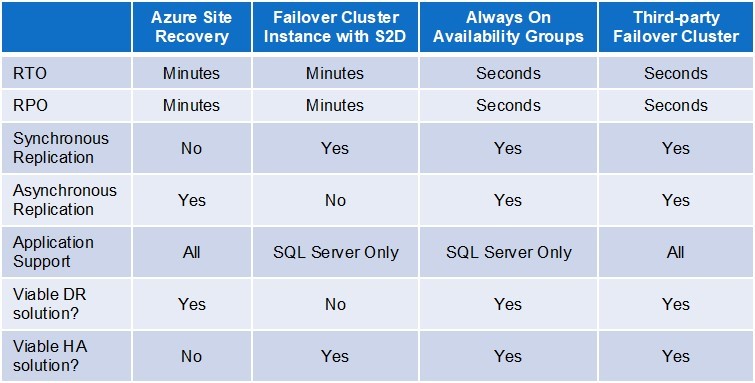
业务关键型应用程序的多云高可用性
根据 Flexera 2021 年云状况报告,云计算在过去十年中变得无处不在,99% 的组织至少使用一个公共或私有云。 虽然 AWS、Microsoft Azure 和 GCP 是当今三大公共云提供商,但许多组织(无论是有意还是无意)采用了多云战略,使他们能够挑选最有吸引力和最适合的云服务以满足他们独特的业务需求。 根据 Flexera 报告,如今 92% 的企业拥有多云战略,平均使用 2.6 个公共云和 2.7 个私有云,包括软件即服务 (SaaS)、平台即服务 (PaaS)、基础设施即服务 (IaaS) 产品。
什么是多云?
多云只是一个由两个或多个公共和/或私有云(包括 SaaS、PaaS 和 IaaS)组成的环境。 多云环境中的不同服务可能会互操作(在这种情况下可能是混合云),也可能不一定会互操作(本质上作为单独的云孤岛运行)。 请记住,尽管所有混合云都是多云,但并非所有多云都是混合云。
多云战略的演变(和广泛采用)
多云环境由任意两个或多个公共或私有云产品组合组成,包括 SaaS、PaaS 和 IaaS。 因此,组织的多云战略可能包括在 Amazon Elastic Cloud Compute (EC2) 上运行的企业工作负载,以及使用 Microsoft 365 处理电子邮件和后台应用程序。 或者,组织可以将私有云中托管的自定义数据库连接到公共云 SaaS 产品 Salesforce。
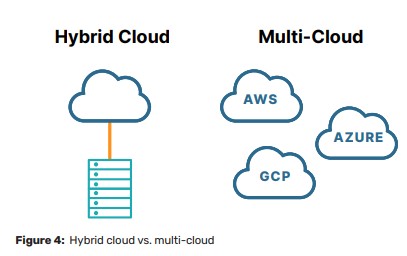
混合云环境由本地、私有云和公共云环境组成。 根据 Flexera 报告,80% 的企业拥有混合云战略(见图 4)。 多云环境通常是影子 IT 的结果,在影子 IT 中,不同的部门采购云服务来满足各自的需求,而无需咨询集中的 IT 部门。 例如,您的营销团队可能早在 IT 部门在 AWS 中部署其第一个工作负载之前就开始使用 Salesforce,而您的人力资源和财务部门正忙于将 Workday 和 Concur 添加到您的组织现在所依赖的 SaaS 应用程序组合中。 或者,也许您拥有在全球范围内从事不同项目的应用程序开发团队。 一个开发团队可能更喜欢 Azure DevOps,而另一个团队可能更喜欢 AWS 中的开源工具。 因此,您的多云策略可能纯粹是偶然演变的——这不一定是坏事。
您的不同部门有权选择同类最佳的解决方案来满足他们的需求,而您的应用程序开发团队可以在他们首选的开发环境中最大限度地提高工作效率并缩短上市时间。
多云环境也会因设计而演变,例如,由于监管要求、并购,或实施高可用性和灾难恢复策略。
监管语言可能含糊不清。 例如,金融行为监管局 (FCA) 关于外包 IT 的规定规定,公司必须能够“知道他们将如何过渡到替代服务提供商并保持业务连续性”。该声明意味着受监管的公司至少需要规划二级云环境。 鉴于许多受到严格监管的公司规避风险的性质,这些类型的问题导致许多公司采用多云战略。
在合并或收购后整合 IT 系统并整合数据中心和云环境是一项重大挑战。 有许多因素会使这一挑战复杂化,包括与云提供商或托管提供商的现有合同。 与整合物理数据中心类似,整合云工作负载可能是一项无法带来显着商业价值的重大工作,因此它经常因优先级更高的项目而被推迟。
最后,通常采用多云策略来支持高可用性和灾难恢复需求。 在评估 AWS 和 Azure 的主要公共云中断时,大多数中断通常一次仅限于一个云区域(并且最常见的是与软件相关)。
越来越多的组织(根据 Flexera 报告,占 34%)采取了额外的步骤,跨多个公共云提供商部署他们的关键任务工作负载。 这对于静态工作负载来说要容易得多,例如可以独立运行的网站和应用程序。 对于数据库和目录服务(例如 Active Directory)等分布式系统,多云灾难恢复可能更具挑战性。
了解多云环境中的独特挑战
与单一云部署相比,多云环境更复杂,因此管理起来更具挑战性。 多云环境中的一些独特挑战包括: • 端到端可见性:确保完整的可见性在任何 IT 环境中都是一项挑战——在高度动态的多云环境中,它的复杂性和挑战性呈指数级增长。 但是,端到端可见性对于解决性能问题和瓶颈、保护您的数字足迹以及识别关键任务系统和应用程序中的单点故障至关重要。
• 安全和身份管理:勒索软件和其他网络安全威胁是当今每位 IT 领导者最关心的问题。 通过将某些安全责任(例如数据中心和物理安全)转移到公共云提供商并提供对加密和网络分段等服务的按需访问,迁移到公共云平台通常可以改善组织的安全状况,但它可以也更容易犯下代价高昂的错误。 例如,网络错误配置可能很常见——数以千计的数据泄露是由配置不当的 AWS S3 存储桶造成的。 身份管理是另一个挑战。 例如,以前在本地环境中使用过 Active Directory 的组织可能非常熟悉 Azure Active Directory,但将身份管理从 Azure 扩展到 AWS、GCP 和 SaaS 产品(例如 Salesforce、ServiceNow、Workday 等) ) 可以引入新的挑战。
• 应用程序和数据可移植性:在混合(多云)环境中跨不同公共云平台动态移动应用程序和数据的能力是许多多云战略的关键。 尽管公共云提供商不一定会构建他们的服务来限制应用程序和数据的可移植性,但他们不一定会合作来促进此功能,并且可能会涉及成本。 不同的云提供商也为其各种服务产品使用不同的技术。
• 多云孤岛:如果组织不针对应用程序和数据可移植性来规划和设计其多云部署,他们最终可能会遇到孤立的应用程序和存储,本质上会在跨多个云平台的传统本地数据中心环境中重现一个常见问题。 至少,组织需要多云安全和管理工具,使他们能够有效地管理跨不同云平台的风险和使用/成本。
根据 Flexera 2021 年云状况报告,81% 的组织将安全性列为其云部署的首要挑战,其次是管理云支出 (79%)。 然而,只有 42% 的组织使用多云成本管理工具,只有 38% 的组织使用多云安全工具。
解决多云环境中的高可用性和灾难恢复问题
尽管多云部署面临许多挑战,但它们可以提供额外的可用性,尤其是在发生重大云中断和灾难恢复的情况下。 如果您的组织正在推行多云战略,您应该与值得信赖的、与云无关的合作伙伴合作,以帮助您使用整体方法设计和实施多云部署。
为了高可用性和灾难恢复,您还需要一个跨越您的多云环境的与云无关的技术解决方案,无论您使用何种云平台。 您总是希望避免这样一种情况,即您的高可用性解决方案会比独立解决方案在您的环境中导致更多的停机时间。 早期版本的 SQL Server 群集提出了这个难题 — 要增加磁盘空间,您必须招致停机,而这在独立解决方案中是不会发生的。 虽然故障转移静态网站之类的东西可能微不足道,但移动多层应用程序堆栈在网络和数据同步方面却极其复杂。 您还需要避免故障转移到安全性较低的云环境,该环境可能由于不了解跨云提供商的不同安全解决方案之间的细微差别而配置错误。
所以我该怎么做?
最后,在每个公共云中,都有一些服务会迅速增加成本。 这些服务根据基于使用的定价收费,并且可能意味着仅仅几天后成本就会急剧增加。 减轻这种风险的一种方法是确保您利用每个云平台中的成本监控服务和警报。
虽然多云部署并不适用于所有组织,但许多组织会走这条路。 了解网络和安全是您最大的技术障碍之一,管理治理和成本是关键的功能挑战。 测试对于确保您的多云集群解决方案正常运行至关重要。 使用支持简单切换和切回的高可用性集群解决方案并了解您的每个应用程序将如何工作非常重要故障转移,最重要的是定期测试故障转移以了解任何网络或数据障碍。
经许可转载自信息系统