ทีละขั้นตอน: วิธีกำหนดค่าคลัสเตอร์การโอนย้าย Linux ใน Microsoft Azure IaaS โดยไม่ใช้ที่เก็บข้อมูลร่วมกัน #azure #sanless
ในคู่มือทีละขั้นตอนนี้ผมจะนำคุณผ่านขั้นตอนทั้งหมดที่จำเป็นในการกำหนดค่าคลัสเตอร์ MySQL แบบ 2 โหนดพร้อมด้วยเซิร์ฟเวอร์พยานใน Microsoft Azure IaaS (Infrastructure as a Service) คู่มือนี้รวมทั้งภาพหน้าจอคำสั่งเชลล์และข้อมูลโค้ดตามความเหมาะสม ฉันคิดว่าคุณค่อนข้างคุ้นเคยกับ Microsoft Azure แล้วและมีบัญชี Azure กับการสมัครสมาชิกที่เกี่ยวข้อง ถ้าไม่คุณสามารถลงชื่อสมัครใช้บัญชีฟรีได้ในวันนี้ ฉันจะสมมติว่าคุณมีทักษะในการบริหารระบบลินุกซ์ขั้นพื้นฐานและเข้าใจแนวคิด failover clustering พื้นฐานเช่น Virtual IPs เป็นต้น
ข้อควรระวัง: Azure เป็นเป้าหมายที่เคลื่อนที่อย่างรวดเร็ว มันเริ่มดีขึ้นเรื่อย ๆ ทุกวัน! ดังนั้นคุณลักษณะ / หน้าจอ / ปุ่มจึงต้องเปลี่ยนแปลงไปตามช่วงเวลาเพื่อให้ประสบการณ์ของคุณอาจแตกต่างจากที่คุณเห็นด้านล่างเล็กน้อย แม้ว่าคู่มือนี้จะแสดงวิธีการสร้างฐานข้อมูล MySQL ที่พร้อมให้บริการคุณสามารถปรับข้อมูลและกระบวนการนี้เพื่อปกป้องโปรแกรมหรือฐานข้อมูลอื่น ๆ เช่น SAP, Oracle, PostgreSQL, NFS file servers และอื่น ๆ ได้ นี่คือขั้นตอนระดับสูงเพื่อสร้างฐานข้อมูล MySQL ที่พร้อมใช้งานภายใน Microsoft Azure IaaS:
- สร้างกลุ่มทรัพยากร
- สร้างเครือข่ายเสมือนจริง
- สร้างบัญชีที่เก็บข้อมูล
- สร้างเครื่องเสมือนในชุดความพร้อมใช้งาน
- ตั้งค่าที่อยู่ IP แบบคงที่ของ VM
- เพิ่มดิสก์ข้อมูลลงในโหนดคลัสเตอร์
- สร้างกฎความปลอดภัยขาเข้าเพื่อให้เข้าถึง VNC
- การกำหนดค่าระบบปฏิบัติการ Linux
- ติดตั้งและกำหนดค่า MySQL
- ติดตั้งและกำหนดค่าคลัสเตอร์
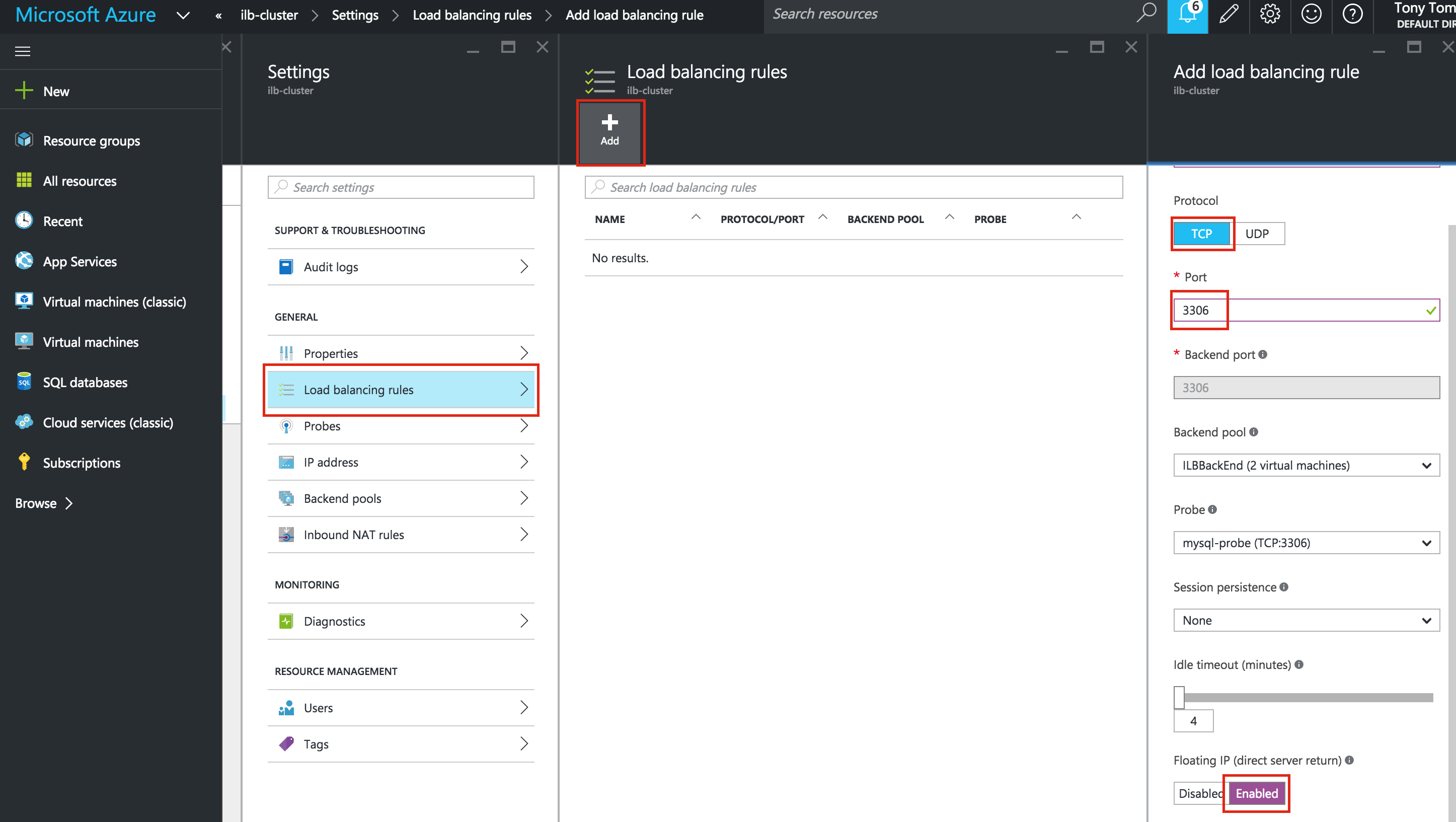
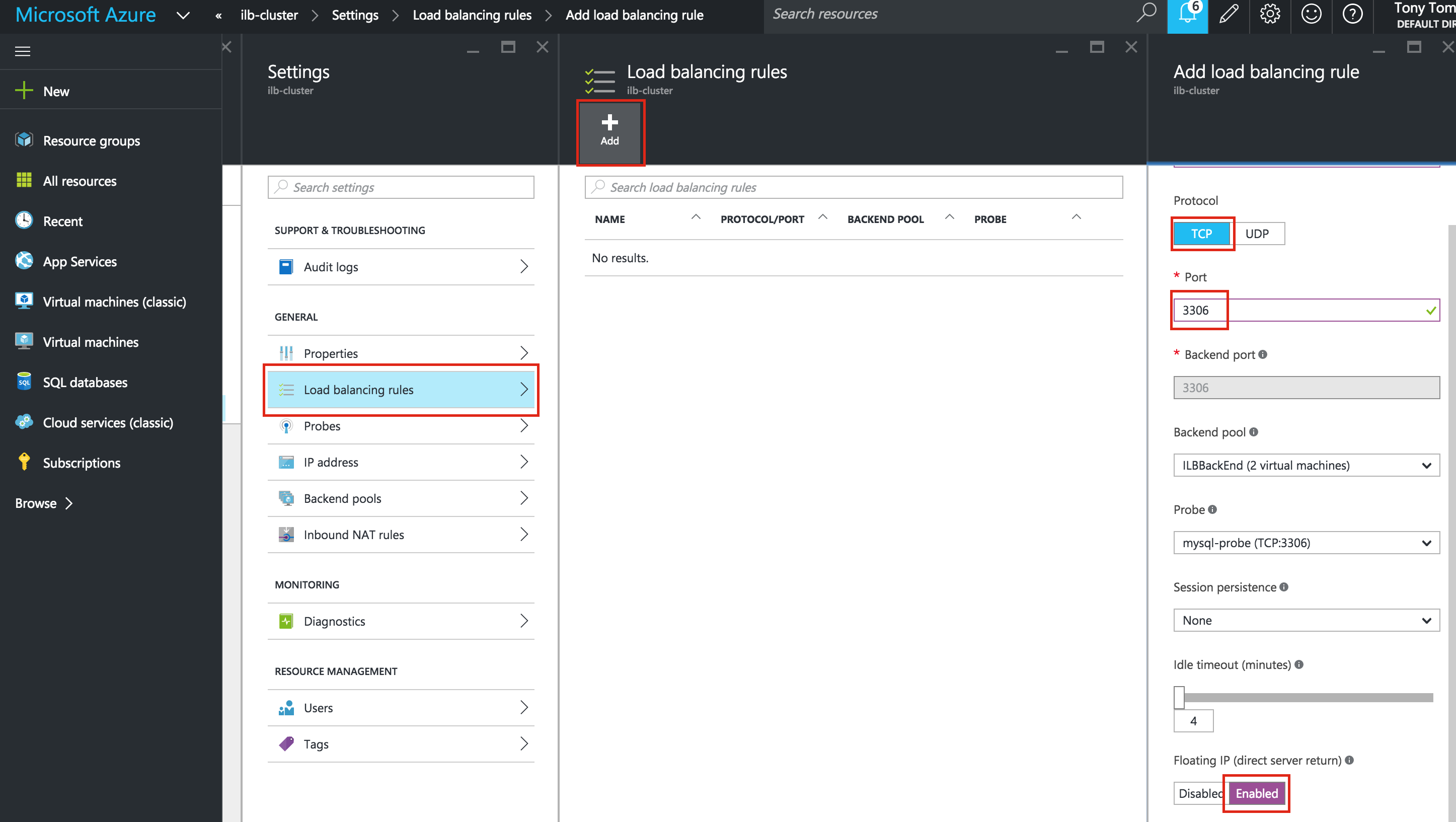
- สร้าง Balancer โหลดภายใน
- ทดสอบ Cluster Connectivity
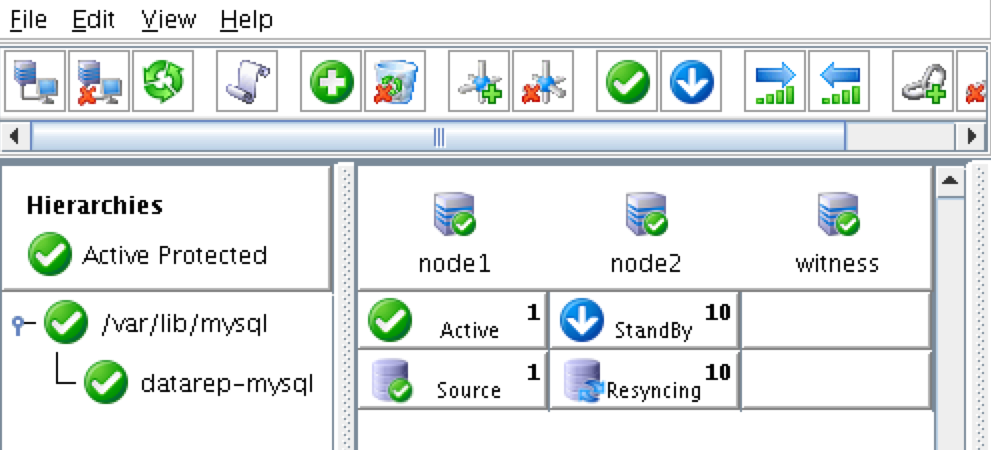
ภาพรวม
บทความนี้จะอธิบายขั้นตอนการตั้งค่า Linux Failover Cluster ใน Microsoft Azure IaaS โดยไม่ใช้ Shared Storage จะอธิบายถึงวิธีการสร้างคลัสเตอร์ภายในพื้นที่ Azure อันเดียว โหนดคลัสเตอร์ (โหนด 1, โหนด 2 และเซิร์ฟเวอร์พยาน) จะอยู่ในชุดความพร้อมใช้งาน (3 โดเมนและโดเมนการอัปเดตที่แตกต่างกัน) เนื่องจาก Azure Resource Manager (ARM) ใหม่ เราจะสร้างแหล่งข้อมูลทั้งหมดโดยใช้ Azure Resource Manager ใหม่ การกำหนดค่าจะมีลักษณะดังนี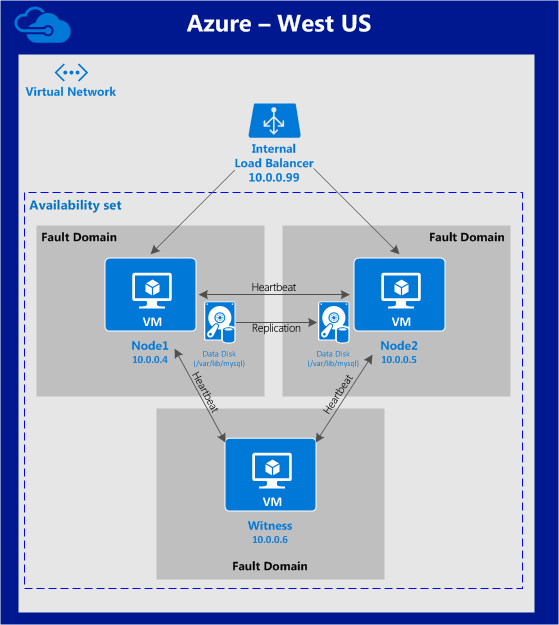 ้: จะใช้ที่อยู่ IP ต่อไปนี้:
้: จะใช้ที่อยู่ IP ต่อไปนี้:
- node1: 10.0.0.4
- node2: 10.0.0.5
- พยาน: 10.0.0.6
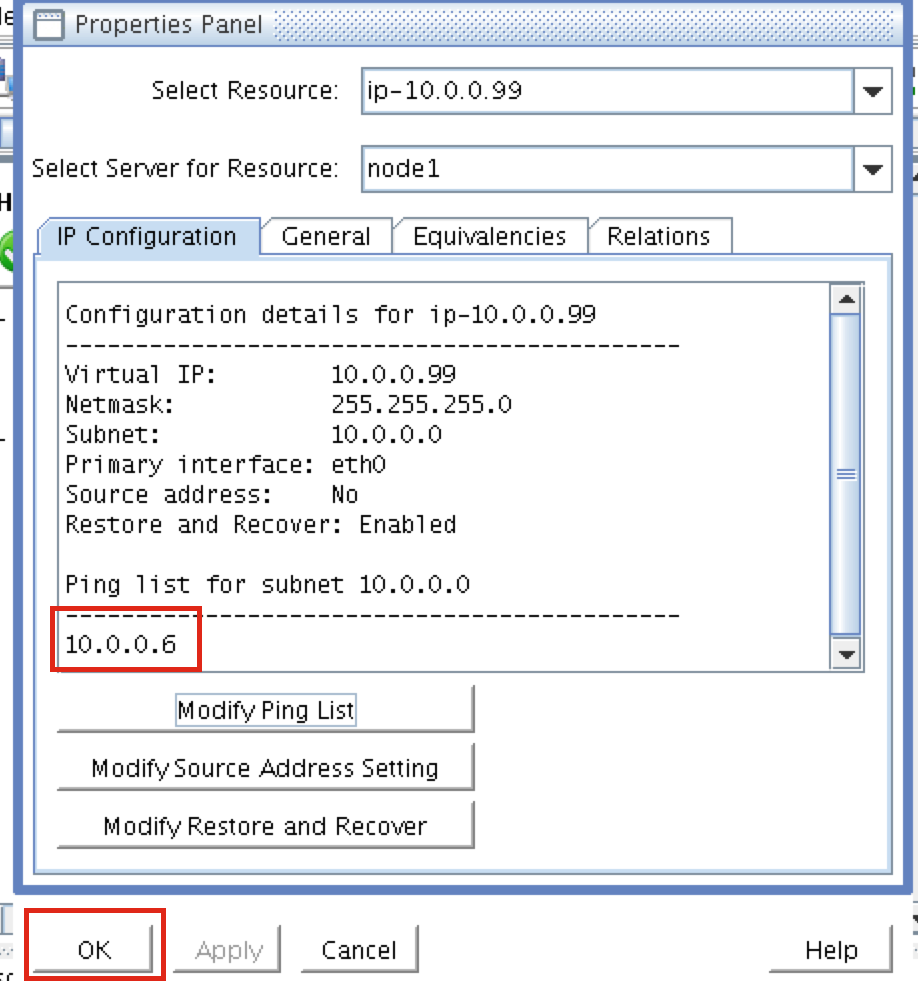
- เสมือน / "ลอย" IP: 10.0.0.99
- พอร์ต MySQL: 3306
สร้างกลุ่มทรัพยากร
ขั้นแรกให้สร้างกลุ่มทรัพยากร กลุ่มทรัพยากรของคุณจะจบลงด้วยเนื้อหาทั้งหมดที่เกี่ยวข้องกับการใช้งานคลัสเตอร์ของเรา: เครื่องเสมือนเครือข่ายเสมือนบัญชีเก็บข้อมูล ฯลฯ ที่นี่เราจะเรียกกลุ่มทรัพยากร "resource-cluster-resources" ที่สร้างขึ้นใหม่  โปรดระวังเมื่อเลือกภูมิภาคของคุณ ทรัพยากรทั้งหมดของคุณจะต้องอาศัยอยู่ในภูมิภาคเดียวกัน ที่นี่เราจะปรับใช้ทุกสิ่งทุกอย่างในภูมิภาค "West US":
โปรดระวังเมื่อเลือกภูมิภาคของคุณ ทรัพยากรทั้งหมดของคุณจะต้องอาศัยอยู่ในภูมิภาคเดียวกัน ที่นี่เราจะปรับใช้ทุกสิ่งทุกอย่างในภูมิภาค "West US": 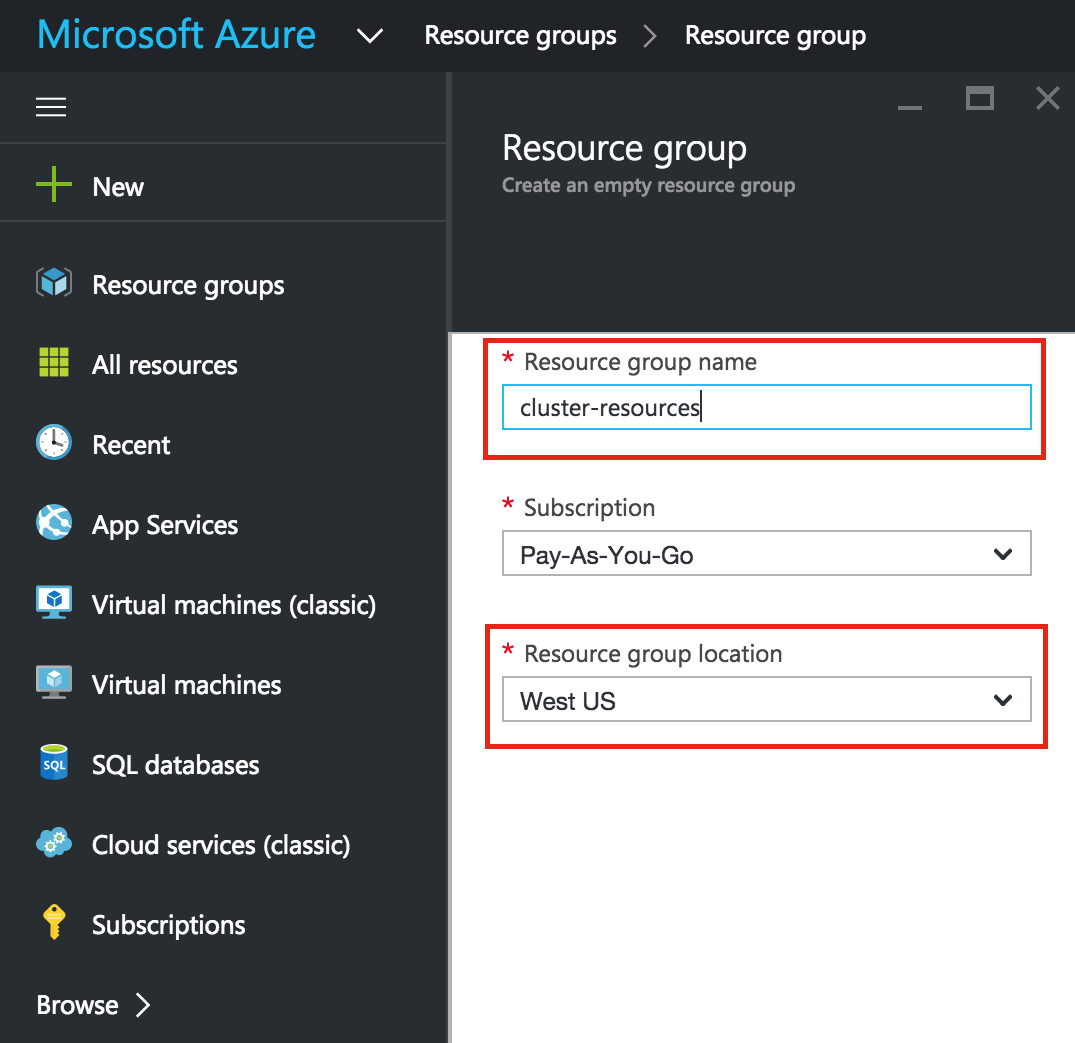
สร้างเครือข่ายเสมือนจริง (VNet)
การสร้างเครือข่ายเสมือนจริงจะเป็นขั้นตอนต่อไปในการกำหนดคอนฟิกคลัสเตอร์ Failover Clustering ใน Microsoft Azure IaaS โดยไม่มีที่เก็บข้อมูลที่ใช้ร่วมกัน เครือข่ายเสมือนเป็นเครือข่ายที่แยกได้ภายในเมฆ Azure ที่ทุ่มเทให้กับคุณ คุณสามารถควบคุมสิ่งต่างๆเช่นบล็อกที่อยู่ IP และเครือข่ายย่อยเส้นทางนโยบายด้านความปลอดภัย (เช่นไฟร์วอลล์) การตั้งค่า DNS และอื่น ๆ คุณจะได้เปิดตัวเครื่องเสมือน (VMs) Azure Iaas ของคุณลงใน Virtual Network ของคุณ  ตรวจสอบให้แน่ใจว่าคุณเลือก Resource Manager เป็นรูปแบบการปรับใช้งานเมื่อคุณได้รับต
ตรวจสอบให้แน่ใจว่าคุณเลือก Resource Manager เป็นรูปแบบการปรับใช้งานเมื่อคุณได้รับต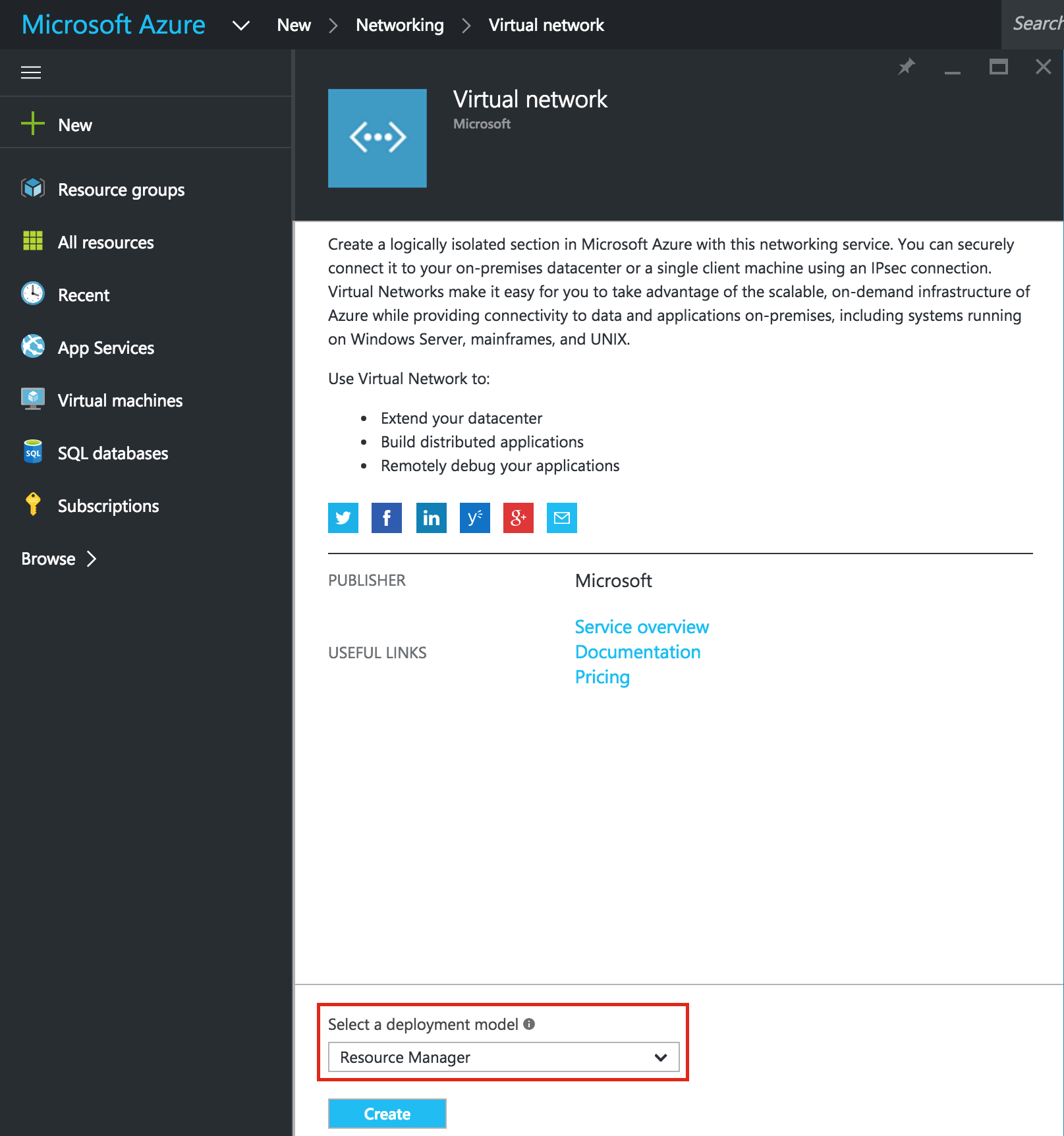 ัวเลือก: ให้ Virtual Network ใหม่เป็นชื่อ ("virtual-network") และตรวจสอบว่าคุณเลือกกลุ่มทรัพยากรที่สร้างขึ้นในขั้นตอนก่อนหน้า (" ทรัพยากร”) เครือข่ายเสมือนของคุณต้องอาศัยอยู่ในภูมิภาคเดียวกับกลุ่มทรัพยากรของคุณ เราจะปล่อยค่า IP Address และ Subnet ให้เป็นค่าเริ่มต้น
ัวเลือก: ให้ Virtual Network ใหม่เป็นชื่อ ("virtual-network") และตรวจสอบว่าคุณเลือกกลุ่มทรัพยากรที่สร้างขึ้นในขั้นตอนก่อนหน้า (" ทรัพยากร”) เครือข่ายเสมือนของคุณต้องอาศัยอยู่ในภูมิภาคเดียวกับกลุ่มทรัพยากรของคุณ เราจะปล่อยค่า IP Address และ Subnet ให้เป็นค่าเริ่มต้น 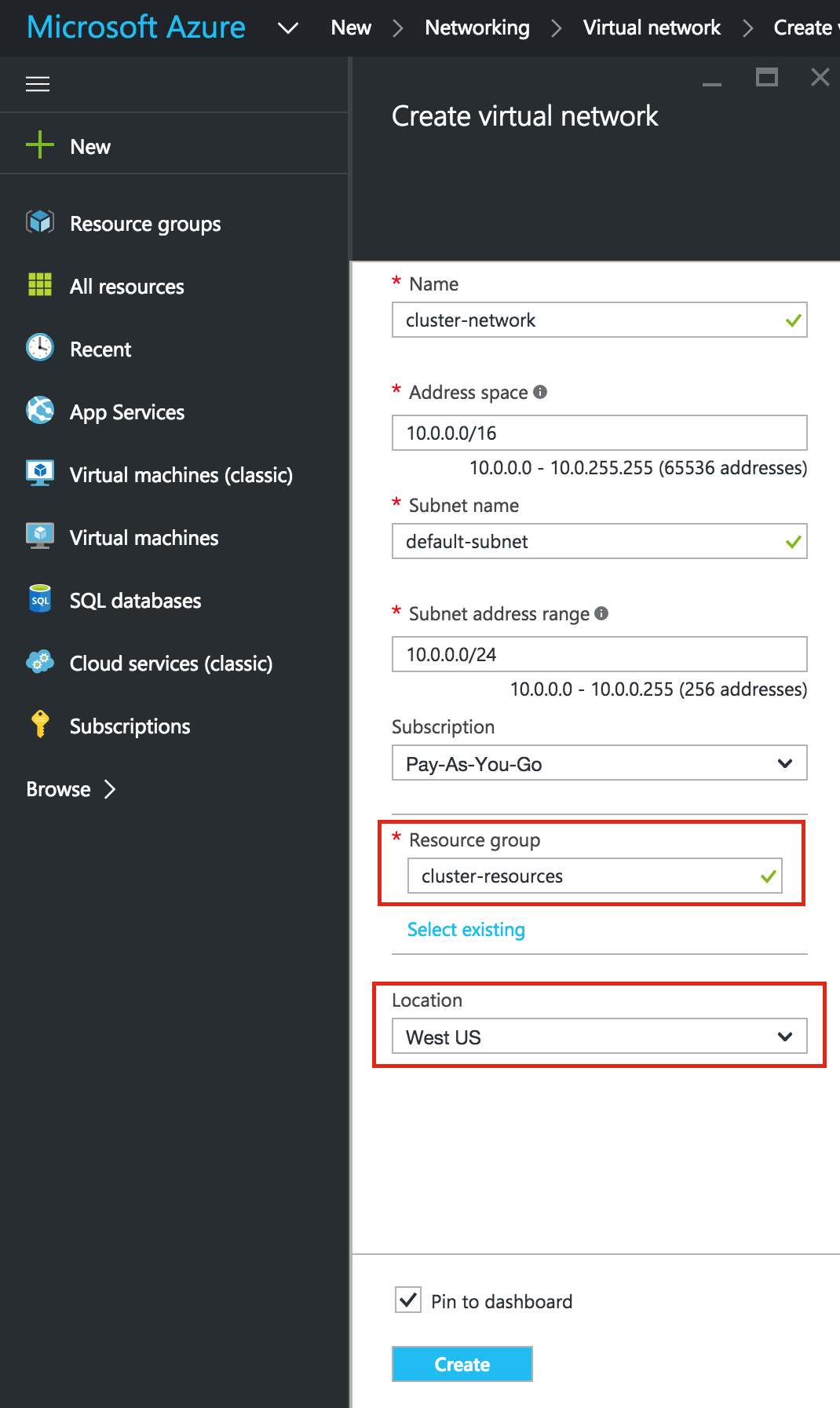
สร้างบัญชีที่เก็บข้อมูล
ก่อนที่คุณจะจัดเตรียมเครื่องเสมือนใด ๆ คุณจะต้องสร้างบัญชีพื้นที่เก็บข้อมูลที่จะจัดเก็บ  อีกครั้งให้แน่ใจว่าคุณเลือก Resource Manager เป็นรูปแบบการปรับใช้ตลอดเวลาที่คุณได้รับตัวเลือก: จากนั้
อีกครั้งให้แน่ใจว่าคุณเลือก Resource Manager เป็นรูปแบบการปรับใช้ตลอดเวลาที่คุณได้รับตัวเลือก: จากนั้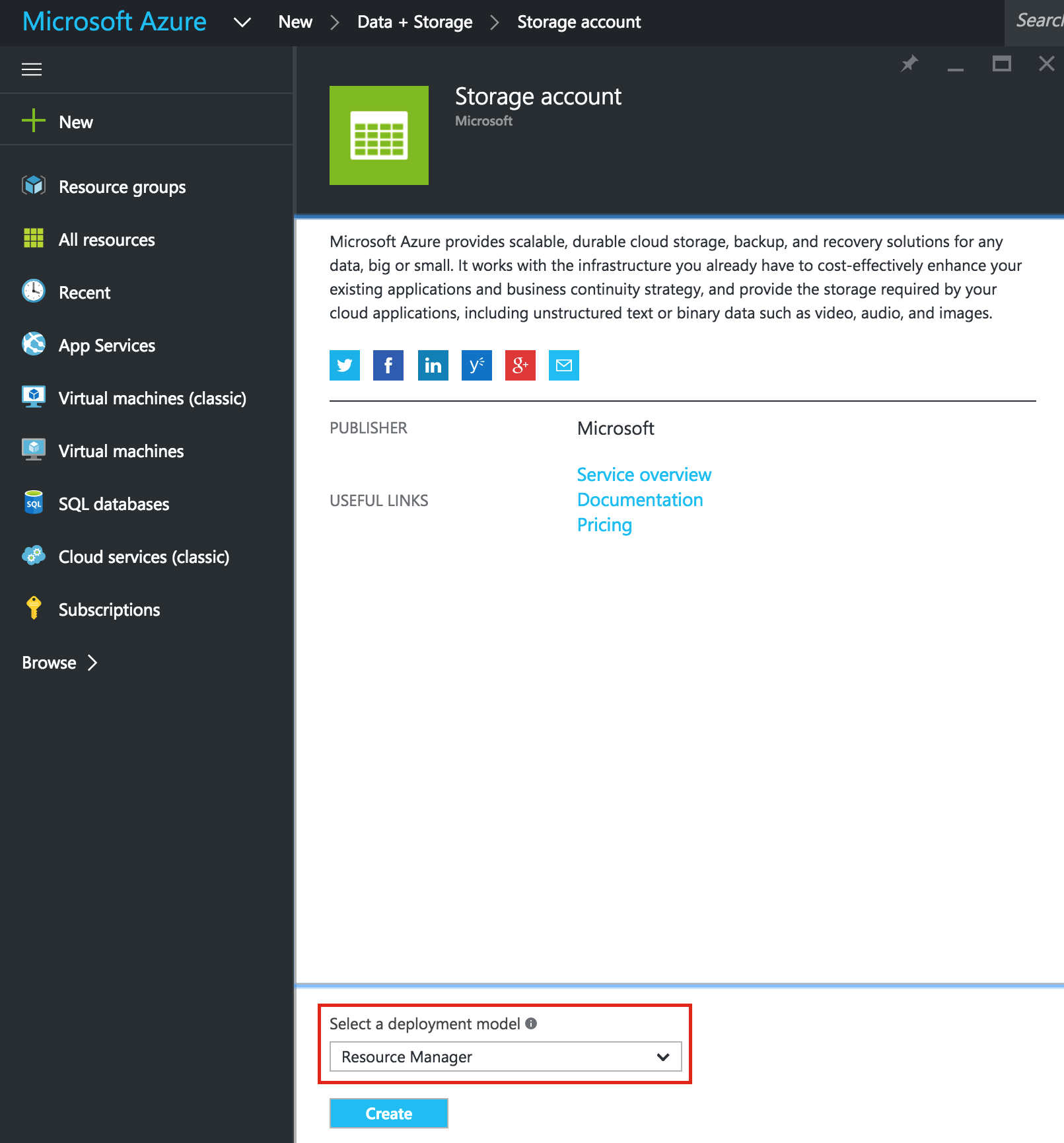 นให้ตั้งชื่อบัญชีพื้นที่เก็บข้อมูลใหม่ของคุณ ชื่อบัญชีพื้นที่เก็บข้อมูลต้องไม่ซ้ำกันใน * ALL * ของ Azure (ทุกๆวัตถุที่คุณเก็บไว้ใน Azure Storage มีที่อยู่ URL ที่ไม่ซ้ำกัน ชื่อบัญชีพื้นที่เก็บข้อมูลจะสร้างโดเมนย่อยของที่อยู่นั้น) ในตัวอย่างนี้ฉันเรียกบัญชีเก็บข้อมูล "linuxclusterstorage" ของฉัน แต่คุณจะต้องเลือกสิ่งที่แตกต่างออกไปในขณะที่คุณตั้งค่าบัญชีของคุณเอง เลือกประเภทพื้นที่เก็บข้อมูลตามความต้องการและงบประมาณของคุณ สำหรับจุดประสงค์ของคู่มือนี้ฉันได้เลือก "Standard-LRS" (กล่าวคือ Redundant) เพื่อลดต้นทุน ตรวจสอบว่าบัญชี Storage ใหม่ของคุณถูกเพิ่มลงในกลุ่มทรัพยากรที่คุณสร้างไว้ในขั้นตอนที่ 1 ("ทรัพยากรคลัสเตอร์") ในตำแหน่งเดียวกัน ("West US" ในตัวอย่างนี้):
นให้ตั้งชื่อบัญชีพื้นที่เก็บข้อมูลใหม่ของคุณ ชื่อบัญชีพื้นที่เก็บข้อมูลต้องไม่ซ้ำกันใน * ALL * ของ Azure (ทุกๆวัตถุที่คุณเก็บไว้ใน Azure Storage มีที่อยู่ URL ที่ไม่ซ้ำกัน ชื่อบัญชีพื้นที่เก็บข้อมูลจะสร้างโดเมนย่อยของที่อยู่นั้น) ในตัวอย่างนี้ฉันเรียกบัญชีเก็บข้อมูล "linuxclusterstorage" ของฉัน แต่คุณจะต้องเลือกสิ่งที่แตกต่างออกไปในขณะที่คุณตั้งค่าบัญชีของคุณเอง เลือกประเภทพื้นที่เก็บข้อมูลตามความต้องการและงบประมาณของคุณ สำหรับจุดประสงค์ของคู่มือนี้ฉันได้เลือก "Standard-LRS" (กล่าวคือ Redundant) เพื่อลดต้นทุน ตรวจสอบว่าบัญชี Storage ใหม่ของคุณถูกเพิ่มลงในกลุ่มทรัพยากรที่คุณสร้างไว้ในขั้นตอนที่ 1 ("ทรัพยากรคลัสเตอร์") ในตำแหน่งเดียวกัน ("West US" ในตัวอย่างนี้): 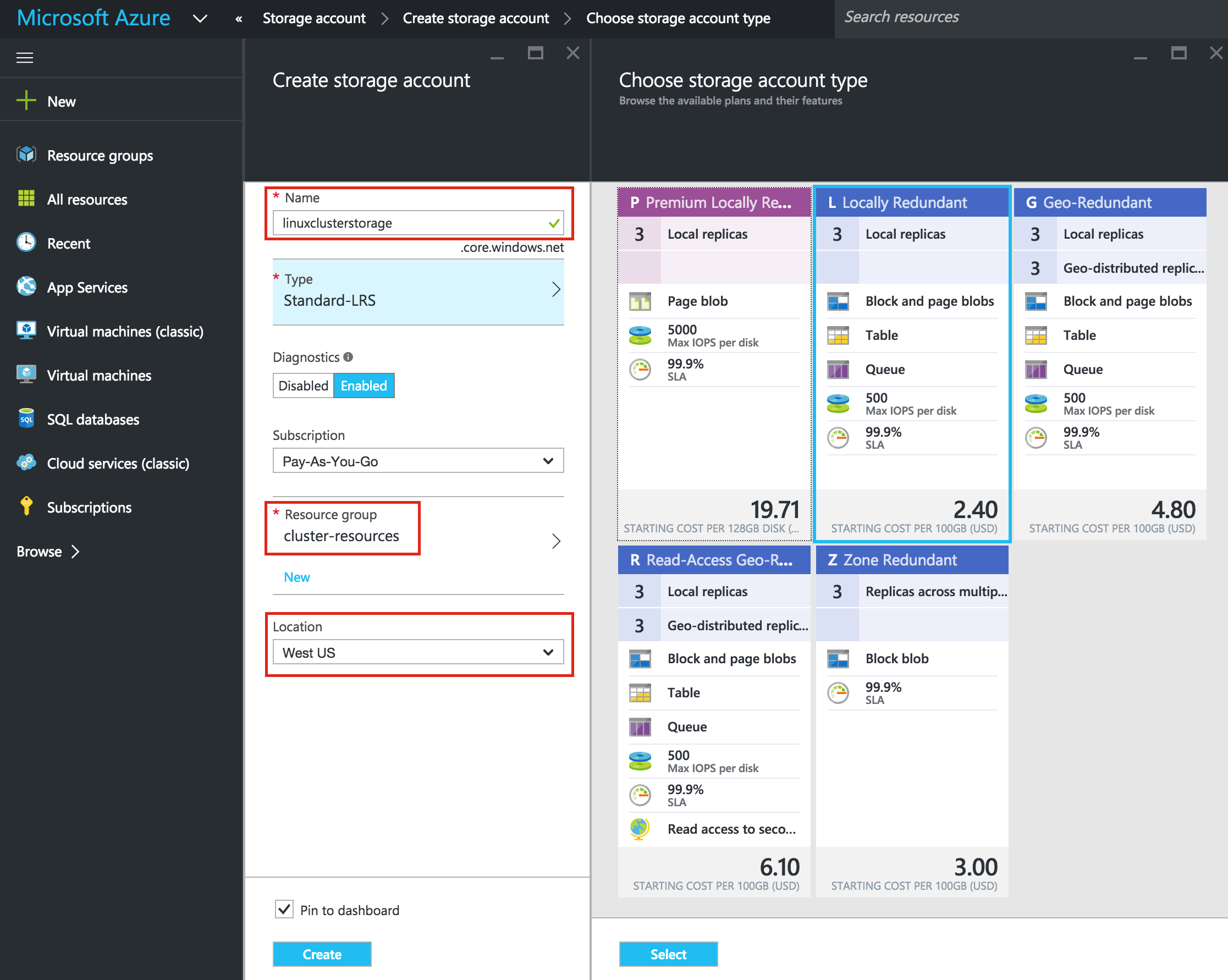
สร้างเครื่องเสมือนในชุดความพร้อมใช้งาน
เราจะเตรียมเครื่องเสมือน 3 เครื่องไว้ในคู่มือนี้ VMs แรก 2 ตัว (ฉันจะเรียกว่า "node1" และ "node2") จะทำหน้าที่เป็นโหนดคลัสเตอร์ที่มีความสามารถในการนำฐานข้อมูล MySQL มาใช้และเป็นแหล่งข้อมูลออนไลน์ที่เกี่ยวข้อง VM ที่ 3 จะทำหน้าที่เป็นเซิร์ฟเวอร์พยานของคลัสเตอร์เพื่อเพิ่มการป้องกันการแยกสมอง เพื่อให้มีพื้นที่ว่างสูงสุด VM ทั้ง 3 เครื่องจะถูกเพิ่มลงในชุดการตั้งค่าความพร้อมกันเพื่อให้แน่ใจว่าพวกเขาจะลงท้ายด้วยโดเมนฟอลต์และโดเมนการอัปเดตที่แตกต่างกัน
สร้าง "node1" VM
สร้าง VM เครื่องแรกของคุณ ("node1") ในคู่มือนี้เราจะใช้ CentOS 6.X: ตรวจสอ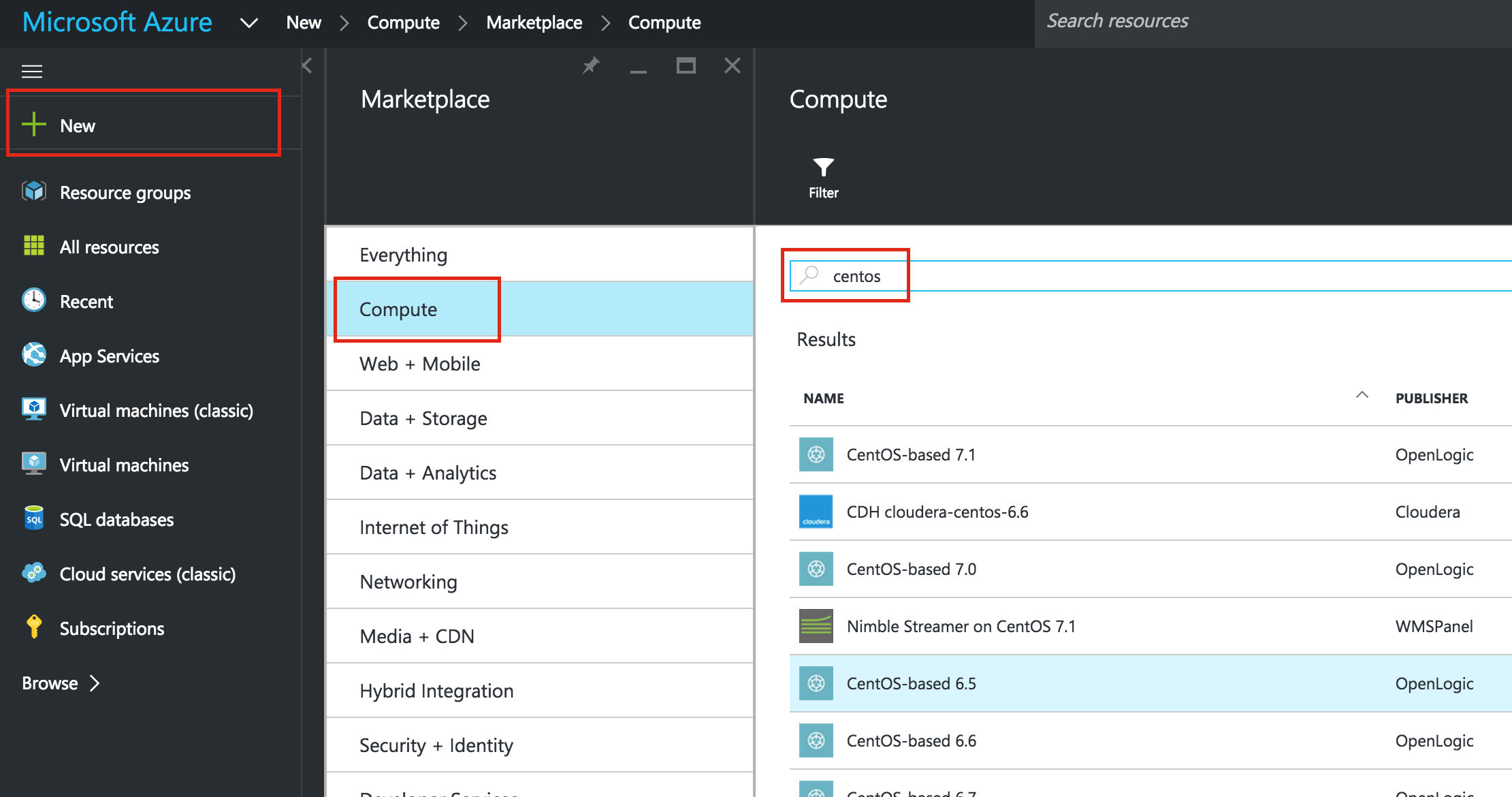 บให้แน่ใจว่าคุณใช้รูปแบบการปรับใช้ Resource Manager ควรเลือกโดยค่าเริ่มต้น: ใ
บให้แน่ใจว่าคุณใช้รูปแบบการปรับใช้ Resource Manager ควรเลือกโดยค่าเริ่มต้น: ใ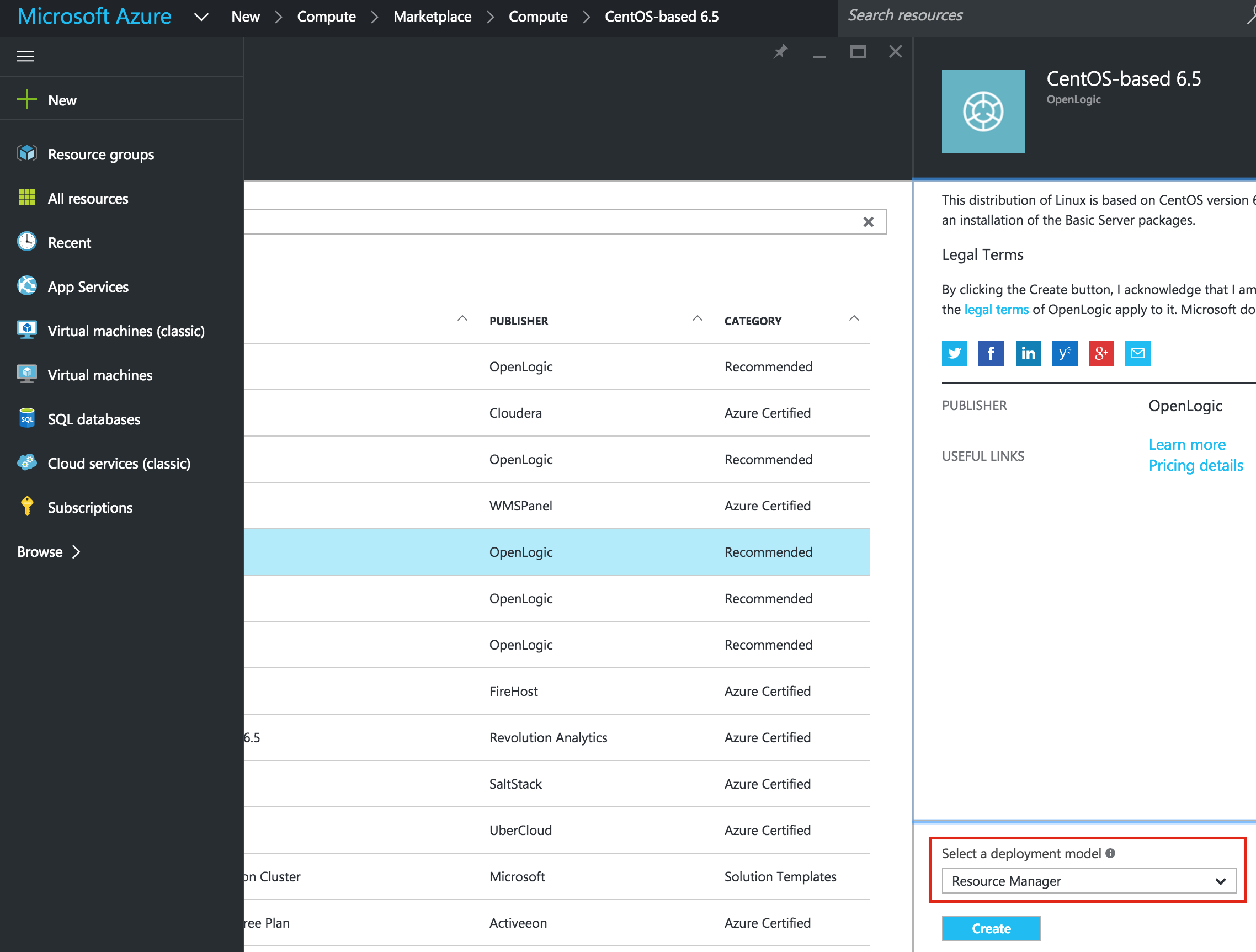 ห้ VM ชื่อโฮสต์ ("node1") และชื่อผู้ใช้ / รหัสผ่านที่จะใช้ใน SSH ในระบบต่อไป ตรวจสอบให้แน่ใจว่าคุณได้เพิ่ม VM นี้ลงใน Resource Group ("cluster-resources") และอยู่ในพื้นที่เดียวกันกับทรัพยากรอื่น ๆ ทั้งหมดของ
ห้ VM ชื่อโฮสต์ ("node1") และชื่อผู้ใช้ / รหัสผ่านที่จะใช้ใน SSH ในระบบต่อไป ตรวจสอบให้แน่ใจว่าคุณได้เพิ่ม VM นี้ลงใน Resource Group ("cluster-resources") และอยู่ในพื้นที่เดียวกันกับทรัพยากรอื่น ๆ ทั้งหมดของ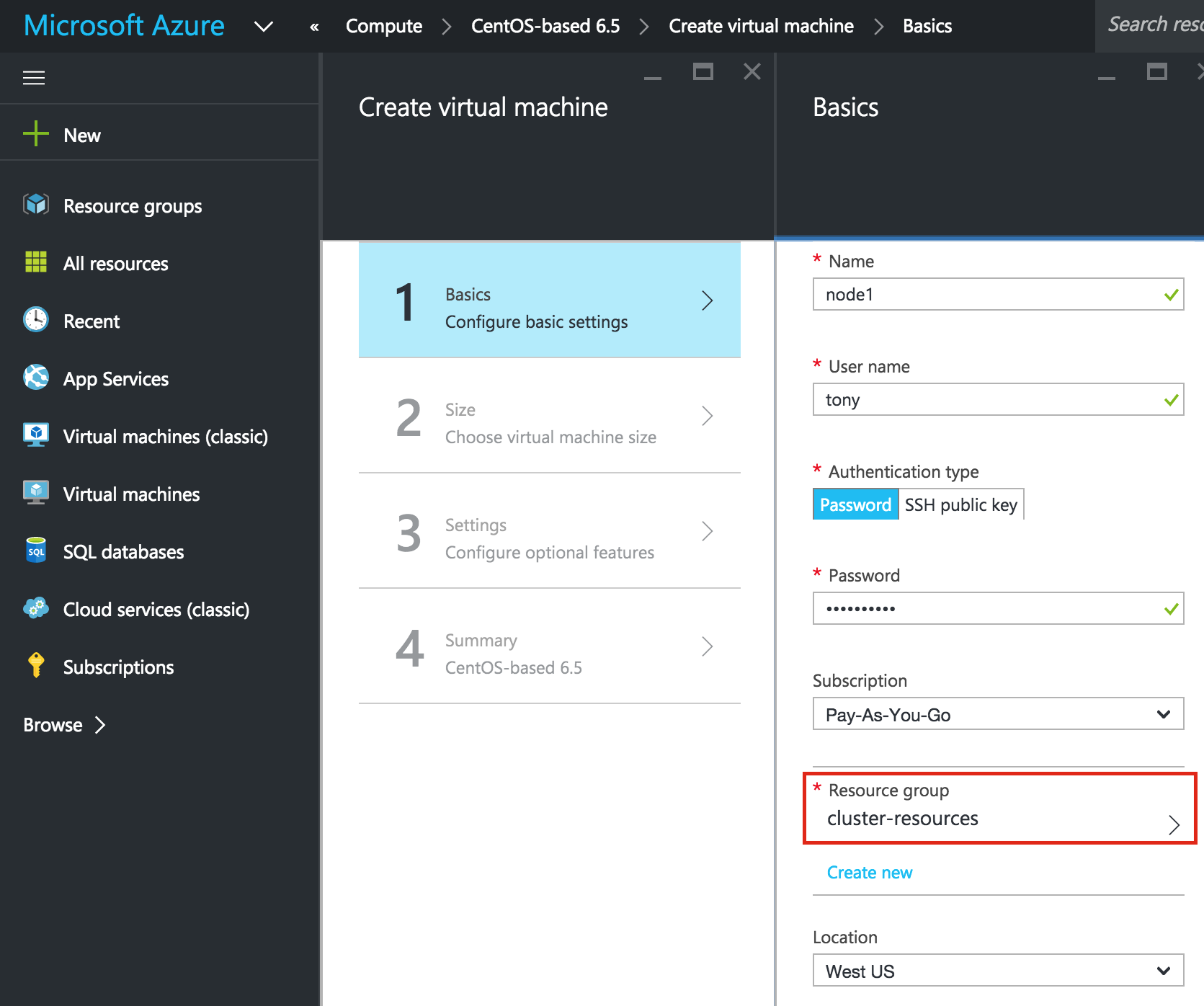 คุณ: ถัดไปเลือกขนาดของอินสแตนซ์ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับขนาดต่างๆที่มีให้คลิกที่นี่ สำหรับจุดประสงค์ของคู่มือนี้ฉันใช้ "A3 Standard" สำหรับ Node1 และ Node2 เพื่อลดต้นทุนเนื่องจากจะไม่ใช้ปริมาณการผลิต ฉันใช้แม้แต่ขนาดเล็ก "A1 มาตรฐาน" ขนาดสำหรับเซิร์ฟเวอร์พยาน เลือกขนาดอินสแตนซ์ที่เหมาะสมกับคุณมากที่สุด
คุณ: ถัดไปเลือกขนาดของอินสแตนซ์ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับขนาดต่างๆที่มีให้คลิกที่นี่ สำหรับจุดประสงค์ของคู่มือนี้ฉันใช้ "A3 Standard" สำหรับ Node1 และ Node2 เพื่อลดต้นทุนเนื่องจากจะไม่ใช้ปริมาณการผลิต ฉันใช้แม้แต่ขนาดเล็ก "A1 มาตรฐาน" ขนาดสำหรับเซิร์ฟเวอร์พยาน เลือกขนาดอินสแตนซ์ที่เหมาะสมกับคุณมากที่สุด 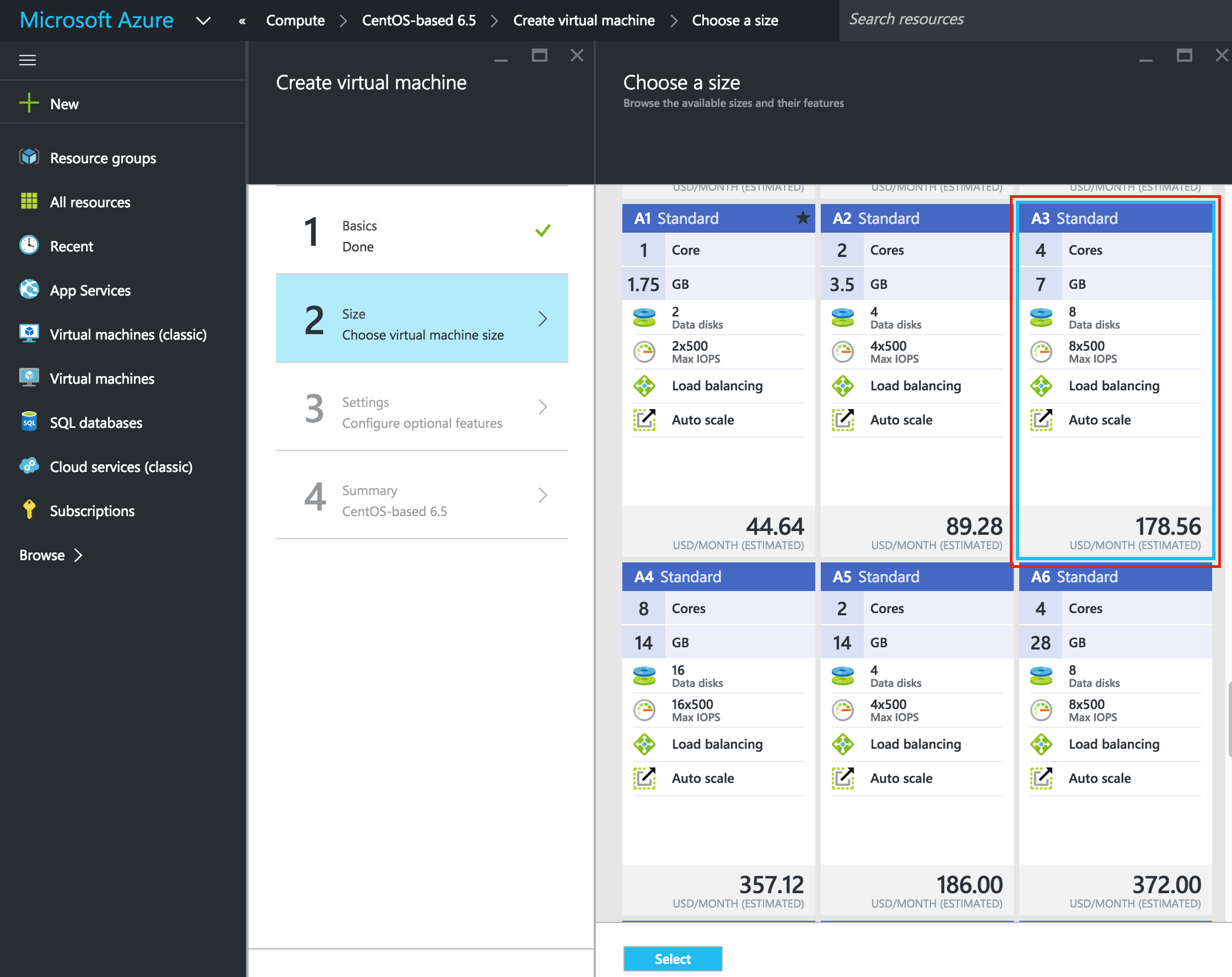 ถ้าคุณต้องการเชื่อมต่อ VM จากภายนอกให้ตั้งค่าที่อยู่ IP สาธารณะ ฉันทำอย่างนี้เพื่อให้สามารถใช้ SSH และ VNC ในระบบได้ต่อไปข้
ถ้าคุณต้องการเชื่อมต่อ VM จากภายนอกให้ตั้งค่าที่อยู่ IP สาธารณะ ฉันทำอย่างนี้เพื่อให้สามารถใช้ SSH และ VNC ในระบบได้ต่อไปข้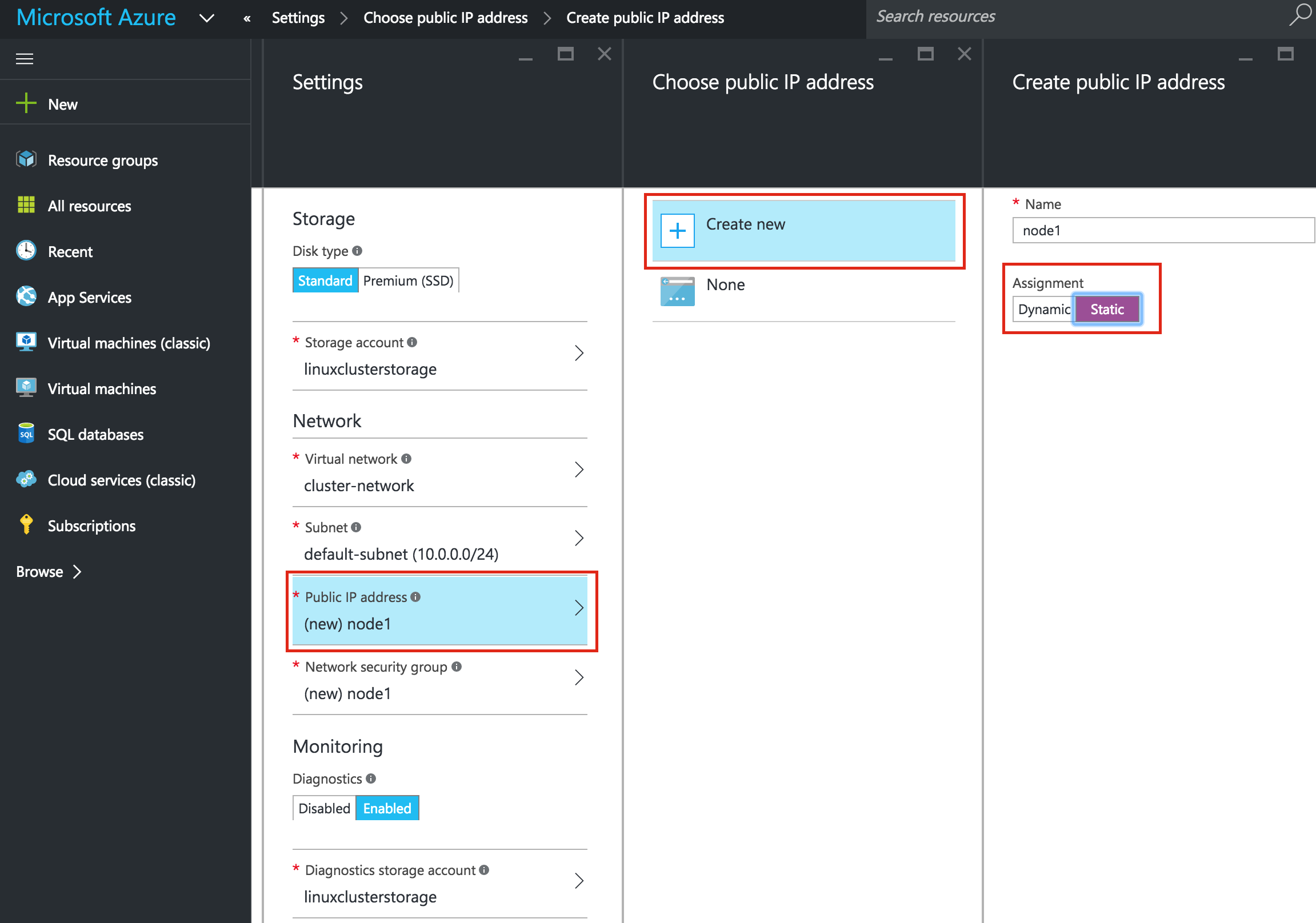 อสำคัญ: โดยค่าเริ่มต้น VM ของคุณจะไม่ถูกเพิ่มลงในชุดการตั้งค่าความพร้อมใช้งาน ในหน้าจอการตั้งค่าระหว่างตรวจสอบให้แน่ใจว่าคุณได้สร้างชุดข้อมูลการให้บริการใหม่แล้วเราจะเรียก "cluster-availability-set" Azure Resource Manager (ARM) ช่วยให้คุณสามารถสร้างชุดการตั้งค่าความพร้อมใช้งานได้โดยใช้โดเมนที่เป็นเท็จ 3 แห่ง ค่าดีฟอลต์ที่นี่ดูดี: ตรวจสอบคุ
อสำคัญ: โดยค่าเริ่มต้น VM ของคุณจะไม่ถูกเพิ่มลงในชุดการตั้งค่าความพร้อมใช้งาน ในหน้าจอการตั้งค่าระหว่างตรวจสอบให้แน่ใจว่าคุณได้สร้างชุดข้อมูลการให้บริการใหม่แล้วเราจะเรียก "cluster-availability-set" Azure Resource Manager (ARM) ช่วยให้คุณสามารถสร้างชุดการตั้งค่าความพร้อมใช้งานได้โดยใช้โดเมนที่เป็นเท็จ 3 แห่ง ค่าดีฟอลต์ที่นี่ดูดี: ตรวจสอบคุ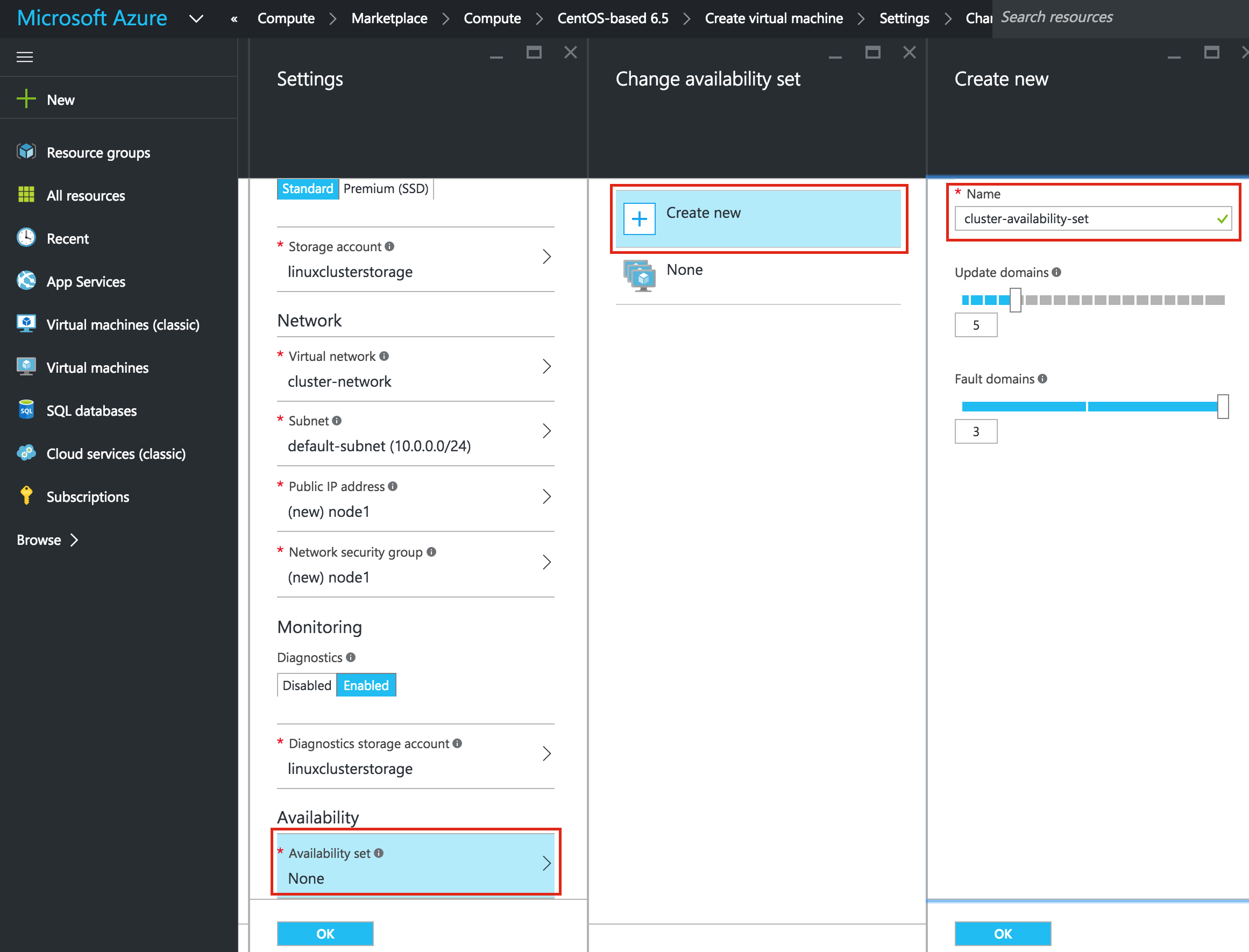 ณสมบัติ VM ของคุณและคลิก OK เพื่อสร้าง VM เครื่องแรกของคุณ:
ณสมบัติ VM ของคุณและคลิก OK เพื่อสร้าง VM เครื่องแรกของคุณ: 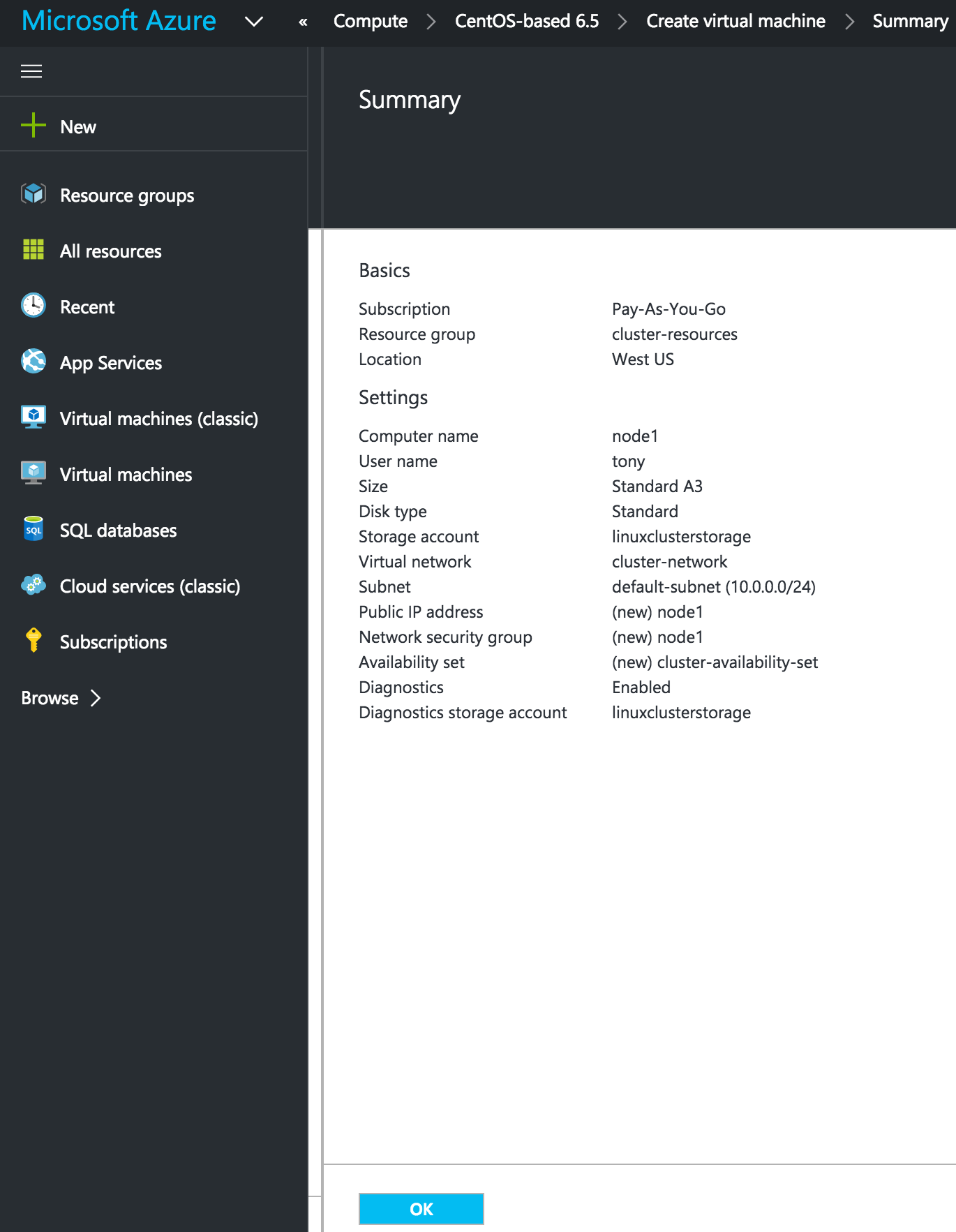
สร้าง "node2" และ "witness" VMs
ทำซ้ำขั้นตอนข้างต้นสองครั้งเพื่อสร้าง VM อีกสองเครื่อง ฉันสร้างอีกขนาด "A3 Standard" ขนาด VM ที่เรียกว่า "node2" และ "A1 Standard" ขนาด VM ที่เรียกว่า "witness" ข้อแตกต่างเพียงอย่างเดียวคือคุณจะเพิ่ม VM เหล่านี้ลงในชุดการตั้งค่าความพร้อมใช้งาน (cluster-availability-set) ซึ่งเราเพิ่งสร้างขึ้น: อาจ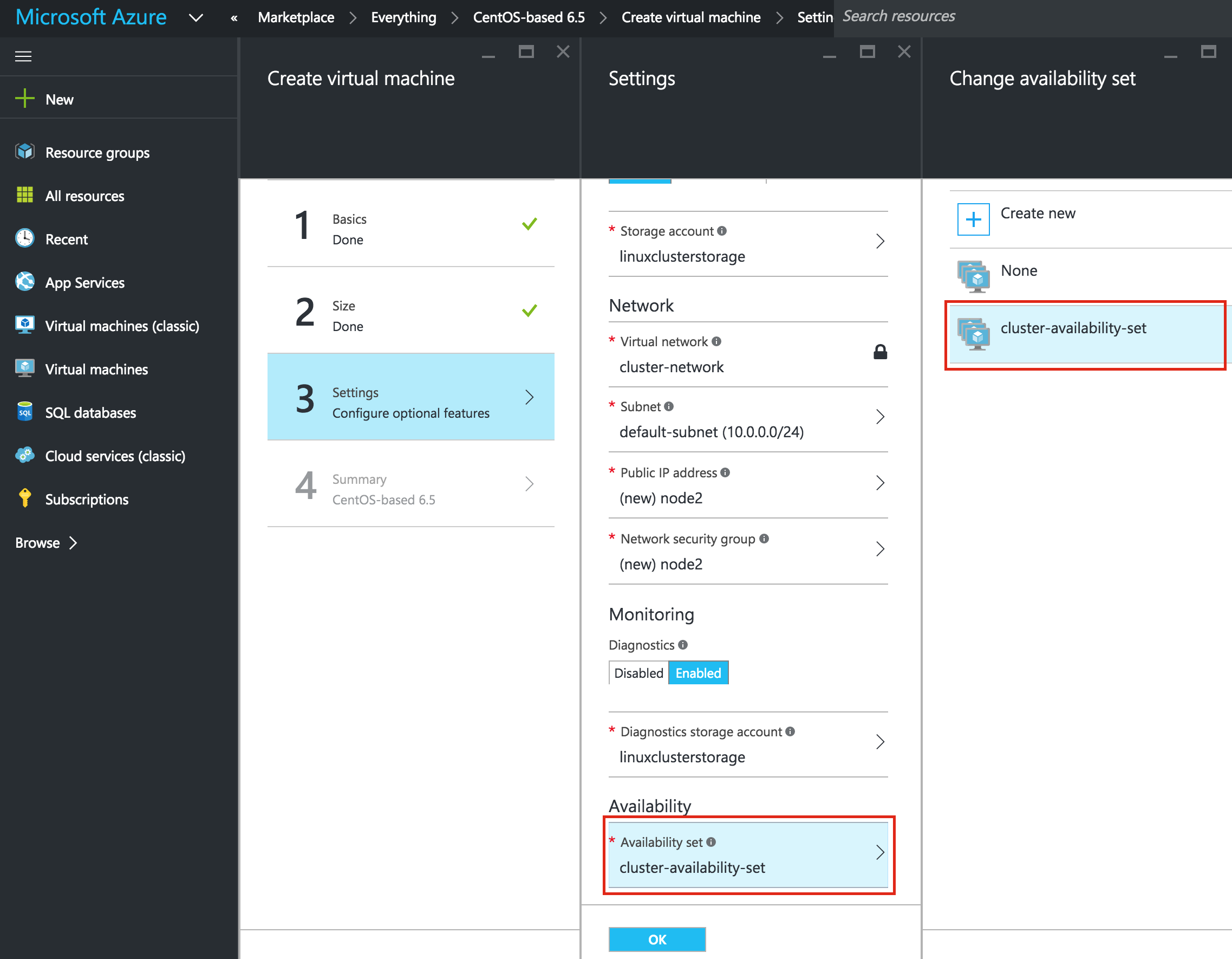 ใช้เวลาสักครู่เพื่อให้อุปกรณ์ 3 เครื่องของคุณสามารถจัดหาได้ เมื่อเสร็จสิ้นคุณจะเห็น VM ของคุณแสดงอยู่ในหน้าจอเครื่องเสมือนภายใน Azure Portal ของคุณ:
ใช้เวลาสักครู่เพื่อให้อุปกรณ์ 3 เครื่องของคุณสามารถจัดหาได้ เมื่อเสร็จสิ้นคุณจะเห็น VM ของคุณแสดงอยู่ในหน้าจอเครื่องเสมือนภายใน Azure Portal ของคุณ: 
ตั้งค่าที่อยู่ IP แบบคงที่ของ VM
VM จะถูกตั้งค่าด้วยที่อยู่ IP ต่อไปนี้:
- node1: 10.0.0.4
- node2: 10.0.0.5
- พยาน: 10.0.0.6
ทำซ้ำขั้นตอนนี้สำหรับแต่ละ VM เลือก VM ของคุณและแก้ไข Network Interface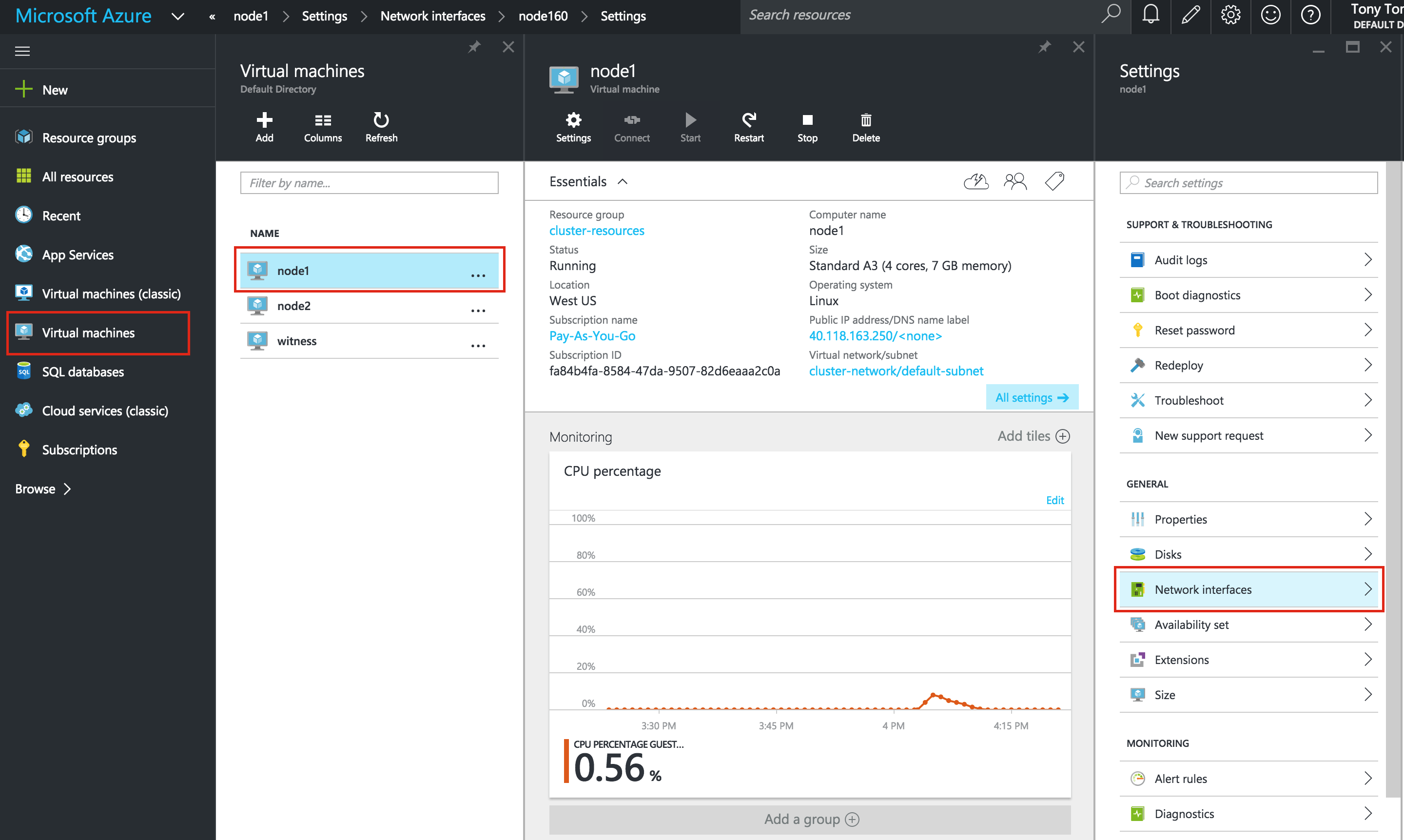 s เลือกอินเตอร์เฟซเครือข่ายที่เกี่ยวข้องกับ VM และแก้ไขที่อยู่ IP เลือก "คงที่" และระบุที่อยู่ IP ที่ต้องการ:
s เลือกอินเตอร์เฟซเครือข่ายที่เกี่ยวข้องกับ VM และแก้ไขที่อยู่ IP เลือก "คงที่" และระบุที่อยู่ IP ที่ต้องการ: 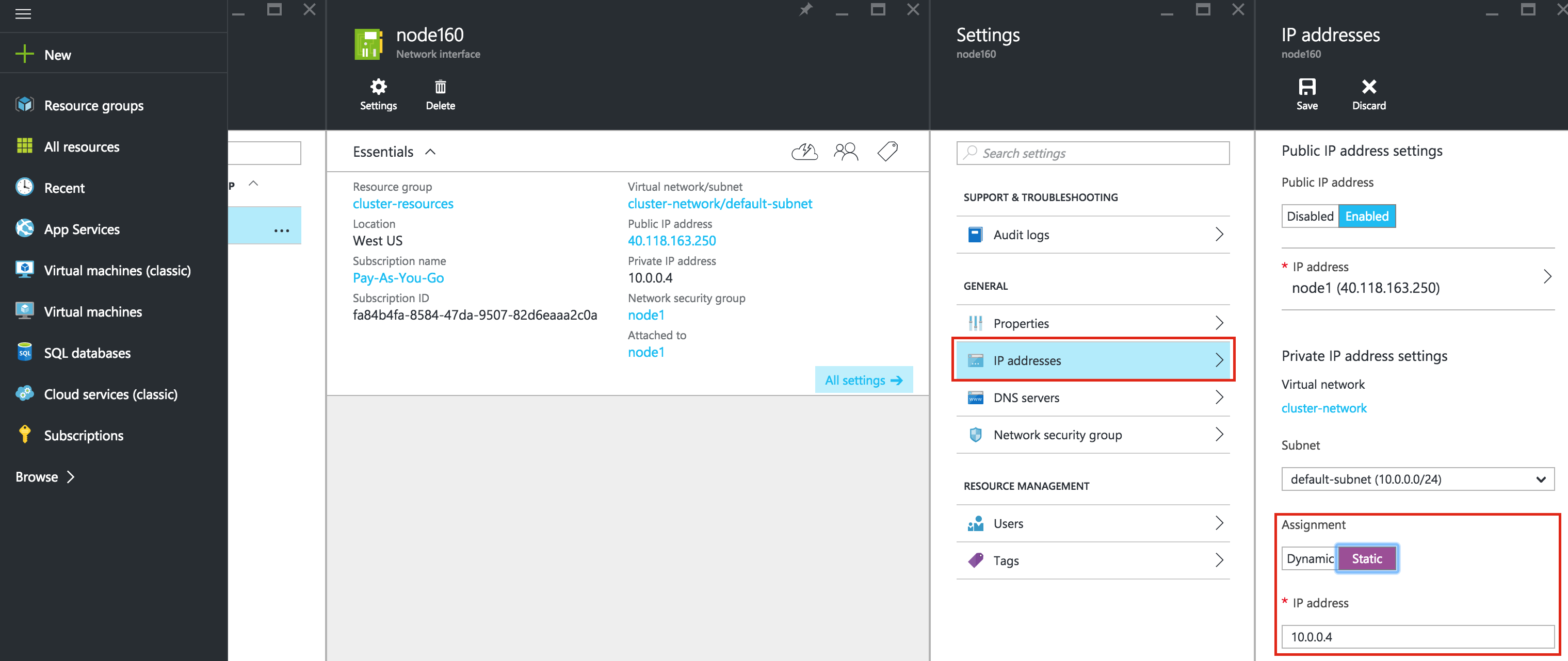
เพิ่มดิสก์ข้อมูลลงในโหนดคลัสเตอร์
ต่อไปเราจะต้องเพิ่มดิสก์พิเศษของโหนดคลัสเตอร์ของเรา ("node1" และ "node2") ดิสก์นี้จะเก็บฐานข้อมูล MySQL ของเราและต่อมาจะจำลองแบบระหว่างโหนด หมายเหตุ: คุณไม่จำเป็นต้องเพิ่มดิสก์พิเศษลงในโหนด "witness" เฉพาะ "node1" และ "node2" แก้ไข VM เลือกดิสก์แล้วใส่ดิสก์ใหม่: เลือกป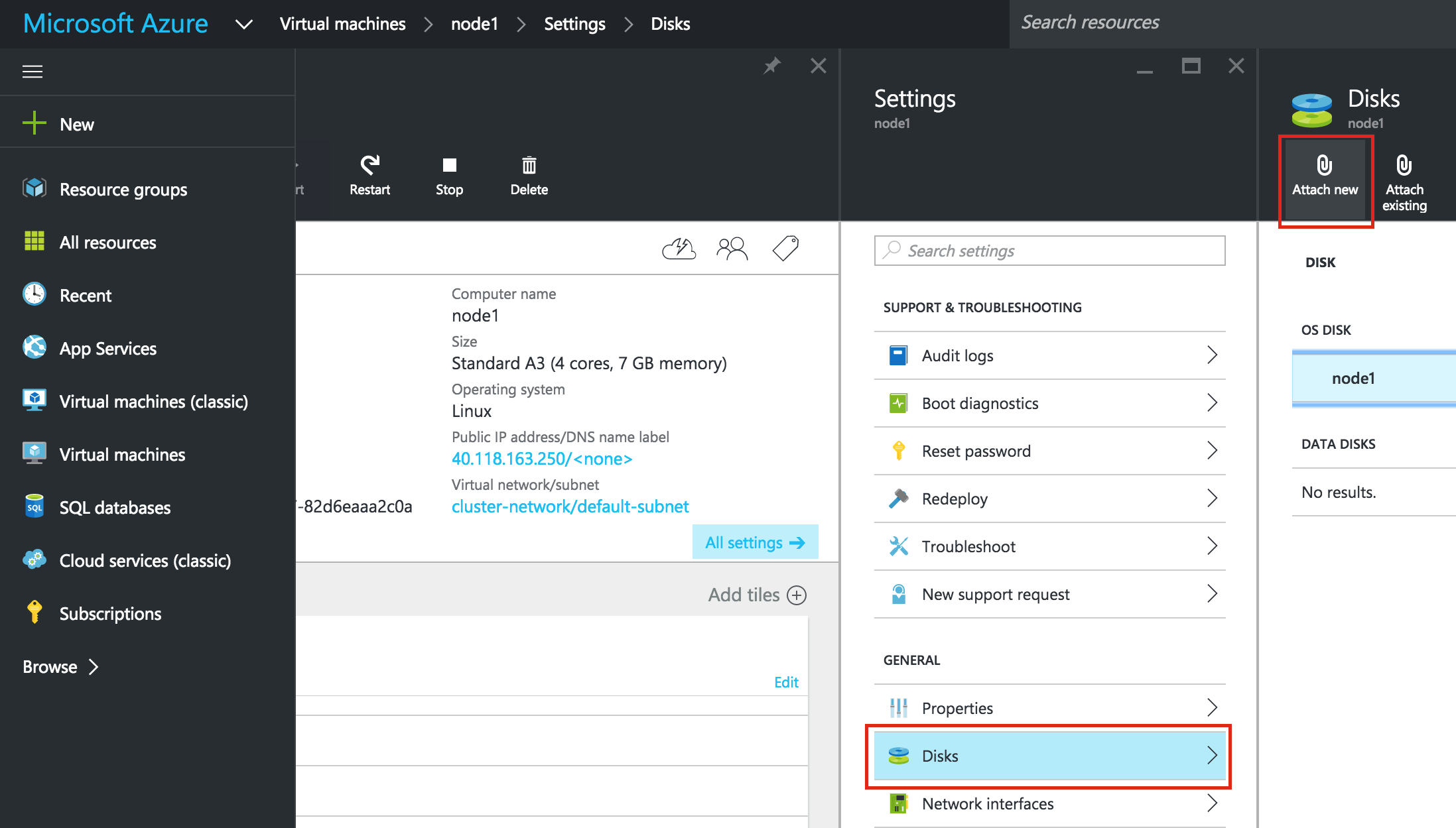 ระเภทดิสก์ (Standard หรือ Premium SSD) และขนาดตามปริมาณงานของคุณ ที่นี่ฉันจะสร้างดิสก์มาตรฐานขนาด 10GB ทั้งโหนดคลัสเตอร์ของฉัน หากแคช Host แคชไป "None" หรือ "Read only" cache ก็ไม่เป็นไร ฉันไม่แนะนำให้ใช้ "อ่าน / เขียน" เนื่องจากอาจทำให้ข้อมูลสูญหายได้:
ระเภทดิสก์ (Standard หรือ Premium SSD) และขนาดตามปริมาณงานของคุณ ที่นี่ฉันจะสร้างดิสก์มาตรฐานขนาด 10GB ทั้งโหนดคลัสเตอร์ของฉัน หากแคช Host แคชไป "None" หรือ "Read only" cache ก็ไม่เป็นไร ฉันไม่แนะนำให้ใช้ "อ่าน / เขียน" เนื่องจากอาจทำให้ข้อมูลสูญหายได้: 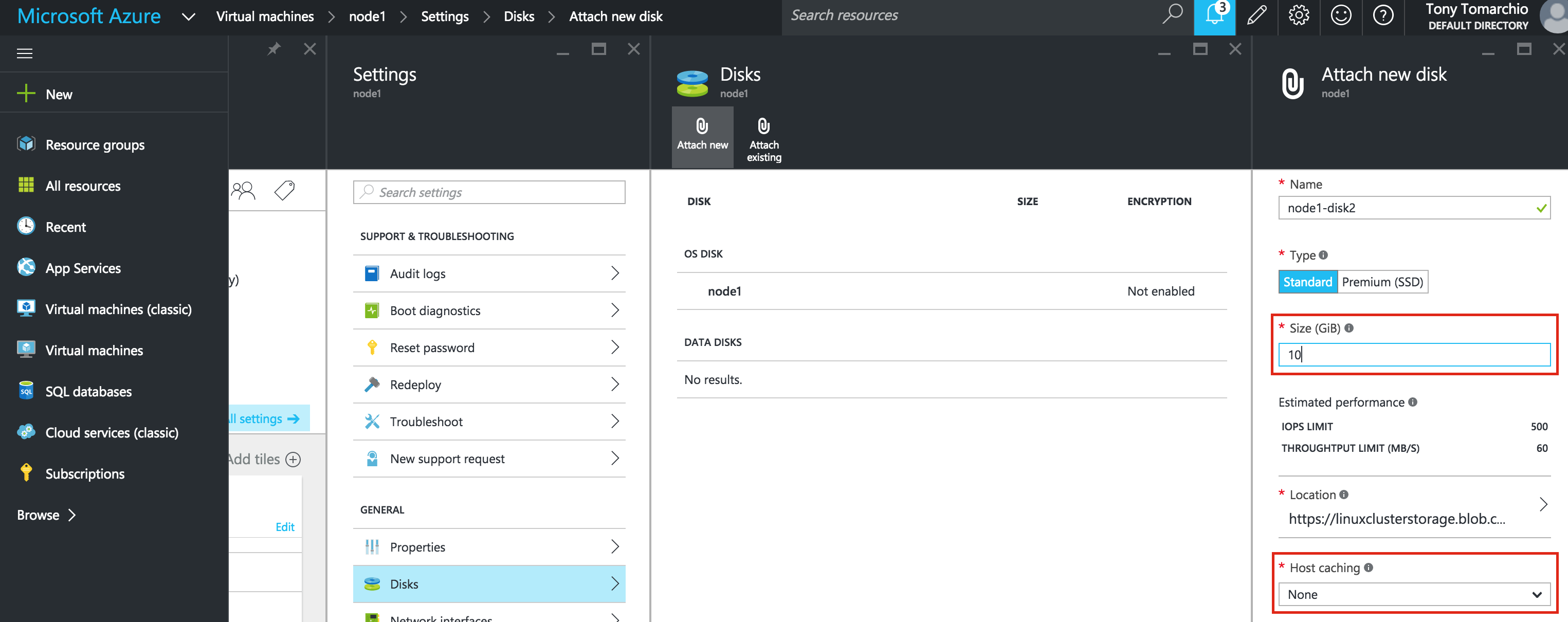
สร้างกฎความปลอดภัยขาเข้าเพื่อให้เข้าถึง VNC
หาก VM ของคุณเป็นส่วนหนึ่งของ Network Security Group (NSG) ซึ่งโดยปกติจะเป็นไปได้ว่าคุณจะไม่ได้ใช้งานในระหว่างการสร้าง VM พอร์ตเฉพาะที่เปิดอยู่ใน "Azure firewall" คือ SSH (พอร์ต 22) ในคู่มือนี้ฉันจะใช้ VNC เพื่อเข้าถึงเดสก์ท็อปของ "node1" และกำหนดค่าคลัสเตอร์โดยใช้ GUI สร้างกฎความปลอดภัยขาเข้าเพื่อเปิดการเข้าถึง VNC ในพอร์ตคู่มือ 5902 นี้ถูกใช้ ปรับค่านี้ตามการกำหนดค่า VNC ของคุณ (เลือก NIC) -> กลุ่มรักษาความปลอดภัยเครือข่าย -> (เลือก NSG) -> กฎความปลอดภัยขาเข้า -> เพิ่ม 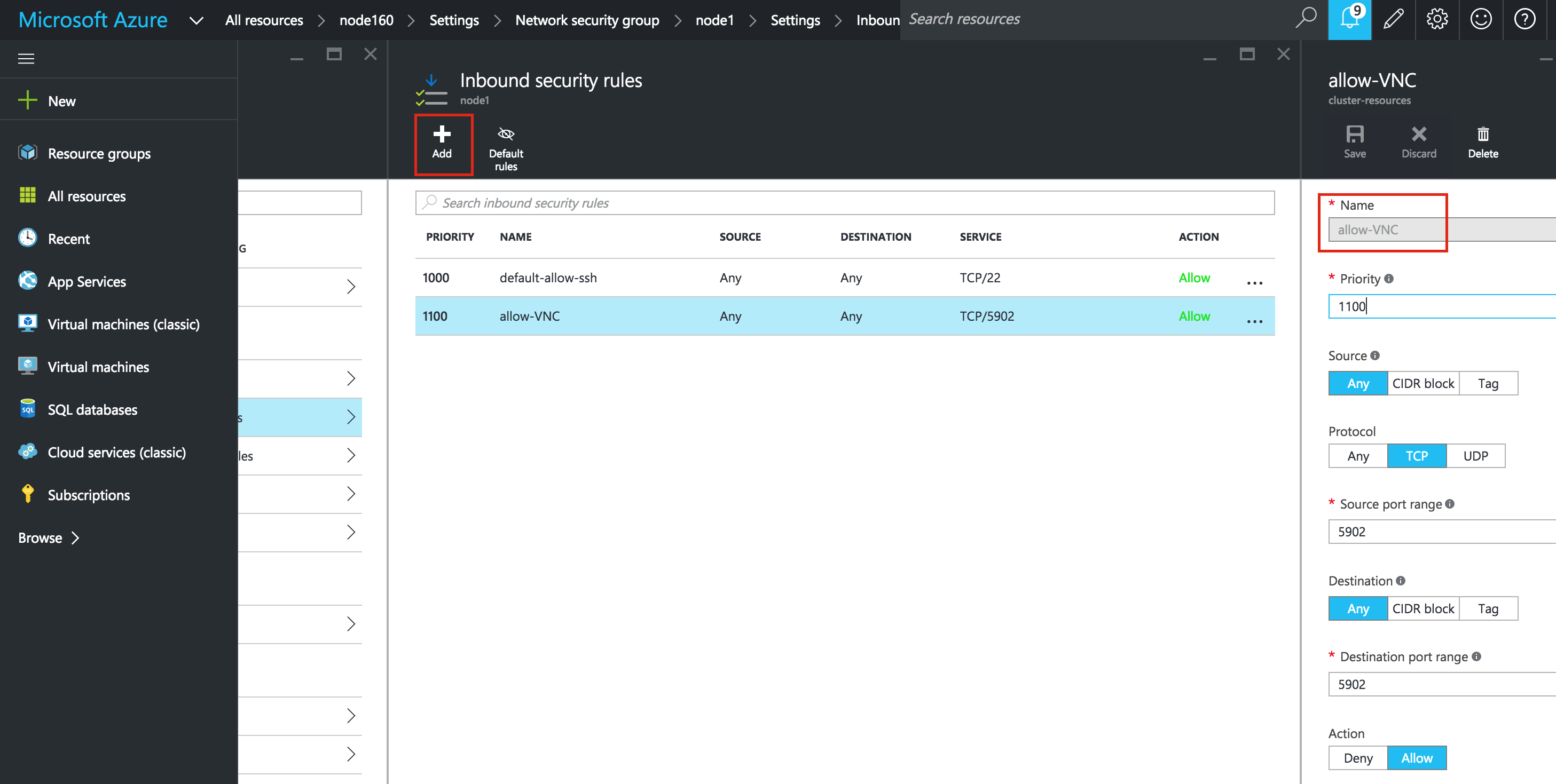
การกำหนดค่าระบบปฏิบัติการ Linux
นี่คือจุดที่เราจะออกจาก Azure Portal นิดหน่อยและทำให้มือของเราสกปรกในบรรทัดคำสั่งซึ่งในขณะนี้คุณควรจะเป็นผู้ดูแลระบบ Linux คุณไม่ได้รับรหัสผ่าน root ไปยัง Linux VM ของคุณใน Azure ดังนั้นเมื่อคุณล็อกอินเป็นผู้ใช้ที่ระบุในระหว่างการสร้าง VM ให้ใช้คำสั่ง "sudo" เพื่อรับสิทธิ์ root:
$ sudo su -
แก้ไข / etc / hosts
ถ้าคุณไม่มีการตั้งค่าเซิร์ฟเวอร์ DNS คุณจะต้องสร้างรายการไฟล์โฮสต์บนเซิร์ฟเวอร์ทั้ง 3 เครื่องเพื่อให้สามารถแก้ไขกันได้ดีโดยใช้ชื่อเพิ่มบรรทัดต่อไปนี้ลงในไฟล์ / etc / hosts ของคุณ:
10.0.0.4 node1 10.0.0.5 node2 10.0.0.6 พยาน 10.0.0.99 mysql-vip
ปิดใช้งาน SELinux
แก้ไข / etc / sysconfig / linux และตั้งค่า "SELINUX = disabled":
# vi / etc / sysconfig / selinux # แฟ้มนี้ควบคุมสถานะ SELinux ในระบบ # SELINUX = สามารถใช้หนึ่งในสามค่าต่อไปนี้: # enforcing - ใช้นโยบายความปลอดภัยของ SELinux # permissive - SELinux พิมพ์คำเตือนแทนการบังคับใช้ # disabled - ไม่มีนโยบาย SELinux ถูกโหลด SELINUX = คนพิการ # SELINUXTYPE = สามารถใช้หนึ่งในสองค่านี้: เป้าหมาย # - กระบวนการกำหนดเป้าหมายได้รับการป้องกัน, # mls - การป้องกันความปลอดภัยแบบหลายระดับ SELINUXTYPE = การกำหนดเป้าหมาย
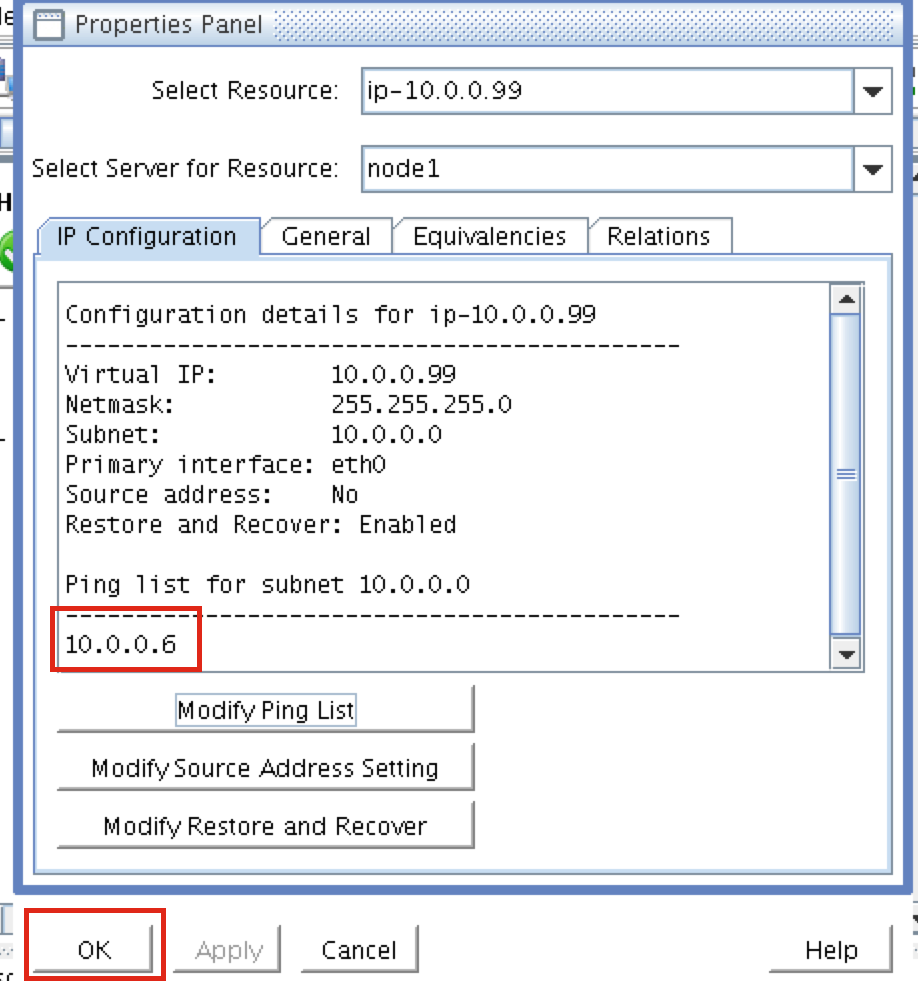
กำหนดค่า iptables เพื่อให้คลัสเตอร์ IP เสมือนทำงานได้
สิ่งสำคัญ: เพื่อให้สามารถเชื่อมต่อกับ Virtual IP ของคลัสเตอร์และตรวจสอบทรัพยากร IP ได้ต้องมีการตั้งค่ากฎ iptables บางอย่าง หมายเหตุ: 10.0.0.99 คือ Virtual IP ที่เราจะใช้ในคลัสเตอร์ของเราและ 3306 เป็นพอร์ตดีฟอลต์ที่ใช้ MySQL ของฉัน ที่ node1 (10.0.0.4) ให้รันคำสั่งต่อไปนี้:
# iptables - ไหล # iptables -t nat -A PREROUTING -p tcp --dport 3306 -j DNAT - ไปยังปลายทาง 10.0.0.99:3306 # iptables -t nat -A POSTROUTING -p-icmp -s 10.0.0.99 -j SNAT - แหล่งที่มา 10.0.0.4 # iptables บริการประหยัด # chkconfig iptables บน
บน Node2 (10.0.0.5) เรียกใช้คำสั่งต่อไปนี้:
# iptables - ไหล # iptables -t nat -A PREROUTING -p tcp --dport 3306 -j DNAT - ไปยังปลายทาง 10.0.0.99:3306 # iptables -t nat -A POSTROUTING -p-icmp -s 10.0.0.99 -j SNAT - แหล่งที่มา 10.0.0.5 # iptables บริการประหยัด # chkconfig iptables บน
ติดตั้งและกำหนดค่า VNC (และแพคเกจที่เกี่ยวข้อง)
ในการเข้าถึง GUI ของเซิร์ฟเวอร์ linux ของเราเพื่อกำหนดค่าคลัสเตอร์ของเราให้ติดตั้งเซิร์ฟเวอร์ VNC ในโหนดคลัสเตอร์ของคุณในภายหลัง ในการตั้งค่าของฉันฉันเท่านั้นนี้ใน "node1"
# yum install tigervnc-server xterm
# vncpasswd
# vi / etc / sysconfig / vncservers
VNCSERVERS = "2: ราก"
VNCSERVERARGS [2] = "- รูปทรงเรขาคณิต 1024x768"
# vncserver เริ่มบริการ
# chkconfig vncserver บน
ทดสอบการเชื่อมต่อโดยการเปิดโปรแกรม VNC บนแล็ปท็อป / เดสก์ท็อปและเชื่อมต่อกับ Public IP ของโหนดคลัสเตอร์ของคุณ
โหนดรีสตาร์ทคลัสเตอร์
รีบูตโหนดคลัสเตอร์ของคุณเพื่อให้ SELinux ถูกปิดใช้งานและตรวจพบดิสก์ที่ 2 ที่คุณเพิ่มไว้ก่อนหน้านี้ เฉพาะ "node1" และ "node2" เท่านั้นที่ต้องบูตเครื่องใหม่
พาร์ทิชันและฟอร์แมตดิสก์ "ข้อมูล"
ในขั้นตอนที่ 6 ของคู่มือนี้ ("เพิ่มดิสก์ข้อมูลไปยังโหนดคลัสเตอร์") เราได้ดำเนินการดังนี้ … เพิ่มดิสก์พิเศษในแต่ละโหนดคลัสเตอร์เพื่อเก็บข้อมูลแอ็พพลิเคชันที่เราจะปกป้อง ในกรณีนี้เป็นฐานข้อมูล MySQL ใน Azure IaaS Linux Virtual Machines ใช้การจัดเรียงต่อไปนี้สำหรับดิสก์:
- / dev / sda – ดิสก์ระบบปฏิบัติการ
- / dev / sdb – ดิสก์ชั่วคราว
- / dev / sdc – ดิสก์ข้อมูลที่ 1
- / dev / sdd – ดิสก์ข้อมูลที่ 2
- …
- / dev / sdj – ดิสก์ข้อมูลที่ 8
ดิสก์ที่เราเพิ่มในขั้นตอนที่ 6 ของคู่มือนี้ควรปรากฏเป็น / dev / sdc คุณสามารถเรียกใช้คำสั่ง "fdisk -l" เพื่อยืนยัน คุณจะเห็นว่า / dev / sda (OS) และ / dev / sdb (ชั่วคราว) มีพาร์ติชันดิสก์อยู่และกำลังใช้อยู่
# fdisk -l ดิสก์ / dev / sdb: 306.0 GB, 306016419840 ไบต์ 255 หัว 63 เซกเมนต์ / แทร็ก 37204 กระบอกสูบ หน่วย = กระบอกสูบ 16065 * 512 = 8225280 ไบต์ ขนาดของเซกเตอร์ (ตรรกะ / ทางกายภาพ): 512 ไบต์ / 512 ไบต์ ขนาด I / O (ต่ำสุด / ดีที่สุด): 512 ไบต์ / 512 ไบต์ ตัวระบุดิสก์: 0xd3920649 Device Boot เริ่มระบบ End Block Block / dev / sdb1 * 1 37205 298842112 83 Linux ดิสก์ / dev / sdc: 10.7 GB, 10737418240 ไบต์ 255 หัว 63 เซกเมนต์ / แทรค, 1305 กระบอกสูบ หน่วย = กระบอกสูบ 16065 * 512 = 8225280 ไบต์ ขนาดของเซกเตอร์ (ตรรกะ / ทางกายภาพ): 512 ไบต์ / 512 ไบต์ ขนาด I / O (ต่ำสุด / ดีที่สุด): 512 ไบต์ / 512 ไบต์ ตัวระบุดิสก์: 0x00000000 ดิสก์ / dev / sda: 32.2 GB, 32212254720 ไบต์ 255 หัว 63 เซกเมนต์ / แทร็ก 3916 กระบอกสูบ หน่วย = กระบอกสูบ 16065 * 512 = 8225280 ไบต์ ขนาดของเซกเตอร์ (ตรรกะ / ทางกายภาพ): 512 ไบต์ / 512 ไบต์ ขนาด I / O (ต่ำสุด / ดีที่สุด): 512 ไบต์ / 512 ไบต์ ตัวระบุดิสก์: 0x000c23d3 Device Boot เริ่มระบบ End Block Block / dev / sda1 * 1 3789 30432256 83 Linux / dev / sda2 3789 3917 1024000 82 Linux swap / Solaris
ที่นี่ฉันจะสร้างพาร์ติชัน (/ dev / sdc1) จัดรูปแบบและติดตั้งไว้ที่ตำแหน่งเริ่มต้นสำหรับ MySQL ซึ่งเป็น / var / lib / mysql ทำตามขั้นตอนต่อไปนี้ทั้ง BOTH "node1" และ "node2":
# fdisk / dev / sdc
คำสั่ง (m สำหรับความช่วยเหลือ): n
Command action
e ขยาย
พาร์ติชันหลัก p (1-4)
พี
หมายเลขพาร์ติชัน (1-4): 1
ถังแรก (1-1305, ค่าเริ่มต้น 1): <enter>
ใช้ค่าเริ่มต้น 1
กระบอกสูบถังหรือขนาด {K, M, G} (1-1305, ค่าเริ่มต้น 1305): <enter>
ใช้ค่าเริ่มต้น 1305
คำสั่ง (m สำหรับความช่วยเหลือ): w
ตารางพาร์ทิชันได้รับการเปลี่ยนแปลง!
เรียก ioctl () เพื่ออ่านตารางพาร์ทิชันอีกครั้ง
การซิงค์ดิสก์
[root @ node1 ~] #
# mkfs.ext4 / dev / sdc1
# mkdir / var / lib / mysql
ใน node1 ให้ติดตั้งระบบไฟล์:
# mount / dev / sdc1 / var / lib / mysql
ติดตั้งและกำหนดค่า MySQL
ถัดไปติดตั้งติดตั้งชุด MySQL, initialize ฐานข้อมูลตัวอย่างและตั้งรหัสผ่าน root สำหรับ MySQL
บน "node1":
# yum -y ติดตั้ง mysql mysql-server
# / usr / bin / mysql_install_db --datadir = "/ var / lib / mysql /" - user = mysql
# mysqld_safe - ผู้ใช้ = root --socket = / var / lib / mysql / mysql.sock --port = 3306
--datadir = / var / lib / mysql --log &
#
# # หมายเหตุ: คำสั่งต่อไปนี้อนุญาตให้เชื่อมต่อระยะไกลจากโฮสต์ใดก็ได้
ไม่ใช่ความคิดที่ดีสำหรับการผลิต!
# echo "update user set Host = '%' ที่ Host = 'node1'; สิทธิ์การล้าง mysql mysql
#
# # ตั้งรหัสผ่าน root ของ MySQL ให้เป็น 'SIOS'
# echo "ตั้งค่าผู้ใช้รหัสผ่าน = PASSWORD ('SIOS') โดยที่ User = 'root'; flush privileges"
| mysql mysql
สร้างแฟ้มการกำหนดค่า MySQL เราจะวางข้อมูลนี้ลงในดิสก์ข้อมูล (ซึ่งจะมีการจำลองแบบ – /var/lib/mysql/my.cnf) ตัวอย่าง:
# vi /var/lib/mysql/my.cnf [mysqld] datadir = / var / lib / MySQL ซ็อกเก็ต = / var / lib / MySQL / mysql.sock pid = ไฟล์ / var / lib / MySQL / mysqld.pid ผู้ใช้ = ราก พอร์ต = 3306 # การปิดใช้งานการเชื่อมโยงสัญลักษณ์แนะนำเพื่อป้องกันความเสี่ยงด้านความปลอดภัยต่างๆ สัญลักษณ์การเชื่อมโยง = 0 [mysqld_safe] เข้าสู่ระบบข้อผิดพลาด = / var / log / mysqld.log pid = ไฟล์ / var / ทำงาน / mysqld / mysqld.pid [ลูกค้า] ผู้ใช้ = ราก รหัสผ่าน = SIOS
ลบไฟล์การกำหนดค่า MySQL ต้นฉบับที่อยู่ใน / etc ถ้ามีอยู่:
# rm /etc/my.cnf
ใน "node2":
ใน "node2" คุณจำเป็นต้องติดตั้งแพคเกจ MySQL เท่านั้น ขั้นตอนอื่น ๆ ไม่จำเป็นต้องมี:
[root @ node2 ~] # yum -y ติดตั้ง mysql mysql-server
ติดตั้งและกำหนดค่าคลัสเตอร์
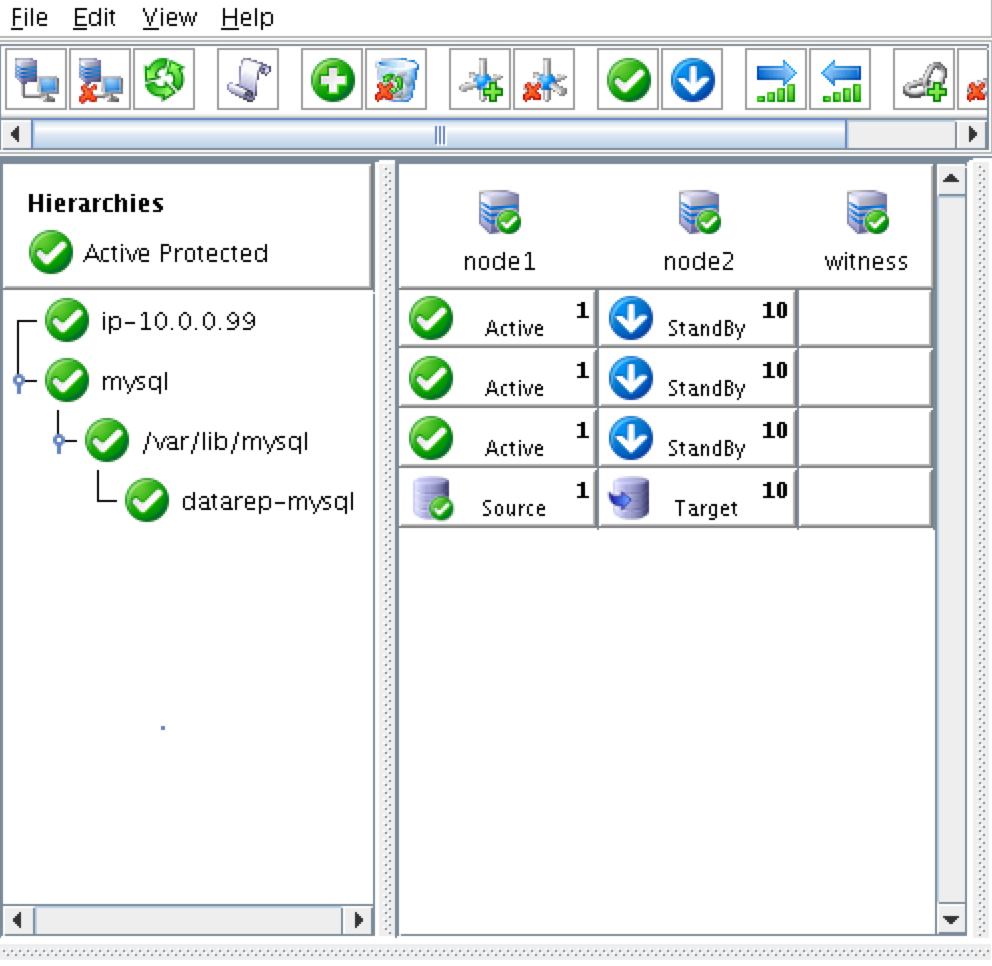
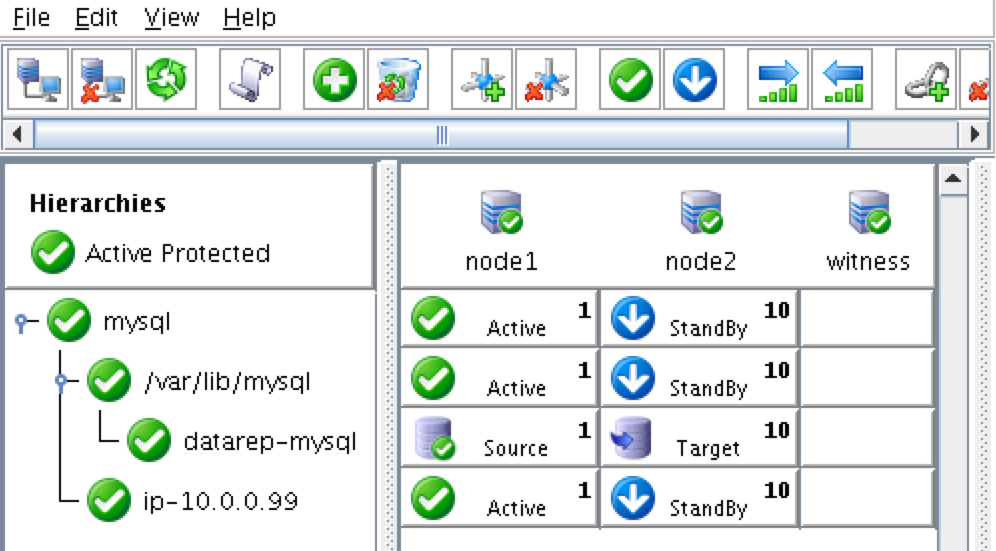
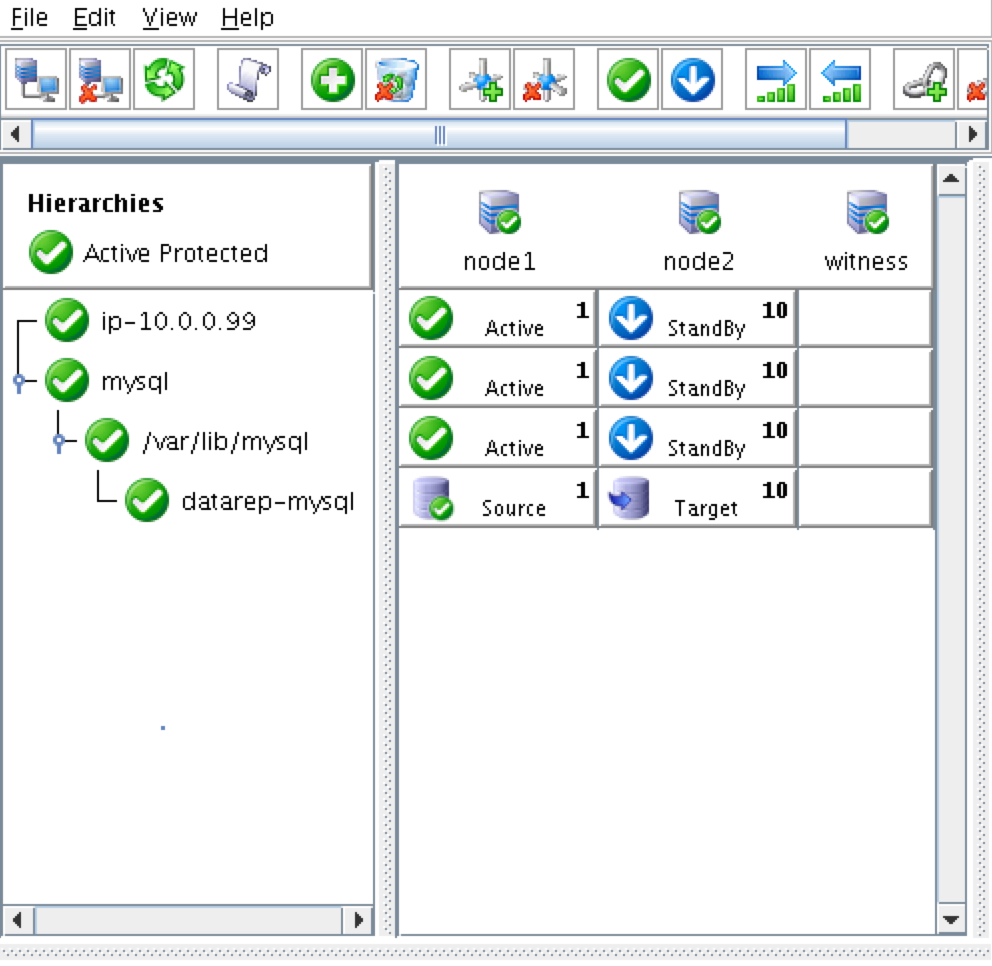
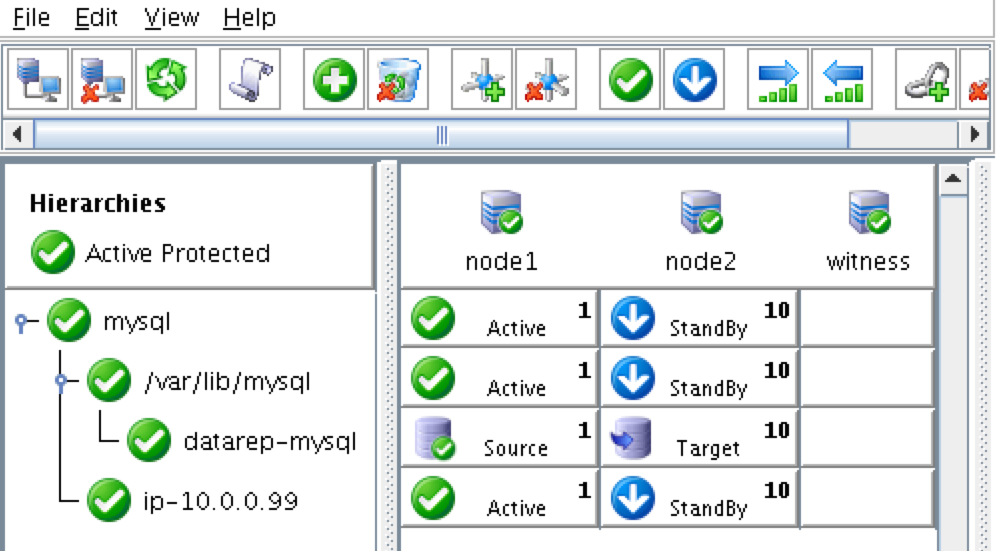
ณ จุดนี้เราพร้อมที่จะติดตั้งและกำหนดค่าคลัสเตอร์ของเราแล้ว SIOS Protection Suite สำหรับ Linux (aka SPS-Linux) จะใช้ในคู่มือนี้เป็นเทคโนโลยีการจัดกลุ่ม มีคุณสมบัติ failover clustering ที่มีประสิทธิภาพสูง (LifeKeeper) ตลอดจนแบบจำลองข้อมูลระดับ (DataKeeper) ในแบบเรียลไทม์ในโซลูชันแบบรวม SPS-Linux ช่วยให้คุณสามารถปรับใช้คลัสเตอร์ "SANLess" หรือที่เรียกว่า "shared nothing" cluster ซึ่งหมายความว่าโหนดคลัสเตอร์ไม่มีที่จัดเก็บข้อมูลร่วมกันเช่นในกรณีที่มี Azure VMs
ติดตั้ง SIOS Protection Suite สำหรับ Linux
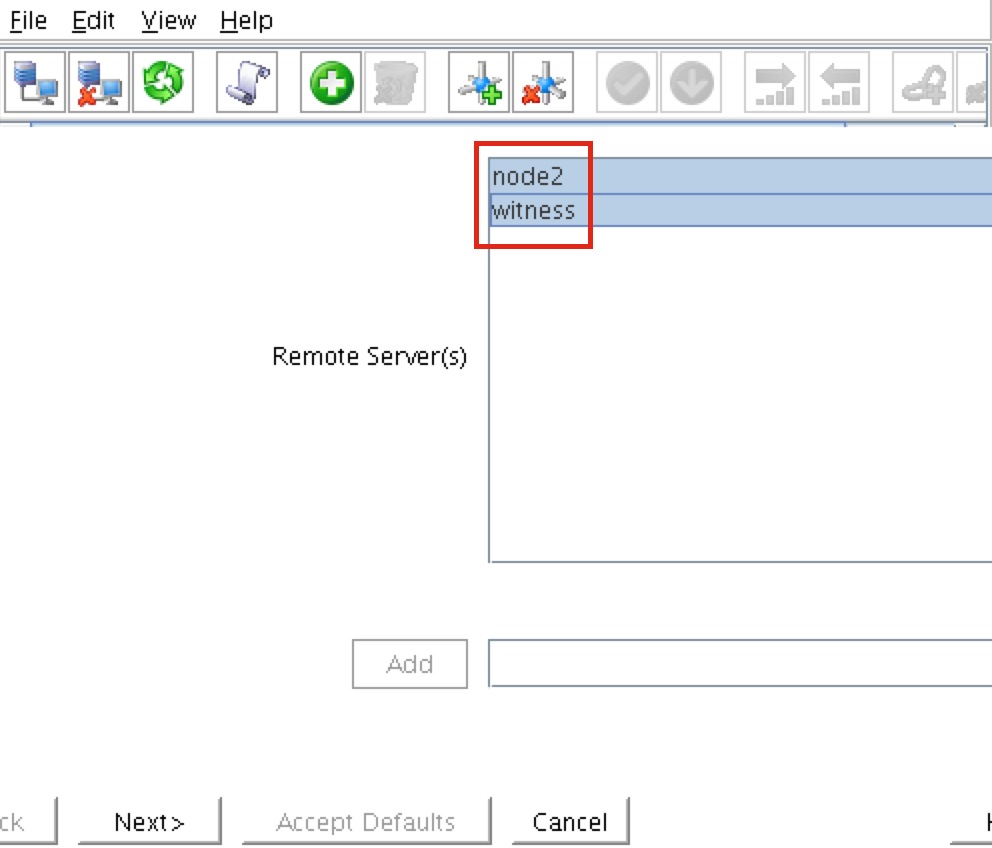
ทำตามขั้นตอนต่อไปนี้บน VM 3 เครื่อง (ดาวน์โหลดไฟล์การติดตั้ง SPS-Linux (sps.img) ติดต่อ SIOS สำหรับข้อมูลเพิ่มเติม คุณจะวนลูปเมาท์และเรียกใช้สคริปต์ "setup" ภายในเป็น root (หรือ "sudo su" แรก "เพื่อให้ได้ root shell) ตัวอย่างเช่น:
# mkdir / tmp / install # mount -o loop sps.img / tmp / install # cd / tmp / install # ./ติดตั้ง
ในระหว่างสคริปต์การติดตั้งคุณจะได้รับพร้อมท์ให้ตอบคำถามหลายข้อ คุณจะกด Enter ในเกือบทุกหน้าจอเพื่อยอมรับค่าดีฟอลต์ หมายเหตุข้อยกเว้นต่อไปนี้:
- บนหน้าจอ "High Availability NFS" คุณสามารถเลือก "n" ได้เนื่องจากเราจะไม่สร้างเซิร์ฟเวอร์ NFS ที่มีประสิทธิภาพสูง
- ในตอนท้ายสคริปต์การตั้งค่าคุณสามารถเลือกที่จะติดตั้งคีย์สิทธิ์การใช้งานทดลองตอนนี้หรือใหม่กว่าได้ เราจะติดตั้งคีย์ใบอนุญาตในภายหลังเพื่อให้คุณสามารถเลือก "n" ได้อย่างปลอดภัย ณ จุดนี้
- ในหน้าจอสุดท้ายของ "การตั้งค่า" เลือก ARK (ชุดการกู้คืนแอ็พพลิเคชัน ได้แก่ "ตัวแทนของคลัสเตอร์") ที่คุณต้องการติดตั้งจากรายการที่แสดงบนหน้าจอ
- ARK จะต้องใช้เฉพาะ "node1" และ "node2" เท่านั้น คุณไม่จำเป็นต้องติดตั้ง "พยาน"
- เลื่อนรายการด้วยลูกศรขึ้น / ลงและกด SPACEBAR เพื่อเลือกรายการต่อไปนี้:
- lkDR – DataKeeper สำหรับ Linux
- lkSQL – ชุดกู้คืนข้อมูล RDBMS ของ LifeKeeper
- ซึ่งจะส่งผลให้ RPM เพิ่มเติมที่ติดตั้งใน "node1" และ "node2":
- Steeleye-lkDR-9.0.2-6513.noarch.rpm
- Steeleye-lkSQL-9.0.2-6513.noarch.rpm
ติดตั้ง Witness / Quorum package
แพคเกจสนับสนุน Quorum / Witness Server สำหรับ LifeKeeper (steeleye-lkQWK) พร้อมกับกระบวนการ failover ที่มีอยู่ของ LifeKeeper core ช่วยให้ failover ระบบเกิดขึ้นได้ด้วยความมั่นใจมากขึ้นในสถานการณ์ที่ความล้มเหลวของเครือข่ายทั้งหมดอาจเป็นเรื่องปกติ นี้มีประสิทธิภาพหมายความว่า failovers สามารถทำได้ในขณะที่ช่วยลดความเสี่ยงของ "แยกสมอง" สถานการณ์ ติดตั้ง Witness / Quorum rpm บนโหนดทั้ง 3 โหนด (โหนด 1, โหนด 2, พยาน):
# cd / tmp / install / quorum # รอบต่อนาที - เหล็กหล่อเหล็ก - lkQWK-9.0.2-6513.noarch.rpm
บน nodes ทั้งหมด 3 โหนด (node1, node2, witness), แก้ไข / etc / default / LifeKeeper, ตั้งค่า NOBCASTPING = 1 เฉพาะบนเซิร์ฟเวอร์ Witness เท่านั้น ("witness"), แก้ไข / etc / default / LifeKeeper, ตั้งค่า WITNESS_MODE = off / none
ติดตั้งคีย์ใบอนุญาต
ใน 3 โหนดทั้งหมดใช้คำสั่ง "lkkeyins" เพื่อติดตั้งไฟล์ใบอนุญาตที่คุณได้รับจาก SIOS:
# / opt / LifeKeeper / bin / lkkeyins <path_to_file> / <filename> .lic
เริ่ม LifeKeeper
บนโหนดทั้ง 3 โหนดให้ใช้คำสั่ง "lkstart" เพื่อเริ่มต้นซอฟต์แวร์คลัสเตอร์:
# / opt / LifeKeeper / bin / lkstart
ตั้งค่าสิทธิ์ผู้ใช้สำหรับ LifeKeeper GUI
ในทั้ง 3 โหนดให้แก้ไข / etc / group และเพิ่มผู้ใช้ "tony" (หรือชื่อผู้ใช้ที่คุณระบุในระหว่างการสร้าง VM) ไปยังกลุ่ม "lkadmin" เพื่อให้สิทธิ์การเข้าถึง LifeKeeper GUI โดยค่าเริ่มต้น "root" เป็นสมาชิกของกลุ่มเท่านั้นและเราไม่มีรหัสผ่าน root ใน:
# vi / etc / group lkadmin: x 1001: ราก tony
เปิด LifeKeeper GUI
ทำการเชื่อมต่อ VNC กับที่อยู่ IP สาธารณะของ node1 จากการกำหนดค่า VNC และการกำหนดค่าความปลอดภัยขาเข้าจากด้านบนคุณจะต้องเชื่อมต่อกับ <Public_IP>: 2 โดยใช้รหัสผ่าน VNC ที่คุณระบุไว้ก่อนหน้านี้ เมื่อเข้าสู่ระบบแล้วให้เปิดหน้าต่างเทอร์มินัลและรัน LifeKeeper GUI โดยใช้คำสั่งต่อไปนี้:
# / opt / LifeKeeper / bin / lkGUIapp &
คุณจะได้รับพร้อมท์ให้เชื่อมต่อกับโหนดคลัสเตอร์แรกของคุณ ("node1")