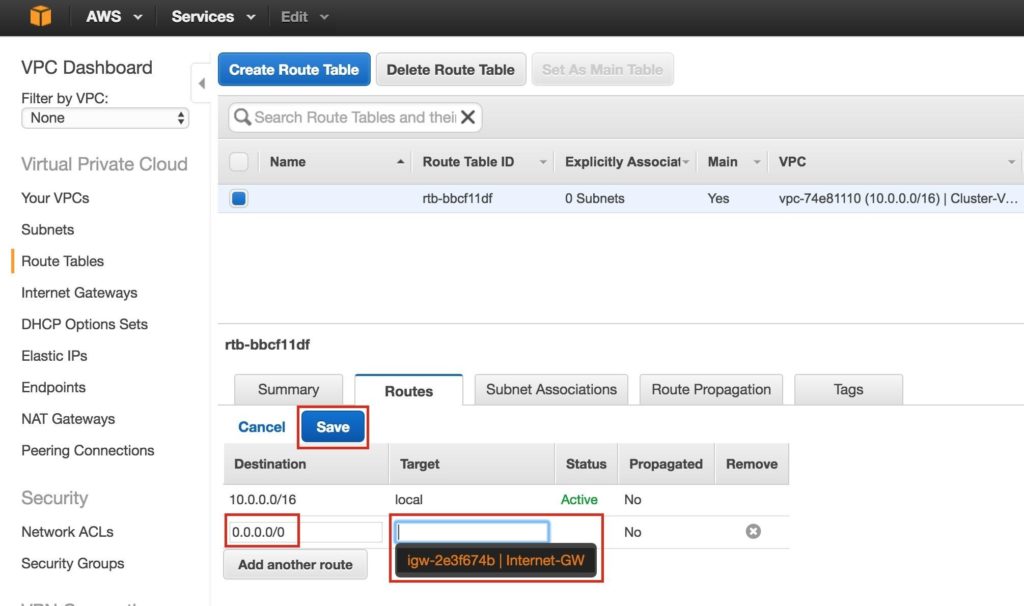
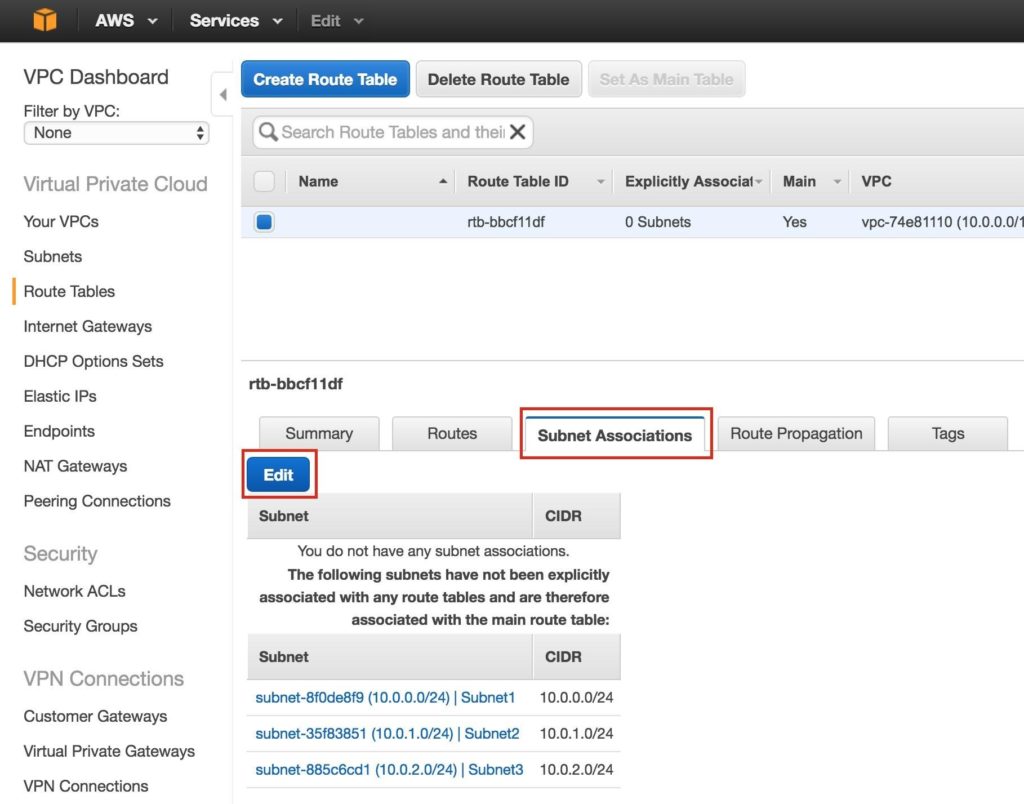
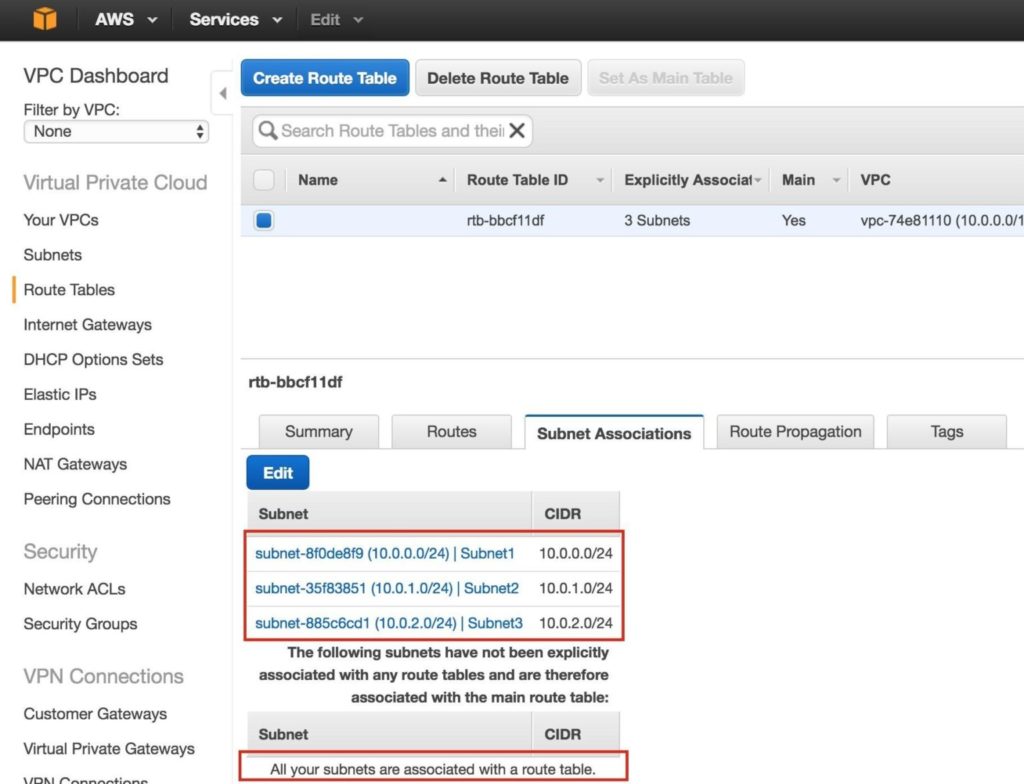
Hilangkan * waktu henti server web Apache dengan SIOS AppKeeper Monitoring
Saat ini, server web Apache adalah server web paling populer di Internet. Perusahaan menerapkan aplikasi misi penting yang menghadap pelanggan yang dibangun di atas Apache menggunakan platform cloud seperti Amazon AWS, Microsoft Azure, dan Google Cloud Platform. Jadi, Anda dapat bertaruh bahwa mereka menginvestasikan banyak waktu dan uang untuk memantau aplikasi tersebut dan mencoba mengurangi waktu henti. Tetapi bagaimana jika kami memberi tahu Anda bahwa kami dapat menghilangkan kebutuhan akan intervensi manual melalui pemantauan otomatis dan memulai ulang aplikasi ketika server web Apache Anda mati?
Sebelum kita membahas bagaimana kita dapat melakukannya, mari kita mundur sejenak dan melihat pilihan yang dimiliki perusahaan dalam hal memantau dan mengelola server web Apache mereka dan aplikasi penting tersebut.
Cara memantau dan melindungi server web Apache Anda dari waktu henti yang tidak perlu
Siapa pun yang menerapkan aplikasi menggunakan server web Apache sedang mempertimbangkan untuk memantau kesehatan server web mereka sendiri atau mengalihkan tugas itu ke pihak ketiga.
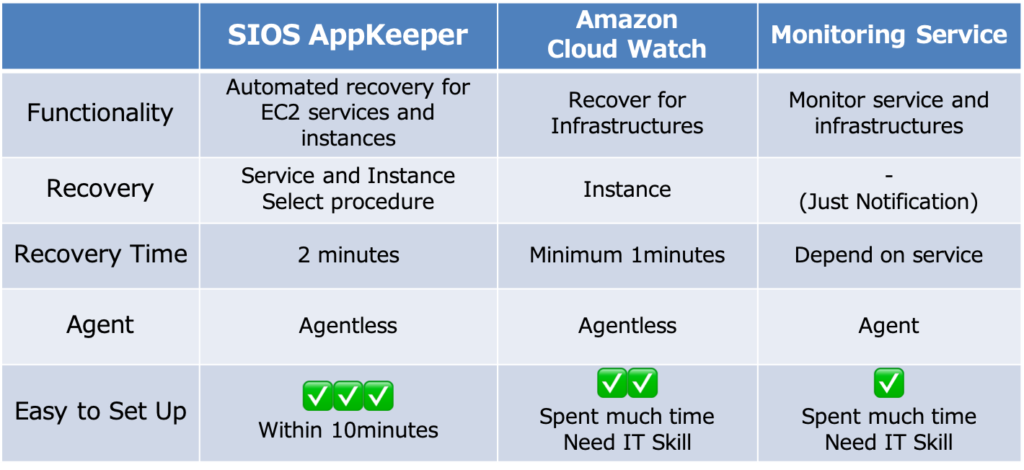
Dalam hal memantau aplikasi cloud yang berjalan di Amazon Web Services, pilihan yang populer adalah menggunakan Amazon CloudWatch. Beberapa perusahaan bahkan memperluas fungsionalitas CloudWatch dengan membuat beberapa tingkat otomatisasi dengan mengembangkan skrip atau dengan menggunakan AWS Lambda. Tetapi mengonfigurasi Amazon CloudWatch dengan benar dengan metrik khusus dan menyiapkan AWS Lambda memerlukan sejumlah keahlian teknis yang mungkin melampaui banyak perusahaan. Dan kemudian ada biaya dan upaya yang diperlukan untuk mempertahankan skrip apa pun saat aplikasi berkembang.
Pilihan lainnya adalah berinvestasi dalam solusi Application Performance Monitoring ("APM") yang komprehensif dari vendor seperti New Relics, Dynatrace, DataDog, atau LogicMonitor. Ini bisa sangat sesuai jika Anda ingin memantau lebih dari sekadar lingkungan AWS Anda. Solusi APM sangat dapat dikonfigurasi dan akan memberi Anda banyak data dalam hal informasi tentang apa yang terjadi.
Tapi apakah Anda sudah mengurangi waktu henti Anda? Mungkin tidak. Apa yang telah Anda lakukan diinvestasikan dalam sistem yang akan segera memberi tahu Anda jika dan ketika server web Apache Anda mati, dan akan membebani Anda dengan data (atau "peringatan badai") saat Anda mencoba menjalankan kembali semuanya.
Beberapa perusahaan telah memutuskan untuk mengalihkan tanggung jawab untuk memantau dan mengelola aplikasi mereka ke pihak ketiga yang tepercaya (seringkali "penyedia layanan terkelola" atau MSP). Sebagai imbalan atas biaya bulanan dasar, MSP memantau aplikasi dan menawarkan serangkaian layanan inti, sering kali terikat oleh Perjanjian Tingkat Layanan. Saat peringatan diterima, mereka menyelidiki. Dalam beberapa kasus, penyelidikan ini dapat memerlukan eskalasi (mahal). Jika dan ketika aplikasi mati, MSP kemudian akan mengambil kendali dan memulai ulang layanan atau mem-boot ulang instans di mana mereka bisa. Tetapi tindakan perbaikan ini seringkali menjadi biaya tambahan.
Pasti ada cara yang lebih baik.
Bagaimana pemantauan otomatis dan restart dengan SIOS AppKeeper menghilangkan waktu henti Apache Webserver
Berdasarkan pengalaman pelanggan kami, rata-rata perusahaan dengan hanya tiga instans EC2 mengalami waktu henti setidaknya sebulan sekali. “Situsnya sedang down! Menjatuhkan semuanya. Cari tahu apa yang perlu dilakukan! ” Yang perlu Anda lakukan adalah mengurangi kebutuhan akan latihan kebakaran yang tidak perlu ini.
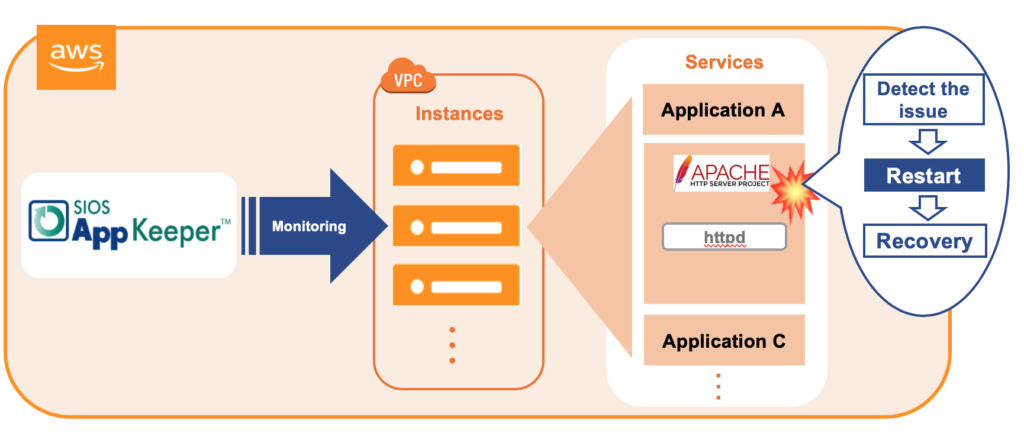
SIOS AppKeeper adalah layanan SaaS yang mudah dipasang dan dikonfigurasi serta memantau layanan dan aplikasi apa pun yang berjalan di Amazon EC2, seperti layanan httpd Apache Anda. Saat anomali terdeteksi, AppKeeper otomatis memulai ulang layanan, dan jika tidak berhasil, seluruh instance akan di-boot ulang. Tidak perlu lagi membaca log untuk menunjukkan alasan kegagalan, atau eskalasi ke pengembang untuk memulai ulang layanan Anda. Atau biaya outsourcing yang mahal. AppKeeper menyediakan fungsionalitas "set-it-and-forget-it" sehingga Anda dapat menghilangkan waktu henti.
Saat ini ratusan perusahaan mengandalkan AppKeeper untuk menjaga lingkungan cloud mereka tetap berjalan. Kami mengundang Anda untuk melihat video di bawah ini untuk mendemonstrasikan bagaimana AppKeeper melindungi server web Apache. Dan jika Anda menyukai apa yang Anda lihat, jangan ragu untuk mendaftar uji coba gratis AppKeeper selama 14 hari.

* Berdasarkan data pelanggan, AppKeeper mengatasi 85% kegagalan layanan aplikasi. Jadi hampir sembilan dari sepuluh AppKeeper mengirimkan email yang memberi tahu pelanggan bahwa waktu henti terdeteksi dan layanan dimulai ulang atau instans di-boot ulang secara otomatis. Bukankah itu lebih baik daripada panik dan menggali file log sebelum memulai ulang semuanya secara manual?
Lihat posting terkait: Mengapa AWS EC2 Application Monitoring Begitu Sulit?