ทีละขั้นตอน: วิธีการกำหนดค่าอินสแตนซ์ของคลัสเตอร์ล้มเหลว SQL Server 2008 R2 ใน Azure
หากคุณต้องการคำแนะนำกำหนดค่าอินสแตนซ์ของคลัสเตอร์เซิร์ฟเวอร์ล้มเหลว SQL ใน Azure คุณอาจยังใช้ SQL Server 2008/2008 R2 อยู่ และต้องการใช้ประโยชน์จากการปรับปรุงความปลอดภัยเพิ่มเติมที่ Microsoft เสนอให้หากคุณย้าย SQL Server 2008/2008 R2 ไปยัง Azure ก่อนหน้านี้ฉันเคยเขียนเกี่ยวกับหัวข้อนี้ในโพสต์บล็อกนี้ คุณอาจสงสัยว่าจะต้องแน่ใจได้อย่างไรว่าอินสแตนซ์ของคลัสเตอร์เซิร์ฟเวอร์ล้มเหลว SQL ของคุณยังคงพร้อมใช้งานสูงเมื่อคุณย้ายไปยัง Azure วันนี้คนส่วนใหญ่มีธุรกิจที่สำคัญ SQL Server 2008/2008 R2 กำหนดค่าเป็นอินสแตนซ์คลัสเตอร์ (SQL Server FCI) ในศูนย์ข้อมูลของพวกเขา เมื่อดูที่ Azure คุณอาจเข้าใจว่าเนื่องจากการขาดพื้นที่เก็บข้อมูลที่ใช้ร่วมกันอาจดูเหมือนว่าคุณไม่สามารถนำ SQL Server FCI ของคุณไปยังกลุ่มเมฆ Azure อย่างไรก็ตามนั่นไม่ใช่กรณีที่ต้องขอบคุณ SIOS DataKeeper SIOS DataKeeper ช่วยให้คุณสามารถสร้างอินสแตนซ์ของคลัสเตอร์เซิร์ฟเวอร์ล้มเหลวของ SQL ใน Azure, AWS, Google Cloud หรือที่อื่นใดที่ไม่มีที่เก็บข้อมูลที่ใช้ร่วมกันหรือที่คุณต้องการกำหนดค่าหลายไซต์คลัสเตอร์ DataKeeper เปิดใช้งาน SANless clusters สำหรับ Windows และ Linux ตั้งแต่ปี 1999 Microsoft จัดทำเอกสารการใช้ SIOS DataKeeper สำหรับอินสแตนซ์ของคลัสเตอร์เซิร์ฟเวอร์ล้มเหลวของ SQL ในเอกสารประกอบ: ความพร้อมใช้งานสูงและการกู้คืนความเสียหายสำหรับ SQL Server ในเครื่องเสมือน Azure ฉันเคยเขียนเกี่ยวกับ SQL Server FCI ที่เคยทำงานใน Azure มาก่อน แต่ฉันไม่เคยเผยแพร่คู่มือแบบทีละขั้นตอนเฉพาะสำหรับ SQL Server 2008/2008 R2 ข่าวดีก็คือมันใช้งานได้ดีกับ SQL 2008/2008 R2 เช่นเดียวกับ SQL 2012/2014/2016/2017 และจะเปิดตัวเร็ว ๆ นี้ 2019 นอกจากนี้ไม่ว่ารุ่นของ Windows Server (2008/2012/2016/2019) หรือ SQL Server (2008/2012/2014/2016/2017) กระบวนการกำหนดค่าจะคล้ายกันมากพอที่คู่มือนี้ควรจะเพียงพอที่จะให้คุณผ่าน การกำหนดค่า หากรสชาติของ SQL หรือ Windows ของคุณไม่ครอบคลุมในคำแนะนำใด ๆ ของฉันอย่ากลัวที่จะกระโดดเข้ามาและสร้าง SQL Server FCI และอ้างอิงคู่มือนี้ฉันคิดว่าคุณจะเข้าใจถึงความแตกต่างและถ้าคุณติดอยู่ ยื่นมือมาหาฉันทาง Twitter @davberm และฉันยินดีที่จะให้คุณ คู่มือนี้ใช้ SQL Server 2008 R2 กับ Windows Server 2012 R2 เวลาเขียนนี้ฉันไม่เห็นภาพ Azure Marketplace ของ SQL 2008 R2 บน Windows Server 2012 R2 ดังนั้นฉันต้องดาวน์โหลดและติดตั้ง SQL 2008 R2 ด้วยตนเอง ส่วนตัวแล้วฉันชอบชุดค่าผสมนี้ แต่ถ้าคุณจำเป็นต้องใช้ Windows Server 2008 R2 หรือ Windows 212 ที่ใช้ได้ หากคุณใช้ Windows Server 2008 R2 อย่าลืมติดตั้ง kb3125574 Conveience Rollup Update สำหรับ Windows Server 2008 R2 SP1 หรือถ้าคุณติดกับ Server 2012 (ไม่ใช่ R2) คุณต้องใช้ Hotfix ใน kb2854082 อย่าหลงกลโดยบทความนี้ที่บอกว่าคุณต้องติดตั้ง kb2854082 ในอินสแตนซ์ของ SQL Server 2008 R2 ของคุณ หากคุณเริ่มค้นหาการอัปเดตนั้นสำหรับ Windows Server 2008 R2 คุณจะพบว่ามีเฉพาะรุ่นสำหรับ Server 2012 เท่านั้น โปรแกรมแก้ไขด่วนนั้นสำหรับ Server 2008 R2 นั้นจะรวมอยู่ในการยกเลิกการปรับปรุงการยกเลิกการอำนวยความสะดวกสำหรับ Windows Server 2008 R2 SP1 แทน
การจัดเตรียม AZURE
ฉันจะไม่เข้าไปดูรายละเอียดที่นี่พร้อมภาพหน้าจอจำนวนมากโดยเฉพาะอย่างยิ่งเนื่องจาก Azure Portal UI มีแนวโน้มที่จะเปลี่ยนค่อนข้างบ่อยดังนั้นภาพหน้าจอใด ๆ ที่ฉันถ่ายจะค้างเงนอย่างรวดเร็ว แต่ฉันจะครอบคลุมหัวข้อสำคัญที่คุณควรระวัง
ความผิดพลาดในโดเมนหรือพื้นที่ว่างหรือไม่
เพื่อให้แน่ใจว่าอินสแตนซ์ของ SQL Server ของคุณพร้อมใช้งานสูงคุณต้องตรวจสอบให้แน่ใจว่าโหนดคลัสเตอร์ของคุณอยู่ใน Fault Domains (FD) หรือโซนความพร้อมใช้งาน (AZ) ที่แตกต่างกัน อินสแตนซ์ของคุณไม่เพียง แต่ต้องอาศัยอยู่ใน FD หรือ AZ ที่ต่างกัน แต่ File Share Witness (ดูด้านล่าง) ยังต้องอยู่ใน FD หรือ AZ ที่แตกต่างจากโหนดคลัสเตอร์ของคุณ นี่คือสิ่งที่ฉันทำ AZs เป็นคุณลักษณะใหม่ล่าสุดของ Azure แต่ได้รับการสนับสนุนในภูมิภาคต่างๆ AZs ให้ SLA ที่สูงขึ้น (99.99%) จากนั้น FDs (99.95%) และปกป้องคุณจากการขาดของคลาวด์ที่ฉันอธิบายในโพสต์ Azure Outage Post-Mortem ของฉัน หากคุณสามารถปรับใช้ในภูมิภาคที่รองรับ AZ ได้ฉันขอแนะนำให้คุณใช้ AZs ในคู่มือนี้ฉันใช้ AZ ซึ่งคุณจะเห็นเมื่อคุณไปที่ส่วนในการกำหนดค่าตัวโหลดบาลานซ์ อย่างไรก็ตามหากคุณใช้ FD ทุกอย่างจะเหมือนกันทุกประการยกเว้นการกำหนดค่าโหลดบาลานเซอร์จะอ้างอิงชุดความพร้อมใช้งานแทนโซนความพร้อมใช้งาน
อะไรคือสิ่งที่แบ่งปันให้คุณถาม?
การทำคลัสเตอร์ Windows Server Failover Clustering (WSFC) จะทำให้คุณต้องกำหนดค่า "พยาน" เพื่อให้แน่ใจว่าการทำงานล้มเหลวอย่างถูกต้อง Windows Server Failover Clustering รองรับพยานสามชนิด: ดิสก์, การแชร์ไฟล์, คลาวด์ เนื่องจากเราอยู่ใน Azure จึงไม่สามารถเป็นพยานได้ Cloud Witness นั้นมีเฉพาะใน Windows Server 2016 และใหม่กว่าเท่านั้นดังนั้นเราจึงมี File Share Witness หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับโควรัมกลุ่มตรวจสอบการโพสต์ของฉันในบล็อก Microsoft Press จาก MVPs: ทำความเข้าใจกับ Quorum คลัสเตอร์เซิร์ฟเวอร์ Windows ล้มเหลวใน Windows Server 2012 R2
เพิ่มการจัดเก็บลงในเซิร์ฟเวอร์ SQL ของคุณ
เมื่อคุณจัดเตรียมอินสแตนซ์ SQL Server ของคุณคุณจะต้องการเพิ่มดิสก์เพิ่มเติมให้กับแต่ละอินสแตนซ์ น้อยที่สุดคุณจะต้องมีหนึ่งดิสก์สำหรับข้อมูล SQL และไฟล์บันทึกหนึ่งดิสก์สำหรับ Tempdb คุณควรมีดิสก์แยกต่างหากสำหรับไฟล์บันทึกและข้อมูลบ้างหรือไม่เมื่อใช้งานในระบบคลาวด์ ที่ปลายด้านหลังพื้นที่เก็บข้อมูลทั้งหมดมาจากที่เดียวกันและขนาดอินสแตนซ์ของคุณจะ จำกัด IOPS ทั้งหมดของคุณ ในความคิดของฉันไม่มีค่าใด ๆ ในการแยกไฟล์บันทึกและข้อมูลของคุณเพราะคุณไม่สามารถมั่นใจได้ว่าไฟล์เหล่านั้นกำลังทำงานอยู่ในดิสก์ที่มีอยู่จริงสองชุด ฉันจะปล่อยให้คุณตัดสินใจ แต่ฉันใส่บันทึกและข้อมูลทั้งหมดในปริมาณเดียวกัน โดยทั่วไปแล้ว SQL Server 2008 R2 FCI จะทำให้คุณต้องวาง tempdb ลงในดิสก์ที่ทำคลัสเตอร์ อย่างไรก็ตาม SIOS DataKeeper มีคุณสมบัติที่ดีมาก ๆ ที่เรียกว่า DataKeeper Non-Mirrored Volume Resource คู่มือนี้ไม่ครอบคลุมถึงการย้าย tempdb ไปยังทรัพยากรปริมาณที่ไม่ใช่มิร์เรอร์ แต่เพื่อประสิทธิภาพที่ดีที่สุดคุณควรทำเช่นนี้ ไม่มีเหตุผลที่ดีที่จะทำซ้ำ tempdb เนื่องจากมันถูกสร้างขึ้นใหม่เมื่อเกิดความล้มเหลว เท่าที่เกี่ยวข้องกับการจัดเก็บคุณสามารถใช้ประเภทการจัดเก็บใด ๆ แต่แน่นอนใช้ดิสก์ที่มีการจัดการเมื่อใดก็ตามที่เป็นไปได้ ตรวจสอบให้แน่ใจว่าแต่ละโหนดในคลัสเตอร์มีการกำหนดค่าการจัดเก็บข้อมูลเหมือนกัน เมื่อคุณเปิดใช้งานอินสแตนซ์คุณจะต้องแนบดิสก์เหล่านี้และฟอร์แมต NTFS ตรวจสอบให้แน่ใจว่าแต่ละอินสแตนซ์ใช้อักษรระบุไดรฟ์เดียวกัน
เครือข่าย
ไม่ใช่ความต้องการที่หนักหน่วง แต่ถ้าเป็นไปได้ให้ใช้ขนาดของอินสแตนซ์ที่รองรับเครือข่ายเร่งความเร็ว ตรวจสอบให้แน่ใจว่าคุณแก้ไขอินเทอร์เฟซเครือข่ายในพอร์ทัล Azure เพื่อให้อินสแตนซ์ของคุณใช้ที่อยู่ IP แบบคงที่ สำหรับการทำคลัสเตอร์ให้ทำงานอย่างถูกต้องคุณต้องแน่ใจว่าคุณอัปเดตการตั้งค่าสำหรับเซิร์ฟเวอร์ DNS เพื่อให้ชี้ไปที่เซิร์ฟเวอร์ Windows AD / DNS ของคุณและไม่ใช่เฉพาะเซิร์ฟเวอร์ DNS สาธารณะบางตัว
การรักษาความปลอดภัย
ตามค่าเริ่มต้นการสื่อสารระหว่างโหนดในเครือข่ายเสมือนเดียวกันจะเปิดกว้าง แต่ถ้าคุณล็อค Azure Security Group ของคุณไว้คุณจะต้องรู้ว่าพอร์ตใดที่จะต้องเปิดระหว่างโหนดคลัสเตอร์และปรับกลุ่มความปลอดภัยของคุณ จากประสบการณ์ของฉันปัญหาเกือบทั้งหมดที่คุณจะพบเมื่อสร้างคลัสเตอร์ใน Azure อาจเกิดจากพอร์ตที่ถูกบล็อก DataKeeper มีบางพอร์ตที่จำเป็นต้องเปิดระหว่างอินสแตนซ์ของคลัสเตอร์ พอร์ตเหล่านั้นมีดังนี้: UDP: 137, 138 TCP: 139, 445, 9999 รวมถึงพอร์ตในช่วง 10,000 ถึง 10025 คลัสเตอร์ Failover มีชุดข้อกำหนดของพอร์ตของตัวเองที่ฉันจะไม่พยายามทำเอกสารที่นี่ บทความนี้ดูเหมือนจะมีที่ครอบคลุม http://dsfnet.blogspot.com/2013/04/windows-server-clustering-sql-server.html นอกจากนี้ Load Balancer ที่อธิบายในภายหลังจะใช้พอร์ตโพรบที่ต้องอนุญาตการรับส่งข้อมูลขาเข้าในแต่ละโหนด พอร์ตที่ใช้กันทั่วไปและอธิบายไว้ในคู่มือนี้คือ 59999 และในที่สุดถ้าคุณต้องการให้ลูกค้าของคุณสามารถเข้าถึงอินสแตนซ์ SQL Server ของคุณคุณต้องการให้แน่ใจว่าพอร์ต SQL Server ของคุณเปิดอยู่ซึ่งโดยค่าเริ่มต้นคือ 1433 จำไว้ว่าพอร์ตเหล่านี้สามารถบล็อกได้โดย Windows Firewall หรือ Azure Security Groups ดังนั้นเพื่อให้แน่ใจว่าได้ตรวจสอบทั้งสองอย่างเพื่อให้แน่ใจว่าสามารถเข้าถึงได้
เข้าร่วม DOMAIN
ข้อกำหนดสำหรับ SQL Server 2008 R2 FCI คืออินสแตนซ์นั้นต้องอยู่ในโดเมน Windows Server เดียวกัน ดังนั้นหากคุณยังไม่ได้ดำเนินการตรวจสอบให้แน่ใจว่าคุณได้เข้าร่วมอินสแตนซ์กับโดเมน Windows ของคุณ
บัญชีบริการท้องถิ่น
เมื่อคุณติดตั้ง DataKeeper มันจะขอให้คุณระบุบัญชีบริการ คุณต้องสร้างบัญชีผู้ใช้โดเมนจากนั้นเพิ่มบัญชีผู้ใช้นั้นไปยังกลุ่มผู้ดูแลระบบท้องถิ่นในแต่ละโหนด เมื่อถูกถามระหว่างการติดตั้ง DataKeeper ให้ระบุบัญชีนั้นเป็นบัญชีบริการ DataKeeper หมายเหตุ – ยังไม่ได้ติดตั้ง DataKeeper เลย!
กลุ่มความปลอดภัยระดับโลก DOMAIN
คุณจะถูกขอให้ระบุกลุ่มความปลอดภัยโดเมนทั่วโลกสองกลุ่มในขณะที่คุณติดตั้ง SQL 2008 R2 คุณอาจต้องการดูคำแนะนำการติดตั้ง SQL และสร้างกลุ่มเหล่านั้นทันที สร้างบัญชีผู้ใช้โดเมนและวางไว้ในแต่ละบัญชีความปลอดภัยเหล่านี้ คุณจะระบุบัญชีนี้เป็นส่วนหนึ่งของการติดตั้ง SQL Server Cluster
ข้อกำหนดล่วงหน้าอื่น ๆ
คุณต้องเปิดใช้งานทั้ง Failover Clustering และ. Net 3.5 ในแต่ละอินสแตนซ์ของสองอินสแตนซ์ของคลัสเตอร์ เมื่อคุณเปิดใช้งานการทำคลัสเตอร์เข้าแทนที่ให้ตรวจสอบให้แน่ใจว่าได้เปิดใช้งานตัวเลือก "เซิร์ฟเวอร์การทำงานอัตโนมัติล้มเหลวแบบคลัสเตอร์" สิ่งนี้จำเป็นสำหรับคลัสเตอร์ SQL Server 2008 R2 ใน Windows Server 2012 R2
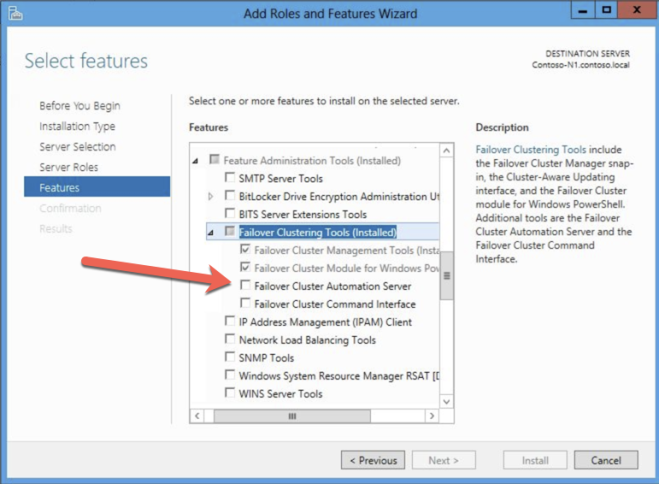
สร้างกลุ่มทรัพยากรและฐานข้อมูลปริมาณ
ตอนนี้เราพร้อมที่จะเริ่มสร้างคลัสเตอร์ ขั้นตอนแรกคือการสร้างคลัสเตอร์ฐาน เนื่องจากวิธีที่ Azure จัดการกับ DHCP เราต้องสร้างคลัสเตอร์โดยใช้ Powershell และไม่ใช่ Cluster UI เราใช้ Powershell เพราะจะให้เราระบุที่อยู่ IP แบบคงที่เป็นส่วนหนึ่งของกระบวนการสร้าง ถ้าเราใช้ UI มันจะเห็นว่า VM ใช้ DHCP และมันจะกำหนดที่อยู่ IP ซ้ำโดยอัตโนมัติ ดังนั้นเพื่อหลีกเลี่ยงสถานการณ์นั้นให้ใช้ Powershell ดังที่แสดงด้านล่าง
ใหม่คลัสเตอร์ชื่อคลัสเตอร์ 1 โหนด sql1, sql2 -StaticAddress 10.0.0.100 -NoStorage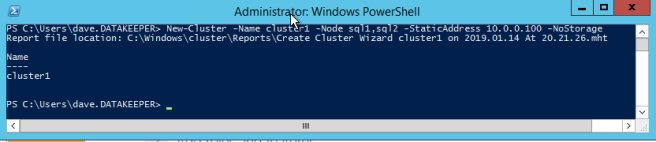
หลังจากสร้างคลัสเตอร์แล้วให้รัน Test-Cluster จำเป็นต้องมีก่อนที่จะติดตั้ง SQL Server
ทดสอบคลัสเตอร์
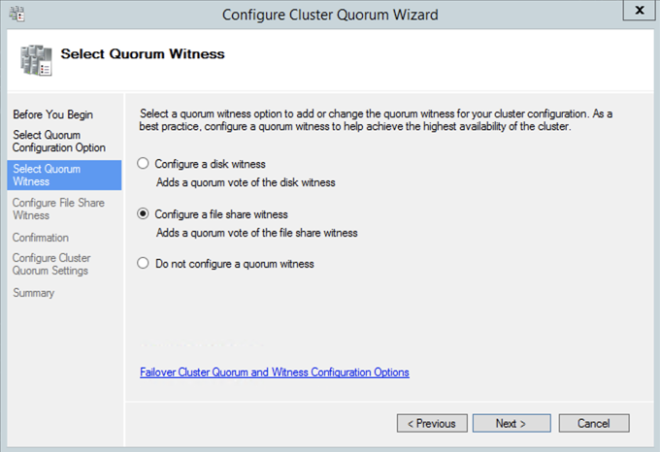
คุณจะได้รับคำเตือนเกี่ยวกับการจัดเก็บและระบบเครือข่าย โชคดีที่คุณสามารถเพิกเฉยสิ่งที่คาดหวังในคลัสเตอร์ SANless ใน Azure อย่างไรก็ตามให้จัดการกับคำเตือนหรือข้อผิดพลาดอื่น ๆ ก่อนดำเนินการ หลังจากสร้างคลัสเตอร์แล้วคุณจะต้องเพิ่ม File Share Witness บนเซิร์ฟเวอร์ที่สามที่เราระบุว่าเป็นพยานการแชร์ไฟล์ให้สร้างการแชร์ไฟล์และให้สิทธิ์ในการอ่าน / เขียนไปยังวัตถุคอมพิวเตอร์คลัสเตอร์ที่เราเพิ่งสร้างขึ้น ในกรณีนี้ $ Cluster1 จะเป็นชื่อของวัตถุคอมพิวเตอร์ที่ต้องการสิทธิ์อ่าน / เขียนที่ระดับความปลอดภัยที่ใช้ร่วมกันและ NTFS เมื่อสร้างการแชร์แล้วคุณสามารถใช้ Configure Cluster Quorum Wizard ดังแสดงด้านล่างเพื่อกำหนดค่าพยานการแชร์ไฟล์




ติดตั้ง DATAKEEPER
สิ่งสำคัญคือต้องรอจนกว่าจะสร้างคลัสเตอร์พื้นฐานก่อนที่เราจะติดตั้ง DataKeeper เนื่องจากการติดตั้ง DataKeeper จะลงทะเบียนประเภท DataKeeper Volume Resource ในการทำคลัสเตอร์ล้มเหลว หากคุณกระโดดปืนและติดตั้ง DataKeeper ไปแล้วก็ไม่เป็นไร เพียงแค่เรียกใช้การตั้งค่าอีกครั้งและเลือกการติดตั้งซ่อม ภาพหน้าจอด้านล่างจะนำคุณไปสู่การติดตั้งพื้นฐาน เริ่มต้นด้วยการรันการตั้งค่า DataKeeper






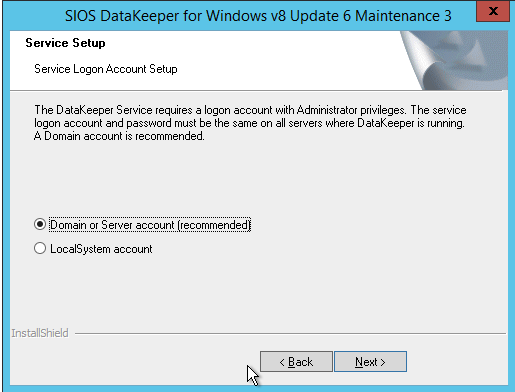
บัญชีที่คุณระบุด้านล่างจะต้องเป็นบัญชีโดเมน ต้องเป็นส่วนหนึ่งของกลุ่ม Local Administrators ในแต่ละโหนดคลัสเตอร์
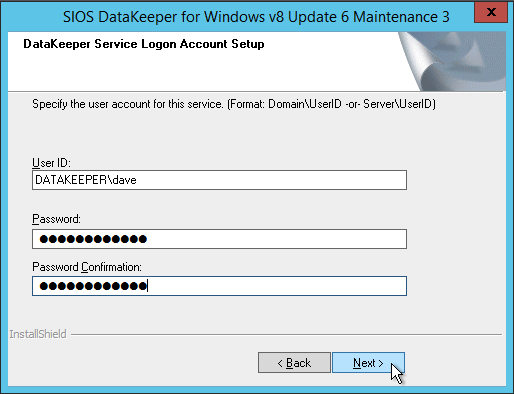
เมื่อนำเสนอกับผู้จัดการคีย์ใบอนุญาต SIOS คุณสามารถเรียกดูคีย์ชั่วคราวของคุณ หรือถ้าคุณมีรหัสถาวรคุณสามารถคัดลอก ID โฮสต์ของระบบและใช้เพื่อขอใบอนุญาตถาวรของคุณ หากคุณจำเป็นต้องรีเฟรชคีย์ SIOS License Key Manager เป็นโปรแกรมที่จะติดตั้งซึ่งคุณสามารถเรียกใช้แยกต่างหากเพื่อเพิ่มคีย์ใหม่

สร้างปริมาณข้อมูล DATAKEEPER
เมื่อติดตั้ง DataKeeper ในแต่ละโหนดแล้วคุณก็พร้อมที่จะสร้าง DataKeeper Volume ทรัพยากรแรกของคุณ ขั้นตอนแรกคือการเปิด DataKeeper UI และเชื่อมต่อกับแต่ละโหนดคลัสเตอร์

หากทุกอย่างทำอย่างถูกต้องรายงานภาพรวมเซิร์ฟเวอร์ควรมีลักษณะเช่นนี้

ตอนนี้คุณสามารถสร้างงานแรกของคุณตามที่แสดงด้านล่าง
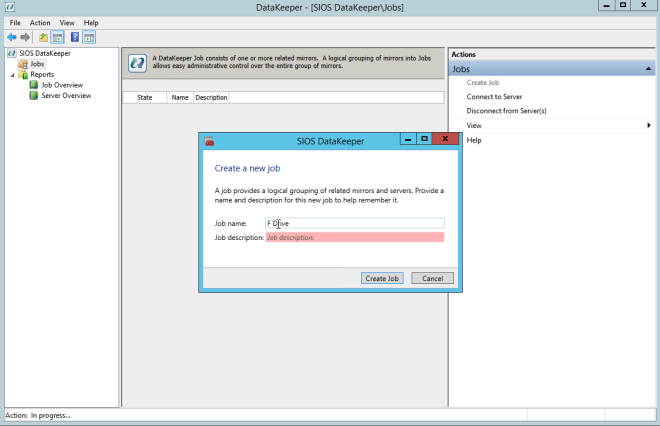


หลังจากที่คุณเลือกแหล่งที่มาและเป้าหมายคุณจะพบกับตัวเลือกต่อไปนี้ สำหรับเป้าหมายในพื้นที่ในภูมิภาคเดียวกันสิ่งเดียวที่คุณต้องเลือกคือซิงโครนัส


เลือกใช่และลงทะเบียนวอลุ่มนี้โดยอัตโนมัติเป็นทรัพยากรคลัสเตอร์

เมื่อคุณทำกระบวนการนี้เสร็จสิ้นให้เปิด Failover Cluster Manager และค้นหาใน Disk คุณควรเห็นทรัพยากร DataKeeper Volume ใน Available Storage เมื่อถึงจุดนี้ WSFC จะถือว่านี่เป็นทรัพยากรดิสก์คลัสเตอร์ปกติ

SLIPSTREAM SP3 ไปยัง SQL 2008 R2 ติดตั้งสื่อ
SQL Server 2008 R2 รองรับ Windows Server 2012 R2 ที่มี SQL Server SP2 หรือใหม่กว่าเท่านั้น น่าเสียดายที่ Microsoft ไม่เคยเผยแพร่สื่อการติดตั้ง SQL Server 2008 R2 ที่มี SP2 หรือ SP3 แต่คุณต้องส่งเซอร์วิสแพ็คลงบนสื่อบันทึกการติดตั้งก่อนทำการติดตั้ง หากคุณพยายามทำการติดตั้งด้วยสื่อบันทึก SQL Server 2008 R2 มาตรฐานคุณจะพบปัญหาทุกประเภท ฉันจำข้อผิดพลาดที่แน่นอนที่คุณจะเห็น แต่ฉันจำได้ว่าพวกเขาไม่ได้ชี้ไปที่ปัญหาที่แท้จริง คุณจะเสียเวลามากพอที่จะคิดออกว่าเกิดอะไรขึ้น ณ วันที่เขียนนี้ Microsoft ไม่มี Windows Server 2012 R2 พร้อม SQL Server 2008 R2 ที่เสนอใน Azure Marketplace ทำใบอนุญาต SQL ของคุณเองถ้าคุณต้องการเรียกใช้ SQL 2008 R2 บน Windows Server 2012 R2 ใน Azure หากพวกเขาเพิ่มอิมเมจนั้นในภายหลังหรือถ้าคุณเลือกที่จะใช้ SQL 2008 R2 บนอิมเมจ Windows Server 2008 R2 คุณต้องถอนการติดตั้งอินสแตนซ์แบบสแตนด์อโลนที่มีอยู่ของ SQL Server ก่อนที่จะดำเนินการต่อ ฉันทำตามคำแนะนำในตัวเลือกที่ 1 ของบทความนี้เพื่อส่ง SP3 บนสื่อการติดตั้ง SQL 2008 R2 ของฉัน แน่นอนว่าคุณจะต้องปรับเปลี่ยนบางสิ่งเนื่องจากบทความนี้อ้างอิง SP2 แทน SP3 ตรวจสอบให้แน่ใจว่าคุณ slipstream SP3 บนสื่อการติดตั้งที่เราจะใช้สำหรับทั้งสองโหนดของคลัสเตอร์ เมื่อเสร็จแล้วให้ทำตามขั้นตอนต่อไป
ติดตั้งเซิร์ฟเวอร์ SQL บนโหนดแรก
การใช้สื่อ SQL Server 2008 R2 กับ SP3 slipstreamed ให้รันการติดตั้งและติดตั้งโหนดแรกของคลัสเตอร์ดังที่แสดงด้านล่าง






หากคุณใช้สิ่งอื่นนอกเหนือจากอินสแตนซ์เริ่มต้นของ SQL Server คุณจะมีขั้นตอนเพิ่มเติมที่ไม่ครอบคลุมในคู่มือนี้ ความแตกต่างที่ใหญ่ที่สุดคือคุณต้องล็อคพอร์ตที่ SQL Server ใช้ตั้งแต่เริ่มต้นอินสแตนซ์ที่มีชื่อของ SQL Server จะไม่ใช้ 1433 เมื่อคุณล็อกพอร์ตคุณจะต้องระบุพอร์ตนั้นแทน 1433 เมื่อใดก็ตามที่เราอ้างอิงพอร์ต 1433 ในคู่มือนี้รวมถึงการตั้งค่าไฟร์วอลล์และการตั้งค่าโหลดบาลานเซอร์
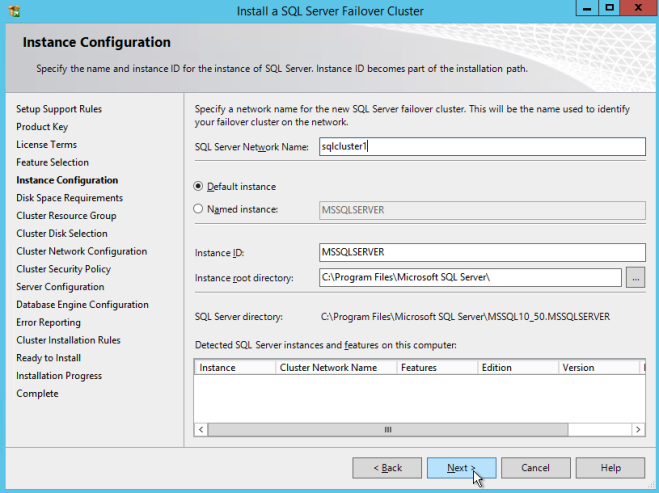


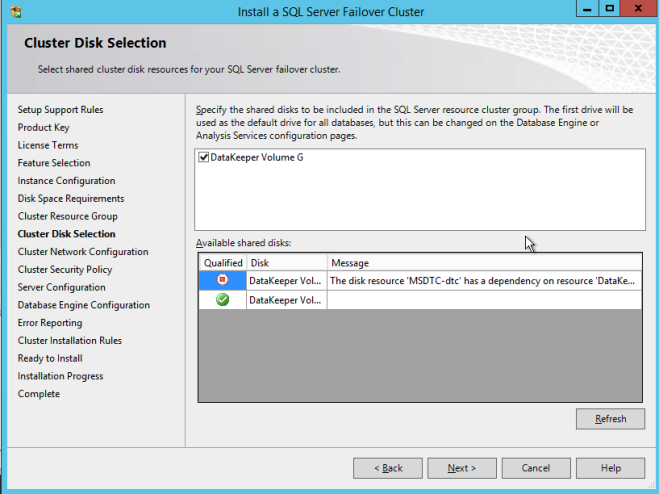
ตรวจสอบให้แน่ใจว่าได้ระบุที่อยู่ IP ใหม่ที่ไม่ได้ใช้งาน นี่คือที่อยู่ IP เดียวกันที่เราจะใช้ในภายหลังเมื่อเรากำหนดค่า Internal Load Balancer ในภายหลัง

ดังที่ฉันได้กล่าวก่อนหน้านี้ SQL Server 2008 R2 ใช้กลุ่มความปลอดภัยของโฆษณา หากคุณยังไม่ได้สร้างพวกเขาไปข้างหน้าและสร้างพวกเขาในขณะนี้ตามที่แสดงด้านล่างก่อนที่จะดำเนินการขั้นตอนต่อไปในการติดตั้ง SQL

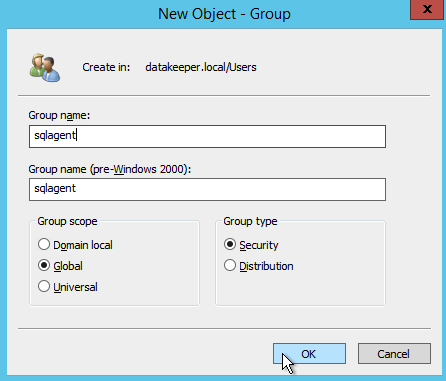
ระบุกลุ่มความปลอดภัยที่คุณสร้างไว้ก่อนหน้า
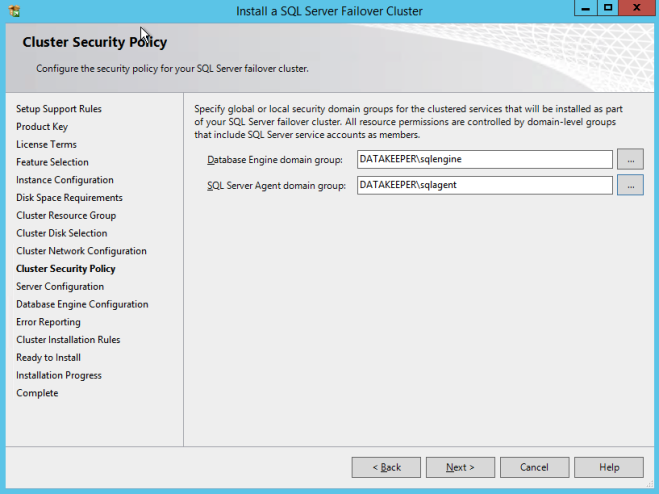
ตรวจสอบให้แน่ใจว่าบัญชีบริการที่คุณระบุเป็นสมาชิกของกลุ่มความปลอดภัยที่เกี่ยวข้อง

ระบุผู้ดูแลระบบ SQL Server ของคุณที่นี่
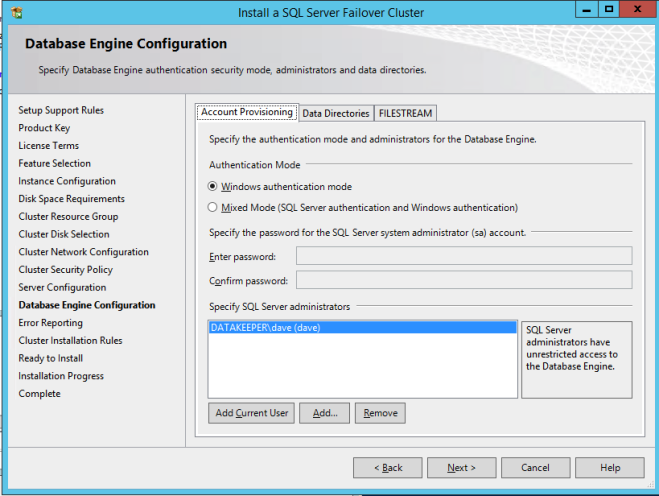

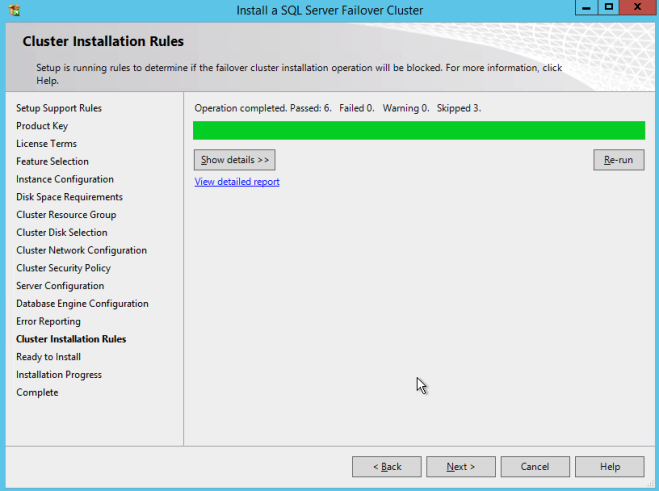
หากทุกอย่างเป็นไปด้วยดีตอนนี้คุณก็พร้อมที่จะติดตั้ง SQL Server บนโหนดที่สองของคลัสเตอร์
ติดตั้งเซิร์ฟเวอร์ SQL บนโหนดที่สอง
หนึ่งโหนดที่สองให้เรียกใช้ SQL Server 2008 R2 ด้วยการติดตั้ง SP3 และเลือกเพิ่มโหนดไปยังอินสแตนซ์ของการทำคลัสเตอร์การเฟลโอเวอร์ของเซิร์ฟเวอร์ SQL

ดำเนินการติดตั้งตามที่แสดงในภาพหน้าจอต่อไปนี้


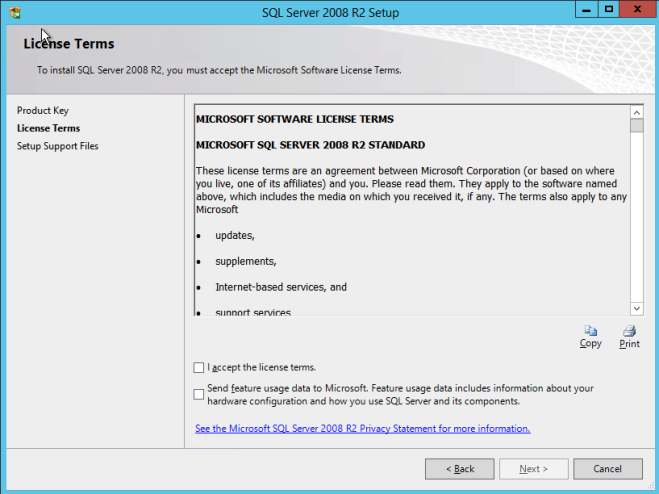

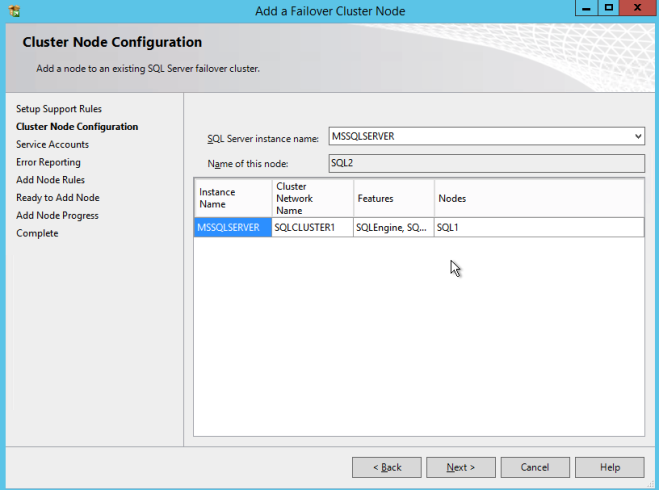



สมมติว่าทุกอย่างเป็นไปด้วยดีตอนนี้คุณควรมีคลัสเตอร์สองโหนดของ SQL Server 2008 R2 ที่ได้รับการกำหนดค่าซึ่งมีลักษณะดังนี้

อย่างไรก็ตามคุณอาจสังเกตเห็นว่าคุณสามารถเชื่อมต่อกับอินสแตนซ์ SQL Server จากโหนดคลัสเตอร์ที่ใช้งานอยู่เท่านั้น ปัญหาคือว่า Azure ไม่รองรับ ARP ฟรีลูกค้าของคุณอาจไม่สามารถเชื่อมต่อโดยตรงกับที่อยู่ IP ของคลัสเตอร์ ไคลเอ็นต์ต้องเชื่อมต่อกับ Azure Load Balancer แทนซึ่งจะเปลี่ยนเส้นทางการเชื่อมต่อไปยังโหนดที่ใช้งานอยู่ ในการทำให้งานนี้มีสองขั้นตอน: สร้าง Load Balancer และแก้ไข IP ของคลัสเตอร์ SQL Server เพื่อตอบสนองต่อโพรบ Load Balancer และใช้ 255net5.255.255 Subnet mask ขั้นตอนเหล่านั้นอธิบายไว้ด้านล่าง
สร้างยอดคงเหลือ AZURE
ฉันจะถือว่าลูกค้าของคุณสามารถสื่อสารโดยตรงไปยังที่อยู่ IP ภายในของคลัสเตอร์ SQL มาก่อนกันเพื่อสร้าง Internal Load Balancer (ILB) ในคู่มือนี้ หากคุณต้องการเปิดเผยอินสแตนซ์ SQL ของคุณบนอินเทอร์เน็ตสาธารณะให้ใช้ Public Load Balancer แทน ในพอร์ทัล Azure ให้สร้าง Load Balancer ใหม่ตามภาพหน้าจอดังที่แสดงด้านล่าง Azure portal UI เปลี่ยนไปอย่างรวดเร็ว เปลี่ยนภาพหน้าจอเหล่านี้ควรให้ข้อมูลมากพอที่จะทำสิ่งที่คุณต้องทำ ฉันจะโทรออกการตั้งค่าที่สำคัญในขณะที่เราไปพร้อมกัน ที่นี่เราสร้าง ILB สิ่งสำคัญที่ควรทราบบนหน้าจอนี้คือคุณต้องเลือก“ การกำหนดที่อยู่ IP แบบคงที่” ระบุที่อยู่ IP เดียวกับที่เราใช้ระหว่างการติดตั้ง SQL Cluster ด้วย เนื่องจากฉันใช้โซนความพร้อมใช้งานฉันจึงเห็นตัวเลือก Zone Redundant หากคุณใช้ชุดความพร้อมใช้งานชุดประสบการณ์ของคุณจะแตกต่างกันเล็กน้อย

ในพูลแบ็คเอนด์ให้แน่ใจว่าได้เลือกอินสแตนซ์ของ SQL Server สองอิน คุณไม่ต้องการเพิ่ม File Share Witness ในพูล
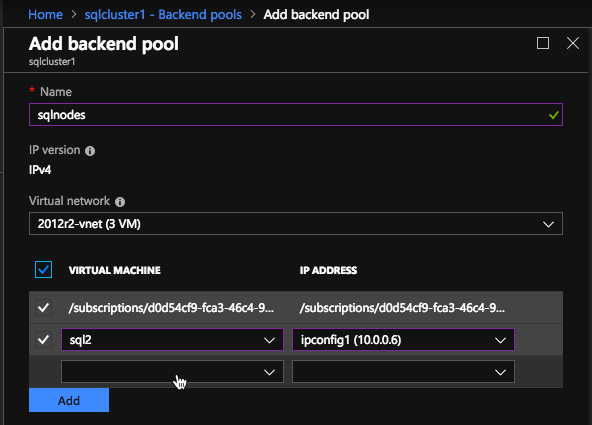
ที่นี่เรากำหนดค่าโพรบสุขภาพ เอกสาร Azure ส่วนใหญ่ใช้พอร์ต 59999 ดังนั้นเราจะยึดกับพอร์ตนั้นสำหรับการกำหนดค่าของเรา

จากนั้นเราจะเพิ่มกฎการปรับสมดุลโหลด ในกรณีของเราเราต้องการเปลี่ยนเส้นทางการรับส่งข้อมูลเซิร์ฟเวอร์ SQL ทั้งหมดไปยังพอร์ต TCP 1433 ของโหนดที่ใช้งานอยู่ สิ่งสำคัญคือคุณต้องเลือก IP แบบลอยตัว (Direct Server Return) เป็น Enabled

เรียกใช้ POWERSHELL SCRIPT เพื่ออัปเดตการเข้าถึงลูกค้า SQL
ตอนนี้เราต้องเรียกใช้สคริปต์ Powershell บนหนึ่งในโหนดคลัสเตอร์เพื่อให้ตัวตรวจสอบการโหลดบาลานซ์ตรวจสอบว่าโหนดใดที่ทำงานอยู่ สคริปต์ยังตั้ง Subnet Mask ของที่อยู่ IP ของ SQL Cluster เป็น 255.255.255.255.255 เพื่อหลีกเลี่ยงข้อขัดแย้งที่อยู่ IP กับ Load Balancer ที่เราเพิ่งสร้างขึ้น
# กำหนดตัวแปร
$ ClusterNetworkName =“”
# ชื่อเครือข่ายคลัสเตอร์ (ใช้ Get-ClusterNetwork บน Windows Server 2012
สูงกว่าเพื่อค้นหาชื่อ)
$ IPResourceName =“”
# ชื่อทรัพยากรที่อยู่ IP
$ ILBIP =“”
# ที่อยู่ IP ของ Internal Load Balancer (ILB) และ SQL Cluster
Import-Module FailoverClusters
# ถ้าคุณใช้ Windows Server 2012 หรือสูงกว่า:
รับ-ClusterResource $ IPResourceName | ตั้ง ClusterParameter
-Multiple @ {ที่อยู่ = $ ILBIP; ProbePort = 59999; SubnetMask = "255.255.255.255";
เครือข่าย = $ ClusterNetworkName; EnableDHCP = 0}
# หากคุณใช้ Windows Server 2008 R2 ให้ใช้สิ่งนี้:
#cluster res $ IPResourceName / priv enabledhcp = 0 ที่อยู่ = $ ILBIP probeport = 59999
SubnetMask = 255.255.255.255นี่คือลักษณะที่เอาต์พุตจะดูเหมือนว่าทำงานอย่างถูกต้อง

คุณอาจสังเกตเห็นว่าจุดสิ้นสุดของสคริปต์นั้นมีบรรทัดของรหัสที่ใส่ความเห็นหากคุณใช้งานบน Windows Server 2008 R2 ใช้ Windows Server 2008 R2 หรือไม่ ตรวจสอบให้แน่ใจว่าคุณเรียกใช้รหัสเฉพาะสำหรับ Windows Server 2008 R2 ที่พรอมต์คำสั่งไม่ใช่ Powershell
ขั้นตอนถัดไป
คุณไม่ใช่คนแรกหากมาถึงจุดนี้และคุณยังไม่สามารถเชื่อมต่อกับคลัสเตอร์ได้จากระยะไกล มีหลายสิ่งหลายอย่างที่อาจผิดพลาดได้ในเรื่องความปลอดภัยโหลดบาลานเซอร์พอร์ต SQL ฯลฯ ฉันเขียนคู่มือนี้เพื่อช่วยแก้ไขปัญหาการเชื่อมต่อ อันที่จริงฉันเจอปัญหาแปลก ๆ ในแง่ของคุณสมบัติ TCP / IP ของ SQL Server ในตัวจัดการการกำหนดค่าเซิร์ฟเวอร์ SQL เมื่อฉันดูคุณสมบัติฉันไม่เห็นที่อยู่ IP ของ SQL Server Cluster เป็นหนึ่งในที่อยู่ที่ฟังอยู่ เช่นฉันต้องเพิ่มมันด้วยตนเอง ฉันไม่แน่ใจว่าเป็นความผิดปกติหรือไม่ แม้ว่ามันจะเป็นปัญหาที่ฉันต้องแก้ไขก่อนที่ฉันจะสามารถเชื่อมต่อกับคลัสเตอร์จากไคลเอนต์ระยะไกลได้ อย่างที่ฉันได้กล่าวไปแล้วการปรับปรุงอื่นที่คุณสามารถทำได้กับการติดตั้งนี้คือการใช้ DataKeeper Non-Mirrored Volume Resource สำหรับ TempDB หากคุณติดตั้งโปรดระวังปัญหาการกำหนดค่าสองประการต่อไปนี้ซึ่งคนทั่วไปมักพบเจอ ปัญหาแรกคือถ้าคุณย้าย tempdb ไปยังโฟลเดอร์บนโหนดที่ 1 คุณต้องแน่ใจว่าได้สร้างโครงสร้างโฟลเดอร์เดียวกันที่แน่นอนบนโหนดที่สอง หากคุณไม่ทำเช่นนั้นเมื่อคุณพยายามล้มเหลว SQL Server จะไม่สามารถออนไลน์ได้เนื่องจากไม่สามารถสร้าง TempDB ได้ ปัญหาที่สองเกิดขึ้นเมื่อใดก็ตามที่คุณเพิ่ม DataKeeper Volume Resource ลงใน SQL Cluster หลังจากสร้างคลัสเตอร์แล้ว คุณต้องเข้าไปในคุณสมบัติของทรัพยากรคลัสเตอร์ของ SQL Server และทำให้มันขึ้นอยู่กับทรัพยากร DataKeeper ปริมาณใหม่ที่คุณเพิ่ม สิ่งนี้เป็นจริงสำหรับวอลุ่ม TempDB และไดรฟ์ข้อมูลอื่น ๆ ที่คุณอาจตัดสินใจที่จะเพิ่มหลังจากสร้างคลัสเตอร์แล้ว หากคุณมีคำถามใด ๆ เกี่ยวกับการกำหนดค่านี้หรือการกำหนดค่าคลัสเตอร์อื่น ๆ โปรดติดต่อฉันที่ Twitter @DaveBerm





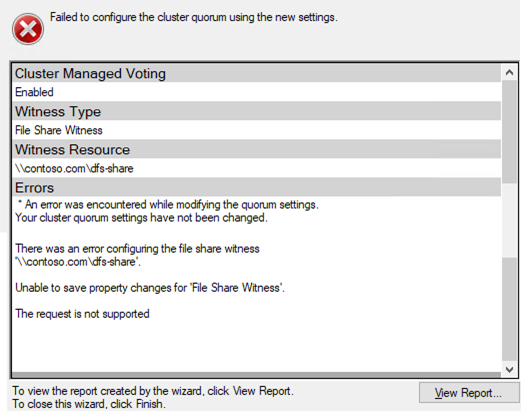 rk Load Balancing Team โพสต์บล็อก" Failover Cluster File Share Witness และ DFS
rk Load Balancing Team โพสต์บล็อก" Failover Cluster File Share Witness และ DFS 

 ถ้าเราดูกราฟนี้เราจะเห็นว่า SIOS DataKeeper มีข้อได้เปรียบที่สำคัญอย่างชัดเจน สำหรับหนึ่ง DataKeeper สนับสนุนช่วงกว้างมากของแพลตฟอร์มไปตลอดทางกลับไปที่ Windows Server 2008 R2 และ SQL Server 2008 R2 โซลูชัน S2D รองรับเฉพาะรุ่นล่าสุดของ Windows และ SQL Server 2016/2017 เท่านั้น นอกจากนี้ S2D ยังต้องการ Windows Datacenter Edition ซึ่งจะช่วยเพิ่มค่าใช้จ่ายในการติดตั้งของคุณได้เป็นอย่างมาก นอกจากนี้ SIOS ยังให้บริการโซ
ถ้าเราดูกราฟนี้เราจะเห็นว่า SIOS DataKeeper มีข้อได้เปรียบที่สำคัญอย่างชัดเจน สำหรับหนึ่ง DataKeeper สนับสนุนช่วงกว้างมากของแพลตฟอร์มไปตลอดทางกลับไปที่ Windows Server 2008 R2 และ SQL Server 2008 R2 โซลูชัน S2D รองรับเฉพาะรุ่นล่าสุดของ Windows และ SQL Server 2016/2017 เท่านั้น นอกจากนี้ S2D ยังต้องการ Windows Datacenter Edition ซึ่งจะช่วยเพิ่มค่าใช้จ่ายในการติดตั้งของคุณได้เป็นอย่างมาก นอกจากนี้ SIOS ยังให้บริการโซ