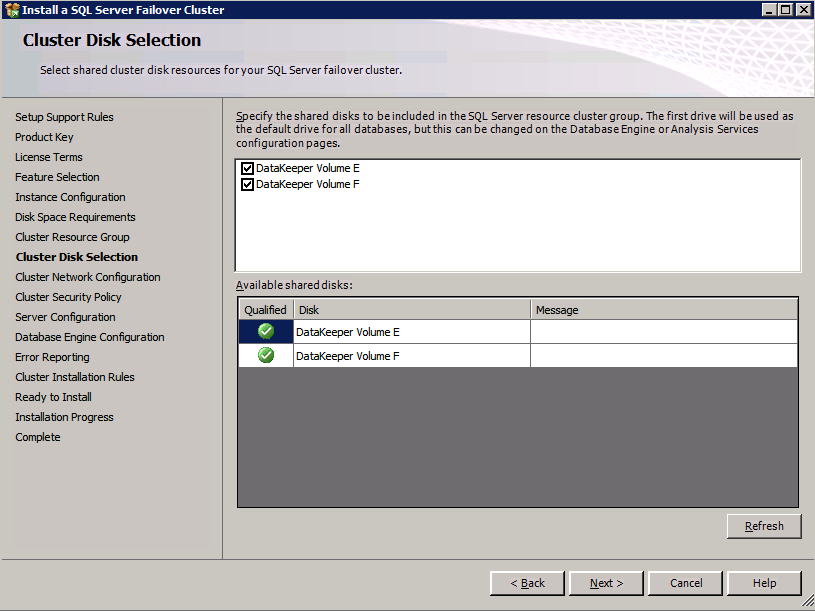
* ลิงก์ที่มีประโยชน์: การจัดการที่อยู่ IP เสมือน การผูกที่อยู่ IP เสมือนกับ EIP หรือ ECS สร้างและแนบวอลุ่ม DataKeeper เป็นโซลูชันการจำลองแบบโวลุ่มระดับบล็อก และต้องการให้แต่ละโหนดในคลัสเตอร์มีโวลุ่มเพิ่มเติม (นอกเหนือจากไดรฟ์ระบบ) ที่มีขนาดเท่ากันและมีอักษรระบุไดรฟ์เหมือนกัน โปรดตรวจสอบ การพิจารณาปริมาณ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับข้อกำหนดในการจัดเก็บ
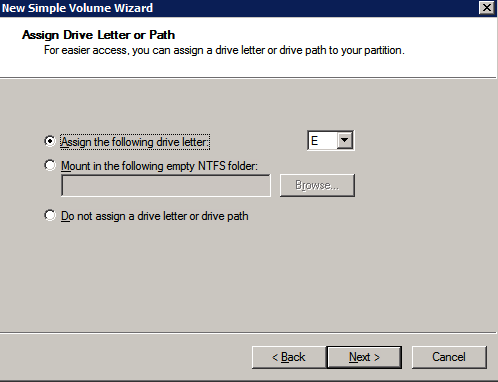
สร้างเล่ม สร้างสองวอลุ่มในแต่ละโซนความพร้อมใช้งานสำหรับอินสแตนซ์เซิร์ฟเวอร์ SQL แต่ละรายการ รวมเป็นสี่วอลุ่ม
- จาก รายการบริการ ดรอปดาวน์ เลือก เซิร์ฟเวอร์คลาวด์ยืดหยุ่น .
- คลิกอินสแตนซ์ที่คุณต้องการจัดการ
- ไปที่ ดิสก์ แท็บ
- คลิก เพิ่มดิสก์ หากต้องการเพิ่มโวลุ่มและขนาดใหม่ที่คุณเลือก ตรวจสอบให้แน่ใจว่าคุณได้เลือกโวลุ่มใน AZ เดียวกันกับเซิร์ฟเวอร์ SQL ที่คุณต้องการแนบ
- เลือกช่องทำเครื่องหมายเพื่อยอมรับ SLA และ ส่ง
- คลิก กลับไปที่คอนโซลเซิร์ฟเวอร์
- แนบ ดิสก์หากจำเป็นสำหรับอินสแตนซ์ SQL
- ทำเช่นนี้สำหรับทั้งสี่เล่ม
* ลิงก์ที่มีประโยชน์: บริการปริมาณยืดหยุ่น กำหนดค่าคลัสเตอร์ ก่อนที่จะติดตั้ง DataKeeper Cluster Edition สิ่งสำคัญคือต้องมี Windows Server ที่กำหนดค่าเป็นคลัสเตอร์โดยใช้โหนดส่วนใหญ่ควอรัม (หากมีโหนดเป็นจำนวนคี่) หรือโควรัมส่วนใหญ่ที่แชร์โหนดและไฟล์ (หากมีจำนวนคู่ โหนด) ศึกษาเอกสารประกอบของ Microsoft เกี่ยวกับการจัดกลุ่มเพิ่มเติมจากหัวข้อนี้สำหรับคำแนะนำทีละขั้นตอนบันทึก: Microsoft เปิดตัว a โปรแกรมแก้ไขด่วน สำหรับ Windows 2008R2 ที่อนุญาตให้ปิดใช้งานการลงคะแนนของโหนด ซึ่งอาจช่วยให้มีความพร้อมใช้งานในระดับที่สูงขึ้นในการกำหนดค่าคลัสเตอร์หลายไซต์บางรายการ
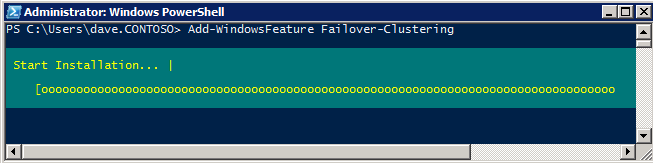
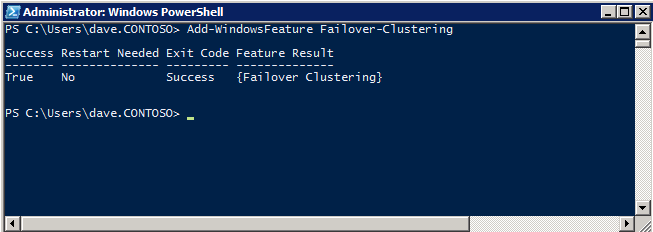
เพิ่ม Failover Clustering เพิ่มฟีเจอร์ Failover Clustering ให้กับอินสแตนซ์ SQL ทั้งสอง
- ปล่อย ตัวจัดการเซิร์ฟเวอร์ .
- เลือก คุณสมบัติ ในบานหน้าต่างด้านซ้ายและคลิก เพิ่มคุณสมบัติ ใน คุณสมบัติ นี้เริ่มต้น เพิ่มตัวช่วยสร้างคุณสมบัติ .
- เลือก คลัสเตอร์ล้มเหลว .
- เลือก ติดตั้ง .
ตรวจสอบการกำหนดค่า
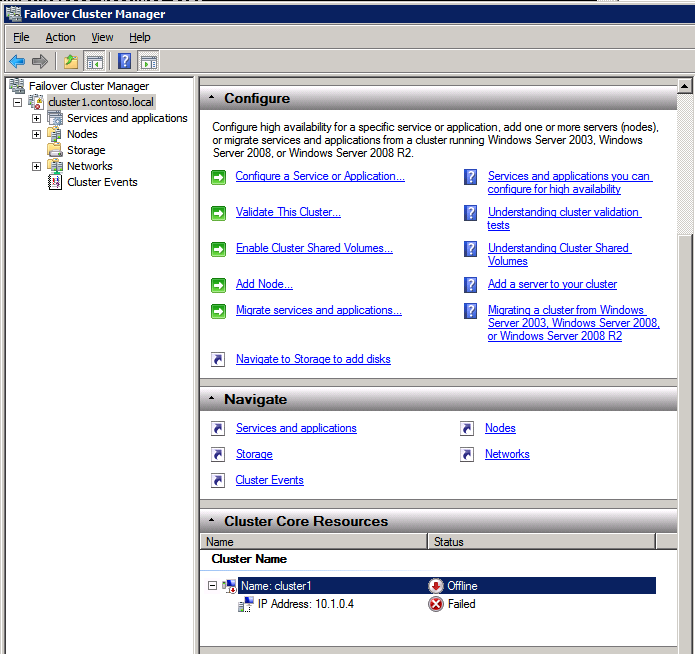
- เปิด ตัวจัดการคลัสเตอร์ล้มเหลว .
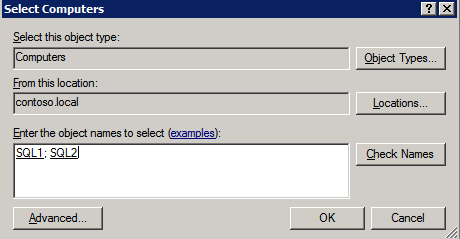
- เลือก Failover Cluster Manager เลือก ตรวจสอบการกำหนดค่า .
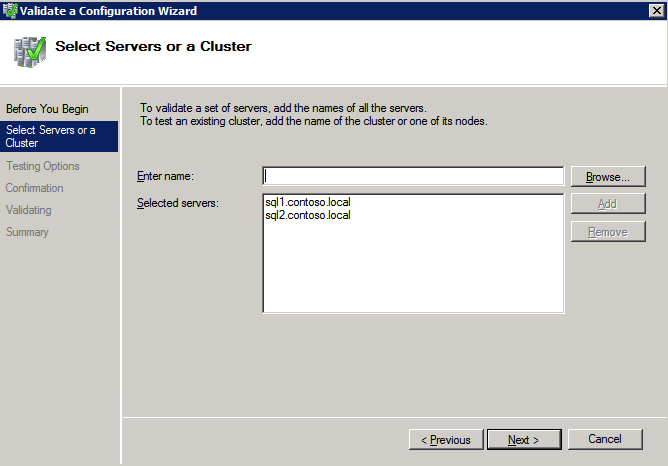
- คลิก ต่อไป แล้วเพิ่มสองของคุณ อินสแตนซ์ SQL .
บันทึก: หากต้องการค้นหา ให้เลือก เรียกดู จากนั้นคลิกที่ ขั้นสูง และ ค้นหาตอนนี้ . นี่จะแสดงรายการอินสแตนซ์ที่พร้อมใช้งาน
- คลิก ต่อไป .
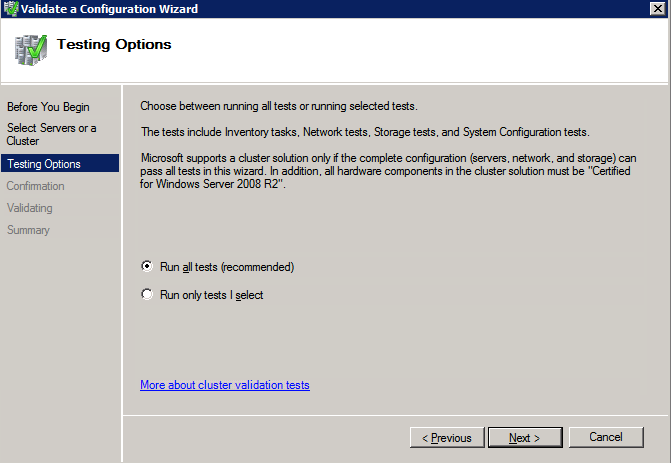
- เลือก เรียกใช้การทดสอบเท่านั้นที่ฉันเลือก และคลิก ต่อไป .
- ใน การเลือกการทดสอบ หน้าจอ ยกเลิกการเลือก พื้นที่จัดเก็บ และคลิก ต่อไป .
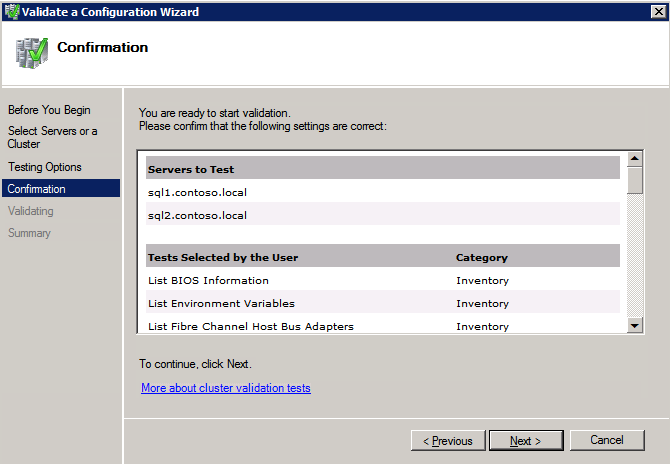
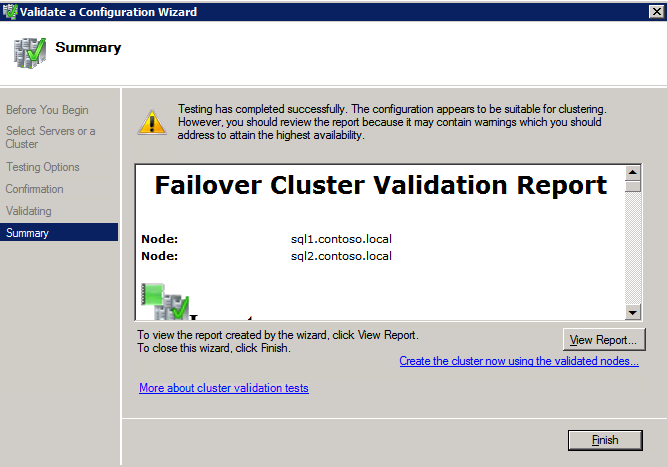
- ที่หน้าจอยืนยันผลลัพธ์ คลิก ต่อไป .
- ทบทวน รายงานสรุปการตรวจสอบ แล้วคลิก เสร็จสิ้น .
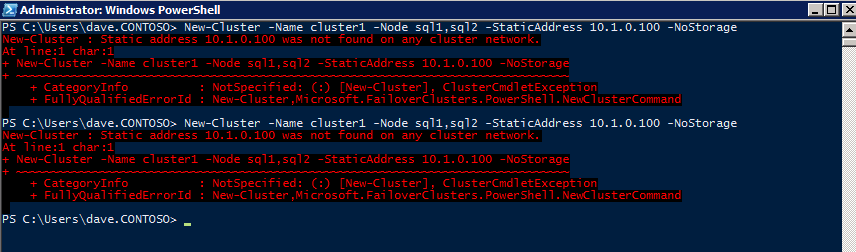
สร้างคลัสเตอร์
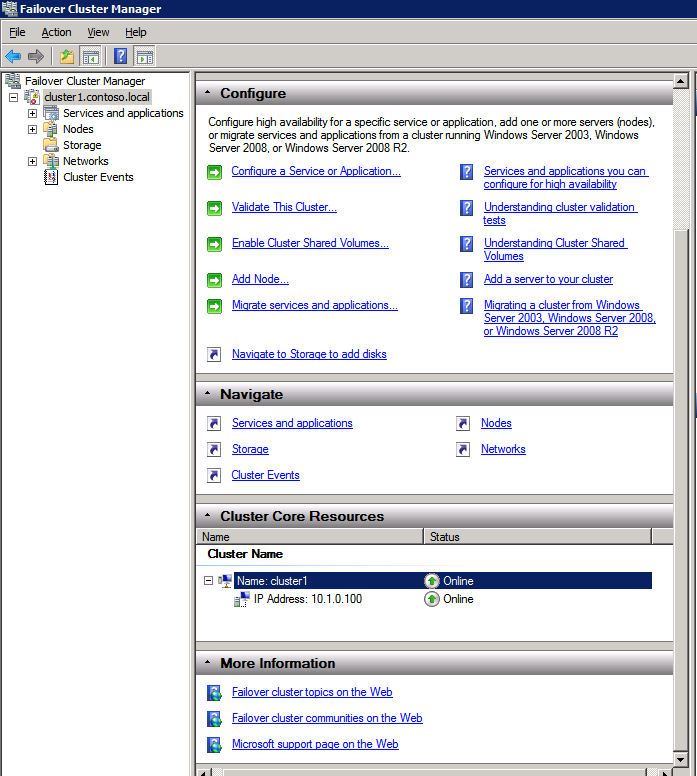
- ใน ตัวจัดการคลัสเตอร์ล้มเหลว , คลิกที่ สร้างคลัสเตอร์ แล้วคลิก ต่อไป .
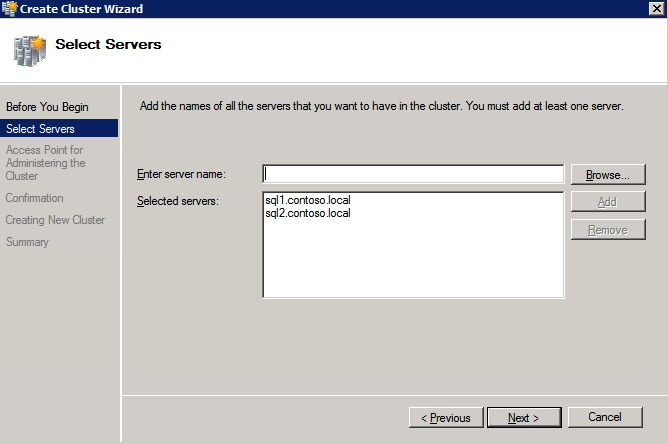
- ใส่สองของคุณ อินสแตนซ์ SQL .
- บน คำเตือนการตรวจสอบความถูกต้อง หน้าเลือก เลขที่ แล้วคลิก ต่อไป .
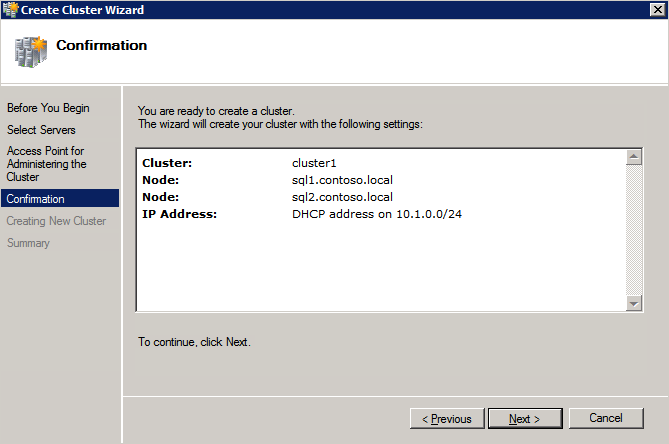
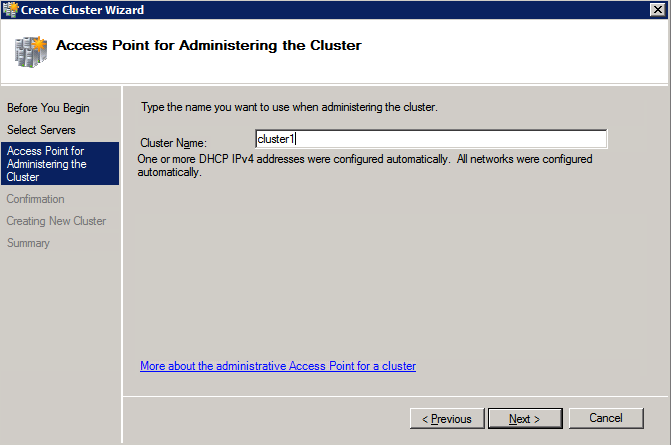
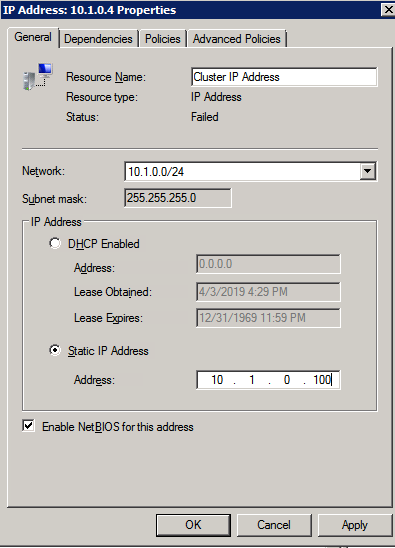
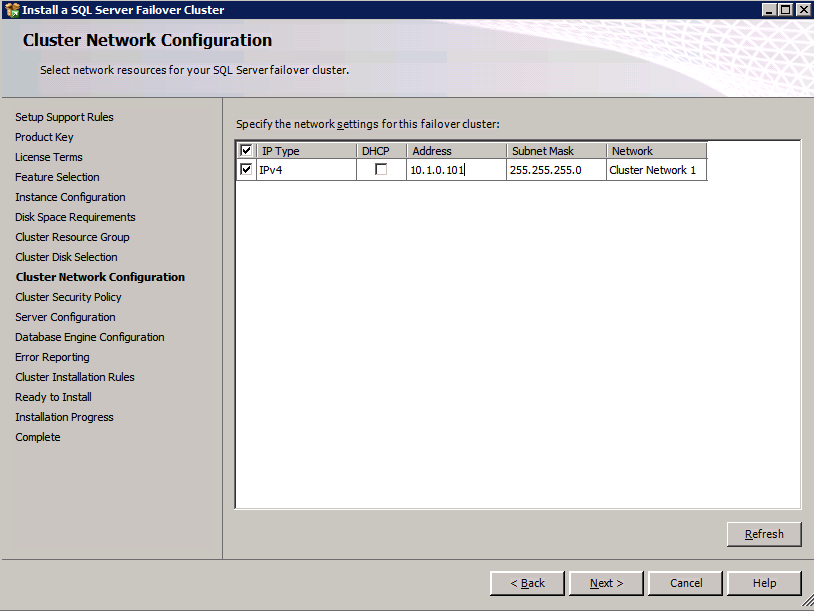
- บน จุดเข้าใช้งานสำหรับการจัดการคลัสเตอร์ ให้ป้อนชื่อเฉพาะสำหรับคลัสเตอร์ WSFC ของคุณ จากนั้นป้อน ที่อยู่ IP ของคลัสเตอร์ล้มเหลว สำหรับแต่ละโหนดที่เกี่ยวข้องในคลัสเตอร์ นี่เป็นครั้งแรกในสาม ที่อยู่ IP สำรอง เพิ่มก่อนหน้านี้ในแต่ละอินสแตนซ์
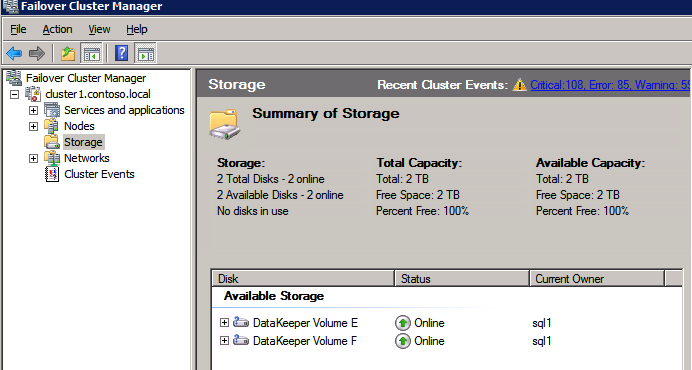
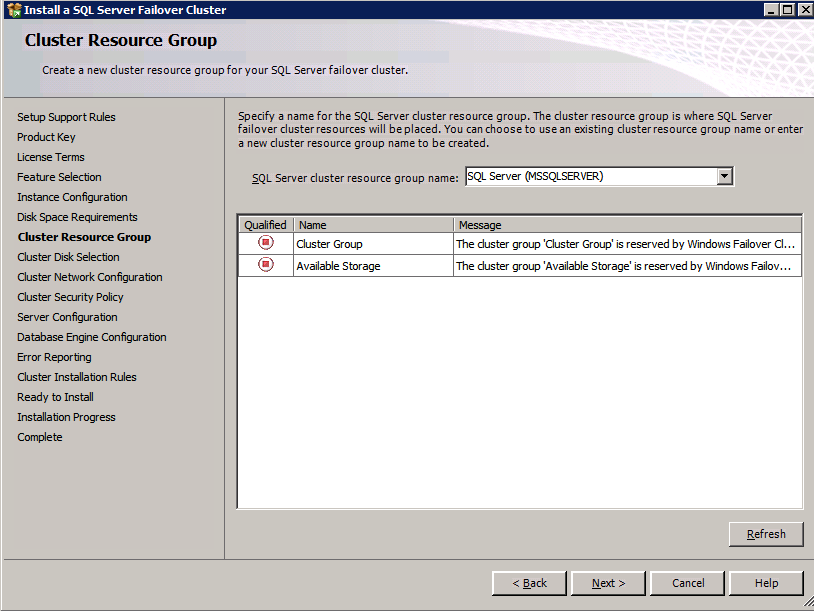
- สำคัญ! ยกเลิกการเลือกช่องทำเครื่องหมาย “เพิ่มที่เก็บข้อมูลที่มีอยู่ทั้งหมดไปยังคลัสเตอร์” ไดรฟ์ที่ทำมิเรอร์ DataKeeper ต้องไม่ได้รับการจัดการโดยกำเนิดโดยคลัสเตอร์ พวกเขาจะได้รับการจัดการเป็น DataKeeper Volumes
- คลิก ต่อไป บน การยืนยัน
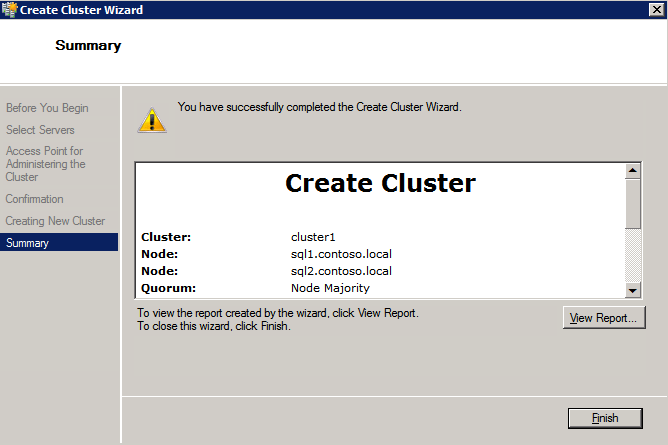
- บน สรุป หน้า ตรวจทานคำเตือนใด ๆ จากนั้นเลือก เสร็จสิ้น .
กำหนดค่าองค์ประชุม/พยาน
- สร้างโฟลเดอร์บนอินสแตนซ์องค์ประชุม/พยานของคุณ (พยาน)
- แชร์โฟลเดอร์
- คลิกขวาที่โฟลเดอร์และเลือก แบ่งปันกับ / เฉพาะบุคคล ….
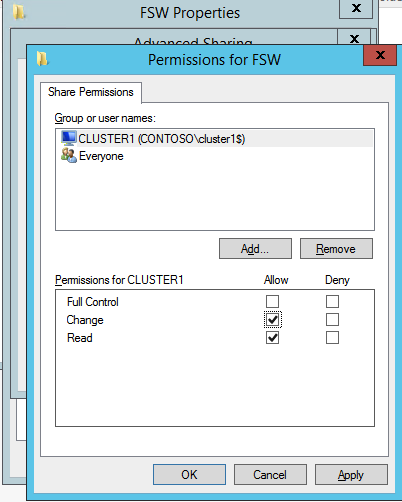
- จากดรอปดาวน์ ให้เลือก ทุกคน และคลิก เพิ่ม .
- ภายใต้ ระดับการอนุญาต , เลือก อ่านเขียน .
- คลิก แบ่งปัน , แล้ว เสร็จแล้ว . (จดบันทึกเส้นทางของการแชร์ไฟล์นี้เพื่อใช้ด้านล่าง)
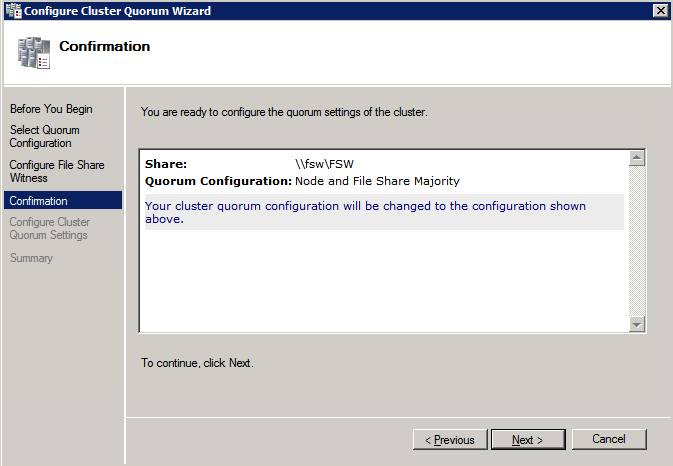
- ใน ตัวจัดการคลัสเตอร์ล้มเหลว , คลิกขวาที่คลัสเตอร์แล้วเลือก การดำเนินการมากขึ้น และ กำหนดการตั้งค่าองค์ประชุมคลัสเตอร์ . คลิก ต่อไป .
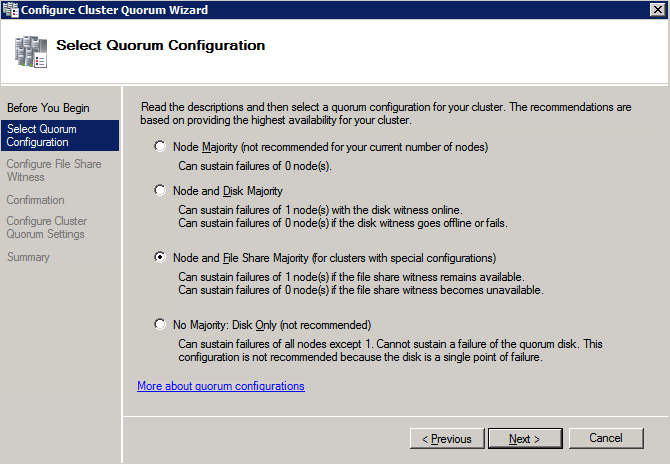
- บน เลือกการกำหนดค่าองค์ประชุม , เลือก โหนดและไฟล์แชร์ส่วนใหญ่ และคลิก ต่อไป .
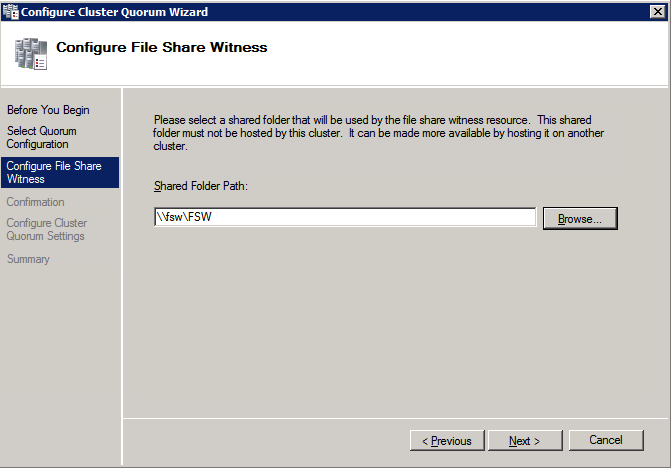
- บน กำหนดค่าพยานแชร์ไฟล์ ให้ป้อนเส้นทางไปยังไฟล์ที่แชร์ที่สร้างไว้ก่อนหน้านี้แล้วคลิก ต่อไป .
- บน การยืนยัน หน้าคลิก ต่อไป .
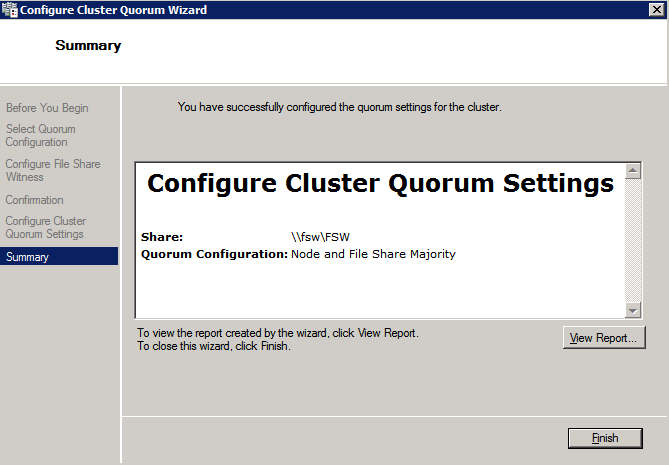
- บน สรุป หน้าคลิก เสร็จสิ้น .
ติดตั้งและกำหนดค่า DataKeeper หลังจากกำหนดค่าคลัสเตอร์พื้นฐานแล้ว แต่ก่อนที่จะสร้างทรัพยากรคลัสเตอร์ใดๆ ให้ติดตั้งและให้สิทธิ์ใช้งาน DataKeeper Cluster Edition บนโหนดคลัสเตอร์ทั้งหมด ดู คู่มือการติดตั้ง DataKeeper Cluster Edition สำหรับคำแนะนำโดยละเอียด
- วิ่ง การตั้งค่า DataKeeper ติดตั้ง DataKeeper Cluster Edition บนอินสแตนซ์ SQL ทั้งสอง
- ใส่ของคุณ คีย์ใบอนุญาต และรีบูตเมื่อได้รับแจ้ง
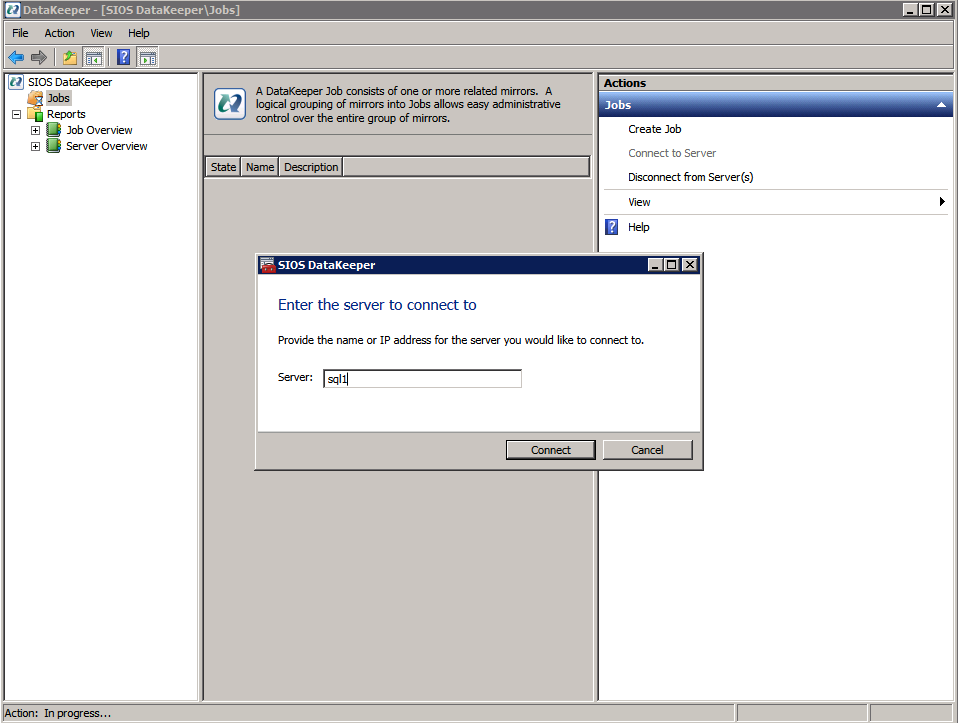
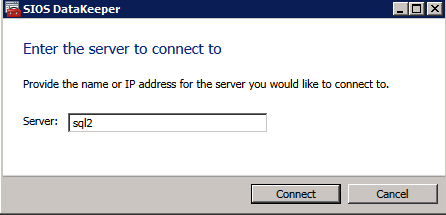
- เปิดตัว DataKeeper GUI และ เชื่อมต่อกับเซิร์ฟเวอร์ .
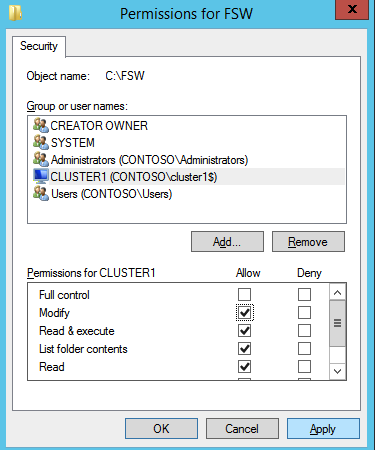
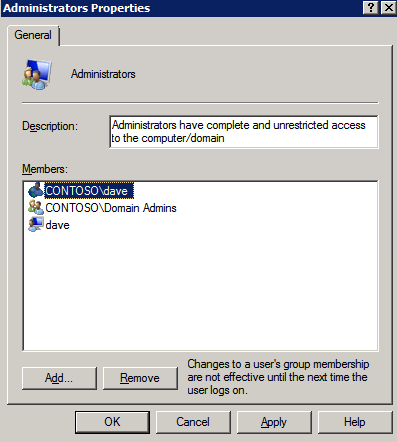
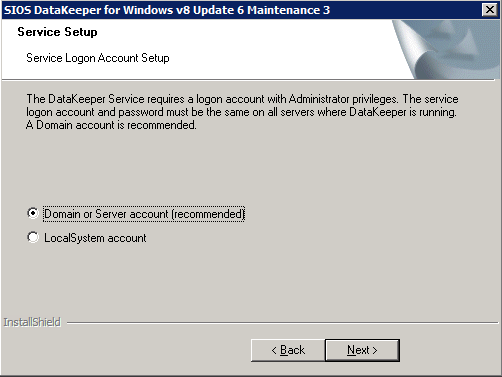
* บันทึก : ต้องเพิ่มบัญชีโดเมนหรือเซิร์ฟเวอร์ที่ใช้ในกลุ่มผู้ดูแลระบบภายใน บัญชีต้องมีสิทธิ์ของผู้ดูแลระบบในแต่ละเซิร์ฟเวอร์ที่ติดตั้ง DataKeeper อ้างถึง บริการ DataKeeper เข้าสู่ระบบ ID และการเลือกรหัสผ่าน สำหรับข้อมูลเพิ่มเติม
- คลิกขวาที่ งาน และเชื่อมต่อกับเซิร์ฟเวอร์ SQL ทั้งสอง
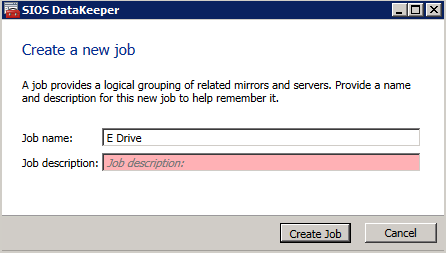
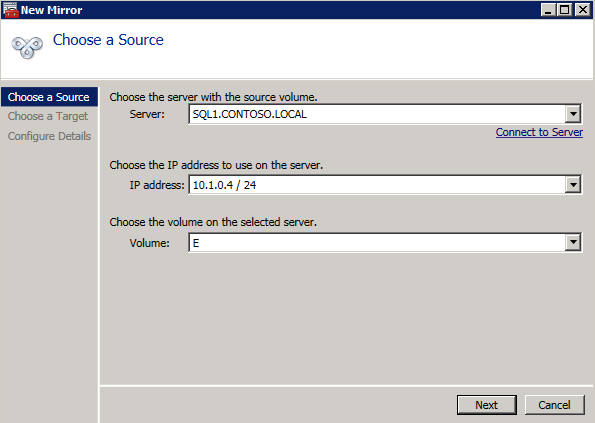
- สร้างงาน สำหรับแต่ละกระจกที่คุณจะสร้างขึ้น หนึ่งรายการสำหรับทรัพยากร DTC ของคุณและอีกรายการสำหรับทรัพยากร SQL ของคุณ..
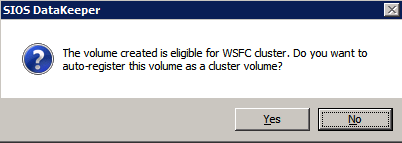
- เมื่อระบบถามว่าคุณต้องการลงทะเบียนโวลุ่มอัตโนมัติเป็นโวลุ่มคลัสเตอร์หรือไม่ ให้เลือก ใช่ .
* บันทึก: หากติดตั้ง DataKeeper Cluster Edition บน Windows “Core” (Windows ที่ไม่มี GUI) โปรดอ่าน การติดตั้งและใช้งาน DataKeeper บน Windows 2008R2/2012 Server Core Platforms สำหรับคำแนะนำโดยละเอียด
กำหนดค่า MSDTC
- สำหรับ Windows Server 2012 และ 2016 ใน GUI ตัวจัดการคลัสเตอร์ล้มเหลว , เลือก บทบาท จากนั้นเลือก กำหนดค่าบทบาท .
- เลือก ผู้ประสานงานธุรกรรมแบบกระจาย (DTC) และคลิก ต่อไป .
* สำหรับ Windows Server 2008 ใน GUI ตัวจัดการคลัสเตอร์ล้มเหลว , เลือก บริการและแอพพลิเคชั่น จากนั้นเลือก กำหนดค่าบริการหรือแอปพลิเคชัน และคลิก ต่อไป .
- บน จุดเข้าใช้งานไคลเอ็นต์ หน้าจอ ป้อนชื่อ จากนั้นป้อน ที่อยู่ IP MSDTC สำหรับแต่ละโหนดที่เกี่ยวข้องในคลัสเตอร์ นี่คือที่สองในสาม ที่อยู่ IP สำรอง เพิ่มก่อนหน้านี้ในแต่ละอินสแตนซ์ คลิก ต่อไป .
- เลือก ปริมาณ MSDTC และคลิก ต่อไป .
- บน การยืนยัน หน้าคลิก ต่อไป .
- เมื่อ สรุป แสดงหน้า คลิก เสร็จสิ้น .
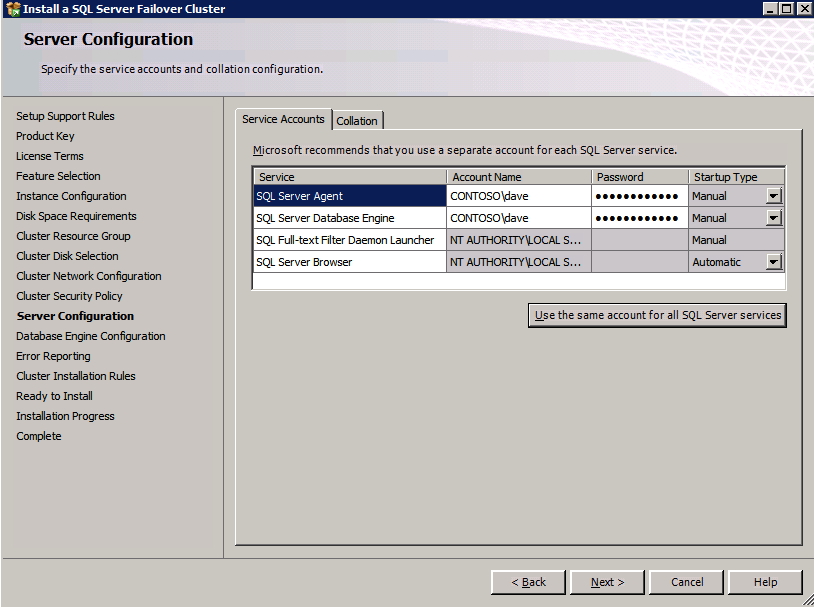
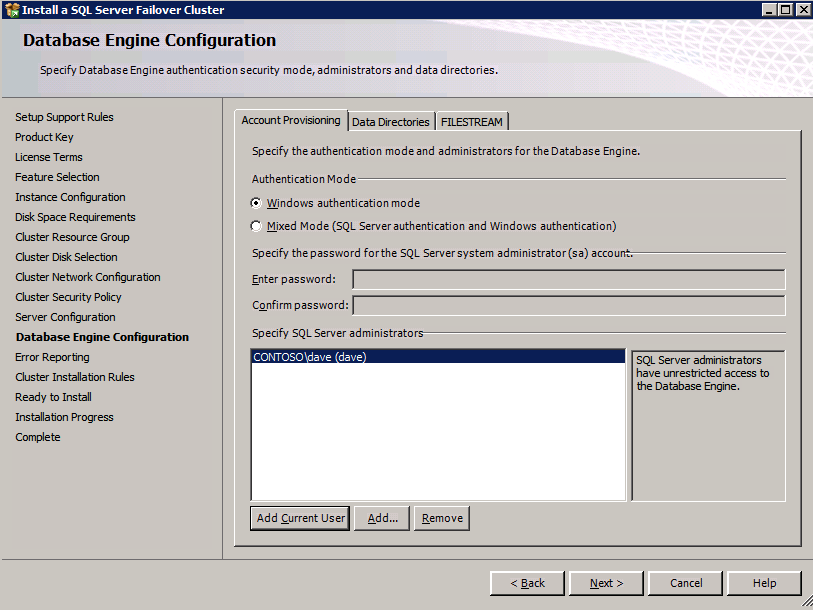
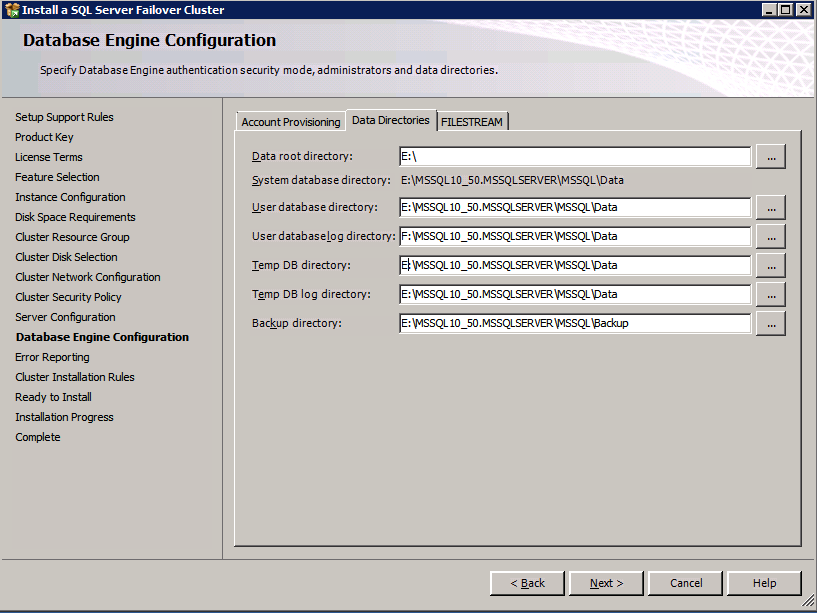
ติดตั้ง SQL บนอินสแตนซ์ SQL ตัวแรก
- บนเซิร์ฟเวอร์ตัวควบคุมโดเมน ให้สร้างโฟลเดอร์และแชร์..
- ตัวอย่างเช่น “TEMPSHARE” โดยได้รับอนุญาตจากทุกคน
- สร้างโฟลเดอร์ย่อย “SQL” และคัดลอกตัวติดตั้ง SQL .iso ลงในโฟลเดอร์ย่อยนั้น
- บนเซิร์ฟเวอร์ SQL ให้สร้างไดรฟ์เครือข่ายและแนบกับโฟลเดอร์ที่ใช้ร่วมกันบนตัวควบคุมโดเมน
- . ตัวอย่างเช่น “การใช้เน็ต S: \TEMPSHARE
- บนเซิร์ฟเวอร์ SQL ไดรฟ์ S: จะปรากฏขึ้น ซีดีไปยังโฟลเดอร์ SQL และค้นหาตัวติดตั้ง SQL .iso คลิกขวาที่ไฟล์ .iso แล้วเลือก ภูเขา . ตัวติดตั้ง setup.exe จะปรากฏขึ้นพร้อมกับตัวติดตั้ง SQL .iso
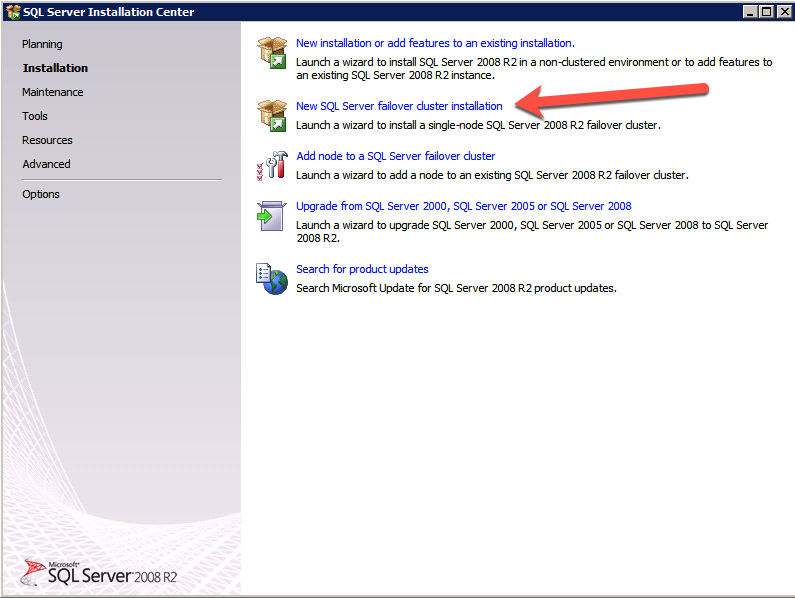
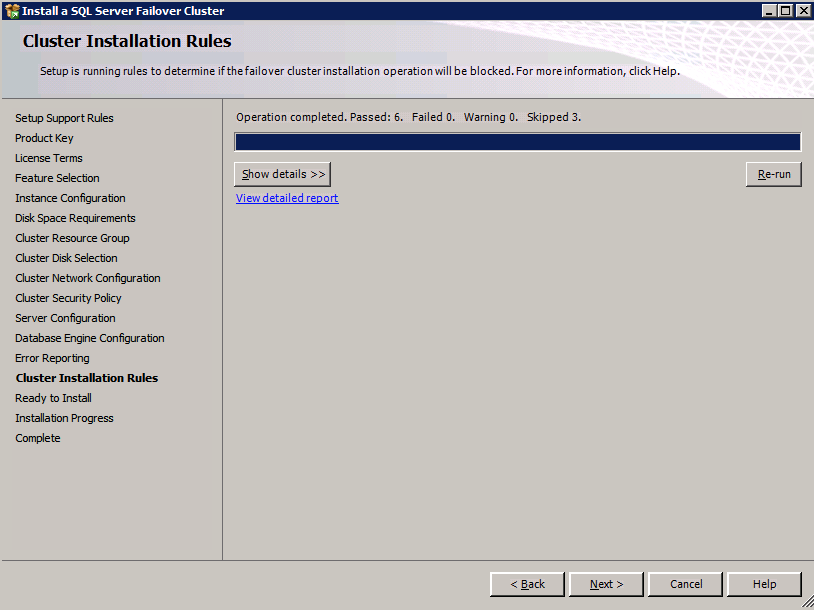
F:>ตั้งค่า /SkipRules=Cluster_VerifyForErrors /Action=InstallFailoverCluster
- บน ตั้งค่ากฎการสนับสนุน , คลิก ตกลง .
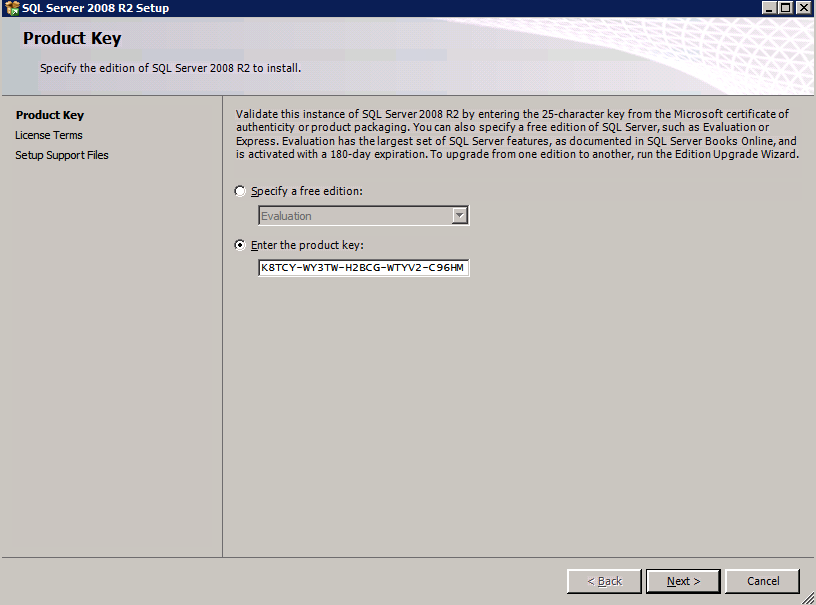
- บน รหัสสินค้า โต้ตอบ ป้อนของคุณ รหัสสินค้า และคลิก ต่อไป .
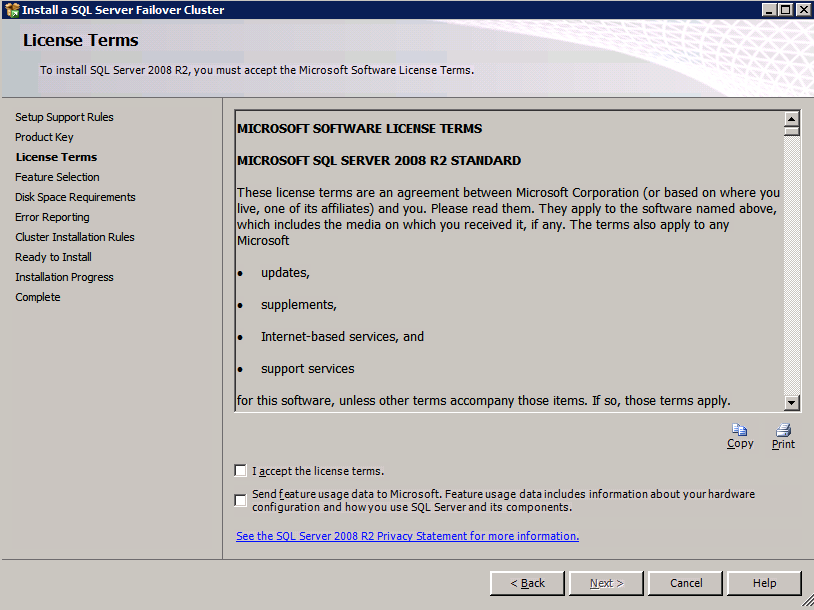
- บน เงื่อนไขใบอนุญาต โต้ตอบ ยอมรับ ข้อตกลง และคลิก ต่อไป .
- บน อัพเดทสินค้า โต้ตอบ คลิก ต่อไป .
- บน ตั้งค่าไฟล์สนับสนุน โต้ตอบ คลิก ติดตั้ง .
- บน ตั้งค่ากฎการสนับสนุน โต้ตอบ คุณจะได้รับคำเตือน คลิก ต่อไป ละเว้นข้อความนี้ เนื่องจากเป็นที่คาดหมายในคลัสเตอร์การจัดเก็บข้อมูลแบบหลายไซต์หรือแบบไม่แบ่งใช้
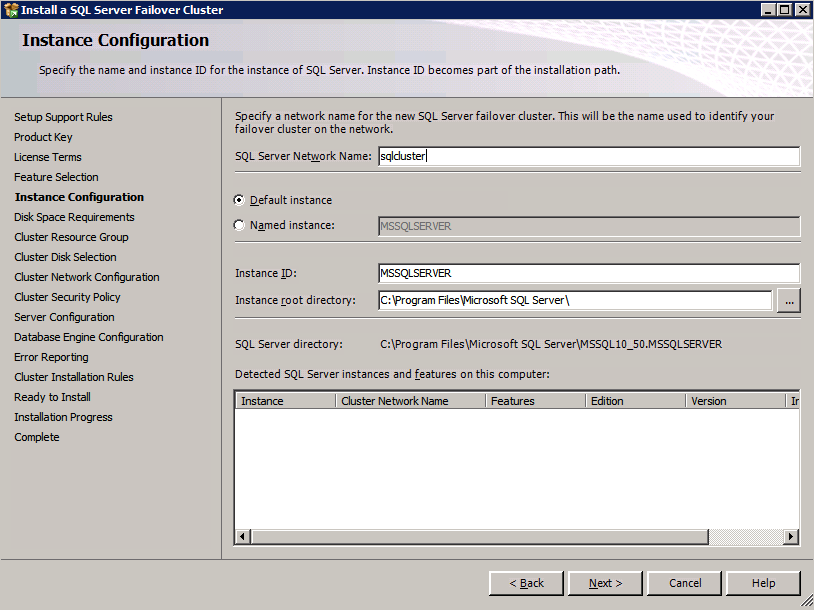
- ตรวจสอบ การกำหนดค่าโหนดคลัสเตอร์ และคลิก ต่อไป .
- กำหนดค่า .ของคุณ เครือข่ายคลัสเตอร์ โดยเพิ่มที่อยู่ IP รอง “ที่สาม” สำหรับอินสแตนซ์ SQL ของคุณและคลิก ต่อไป . คลิก ใช่ เพื่อดำเนินการกำหนดค่าหลายซับเน็ต
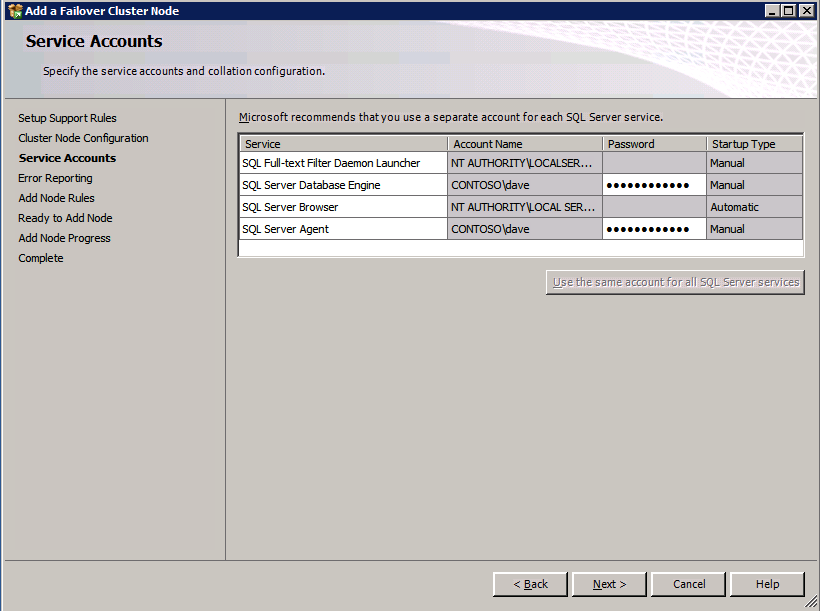
- เข้า รหัสผ่าน สำหรับบัญชีบริการและคลิก ต่อไป .
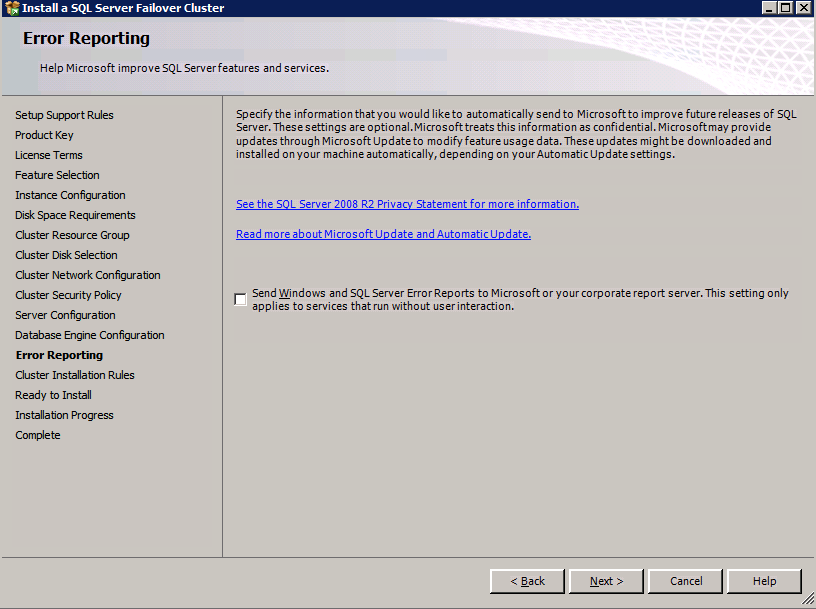
- บน การรายงานข้อผิดพลาด โต้ตอบ คลิก ต่อไป .
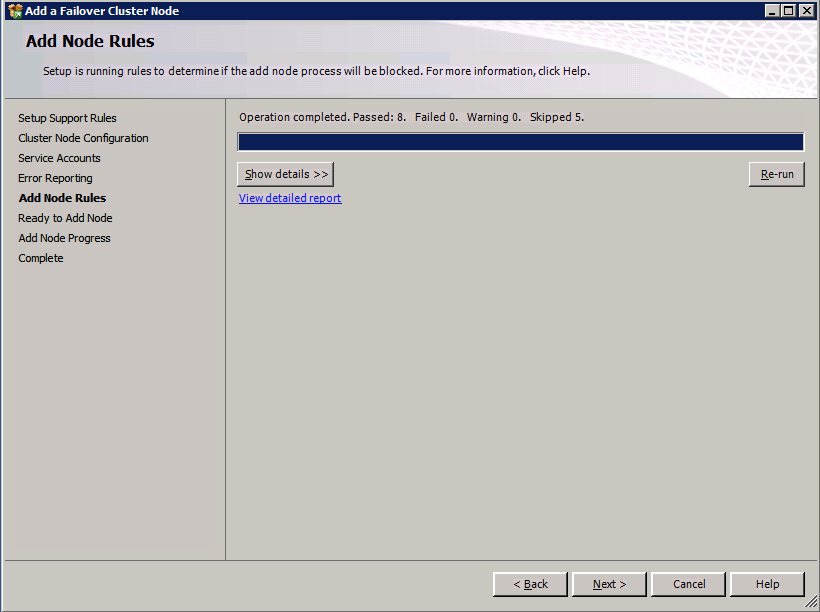
- บน เพิ่มกฎโหนด ไดอะล็อก คำเตือนการทำงานที่ข้ามไปสามารถละเว้นได้ คลิก ต่อไป .
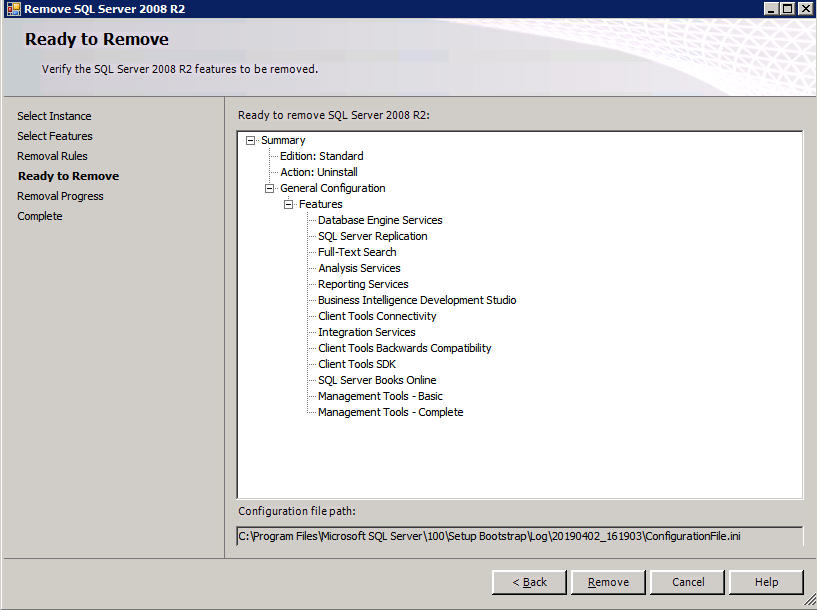
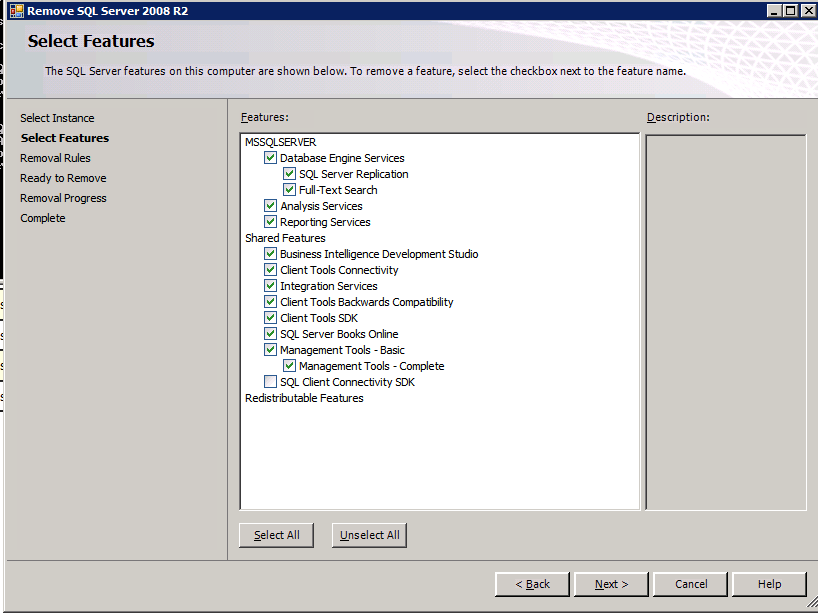
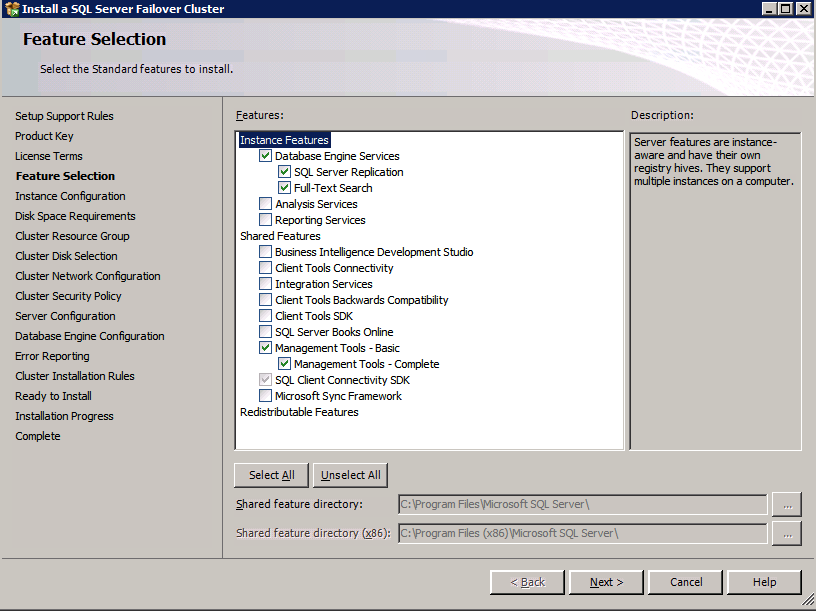
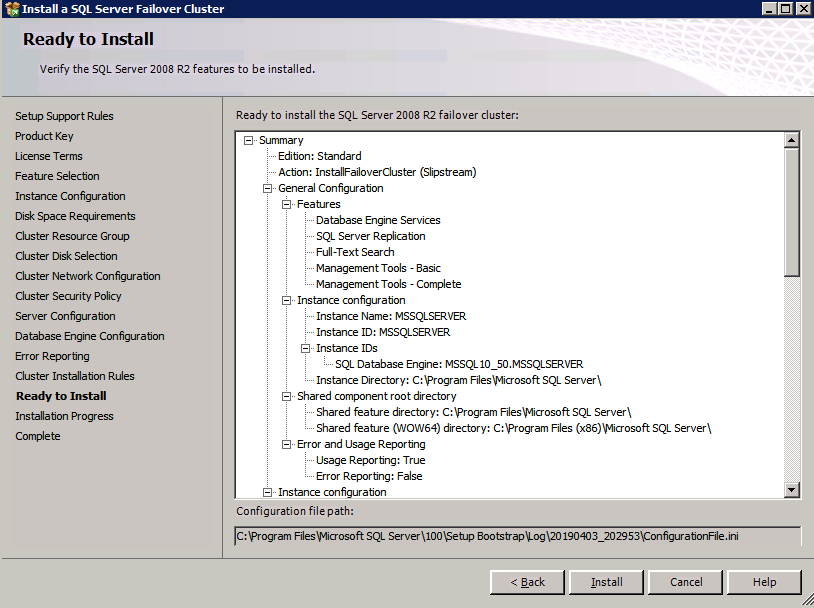
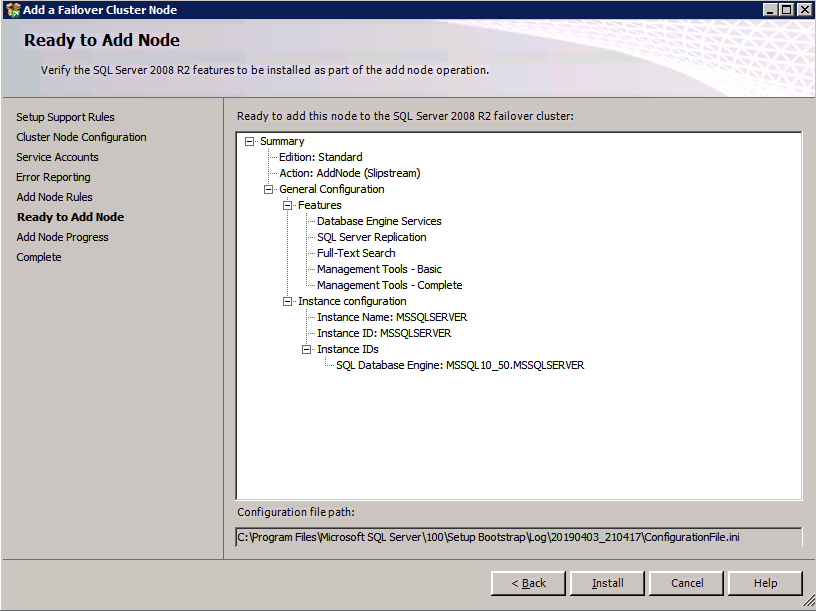
- ตรวจสอบคุณสมบัติและคลิก ติดตั้ง .
- คลิก ปิด I เพื่อสิ้นสุดขั้นตอนการติดตั้ง
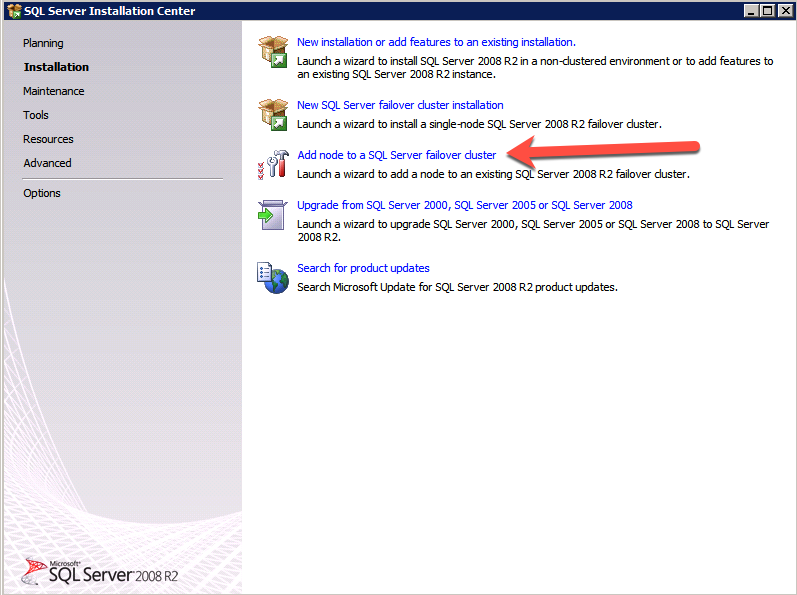
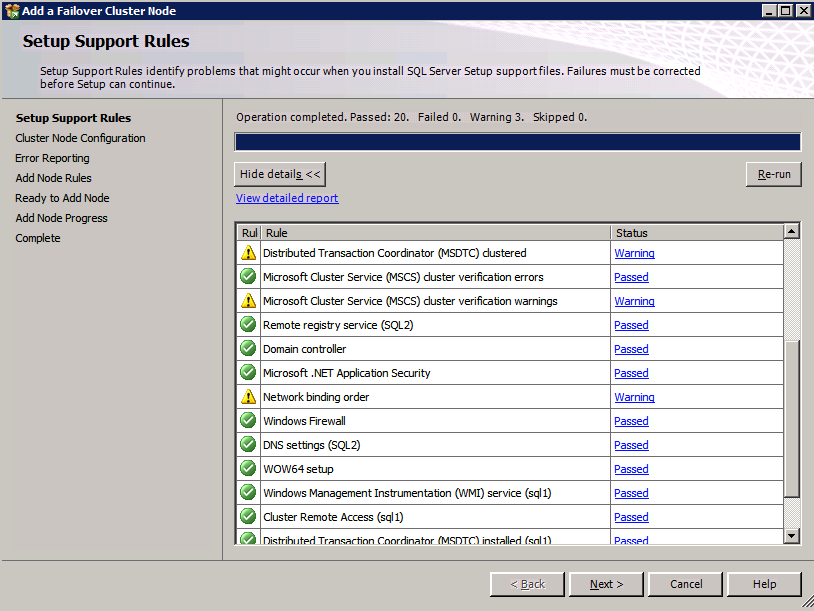
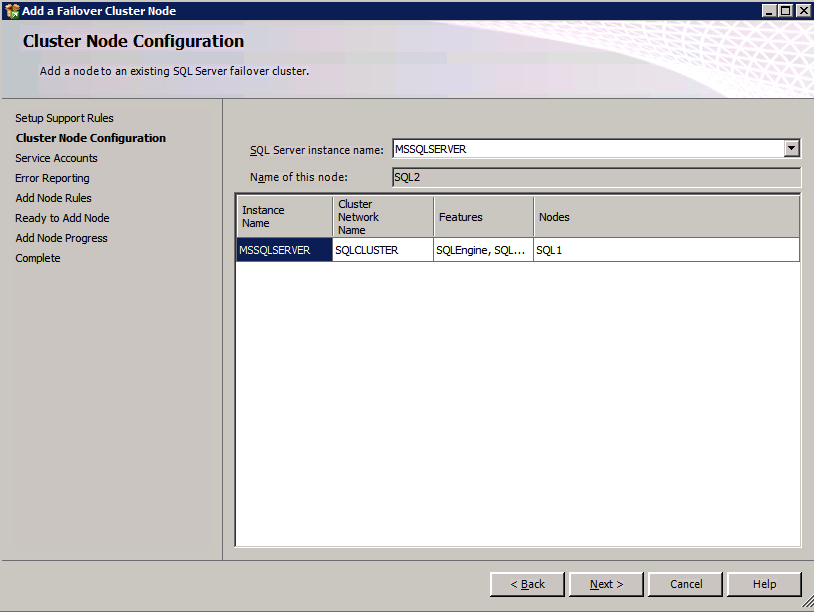
ติดตั้ง SQL บนอินสแตนซ์ SQL ที่สอง การติดตั้งอินสแตนซ์ SQL ที่สองจะคล้ายกับอินสแตนซ์แรก
- บนเซิร์ฟเวอร์ SQL ให้สร้างไดรฟ์เครือข่ายและแนบกับโฟลเดอร์ที่ใช้ร่วมกันบนตัวควบคุมโดเมนตามที่อธิบายไว้ข้างต้นสำหรับเซิร์ฟเวอร์ SQL ตัวแรก
- เมื่อติดตั้งโปรแกรมติดตั้ง .iso แล้ว ให้เรียกใช้ การตั้งค่า SQL อีกครั้งจากบรรทัดคำสั่งเพื่อข้าม ตรวจสอบความถูกต้อง เปิด สั่งการ หน้าต่าง เรียกดูของคุณ ไดเร็กทอรีการติดตั้ง SQL และพิมพ์คำสั่งต่อไปนี้:
ตั้งค่า /SkipRules=Cluster_VerifyForErrors /Action=AddNode /INSTANCENAME=”MSSQLSERVER” ( บันทึก : นี่ถือว่าคุณติดตั้งอินสแตนซ์เริ่มต้นบนโหนดแรก)
- บน ตั้งค่ากฎการสนับสนุน , คลิก ตกลง .
- บน รหัสสินค้า โต้ตอบ ป้อนของคุณ รหัสสินค้า และคลิก ต่อไป .
- บน เงื่อนไขใบอนุญาต โต้ตอบ ยอมรับ ข้อตกลง และคลิก ต่อไป .
- บน อัพเดทสินค้า โต้ตอบ คลิก ต่อไป .
- บน ตั้งค่าไฟล์สนับสนุน โต้ตอบ คลิก ติดตั้ง .
- บน ตั้งค่ากฎการสนับสนุน โต้ตอบ คุณจะได้รับคำเตือน คลิก ต่อไป ละเว้นข้อความนี้ เนื่องจากเป็นที่คาดหมายในคลัสเตอร์การจัดเก็บข้อมูลแบบหลายไซต์หรือแบบไม่แบ่งใช้
- ตรวจสอบ การกำหนดค่าโหนดคลัสเตอร์ และคลิก ต่อไป .
- กำหนดค่า .ของคุณ เครือข่ายคลัสเตอร์ โดยเพิ่มที่อยู่ IP รอง “ที่สาม” สำหรับอินสแตนซ์ SQL ของคุณและคลิก ต่อไป . คลิก ใช่ เพื่อดำเนินการกำหนดค่าหลายซับเน็ต
- เข้า รหัสผ่าน สำหรับบัญชีบริการและคลิก ต่อไป .
- บน การรายงานข้อผิดพลาด โต้ตอบ คลิก ต่อไป .
- บน เพิ่มกฎโหนด ไดอะล็อก คำเตือนการทำงานที่ข้ามไปสามารถละเว้นได้ คลิก ต่อไป .
- ตรวจสอบคุณสมบัติและคลิก ติดตั้ง .
- คลิก ปิด I เพื่อสิ้นสุดขั้นตอนการติดตั้ง
การกำหนดค่าคลัสเตอร์ทั่วไป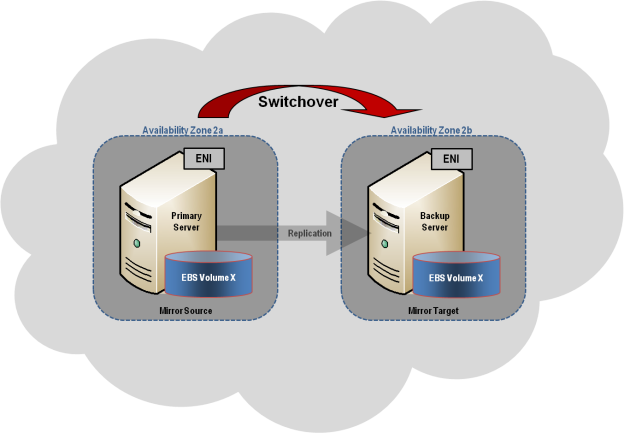 ส่วนนี้อธิบาย a การกำหนดค่าคลัสเตอร์ที่จำลองแบบ 2 โหนดทั่วไป .
ส่วนนี้อธิบาย a การกำหนดค่าคลัสเตอร์ที่จำลองแบบ 2 โหนดทั่วไป .
- การกำหนดค่าเริ่มต้นต้องทำจาก DataKeeper UI ทำงานบนโหนดคลัสเตอร์ใดโหนดหนึ่ง หากไม่สามารถเรียกใช้ DataKeeper UI บนโหนดคลัสเตอร์ได้ เช่น เมื่อเรียกใช้ DataKeeper บนเซิร์ฟเวอร์ Windows Core เท่านั้น ให้ติดตั้ง DataKeeper UI บนคอมพิวเตอร์ทุกเครื่องที่ใช้ Windows XP หรือสูงกว่า และปฏิบัติตามคำแนะนำใน หลักเท่านั้น ส่วนสำหรับการสร้างมิเรอร์และการลงทะเบียนทรัพยากรคลัสเตอร์ผ่านบรรทัดคำสั่ง
- เมื่อ DataKeeper UI ทำงาน เชื่อมต่อกับแต่ละโหนด ในคลัสเตอร์
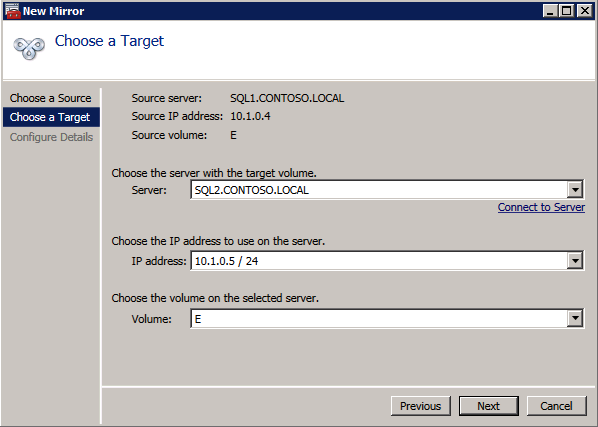
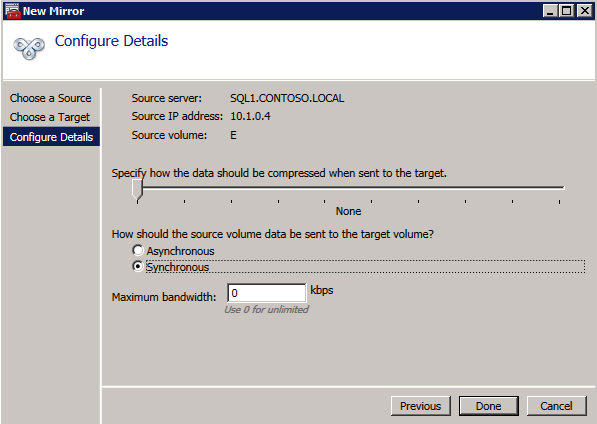
- สร้างงาน โดยใช้ DataKeeper UI กระบวนการนี้สร้างมิเรอร์และเพิ่มทรัพยากร DataKeeper Volume ไปยังที่เก็บข้อมูลที่มีอยู่
! สำคัญ: ทำให้เเน่นอน ชื่อเครือข่ายเสมือน สำหรับ การเชื่อมต่อ NIC เหมือนกันในโหนดคลัสเตอร์ทั้งหมด
- หากต้องการกระจกเพิ่มเติม คุณสามารถ เพิ่มกระจกเงาให้กับงาน .
- กับ ปริมาณ DataKeeper ตอนนี้ใน พื้นที่เก็บข้อมูลที่มีอยู่ คุณสามารถสร้างทรัพยากรคลัสเตอร์ (SQL, File Server เป็นต้น) ได้ในลักษณะเดียวกับที่มีทรัพยากรดิสก์ที่ใช้ร่วมกันในคลัสเตอร์ โปรดดูเอกสารประกอบของ Microsoft สำหรับข้อมูลเพิ่มเติมนอกเหนือจากข้างต้นสำหรับคำแนะนำในการกำหนดค่าคลัสเตอร์ทีละขั้นตอน
การเชื่อมต่อกับคลัสเตอร์ (เสมือน) IPs นอกจาก IP หลักและ IP รองแล้ว คุณจะต้องกำหนดค่าที่อยู่ IP เสมือนใน Huawei Cloud เพื่อให้สามารถกำหนดเส้นทางไปยังโหนดที่ใช้งานอยู่ได้
- จาก รายการบริการ ดรอปดาวน์ เลือก เซิร์ฟเวอร์คลาวด์ยืดหยุ่น .
- คลิกที่อินสแตนซ์ SQL ที่คุณต้องการเพิ่มที่อยู่ IP เสมือนของคลัสเตอร์ (หนึ่งรายการสำหรับ MSDTC และอีกรายการสำหรับ SQL Failover Cluster)
- เลือก NIC > จัดการที่อยู่ IP เสมือน .
- คลิกที่ กำหนดที่อยู่ IP เสมือน และเลือก คู่มือ ป้อนที่อยู่ IP ที่อยู่ภายในช่วงซับเน็ตสำหรับอินสแตนซ์ (เช่น สำหรับ 15.0.1.25 ให้ป้อน 15.0.1.26) คลิก ตกลง .
- คลิกที่ มากกว่า ดรอปดาวน์บนแถวที่อยู่ IP แล้วเลือก ผูกกับเซิร์ฟเวอร์ ให้เลือกทั้งเซิร์ฟเวอร์ที่จะผูกที่อยู่ IP และการ์ด NIC
- ใช้ขั้นตอนที่ 4 และ 5 เดียวกันสำหรับ IP เสมือน MSDTC และ SQLFC
- คลิก ตกลง เพื่อบันทึกงานของคุณ
การจัดการ เมื่อไดรฟ์ข้อมูล DataKeeper ลงทะเบียนกับ Windows Server Failover Clustering แล้ว การจัดการทั้งหมดของไดรฟ์ข้อมูลนั้นจะทำผ่านอินเทอร์เฟซ Windows Server Failover Clustering ฟังก์ชันการจัดการทั้งหมดมีอยู่ใน DataKeeper . ตามปกติ จะถูกปิดการใช้งาน บนโวลุ่มใดๆ ที่อยู่ภายใต้การควบคุมคลัสเตอร์ ทรัพยากรคลัสเตอร์ DataKeeper Volume จะควบคุมทิศทางมิเรอร์แทน ดังนั้นเมื่อ DataKeeper Volume ออนไลน์บนโหนด โหนดนั้นจะกลายเป็นแหล่งที่มาของมิเรอร์ คุณสมบัติของทรัพยากรคลัสเตอร์ DataKeeper Volume ยังแสดงข้อมูลการมิเรอร์พื้นฐาน เช่น แหล่งที่มา เป้าหมาย ประเภท และสถานะของมิเรอร์
การแก้ไขปัญหา ใช้แหล่งข้อมูลต่อไปนี้เพื่อช่วยแก้ไขปัญหา:
- การแก้ไขปัญหา ส่วนปัญหา
- สำหรับลูกค้าที่มีสัญญาการสนับสนุน – http://us.sios.com/support/overview/
- สำหรับลูกค้าประเมินเท่านั้น – การสนับสนุนก่อนการขาย
แหล่งข้อมูลเพิ่มเติม: ทีละขั้นตอน: การกำหนดค่า 2-Node Multi-Site Cluster บน Windows Server 2008 R2 – ส่วนที่ 1 — http://clusteringformeremortals.com/2009/09/15/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2%80%93 -ส่วนที่ 1/ ทีละขั้นตอน: การกำหนดค่า 2-Node Multi-Site Cluster บน Windows Server 2008 R2 – ตอนที่ 3 — http://clusteringformeremortals.com/2009/10/07/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2%80%93 -ส่วน-3/

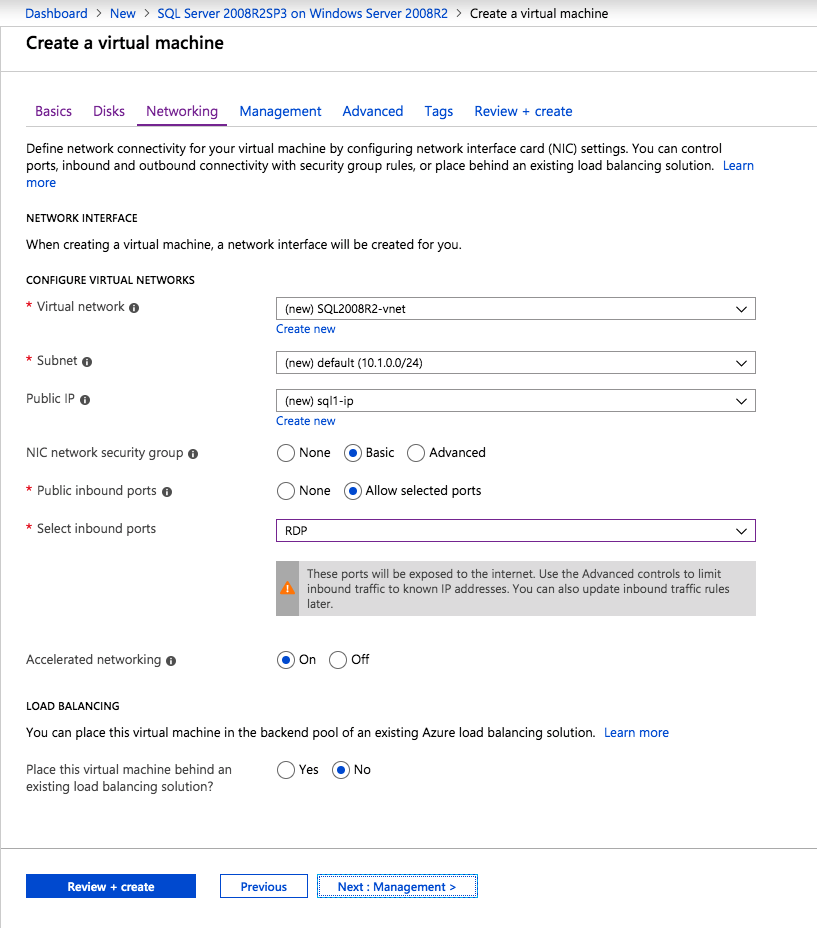
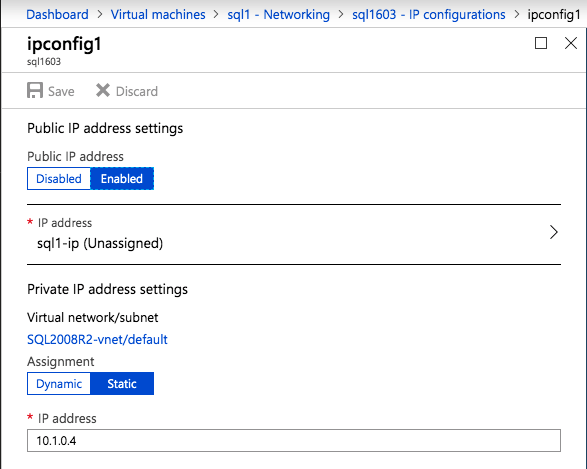

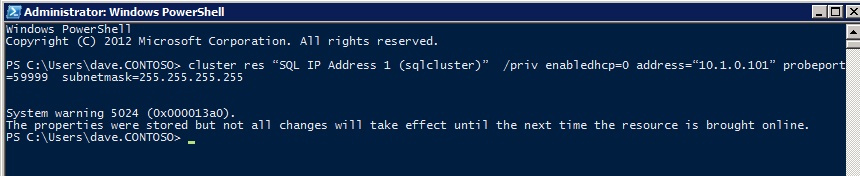
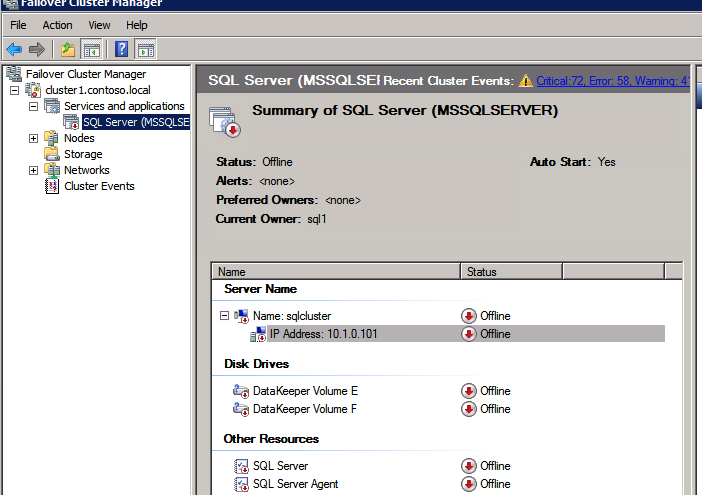
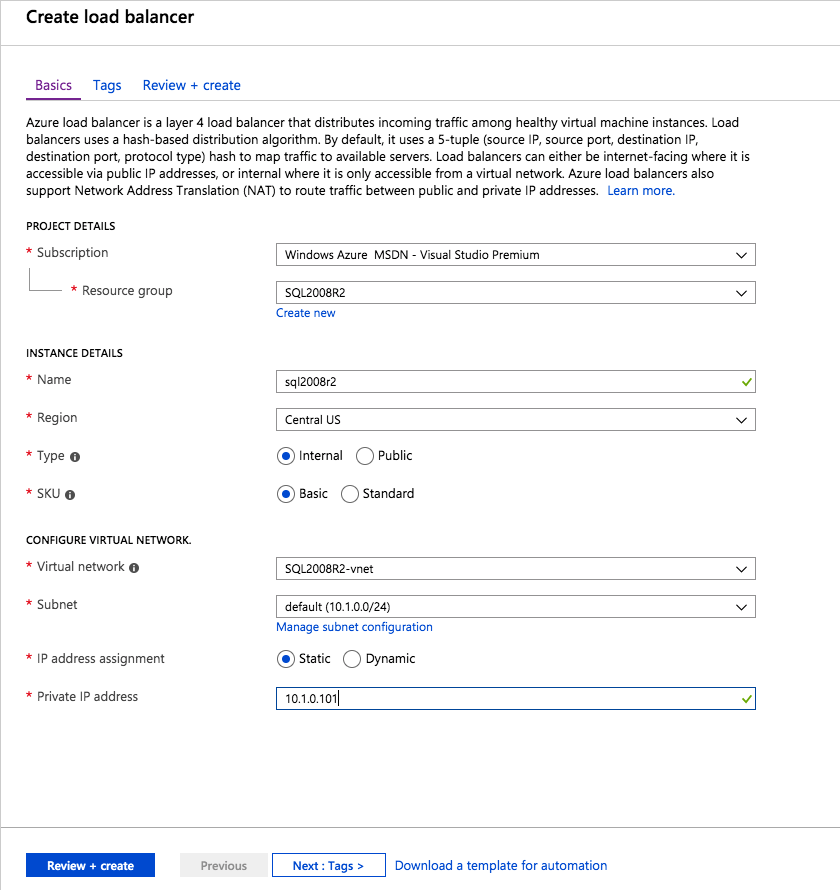
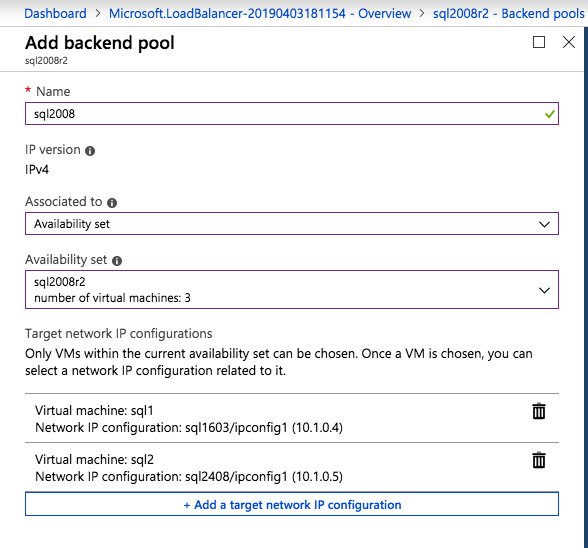
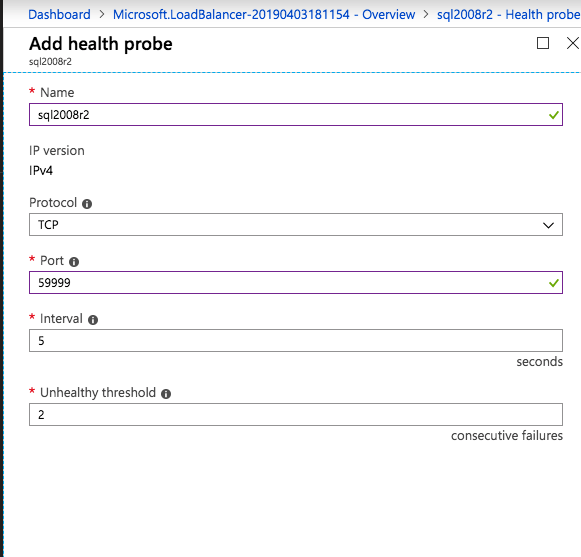
 ต่อไปเราจะต้องเพิ่มโพรบอื่นเนื่องจากอินสแตนซ์อาจทำงานบนเซิร์ฟเวอร์อื่น ดังที่แสดงด้านล่างฉันเพิ่มโพรบที่โพรบพอร์ต 59998 (แทนที่จะเป็น 59999 ปกติ) เราจะต้องตรวจสอบให้แน่ใจว่ากฎใหม่อ้างอิงการสอบสวนนี้ เราจะต้องจำหมายเลขพอร์ตนั้นเนื่องจากเราจะต้องอัปเดตที่อยู่ IP ที่เชื่อมโยงกับอินสแตนซ์นี้ในระหว่างขั้นตอนสุดท้ายของกระบวนการนี้
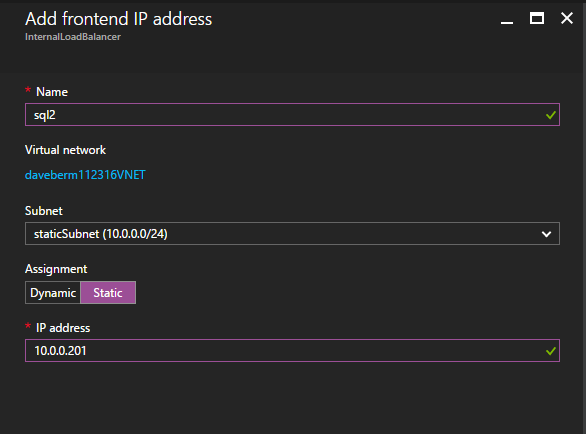
ต่อไปเราจะต้องเพิ่มโพรบอื่นเนื่องจากอินสแตนซ์อาจทำงานบนเซิร์ฟเวอร์อื่น ดังที่แสดงด้านล่างฉันเพิ่มโพรบที่โพรบพอร์ต 59998 (แทนที่จะเป็น 59999 ปกติ) เราจะต้องตรวจสอบให้แน่ใจว่ากฎใหม่อ้างอิงการสอบสวนนี้ เราจะต้องจำหมายเลขพอร์ตนั้นเนื่องจากเราจะต้องอัปเดตที่อยู่ IP ที่เชื่อมโยงกับอินสแตนซ์นี้ในระหว่างขั้นตอนสุดท้ายของกระบวนการนี้  ตอนนี้เราจำเป็นต้องเพิ่มกฎใหม่สองข้อใน ILB เพื่อให้ปริมาณข้อมูลตรงที่กำหนดไว้สำหรับ SQL ลำดับที่ 2 นี้ แน่นอนว่าเราต้องเพิ่มกฎเพื่อเปลี่ยนเส้นทางพอร์ต TCP 1440 (พอร์ตที่ฉันใช้สำหรับอินสแตนซ์ที่มีชื่อของ SQL) แต่เนื่องจากตอนนี้เราใช้อินสแตนซ์ที่ตั้งชื่อแล้วเราจะต้องมีพอร์ตเพื่อรองรับบริการเบราว์เซอร์เซิร์ฟเวอร์ SQL พอร์ต UDP 1434 ในภาพด้านล่างแสดงกฎสำหรับบริการเซิร์ฟเวอร์เบราว์เซอร์ SQL โปรดทราบว่าที่อยู่ IP ของ Front End อ้างอิงที่อยู่ FrontendIP ใหม่ (10.0.0.201), พอร์ต UDP 1434 สำหรับทั้งพอร์ตและพอร์ตแบ็กเอนด์ ในกลุ่มคุณจะต้องระบุเซิร์ฟเวอร์สองตัวในคลัสเตอร์และในที่สุดให้แน่ใจว่าคุณเลือก Health Probe ใหม่ที่เราเพิ่งสร้างขึ้น
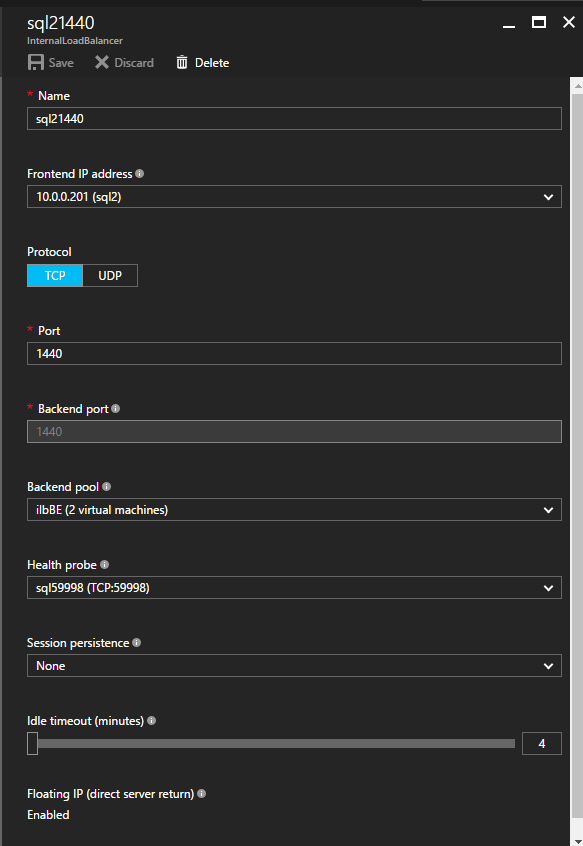
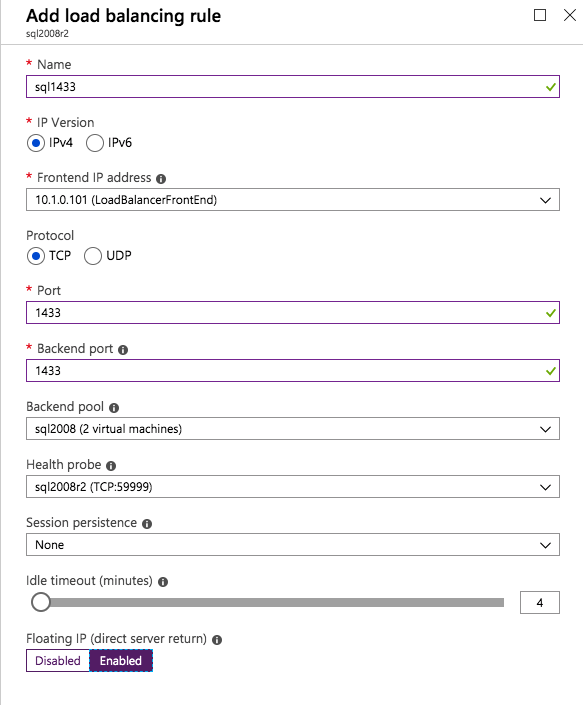
ตอนนี้เราจำเป็นต้องเพิ่มกฎใหม่สองข้อใน ILB เพื่อให้ปริมาณข้อมูลตรงที่กำหนดไว้สำหรับ SQL ลำดับที่ 2 นี้ แน่นอนว่าเราต้องเพิ่มกฎเพื่อเปลี่ยนเส้นทางพอร์ต TCP 1440 (พอร์ตที่ฉันใช้สำหรับอินสแตนซ์ที่มีชื่อของ SQL) แต่เนื่องจากตอนนี้เราใช้อินสแตนซ์ที่ตั้งชื่อแล้วเราจะต้องมีพอร์ตเพื่อรองรับบริการเบราว์เซอร์เซิร์ฟเวอร์ SQL พอร์ต UDP 1434 ในภาพด้านล่างแสดงกฎสำหรับบริการเซิร์ฟเวอร์เบราว์เซอร์ SQL โปรดทราบว่าที่อยู่ IP ของ Front End อ้างอิงที่อยู่ FrontendIP ใหม่ (10.0.0.201), พอร์ต UDP 1434 สำหรับทั้งพอร์ตและพอร์ตแบ็กเอนด์ ในกลุ่มคุณจะต้องระบุเซิร์ฟเวอร์สองตัวในคลัสเตอร์และในที่สุดให้แน่ใจว่าคุณเลือก Health Probe ใหม่ที่เราเพิ่งสร้างขึ้น 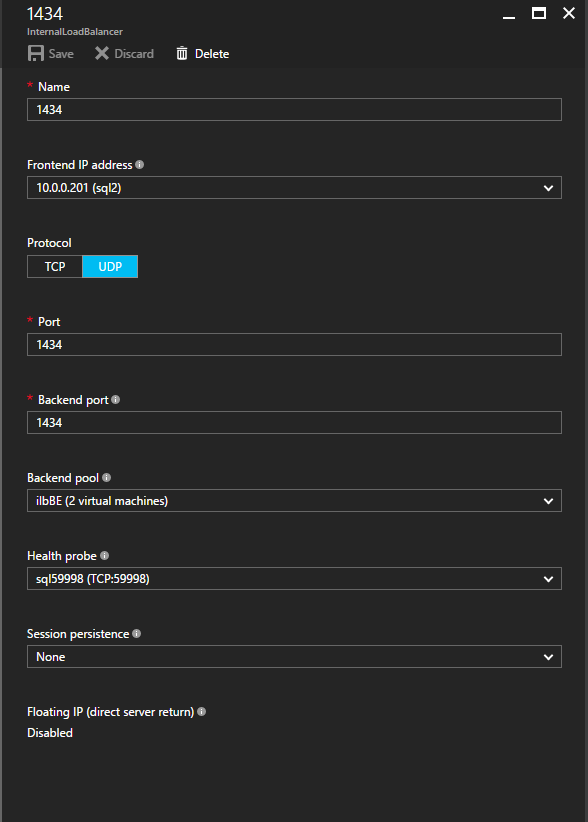 ตอนนี้เราจะเพิ่มกฎสำหรับ TCP / 1440 ดังแสดงในภาพด้านล่างเพิ่มกฎใหม่สำหรับพอร์ต TCP 1440 หรือพอร์ตใด ๆ ที่ถูกล็อคไว้สำหรับอินสแตนซ์ที่มีชื่อของ SQL Server ตรวจสอบให้แน่ใจว่าได้เลือกที่อยู่ IP FrontEnd ใหม่และ Health Probe ใหม่ (59998) ตรวจสอบให้แน่ใจด้วยว่า IP แบบลอยตัว (การส่งคืนเซิร์ฟเวอร์โดยตรง) ถูกเปิดใช้งาน
ตอนนี้เราจะเพิ่มกฎสำหรับ TCP / 1440 ดังแสดงในภาพด้านล่างเพิ่มกฎใหม่สำหรับพอร์ต TCP 1440 หรือพอร์ตใด ๆ ที่ถูกล็อคไว้สำหรับอินสแตนซ์ที่มีชื่อของ SQL Server ตรวจสอบให้แน่ใจว่าได้เลือกที่อยู่ IP FrontEnd ใหม่และ Health Probe ใหม่ (59998) ตรวจสอบให้แน่ใจด้วยว่า IP แบบลอยตัว (การส่งคืนเซิร์ฟเวอร์โดยตรง) ถูกเปิดใช้งาน