
วิธีการรวม DataKeeper สำหรับ Linux เข้ากับเครื่องมือสำรองข้อมูลและการจำลองแบบอย่างปลอดภัย
เมื่อใช้ซอฟต์แวร์สำรองข้อมูลหรือจำลองแบบอื่นกับ DataKeeper สำหรับ Linux วัตถุประสงค์ของดาต้าคีปเปอร์คือการจำลองข้อมูลระหว่างเซิร์ฟเวอร์ในคลัสเตอร์ เพื่อให้แน่ใจว่าเซิร์ฟเวอร์ที่เกี่ยวข้องทั้งหมดมีสำเนาข้อมูลล่าสุด ซึ่งเป็นสิ่งสำคัญอย่างยิ่งเมื่อเซิร์ฟเวอร์ประสบปัญหาที่ไม่ได้วางแผนไว้เวลาหยุดทำงาน, และไลฟ์คีปเปอร์สามารถมั่นใจได้ว่าแอปพลิเคชันที่สำคัญมีความพร้อมใช้งานสูงและสามารถรักษาเวลาการทำงานได้ด้วยการใช้ DataKeeper
เมื่อรวม DataKeeper เข้ากับซอฟต์แวร์สำรองข้อมูลหรือการจำลองข้อมูลอื่นๆ สิ่งสำคัญคือต้องยืนยันความเข้ากันได้เพื่อหลีกเลี่ยงความขัดแย้ง ซอฟต์แวร์การจำลองข้อมูลอาจรบกวนการซิงโครไนซ์ข้อมูลของ DataKeeper ซึ่งบางครั้งอาจเกิดจากลำดับการเริ่มต้นของกระบวนการจำลองข้อมูล ขณะเดียวกันก็ตั้งเป้าหมายให้มีประสิทธิภาพสูงสุดเวลาทำงานและความพร้อมใช้งานนั้นเป็นประโยชน์ จึงเป็นสิ่งสำคัญที่จะต้องตรวจสอบว่ามาตรการดังกล่าวจะรักษาคลัสเตอร์ของคุณไว้ในสถานะที่เหมาะสมที่สุดได้หรือไม่
วิธีทดสอบ DataKeeper สำหรับ Linux ด้วยซอฟต์แวร์สำรองข้อมูลและการจำลองข้อมูล
สิ่งสำคัญคือต้องทดสอบความเข้ากันได้ของซอฟต์แวร์จำลองข้อมูลที่ใช้งานควบคู่ไปกับ DataKeeper เพื่อให้มั่นใจถึงประสิทธิภาพการทำงาน ด้านล่างนี้คือรายการสิ่งที่คุณสามารถตรวจสอบเพื่อยืนยันประสิทธิภาพการทำงาน
-
ทดสอบบนคลัสเตอร์ QA
ก่อนใช้ซอฟต์แวร์สำรองข้อมูล/จำลองแบบทั้งสองบนคลัสเตอร์การผลิตของคุณ ให้สร้างสภาพแวดล้อมคลัสเตอร์ QA ด้วย DataKeeper เพื่อเรียกใช้การทดสอบ
คลัสเตอร์ QA มีประโยชน์สำหรับการทดสอบก่อนที่จะนำสิ่งใหม่ๆ เข้ามาในคลัสเตอร์การผลิตของคุณ การทำเช่นนี้จะช่วยหลีกเลี่ยงปัญหาที่อาจเกิดขึ้นกับคลัสเตอร์การผลิตของคุณ โดยการตรวจสอบและ/หรือแก้ไขปัญหาใดๆ ที่เกิดขึ้นกับคลัสเตอร์ QA ของคุณอย่างเชิงรุก
-
ทำการทดสอบการทำงานขั้นพื้นฐานให้เสร็จสมบูรณ์
ควรทำการทดสอบพื้นฐานสองสามข้อโดยใช้ DataKeeper เป็นซอฟต์แวร์จำลองข้อมูลเพียงตัวเดียวที่ติดตั้งไว้ นี่คือการตรวจสอบความถูกต้องก่อนที่จะดำเนินการกับซอฟต์แวร์อื่นต่อไป
การทดสอบพื้นฐานควรรวมถึงการทดสอบเพื่อให้การสลับและเฟลโอเวอร์สำเร็จ ดูขั้นตอนต่างๆ เพื่อยืนยันว่าการสลับและเฟลโอเวอร์สำเร็จได้ที่ลิงก์ด้านล่าง
https://docs.us.sios.com/spslinux/9.9.1/en/topic/การทดสอบลำดับชั้นทรัพยากรผู้ดูแลข้อมูลของคุณ
-
ทำการทดสอบการทำงานขั้นพื้นฐานกับซอฟต์แวร์อื่น ๆ
รันการทดสอบแบบเดียวกันที่กล่าวไว้ข้างต้นในขณะที่ซอฟต์แวร์กำลังสำรอง/จำลองข้อมูลของคุณ และหลังจากที่ซอฟต์แวร์ทำการสำรอง/จำลองข้อมูลของคุณเสร็จสิ้นแล้ว
ในการใช้ซอฟต์แวร์ร่วมกับ DataKeeper สิ่งสำคัญคือต้องผ่านการทดสอบการทำงานทั้งหมดเหล่านี้
การใช้ทรัพยากร GenApp เพื่อจัดการกระบวนการสำรองข้อมูลและการจำลองข้อมูลด้วย DataKeeper สำหรับ Linux
หากการทดสอบให้ผลลัพธ์ที่ไม่สำเร็จ คุณสามารถสร้างแอปพลิเคชันทั่วไป (GenApp)เพื่อเริ่มและหยุดกระบวนการที่เกี่ยวข้องในระหว่างการสลับ
- GenApp สามารถใช้ในลำดับชั้นเพื่อเรียกคืนและลบกระบวนการที่ใช้โดยซอฟต์แวร์จำลองเพื่อจัดการลำดับการทำงานของซอฟต์แวร์
- ลำดับชั้นเป็นตัวกำหนดความสัมพันธ์ระหว่างทรัพยากร ทรัพยากรระดับบนสุดจะพึ่งพาทรัพยากรระดับล่างสุดเพื่อสร้างความสัมพันธ์แบบพึ่งพา เมื่อลำดับชั้นถูกยกเลิก LifeKeeper จะใช้แนวทางจากบนลงล่าง โดยลบทรัพยากรระดับบนสุดออกก่อนทรัพยากรระดับล่างสุด เมื่อมีการเรียกคืนทรัพยากร LifeKeeper จะใช้แนวทางจากล่างขึ้นบนเพื่อเรียกคืนทรัพยากรระดับล่างสุดก่อนการเรียกคืนทรัพยากรระดับบนสุด
ด้วยความเข้าใจนี้ จะสร้าง GenApps สองชุด ชุดหนึ่งเป็นทรัพยากรระดับบนสุด และอีกชุดหนึ่งเป็นทรัพยากรระดับล่างสุด การกำหนดค่านี้ช่วยให้มั่นใจได้ว่าเมื่อลำดับชั้นเริ่มทำงาน GenApp ระดับล่างสุดจะหยุดกระบวนการ และ GenApp ระดับบนสุดจะเริ่มต้นกระบวนการนั้นเอง เมื่อลำดับชั้นถูกลบออก สิ่งเดียวที่ทำได้คือให้ทรัพยากรระดับล่างสุดหยุดกระบวนการ
- อ่านเพิ่มเติมเกี่ยวกับการสร้าง GenApp ได้จากลิงค์ด้านล่าง
https://docs.us.sios.com/spslinux/9.9.1/en/topic/การสร้างลำดับชั้นทรัพยากรแอปพลิเคชันทั่วไป
การรับรองความเข้ากันได้ของคลัสเตอร์ DataKeeper และป้องกันการหยุดทำงาน
ท้ายที่สุดแล้ว การทดสอบและการตรวจสอบความถูกต้องเป็นสิ่งสำคัญก่อนที่จะนำซอฟต์แวร์สำรองข้อมูลหรือการจำลองข้อมูลเพิ่มเติมเข้าสู่คลัสเตอร์ DataKeeper ของคุณ ขั้นตอนเหล่านี้มีจุดมุ่งหมายเพื่อหลีกเลี่ยงการหยุดทำงานโดยให้รายการสิ่งที่ต้องทำให้เสร็จสมบูรณ์เพื่อให้แน่ใจว่าการกำหนดค่าของคุณเป็นไปตามลำดับก่อนที่จะนำเข้าสู่สภาพแวดล้อมการใช้งานจริง ก่อนที่จะรวมซอฟต์แวร์สำรองข้อมูลหรือการจำลองข้อมูลเพิ่มเติมเข้ากับคลัสเตอร์ Linux DataKeeper ของคุณ การทดสอบและการตรวจสอบความถูกต้องอย่างละเอียดเป็นสิ่งสำคัญ การทำตามขั้นตอนเหล่านี้ให้เสร็จสมบูรณ์จะช่วยให้มั่นใจได้ว่าการกำหนดค่าของคุณได้รับการตั้งค่าอย่างถูกต้องและช่วยป้องกันการหยุดทำงานเมื่อนำเข้าสู่สภาพแวดล้อมการใช้งานจริงของคุณ
พร้อมที่จะดูว่า SIOS จะช่วยคุณลดความซับซ้อนของความพร้อมใช้งานสูงและรับรองการสำรองข้อมูลและการจำลองแบบที่ราบรื่นด้วย DataKeeper สำหรับ Linux ได้อย่างไรหรือยังขอสาธิตวันนี้
ผู้เขียน: Alexus Gore วิศวกรซอฟต์แวร์ประสบการณ์ลูกค้า
พิมพ์ซ้ำโดยได้รับอนุญาตจากSIOS


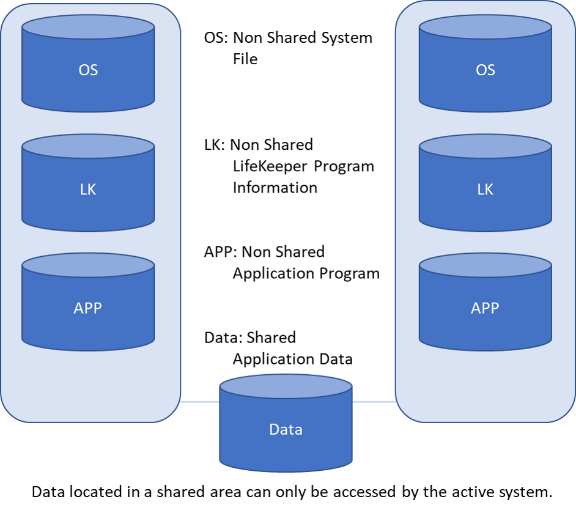
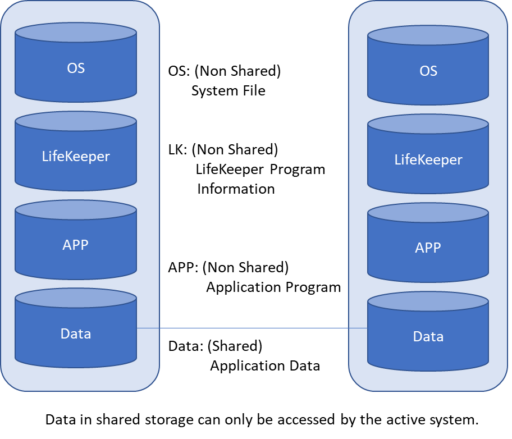
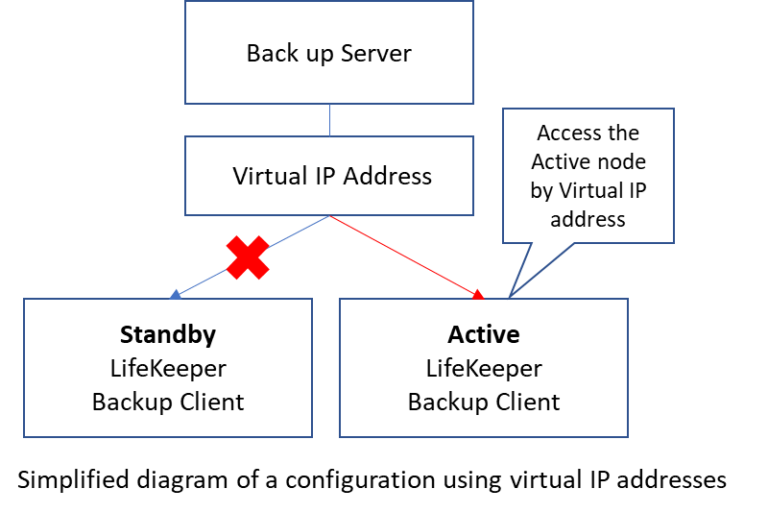
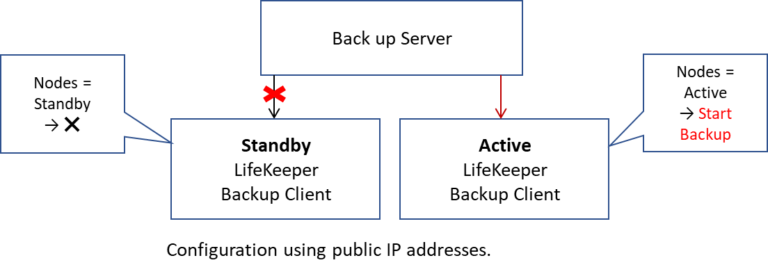




 r Failover Cluster แบบหลายอินสแตนซ์ใน Azure บัญชีเก็บข้อมูลระบบคลาวด์ควรได้รับการกำหนดค่าที่เก็บข้อมูลแบบ redundant Storage ตามปกติ (LRS) [/ คำอธิบาย]
r Failover Cluster แบบหลายอินสแตนซ์ใน Azure บัญชีเก็บข้อมูลระบบคลาวด์ควรได้รับการกำหนดค่าที่เก็บข้อมูลแบบ redundant Storage ตามปกติ (LRS) [/ คำอธิบาย]