Date: January 27, 2019
Tags: public cloud service levels

Options for When Public Cloud Service Levels Fall Short
All public cloud service providers offer some form of guarantee regarding availability. These may or may not be sufficient, depending on each application’s requirement for uptime. These guarantees typically range from 95.00% to 99.99% of uptime during the month. Most impose some type of “penalty” on the service provider for falling short of those thresholds.
Usually, most cloud service providers offer a 99.00% uptime threshold. This equates to about seven hours of downtime per month. And for many applications, those two-9’s might be enough. But for mission-critical applications, more 9’s are needed. Especially given the fact that many common causes of downtime are excluded from the guarantee.
There are, of course, cost-effective ways to achieve five-9’s high availability and robust disaster recovery protection in configurations using public cloud services, either exclusively or as part of a hybrid arrangement. This article highlights limitations involving HA and DR provisions in the public cloud. It explores three options for overcoming these limitations, and describes two common configurations for failover clusters.
Caveat Emptor in the Cloud
While all cloud service providers (CSPs) define “downtime” or “unavailable” somewhat differently, these definitions include only a limited set of all possible causes of failures at the application level. Generally included are failures affecting a zone or region, or external connectivity. All CSPs also offer credits ranging from 10% for failing to meet four-9’s of uptime to around 25% for failing to meet two-9’s of uptime.
Redundant resources can be configured to span the zones and/or regions within the CSP’s infrastructure. It will help to improve application-level availability. But even with such redundancy, there remain some limitations that are often unacceptable for mission-critical applications. Especially those requiring high transactional throughput performance. These limitations include each master being able to create only a single failover replica. And it requires the use of the master dataset for backups, and using event logs to replicate data. These and other limitations can increase recovery time during a failure and make it necessary to schedule at least some planned downtime.
Significant Limitations
The more significant limitations involve the many exclusions to what constitutes downtime. Here are just a few examples from actual Public Cloud Service Levels agreements of what is excluded from “downtime” or “unavailability” that cause application-level failures resulting from:
- factors beyond the CSP’s reasonable control (in other words, some of the stuff that happens regularly, such as carrier network outages and natural disasters)
- the customer’s software, or third-party software or technology, including application software
- faulty input or instructions, or any lack of action when required (in other words, the inevitable mistakes caused by human fallibility)
- problems with individual instances or volumes not attributable to specific circumstances of “unavailability”
- any hardware or software maintenance as provided for pursuant to the agreement
To be sure, it is reasonable for CSPs to exclude certain causes of failure. But it would be irresponsible for system administrators to use these as excuses. It is necessary to ensure application-level availability by some other means.
What Public Cloud Service Levels Are Available?
Provisioning resources for high availability in a way that does not sacrifice security or performance has never been a trivial endeavor. The challenge is especially difficult in a hybrid cloud environment where the private and public cloud infrastructures can differ significantly. It makes configurations difficult to test and maintain. Furthermore, it can result in failover provisions failing when actually needed.
For applications where the service levels offered by the CSP fall short, there are three additional options available based on the application itself, features in the operating system, or through the use of purpose-built failover clustering software.
Three Options for Improving Application-level Availability
HA/DR
The HA/DR options that might appear to be the easiest to implement are those specifically designed for each application. A good example is Microsoft’s SQL Server database with its carrier-class Always On Availability Groups feature. There are two disadvantages to this approach, however. The higher licensing fees, in this case for the Enterprise Edition, can make it prohibitively expensive for many needs. And the more troubling disadvantage is the need for different HA/DR provisions for different applications, which makes ongoing management a constant (and costly) struggle.
Uptime-Related Features Integrated Into The Operating System
Second option to improve Public Cloud Service Levels involves using uptime-related features integrated into the operating system. Windows Server Failover Clustering, for example, is a powerful and proven feature that is built into the OS. But on its own, WSFC might not provide a complete HA/DR solution because it lacks a data replication feature. In a private cloud, data replication can be provided using some form of shared storage, such as a storage area network. But because shared storage is not available in public clouds, implementing robust data replication requires using separate commercial or custom-developed software.
For Linux, which lacks a feature like WSFC, the need for additional HA/DR provisions and/or custom development is considerably greater. Using open source software like Pacemaker and Corosync requires creating (and testing) custom scripts for each application. These scripts often need to be updated and retested after even minor changes are made to any of the software or hardware being used. But because getting the full HA stack to work well for every application can be extraordinarily difficult, only very large organizations have the wherewithal needed to even consider taking on the effort.
Purpose-Built Failover Cluster
Ideally there would be a “universal” approach to HA/DR capable of working cost-effectively for all applications running on either Windows or Linux across public, private and hybrid clouds. Among the most versatile and affordable of such solutions is the third option: the purpose-built failover cluster. These HA/DR solutions are implemented entirely in software that is designed specifically to create, as their designation implies, a cluster of virtual or physical servers and data storage with failover from the active or primary instance to a standby to assure high availability at the application level.
Benefits Of These Solutions
These solutions provide, at a minimum, a combination of real-time data replication, continuous application monitoring and configurable failover/failback recovery policies. Some of the more robust ones offer additional advanced capabilities, such as a choice of block-level synchronous or asynchronous replication, support for Failover Cluster Instances (FCIs) in the less expensive Standard Edition of SQL Server, WAN optimization for enhanced performance and minimal bandwidth utilization, and manual switchover of primary and secondary server assignments to facilitate planned maintenance.
Although these general-purpose solutions are generally storage-agnostic, enabling them to work with storage area networks, shared-nothing SANless failover clusters are normally preferred based on their ability to eliminate potential single points of failure.
Two Common Failover Clustering Configurations
Every failover cluster consists of two or more nodes. Locating at least one of the nodes in a different datacenter is necessary to protect against local disasters. Presented here are two popular configurations: one for disaster recovery purposes; the other for providing both mission-critical high availability and disaster recovery. High transactional performance is often a requirement for highly available configurations. The example application is a database.
The basic SANless failover cluster for disaster recovery has two nodes with one primary and one secondary or standby server or server instance. This minimal configuration also requires a third node or instance to function as a witness, which is needed to achieve a quorum for determining assignment of the primary. For database applications, replication to the standby instance across the WAN is asynchronous to maintain high performance in the primary instance.
The SANless failover cluster affords a rapid recovery in the event of a failure in the primary. Resulting in a basic DR configuration suitable for many applications. It is capable of detecting virtually all possible failures, including those not counted as downtime in public cloud services. As such it will work in a private, public or hybrid cloud environment.
For example, the primary could be in the enterprise datacenter with the secondary deployed in the public cloud. Because the public cloud instance would be needed only during planned maintenance of the primary or in the event of its failure—conditions that can be fairly quickly remedied—the service limitations and exclusions cited above may well be acceptable for all but the most mission-critical of applications.
Three-Node SANless Failover Clusters
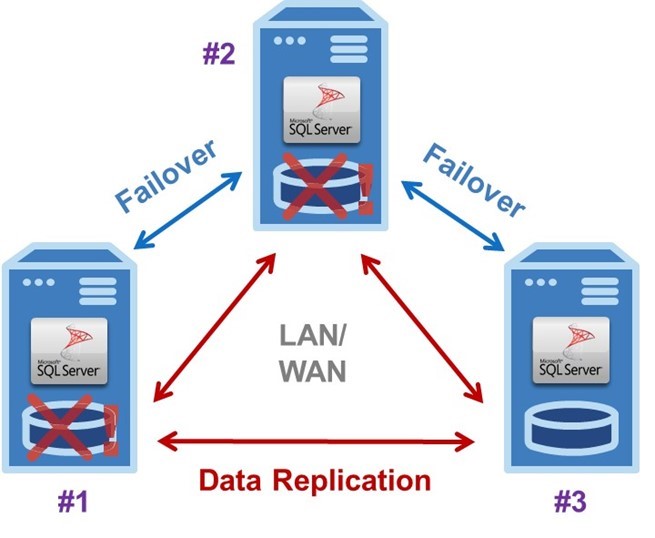
The figure shows an enhanced three-node SANless failover cluster that affords both five-9’s high availability and robust disaster recovery protection. As with the two-node cluster, this configuration will also work in a private, public or hybrid cloud environment. In this example, servers #1 and #2 are located in an enterprise datacenter with server #3 in the public cloud. Within the datacenter, replication across the LAN can be fully synchronous to minimize the time it takes to complete a failover. Therefore, maximize availability.
When properly configured, three-node SANless failover clusters afford truly carrier-class HA and DR. The basic operation is application-agnostic and works the same for Windows or Linux. Server #1 is initially the primary or active instance that replicates data continuously to both servers #2 and #3. If it experiences a failure, the application would automatically failover to server #2, which would then become the primary replicating data to server #3.
Recovery
Immediately after a failure in server #1, the IT staff would begin diagnosing and repairing whatever caused the problem. Once fixed, server #1 could be restored as the primary with a manual failback, or server #2 could continue functioning as the primary replicating data to servers #1 and #3. Should server #2 fail before server #1 is returned to operation, as shown, server #3 would become the primary. Because server #3 is across the WAN in the public cloud, data replication is asynchronous and the failover is manual to prevent “replication lag” from causing the loss of any data.
SANless failover clustering software is able to detect all possible failures at the application level. It readily overcomes the CSP limitations and exclusions mentioned above. So, it makes it possible for this three-node configuration to be deployed entirely within the public cloud. To afford the same five-9’s high availability based on immediate and automatic failovers, servers #1 and #2 would need to be located within a single zone or region where the LAN facilitates synchronous replication.
For appropriate DR protection, server #3 should be located in a different datacenter or region, where the use of asynchronous replication and manual failover/failback would be needed for applications requiring high transactional throughput. Three-node clusters can also facilitate planned hardware and software maintenance for all three servers. At the same time, continue to provide continuous DR protection for the application and its data.
By offering multiple, geographically-dispersed datacenters, public clouds afford numerous opportunities to improve availability and enhance DR provisions. SANless failover clustering software makes effective and efficient use of all compute, storage and network resources. It also being easy to implement and operate. These purpose-built solutions minimize all capital and operational expenditures. Finally, resulting in high availability being more robust and more affordable than ever before.
# # #
About the Author
Cassius Rhue is Director of Engineering at SIOS Technology. He leads the software product development and engineering team in Lexington, SC. Cassius has over 17 years of software engineering, development and testing experience. He also holds a BS in Computer Engineering from the University of South Carolina.