循序渐进:如何在Azure中配置SQL Server 2008 R2故障转移群集实例
如果您需要指南在Azure中配置SQL Server故障转移群集实例,您可能仍在使用SQL Server 2008/2008 R2。并且,如果将SQL Server 2008/2008 R2移动到Azure,则希望利用Microsoft提供的扩展安全更新。我之前在这篇博文中写过关于这个主题的文章。您可能想知道如何在迁移到Azure后确保SQL Server故障转移群集实例保持高可用性。今天,大多数人将业务关键型SQL Server 2008/2008 R2配置为其数据中心中的群集实例(SQL Server FCI)。在查看Azure时,您可能已经意识到由于缺少共享存储,您似乎无法将SQL Server FCI引入Azure云。然而,由于SIOS DataKeeper,情况并非如此。 SIOS DataKeeper使您能够在Azure,AWS,Google Cloud或其他任何无法使用共享存储的位置或您希望配置共享存储无意义的多站点群集的位置构建SQL Server故障转移群集实例。自1999年以来,DataKeeper一直在为Windows和Linux启用SANless集群。Microsoft在其文档中记录了SIOS DataKeeper在SQL Server故障转移群集实例中的使用:Azure虚拟机中SQL Server的高可用性和灾难恢复。 我之前写过有关SQL Server FCI在Azure中运行的文章,但我从未发布过特定于SQL Server 2008/2008 R2的循序渐进指南。好消息是它在SQL 2008/2008 R2和SQL 2012/2014/2016/2017以及即将发布的2019年一样好用。此外,无论Windows Server(2008/2012/2016/2019)或SQL Server(2008/2012/2014/2016/2017)的版本如何,配置过程都足够相似,本指南应足以让您完成任何操作配置。如果我的任何指南都没有涵盖您的SQL或Windows风格,请不要害怕跳进并构建SQL Server FCI并参考本指南,我想您会发现任何差异,如果您遇到困难在Twitter @daveberm上与我联系,我很乐意帮助你。本指南使用SQL Server 2008 R2和Windows Server 2012 R2。截至撰写本文时,我没有在Windows Server 2012 R2上看到SQL 2008 R2的Azure Marketplace映像,因此我不得不手动下载并安装SQL 2008 R2。我个人更喜欢这种组合,但如果您需要使用Windows Server 2008 R2或Windows 212,那就没问题了。如果您使用Windows Server 2008 R2,请不要忘记安装适用于Windows Server 2008 R2 SP1的kb3125574Convenience汇总更新。或者,如果您遇到Server 2012(而不是R2),则需要kb2854082中的修补程序。 不要被这篇文章所愚弄,该文章说你必须在SQL Server 2008 R2实例上安装kb2854082。如果您开始搜索Windows Server 2008 R2的更新,您会发现只有Server 2012的版本可用。Server 2008 R2的特定修补程序包含在Windows Server 2008 R2 SP1的汇总便捷汇总更新中。
提供无效的实例
我不会在这里详细介绍一些屏幕截图,特别是因为Azure门户UI经常会经常更改,所以我拍摄的任何屏幕截图都会很快变得陈旧。相反,我将只介绍您应该了解的重要主题。
故障域或可用区域?
为了确保您的SQL Server实例具有高可用性,您必须确保您的群集节点位于不同的故障域(FD)或不同的可用区(AZ)中。您的实例不仅需要驻留在不同的FD或AZ中,而且您的文件共享见证(见下文)也需要驻留在与您的群集节点所在的FD或AZ不同的FD或AZ中。这是我的看法。AZ是最新的Azure功能,但到目前为止它们仅在少数几个地区得到支持。AZ给你一个更高的SLA(99.99%)然后FD(99.95%),并保护你免受我在我的Azure Outage Post-Mortem后期描述的那种云中断。 如果您可以在支持AZ的区域中部署,那么我建议您使用AZ。在本指南中,我使用了AZ,当您进入有关配置负载均衡器的部分时,您会看到这些AZ。但是,如果使用FD,则所有内容都将完全相同,但负载均衡器配置将引用可用性集而不是可用区。
什么是文件分享证明你问的?
Windows Server故障转移群集(WSFC)要求您配置“见证”以确保故障转移正常运行,而无需详细说明。Windows Server Failover Clustering支持三种见证:磁盘,文件共享,云。由于我们在Azure中,因此无法使用磁盘见证。Cloud Witness仅适用于Windows Server 2016及更高版本,因此我们可以使用文件共享见证。如果您想了解有关群集仲裁的更多信息,请查看Microsoft Press博客上的帖子,来自MVP:了解Windows Server 2012 R2中的Windows Server故障转移群集仲裁
添加存储到您的SQL Server实例
在配置SQL Server实例时,您需要为每个实例添加其他磁盘。最低限度,您需要一个磁盘用于SQL数据和日志文件,一个磁盘用于Tempdb。在云中运行时,是否应该为日志和数据文件设置单独的磁盘有些争议。在后端,存储全部来自同一个地方,您的实例大小限制了您的总IOPS。在我看来,分离日志和数据文件确实没有任何价值,因为您无法确保它们在两个物理磁盘集上运行。我会留给你决定,但我把日志和数据全部放在同一卷上。通常,SQL Server 2008 R2 FCI会要求您将tempdb放在群集磁盘上。但是,SIOS DataKeeper有一个非常好的功能,称为DataKeeper非镜像卷资源。本指南不包括将tempdb移动到此非镜像卷资源,但为了获得最佳性能,您应该执行此操作。真的没有理由复制tempdb,因为它无论如何都是在故障转移时重新创建的。就存储而言,您可以使用任何存储类型,但必要时尽可能使用托管磁盘。确保群集中的每个节点都具有相同的存储配置。启动实例后,您需要附加这些磁盘并将它们格式化为NTFS。确保每个实例使用相同的驱动器号。
联网
这不是一个硬性要求,但如果可能的话,使用支持加速网络的实例大小。此外,请确保在Azure门户中编辑网络接口,以便您的实例使用静态IP地址。要使群集正常工作,您需要确保更新DNS服务器的设置,使其指向Windows AD / DNS服务器而不仅仅是某个公共DNS服务器。
安全
默认情况下,同一虚拟网络中的节点之间的通信是敞开的,但如果您已锁定Azure安全组,则需要知道必须在群集节点之间打开哪些端口并调整安全组。根据我的经验,在Azure中构建群集时遇到的几乎所有问题都是由阻塞的端口引起的。DataKeeper有一些端口需要在群集实例之间打开。这些端口如下:UDP:137,138 TCP:139,445,9999,以及10000到10025范围内的端口故障转移群集有自己的一组端口要求,我甚至不会尝试在此处进行记录。这篇文章似乎涵盖了这一点。 http://dsfnet.blogspot.com/2013/04/windows-server-clustering-sql-server.html此外,稍后描述的Load Balancer将使用必须允许每个节点上的入站流量的探测端口。本指南中常用和描述的端口是59999。最后,如果您希望您的客户端能够访问您的SQL Server实例,您需要确保您的SQL Server端口是打开的,默认情况下是1433。请记住,Windows防火墙或Azure安全组可以阻止这些端口,因此请务必检查这两个端口以确保它们可访问。
加入域名
SQL Server 2008 R2 FCI的要求是实例必须驻留在同一Windows Server域中。因此,如果您还没有这样做,请确保已将实例加入Windows域
本地服务帐户
安装DataKeeper时,它会要求您提供服务帐户。您必须创建域用户帐户,然后将该用户帐户添加到每个节点上的本地管理员组。在DataKeeper安装期间询问时,请将该帐户指定为DataKeeper服务帐户。注意 – 不要安装DataKeeper!
域名全球安全组织
安装SQL 2008 R2时,系统会要求您指定两个全局域安全组。您可能希望展望SQL安装说明并立即创建这些组。此外,创建域用户帐户并将它们放在每个安全帐户中。您将指定此帐户作为SQL Server群集安装的一部分。
其他预先要求
您必须在两个群集实例的每个实例上启用故障转移群集和.Net 3.5。启用故障转移群集时,还要确保启用可选的“故障转移群集自动化服务器”。 这是Windows Server 2012 R2中的SQL Server 2008 R2群集所必需的。
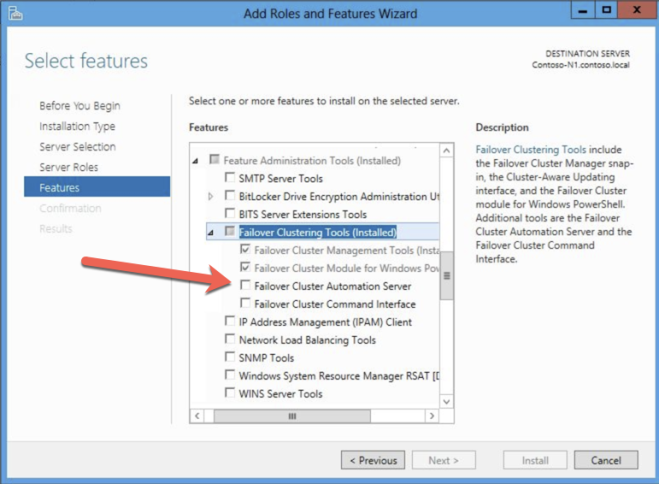
创建集群和DATAKEEPER卷资源
我们现在准备开始构建集群。第一步是创建基本群集。由于Azure处理DHCP的方式,我们必须使用Powershell创建集群,而不是集群UI。我们使用Powershell,因为它允许我们在创建过程中指定静态IP地址。如果我们使用UI,则会看到VM使用DHCP并且它将自动分配重复的IP地址。因此,为了避免这种情况,让我们使用Powershell,如下所示。
New-Cluster -Name cluster1 -Node sql1,sql2 -StaticAddress 10.0.0.100 -NoStorage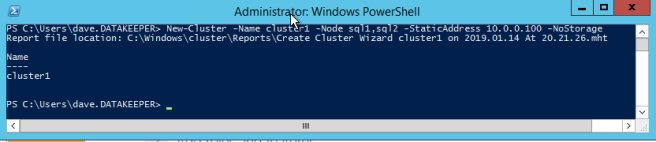
群集创建后,运行Test-Cluster。这在SQL Server安装之前是必需的。
测试群集
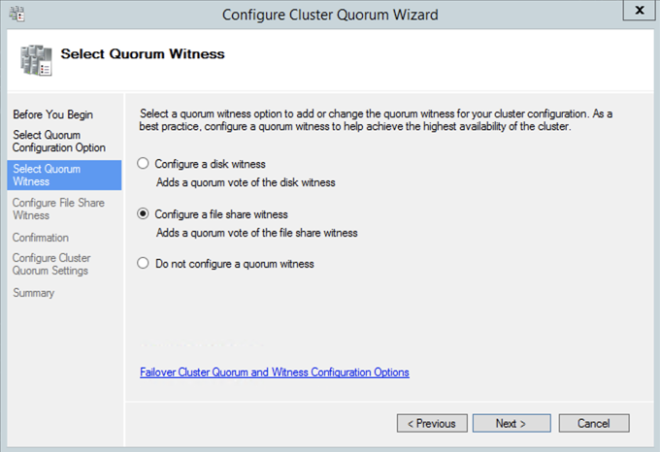
您将收到有关存储和网络的警告。值得庆幸的是,您可以忽略Azure中SANless群集中的预期。但是,请在继续之前解决任何其他警告或错误。创建群集后,您需要添加文件共享见证。在我们指定为文件共享见证的第三台服务器上,创建一个文件共享,并为我们刚刚创建的集群计算机对象提供读/写权限。在这种情况下,$ Cluster1将是在共享和NTFS安全级别都需要读/写权限的计算机对象的名称。创建共享后,您可以使用配置群集仲裁向导(如下所示)配置文件共享见证。




安装DATAKEEPER
在安装DataKeeper之前等待创建基本集群非常重要,因为DataKeeper安装会在故障转移群集中注册DataKeeper Volume Resource类型。如果你已经跳过枪并安装了DataKeeper就可以了。只需再次运行安装程序并选择“修复安装”。下面的屏幕截图将引导您完成基本安装。首先运行DataKeeper安装程序。






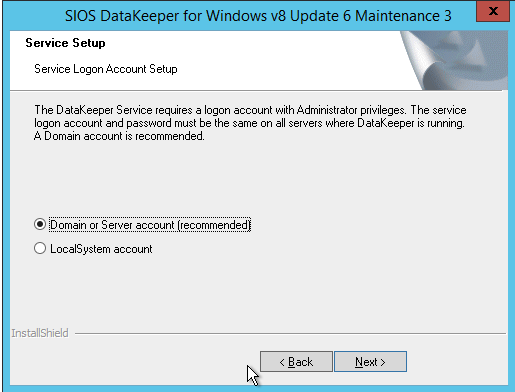
您在下面指定的帐户必须是域帐户。它必须是每个群集节点上的Local Administrators组的一部分。
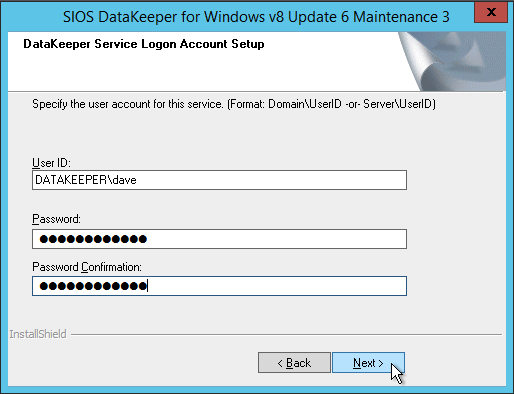
当提供SIOS许可证密钥管理器时,您可以浏览到临时密钥。或者,如果您有永久密钥,则可以复制系统主机ID并使用它来申请永久许可证。如果您需要刷新密钥,SIOS许可证密钥管理器是一个将安装的程序,您可以单独运行以添加新密钥。

创建DATAKEEPER VOLUME RESOURCE
在每个节点上安装DataKeeper后,您就可以创建第一个DataKeeper卷资源了。第一步是打开DataKeeper UI并连接到每个群集节点。

如果一切都正确完成,服务器概述报告应该如下所示。

您现在可以创建第一个Job,如下所示。
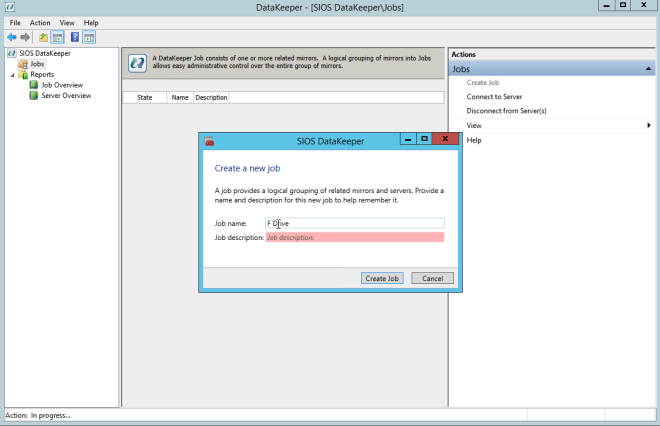


选择源和目标后,您将看到以下选项。对于同一区域中的本地目标,您唯一需要选择的是同步。


选择“是”并将此卷自动注册为群集资源。

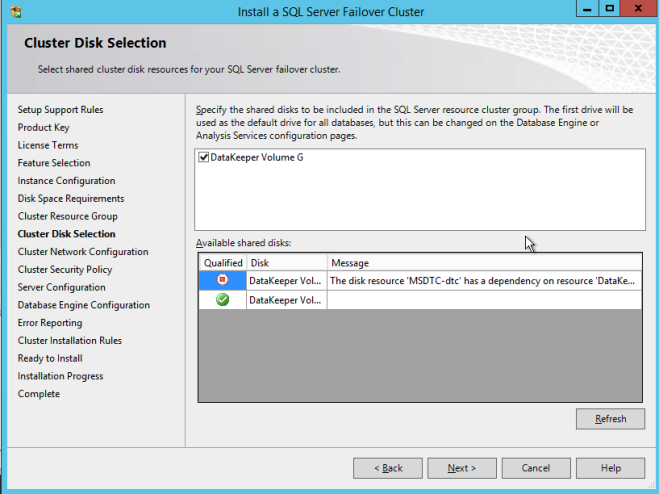
完成此过程后,打开故障转移群集管理器并查看磁盘。您应该在Available Storage中看到DataKeeper Volume资源。此时,WSFC将其视为普通的群集磁盘资源。

SLIPSTREAM SP3 ONTO SQL 2008 R2安装媒体
SQL Server 2008 R2仅在带有SQL Server SP2或更高版本的Windows Server 2012 R2上受支持。不幸的是,Microsoft从未发布过包含SP2或SP3的SQL Server 2008 R2安装介质。相反,您必须在安装之前将Service Pack整合到安装介质上。如果您尝试使用标准SQL Server 2008 R2媒体进行安装,则会遇到各种问题。我不记得你会看到的确切错误。但我记得他们并没有真正指出确切的问题。 你会浪费很多时间来弄清楚出了什么问题。截至本文撰写之日,Microsoft在Azure Marketplace中没有带有SQL Server 2008 R2产品的Windows Server 2012 R2。如果要在Azure中的Windows Server 2012 R2上运行SQL 2008 R2,请带上自己的SQL许可证。如果他们稍后添加该图像,或者您选择在Windows Server 2008 R2映像上使用SQL 2008 R2,则必须先卸载现有的SQL Server独立实例,然后再继续。我按照本文选项1中的指导将SP3整合到我的SQL 2008 R2安装介质上。您当然必须调整一些内容,因为本文引用的是SP2而不是SP3。确保在我们将用于群集的两个节点的安装介质上整合SP3。完成后,继续下一步。
在第一个节点上安装SQL SERVER
使用带有SP3的SQL Server 2008 R2媒体进行整理,运行安装程序并安装群集的第一个节点,如下所示。


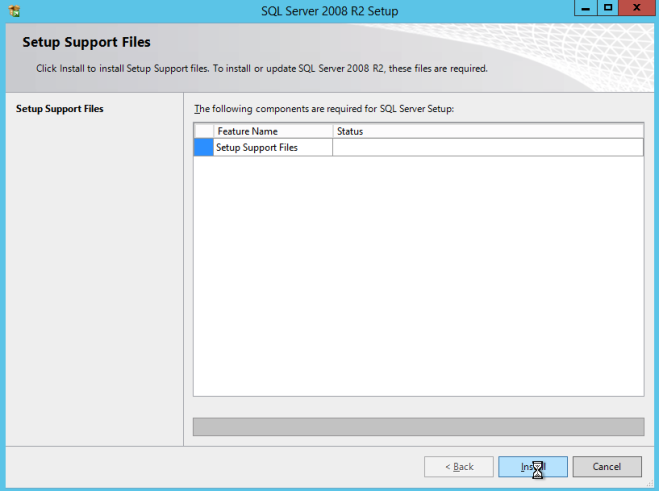




如果您使用除SQL Server的默认实例以外的任何其他内容,则本指南中将介绍一些其他步骤。最大的区别是您必须锁定SQL Server使用的端口,因为默认情况下SQL Server的命名实例不使用1433。一旦锁定端口,每当我们引用本指南中的端口1433时,您还需要指定该端口而不是1433,包括防火墙设置和Load Balancer设置。
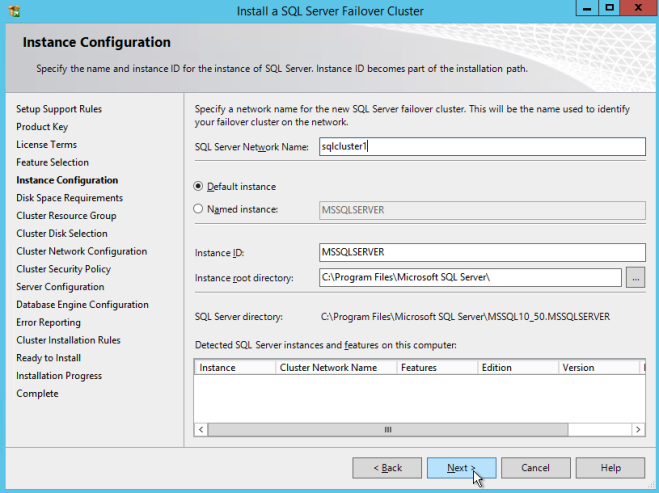


这里确保指定一个未使用的新IP地址。这是我们稍后在配置内部负载均衡器时将使用的相同IP地址。

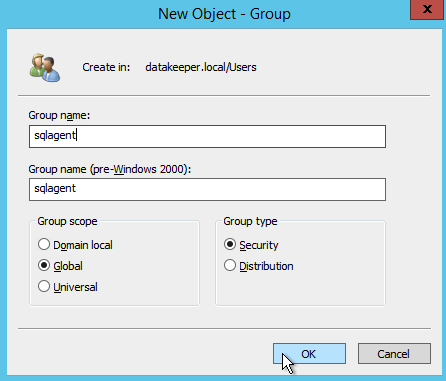
正如我之前提到的,SQL Server 2008 R2使用AD安全组。如果您还没有创建它们,请继续创建它们,如下图所示,然后再继续执行SQL安装中的下一步

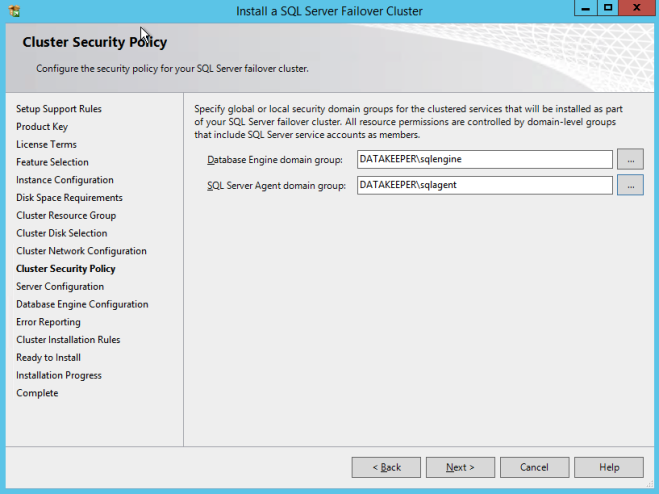
指定先前创建的安全组。
确保您指定的服务帐户是关联的安全组的成员。

在此处指定SQL Server管理员。
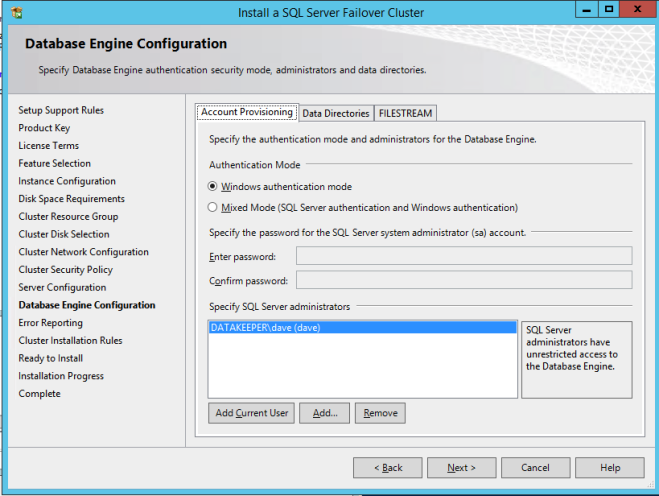

如果一切顺利,您现在可以在群集的第二个节点上安装SQL Server。
在第二个节点上安装SQL SERVER
在第二个节点中,运行带有SP3安装的SQL Server 2008 R2,然后选择“将节点添加到SQL Server故障转移群集实例”。

继续安装,如以下屏幕截图所示。



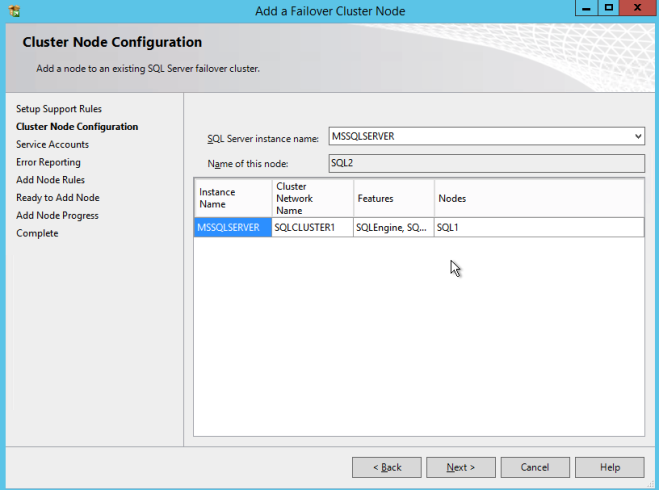



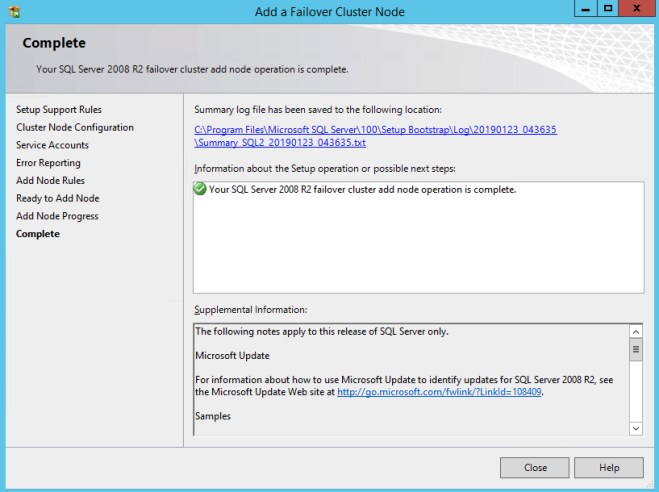
假设一切顺利,您现在应该配置一个双节点SQL Server 2008 R2群集,其外观如下所示。

但是,您可能会注意到只能从活动群集节点连接到SQL Server实例。问题是Azure不支持免费ARP。您的客户端可能无法直接连接到群集IP地址。相反,客户端必须连接到Azure负载均衡器,该负载均衡器将连接重定向到活动节点。要使此工作有两个步骤:创建负载均衡器并修复SQL Server群集IP以响应负载均衡器探测并使用255.255.255.255子网掩码。这些步骤如下所述。
创建AZURE负载平衡器
我将假设您的客户端可以直接与SQL群集的内部IP地址通信。让我们继续在本指南中创建一个内部负载均衡器(ILB)。如果需要在公共Internet上公开SQL实例,请改用Public Load Balancer。在Azure门户中,按照屏幕截图创建一个新的Load Balancer,如下所示。Azure门户UI快速变化。但是这些屏幕截图应该为您提供足够的信息来完成您需要做的事情。随着我们的进展,我会召集重要的设置。在这里,我们创建了ILB。在此屏幕上需要注意的重要事项是您必须选择“静态IP地址分配”。指定我们在SQL群集安装期间使用的相同IP地址。由于我使用了可用区,我将Zone Redundant视为一种选择。如果您使用可用性集,您的体验将略有不同。

在后端池中,请确保选择两个SQL Server实例。您不希望在池中添加文件共享见证。
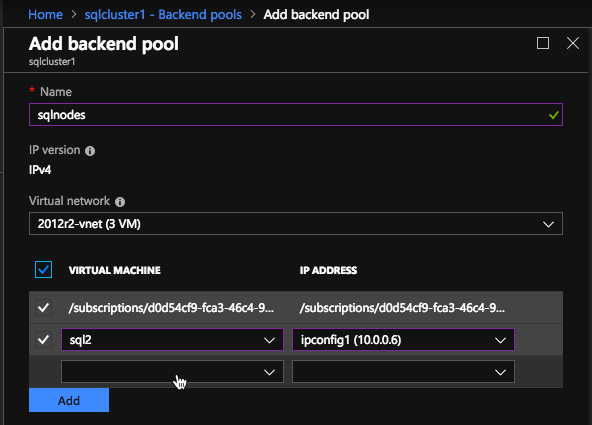
在这里,我们配置健康探测器。大多数Azure文档使用端口59999,因此我们将坚持使用该端口进行配置。

然后我们将添加一个负载平衡规则。在我们的示例中,我们希望将所有SQL Server流量重定向到活动节点的TCP端口1433。选择浮动IP(直接服务器返回)为已启用也很重要。

运行POWERSHELL脚本以更新SQL客户端访问点
现在,我们必须在其中一个群集节点上运行Powershell脚本,以允许Load Balancer Probe检测哪个节点处于活动状态。该脚本还将SQL群集IP地址的子网掩码设置为255.255.255.255.255,以避免与我们刚刚创建的Load Balancer发生IP地址冲突。
#定义变量
$ ClusterNetworkName =“”
#群集网络名称(在Windows Server 2012上使用Get-ClusterNetwork)
更高的找到名字)
$ IPResourceName =“”
#IP地址资源名称
$ ILBIP =“”
#内部负载均衡器(ILB)和SQL群集的IP地址
导入模块FailoverClusters
#如果您使用的是Windows Server 2012或更高版本:
Get-ClusterResource $ IPResourceName | SET-ClusterParameter
-Multiple @ {Address = $ ILBIP; ProbePort = 59999; SubnetMask =“255.255.255.255”;
网络= $ ClusterNetworkName; EnableDHCP时= 0}
#如果您使用的是Windows Server 2008 R2,请使用以下命令:
#cluster res $ IPResourceName / priv enabledhcp = 0 address = $ ILBIP probeport = 59999
子网掩码= 255.255.255.255如果正确运行,这就是输出的样子。

您可能会注意到,如果您在Windows Server 2008 R2上运行,该脚本的末尾会有一行注释代码。运行Windows Server 2008 R2?确保在命令提示符下运行特定于Windows Server 2008 R2的代码,它不是Powershell。
下一步
如果你达到这一点,你不是第一个,你仍然无法远程连接到群集。在安全性,负载均衡器,SQL端口等方面存在许多可能出错的问题。我编写本指南以帮助解决连接问题。事实上,我在SQL Server配置管理器中的SQL Server TCP / IP属性方面遇到了一些奇怪的问题。当我查看属性时,我没有看到SQL Server群集IP地址作为其正在侦听的地址之一。因此我必须手动添加它。我不确定这是不是异常。虽然在我从远程客户端连接到群集之前,我必须先解决这个问题。正如我之前提到的,您可以对此安装进行的另一项改进是为TempDB使用DataKeeper非镜像卷资源。如果你设置它,请注意人们经常遇到的以下两个配置问题。第一个问题是如果将tempdb移动到第一个节点上的文件夹,则必须确保在第二个节点上创建完全相同的文件夹结构。如果不这样做,当您尝试进行故障转移时,SQL Server将无法联机,因为它无法创建TempDB。第二个问题发生在创建集群后,将其他DataKeeper卷资源添加到SQL集群的任何时候。您必须进入SQL Server群集资源的属性,并使其依赖于您添加的新DataKeeper Volume资源。对于TempDB卷和您在创建集群后可能决定添加的任何其他卷都是如此。如果您对此配置或任何其他群集配置有任何疑问,请随时通过Twitter @DaveBerm与我联系。






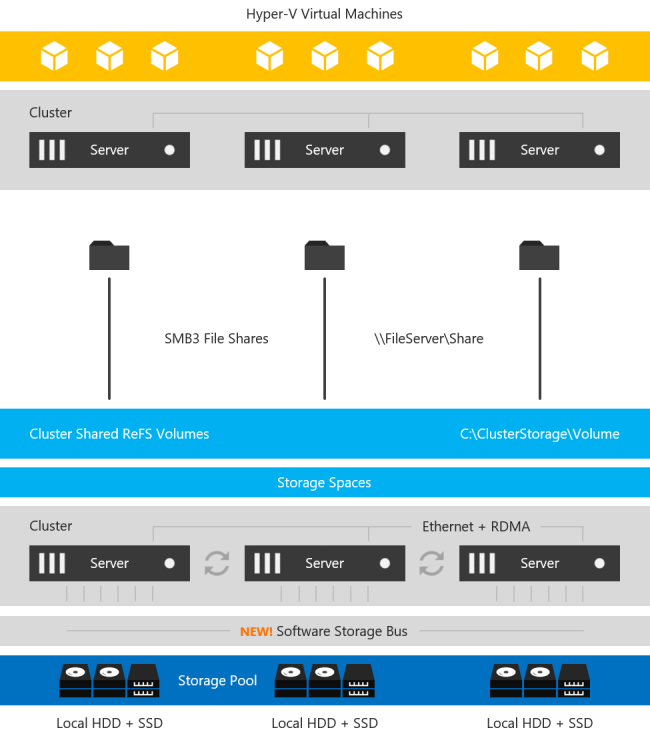

 如果我们浏览此图表,我们会发现SIOS DataKeeper显然具有一些显着优势。例如,DataKeeper支持更广泛的平台,一直回到Windows Server 2008 R2和SQL Server 2008 R2。S2D解决方案仅支持最新版本的Windows和SQL Server 2016/2017。S2D还需要Windows的Datacenter Edition,这会显着增加部署成本。此外,SIOS还为Linux上
如果我们浏览此图表,我们会发现SIOS DataKeeper显然具有一些显着优势。例如,DataKeeper支持更广泛的平台,一直回到Windows Server 2008 R2和SQL Server 2008 R2。S2D解决方案仅支持最新版本的Windows和SQL Server 2016/2017。S2D还需要Windows的Datacenter Edition,这会显着增加部署成本。此外,SIOS还为Linux上