Date: November 18, 2021
Tag: SIOS

Pengantar Cluster – Bagian 1
Apa itu clustering?
Teknologi clustering adalah teknologi yang memungkinkan Anda untuk menghubungkan beberapa server untuk bertindak sebagai satu unit fungsional.
Jenis pengelompokan
Kamu bisa gugus server untuk beberapa tujuan. Misalnya, Anda dapat menggabungkan kekuatan pemrosesan beberapa server kecil untuk kinerja tinggi. Anda juga dapat mendistribusikan pekerjaan pemrosesan ke beberapa node menggunakan penyeimbang beban untuk efisiensi tambahan.
Pengelompokan ketersediaan tinggi (HA) adalah proses menggabungkan node server untuk melindungi aplikasi penting dari downtime dan kehilangan data.
Pengelompokan HA
Pengelompokan ketersediaan tinggi (HA) adalah mekanisme yang mengurangi waktu henti dengan menghilangkan titik kegagalan tunggal (SPOF). Dalam sebuah cluster HA, aplikasi penting dijalankan pada node utama yang terhubung ke satu atau lebih node sekunder atau remote dalam sebuah cluster. Perangkat lunak clustering memantau kesehatan aplikasi, server, dan jaringan. Jika terjadi kegagalan pada node utama, itu memindahkan operasi aplikasi ke node sekunder dalam proses yang disebut failover, di mana operasi berlanjut.
Ketersediaan Tinggi
Application high availability adalah ukuran berapa banyak waktu dalam satu tahun tertentu sebuah aplikasi tersedia dan beroperasi. Secara umum, kluster HA menyediakan 99,99% (Four nines) ketersediaan atau sedikit lebih dari 52 menit waktu henti selama tahun tertentu.
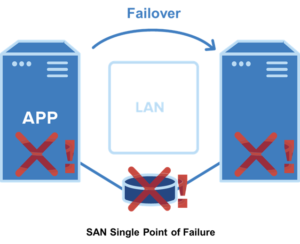
Penting untuk dicatat bahwa dalam klaster HA tradisional, semua node klaster terhubung ke penyimpanan bersama yang sama – biasanya SAN. Dengan cara ini, setelah failover, node sekunder mengakses data yang sama dengan node utama dan operasi dapat dilanjutkan.
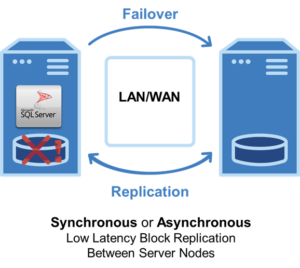
Cluster tanpa SAN
Namun, banyak perusahaan lebih suka menggunakan klaster SANless karena beberapa alasan. Pertama, penyimpanan bersama mewakili satu titik kegagalan kritis. Kedua, penyimpanan bersama seringkali bukan pilihan di lingkungan cloud publik. Ketiga, SAN terkadang dapat menghambat kinerja aplikasi database, seperti SQL Server, Oracle, dan SAP.
Alih-alih penyimpanan bersama, perusahaan-perusahaan ini menggunakan replikasi tingkat blok yang efisien, berbasis host, untuk menyinkronkan penyimpanan lokal di semua node cluster. Jika terjadi failover, node sekunder terhubung ke penyimpanan lokal dengan salinan identik dari penyimpanan utama. Ini tidak hanya menghilangkan risiko SAN SPOF tetapi juga memungkinkan penambahan fast disk (SSD) ke penyimpanan lokal lokal untuk kinerja tinggi yang hemat biaya. Pengelompokan SANless juga memungkinkan perusahaan untuk memigrasikan lingkungan HA lokal ke cloud dengan sedikit usaha atau gangguan proses bisnis yang sedang berlangsung.
Direproduksi dari SIOS