단계별 : Azure의 Windows Server 2008 R2에서 SQL Server 2008 R2 장애 조치 (failover) 클러스터 인스턴스를 구성하는 방법
소개
2019 년 7 월 9 일에 SQL Server 2008 및 2008 R2에 대한 지원이 종료됩니다. 이는 정기적 인 보안 업데이트가 끝났음을 의미합니다. 그러나 SQL Server 인스턴스를 Azure로 옮길 경우 Microsoft는 추가 비용없이 3 년 동안 연장 보안 업데이트를 제공합니다. 현재 SQL Server 2008/2008 R2를 실행 중이고 7 월 9 일 이전에 SQL Server의 이후 버전으로 업데이트 할 수없는 경우 향후 보안 취약성에 직면 할 위험을 감수하기보다는이 제안을 활용하는 것이 좋습니다. . 패치되지 않은 SQL Server 인스턴스는 데이터 손실, 가동 중지 시간 또는 치명적인 데이터 유출로 이어질 수 있습니다.
Azure에서 SQL Server 2008/2008 R2를 실행할 때 직면하게 될 과제 중의 하나는 고 가용성을 보장하는 것입니다. 구내에서 고 가용성을 위해 SQL Server 장애 조치 클러스터 (FCI) 인스턴스를 실행하고 있거나 가상 컴퓨터에서 SQL Server를 실행하고 있으며 가용성을 위해 VMware HA 또는 Hyper-V 클러스터에 의존하고있을 수 있습니다. Azure로 이동할 때 사용할 수있는 옵션이 없습니다. Azure의 가동 중지 시간은 완화 조치를 취해야하는 매우 현실적인 가능성입니다.
가동 중지 시간을 줄이고 Azure의 99.95 % 또는 99.99 % SLA 자격을 얻으려면 SIOS DataKeeper를 사용해야합니다. DataKeeper는 Azure의 공유 저장 장치 부족을 극복하고 Azure에 SQL Server FCI를 구축 할 수있게하여 각 인스턴스에서 로컬로 연결된 저장소를 활용합니다. SIOS DataKeeper는이 가이드에 설명 된대로 SQL Server 2008 R2 및 Windows Server 2008 R2를 지원할뿐만 아니라 2008 R2에서 Windows Server 2019까지의 모든 버전의 Windows Server 및 SQL Server 2008에서 SQL Server 2019까지의 모든 버전의 SQL Server를 지원합니다 .
이 가이드는 Windows Server 2008 R2에서 실행되는 Azure에서 2 노드 SQL Server 2008 R2 장애 조치 (FCI) 인스턴스를 만드는 과정을 안내합니다. SIOS DataKeeper는 가용 영역 또는 영역에 걸쳐있는 클러스터도 지원하지만이 안내서는 각 노드가 동일한 Azure Region에 있지만 다른 오류 도메인에 있다고 가정합니다. SIOS DataKeeper는 일반적으로 SQL Server 2008 R2 FCI를 만드는 데 필요한 공유 저장소 대신 사용됩니다.
Azure에서 첫 번째 SQL Server 인스턴스 만들기
이 가이드는 Azure 마켓 플레이스에 게시 된 Windows Server 2008R2 이미지의 SQL Server 2008R2SP3을 활용합니다.
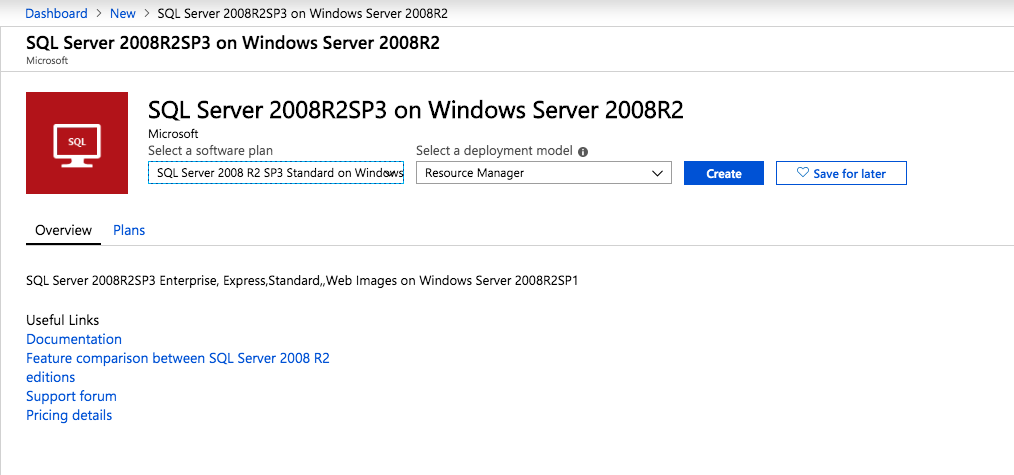
첫 번째 인스턴스를 프로비저닝 할 때 새 가용성 세트를 만들어야합니다. 이 과정에서 오류 도메인의 수를 3으로 늘리십시오. 이렇게하면 두 클러스터 노드와 파일 공유 감시 서버 각각이 자체 폴트 도메인에 상주 할 수 있습니다.
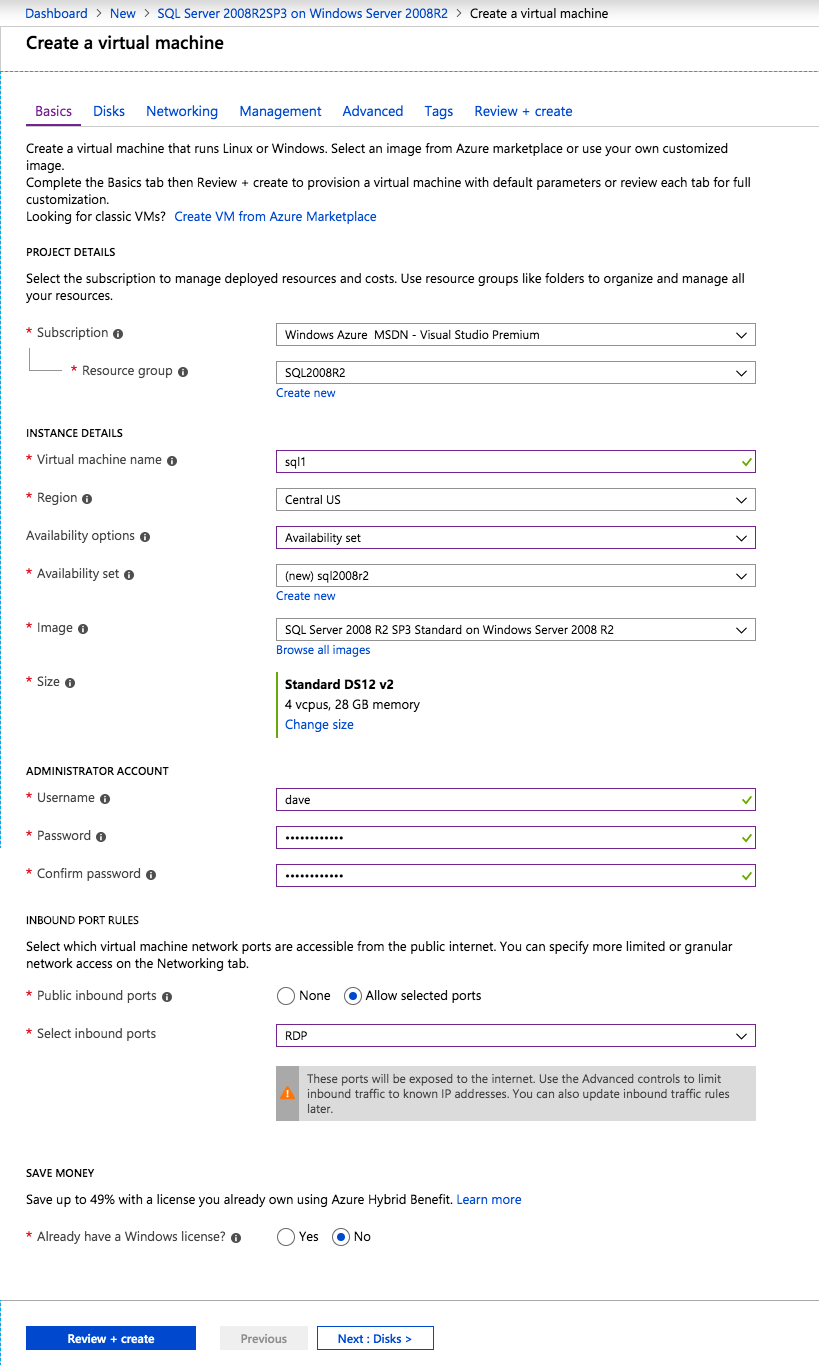
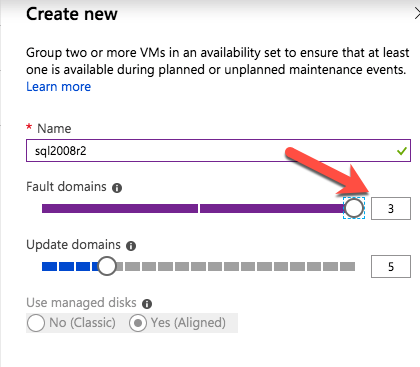
각 인스턴스에 디스크를 추가하십시오. Premium 또는 Ultra SSD를 권장합니다. SQL 로그 파일에 사용되는 디스크에서 캐싱을 사용하지 않습니다. SQL 데이터 파일에 사용되는 디스크에서 읽기 전용 캐싱을 사용합니다. 저장소 모범 사례에 대한 추가 정보는 Azure 가상 컴퓨터의 SQL Server 성능 가이드 라인을 참조하십시오.
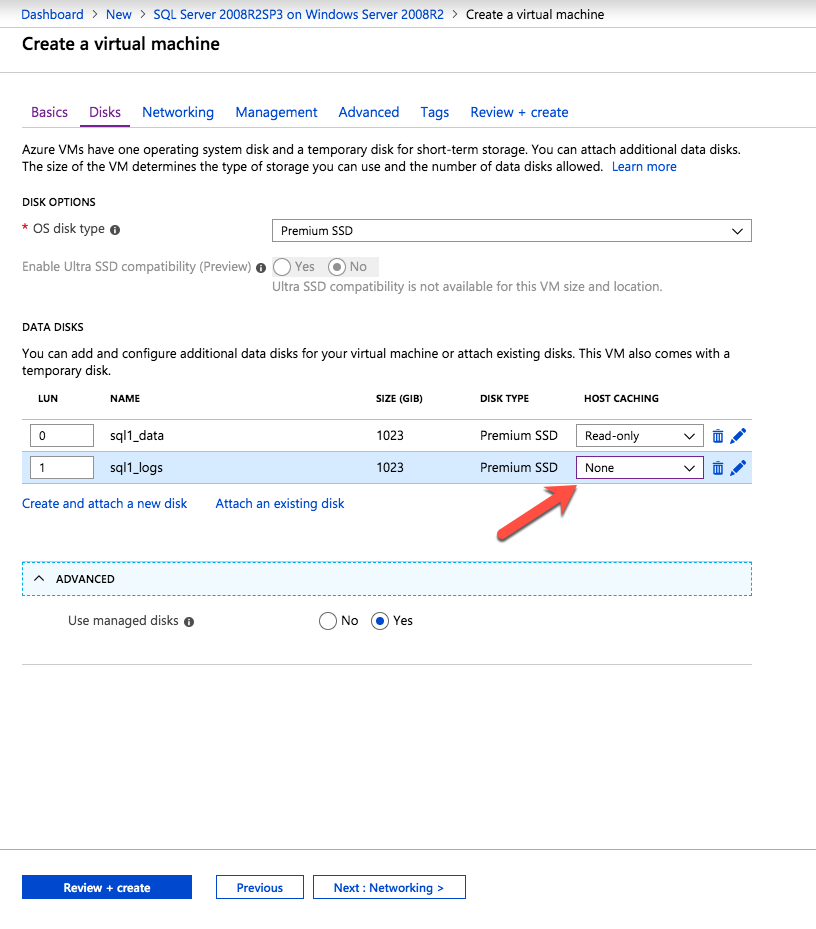
가상 네트워크를 구성하지 않은 경우 만들기 마법사에서 새 가상 네트워크를 만들 수 있습니다.
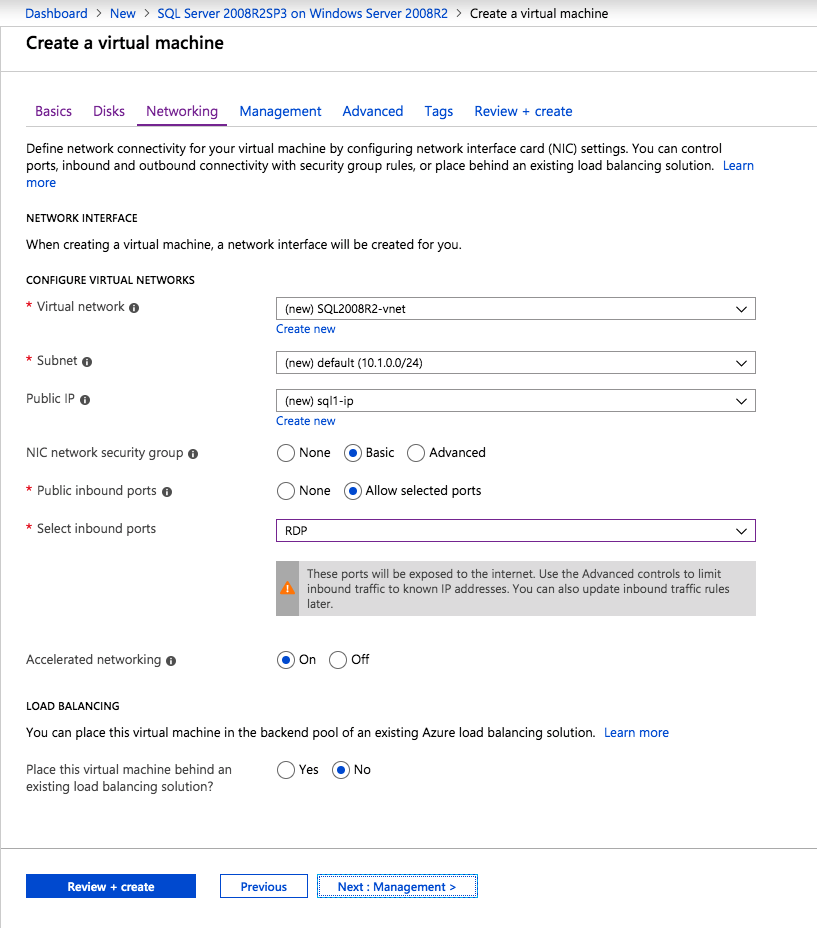
인스턴스가 생성되면 IP 구성으로 이동하여 개인 IP 주소를 고정시킵니다. 이는 SIOS DataKeeper에 필요하며 클러스터 된 인스턴스의 모범 사례입니다.
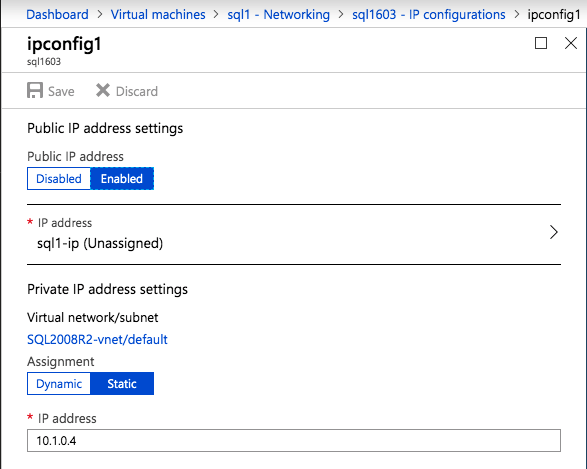
DNS 서버를 로컬 Windows AD 컨트롤러로 설정하도록 가상 네트워크가 구성되어 있는지 확인하십시오. 이것은 나중에 도메인에 가입 할 수 있는지 확인하기위한 것입니다.
Azure에서 최종 SQL Server 인스턴스 만들기
위와 동일한 단계를 따르십시오. 이 인스턴스를 첫 번째 인스턴스로 만든 동일한 가상 네트워크 및 가용성 집합에 배치해야합니다.
FSW (File Share Witness) 인스턴스 만들기
WSFC (Windows Server 장애 조치 클러스터)가 최적으로 작동하려면 다른 Windows Server 인스턴스를 만들어 SQL Server 인스턴스와 동일한 가용성 집합에 배치해야합니다. 동일한 가용성 세트에 배치하여 각 클러스터 노드와 FSW가 다른 오류 도메인에 있는지 확인합니다. 따라서 전체 오류 도메인이 오프라인 상태가되면 클러스터가 온라인 상태를 유지하게됩니다. 이 인스턴스에는 SQL Server가 필요하지 않습니다. 그것은 단순한 파일 공유를 호스트하는 것만 큼 단순한 Windows 서버가 될 수 있습니다.
이 인스턴스는 WSFC에 필요한 파일 공유 감시를 호스팅합니다. 이 인스턴스는 동일한 크기 일 필요가 없으며 추가 디스크를 연결하지 않아도됩니다. 단순한 파일 공유를 호스팅하는 것이 유일한 목적입니다. 사실 다른 용도로 사용될 수 있습니다. 내 실험 환경에서 FSW는 또한 내 도메인 컨트롤러입니다.
SQL Server 2008 R2 제거
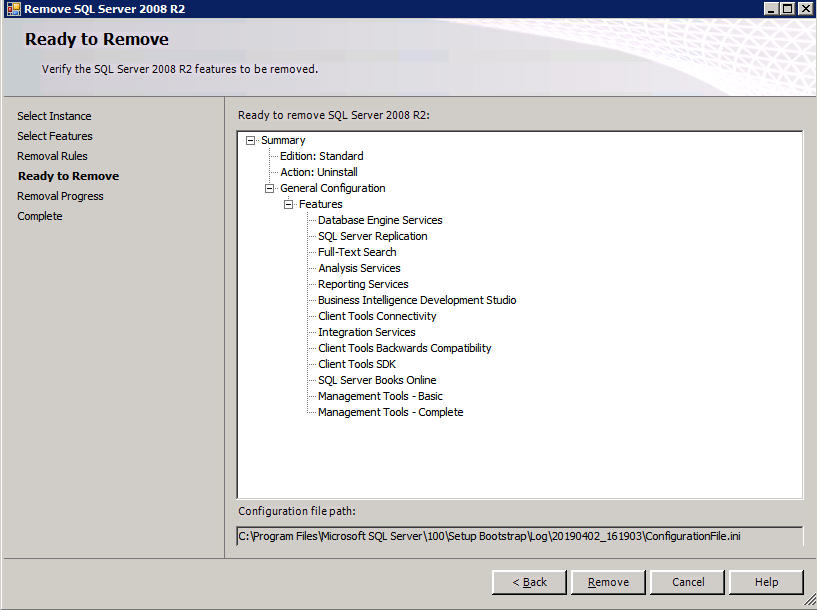
프로비저닝 된 두 SQL Server 인스턴스에는 이미 SQL Server 2008 R2가 설치되어 있습니다. 그러나 클러스터 된 인스턴스가 아닌 독립 실행 형 SQL Server 인스턴스로 설치됩니다. 클러스터 인스턴스를 설치하기 전에 이러한 각 인스턴스에서 SQL Server를 제거해야합니다. 가장 쉬운 방법은 아래와 같이 SQL Setup을 실행하는 것입니다.
setup.exe / Action-RunDiscovery를 실행하면 사전 설치된 모든 항목이 표시됩니다.
setup.exe / Action-RunDiscovery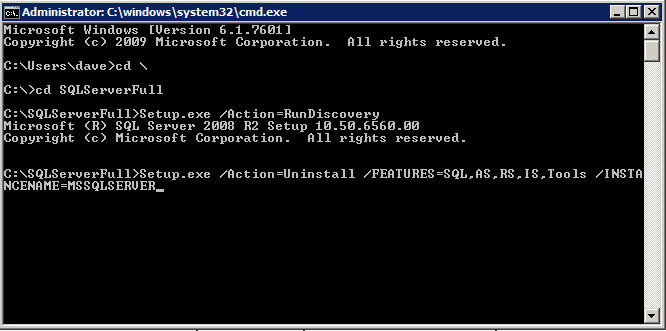

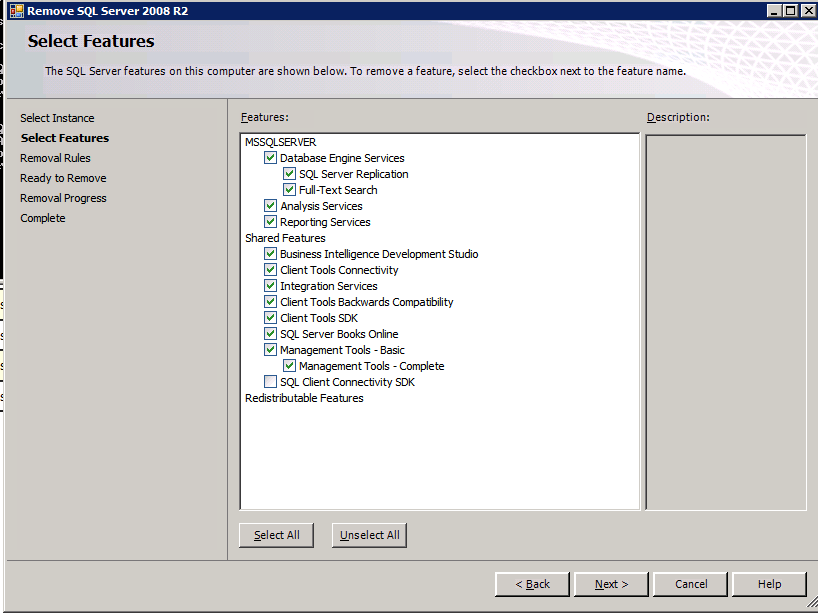
setup.exe / Action = Uninstall / FEATURES = SQL, AS, RS, IS, Tools / INSTANCENAME = MSSQLSERVER를 실행하면 제거 프로세스가 시작됩니다.
setup.exe / Action = Uninstall / FEATURES = SQL, AS, RS, IS, 도구 / INSTANCENAME = MSSQLSERVER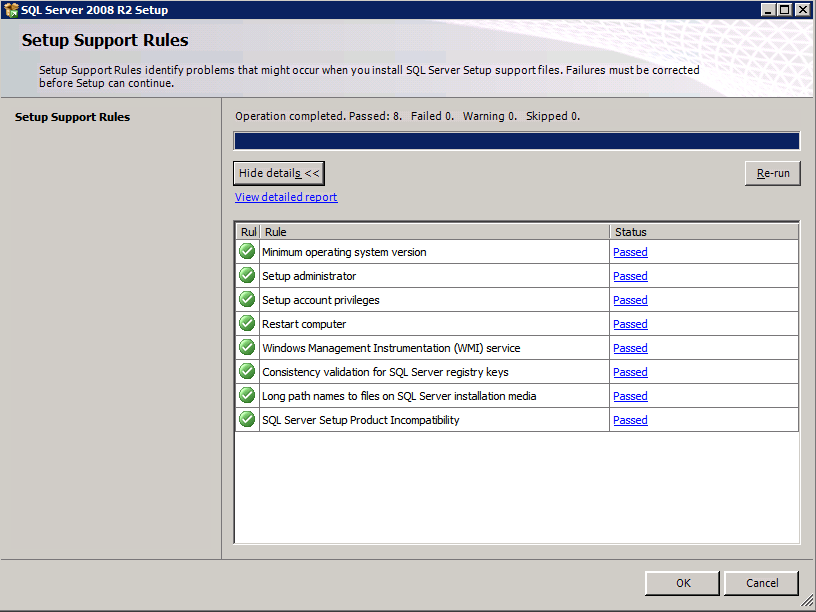
setup.exe / Action-RunDiscovery를 실행하면 제거가 완료 되었음이 확인됩니다.
setup.exe / Action-RunDiscovery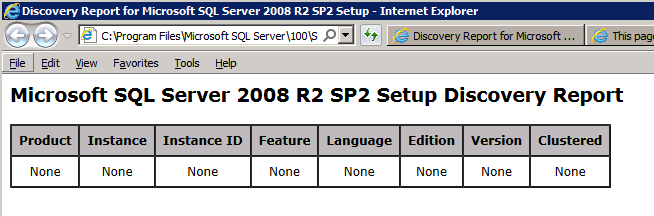
두 번째 인스턴스에서이 제거 프로세스를 다시 실행하십시오.
도메인에 인스턴스 추가
세 인스턴스 모두 Windows 도메인에 추가해야합니다.
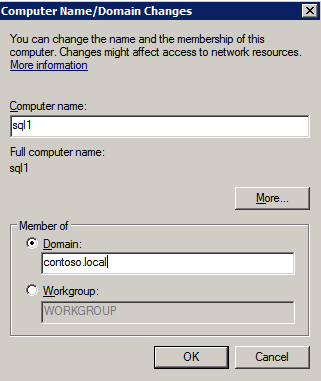
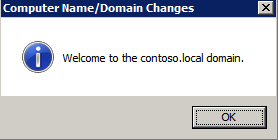
Windows 장애 조치 (Failover) 클러스터링 기능 추가
장애 조치 (Failover) 클러스터링 기능을 두 SQL Server 인스턴스에 추가해야합니다.
Add-WindowsFeature 장애 조치 - 클러스터링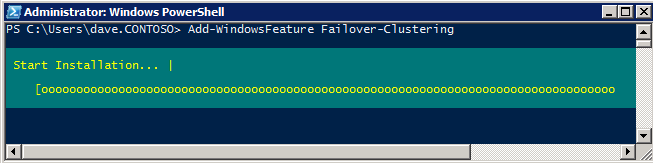
Windows 방화벽 끄기
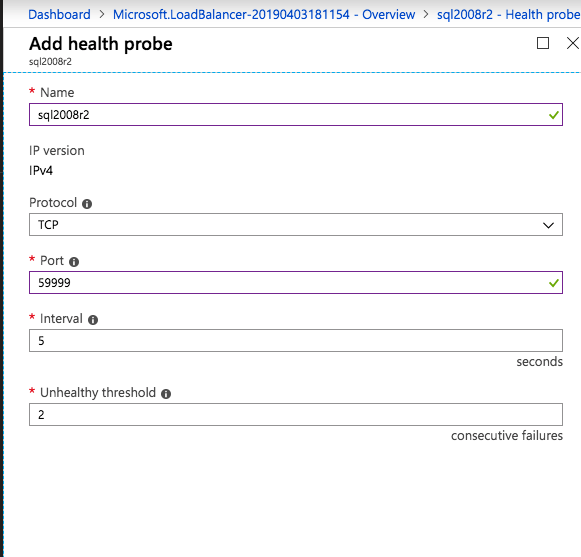
간단히하기 위해 SQL Server FCI 설치 및 구성 중에 Windows 방화벽을 해제하십시오. Azure Network Security Best Practices에 문의하여 Azure 리소스 보안에 대한 조언을 얻으십시오. 필수 Windows 포트에 대한 자세한 내용은 여기, SQL Server 포트는 여기, SIOS DataKeeper 포트는 여기에서, 내부로드 밸런서에는 나중에 포트 59999 액세스가 필요합니다. 따라서 보안 구성에서이를 고려해야합니다.
NetSh Advfirewall이 allprofiles 상태를 해제합니다.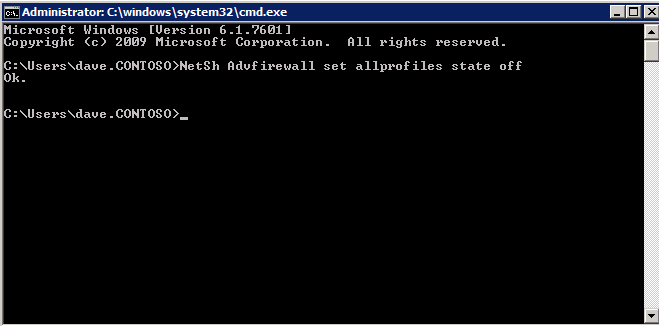
Windows Server 2008 R2 SP1 용 편의 롤업 업데이트 설치
Azure에서 Windows Server 2008 R2 인스턴스를 구성하는 데 필요한 중요 업데이트 (kb2854082)가 있습니다. 이 업데이트와 그 이상은 Windows Server 2008 R2 SP1 용 편의 롤업 업데이트에 포함되어 있습니다. 두 SQL Server 인스턴스 각각에이 업데이트를 설치하십시오.
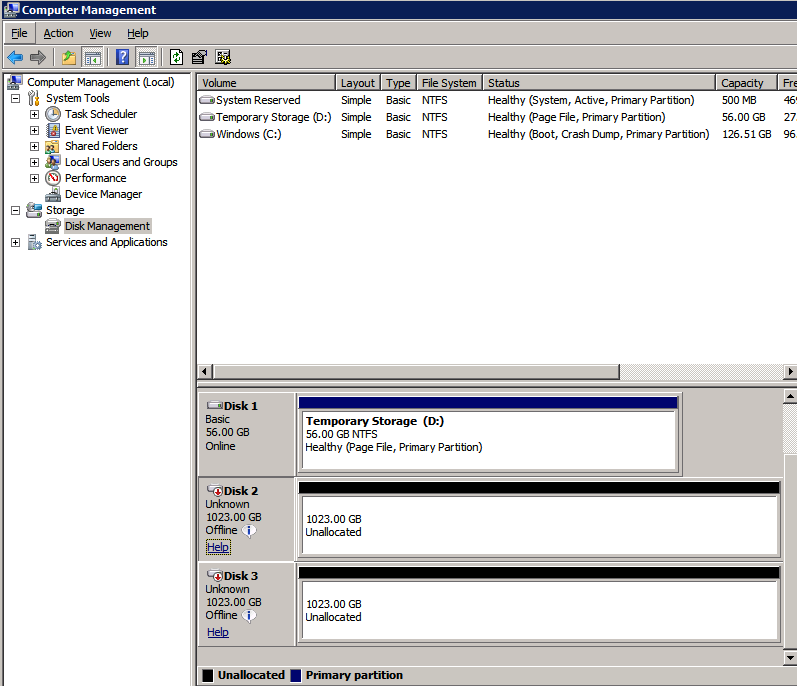
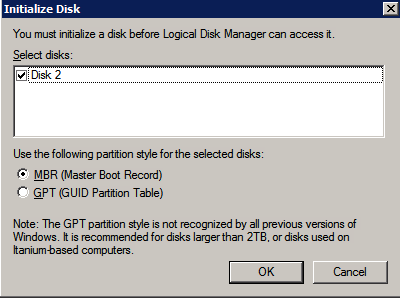
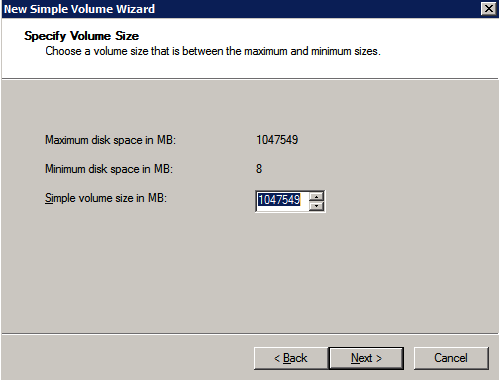
스토리지 포맷
두 개의 SQL Server 인스턴스를 프로비저닝 할 때 첨부 된 추가 디스크를 포맷해야합니다. 각 인스턴스의 각 볼륨에 대해 다음을 수행하십시오.
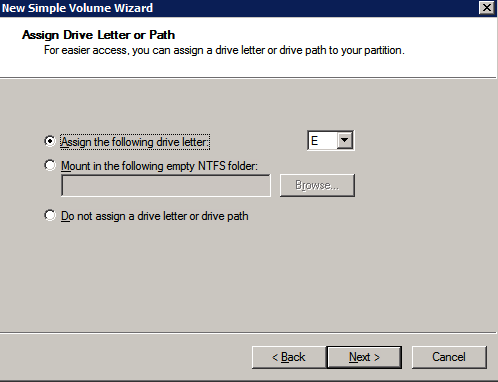
마이크로 소프트 모범 사례는 다음과 같이 말합니다 …
"NTFS 할당 단위 크기 : 데이터 디스크를 포맷 할 때 데이터 및 로그 파일과 TempDB에 대해 64KB 할당 단위 크기를 사용하는 것이 좋습니다."
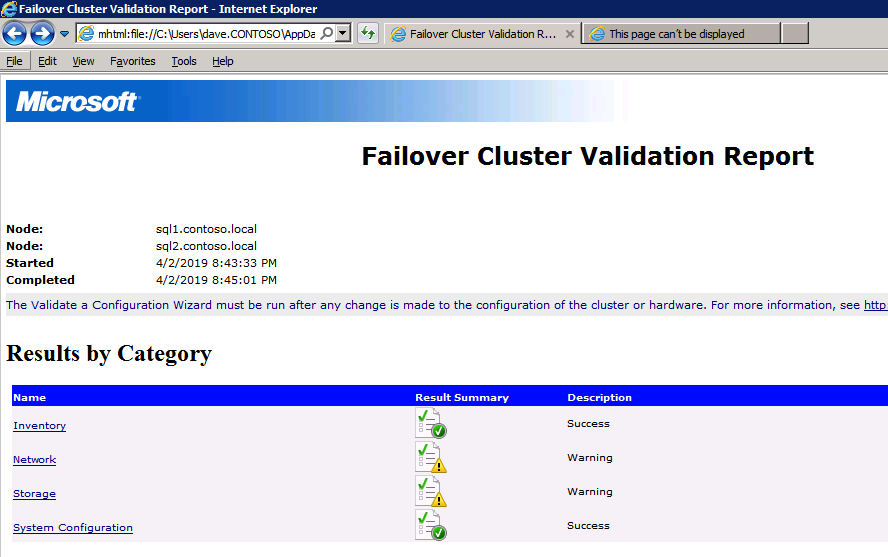
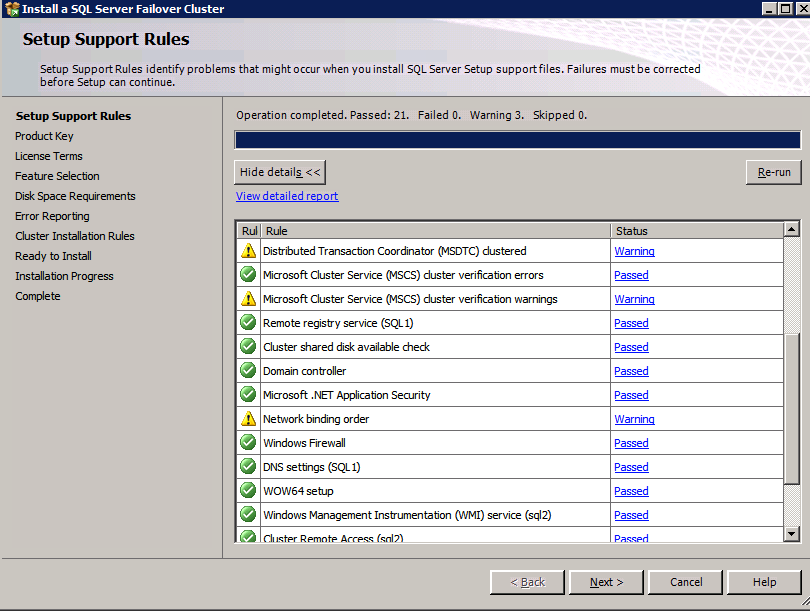
클러스터 유효성 검사 실행
클러스터 유효성 검사를 실행하여 모든 것이 클러스터 될 준비가되었는지 확인하십시오.
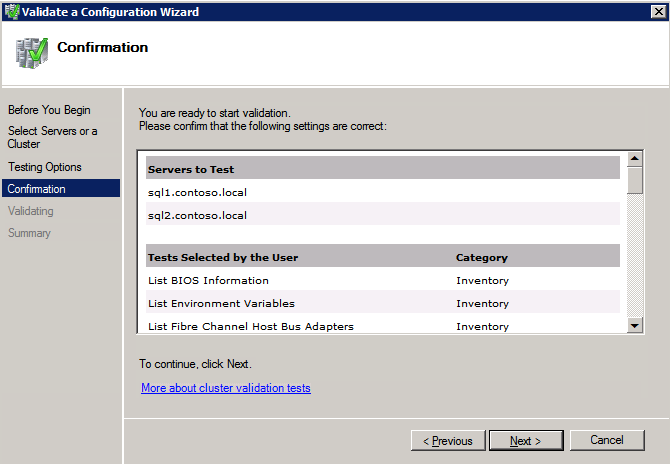
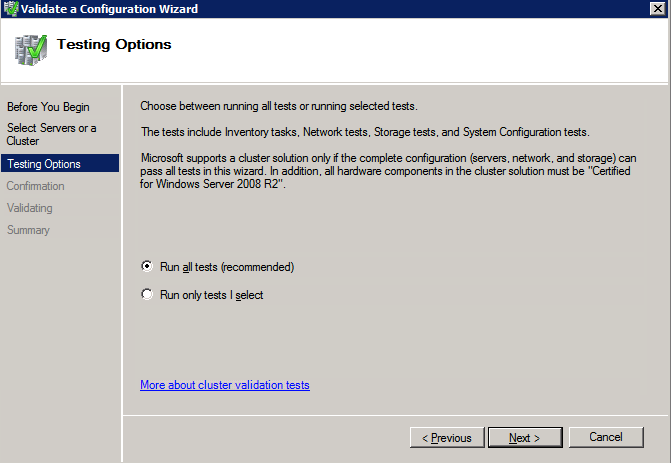
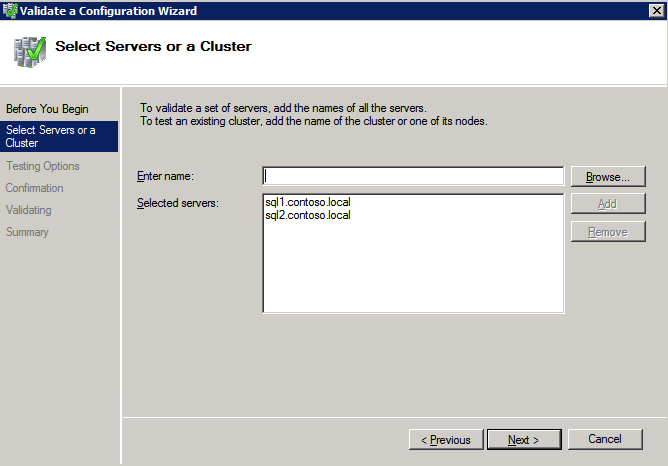
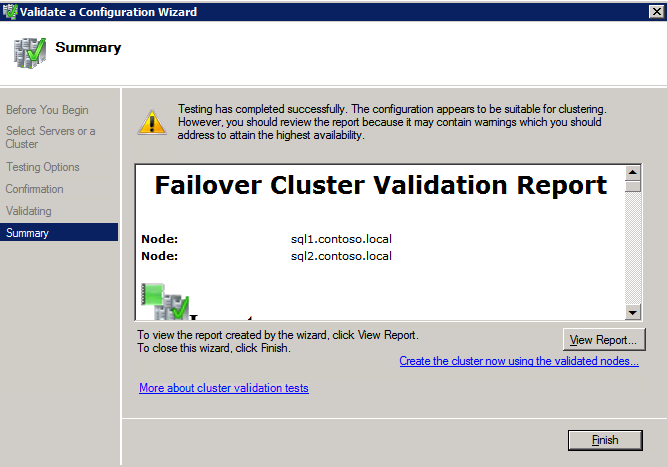
보고서에는 저장 및 네트워킹에 대한 경고가 포함됩니다. 공유 디스크가없고 서버간에 단일 네트워크 연결 만 있다는 것을 알기 때문에 경고를 무시할 수 있습니다. 또한 무시할 수있는 네트워크 바인딩 순서에 대한 경고를받을 수도 있습니다. 오류가 발생하면 계속하기 전에 해결해야합니다.
클러스터 만들기
Azure에서 클러스터를 만드는 가장 좋은 방법은 아래와 같이 Powershell을 사용하는 것입니다. Powershell을 사용하면 정적 IP 주소를 지정할 수 있지만 GUI 방법은 지정할 수 없습니다. 안타깝게도 Azure의 DHCP 구현은 Windows Server 장애 조치 (Failover) 클러스터링에서 제대로 작동하지 않습니다. GUI 방법을 사용하는 경우 클러스터 IP 주소로 중복 IP 주소가 표시됩니다. 그것은 세상의 종말은 아니지만, 내가 보여 주듯이 그것을 고쳐야 할 것입니다.
앞서 말했듯이 Powershell 방법이 일반적으로 가장 잘 작동합니다. 그러나 다음과 같이 Windows Server 2008 R2에서 어떤 이유로 인해 문제가있는 것으로 보입니다.
새 클러스터 -Name cluster1 -Node sql1, sql2 -StaticAddress 10.1.0.100 -NoStorage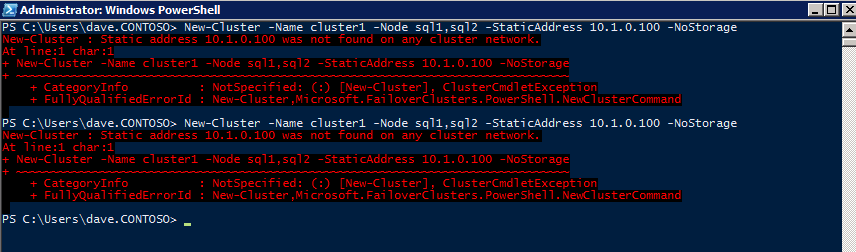
당신은 그 방법을 시도해 볼 수 있습니다. 다시 돌아가서 이것이 우연인지 좀 더 조사해야합니다. Powershell이 작동하지 않는 경우 탐색 할 또 다른 옵션은 Cluster.exe입니다. cluster / create /?를 실행 중입니다. 더 이상 사용되지 않는 cluster.exe 명령을 사용하여 클러스터를 만드는 데 사용할 적절한 구문을 제공합니다.
그러나 Powershell 또는 Cluster.exe에서 실패한 경우 아래 단계에서는 클러스터에 할당 할 중복 IP 주소를 수정하는 등 Windows Server 장애 조치 (Failover) 클러스터링 UI를 통해 클러스터를 만드는 방법을 보여줍니다.
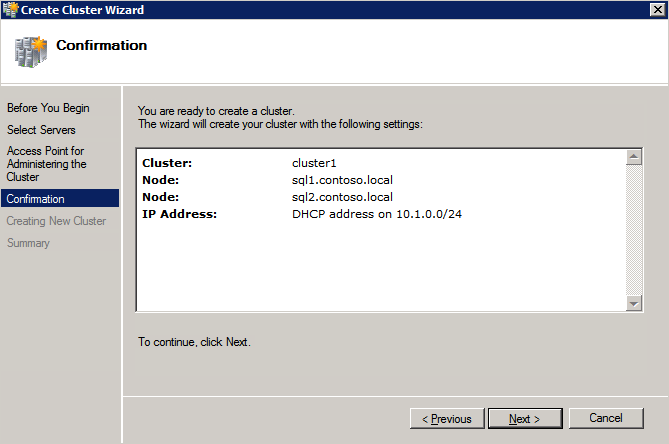
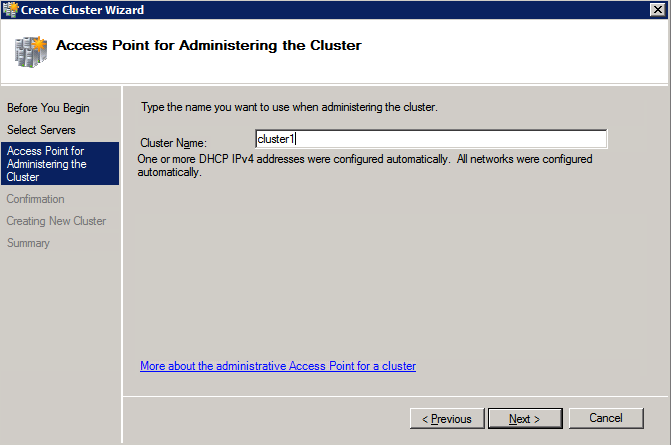
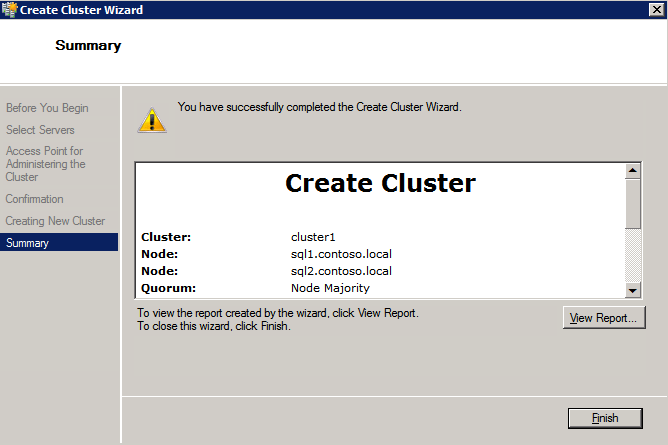
여기서 지정한 이름은 CNO (Cluster Name Object)입니다. 이 이름은 SQL 클라이언트가 클러스터에 연결하는 데 사용하는 이름이 아닙니다. 다음 단계에서 SQL Server 클러스터를 설정하는 동안이를 정의 할 것입니다.
이 시점에서 클러스터가 만들어 지지만 중복 IP 주소 문제로 인해 Windows Server 장애 조치 (Failover) 클러스터링 UI로 클러스터에 연결할 수 없습니다.
Duplicate IP Address 수정
앞서 언급했듯이 GUI를 사용하여 클러스터를 작성하면 클러스터의 IP 주소를 선택할 기회가 제공되지 않습니다. 인스턴스가 DHCP를 사용하도록 구성 되었기 때문에 (Azure에서 필요함) GUI는 DHCP를 사용하여 자동으로 IP 주소를 할당하려고합니다. 안타깝게도 Azure의 DHCP 구현은 예상대로 작동하지 않으며 클러스터는 노드 중 하나에서 이미 사용중인 것과 동일한 주소를 할당합니다. 클러스터가 제대로 생성 되더라도이 문제를 해결해야만 클러스터에 연결할 수 있습니다.
이 문제를 해결하려면 노드 중 하나에서 다음 명령을 실행하여 해당 노드에서 클러스터 서비스가 시작되는지 확인하십시오.
net start clussvc / fq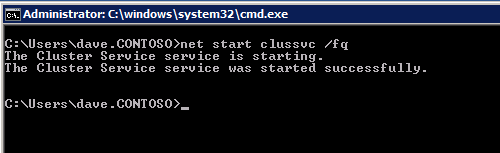
동일한 노드에서 이제 IP 주소가 온라인 상태가되지 않은 것을 볼 수있는 Windows Server 장애 조치 (Failover) 클러스터링 UI에 연결할 수 있어야합니다.
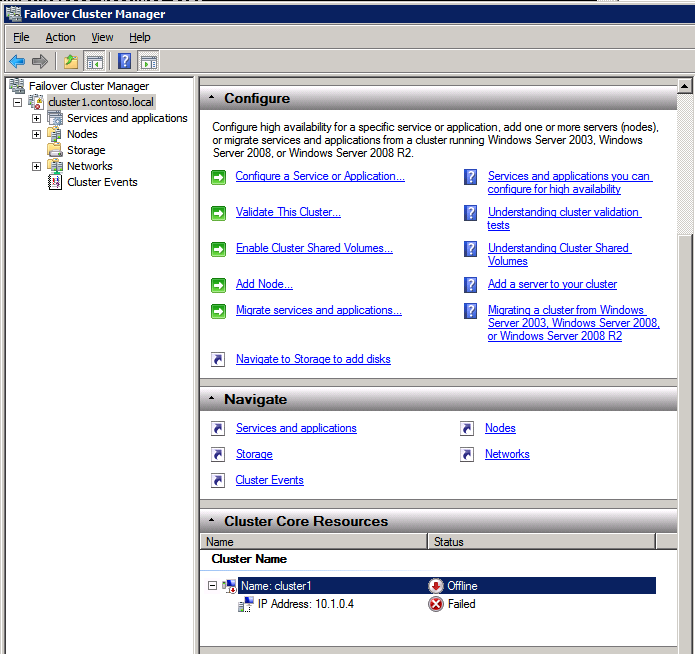
클러스터 IP 주소의 등록 정보를 열고이를 DHCP에서 정적으로 변경하고 사용하지 않는 IP 주소를 할당하십시오.
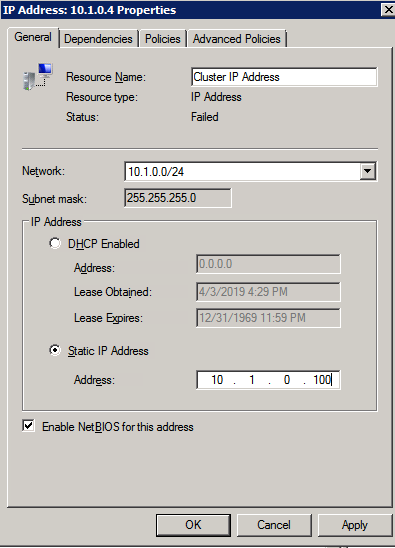
이름 리소스를 온라인 상태로 만듭니다.
파일 공유 감시 기능 추가
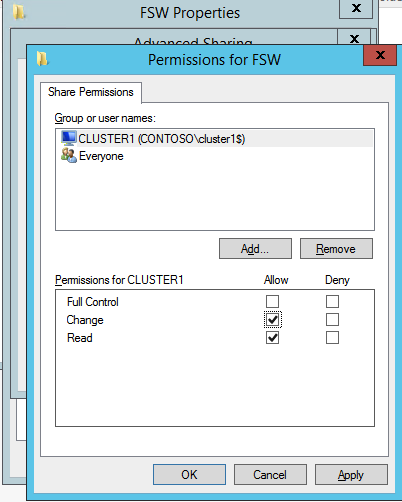
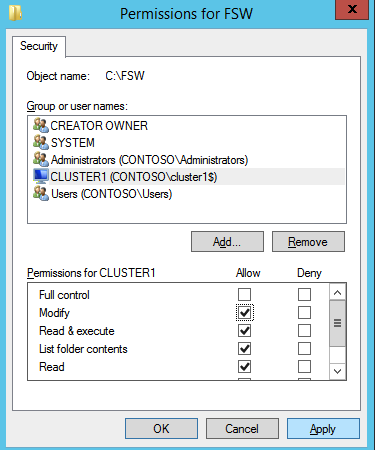
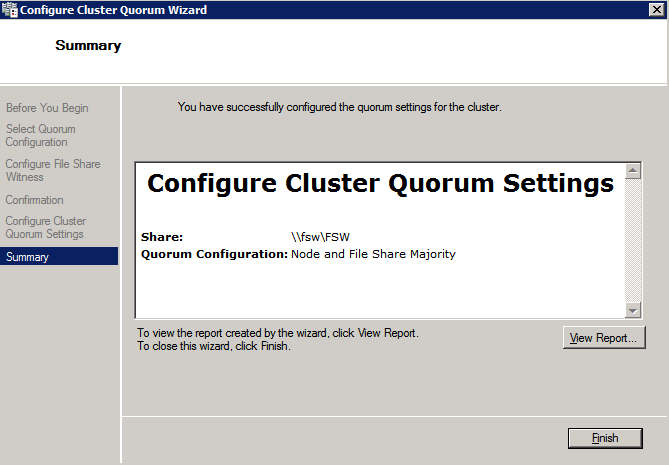
다음으로 File Share Witness를 추가해야합니다. 우리가 FSW로 프로비저닝 한 세 번째 서버에서 폴더를 만들고 아래 그림과 같이 공유하십시오. 아래와 같이 공유 및 보안 수준에서 CNO (클러스터 이름 개체) 읽기 / 쓰기 권한을 부여해야합니다.
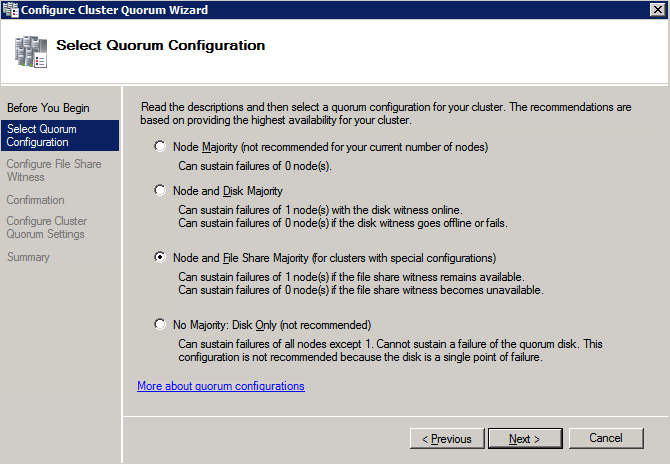
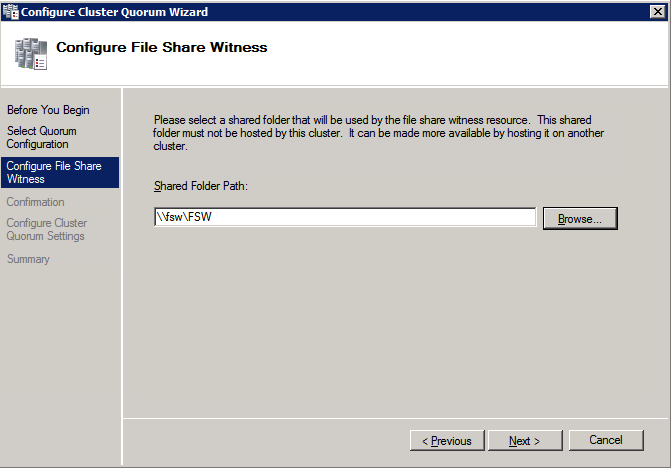
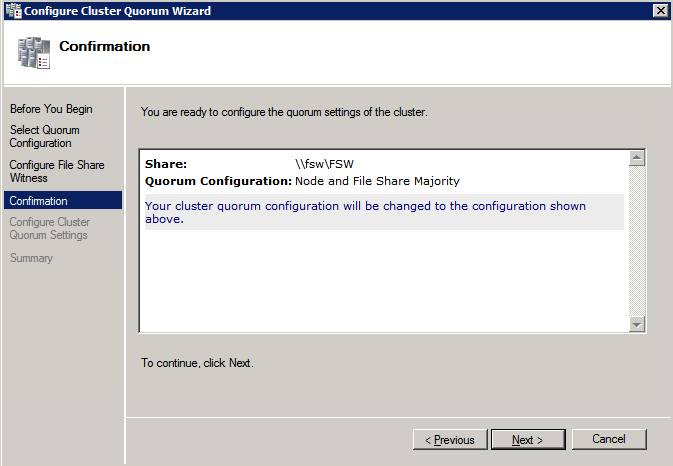
공유가 생성되면 클러스터 노드 중 하나에서 클러스터 쿼럼 구성 마법사를 실행하고 아래에 설명 된 단계를 수행하십시오.
DataKeeper를위한 서비스 계정 만들기
우리는 거의 DataKeeper를 설치할 준비가되었습니다. 그러나이 작업을 수행하기 전에 도메인 계정을 만들어 각 SQL Server 클러스터 인스턴스의 로컬 관리자 그룹에 추가해야합니다. DataKeeper를 설치할 때이 계정을 지정합니다.
DataKeeper 설치
아래 그림과 같이 두 SQL Server 클러스터 노드 각각에 DataKeeper를 설치하십시오.
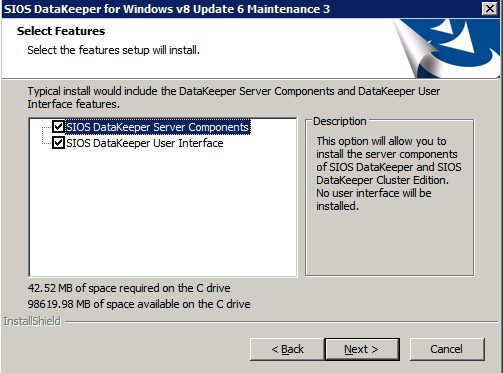
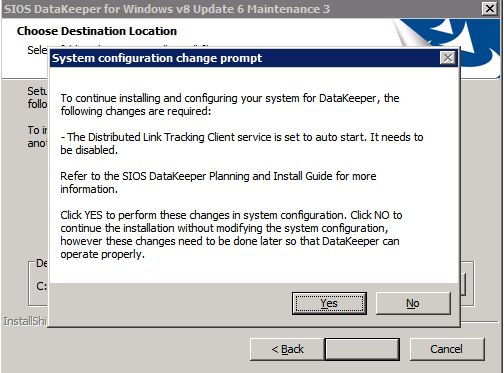
여기서 각 로컬 도메인 관리자 그룹에 추가 한 도메인 계정을 지정합니다.
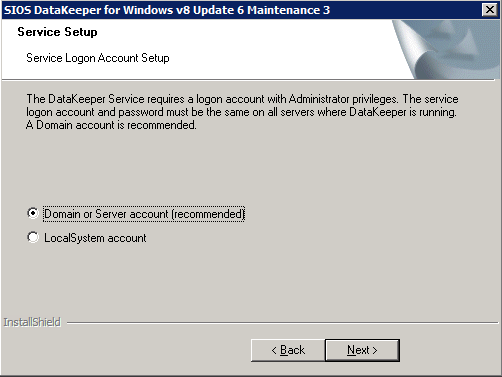
DataKeeper 구성
DataKeeper가 두 개의 클러스터 노드 각각에 설치되면 DataKeeper를 구성 할 준비가 된 것입니다.
참고 – 다음 단계에서 가장 흔히 발생하는 오류는 보안과 관련이 있으며, 주로 기존의 Azure Security 그룹이 필요한 포트를 차단하고 있습니다. 서버가 필요한 포트를 통해 통신 할 수 있는지 확인하려면 SIOS 설명서를 참조하십시오.
먼저 두 노드 각각에 연결해야합니다.
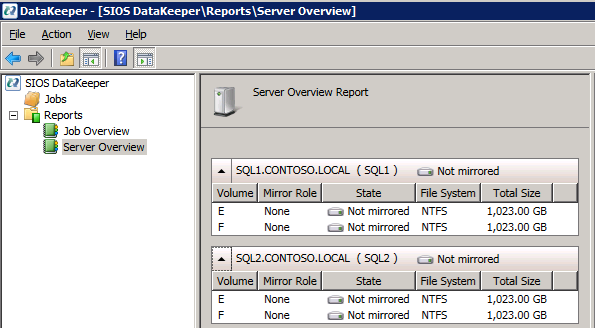
모든 것이 제대로 구성되면 서버 개요 보고서에 다음 내용이 표시되어야합니다.
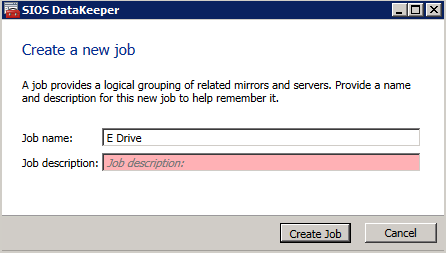
다음으로 새 작업을 만들고 아래에 설명 된 단계를 따르십시오.
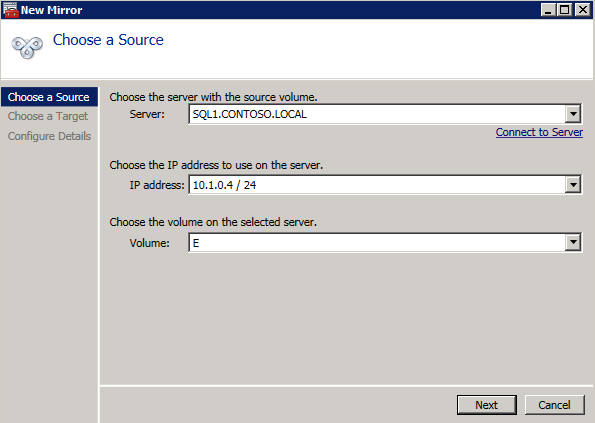
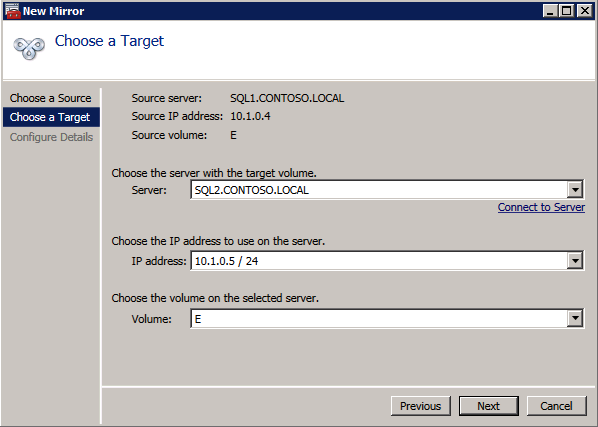
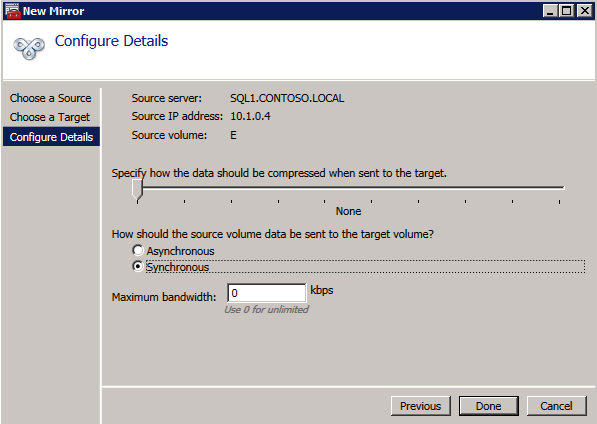
사용 가능한 저장소에 DataKeeper 볼륨 리소스를 등록하려면 여기에서 예를 선택하십시오.
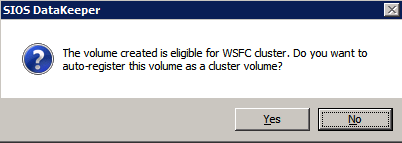
각 볼륨에 대해 위의 단계를 완료하십시오. 완료되면 Windows Server 장애 조치 (Failover) 클러스터링 UI에서 다음을 볼 수 있습니다.
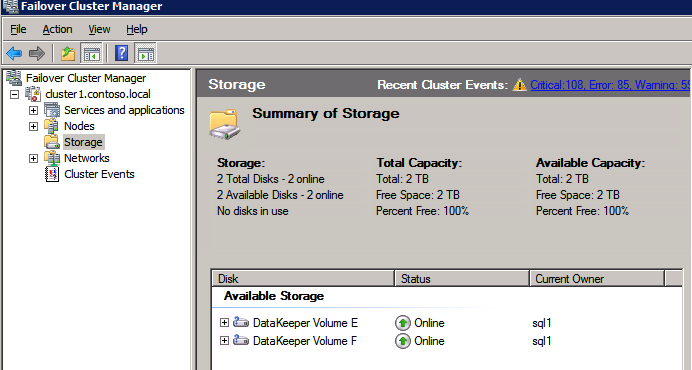
이제 SQL Server를 클러스터에 설치할 준비가되었습니다.
참고 -이 시점에서 복제 된 볼륨은 현재 Available Storage를 호스팅하고있는 노드에서만 액세스 할 수 있습니다. 예상 했으니 걱정하지 마라.
첫 번째 노드에 SQL Server 설치
첫 번째 노드에서 SQL Server 설치 프로그램을 실행합니다.
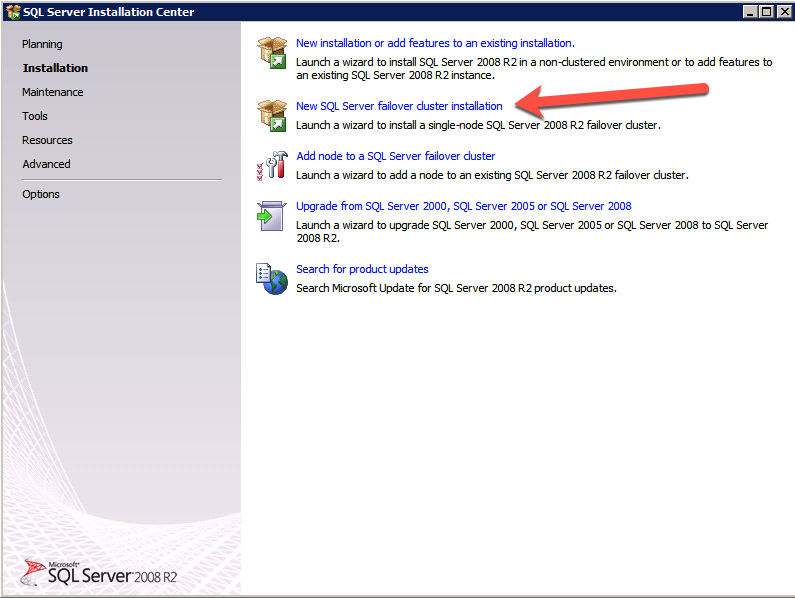
새 SQL Server 장애 조치 (Failover) 클러스터 설치를 선택하고 그림과 같은 단계를 수행하십시오.
필요한 옵션 만 선택하십시오.
이 문서는 사용자가 SQL Server의 기본 인스턴스를 사용한다고 가정합니다. 명명 된 인스턴스를 사용하는 경우에는 수신 대기 포트를 잠그고 나중에로드 밸런서를 구성 할 때 해당 포트를 사용해야합니다. 또한 명명 된 인스턴스에 연결하기 위해 SQL Server Browser Service (UDP 1434)에 대한 부하 분산 장치 규칙을 만들어야합니다. 이 두 가지 요구 사항 중 어느 것도이 가이드에서 다루지 않습니다. 그러나 명명 된 인스턴스가 필요한 경우 두 가지 추가 단계를 수행하면 작동합니다.
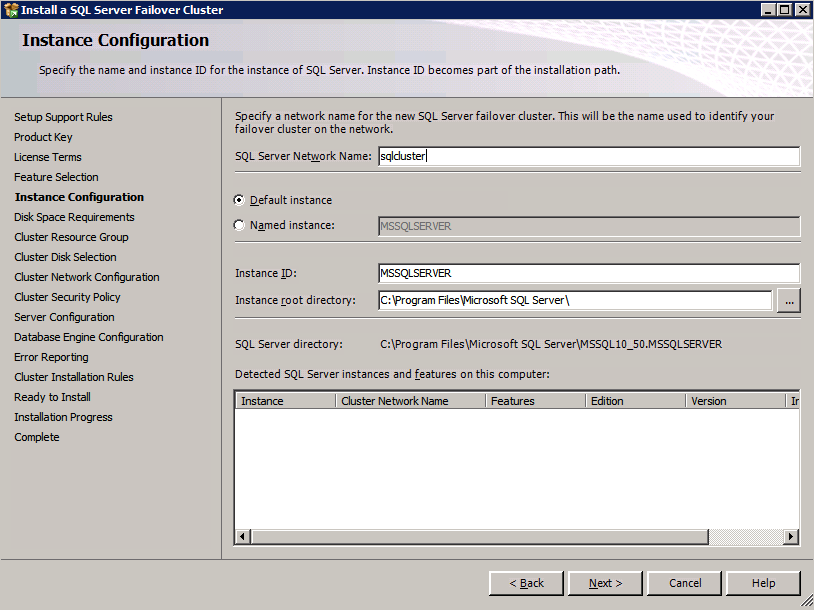
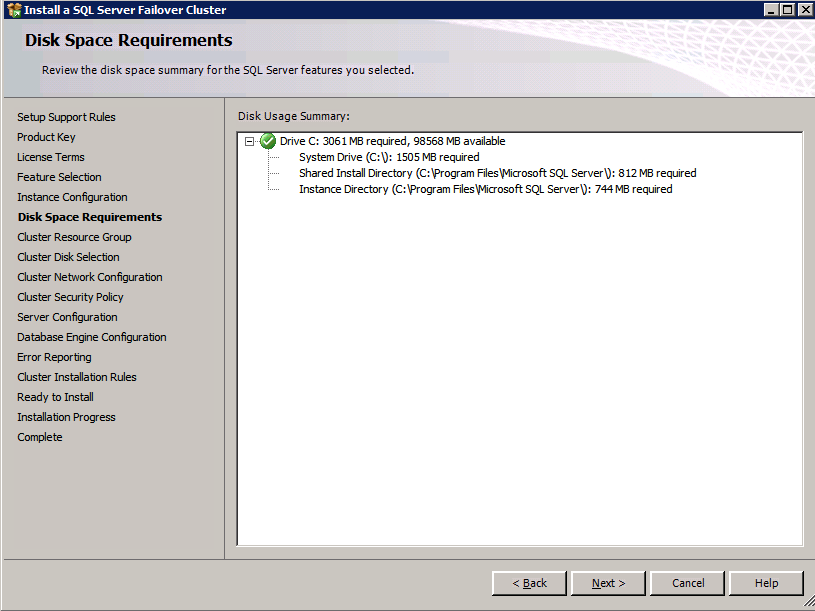
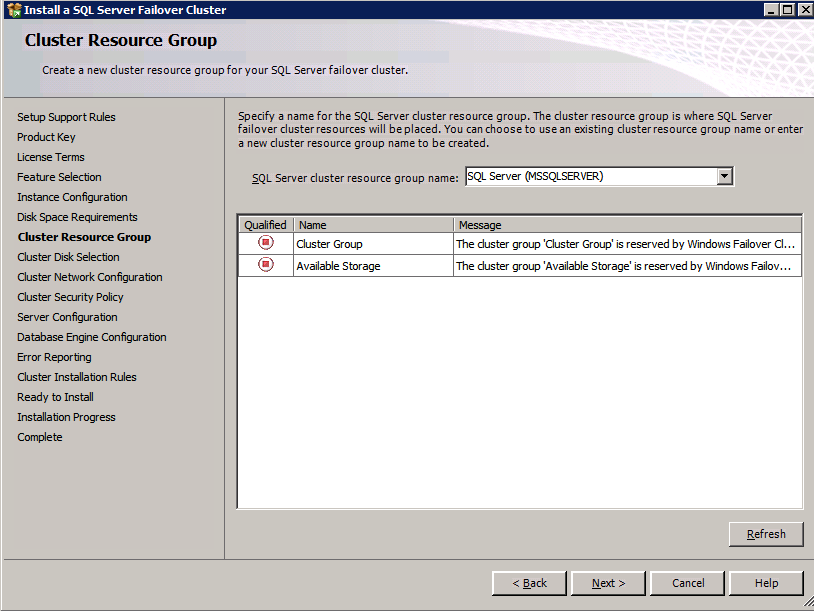
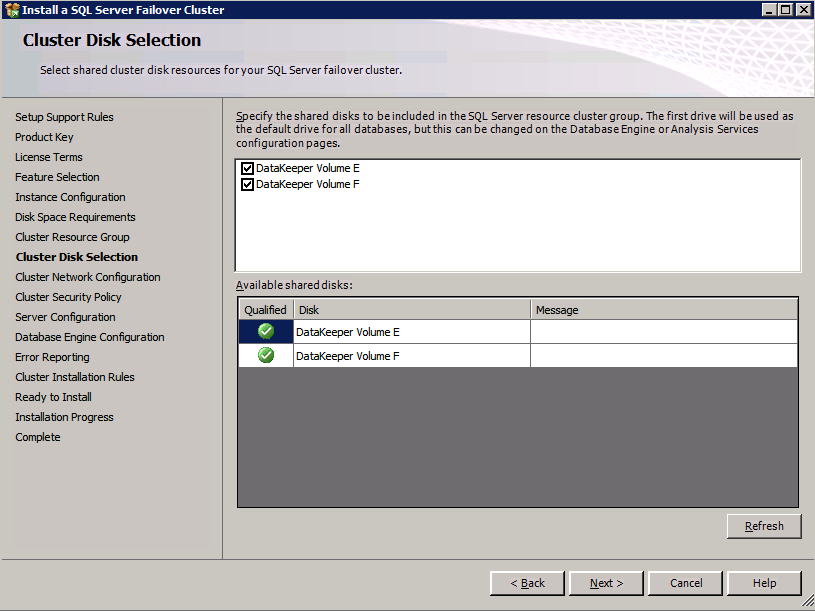
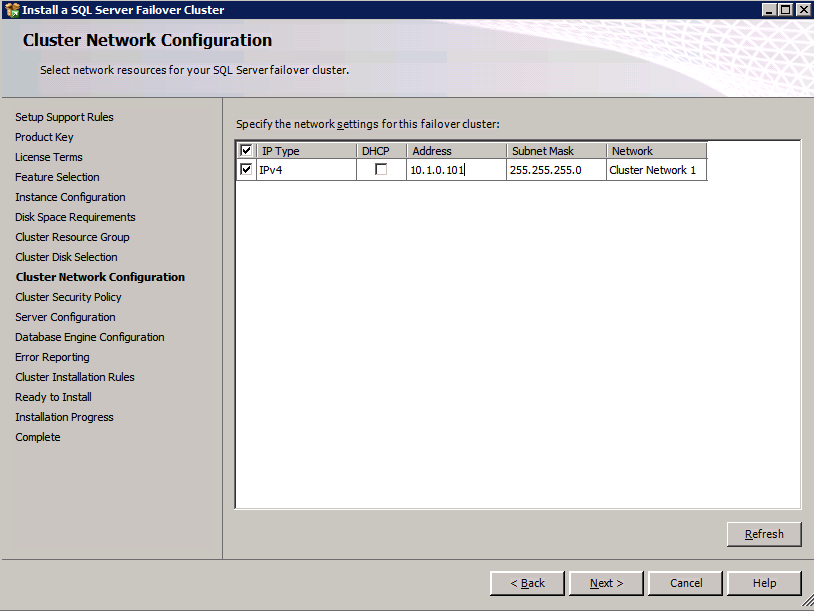
여기서 사용하지 않는 IP 주소를 지정해야합니다.
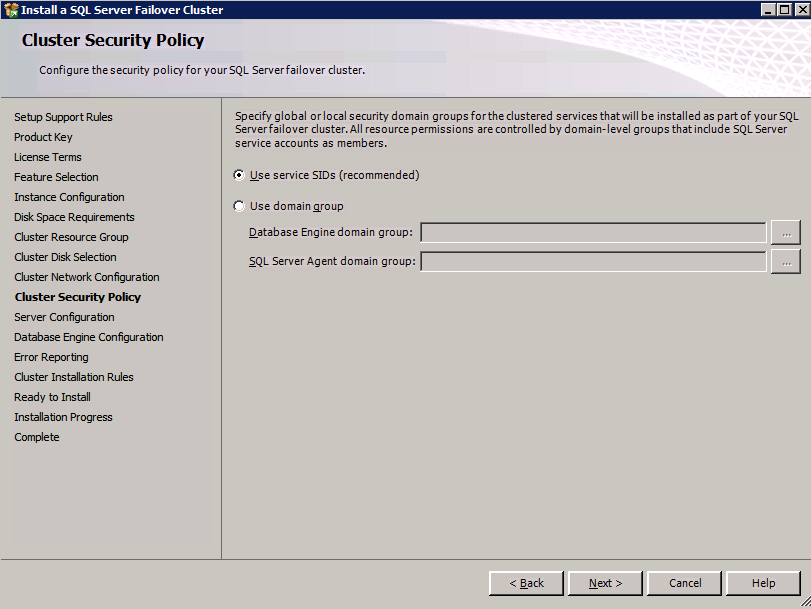
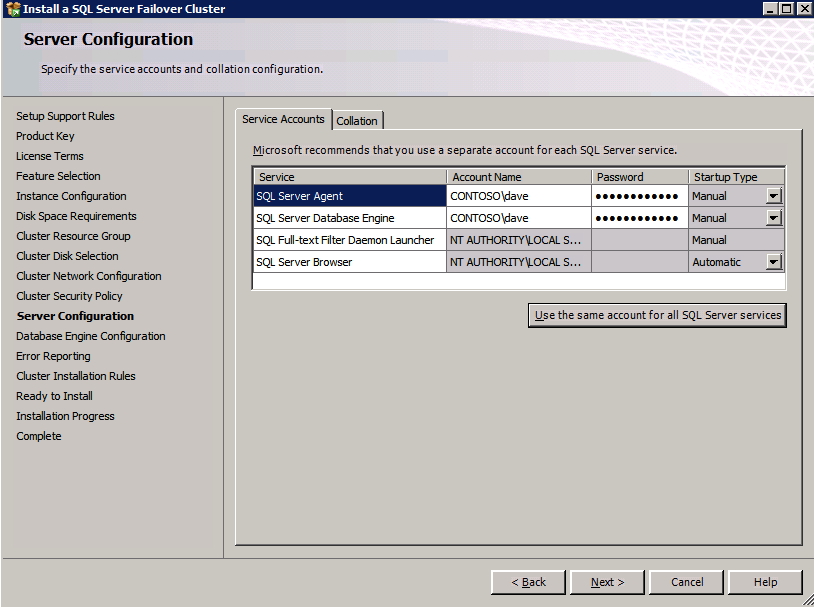
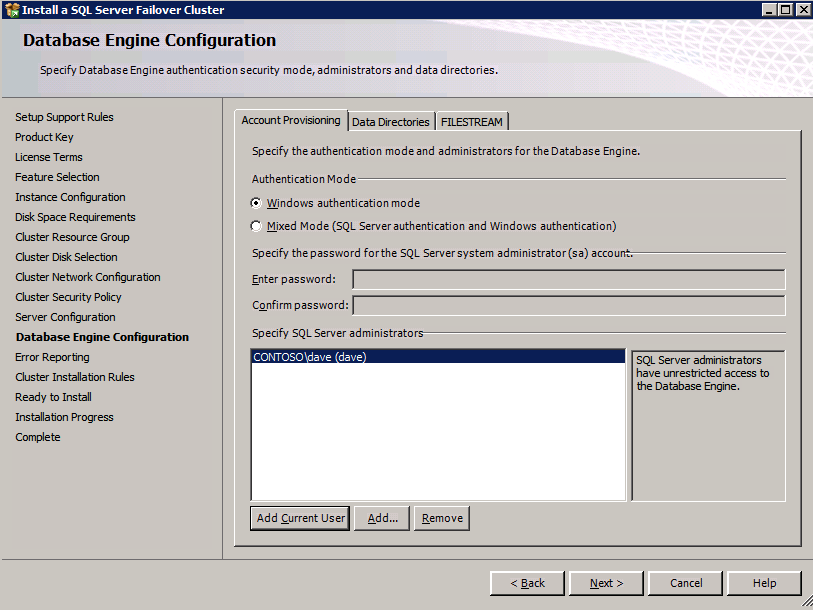
데이터 디렉토리 탭으로 이동하여 데이터 및 로그 파일을 재배치하십시오. 이 가이드의 끝 부분에서는 최적의 성능을 위해 미러되지 않은 DataKeeper 볼륨에 tempdb를 재배치하는 방법에 대해 설명합니다. 지금은 클러스터 된 디스크 중 하나에 보관하십시오.
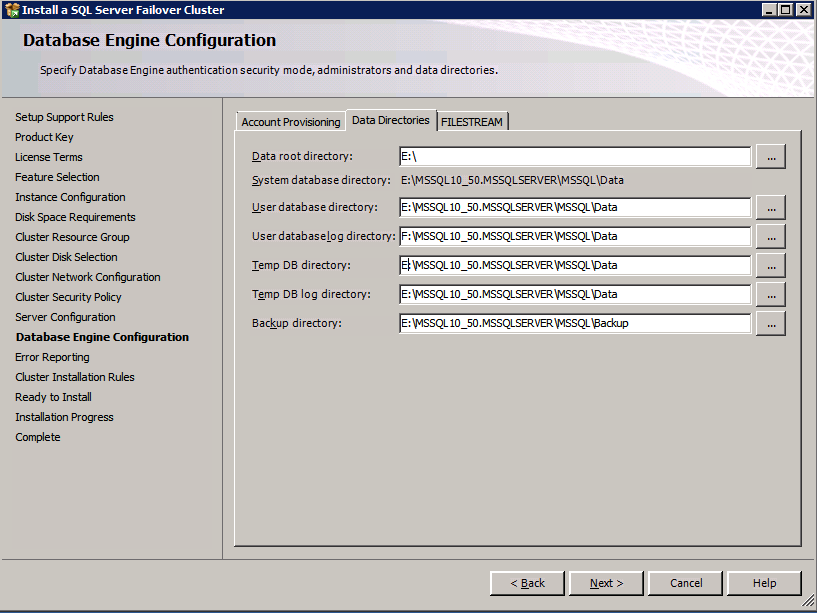
두 번째 노드에 SQL 설치
두 번째 노드에서 SQL Server 설치 프로그램을 다시 실행하십시오. 그런 다음 SQL Server 장애 조치 (failover) 클러스터에 노드 추가를 선택하십시오.
축하합니다. 거의 완료되었습니다! 그러나 Azure가 ARP를 지원하지 않기 때문에 다음 단계 에서처럼 클라이언트 리디렉션을 지원하기 위해 내부로드 밸런서 (ILB)를 구성해야합니다.
SQL 클러스터 IP 주소 업데이트
ILB가 제대로 작동하려면 클러스터 노드 중 하나에서 다음 명령을 실행해야합니다. SQL 클러스터 IP를 사용하면 SQL 클러스터 IP 주소가 ILB 상태 프로브에 응답하고 상태 프로브와의 IP 주소 충돌을 피하기 위해 서브넷 마스크를 255.255.255.255로 설정할 수 있습니다.
클러스터 res <IPResourceName> / priv enabledhcp = 0 주소 = <ILBIP> probeport = 59999 subnetmask = 255.255.255.255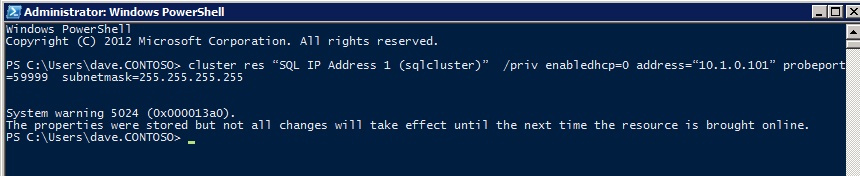
참고 – 그것이 우연인지 나는 모른다. 때때로이 명령을 실행했지만 작동하는 것처럼 보이지만 작업이 완료되지 않아 다시 시작해야합니다. 작동 여부를 알 수있는 방법은 SQL Server IP 리소스의 서브넷 마스크를 보는 것입니다. 255.255.255.255가 아니라면 성공적으로 실행되지 않았다는 것을 알 수 있습니다. 단순히 GUI 새로 고침 문제 일 수 있습니다. 서브넷 마스크가 업데이트되었는지 확인하려면 클러스터 GUI를 다시 시작하십시오.
성공적으로 실행 한 후에는 리소스를 오프라인으로 전환 한 다음 다시 온라인으로 가져와 변경 내용을 적용하십시오.
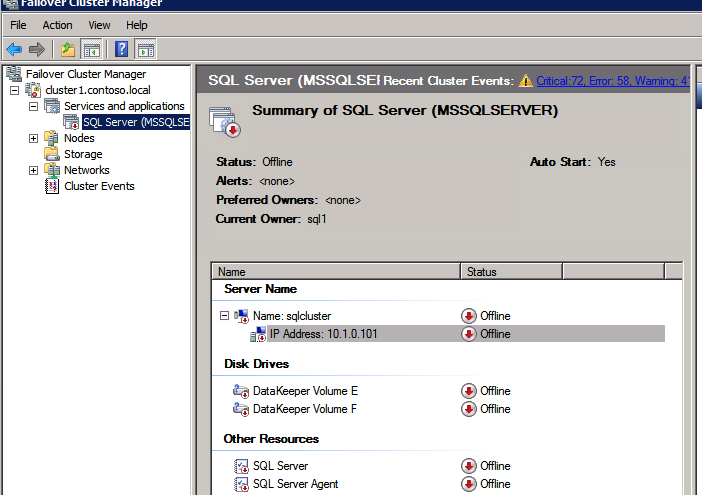
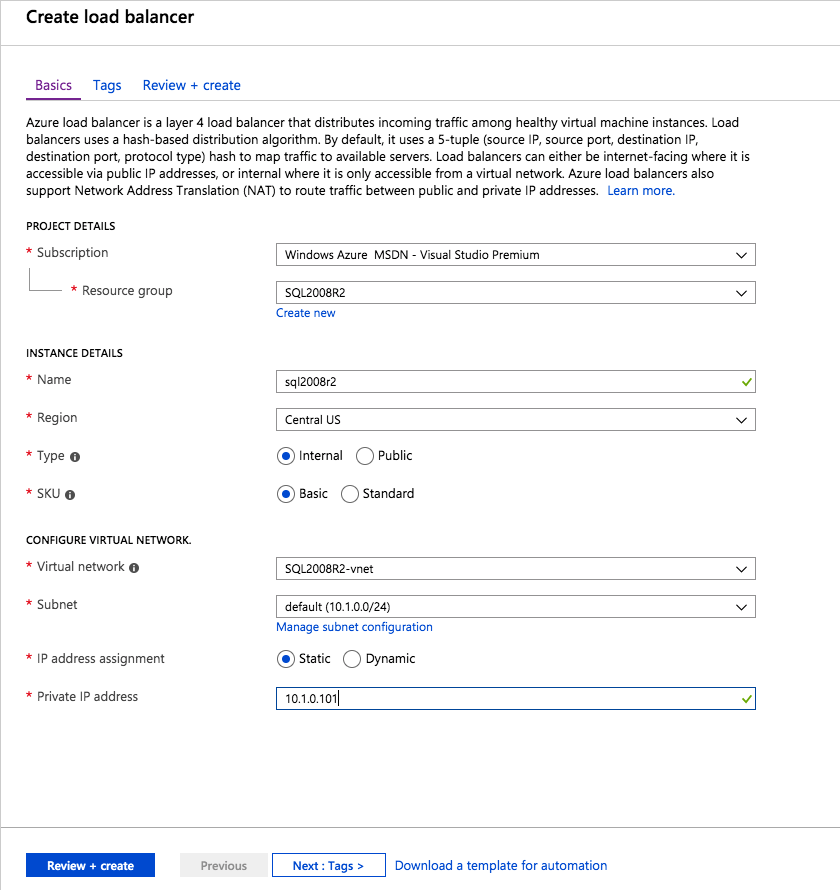
로드 밸런서 만들기
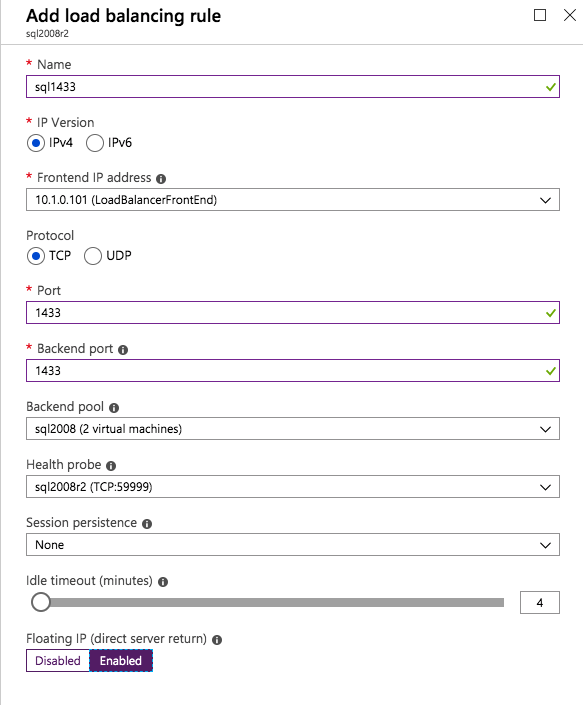
마지막 단계는로드 밸런서를 만드는 것입니다. 이 경우 우리는 포트 1433에서 수신 대기하는 SQL Server의 기본 인스턴스를 실행하고 있다고 가정합니다.
부하 분산 장치를 만들 때 정의한 개인 IP 주소는 SQL Server FCI가 사용하는 주소와 완전히 동일합니다.
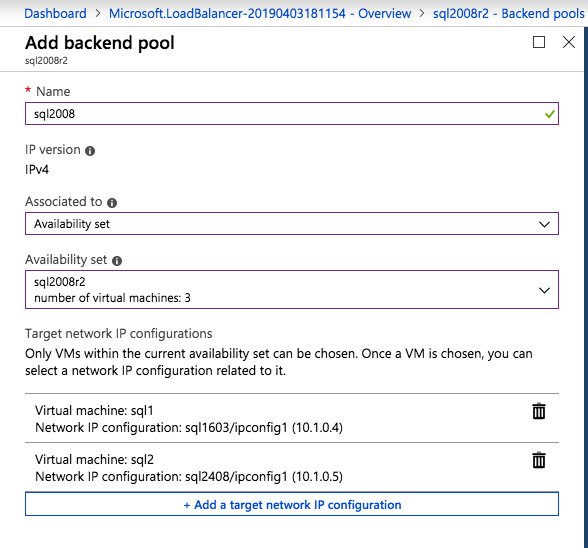
두 SQL Server 인스턴스를 백엔드 풀에 추가합니다. FSW를 백엔드 풀에 추가하지 마십시오.
이로드 밸런싱 규칙에서 유동 IP를 활성화해야합니다.
클러스터 테스트
가장 간단한 테스트는 패시브 노드에서 SQL Server Management Studio를 열고 클러스터에 연결하는 것입니다. 축하해! 연결하는대로 올바르게 했어! 연결할 수 없다면 두려워하지 마십시오. 문제를 해결하는 데 도움이되는 블로그 기사를 작성했습니다. 클러스터 관리는 기존의 공유 스토리지 클러스터를 관리하는 것과 완전히 동일합니다. 모든 것은 장애 조치 클러스터 관리자를 통해 제어됩니다.
선택 사항 – TempDB 재배치
최적의 성능을 위해 tempdb를 복제되지 않은 로컬 SSD로 옮기는 것이 좋습니다. 그러나 SQL Server 2008 R2에서는 tempdb가 클러스터 된 디스크에 있어야합니다. SIOS에는이 문제를 해결하는 비 미러 볼륨 리소스 (Non-Mirrored Volume Resource)라는 솔루션이 있습니다. 로컬 SSD 드라이브의 미러되지 않은 볼륨 리소스를 생성하고 거기에서 tempdb를 이동하는 것이 좋습니다. 참고로, 로컬 SSD 드라이브는 비 지속성입니다. tempdb를 보관하는 폴더와 해당 폴더에 대한 사용 권한이 서버를 다시 부팅 할 때마다 다시 만들어 지도록주의해야합니다.
로컬 SSD의 미러되지 않은 볼륨 리소스를 만든 후에는이 문서의 단계에 따라 tempdb의 위치를 변경하십시오. 이 기사에서 설명하는 시작 스크립트는 각 클러스터 노드에 추가되어야합니다.
Clusteringformeremortals.com의 허락을 받아 재현


