더 나은 결과로 클라우드에서 가용성을 복제하는 방법
영화 팁 – 다중성
Multiplicity는 1996 년 미국 공상 과학 코미디 영화로 Michael Keaton이 그의 가족과 까다로운 직업을 위해 시간을 내기 위해 고군분투하는 바쁜 건설 노동자 Doug Kinney 역으로 주연을 맡았습니다. 과학자가 그를 복제하겠다고 제안했을 때 Doug는 자신의 일정과 약속을 더 쉽게 충족시키는 데 동의합니다. 그러나 그의 사본은 자신의 사본을 만들기 시작합니다. 마지막 사본이 만들어 질 때까지 요점은 분명합니다. 복제만으로는 충분하지 않을 수도 있고 최소한 몇 가지 강력한 경고, 문제 및 부작용이있을 수 있습니다. 유명한 오리지널 스타 트렉 에피소드“Trouble with Tribbles”는 비슷한 점을 보여줍니다.
큰 화면 (또는 작은 화면)에서의 복제와 마찬가지로 클라우드에서의 복제는 훌륭한 도구이지만 문제가없는 것은 아닙니다.
클라우드에서 가용성을 복제 할 때 더 나은 결과를 얻는 방법에 대한 팁
1. 운영 체제 복제
이것은 당연한 것처럼 들리지만 실제 기업 환경에서 두 번 이상 발생하는 것을 보았습니다. 작동하지 않는 시스템을 복제하면 복제가 작동하지 않고 복원 할 때 문제가됩니다. 만든 클론이 운영 및 기능 시스템에서 생성되었는지 확인합니다.
2. 데이터를 디스크에 동기화하고 복원시 다시 동기화
파일 시스템 무결성이 중요합니다. 애플리케이션 및 / 또는 VM이 일관된 상태인지 확인하지 않는 경우 대부분의 공급 업체는 생성 된 결과 이미지를 보장하지 않습니다. 스냅 샷은 스냅 샷 명령이 실행될 때 볼륨에 기록 된 데이터 만 캡처하므로 모든 애플리케이션 또는 운영 체제에서 캐시 한 모든 데이터를 제외 할 수 있습니다. 데이터가 파일 시스템에 올바르게 동기화되었는지 확인하는 것은 중요한 단계이며 클러스터 환경에서 절대적으로 중요합니다.
이미지에서 복원 할 때 파일 시스템 무결성도 염두에 두어야합니다. 데이터 복제를 사용 중이고 이미지를 클러스터의 소스 또는 대상으로 복원하는 경우 두 노드가 동기화되어 있는지 확인하는 것이 가장 중요합니다. 그렇게하지 않으면 장애 조치 또는 전환시 파일 시스템 오류가 발생하거나 데이터가 손실 될 수 있습니다. 클라우드에서 가용성을 복제하여 원하는 결과를 얻으십시오.
3. 인스턴스 중지
많은 환경에서는 이미지를 생성하기 위해 인스턴스를 중지 할 필요가 없으며 AWS와 같은 일부 환경에서는 복사하기 전에 노드 전원을 끄는 단계를 수행합니다.그러나 많은 도구와 사이트에서는 손상, 무결성 손실 또는 설치된 응용 프로그램을 시작, 중지 또는 실행하는 데 문제가있는 이미지를 생성하지 않도록 응용 프로그램을 중지하고 파일 시스템 액세스를 올바르게 동기화 할 것을 권장합니다.
4. 클라우드의 모든 항목 (노드, 디스크, NIC, 모든 항목)에 라벨 지정
클론 생성은 무료 작업이지만 결과 디스크와 구성 요소는 일반적으로 그렇지 않습니다.예를 들어 AWS는 "이미지를 등록 취소하고 스냅 샷을 삭제할 때까지 스냅 샷에 대한 요금이 부과됩니다"라고 말합니다. 항목에 라벨이 지정되지 않은 경우 사용중인 항목과 사용하지 않는 항목 및 만든 이유를 알면 문제가 될 수 있습니다. 또한 기존 팀원들의 덧없는 기억이나 집중력 저하의 영향을받습니다.모든 것에 라벨을 붙입니다.
5. 클론과 스냅 샷을 자주 정리 (비용 절감 및 골치 아픈 일 절감)
오래된 스냅 샷과 클론을 정리하면 비용을 절감 할 수있을뿐만 아니라 골칫거리를 줄이는데도 좋습니다.오래된 스냅 샷은 최신 복사본에서 해결되거나 해결 된 취약성을 다시 도입 할 위험이 있습니다.SIOS Technology Corp.의 고객 경험 부사장으로서 스냅 샷에서 복원 한 고객과 함께 작업했을 때 그 결과를 직접 보았습니다. 응용 프로그램을 다시 시작하면서 몇 가지 문제가 발생했습니다. 문제 해결 후 복제본이 이전 버전의 보안 소프트웨어를 실행하고 있음을 확인했습니다. 사용자 프로필에 저장된 캐시 된 자격 증명 및 메타 데이터는 더 이상 외부 탑재 데이터 드라이브에 저장된 실제 애플리케이션 데이터와 동기화되지 않았습니다.
6. 클라우드에서 클론 복제 제한 또는 제한
마지막으로 클라우드에서 수행하는 모든 작업을 복제 할 필요는 없습니다. 복제 할 워크로드 유형을 제한하고 환경에서 복제를 생성 할 수있는 역할의 수를 제한하십시오.
영화에서 Doug의 클론이 자신의 복제 시리즈를 촉발했을 때 이미 압도 된 Doug (Michael Keaton)는 아내에게서 만든 엉망진창을 숨기려고 노력하면서 자신의 많은 클론을 관리하기 위해 추가 에너지를 투입해야합니다. 클라우드에서 더 나은 결과로 클론 가용성을 달성하는 것은 어렵지 않습니다. 작업을 더 쉽게 만들고 환경을 더 안전하게 만드는 도구에서 더 많은 작업을 수행하고 위험을 추가하지 않도록 신중하게 복제하십시오.
– Cassius Rhue, 고객 경험 담당 부사장
SIOS에서 재현





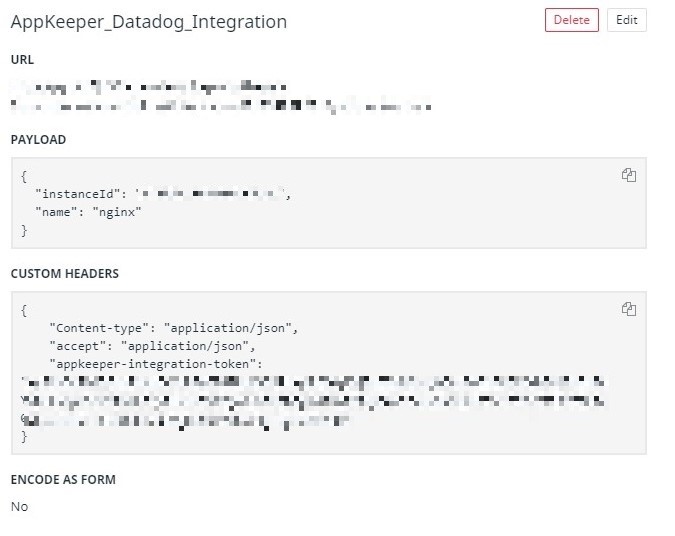
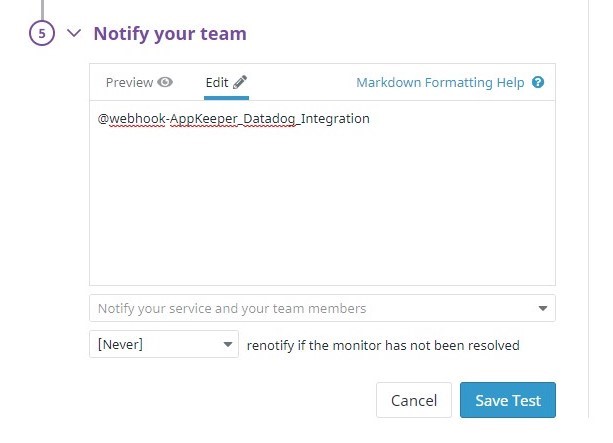
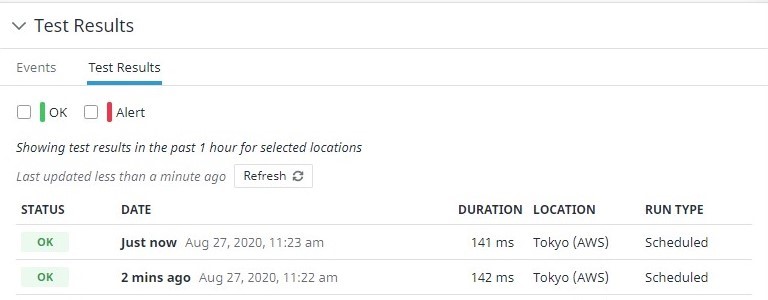
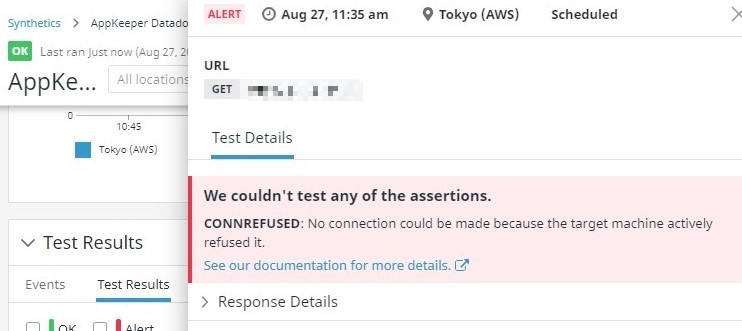
 "구성"을 클릭하여 Webhook 통합 구성 페이지를 엽니 다.
"구성"을 클릭하여 Webhook 통합 구성 페이지를 엽니 다.