
* PENOLAKAN: Meskipun yang berikut ini sepenuhnya mencakup porsi ketersediaan tinggi dalam cakupan produk kami, ini hanya “panduan” pengaturan dan harus disesuaikan dengan konfigurasi Anda sendiri.
Gambaran AWAN HUAWEI adalah penyedia layanan cloud terkemuka tidak hanya di China tetapi juga memiliki jejak global dengan banyak pusat data di seluruh dunia. Mereka menyatukan lebih dari 30 tahun keahlian Huawei dalam produk dan solusi infrastruktur TIK dan berkomitmen untuk menyediakan layanan cloud yang andal, aman, dan hemat biaya untuk memberdayakan aplikasi, memanfaatkan kekuatan data, dan membantu organisasi dari semua ukuran tumbuh di era sekarang ini. dunia yang cerdas. HUAWEI CLOUD juga berkomitmen untuk menghadirkan layanan cloud dan AI yang terjangkau, efektif, dan andal melalui inovasi teknologi.
DataKeeper Cluster Edition menyediakan replikasi di cloud pribadi virtual (VPC) dalam satu wilayah di seluruh zona ketersediaan untuk cloud Huawei. Dalam contoh pengelompokan SQL Server khusus ini, kami akan meluncurkan empat instance (satu instance pengontrol domain, dua instance SQL Server, dan instance kuorum/saksi) ke dalam tiga zona ketersediaan.
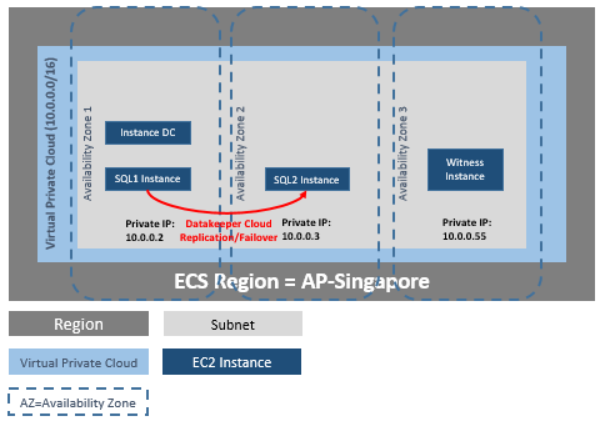
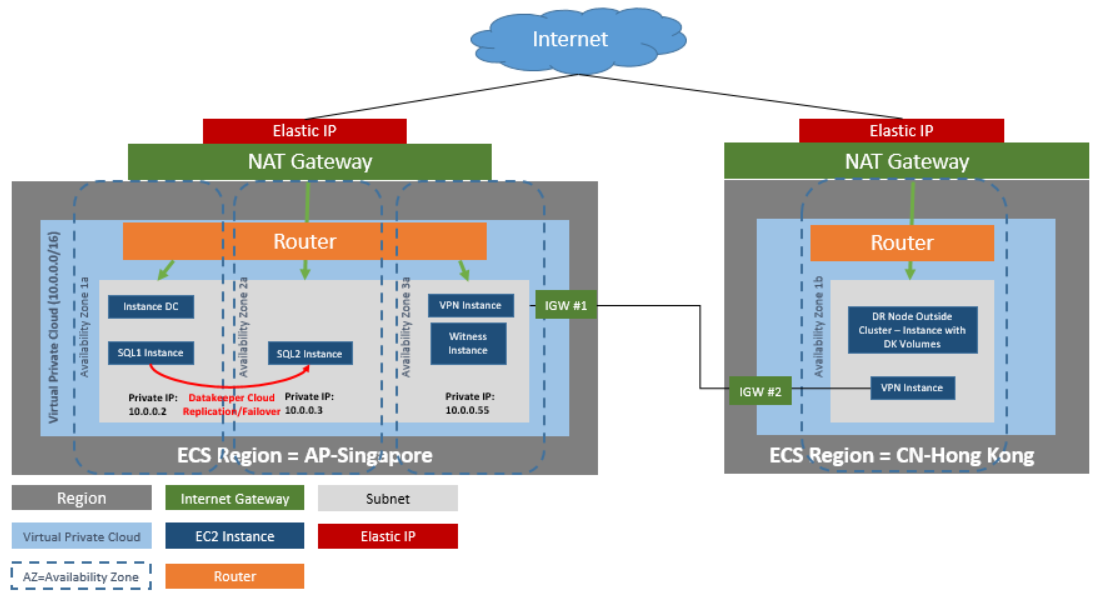
DataKeeper Cluster Edition menyediakan dukungan untuk node replikasi data di luar cluster dengan semua node di cloud Huawei. Dalam contoh pengelompokan SQL Server khusus ini, empat contoh diluncurkan (satu contoh pengontrol domain, dua contoh SQL Server dan contoh kuorum/saksi) ke dalam tiga zona ketersediaan. Kemudian instans DataKeeper tambahan diluncurkan di wilayah kedua termasuk instans VPN di kedua wilayah. Silahkan lihat Konfigurasi Replikasi Data Dari Node Cluster ke Situs DR Eksternal untuk informasi lebih lanjut. Untuk informasi tambahan tentang penggunaan beberapa wilayah, silakan lihat Menghubungkan Dua VPC di Wilayah Berbeda .
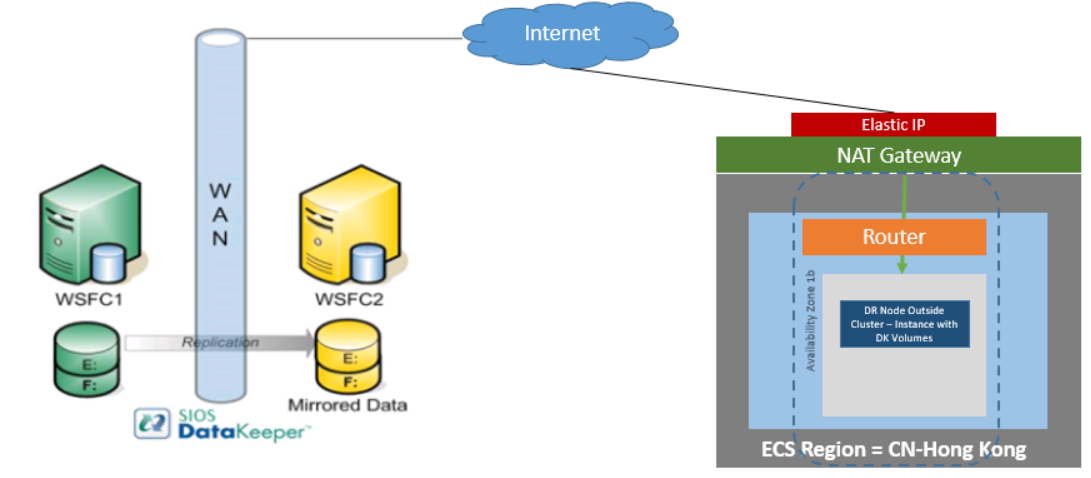
DataKeeper Cluster Edition juga menyediakan dukungan untuk node replikasi data di luar cluster dengan hanya node di luar cluster di Huawei Cloud. Dalam contoh pengelompokan SQL Server khusus ini, WSFC1 dan WSFC2 berada dalam kluster di tempat yang mereplikasi ke instans Huawei Cloud. Kemudian instans DataKeeper tambahan diluncurkan di suatu wilayah di Huawei Cloud. Silahkan lihat Konfigurasi Replikasi Data Dari Node Cluster ke Situs DR Eksternal untuk informasi lebih lanjut.
Persyaratan
| Keterangan | Persyaratan |
| Awan Pribadi Virtual | Dalam satu wilayah dengan tiga zona ketersediaan |
| Jenis Instance | Jenis instans minimum yang disarankan: s3.large.2 |
| Sistem operasi | Lihat Matriks Dukungan DKCE |
| IP elastis | Satu alamat IP elastis yang terhubung ke pengontrol domain |
| Empat contoh | Satu instance pengontrol domain, dua instance SQL Server, dan satu instance kuorum/saksi |
| Setiap SQL Server | ENI (Elastic Network Interface) dengan 4 IP · IP ENI Primer didefinisikan secara statis di Windows dan digunakan oleh DataKeeper Cluster Edition · Tiga IP dikelola oleh ECS saat digunakan oleh Windows Failover Clustering, DTC, dan SQLFC |
| Volume | Tiga volume (hanya EBS dan NTFS) · Satu volume utama (drive C) · Dua volume tambahan o Satu untuk Failover Clustering o Satu untuk MSDTC |
Catatan Rilis Sebelum memulai, pastikan Anda membaca Catatan Rilis Edisi DataKeeper Cluster untuk informasi terbaru. Sangat disarankan agar Anda membaca dan memahami Panduan Instalasi DataKeeper Cluster Edition .
Buat Virtual Private Cloud (VPC) Awan pribadi virtual adalah objek pertama yang Anda buat saat menggunakan DataKeeper Cluster Edition.
* Virtual Private Cloud (VPC) adalah cloud pribadi terisolasi yang terdiri dari kumpulan sumber daya komputasi bersama yang dapat dikonfigurasi di cloud publik.
- Menggunakan alamat email dan kata sandi yang ditentukan saat mendaftar Huawei Cloud , masuk ke Konsol Manajemen Cloud Huawei .
- Dari Jasa tarik-turun, pilih Awan Pribadi Virtual .
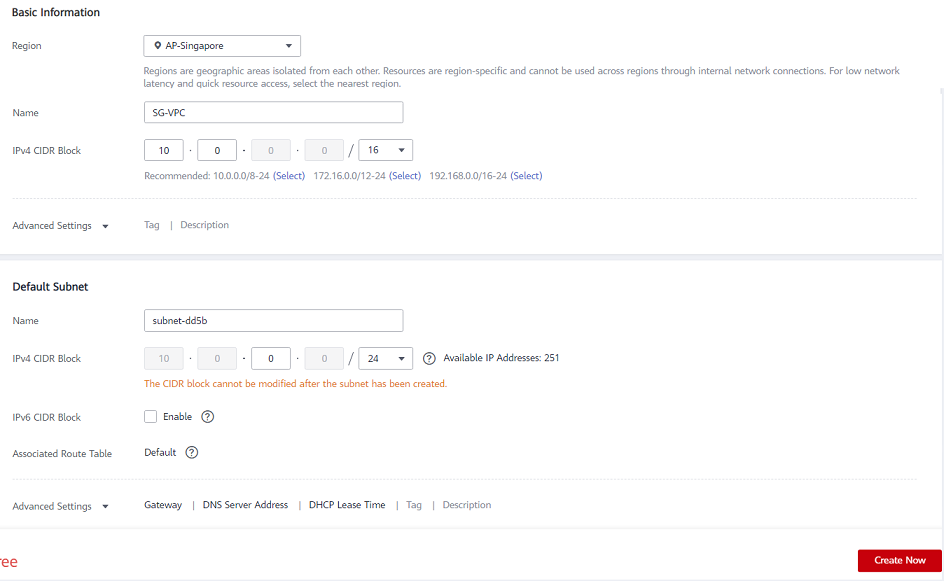
- Di sisi kanan layar, klik Buat VPC dan pilih wilayah yang ingin Anda gunakan.
- Masukkan nama yang ingin Anda gunakan untuk VPC
- Tentukan subnet cloud pribadi virtual Anda dengan memasukkan CIDR (Perutean Antar-Domain Tanpa Kelas) seperti yang dijelaskan di bawah ini
- Masukkan nama subnet, lalu klik Buat sekarang .
* Tabel Rute akan secara otomatis dibuat dengan asosiasi “utama” ke VPC baru. Anda dapat menggunakannya nanti atau membuat Tabel Rute lain.
* LINK BERMANFAAT: Huawei Membuat Virtual Private Cloud (VPC) Luncurkan Instance Berikut ini memandu Anda dalam meluncurkan instance ke subnet Anda. Anda akan ingin meluncurkan dua instans ke dalam satu zona ketersediaan, satu untuk instans pengontrol domain dan satu untuk instans SQL Anda. Kemudian Anda akan meluncurkan instans SQL lain ke zona ketersediaan lain dan instans saksi kuorum ke zona ketersediaan lain.
* LINK BERMANFAAT: Instans Huawei Cloud ECS
- Menggunakan alamat email dan kata sandi yang ditentukan saat mendaftar Huawei Cloud , masuk ke Konsol Manajemen Cloud Huawei .
- Dari Daftar Layanan tarik-turun, pilih Server Cloud Elastis .

- Pilih Beli ECS dan pilih Mode Penagihan, Wilayah, dan AZ (Zona Ketersediaan) untuk menerapkan Instans
- Pilih Jenis Instans Anda. ( Catatan: Pilih s3.large.2 atau lebih besar.).
- Pilih Gambar. Di bawah Gambar Publik, pilih Windows Server 2019 Pusat Data 64bit Bahasa Inggris gambar
- Untuk Konfigurasi Jaringan , pilih VPC Anda.
- Untuk Subnet , pilih Subnet yang ingin Anda gunakan, pilih Alamat IP yang ditentukan secara manual dan masukkan alamat IP yang ingin Anda gunakan
- Pilih Grup Keamanan untuk menggunakan atau Edit dan pilih yang sudah ada.
- Tetapkan EIP jika Anda memerlukan instans ECS untuk mengakses internet
- Klik Konfigurasikan Pengaturan Lanjut dan berikan nama untuk ECS, gunakan Kata sandi untuk Mode Masuk dan berikan kata sandi aman untuk login Administrator
- Klik Konfigurasi Sekarang pada Opsi Lanjutan Tambah sebuah Menandai untuk memberi nama instance Anda dan Klik pada Mengonfirmasi
- Lakukan tinjauan akhir Instance dan klik Kirim .
* PENTING: Catat kata sandi administrator awal ini. Ini akan diperlukan untuk masuk ke instance Anda.
Ulangi langkah di atas untuk semua instance.
Hubungkan ke Instance Anda dapat terhubung ke instance pengontrol domain Anda melalui Login Jarak Jauh dari panel ECS.
Masuk sebagai administrator dan masukkan Anda kata sandi administrator .
* PRAKTEK TERBAIK: Setelah masuk, praktik terbaik adalah mengubah kata sandi Anda.
Konfigurasikan Instance Pengontrol Domain Sekarang setelah instance telah dibuat, kami mulai dengan menyiapkan instance Layanan Domain.
Panduan ini bukan tutorial tentang cara menyiapkan instance server Domain Aktif. Kami merekomendasikan membaca artikel tentang cara mengatur dan mengkonfigurasi server Active Directory. Sangat penting untuk dipahami bahwa meskipun instance berjalan di cloud Huawei, ini adalah instalasi reguler Active Directory.
Alamat IP Statis Konfigurasikan Alamat IP Statis untuk Instans Anda
- Hubungkan ke instance pengontrol domain Anda.
- Klik Awal / Panel kendali .
- Klik Jaringan dan pusat Berbagi .
- Pilih antarmuka jaringan Anda.
- Klik Properti .
- Klik Protokol Internet Versi 4 (TCP/IPv4) , kemudian Properti .
- Dapatkan saat ini alamat IPv4 , gerbang default dan server DNS untuk antarmuka jaringan dari Amazon .
- Dalam Properti Internet Protocol Version 4 (TCP/IPv4) kotak dialog, di bawah Gunakan alamat IP berikut , Masukkan alamat IPv4 .
- Dalam Subnetmask kotak, ketik subnet mask yang terkait dengan subnet cloud pribadi virtual Anda.
- Dalam Gerbang Default kotak, ketik alamat IP dari gateway default dan kemudian klik oke .
- Untuk Server DNS Pilihan , Masukkan Alamat IP Primer Pengontrol Domain Anda (mis. 15.0.1.72).
- Klik Oke , lalu pilih Menutup . keluar Jaringan dan pusat Berbagi .
- Ulangi langkah di atas pada instance Anda yang lain.
Bergabunglah dengan Dua Instance SQL dan Instance Witness ke Domain * Sebelum mencoba bergabung dengan domain, lakukan penyesuaian jaringan ini. Pada adaptor jaringan Anda, Tambah/Ubah server DNS Pilihan ke alamat Pengontrol Domain baru dan server DNS-nya. Gunakan ipconfig /flushdns untuk menyegarkan daftar pencarian DNS setelah perubahan ini. Lakukan ini sebelum mencoba bergabung dengan Domain.
* Memastikan bahwa Jaringan Inti dan Berbagi File dan Printer opsi diizinkan di Windows Firewall.
- Pada setiap contoh, klik Awal , lalu klik kanan Komputer dan pilih Properti .
- Di paling kanan, pilih Ubah pengaturan .
- Klik Mengubah .
- Masukkan yang baru Nama komputer .
- Pilih Domain .
- Memasuki Nama domain – (mis. docs.huawei.com).
- Klik Berlaku .
* Menggunakan Panel kendali untuk memastikan semua instans menggunakan zona waktu yang benar untuk lokasi Anda.
* PRAKTEK TERBAIK: Disarankan agar File Halaman Sistem diatur ke sistem dikelola (tidak otomatis) dan untuk selalu menggunakan drive C:.
Panel Kontrol > Pengaturan sistem lanjutan > Kinerja > Pengaturan > Lanjutan > Memori Virtual. Pilih Ukuran yang dikelola sistem , Volume C: saja, lalu pilih Mengatur untuk menyimpan.
Tetapkan IP Pribadi Sekunder ke Dua Instance SQL Selain IP Primer, Anda perlu menambahkan tiga IP tambahan (IP Sekunder) ke antarmuka jaringan elastis untuk setiap instans SQL.
- Dari Daftar Layanan tarik-turun, pilih Server Cloud Elastis .
- Klik instance yang ingin Anda tambahkan alamat IP pribadi sekundernya.
- Pilih NIC > Kelola Alamat IP Virtual .
- Klik Tetapkan alamat IP Virtual dan pilih manual masukkan alamat IP yang berada dalam rentang subnet untuk instance (mis. Untuk 15.0.1.25, masukkan 15.0.1.26). Klik Oke .
- Klik pada Lagi dropdown pada baris alamat IP, dan pilih Ikat ke Server , pilih server untuk mengikat alamat IP, dan kartu NIC.
- Klik oke untuk menyimpan pekerjaan Anda.
- Lakukan hal di atas pada kedua Instance SQL .
* LINK BERMANFAAT: Mengelola Alamat IP Virtual Mengikat Alamat IP Virtual ke EIP atau ECS Buat dan Lampirkan Volume DataKeeper adalah solusi replikasi volume tingkat blok dan mengharuskan setiap node dalam cluster memiliki volume tambahan (selain drive sistem) yang berukuran sama dan huruf drive yang sama. Silakan tinjau Pertimbangan Volume untuk informasi tambahan mengenai persyaratan penyimpanan.
Buat Volume Buat dua volume di setiap zona ketersediaan untuk setiap instance SQL server, total empat volume.
- Dari Daftar Layanan tarik-turun, pilih Server Cloud Elastis .
- Klik instance yang ingin Anda kelola
- Pergi ke Disk tab
- Klik Tambahkan Disk untuk menambahkan volume baru pilihan dan ukuran Anda, pastikan Anda memilih volume di AZ yang sama dengan server SQL yang ingin Anda lampirkan
- Pilih kotak centang untuk menyetujui SLA dan Kirim
- Klik Kembali ke Konsol Server
- Menempel disk jika perlu ke instance SQL
- Lakukan ini untuk keempat volume.
* LINK BERMANFAAT: Layanan Volume Elastis Konfigurasikan Cluster Sebelum menginstal DataKeeper Cluster Edition, penting untuk mengonfigurasi Windows Server sebagai cluster menggunakan kuorum mayoritas node (jika ada jumlah node ganjil) atau kuorum mayoritas berbagi node dan file (jika ada jumlah genap node). Lihat dokumentasi Microsoft tentang pengelompokan selain topik ini untuk petunjuk langkah demi langkah.Catatan: Microsoft merilis perbaikan terbaru untuk Windows 2008R2 yang memungkinkan penonaktifan suara simpul yang dapat membantu mencapai tingkat ketersediaan yang lebih tinggi dalam konfigurasi klaster multi-situs tertentu.
Tambahkan Pengelompokan Failover Tambahkan fitur Failover Clustering ke kedua instance SQL.
- Meluncurkan Manajer Server .
- Pilih Fitur di panel kiri dan klik Tambah Fitur dalam Fitur Ini memulai Tambahkan Fitur Wizard .
- Pilih Pengelompokan failover .
- Pilih Install .
Memvalidasi Konfigurasi
- Membuka Manajer Cluster Failover .
- Pilih Failover Cluster Manager, pilih Memvalidasi Konfigurasi .
- Klik Lanjut , lalu tambahkan dua Contoh SQL .
Catatan: Untuk mencari, pilih Jelajahi , lalu klik Canggih dan Cari sekarang . Ini akan mencantumkan instance yang tersedia.
- Klik Lanjut .
- Pilih Jalankan Hanya Tes yang Saya Pilih dan klik Lanjut .
- Dalam Seleksi Tes layar, batalkan pilihan Penyimpanan dan klik Lanjut .
- Pada layar konfirmasi yang dihasilkan, klik Lanjut .
- Tinjauan Laporan Ringkasan Validasi lalu klik Menyelesaikan .
Buat Cluster
- Di dalam Manajer Cluster Failover , klik Buat Cluster lalu klik Lanjut .
- Masukkan dua Anda Contoh SQL .
- pada Peringatan Validasi halaman, pilih Tidak lalu klik Lanjut .
- pada Titik Akses untuk Mengelola Cluster halaman, masukkan nama unik untuk Cluster WSFC Anda. Kemudian masukkan Alamat IP Failover Clustering untuk setiap node yang terlibat dalam cluster. Ini yang pertama dari ketiganya alamat IP sekunder ditambahkan sebelumnya ke setiap instance.
- PENTING! Hapus centang pada kotak “Tambahkan semua penyimpanan yang tersedia ke kluster”. Drive cermin DataKeeper tidak boleh dikelola secara asli oleh cluster. Mereka akan dikelola sebagai Volume DataKeeper.
- Klik Lanjut di Konfirmasi
- Pada Ringkasan halaman, tinjau peringatan apa pun lalu pilih Menyelesaikan .
Konfigurasikan Kuorum/Saksi
- Buat folder pada contoh kuorum/saksi (saksi) Anda.
- Bagikan foldernya.
- Klik kanan folder dan pilih Bagikan Dengan / Orang Tertentu ….
- Dari tarik-turun, pilih Setiap orang dan klik Menambahkan .
- Dibawah Tingkat Izin , Pilih Baca tulis .
- Klik Membagikan , kemudian Selesai . (Catat jalur berbagi file ini untuk digunakan di bawah.)
- Di dalam Manajer Cluster Failover , klik kanan cluster dan pilih Lebih Banyak Tindakan dan Konfigurasikan Pengaturan Kuorum Cluster . Klik Lanjut .
- pada Pilih Konfigurasi Kuorum , memilih Node dan Berbagi File Mayoritas dan klik Lanjut .
- pada Konfigurasikan File Share Witness layar, masukkan path ke file share yang dibuat sebelumnya dan klik Lanjut .
- pada Konfirmasi halaman, klik Lanjut .
- pada Ringkasan halaman, klik Menyelesaikan .
Instal dan Konfigurasi DataKeeper Setelah cluster dasar dikonfigurasi tetapi sebelum sumber daya cluster dibuat, instal dan lisensi Edisi Cluster DataKeeper pada semua node cluster. Lihat Panduan Instalasi DataKeeper Cluster Edition untuk petunjuk rinci.
- Lari Penyiapan DataKeeper untuk memasang Edisi Cluster DataKeeper pada kedua contoh SQL.
- Masukkan kunci lisensi dan reboot saat diminta.
- Luncurkan GUI DataKeeper dan sambungkan ke server .
* Catatan : Domain atau akun server yang digunakan harus ditambahkan ke Grup Administrator Sistem Lokal. Akun harus memiliki hak administrator di setiap server tempat DataKeeper diinstal. Mengacu pada Layanan DataKeeper Login ID dan Pemilihan Kata Sandi untuk informasi tambahan.
- Klik kanan pada Pekerjaan dan terhubung ke kedua server SQL.
- Buat Pekerjaan untuk setiap cermin yang akan Anda buat. Satu untuk sumber daya DTC Anda, dan satu untuk sumber daya SQL Anda..
- Saat ditanya apakah Anda ingin mendaftarkan volume secara otomatis sebagai volume cluster, pilih Ya .
* Catatan: Jika menginstal DataKeeper Cluster Edition di Windows “Core” (Windows tanpa GUI), pastikan untuk membaca Menginstal dan Menggunakan DataKeeper di Platform Inti Server Windows 2008R2/2012 untuk petunjuk rinci.
Konfigurasikan MSDTC
- Untuk Windows Server 2012 dan 2016, di GUI Pengelola Gugus Failover , Pilih Peran , lalu pilih Konfigurasikan Peran .
- Pilih Koordinator Transaksi Terdistribusi (DTC) , dan klik Lanjut .
* Untuk Windows Server 2008, di GUI Pengelola Gugus Failover , Pilih Layanan dan Aplikasi , lalu pilih Konfigurasikan Layanan atau Aplikasi dan klik Lanjut .
- pada Titik Akses Klien layar, masukkan nama, lalu masukkan Alamat IP MSDTC untuk setiap node yang terlibat dalam cluster. Ini adalah yang kedua dari tiga alamat IP sekunder ditambahkan sebelumnya ke setiap instance. Klik Lanjut .
- Pilih Volume MSDTC dan klik Lanjut .
- pada Konfirmasi halaman, klik Lanjut .
- sekali Ringkasan tampilan halaman, klik Menyelesaikan .
Instal SQL pada Instance SQL Pertama
- Di server pengontrol domain, buat folder dan bagikan..
- Misalnya “TEMPSHARE” dengan izin Semua Orang.
- Buat sub folder “SQL” dan salin penginstal SQL .iso ke dalam sub folder itu.
- Di server SQL, buat drive jaringan dan lampirkan ke folder bersama di pengontrol domain.
- . Misalnya “penggunaan bersih S: \TEMPSHARE
- Di server SQL, drive S: akan muncul. CD ke folder SQL dan temukan penginstal SQL .iso. Klik kanan pada file .iso dan pilih Gunung . Penginstal setup.exe akan muncul dengan penginstal SQL .iso.
F:>Setup /SkipRules=Cluster_VerifyForErrors /Action=InstallFailoverCluster
- Pada Siapkan Aturan Dukungan , klik oke .
- pada Kunci produk dialog, masukkan kunci produk dan klik Lanjut .
- pada Persyaratan Lisensi dialog, terima perjanjian lisensi dan klik Lanjut .
- pada Pembaruan Produk dialog, klik Lanjut .
- pada Siapkan File Dukungan dialog, klik Install .
- pada Siapkan Aturan Dukungan dialog, Anda akan menerima peringatan. Klik Lanjut , mengabaikan pesan ini, karena pesan tersebut diharapkan berada di kluster penyimpanan multi-situs atau non-bersama.
- Memeriksa Konfigurasi Node Cluster dan klik Lanjut .
- Konfigurasikan Anda Jaringan Kluster dengan menambahkan alamat IP sekunder “ketiga” untuk instance SQL Anda dan klik Lanjut . Klik Ya untuk melanjutkan dengan konfigurasi multi-subnet.
- Memasuki kata sandi untuk akun layanan dan klik Lanjut .
- pada Pelaporan Kesalahan dialog, klik Lanjut .
- pada Tambahkan Aturan Node dialog, peringatan operasi yang dilewati dapat diabaikan. Klik Lanjut .
- Verifikasi fitur dan klik Install .
- Klik Menutup untuk menyelesaikan proses instalasi.
Instal SQL pada Instance SQL Kedua Menginstal instance SQL kedua mirip dengan yang pertama.
- Di server SQL, buat drive jaringan dan lampirkan ke folder bersama di pengontrol domain seperti yang dijelaskan di atas untuk server SQL pertama.
- Setelah penginstal .iso dipasang, jalankan Pengaturan SQL sekali lagi dari baris perintah untuk melewati Mengesahkan Buka sebuah Memerintah jendela, telusuri ke Direktori instalasi SQL dan ketik perintah berikut:
Setup /SkipRules=Cluster_VerifyForErrors /Action=AddNode /INSTANCENAME=”MSSQLSERVER” ( Catatan : Ini mengasumsikan Anda menginstal instance default pada node pertama)
- Pada Siapkan Aturan Dukungan , klik oke .
- pada Kunci produk dialog, masukkan kunci produk dan klik Lanjut .
- pada Persyaratan Lisensi dialog, terima perjanjian lisensi dan klik Lanjut .
- pada Pembaruan Produk dialog, klik Lanjut .
- pada Siapkan File Dukungan dialog, klik Install .
- pada Siapkan Aturan Dukungan dialog, Anda akan menerima peringatan. Klik Lanjut , mengabaikan pesan ini, karena pesan tersebut diharapkan berada di kluster penyimpanan multi-situs atau non-bersama.
- Memeriksa Konfigurasi Node Cluster dan klik Lanjut .
- Konfigurasikan Anda Jaringan Kluster dengan menambahkan alamat IP sekunder “ketiga” untuk Instans SQL Anda dan klik Lanjut . Klik Ya untuk melanjutkan dengan konfigurasi multi-subnet.
- Memasuki kata sandi untuk akun layanan dan klik Lanjut .
- pada Pelaporan Kesalahan dialog, klik Lanjut .
- pada Tambahkan Aturan Node dialog, peringatan operasi yang dilewati dapat diabaikan. Klik Lanjut .
- Verifikasi fitur dan klik Install .
- Klik Menutup untuk menyelesaikan proses instalasi.
Konfigurasi Cluster Umum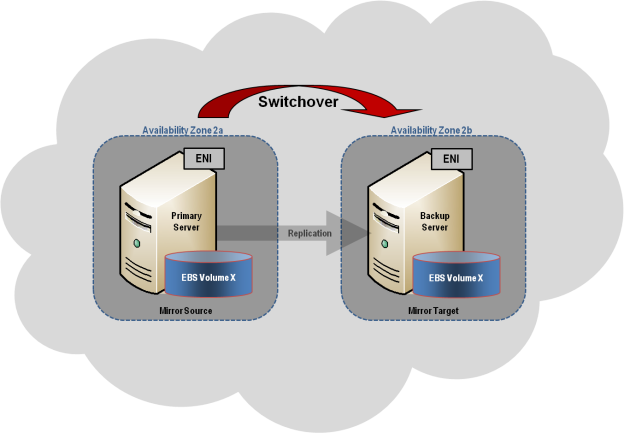
Bagian ini menjelaskan konfigurasi cluster yang direplikasi 2-simpul umum .
- Konfigurasi awal harus dilakukan dari UI Penjaga Data berjalan di salah satu node cluster. Jika tidak mungkin menjalankan DataKeeper UI pada node cluster, seperti saat menjalankan DataKeeper di server Windows Core saja, instal UI DataKeeper di komputer mana pun yang menjalankan Windows XP atau lebih tinggi dan ikuti instruksi di Inti Saja bagian untuk membuat cermin dan mendaftarkan sumber daya cluster melalui baris perintah.
- Setelah UI DataKeeper berjalan, terhubung ke masing-masing node di klaster.
- Buat Pekerjaan menggunakan UI DataKeeper. Proses ini membuat cermin dan menambahkan sumber daya Volume DataKeeper ke Penyimpanan yang Tersedia.
! PENTING: Pastikan bahwa Nama Jaringan Virtual untuk koneksi NIC identik pada semua node cluster.
- Jika cermin tambahan diperlukan, Anda dapat Tambahkan Cermin ke Pekerjaan .
- Dengan Volume Penjaga Data sekarang di Penyimpanan yang Tersedia , Anda dapat membuat sumber daya cluster (SQL, File Server, dll.) dengan cara yang sama seperti jika ada sumber daya disk bersama di cluster. Lihat dokumentasi Microsoft untuk informasi tambahan selain di atas untuk petunjuk konfigurasi cluster langkah-demi-langkah.
Konektivitas ke IP cluster (virtual) Selain IP Primer dan IP sekunder, Anda juga perlu mengonfigurasi alamat IP virtual di Huawei Cloud agar dapat dirutekan ke node aktif.
- Dari Daftar Layanan tarik-turun, pilih Server Cloud Elastis .
- Klik salah satu contoh SQL yang ingin Anda tambahkan alamat IP virtual cluster (satu untuk MSDTC, satu untuk SQL Failover Cluster)
- Pilih NIC > Kelola Alamat IP Virtual .
- Klik Tetapkan alamat IP Virtual dan pilih manual masukkan alamat IP yang berada dalam rentang subnet untuk instance (mis. Untuk 15.0.1.25, masukkan 15.0.1.26). Klik Oke .
- Klik pada Lagi dropdown pada baris alamat IP, dan pilih Ikat ke Server , pilih server untuk mengikat alamat IP, dan kartu NIC.
- Gunakan langkah 4. dan 5 yang sama untuk IP virtual MSDTC dan SQLFC
- Klik oke untuk menyimpan pekerjaan Anda.
Pengelolaan Setelah volume DataKeeper terdaftar dengan Windows Server Failover Clustering, semua pengelolaan volume tersebut akan dilakukan melalui antarmuka Windows Server Failover Clustering. Semua fungsi manajemen biasanya tersedia di DataKeeper akan dinonaktifkan pada setiap volume yang berada di bawah kendali cluster. Sebagai gantinya, sumber daya cluster DataKeeper Volume akan mengontrol arah cermin, jadi ketika Volume DataKeeper online pada sebuah node, node tersebut menjadi sumber mirror. Properti sumber daya cluster Volume DataKeeper juga menampilkan informasi pencerminan dasar seperti sumber, target, jenis, dan status cermin.
Penyelesaian masalah Gunakan sumber daya berikut untuk membantu memecahkan masalah:
- Penyelesaian masalah bagian masalah
- Untuk pelanggan dengan kontrak dukungan – http://us.sios.com/support/overview/
- Hanya untuk pelanggan evaluasi – Dukungan pra-penjualan
Sumber daya tambahan: Langkah-demi-Langkah: Mengonfigurasi Cluster Multi-Situs 2-Node di Windows Server 2008 R2 – Bagian 1 — http://clusteringformeremortals.com/2009/09/15/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2%80%93 -Bagian 1/ Langkah-demi-Langkah: Mengonfigurasi Cluster Multi-Situs 2-Node di Windows Server 2008 R2 – Bagian 3 — http://clusteringformeremortals.com/2009/10/07/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2%80%93 -bagian-3/



