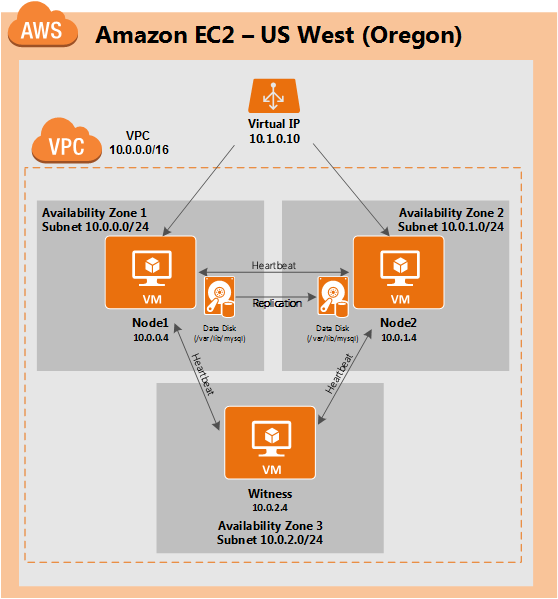
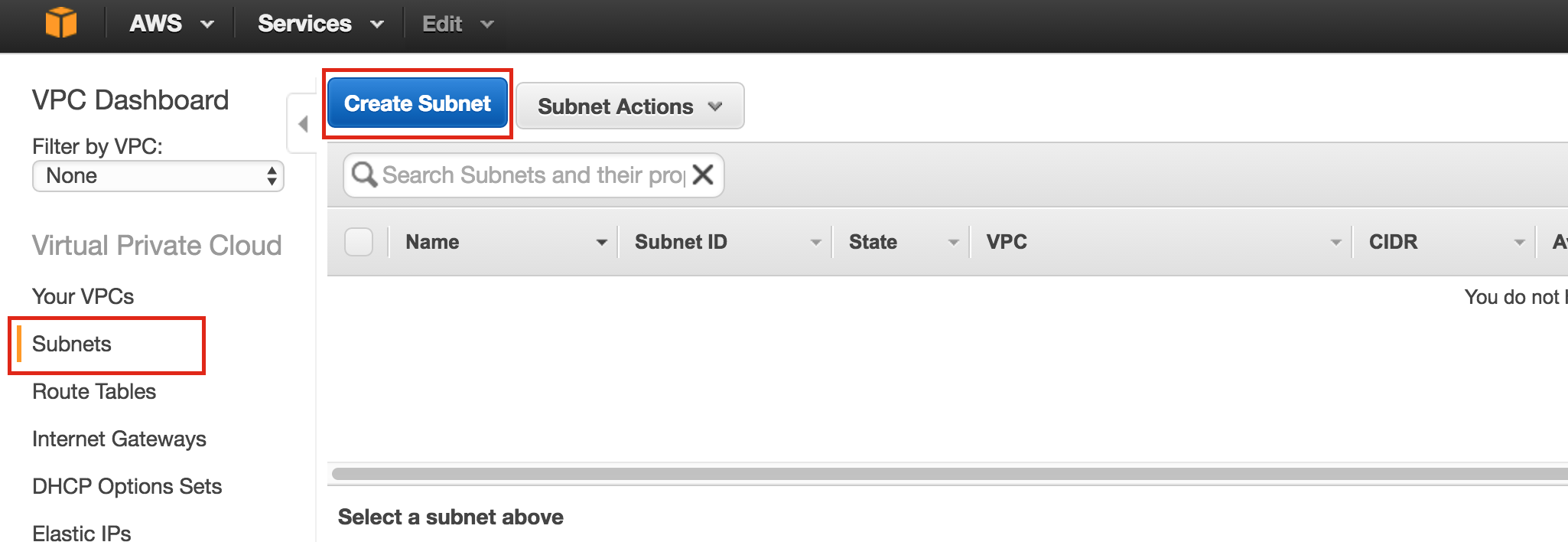
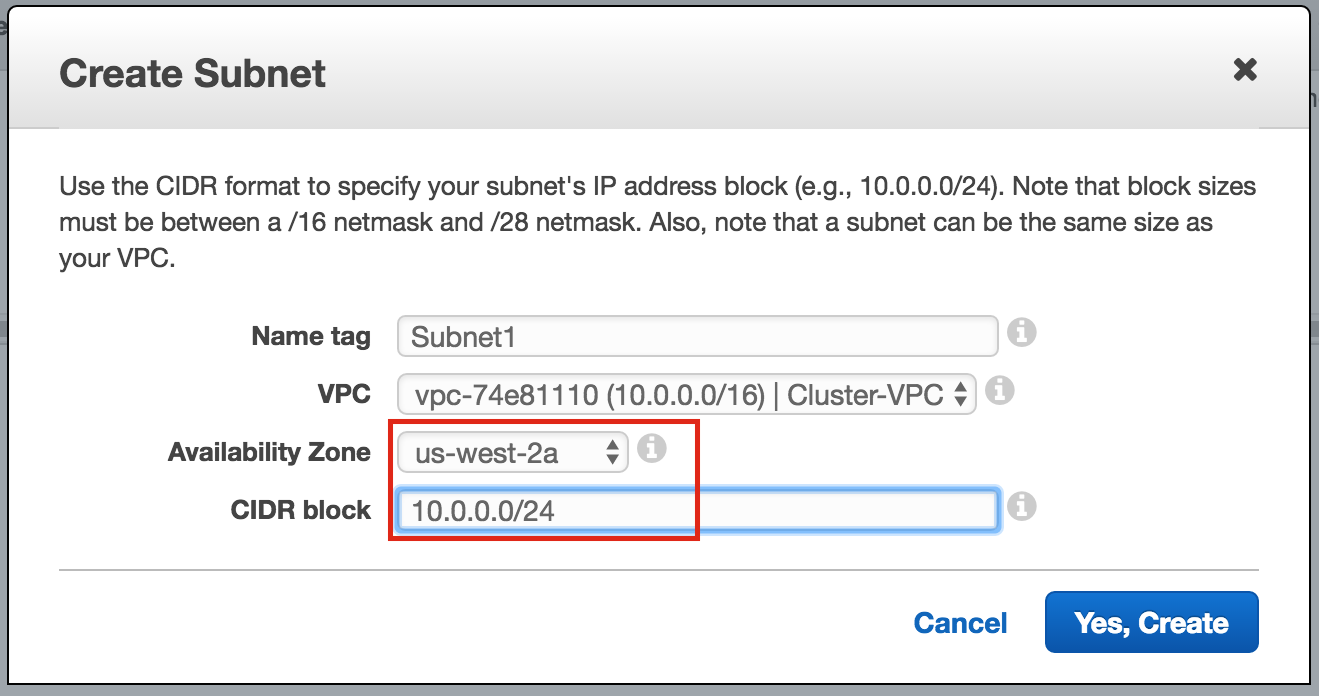
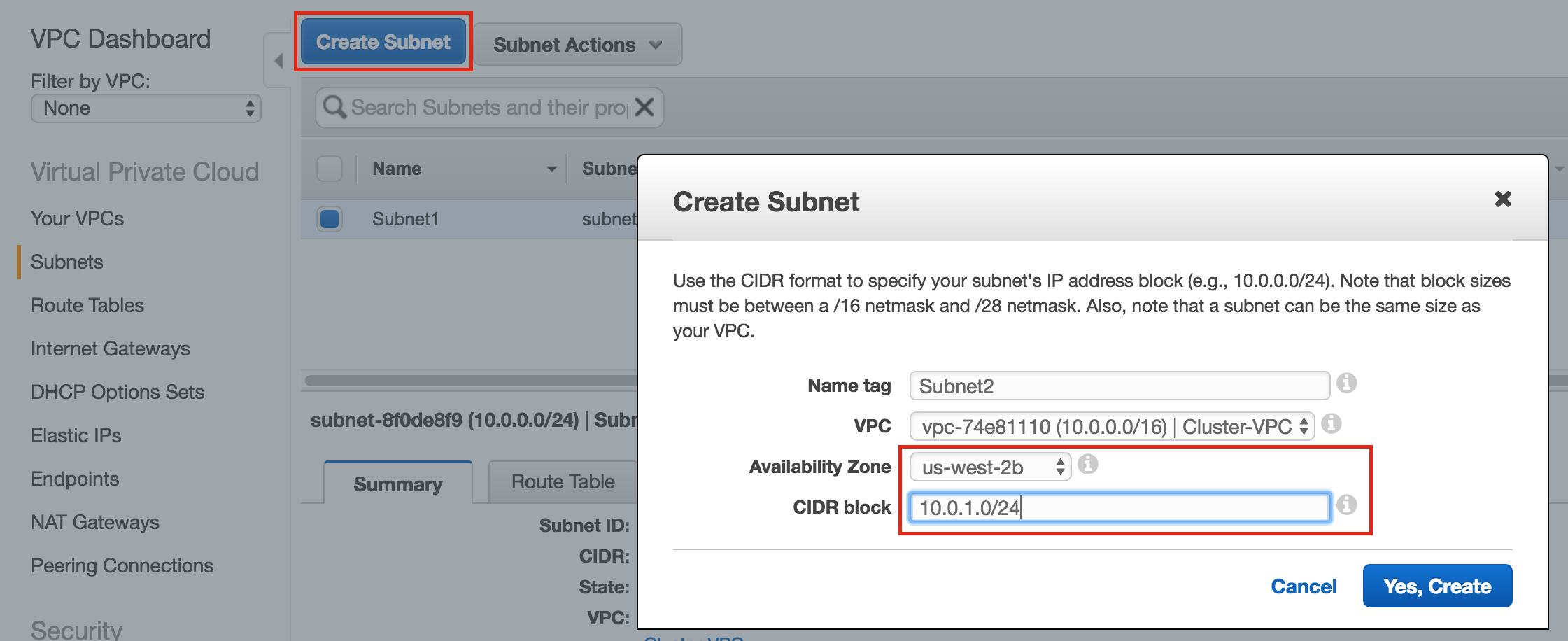
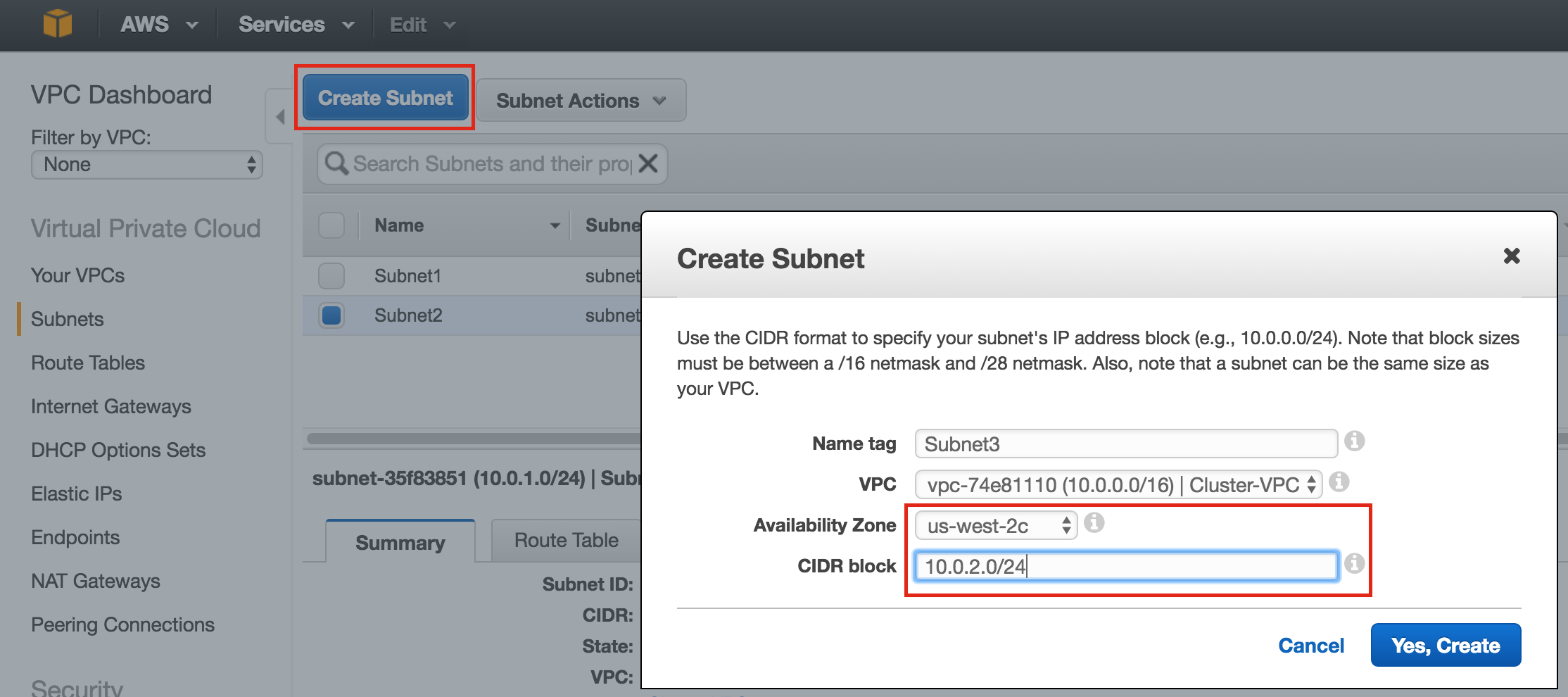
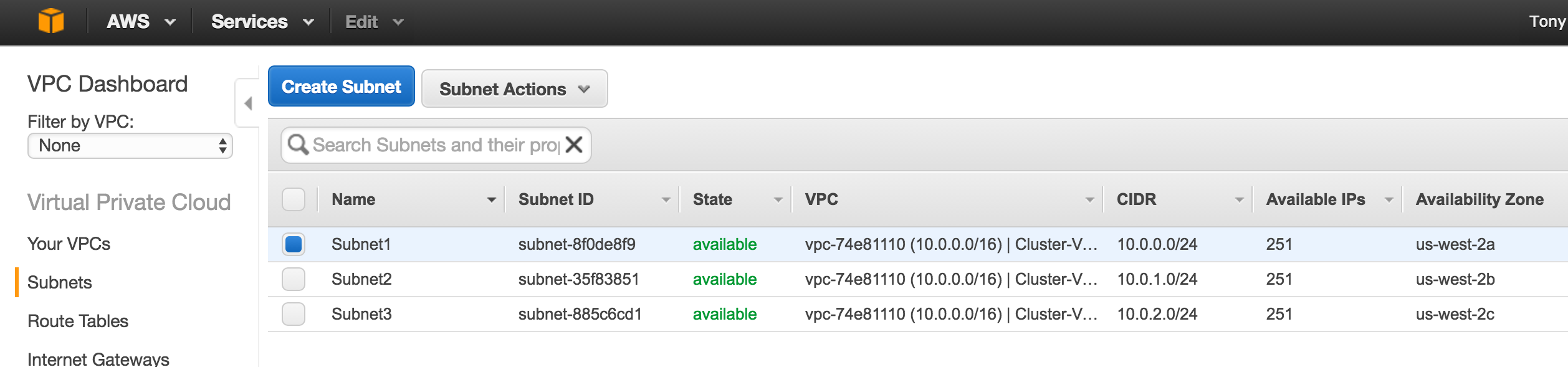
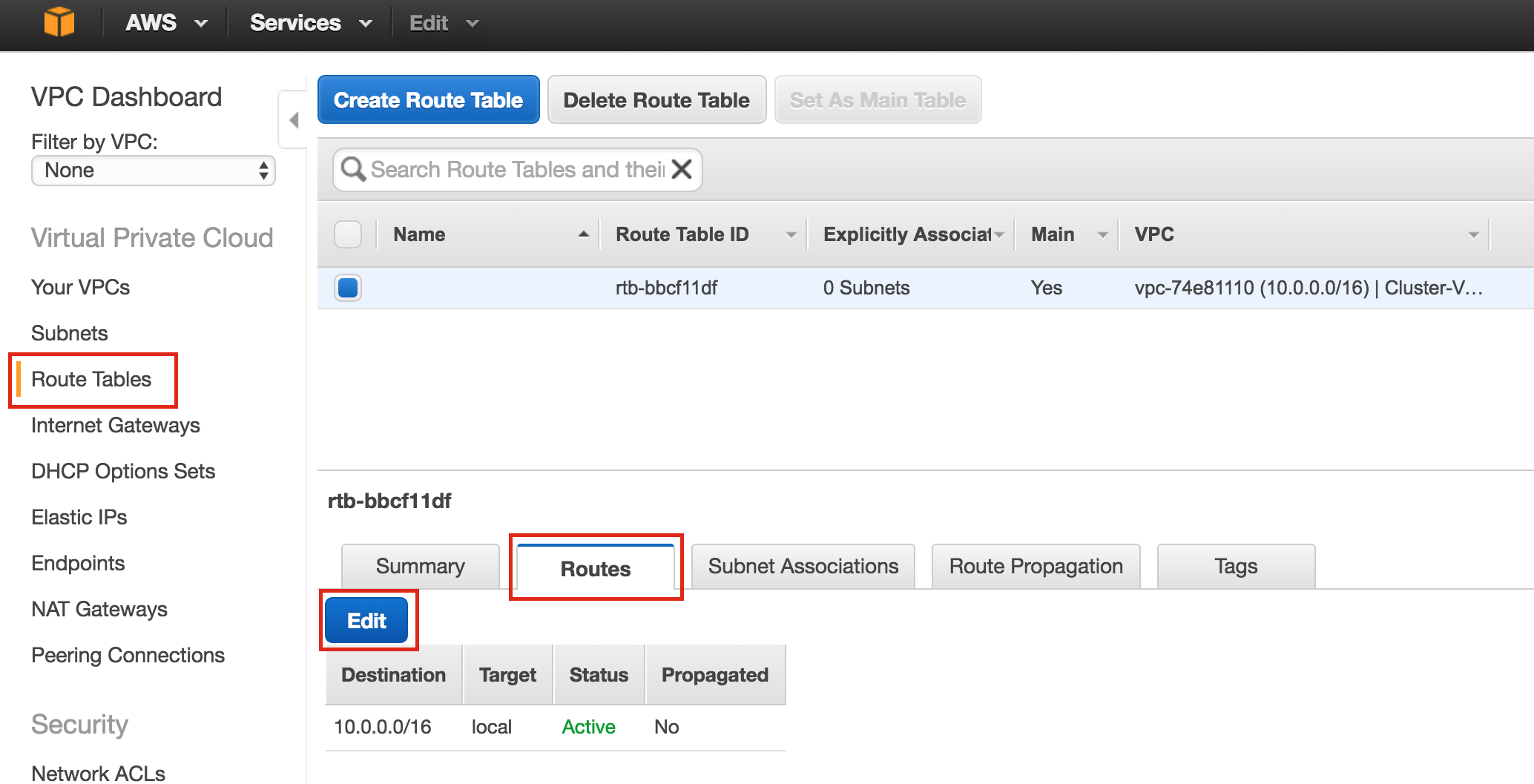
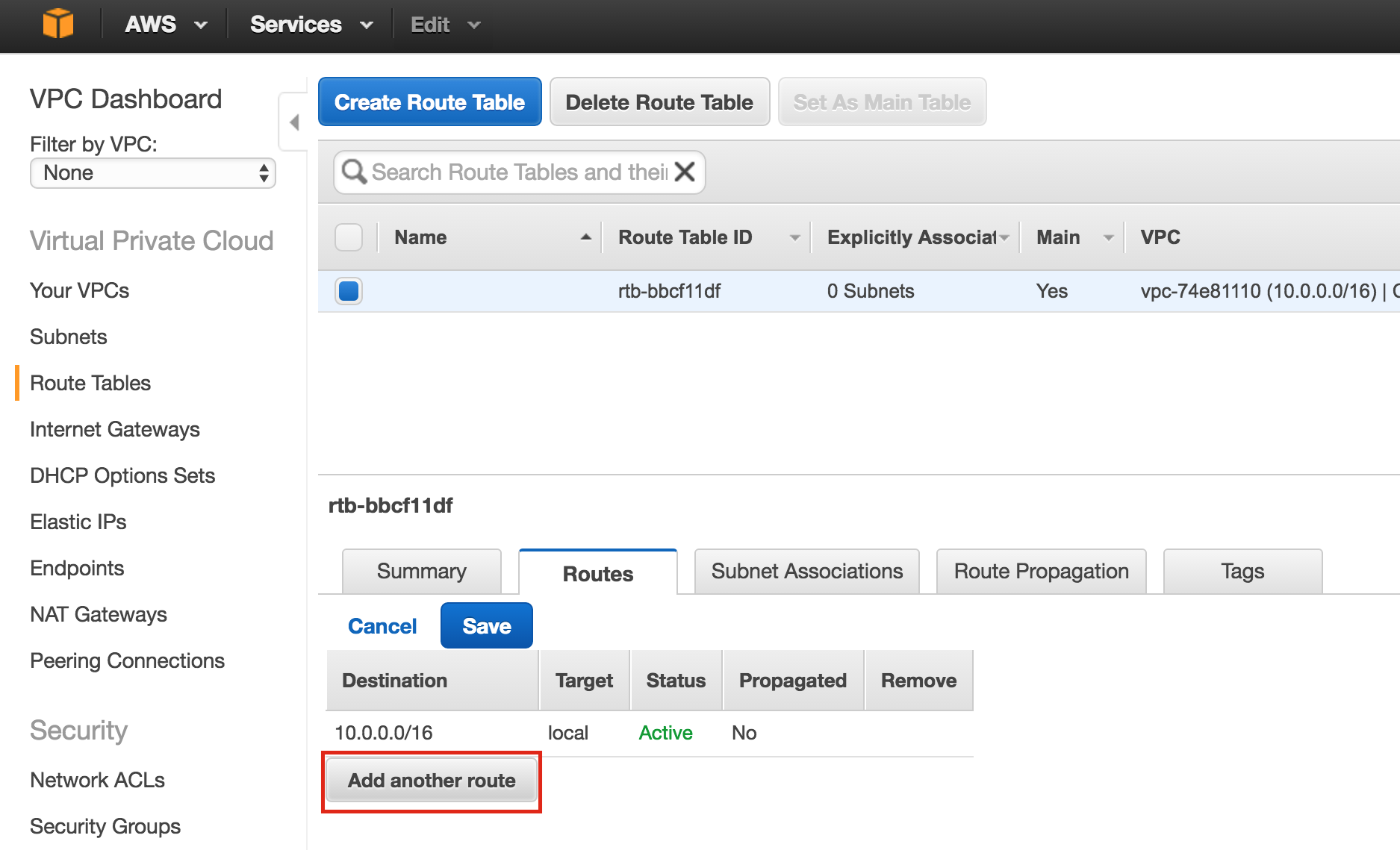
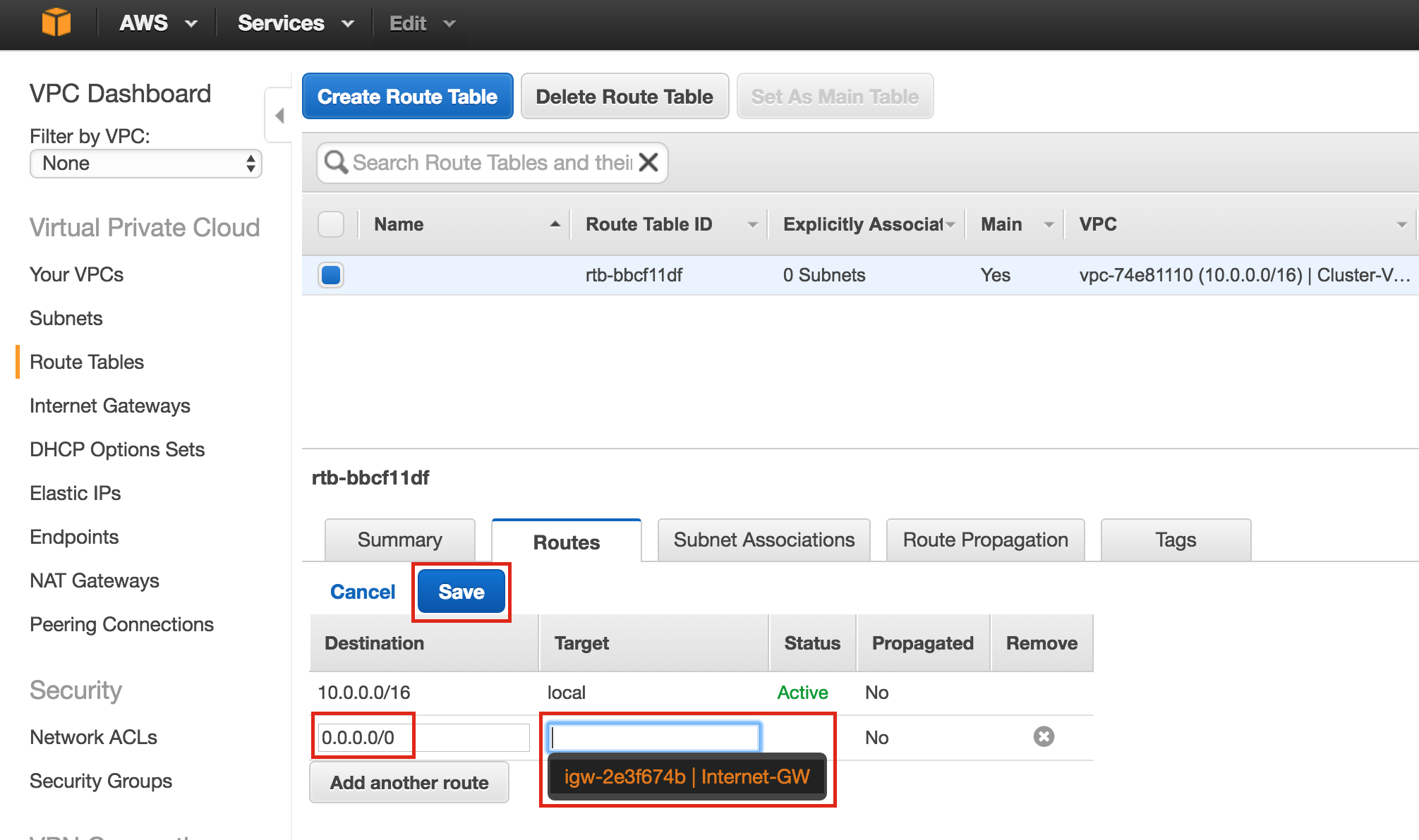
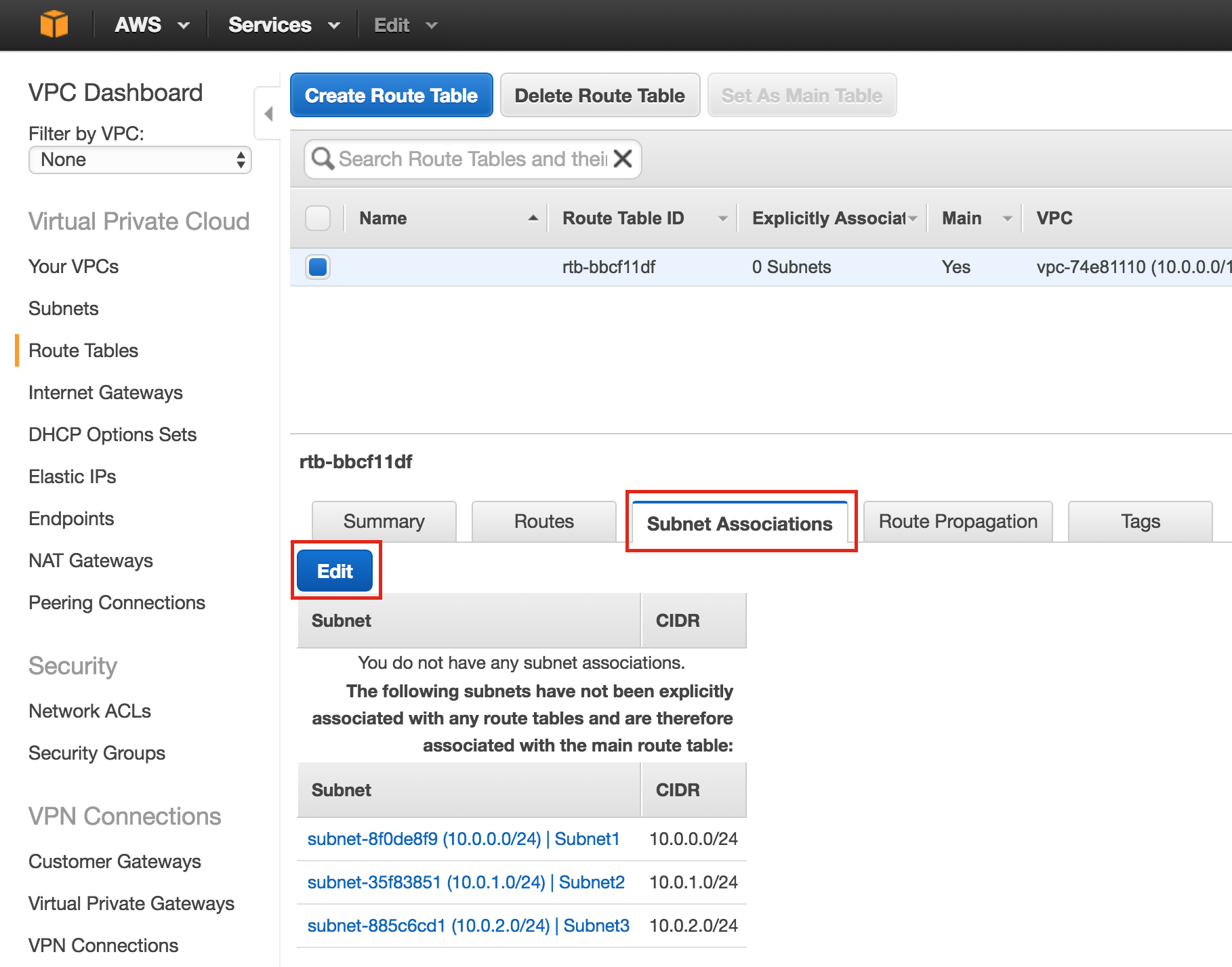
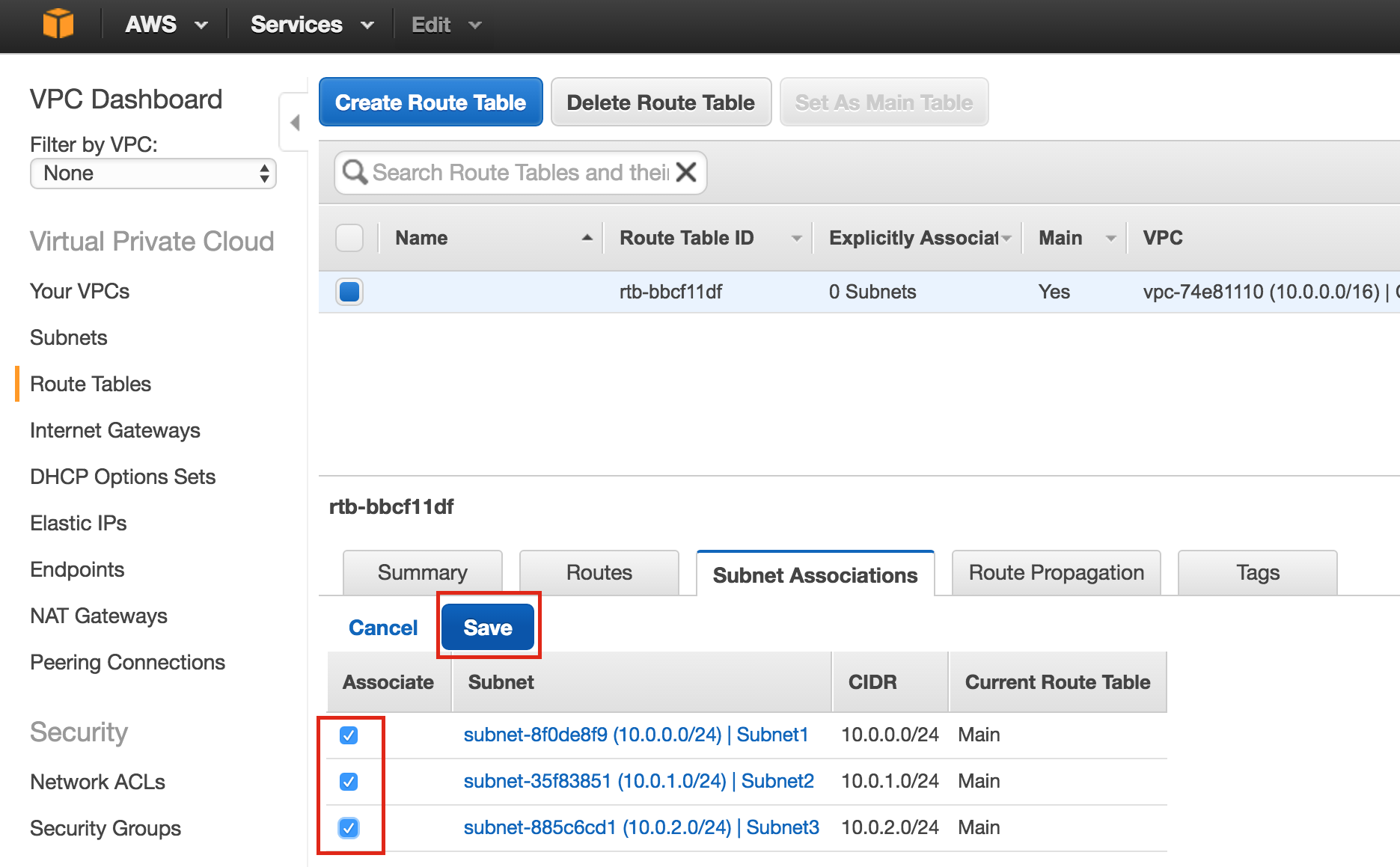
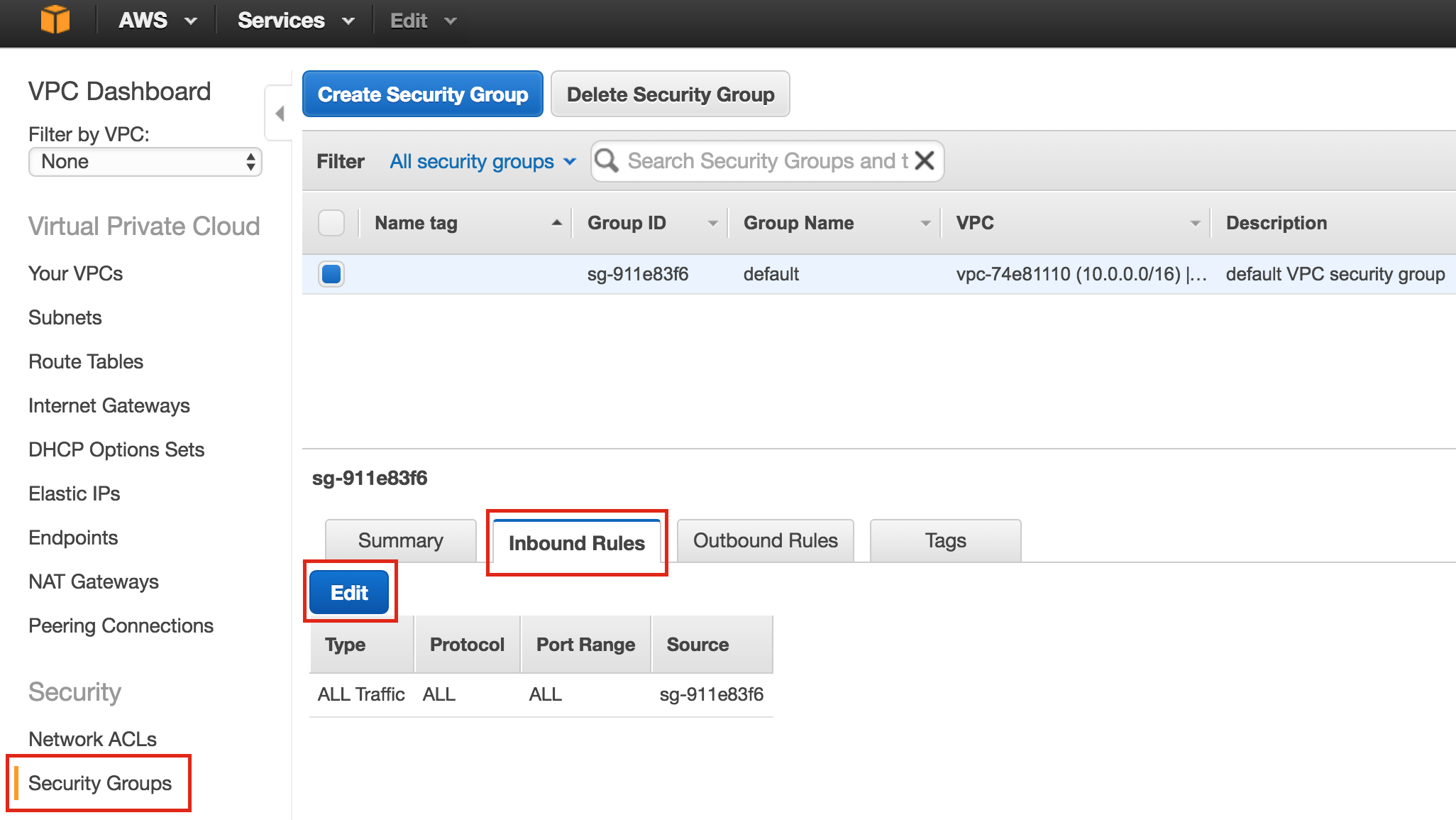
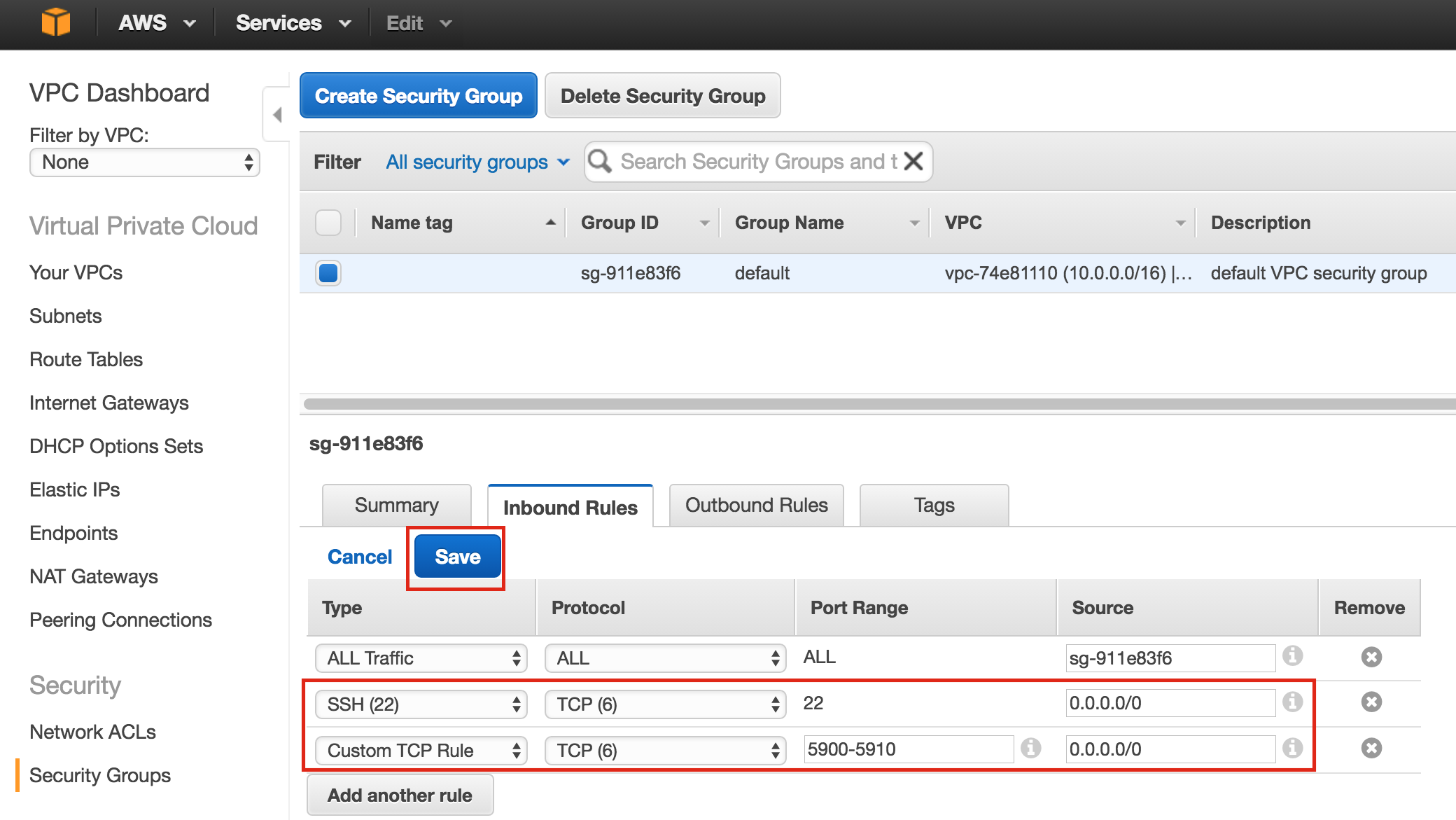
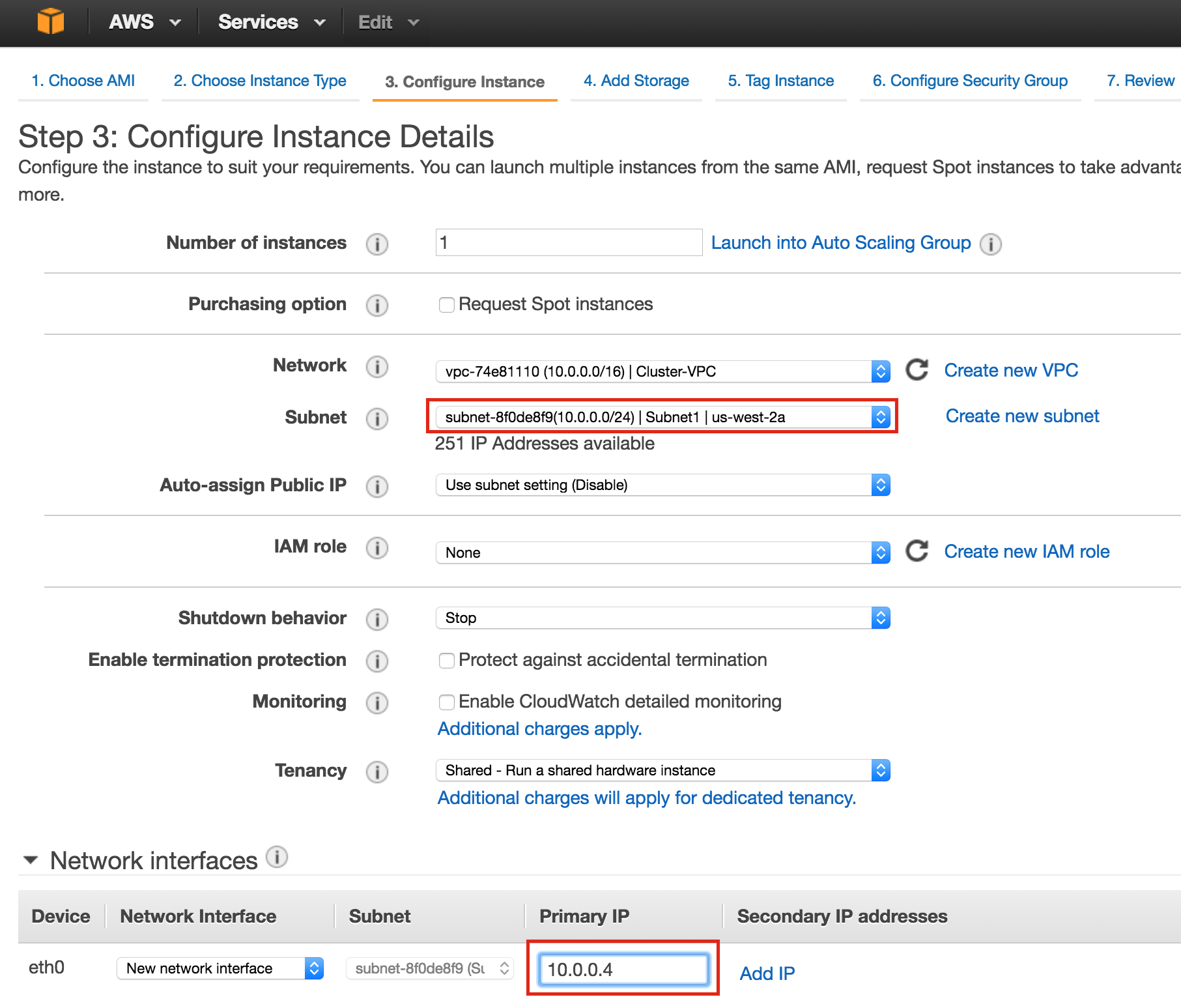
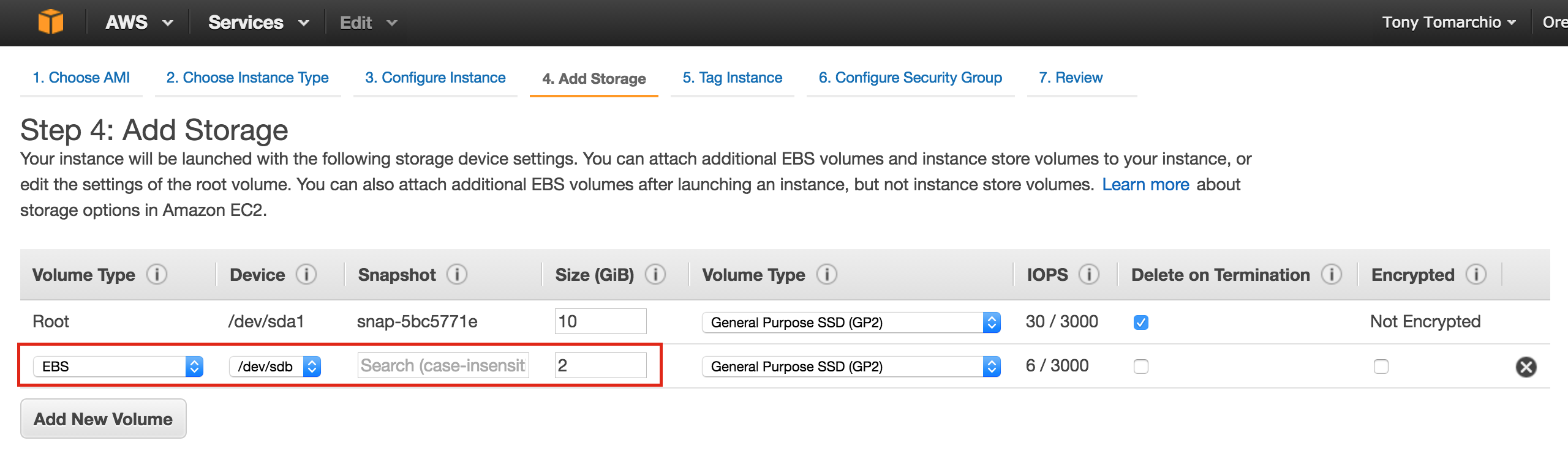
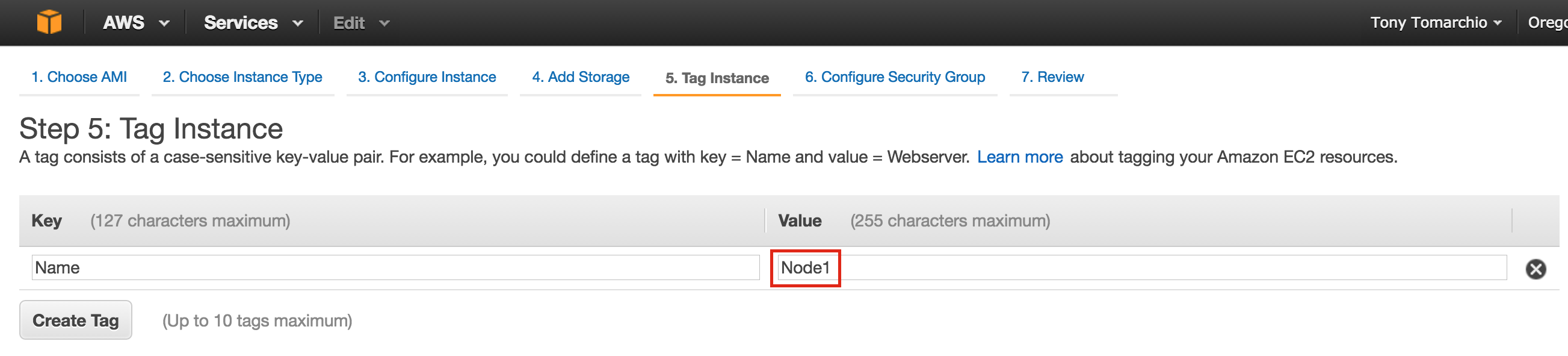
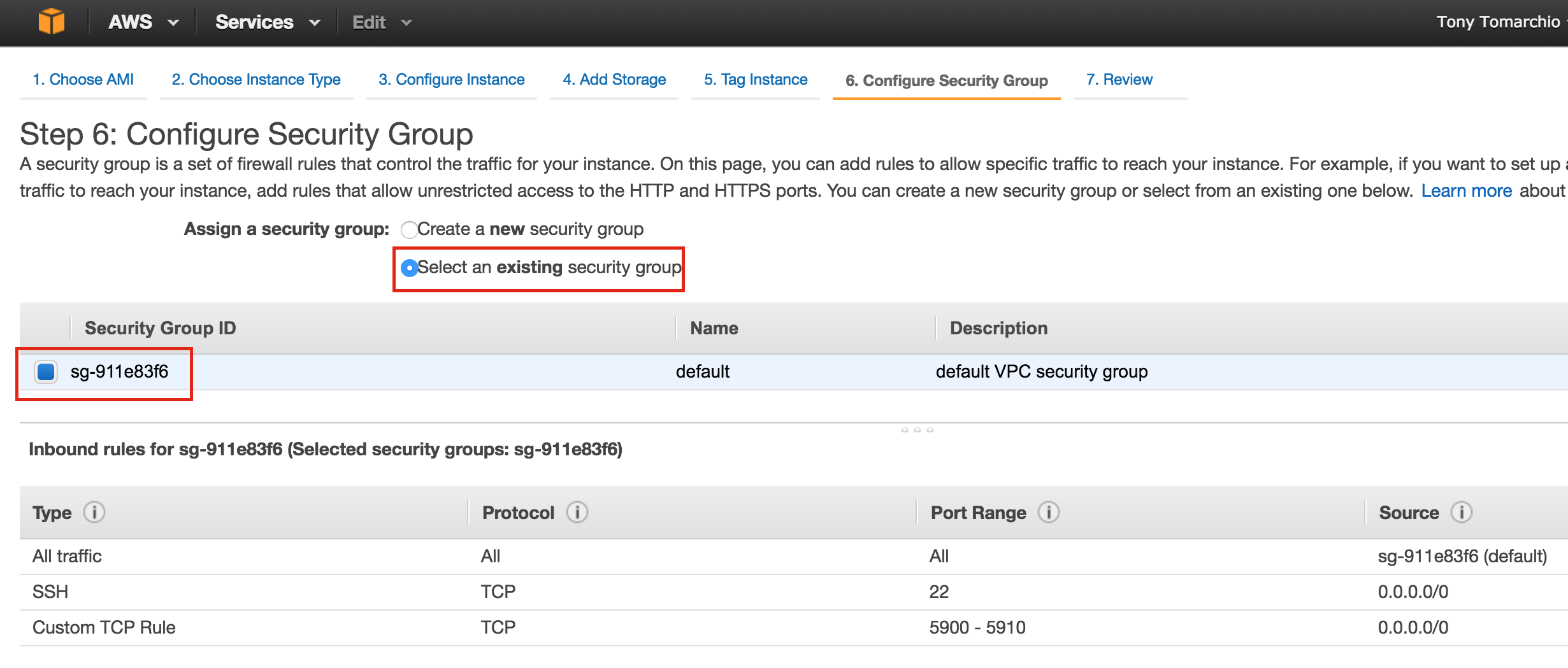
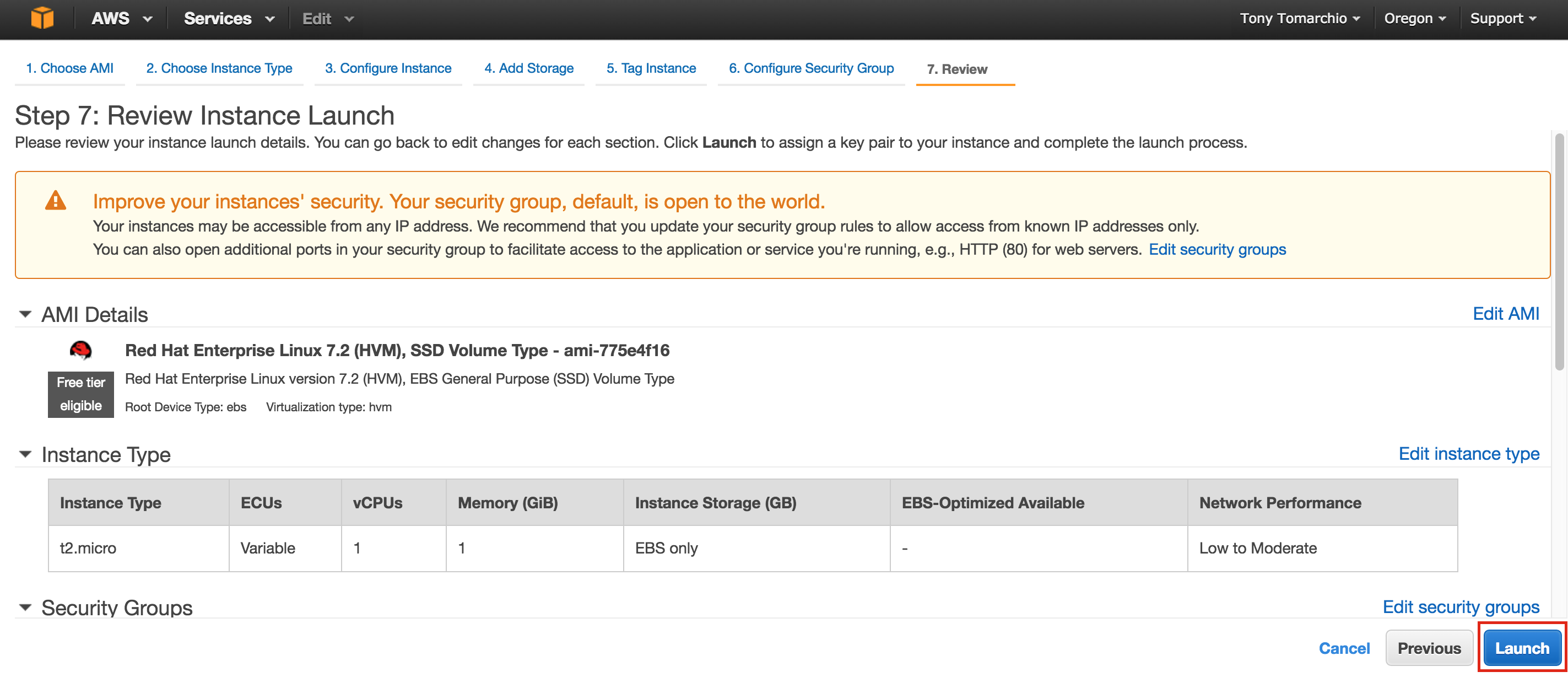
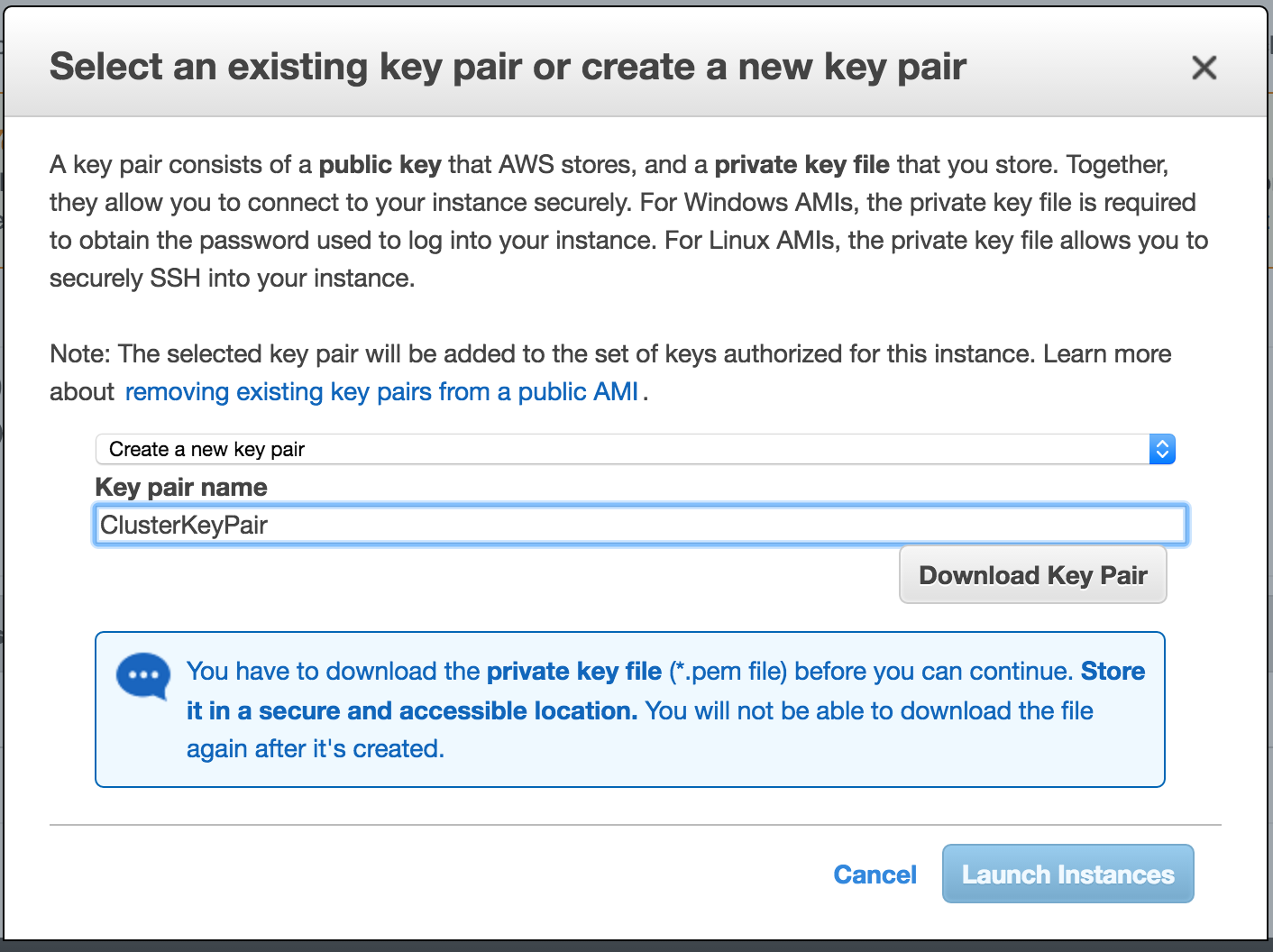
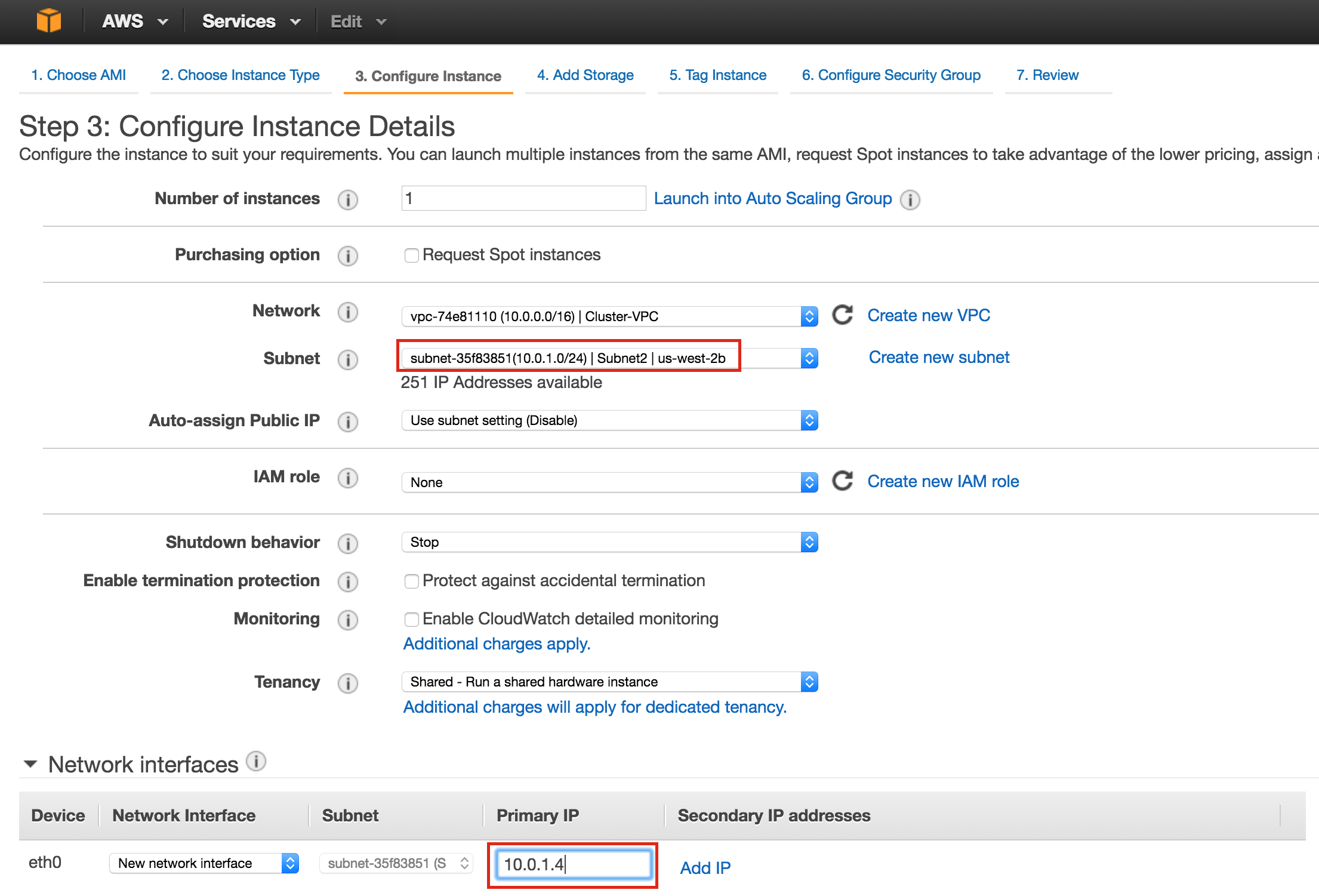
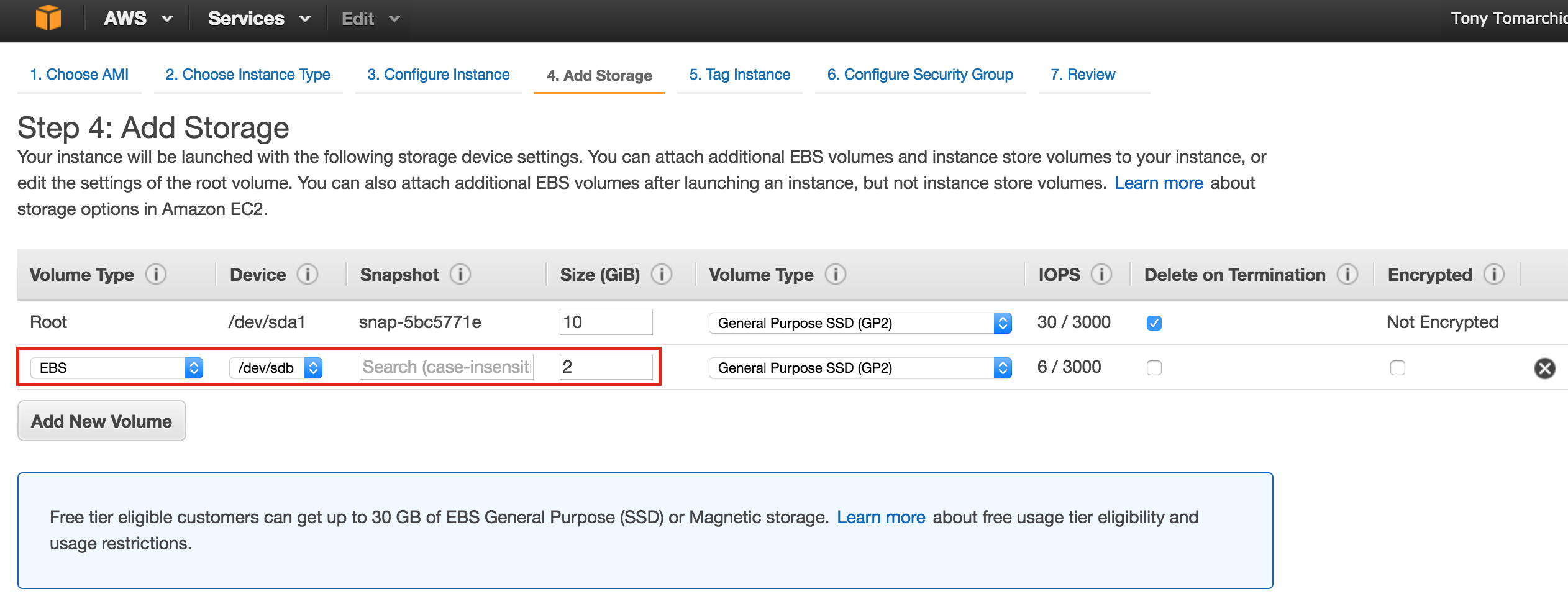
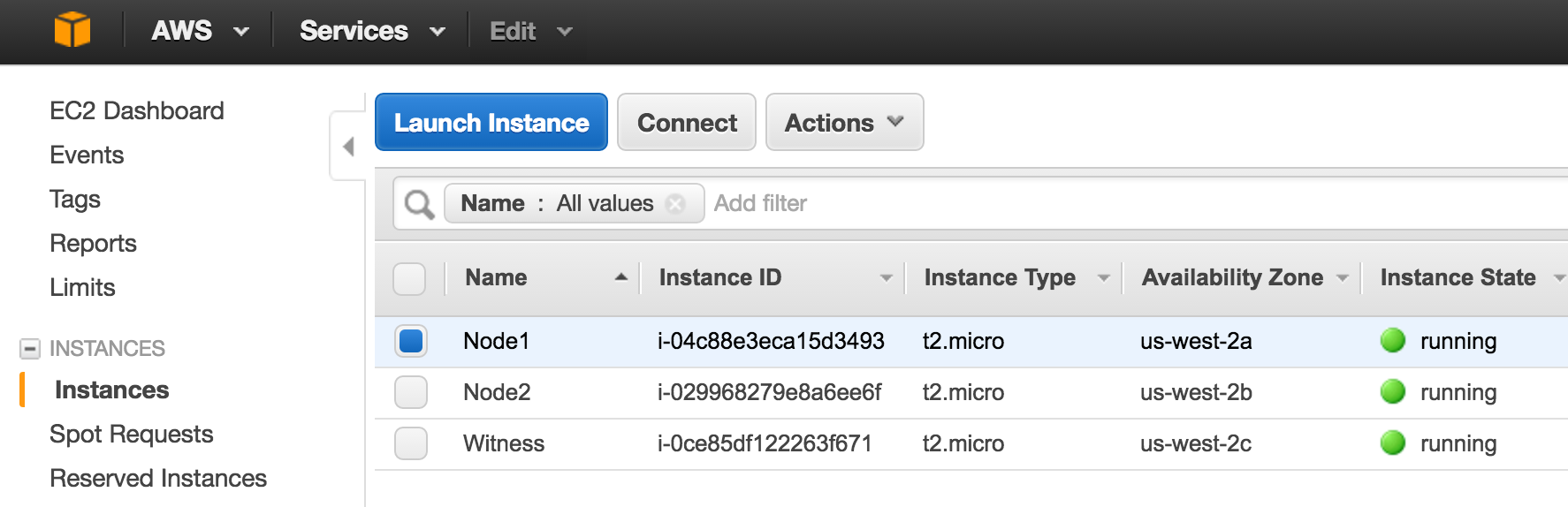
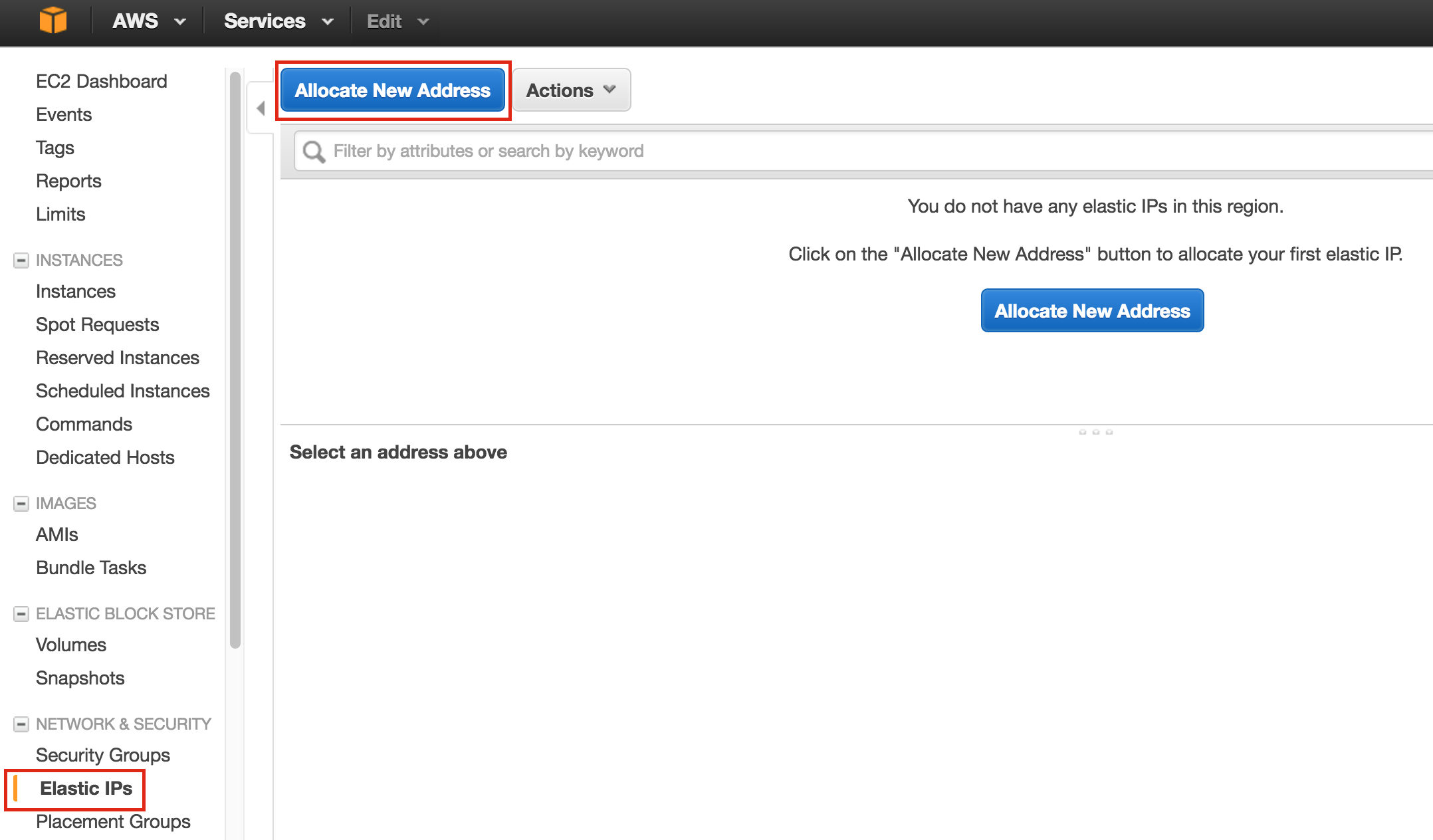
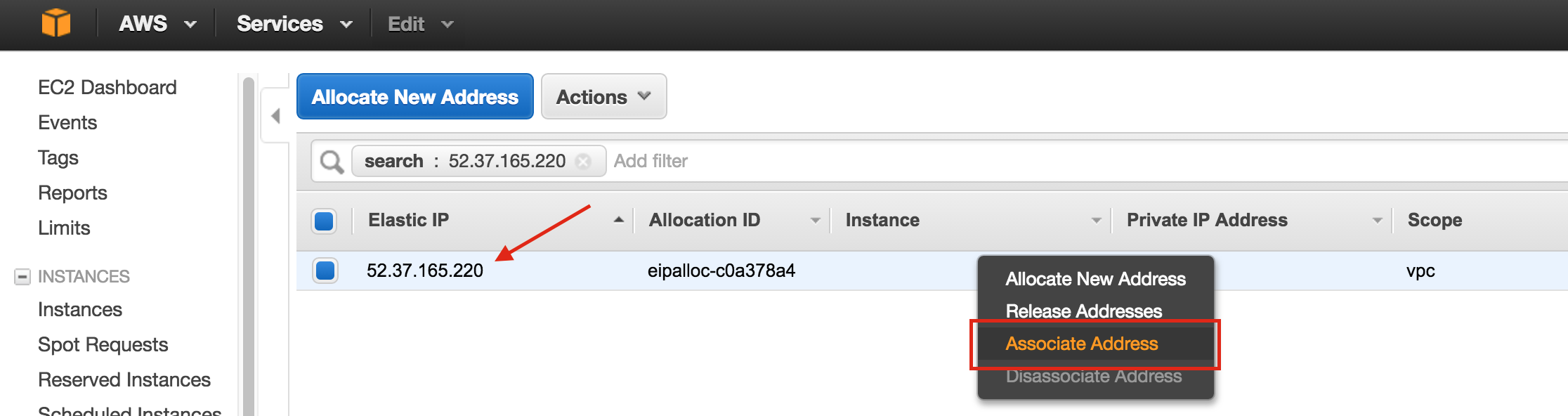
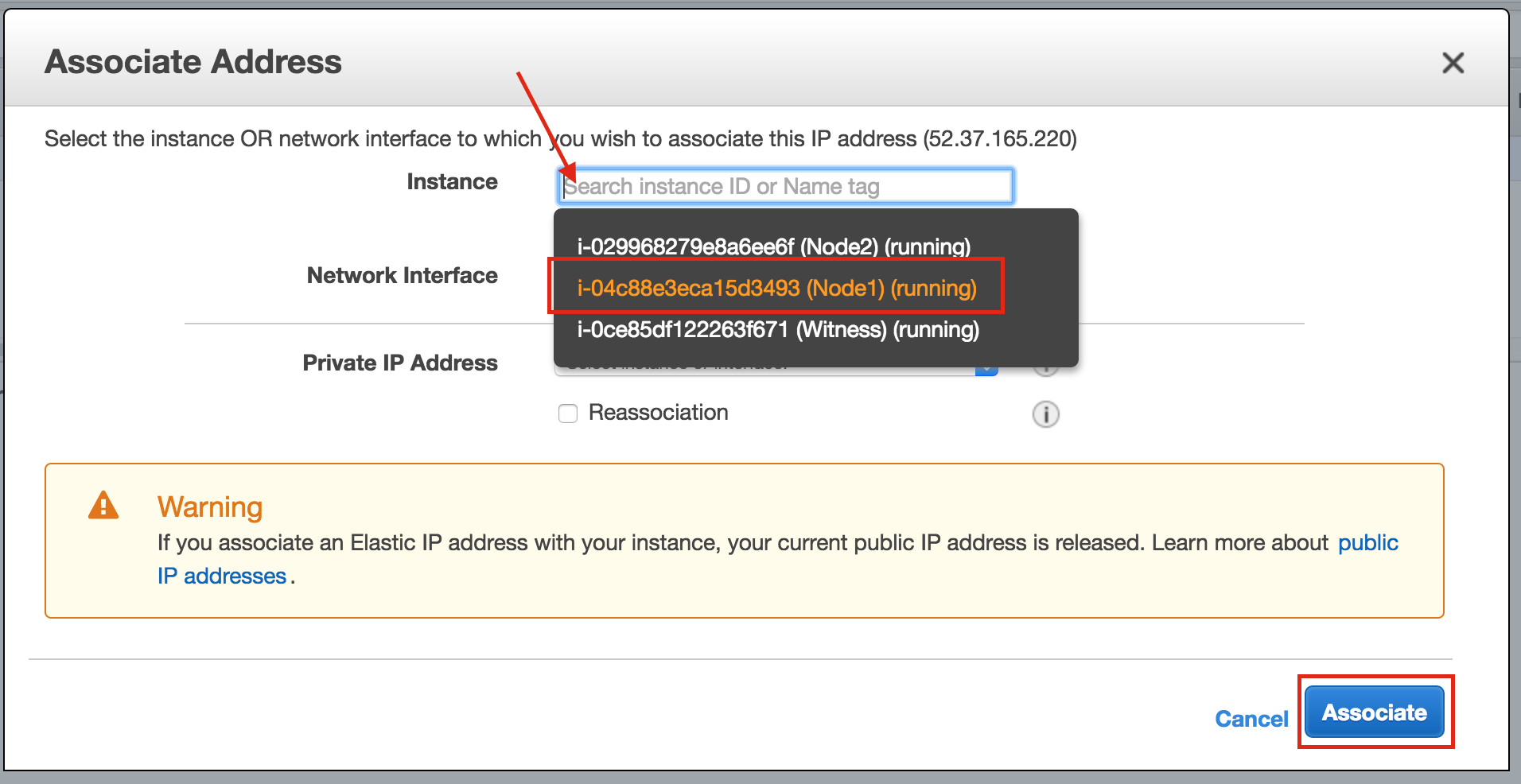
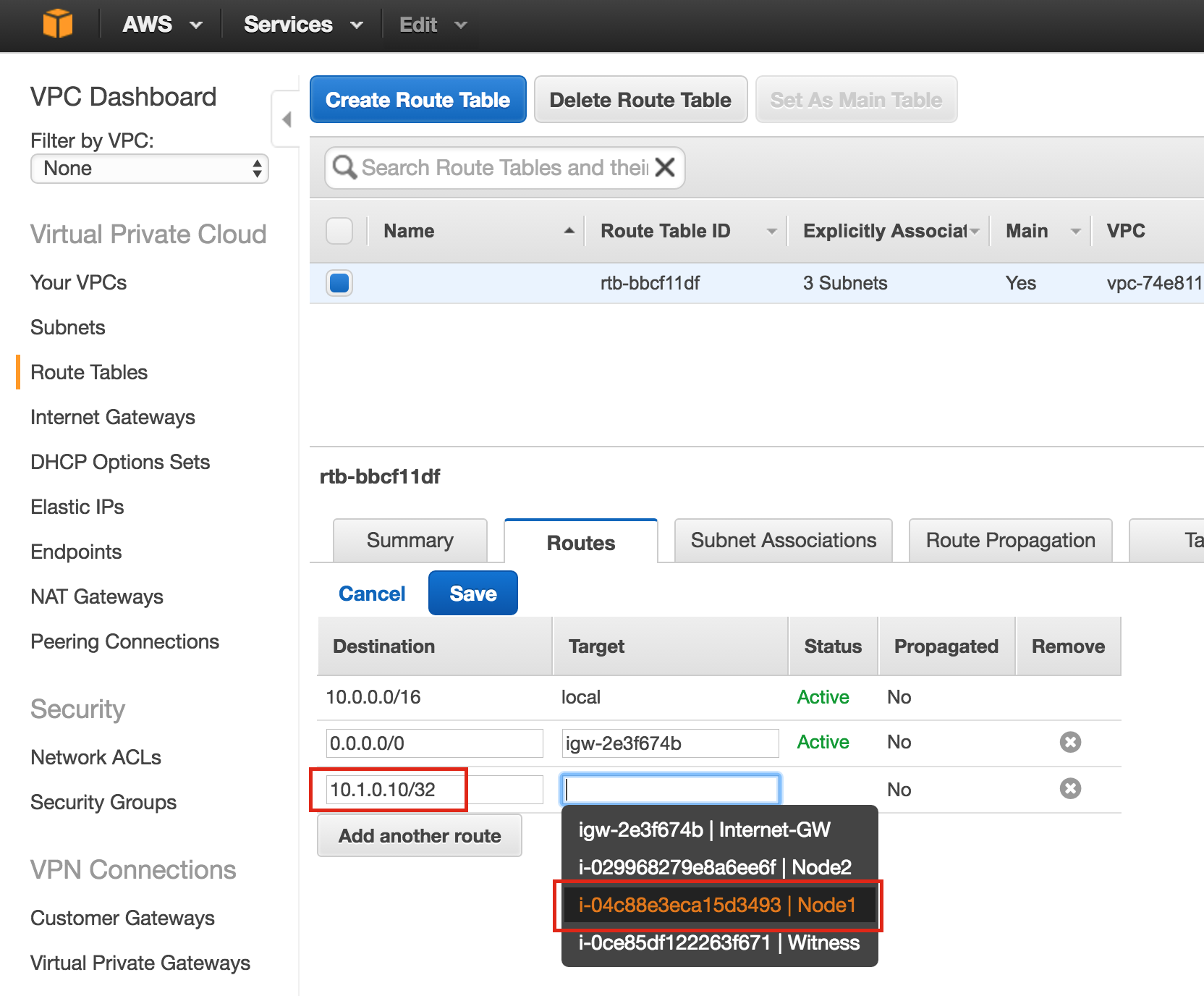
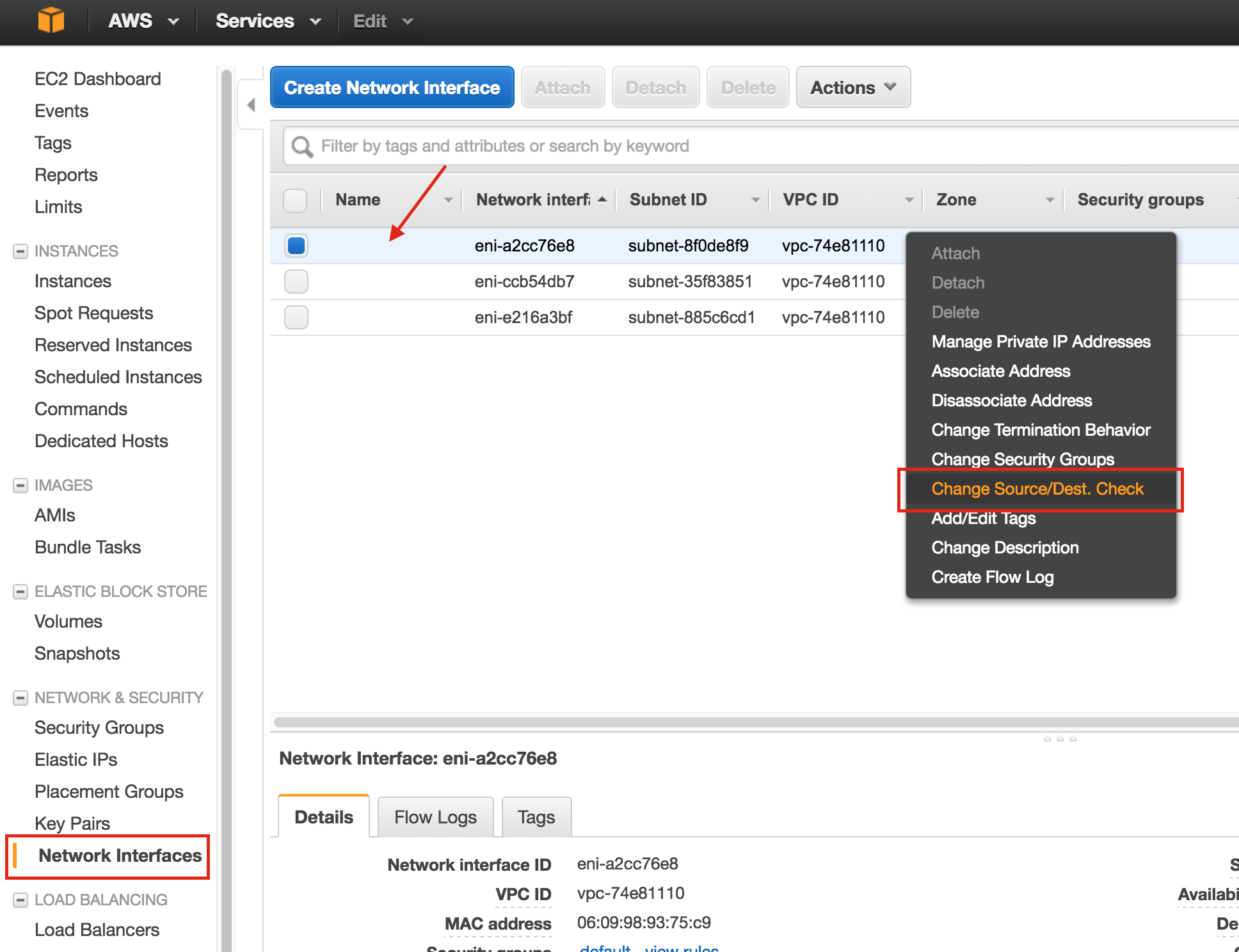
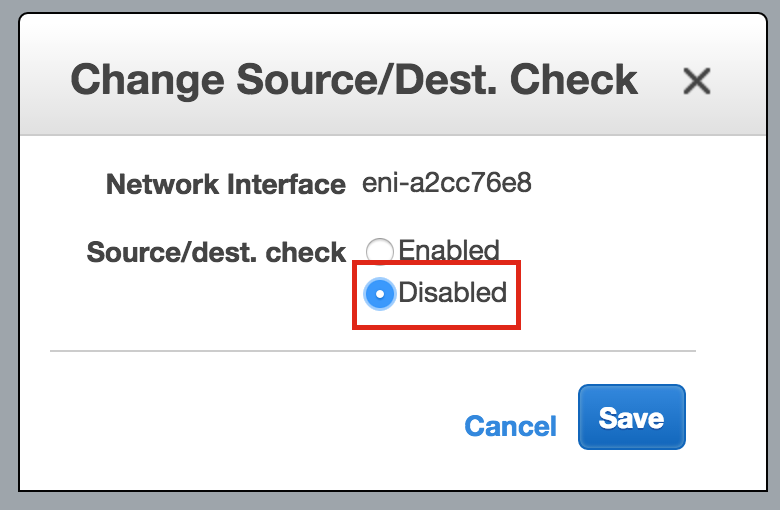
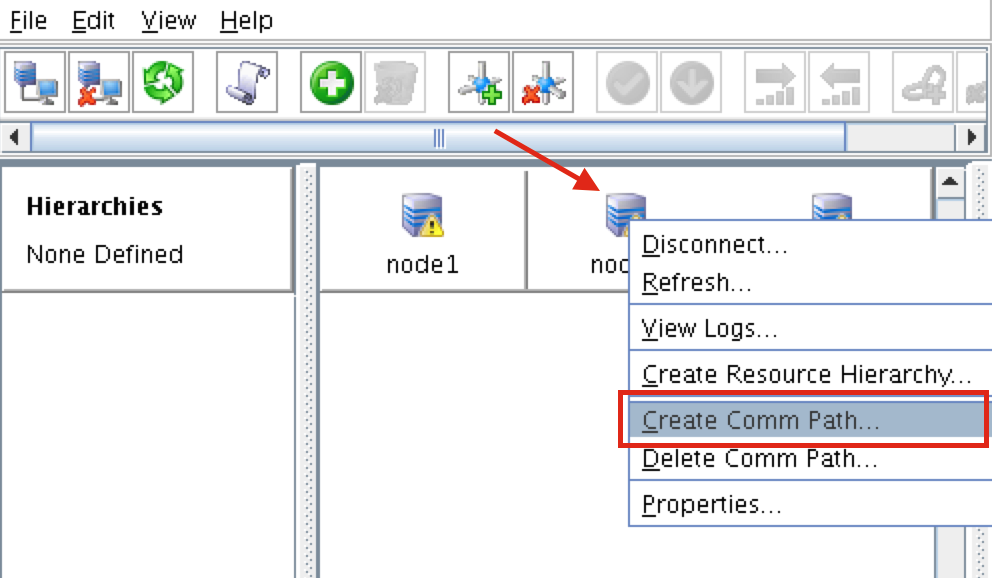
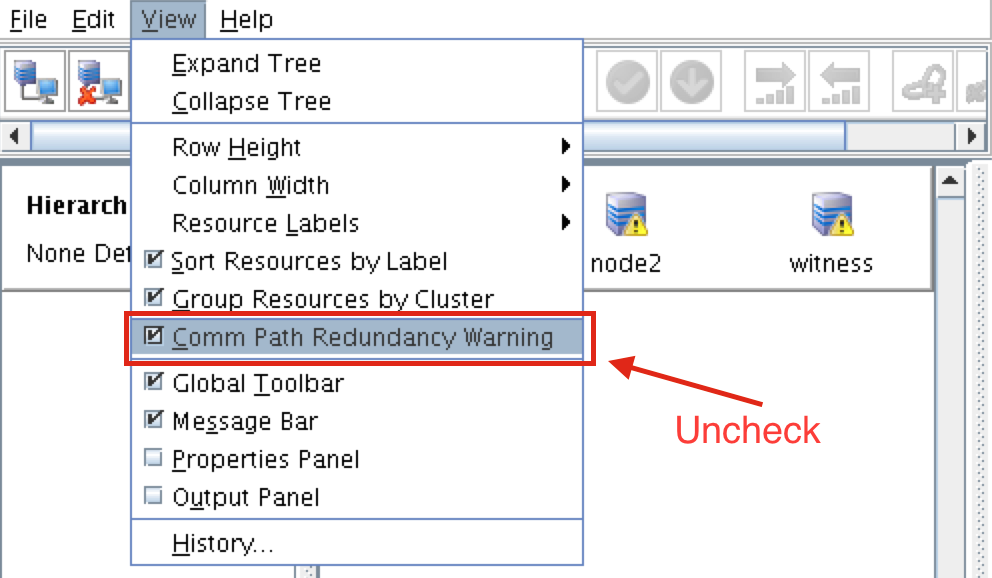
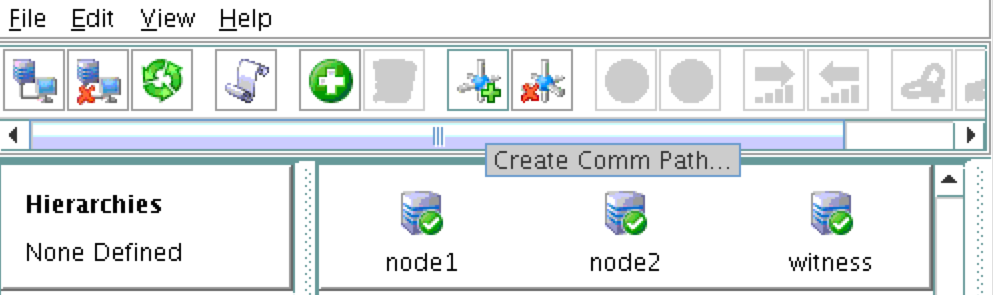
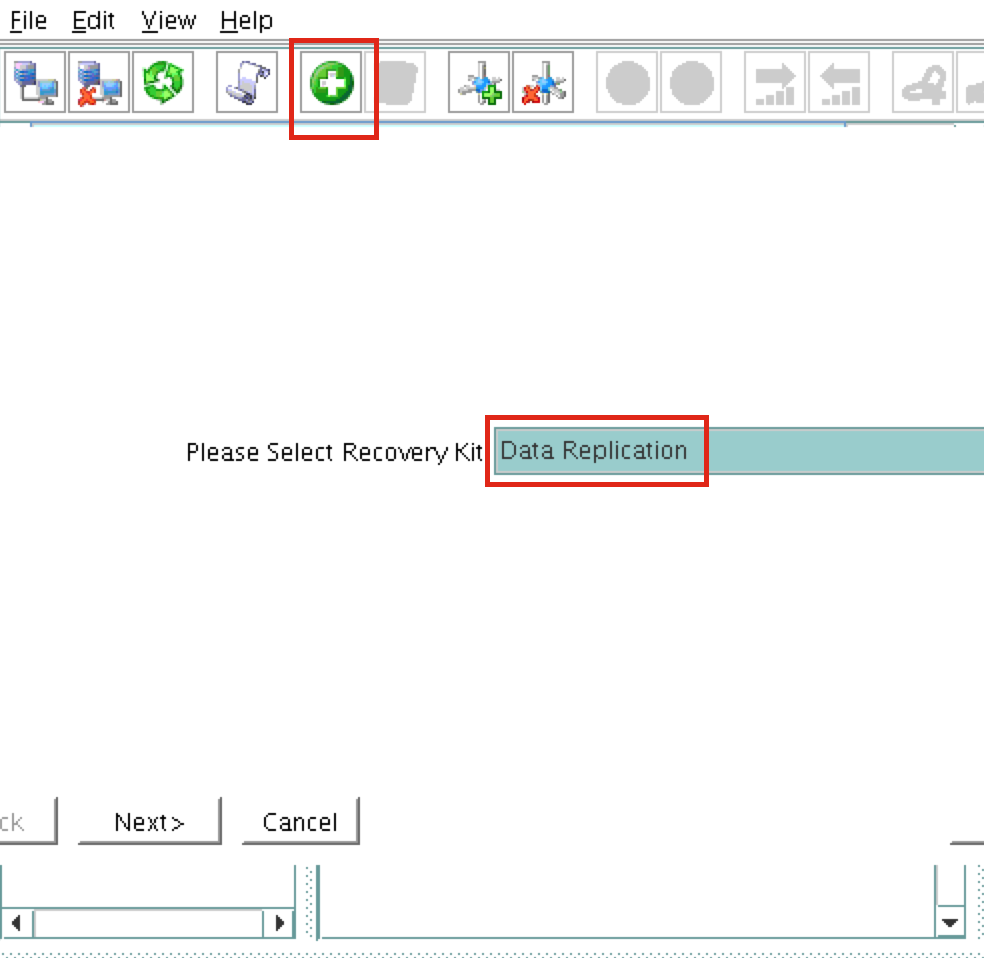
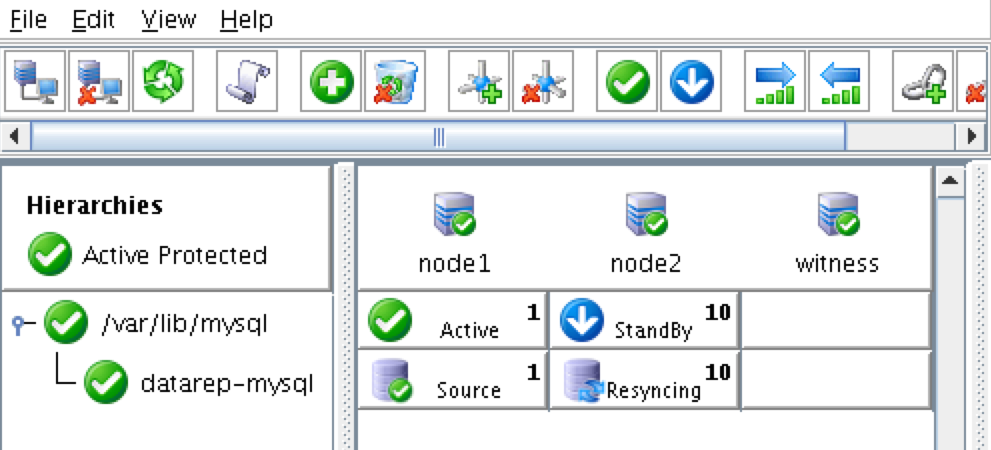
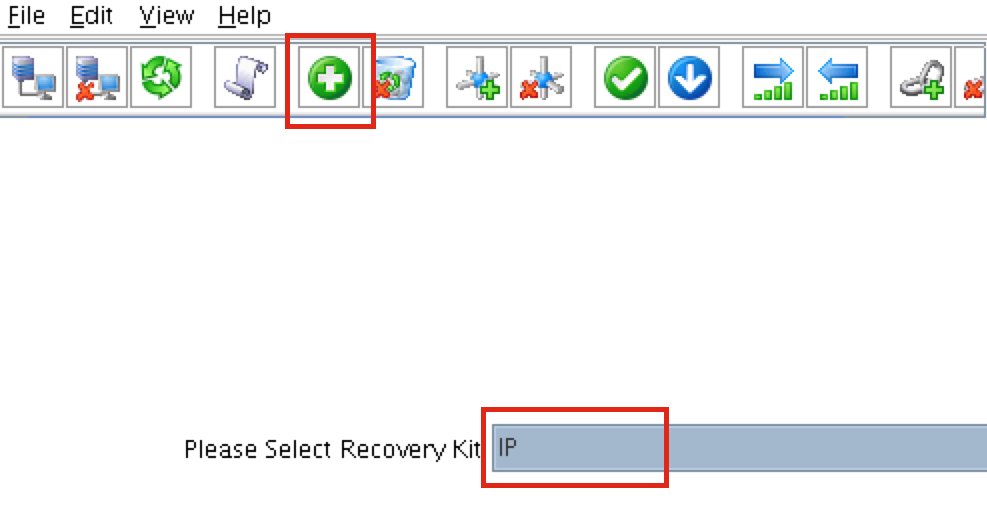
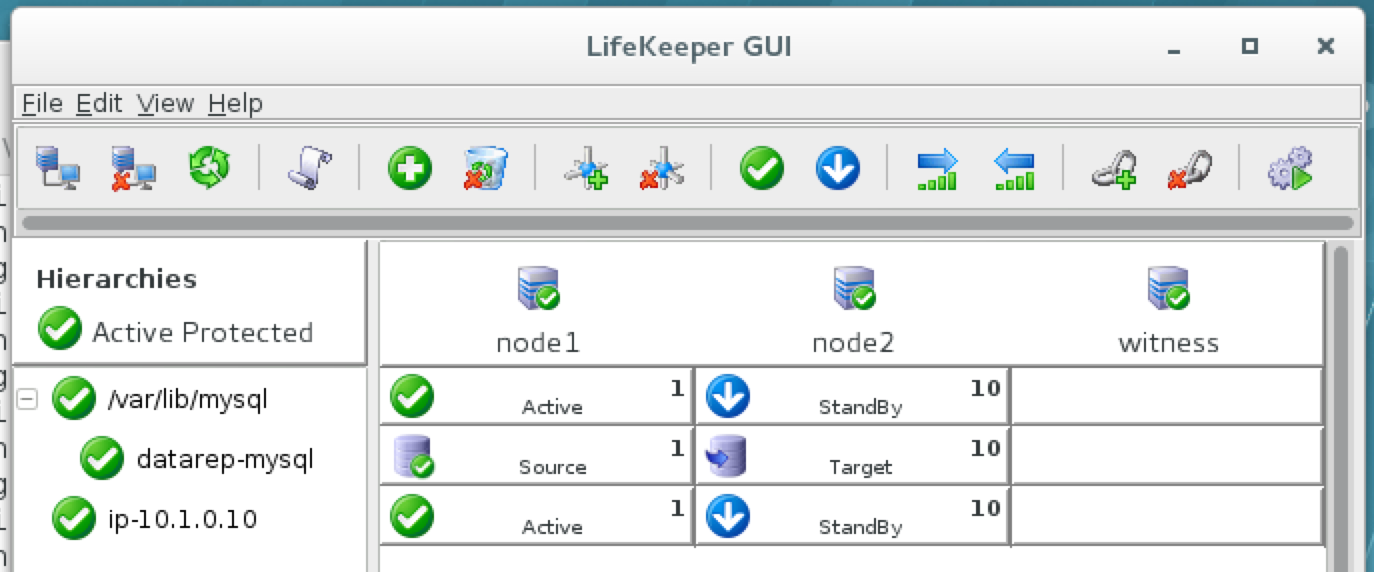
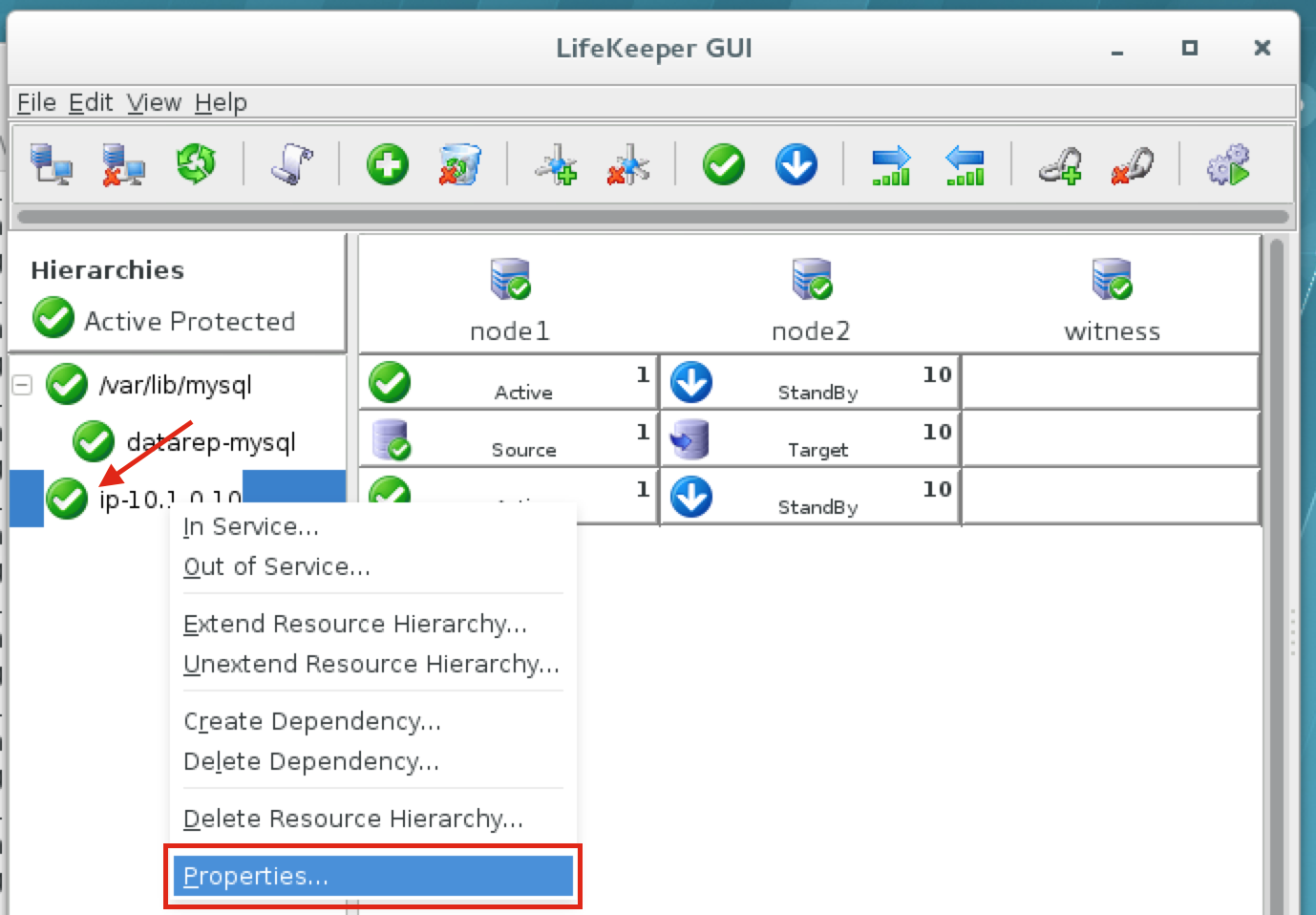
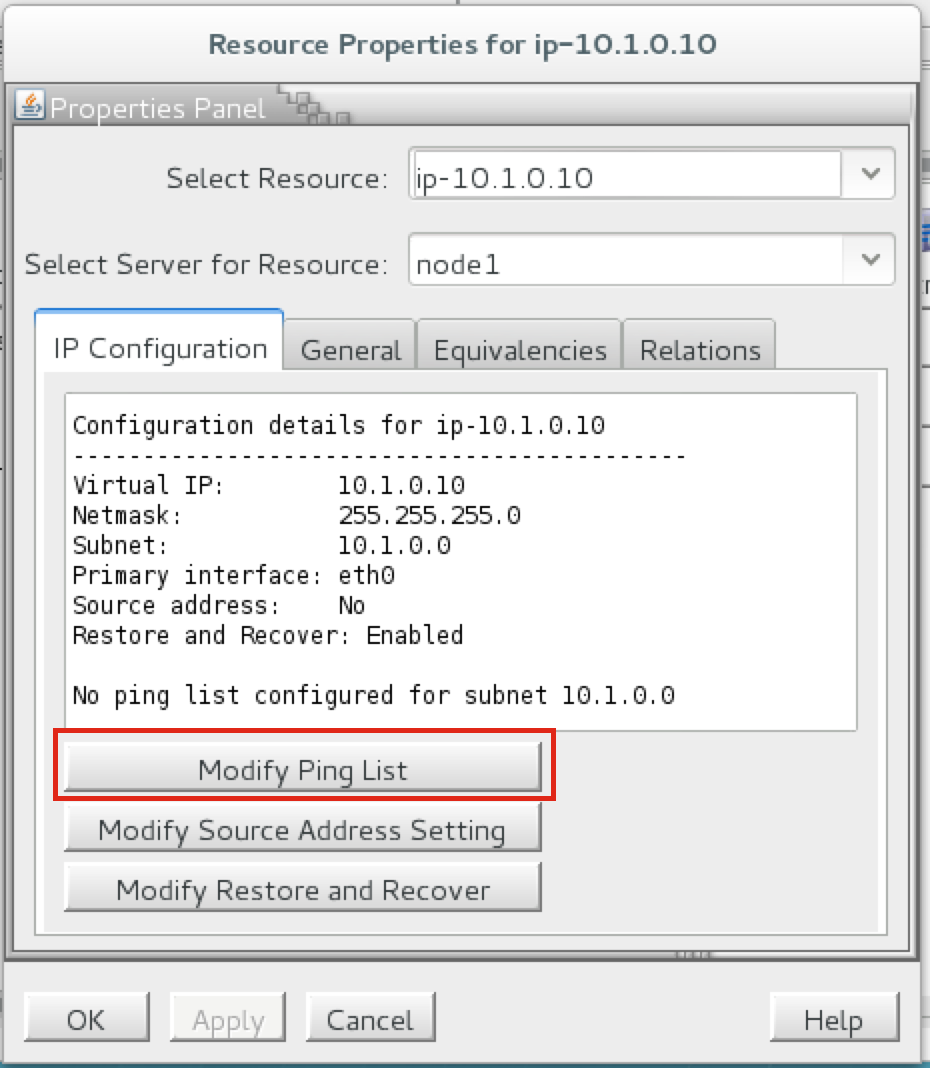
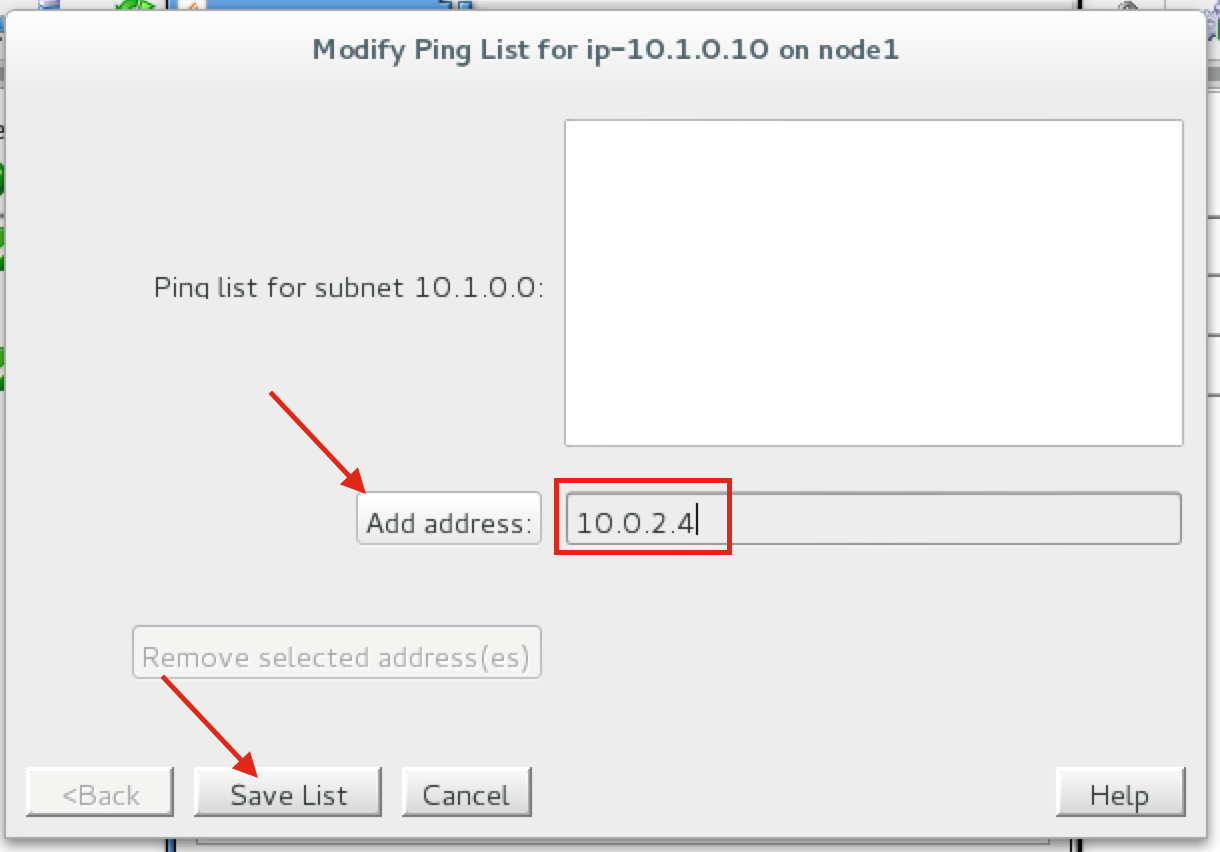
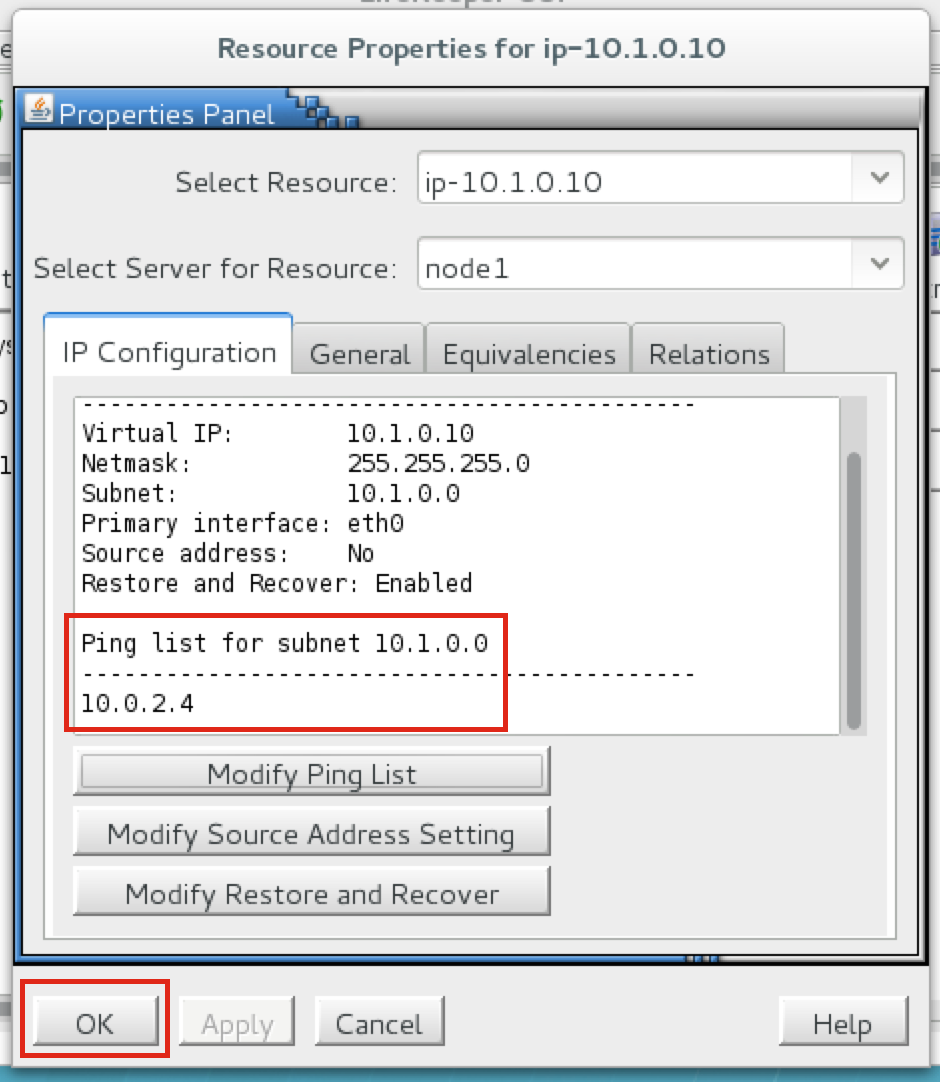
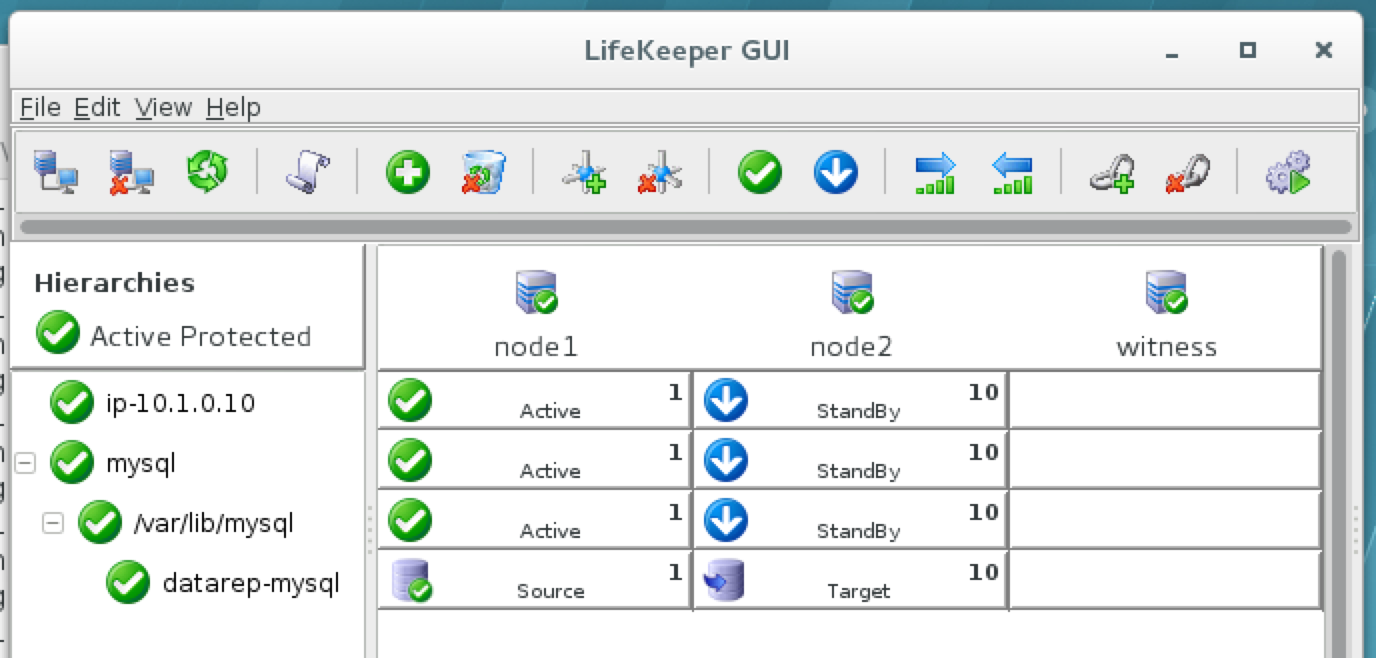
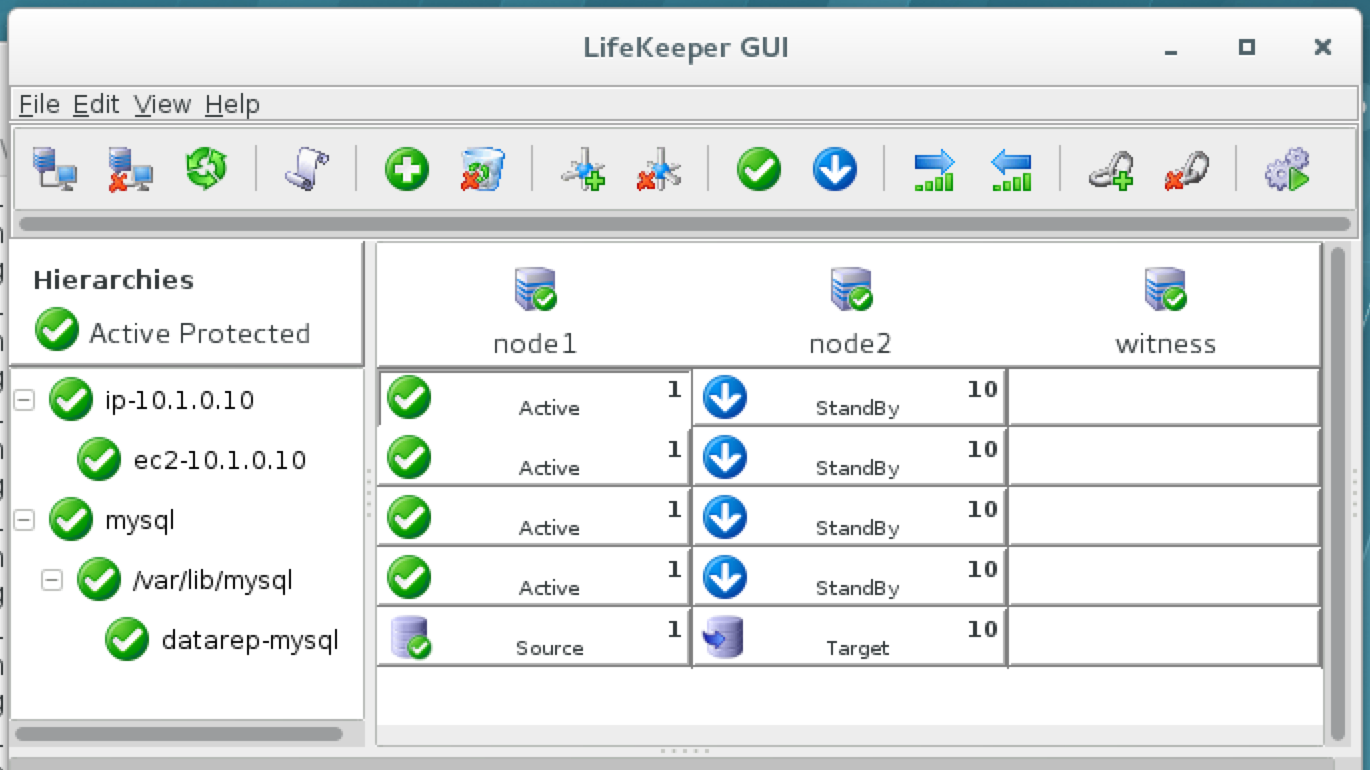
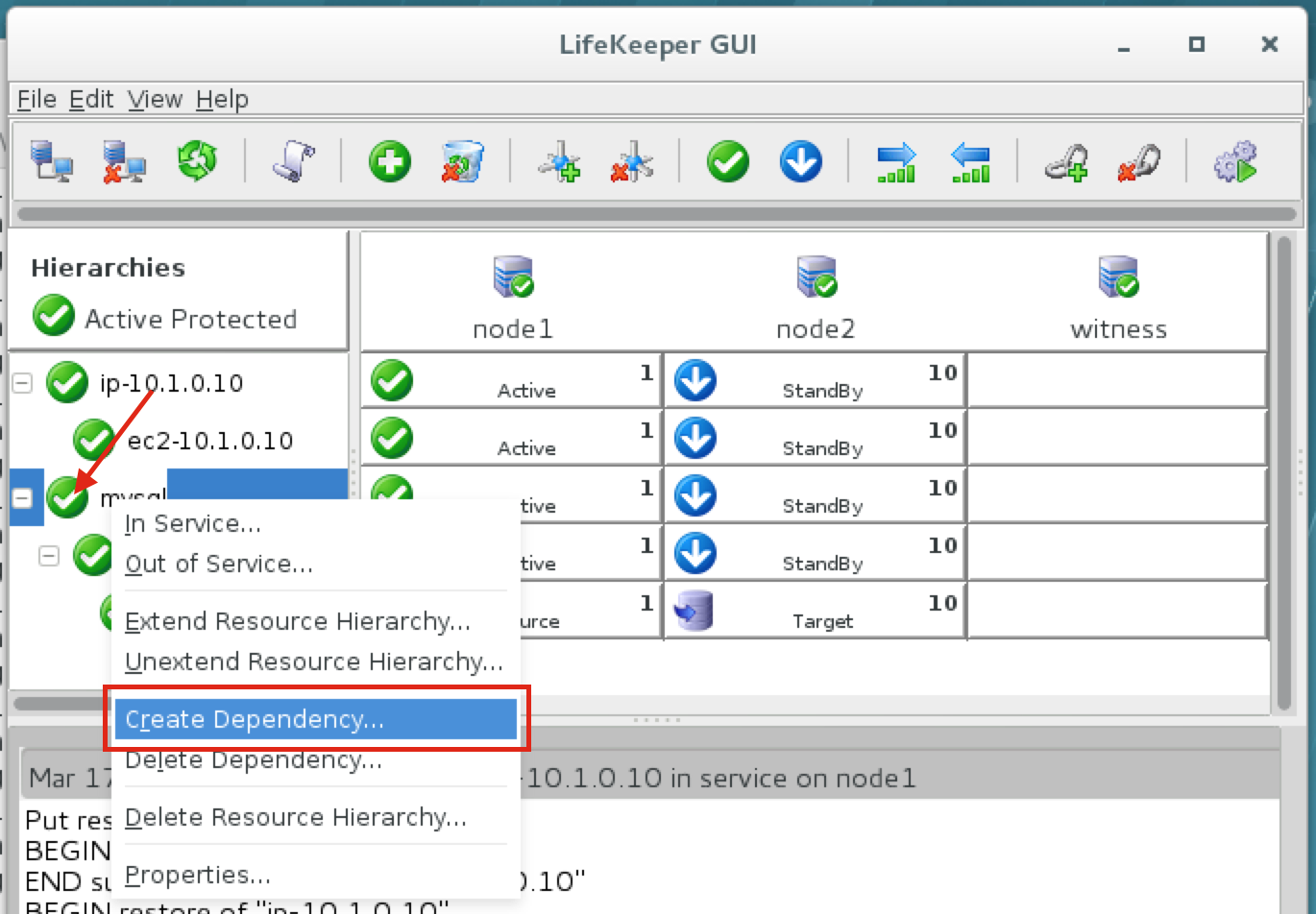
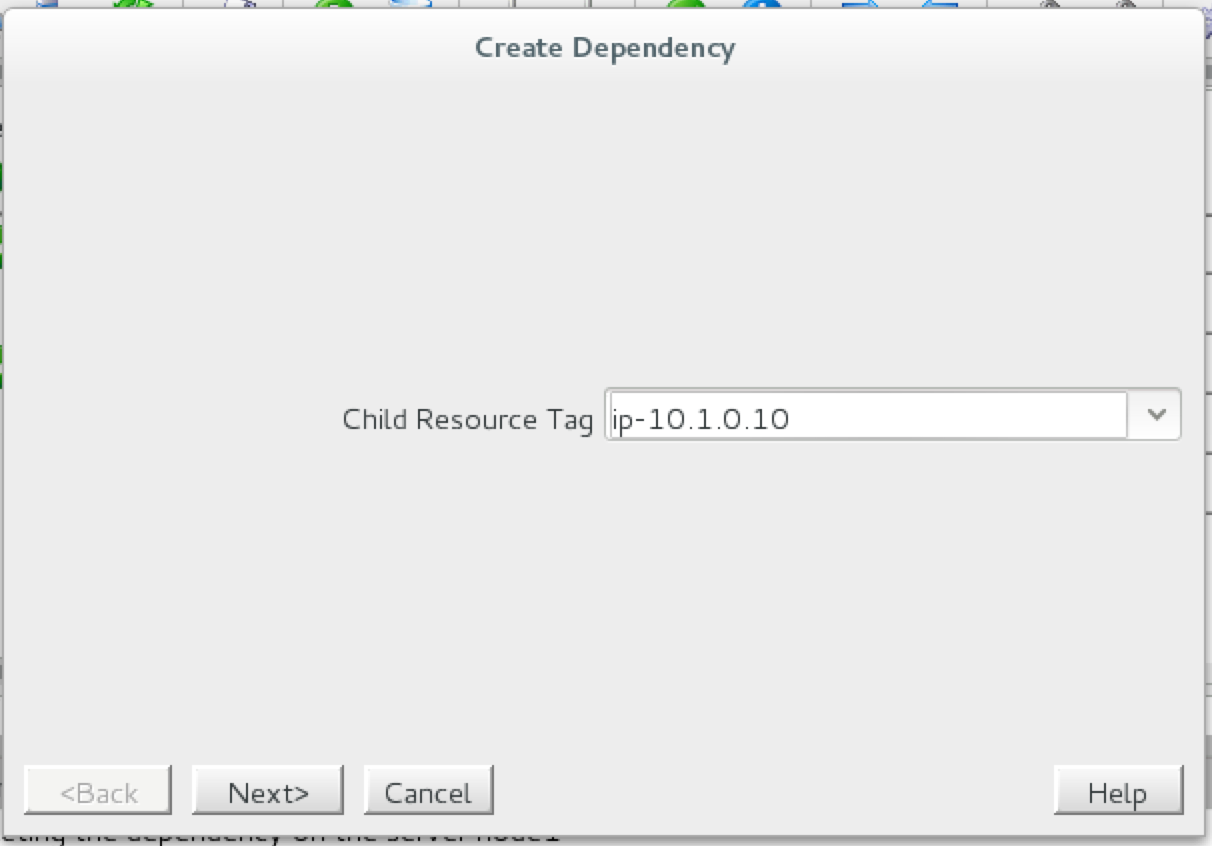
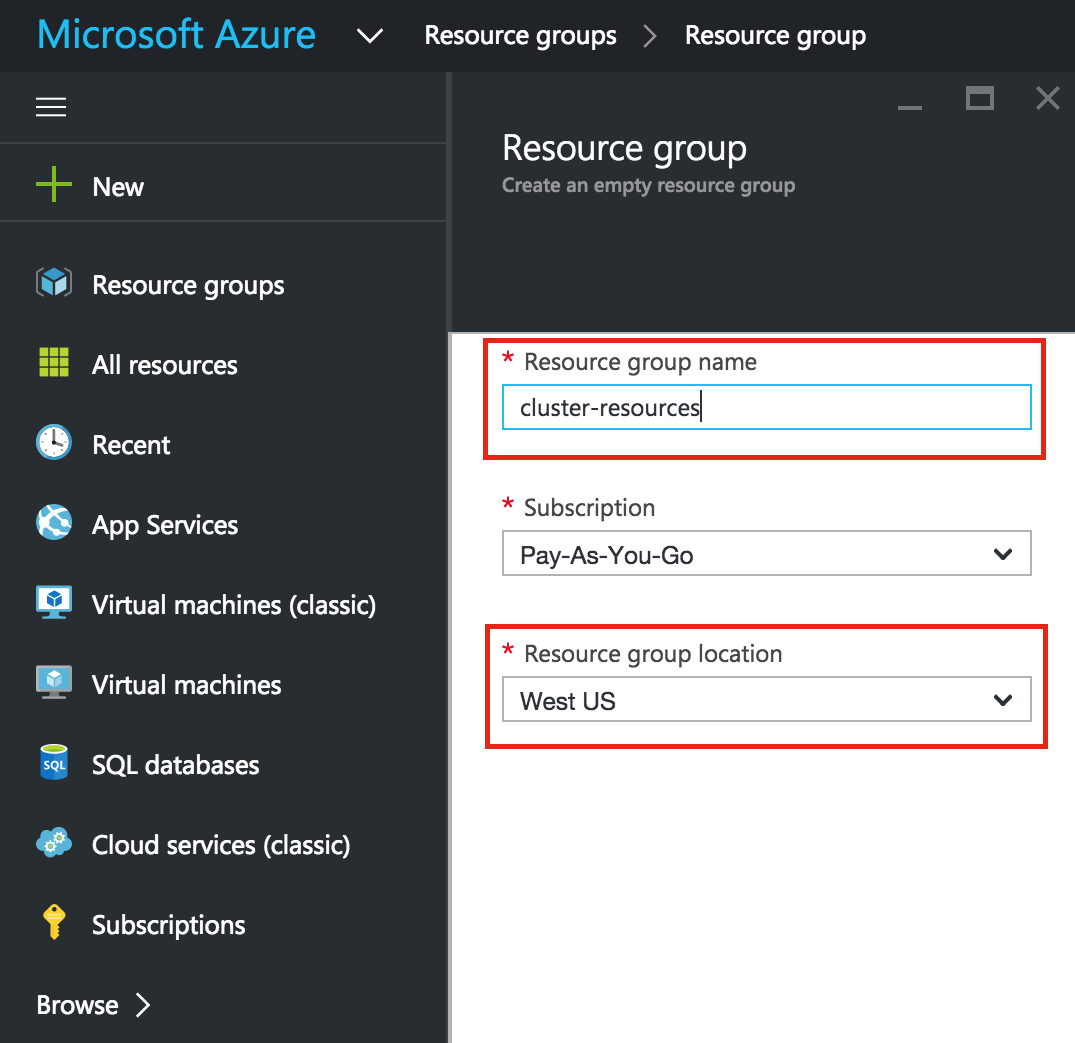
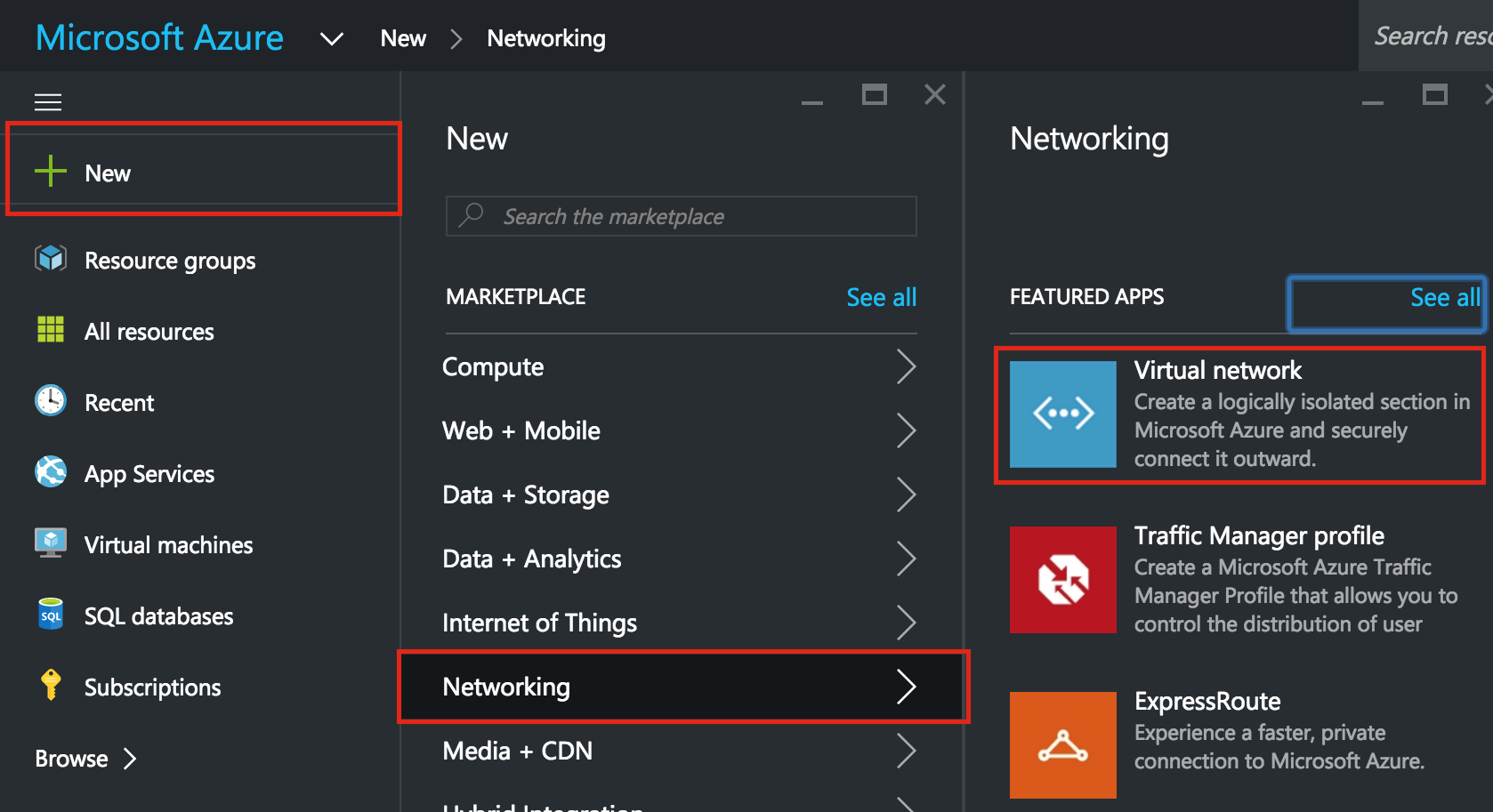
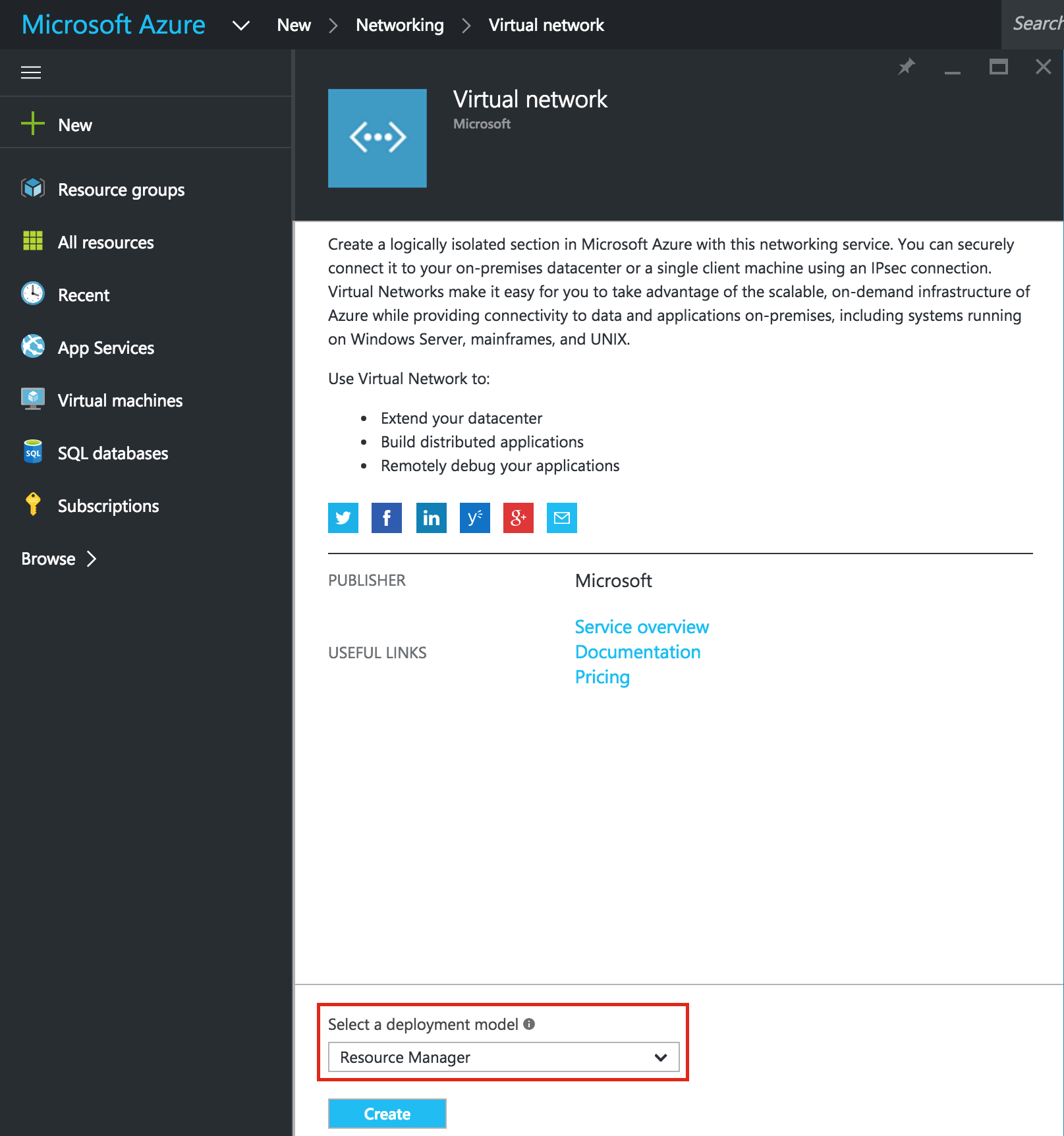
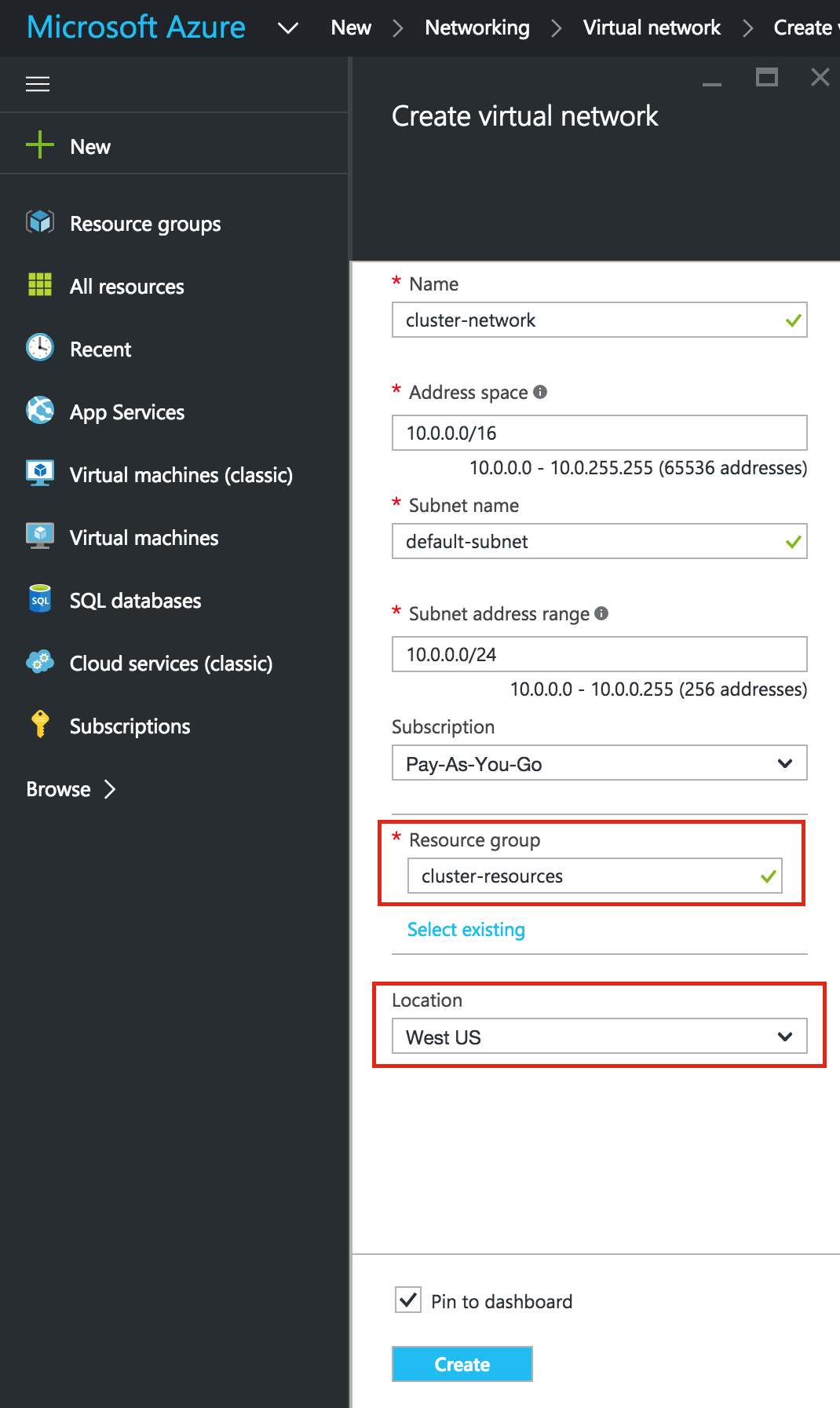
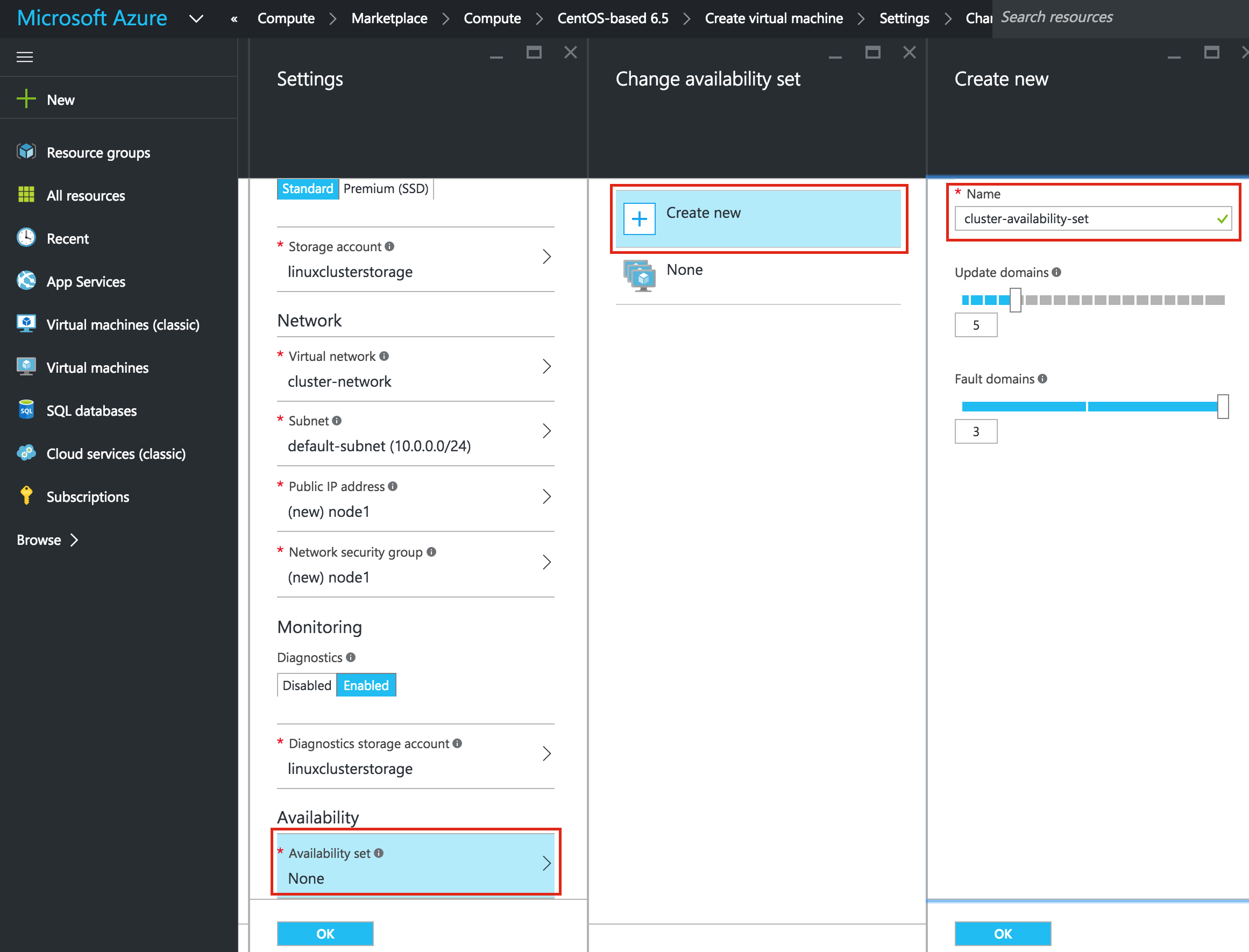
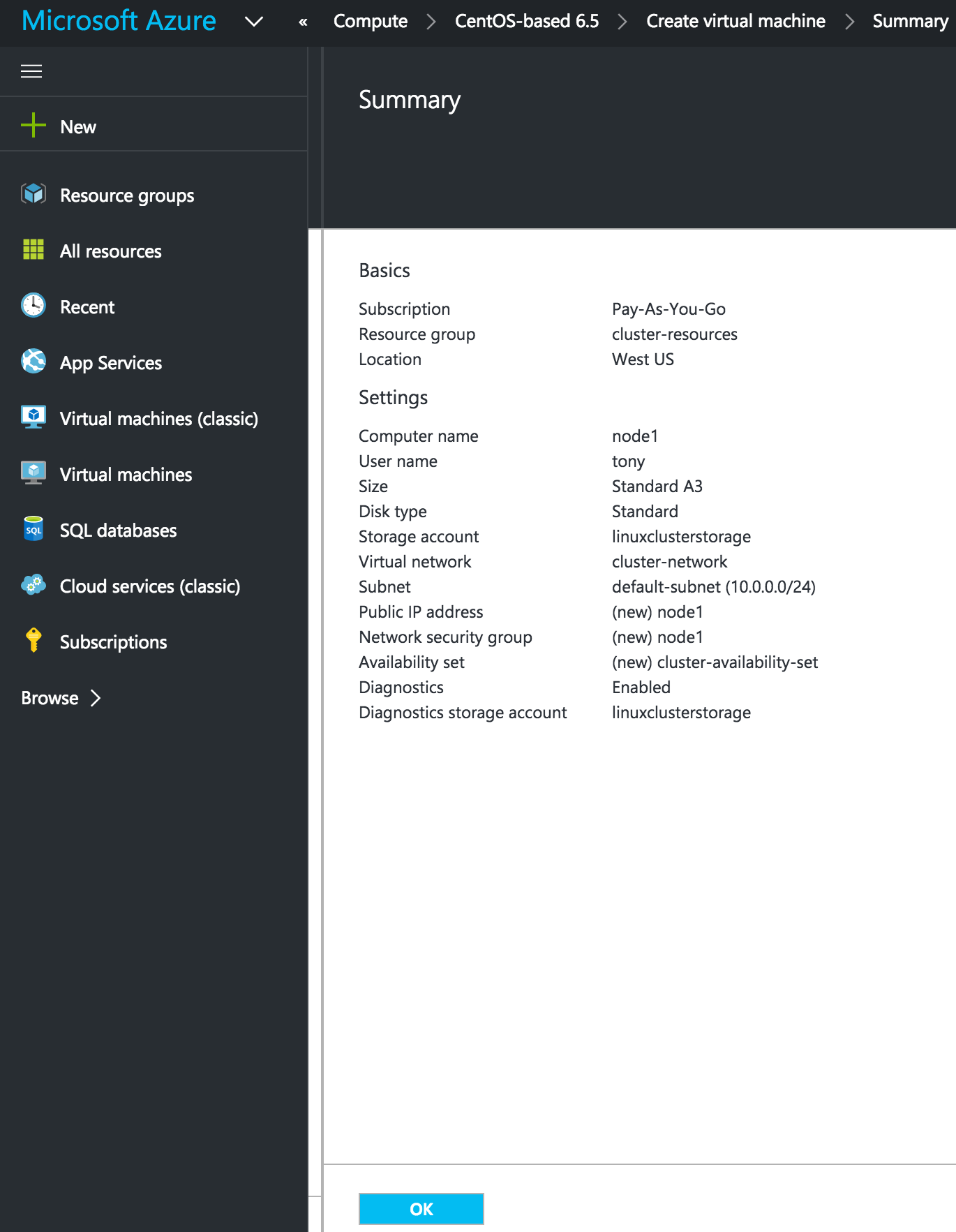
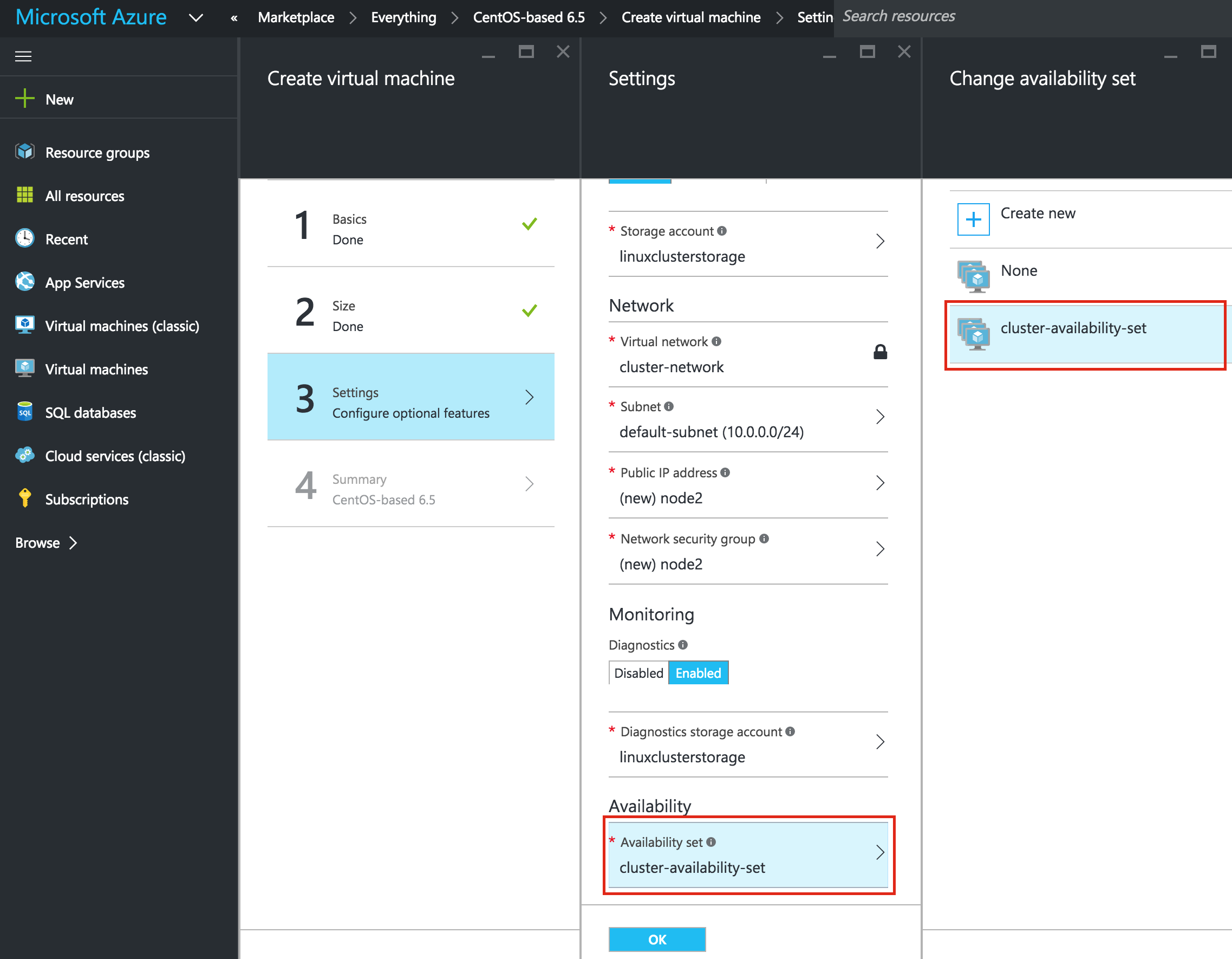
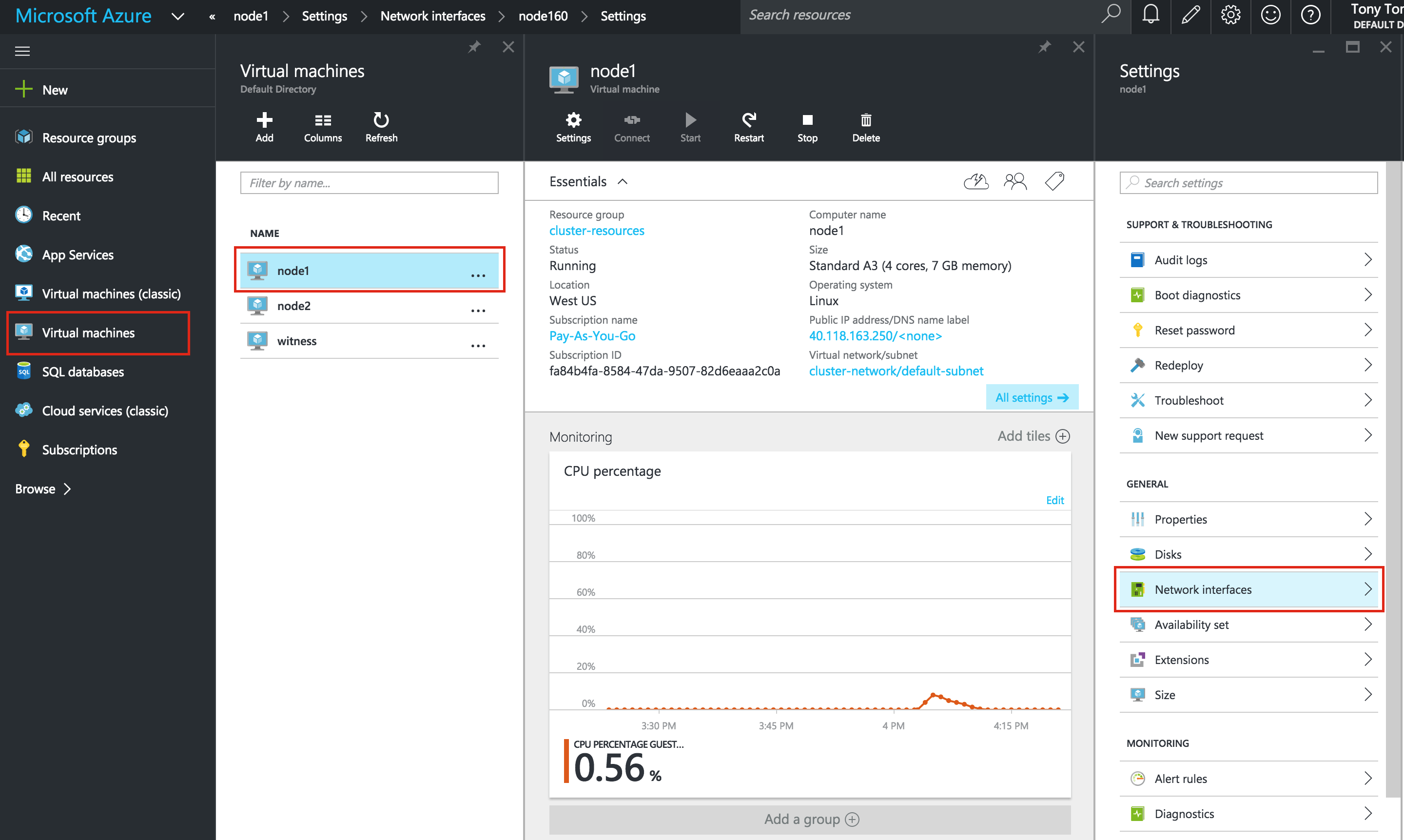
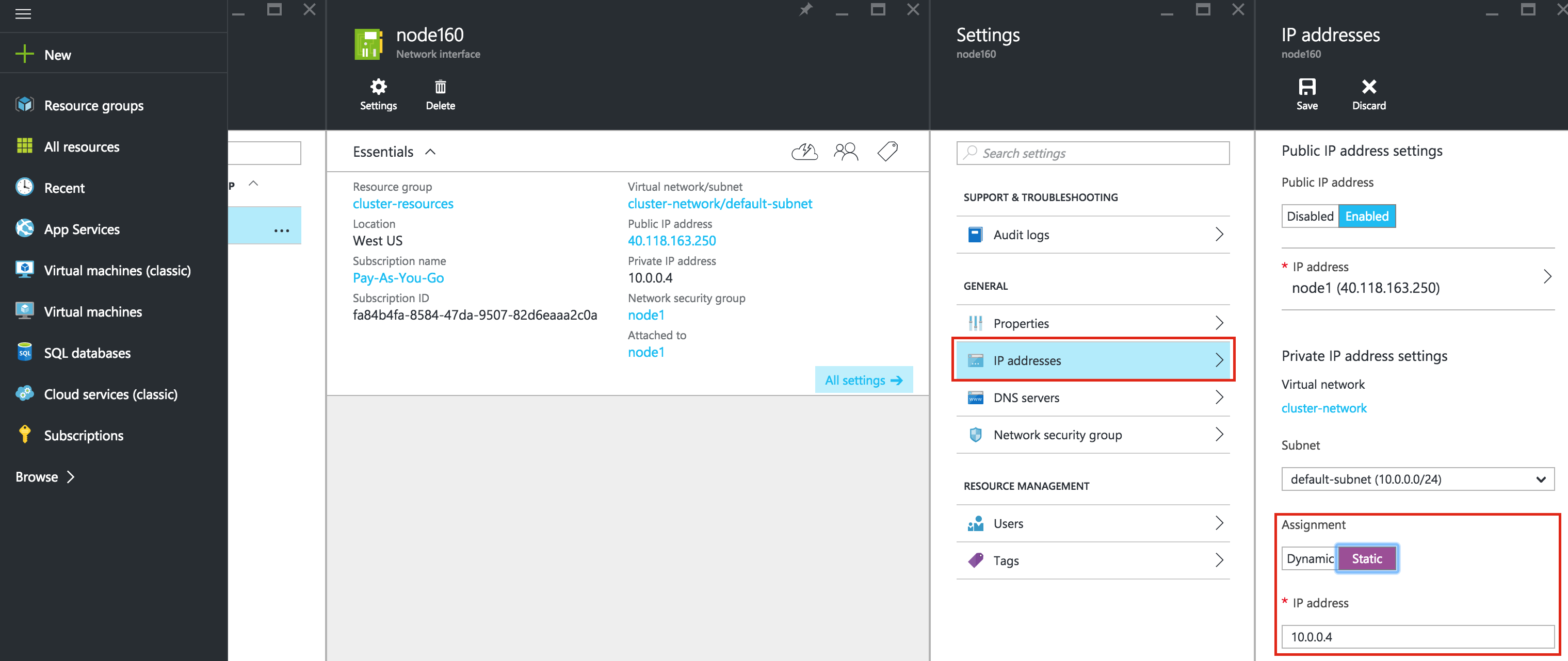
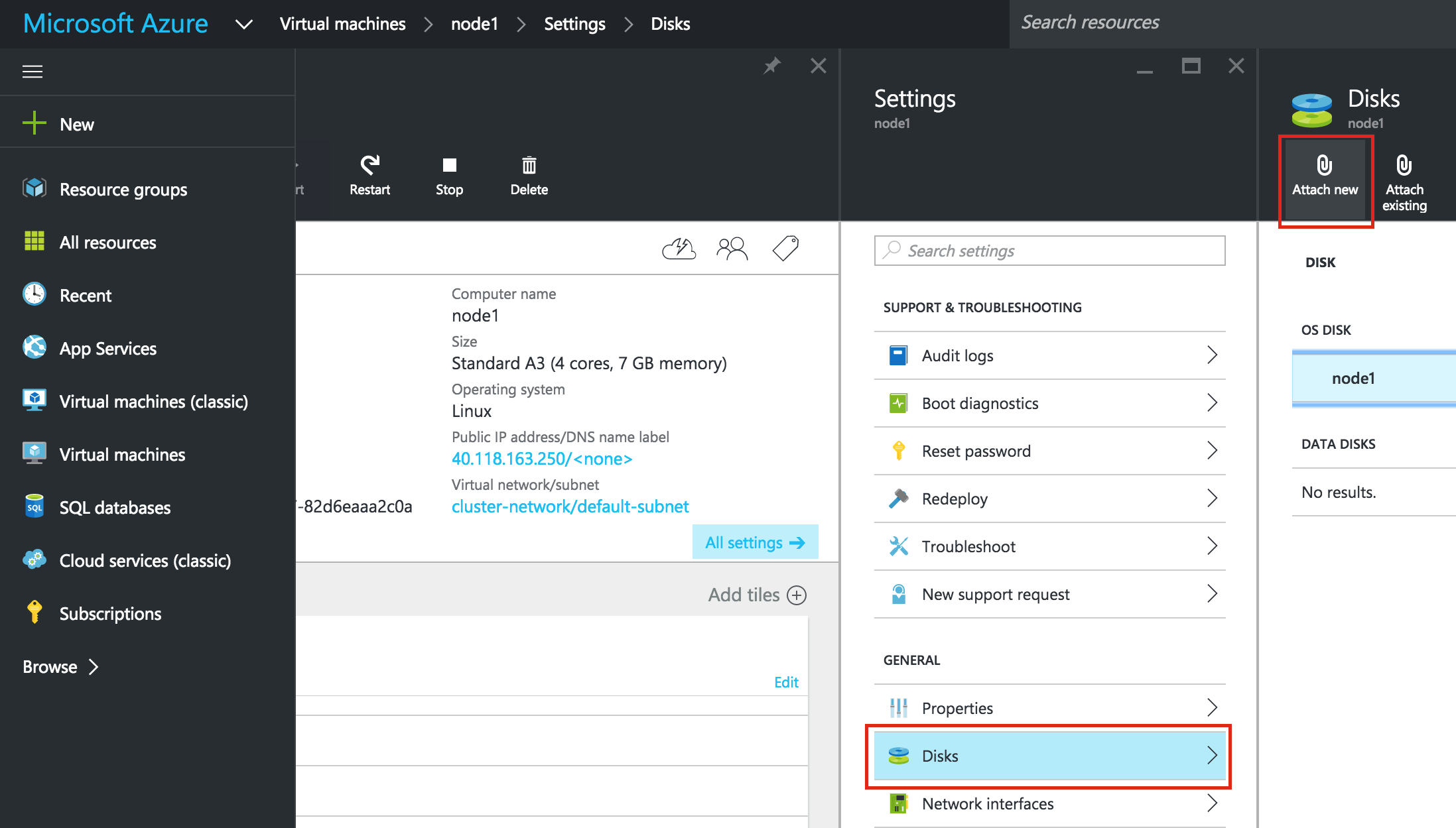
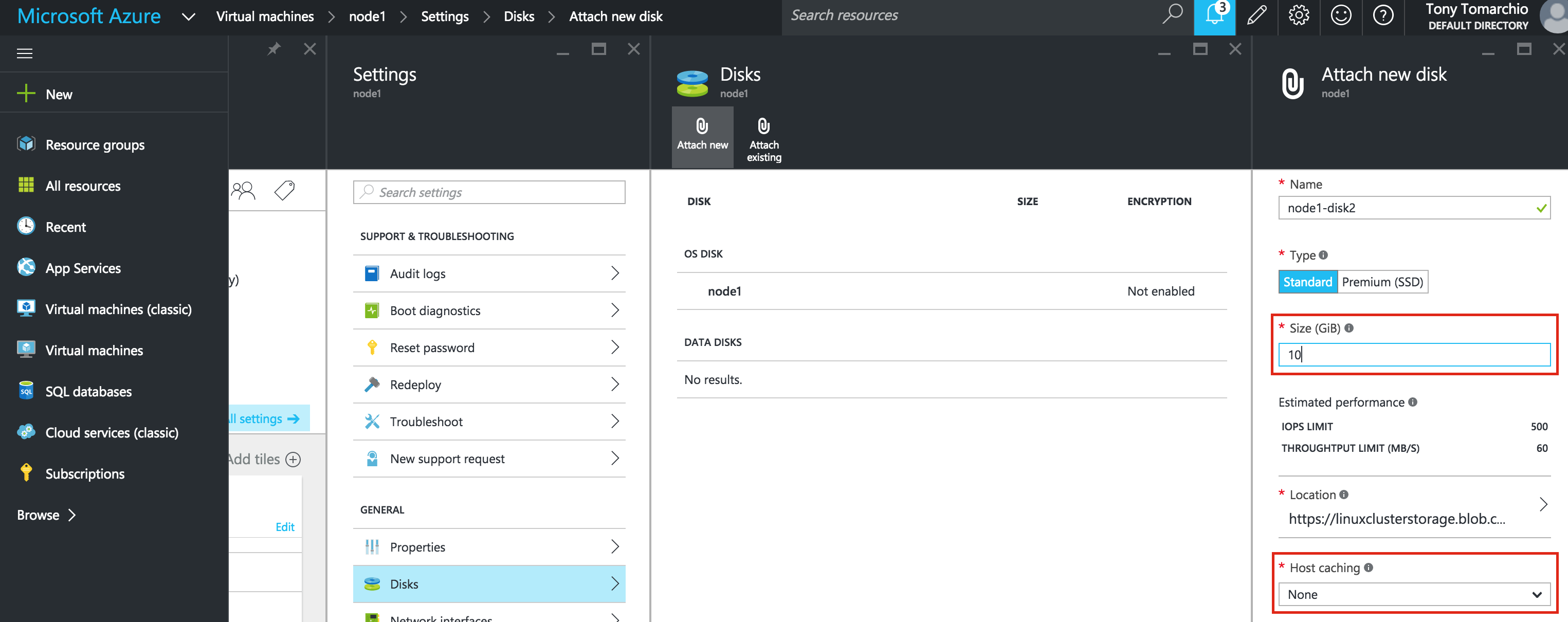
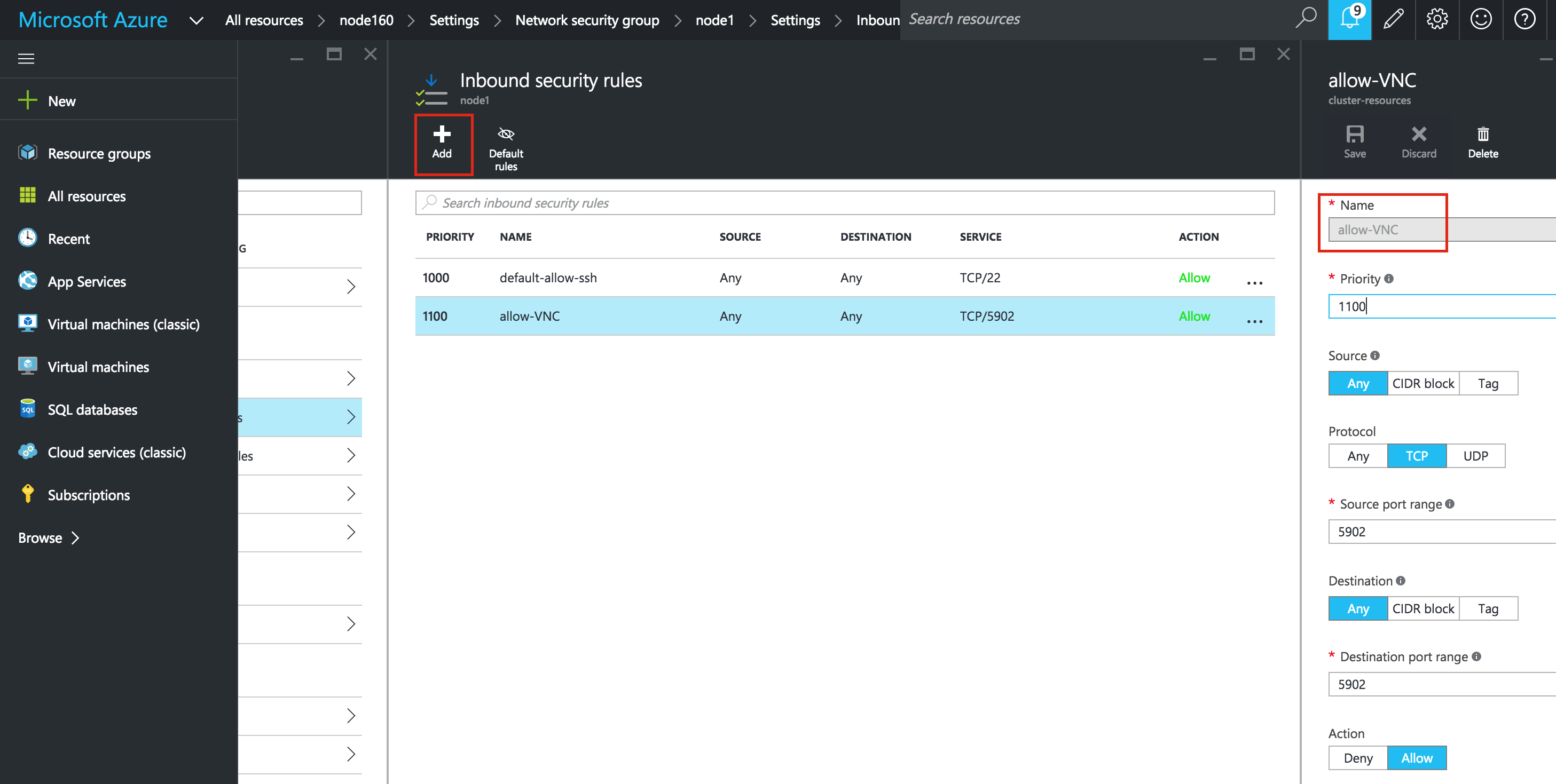
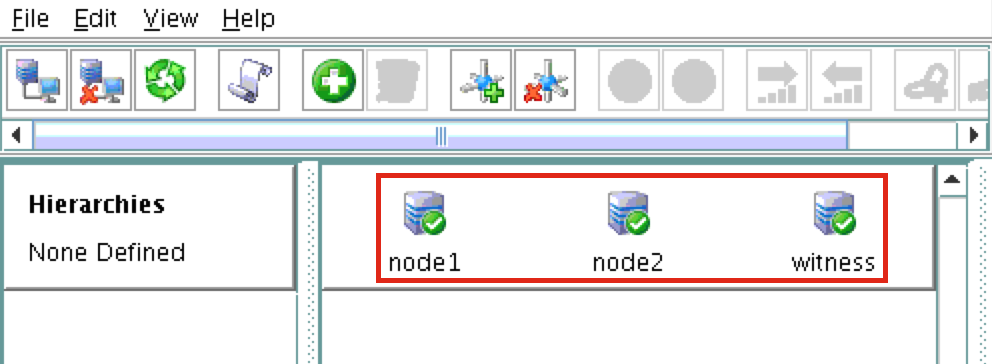
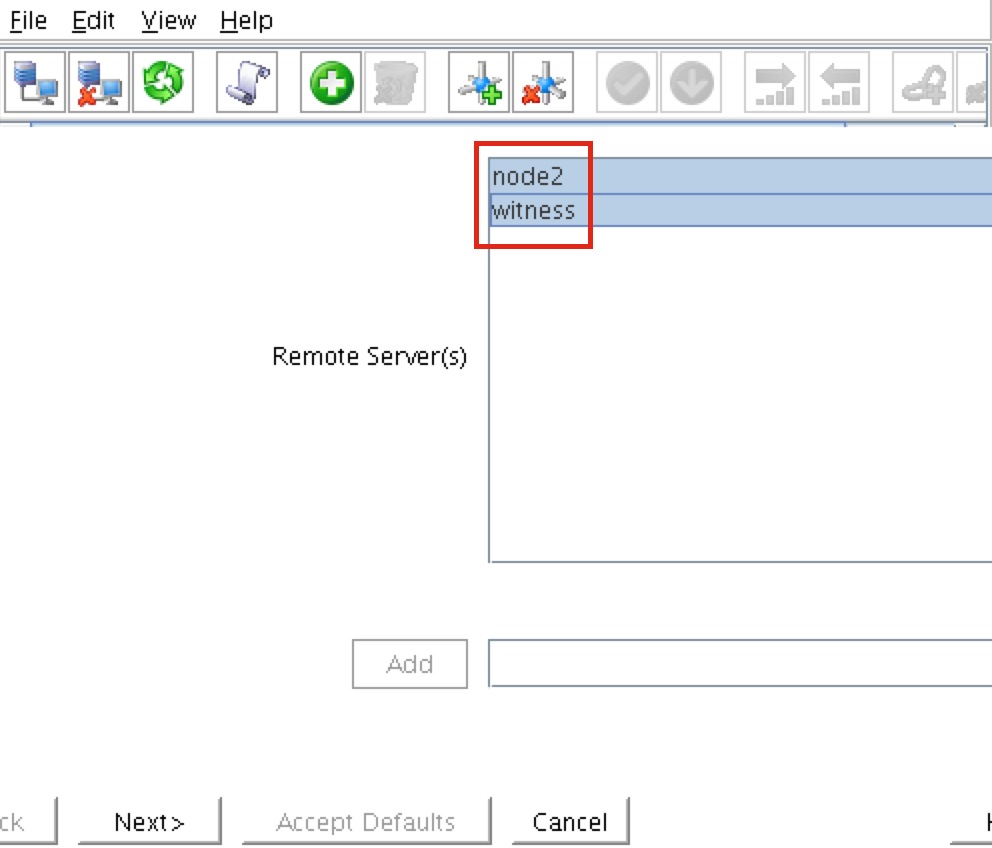
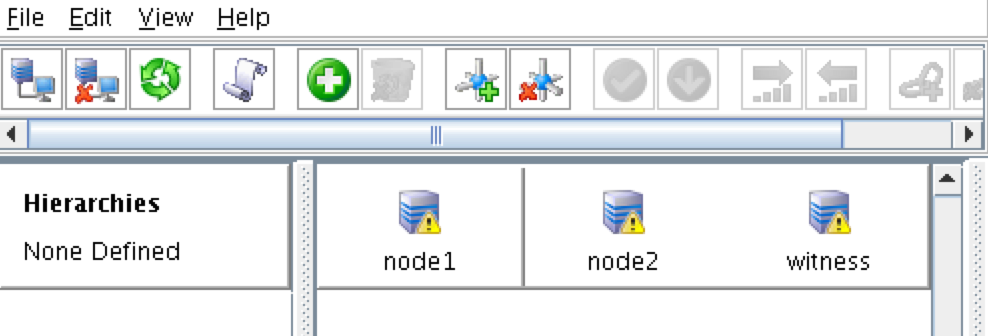
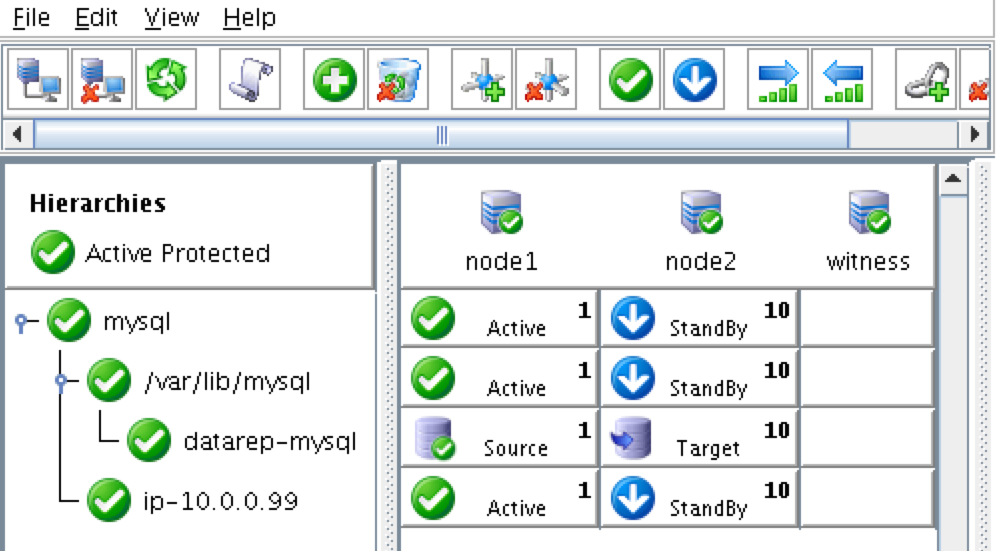
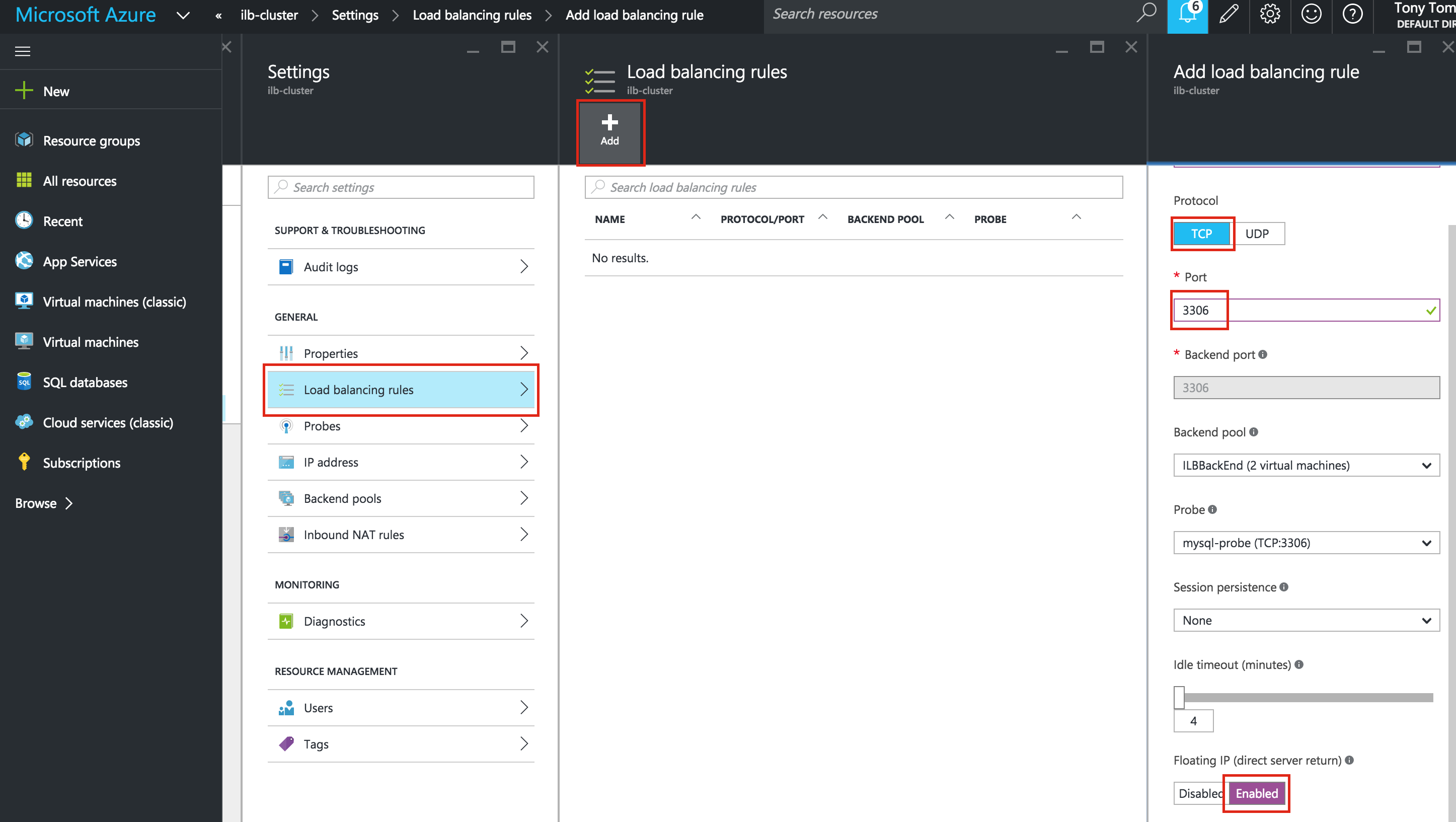
Linux 용 SQL Server – 공용 미리보기 사용 가능
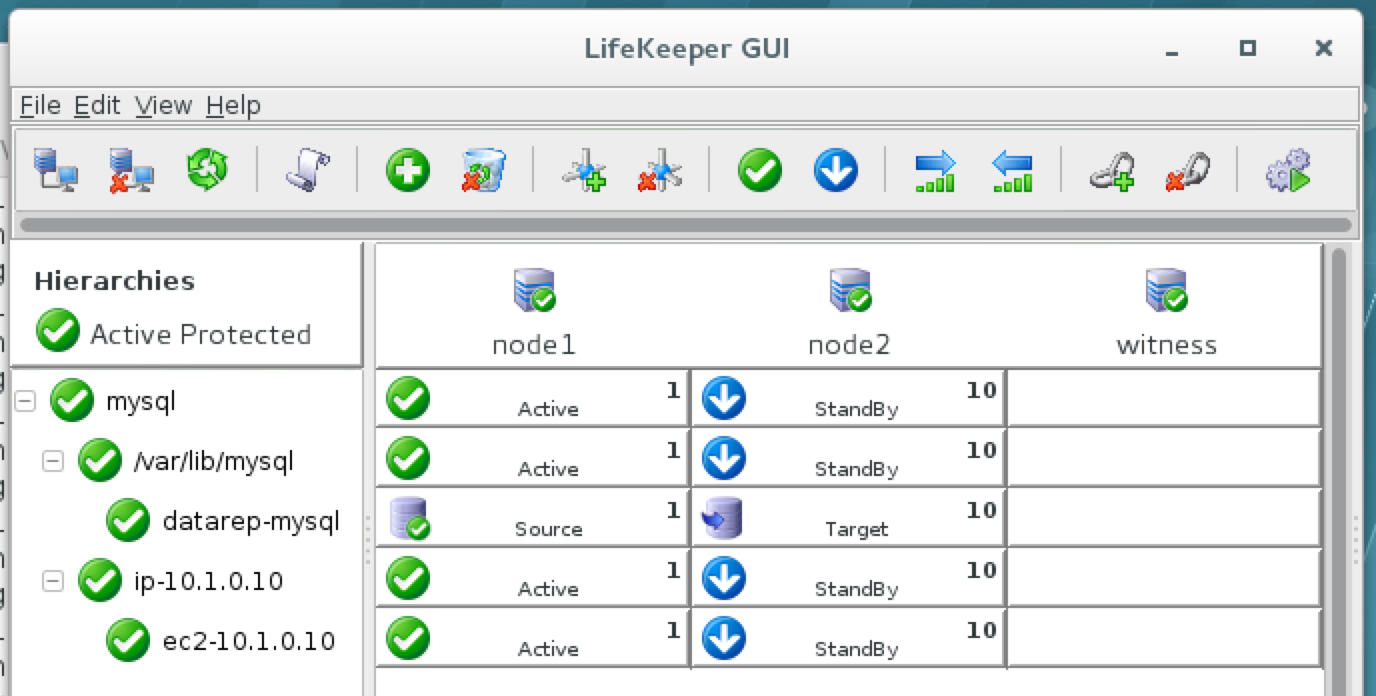
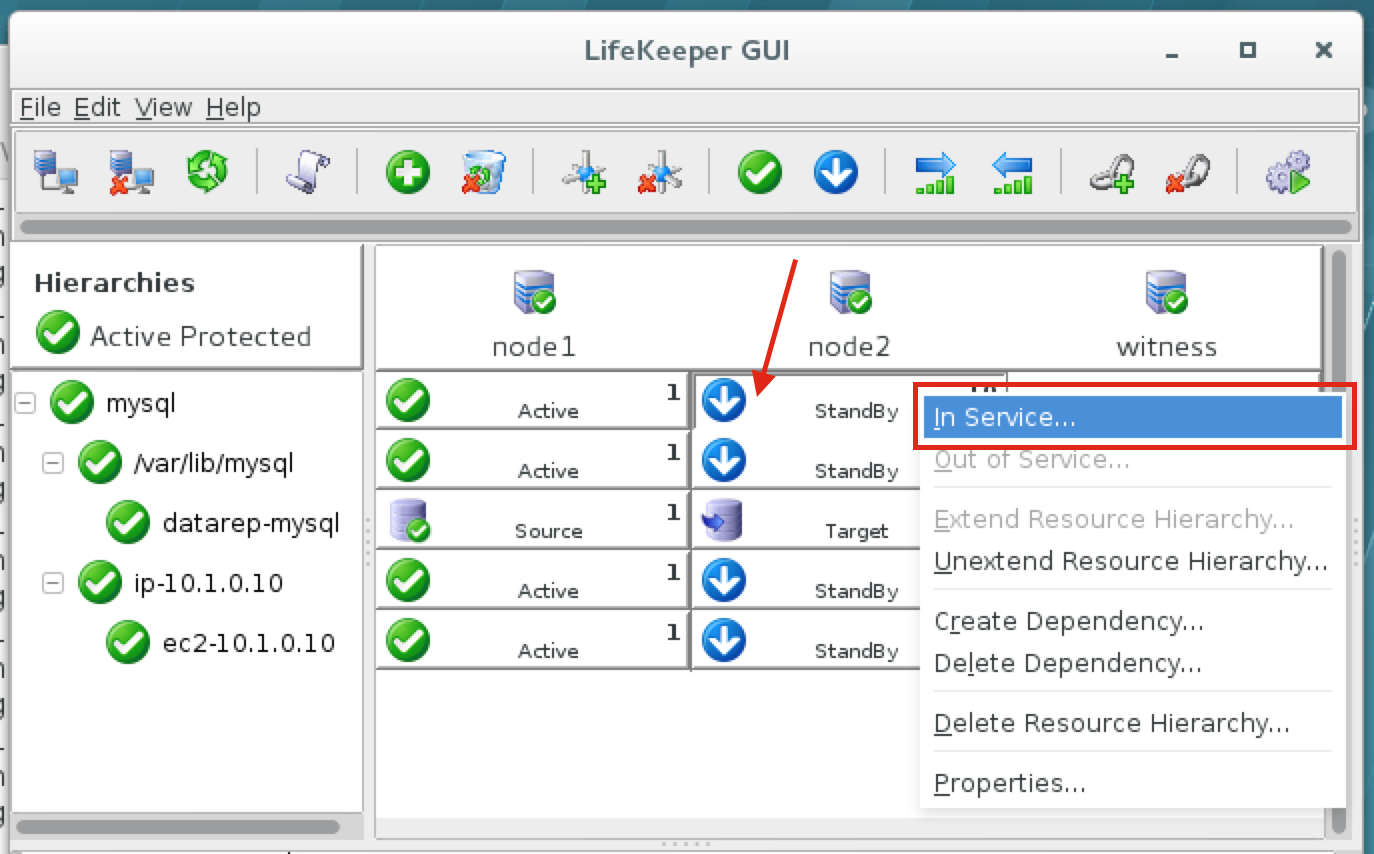
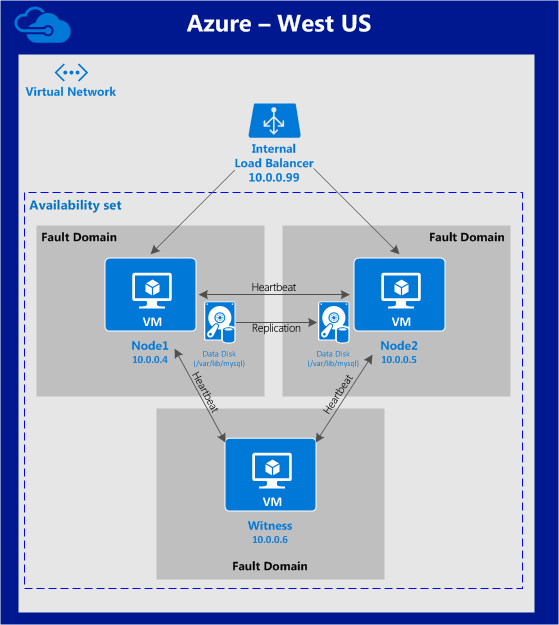
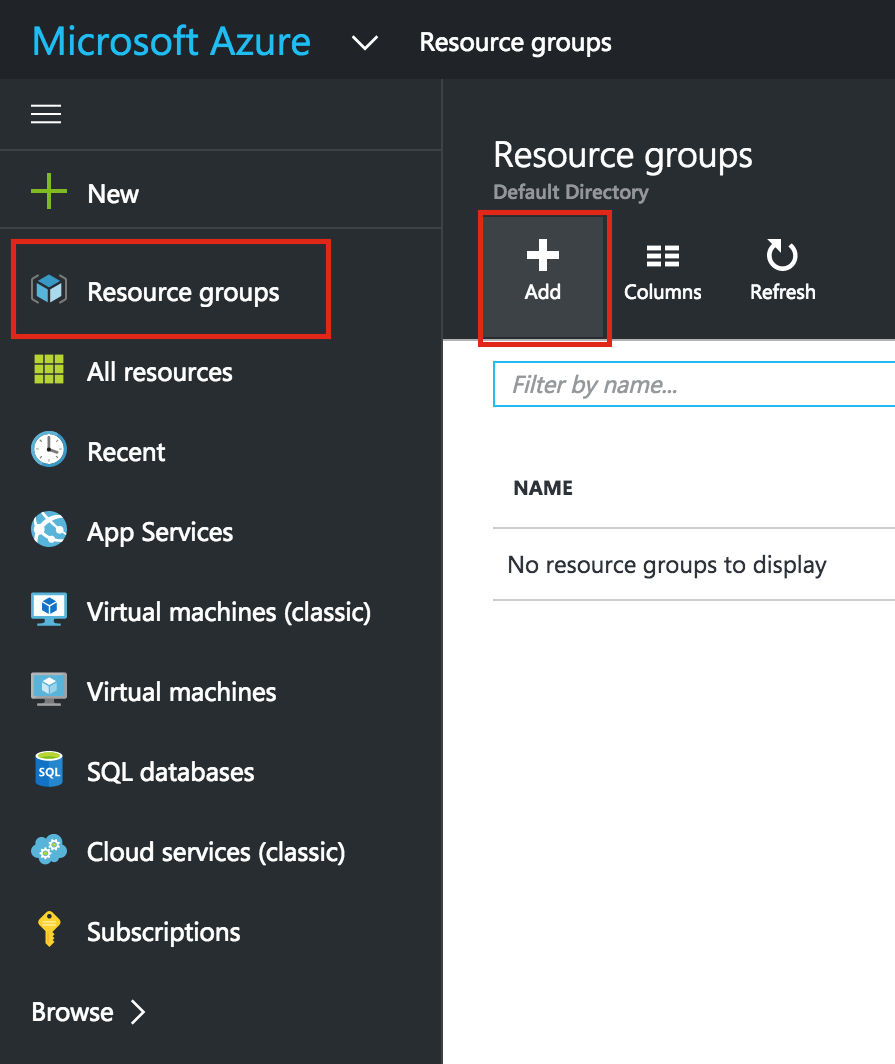
이제 SQL Server v.Next에 대한 공개 미리보기를 사용할 수 있습니다. Microsoft는 마침내 Linux에 대한 지원을 추가했습니다. 자세한 내용은 아래 링크를 확인하십시오. 곧 고 가용성 기능을 다운로드하고 살펴볼 것입니다. 계속 지켜봐!
SQL Server v.Next 공개 미리보기 : https://www.microsoft.com/en-us/sql-server/sql-server-vnext-including-Linux 원본 SQL Server Linux 발표 : https://blogs.microsoft.com / blog / 2016 / 03 / 07 / announce-sql-server-on-linux / Linuxclustering의 허가를 얻어 복제했습니다.