* 면책 조항: 다음은 당사 제품 범위 내에서 고가용성 부분을 완전히 다루지만 이것은 설정 “가이드”일 뿐이며 사용자 고유의 구성에 맞게 조정해야 합니다.
개요 화웨이 클라우드 는 중국뿐만 아니라 전 세계에 많은 데이터 센터가 있는 글로벌 기반을 갖춘 선도적인 클라우드 서비스 제공업체입니다. 그들은 ICT 인프라 제품 및 솔루션에 대한 화웨이의 30년 이상의 전문 지식을 결합하고 애플리케이션을 강화하고 데이터의 힘을 활용하며 오늘날 모든 규모의 조직이 성장하도록 돕기 위해 안정적이고 안전하며 비용 효율적인 클라우드 서비스를 제공하기 위해 최선을 다하고 있습니다. 지적인 세계. HUAWEI CLOUD는 또한 기술 혁신을 통해 저렴하고 효과적이고 안정적인 클라우드 및 AI 서비스를 제공하기 위해 노력하고 있습니다.
DataKeeper Cluster Edition은 Huawei 클라우드의 가용 영역 전반에 걸쳐 단일 지역 내의 가상 사설 클라우드(VPC)에서 복제를 제공합니다. 이 특정 SQL Server 클러스터링 예제에서는 4개의 인스턴스(도메인 컨트롤러 인스턴스 1개, SQL Server 인스턴스 2개 및 쿼럼/감시 인스턴스 1개)를 3개의 가용성 영역으로 시작합니다.
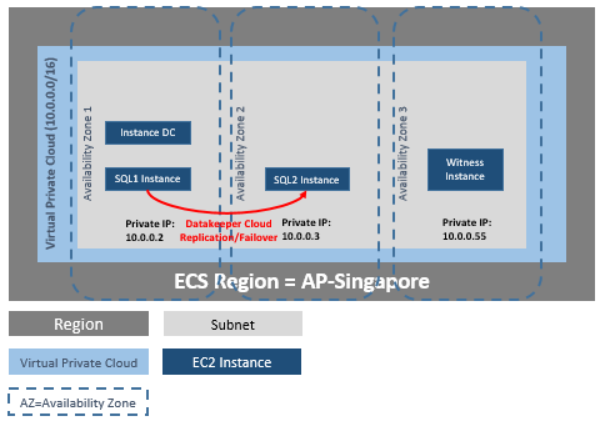
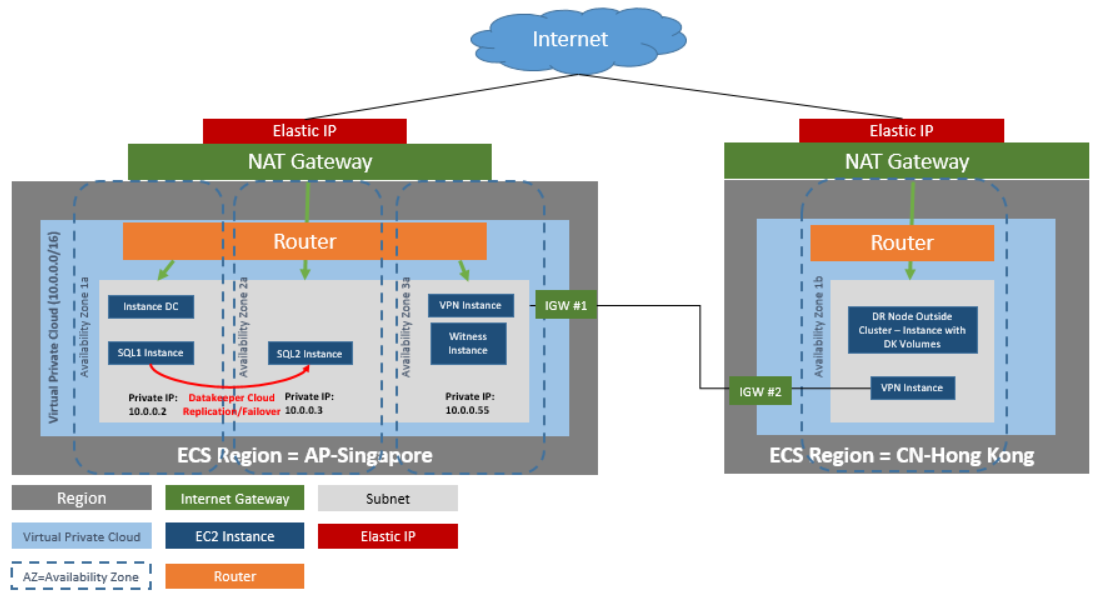
DataKeeper Cluster Edition은 Huawei 클라우드의 모든 노드와 함께 클러스터 외부의 데이터 복제 노드를 지원합니다. 이 특정 SQL Server 클러스터링 예제에서는 4개의 인스턴스(도메인 컨트롤러 인스턴스 1개, SQL Server 인스턴스 2개 및 쿼럼/감시 인스턴스 1개)가 3개의 가용성 영역으로 시작됩니다. 그런 다음 두 지역의 VPN 인스턴스를 포함하여 두 번째 지역에서 추가 DataKeeper 인스턴스가 시작됩니다. 봐주세요 클러스터 노드에서 외부 DR 사이트로 데이터 복제 구성 자세한 내용은. 여러 지역 사용에 대한 추가 정보는 다음을 참조하십시오. 서로 다른 지역에 있는 두 VPC 연결 .
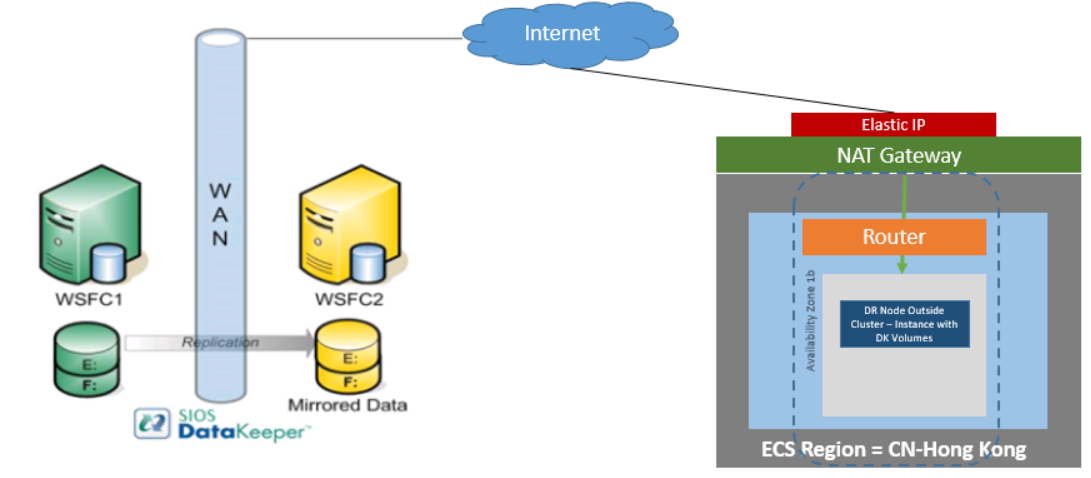
DataKeeper Cluster Edition은 또한 Huawei Cloud의 클러스터 외부에 있는 노드만 있는 클러스터 외부의 데이터 복제 노드에 대한 지원을 제공합니다. 이 특정 SQL Server 클러스터링 예제에서 WSFC1 및 WSFC2는 Huawei Cloud 인스턴스로 복제하는 온사이트 클러스터에 있습니다. 그런 다음 Huawei Cloud의 한 지역에서 추가 DataKeeper 인스턴스가 시작됩니다. 봐주세요 클러스터 노드에서 외부 DR 사이트로 데이터 복제 구성 자세한 내용은.
요구 사항
| 설명 | 요구 사항 |
| 가상 사설 클라우드 | 3개의 가용 영역이 있는 단일 지역에서 |
| 인스턴스 유형 | 최소 권장 인스턴스 유형: s3.large.2 |
| 운영 체제 | DKCE 지원 매트릭스 보기 |
| 탄력적 IP | 도메인 컨트롤러에 연결된 하나의 탄력적 IP 주소 |
| 4개의 인스턴스 | 도메인 컨트롤러 인스턴스 1개, SQL Server 인스턴스 2개 및 쿼럼/감시 인스턴스 1개 |
| 각 SQL 서버 | 4개의 IP가 있는 ENI(탄력적 네트워크 인터페이스) · Windows에서 정적으로 정의되고 DataKeeper Cluster Edition에서 사용되는 기본 ENI IP · Windows Failover Clustering, DTC 및 SQLFC에서 사용되는 동안 ECS에서 유지 관리하는 3개의 IP |
| 볼륨 | 3개의 볼륨(EBS 및 NTFS만 해당) · 1개의 기본 볼륨(C 드라이브) · 2개의 추가 볼륨 o 장애 조치 클러스터링용 1개 o MSDTC용 1개 |
릴리즈 노트 시작하기 전에 DataKeeper 클러스터 에디션 출시 정보 최신 정보를 위해. 읽고 이해하는 것이 좋습니다. DataKeeper 클러스터 에디션 설치 가이드 .
가상 사설 클라우드(VPC) 생성 가상 사설 클라우드는 DataKeeper Cluster Edition을 사용할 때 생성하는 첫 번째 개체입니다.
* 가상 사설 클라우드(VPC)는 공용 클라우드에서 구성 가능한 공유 컴퓨팅 리소스 풀로 구성된 격리된 사설 클라우드입니다.
- 회원가입 시 지정한 이메일 주소와 비밀번호 사용 화웨이 클라우드 , 로그인 화웨이 클라우드 관리 콘솔 .
- 로부터 서비스 드롭다운, 선택 가상 사설 클라우드 .
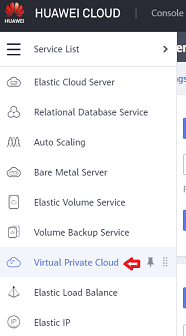
- 화면 오른쪽에서 다음을 클릭합니다. VPC 생성 사용하려는 지역을 선택합니다.
- VPC에 사용할 이름을 입력하십시오.
- 다음을 입력하여 가상 사설 클라우드 서브넷을 정의합니다. CIDR(클래스 없는 도메인 간 라우팅) 아래에 설명된 대로
- 서브넷 이름을 입력한 다음 클릭 지금 만들기 .
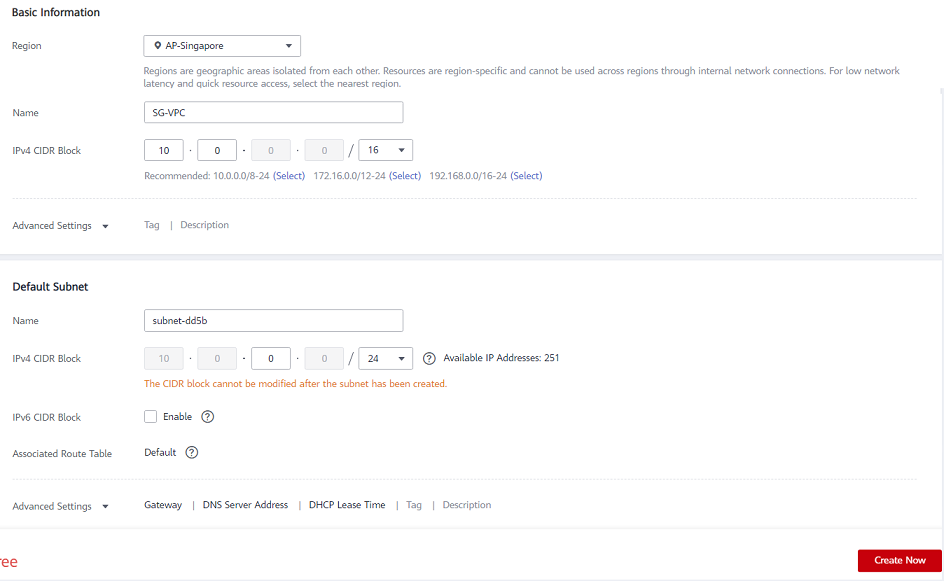
* 새 VPC에 대한 “기본” 연결을 사용하여 라우팅 테이블이 자동으로 생성됩니다. 나중에 사용하거나 다른 라우팅 테이블을 생성할 수 있습니다.
* 유용한 링크: 화웨이의 가상 사설 클라우드(VPC) 생성 인스턴스 시작 다음은 서브넷으로 인스턴스를 시작하는 과정을 안내합니다. 두 개의 인스턴스를 하나의 가용성 영역으로 시작하려고 할 것입니다. 하나는 도메인 컨트롤러 인스턴스용이고 다른 하나는 SQL 인스턴스용입니다. 그런 다음 다른 가용 영역으로 다른 SQL 인스턴스를 시작하고 또 다른 가용 영역으로 쿼럼 감시 인스턴스를 시작합니다.
* 유용한 링크: 화웨이 클라우드 ECS 인스턴스
- 회원가입 시 지정한 이메일 주소와 비밀번호 사용 화웨이 클라우드 , 로그인 화웨이 클라우드 관리 콘솔 .
- 로부터 서비스 목록 드롭다운, 선택 탄력적 클라우드 서버 .

- 선택하다 ECS 구매 버튼을 누르고 결제 모드, 리전 및 AZ(가용 영역)를 선택하여 인스턴스를 배포합니다.
- 인스턴스 유형을 선택합니다. ( 메모: s3.large.2 이상을 선택하십시오.).
- 이미지를 선택합니다. 공개 이미지에서 Windows Server 2019 데이터 센터 64비트 영어 영상
- 을위한 네트워크 구성 , VPC를 선택하십시오.
- 을위한 서브넷 , 사용하려는 서브넷을 선택하고 수동으로 지정한 IP 주소 사용하려는 IP 주소를 입력하십시오.
- 선택 보안 그룹 사용하거나 기존 것을 편집하고 선택합니다.
- EIP 할당 인터넷에 액세스하기 위해 ECS 인스턴스가 필요한 경우
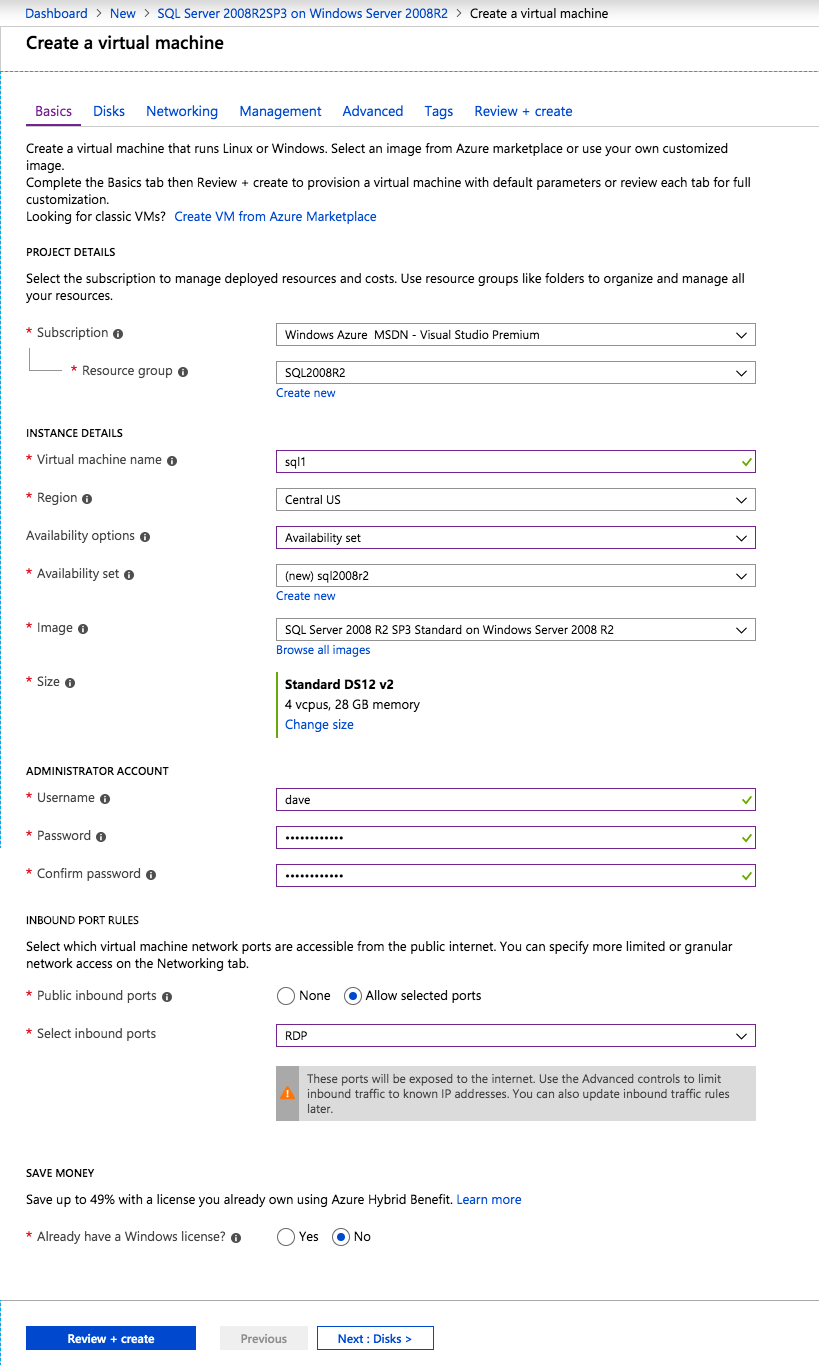
- 딸깍 하는 소리 고급 설정 구성 ECS의 이름을 제공하고 비밀번호 ~을위한 로그인 모드 관리자 로그인을 위한 보안 암호 제공
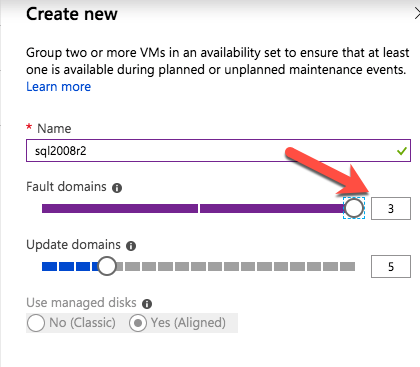
- 딸깍 하는 소리 지금 구성 ~에 고급 옵션 을 추가하다 꼬리표 인스턴스 이름을 지정하고 확인하다
- 인스턴스의 최종 검토를 수행하고 제출하다 .
* 중요한: 이 초기 관리자 암호를 기록해 두십시오. 인스턴스에 로그온하는 데 필요합니다.
모든 인스턴스에 대해 위의 단계를 반복합니다.
인스턴스에 연결 다음을 통해 도메인 컨트롤러 인스턴스에 연결할 수 있습니다. 원격 로그인 ECS 창에서.
관리자로 로그인하고 다음을 입력하십시오. 관리자 비밀번호 .
* 모범 사례: 로그인한 후에는 비밀번호를 변경하는 것이 가장 좋습니다.
도메인 컨트롤러 인스턴스 구성 이제 인스턴스가 생성되었으므로 도메인 서비스 인스턴스 설정을 시작했습니다.
이 가이드는 Active Domain 서버 인스턴스를 설정하는 방법에 대한 자습서가 아닙니다. 읽기를 권장합니다 조항 Active Directory 서버를 설정하고 구성하는 방법에 대해 설명합니다. 인스턴스가 Huawei 클라우드에서 실행 중이더라도 이것은 Active Directory의 일반 설치임을 이해하는 것이 매우 중요합니다.
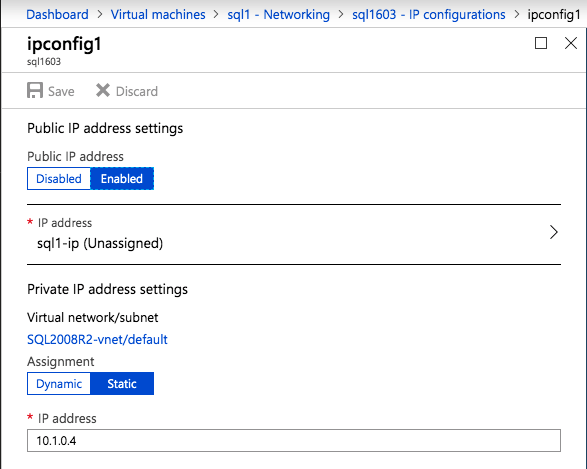
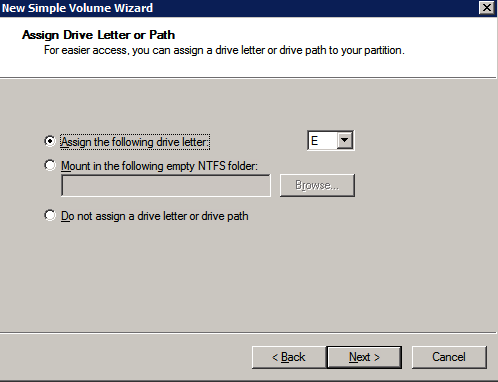
고정 IP 주소 인스턴스에 대한 고정 IP 주소 구성
- 도메인 컨트롤러 인스턴스에 연결합니다.
- 딸깍 하는 소리 시작 / 제어판 .
- 딸깍 하는 소리 네트워크 및 공유 센터 .
- 네트워크 인터페이스를 선택하십시오.
- 딸깍 하는 소리 속성 .
- 딸깍 하는 소리 인터넷 프로토콜 버전 4(TCP/IPv4) , 그 다음에 속성 .
- 현재 얻기 IPv4 주소 , 기본 게이트웨이 그리고 DNS 서버 네트워크 인터페이스의 경우 아마존 .
- 에서 인터넷 프로토콜 버전 4(TCP/IPv4) 속성 대화 상자, 아래 다음 IP 주소 사용 , 귀하의 IPv4 주소 .
- 에서 서브넷 마스크 상자에 가상 사설 클라우드 서브넷과 연결된 서브넷 마스크를 입력합니다.
- 에서 기본 게이트웨이 상자에 입력 IP 주소 기본 게이트웨이의 다음을 클릭합니다. 좋아요 .
- 를 위해 선호하는 DNS 서버 , 들어가다 도메인 컨트롤러의 기본 IP 주소 (예: 15.0.1.72).
- 딸깍 하는 소리 괜찮아 , 선택 닫다 . 출구 네트워크 및 공유 센터 .
- 다른 인스턴스에서 위의 단계를 반복합니다.
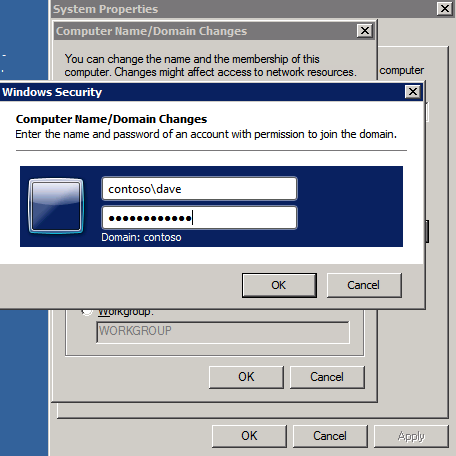
두 개의 SQL 인스턴스와 증인 인스턴스를 도메인에 조인 * 도메인에 가입하기 전에 이러한 네트워크 조정을 수행하십시오. 네트워크 어댑터에서 기본 설정 DNS 서버를 새 도메인 컨트롤러 주소와 해당 DNS 서버로 추가/변경합니다. 이 변경 후 DNS 검색 목록을 새로 고치려면 ipconfig /flushdns를 사용하십시오. 도메인 가입을 시도하기 전에 이 작업을 수행하십시오.
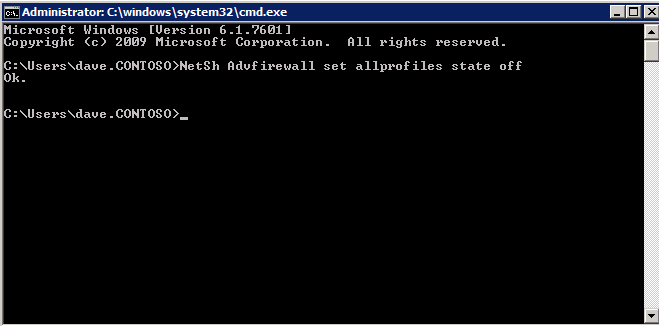
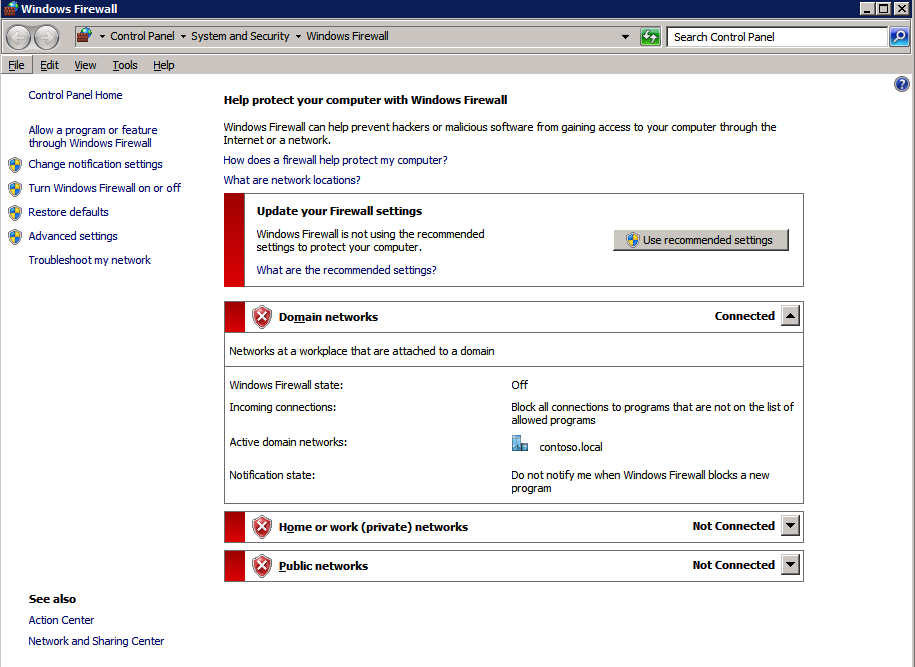
* 다음을 확인하십시오. 핵심 네트워킹 그리고 파일 및 프린터 공유 옵션은 Windows 방화벽에서 허용됩니다.
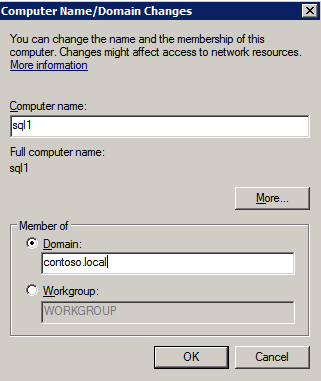
- 각 인스턴스에서 시작 을 클릭한 다음 마우스 오른쪽 버튼을 클릭합니다. 컴퓨터 그리고 선택 속성 .
- 맨 오른쪽에서 설정 변경 .
- 클릭 변화 .
- 새로 입력 컴퓨터 이름 .
- 선택하다 도메인 .
- 입력하다 도메인 이름 – (예: docs.huawei.com).
- 딸깍 하는 소리 적용하다 .
* 사용하다 제어판 모든 인스턴스가 해당 위치에 올바른 시간대를 사용하고 있는지 확인합니다.
* 모범 사례: 시스템 페이지 파일을 다음으로 설정하는 것이 좋습니다. 시스템 관리 (자동이 아님) 항상 C: 드라이브를 사용합니다.
제어판 > 고급 시스템 설정 > 성능 > 설정 > 고급 > 가상 메모리. 선택하다 시스템 관리 크기 , 볼륨 C: 만 선택한 다음 세트 저장합니다.
두 개의 SQL 인스턴스에 보조 프라이빗 IP 할당 기본 IP 외에도 각 SQL 인스턴스의 탄력적 네트워크 인터페이스에 3개의 추가 IP(보조 IP)를 추가해야 합니다.
- 로부터 서비스 목록 드롭다운, 선택 탄력적 클라우드 서버 .
- 보조 사설 IP 주소를 추가하려는 인스턴스를 클릭합니다.
- 선택하다 NIC > 가상 IP 주소 관리 .
- 클릭 가상 IP 주소 할당 그리고 선택 설명서 인스턴스의 서브넷 범위 내에 있는 IP 주소를 입력합니다(예: 15.0.1.25의 경우 15.0.1.26을 입력합니다. 딸깍 하는 소리 확인 .
- 클릭 더 IP 주소 행에서 드롭다운을 선택하고 서버에 바인딩 , IP 주소를 바인딩할 서버와 NIC 카드를 선택합니다.
- 딸깍 하는 소리 좋아요 작업을 저장합니다.
- 에서 위의 작업을 수행합니다. 두 SQL 인스턴스 .
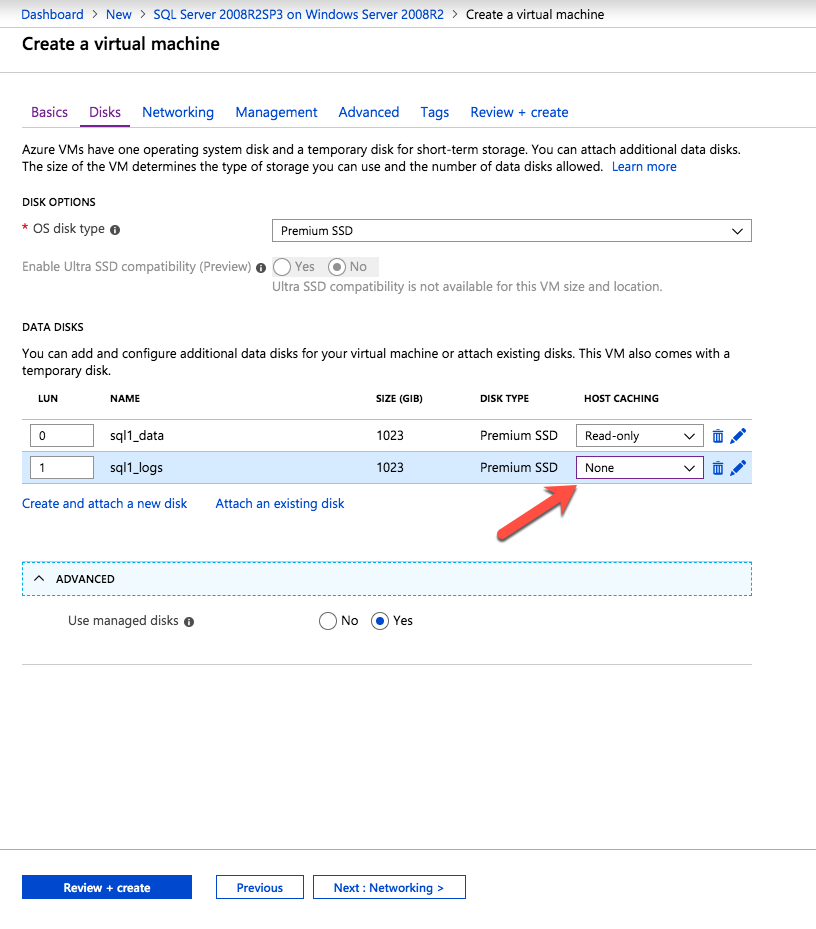
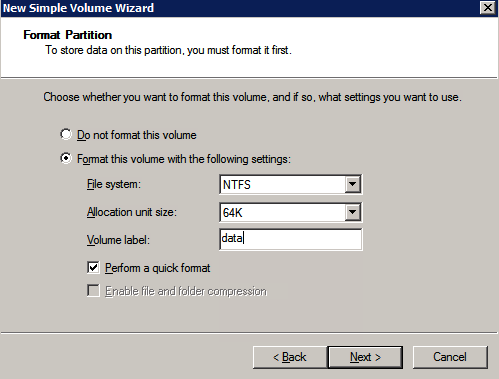
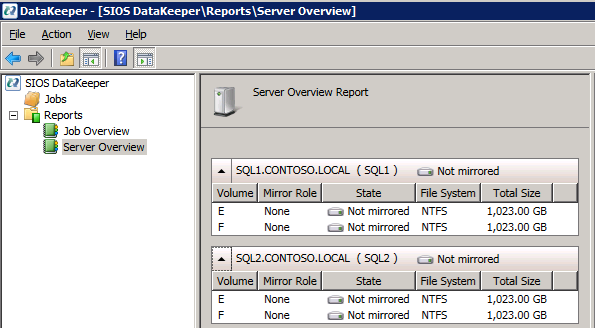
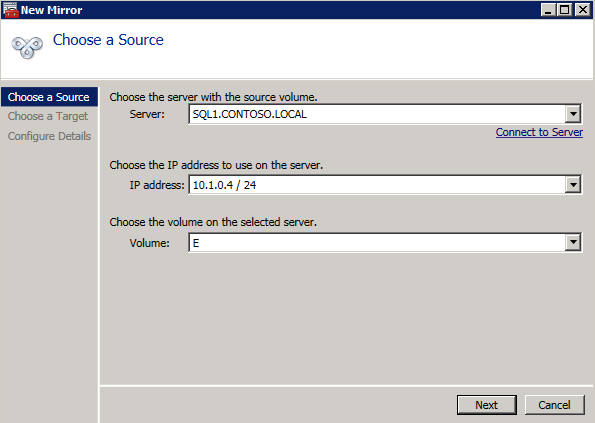
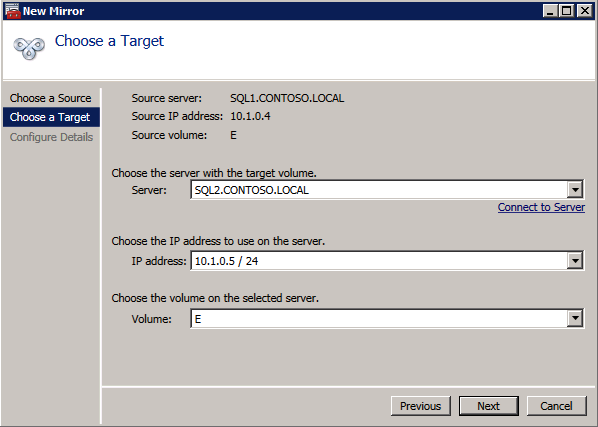
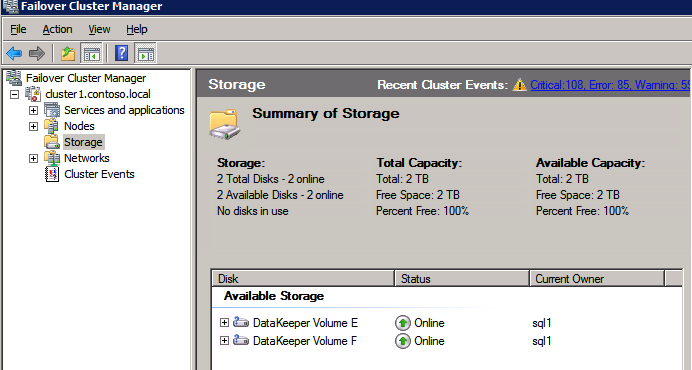
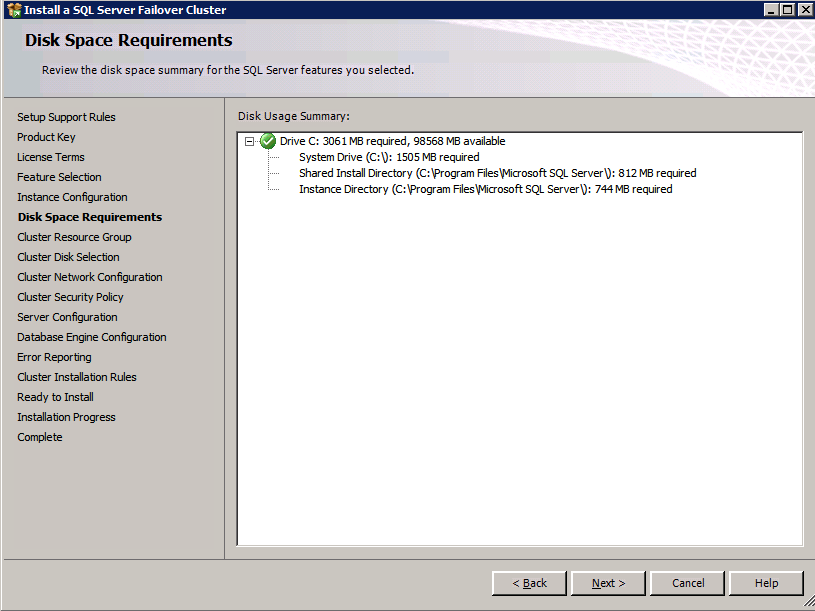
* 유용한 링크: 가상 IP 주소 관리 가상 IP 주소를 EIP 또는 ECS에 바인딩 볼륨 생성 및 연결 DataKeeper는 블록 수준 볼륨 복제 솔루션이며 클러스터의 각 노드에는 크기와 드라이브 문자가 동일한 추가 볼륨(시스템 드라이브 제외)이 있어야 합니다. 검토하시기 바랍니다 볼륨 고려 사항 저장 요구 사항에 대한 추가 정보는
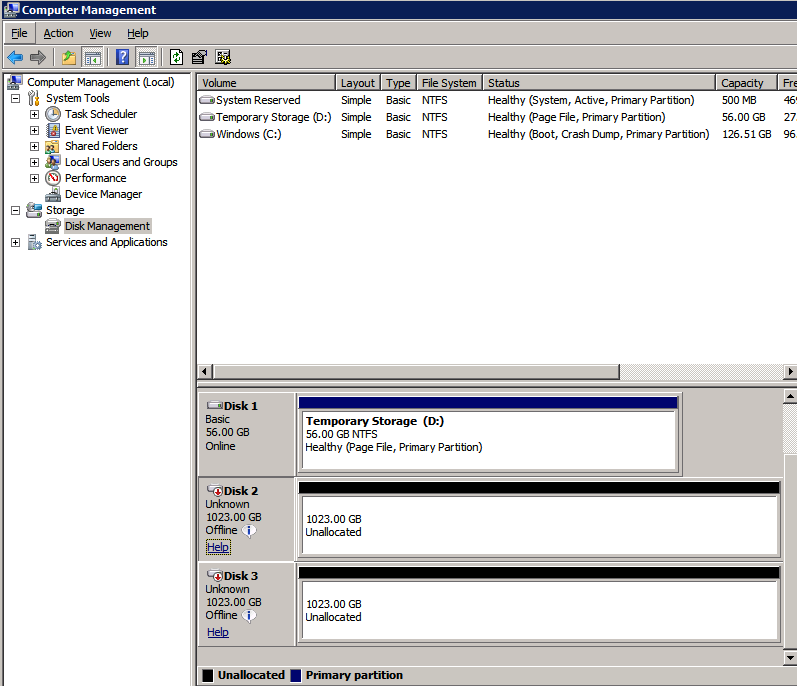
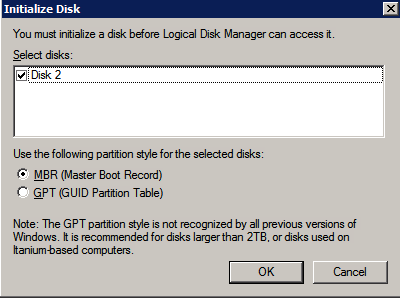
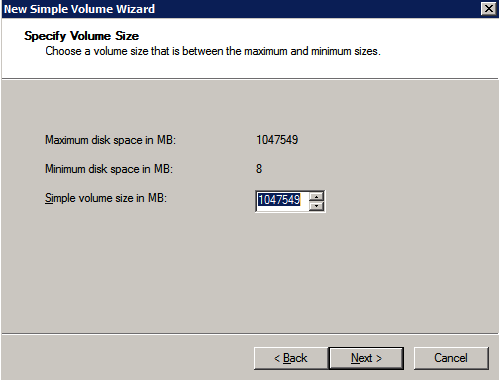
볼륨 생성 각 SQL Server 인스턴스에 대해 각 가용성 영역에 2개의 볼륨을 생성하여 총 4개의 볼륨을 생성합니다.
- 로부터 서비스 목록 드롭다운, 선택 탄력적 클라우드 서버 .
- 관리하려는 인스턴스를 클릭합니다.
- 로 이동 디스크 탭
- 딸깍 하는 소리 디스크 추가 원하는 크기와 크기의 새 볼륨을 추가하려면 볼륨을 연결할 SQL 서버와 동일한 AZ에 있는 볼륨을 선택해야 합니다.
- SLA에 동의하는 확인란을 선택하고 제출하다
- 딸깍 하는 소리 서버 콘솔로 돌아가기
- 붙이다 SQL 인스턴스에 필요한 경우 디스크
- 네 권 모두에 대해 이 작업을 수행합니다.
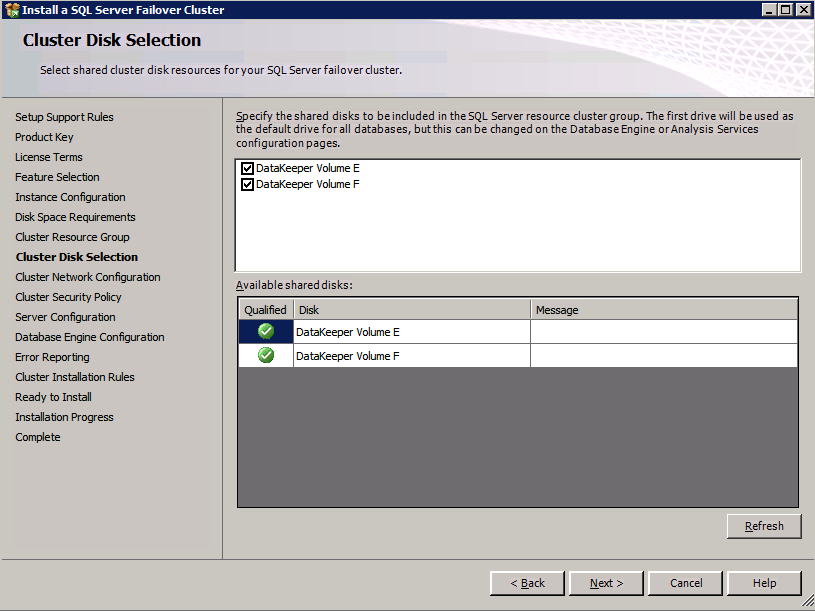
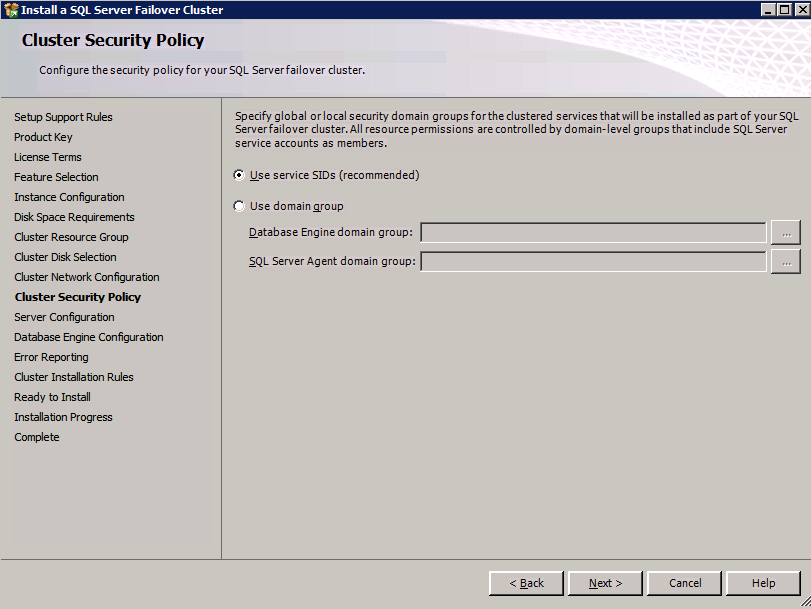
* 유용한 링크: 탄력적 볼륨 서비스 클러스터 구성 DataKeeper Cluster Edition을 설치하기 전에 노드 과반수 쿼럼(노드 수가 홀수인 경우) 또는 노드 및 파일 공유 과반수 쿼럼(짝수가 있는 경우)을 사용하여 Windows Server를 클러스터로 구성하는 것이 중요합니다. 노드). 단계별 지침은 이 항목 외에 클러스터링에 대한 Microsoft 설명서를 참조하십시오.메모: 마이크로소프트가 발표한 핫픽스 특정 다중 사이트 클러스터 구성에서 더 높은 수준의 가용성을 달성하는 데 도움이 될 수 있는 노드의 투표를 비활성화할 수 있는 Windows 2008R2용.
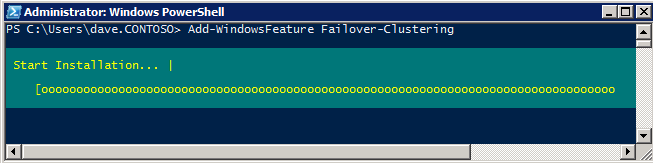
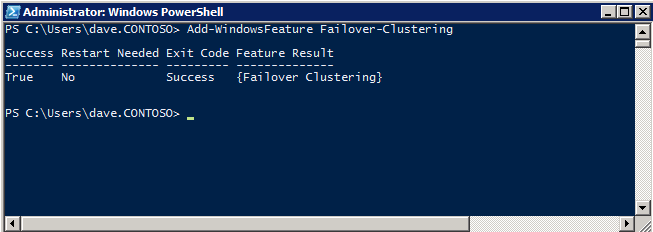
장애 조치 클러스터링 추가 두 SQL 인스턴스에 장애 조치 클러스터링 기능을 추가합니다.
- 시작하다 서버 매니저 .
- 선택하다 특징 왼쪽 창에서 기능 추가 에서 특징 이것은 시작 기능 추가 마법사 .
- 선택하다 장애 조치 클러스터링 .
- 선택하다 설치 .
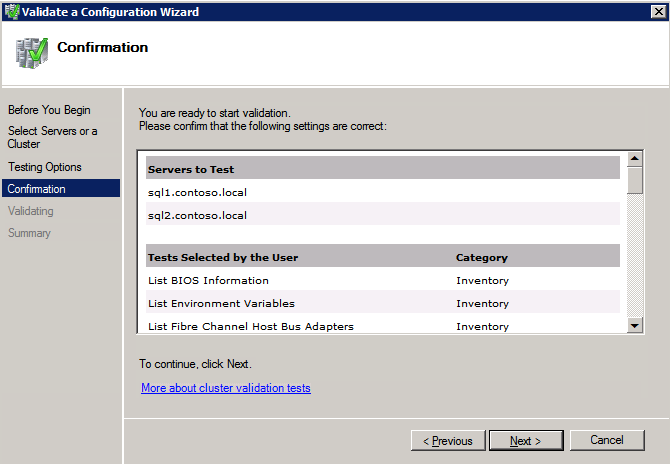
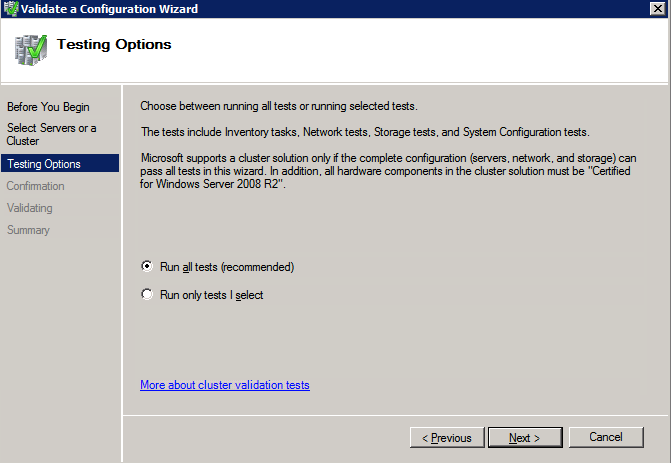
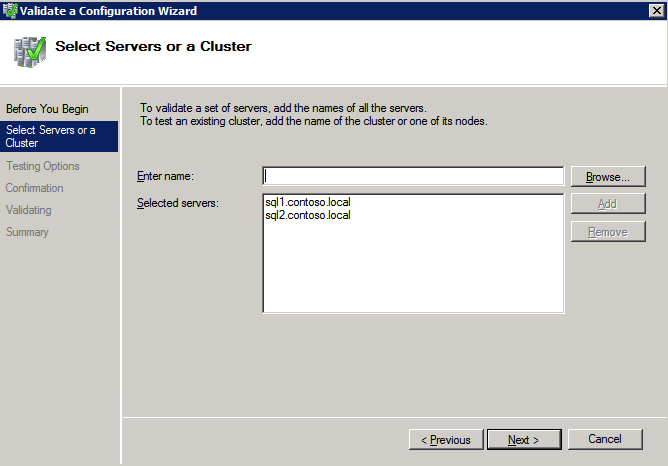
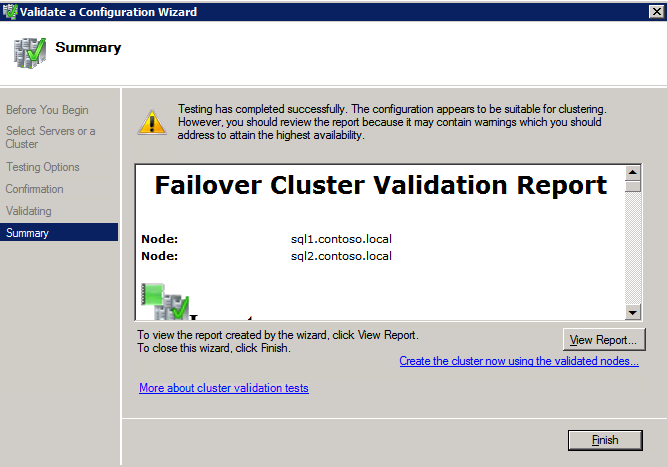
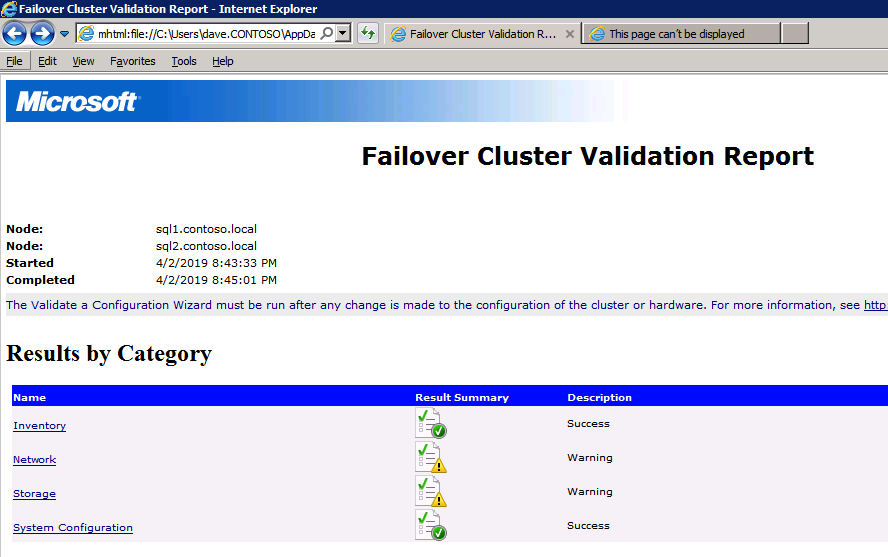
구성 검증
- 열려있는 장애 조치 클러스터 관리자 .
- 장애 조치(Failover) 클러스터 관리자를 선택하고 구성 검증 .
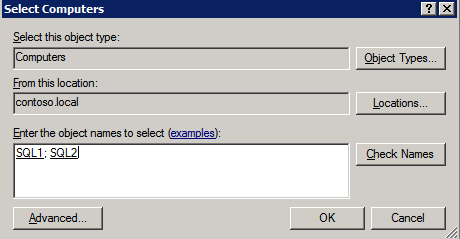
- 딸깍 하는 소리 다음 , 다음 두 개를 추가하십시오 SQL 인스턴스 .
메모: 검색하려면 다음을 선택하십시오. 검색 을 클릭한 다음 고급의 그리고 지금 찾기 . 사용 가능한 인스턴스가 나열됩니다.
- 딸깍 하는 소리 다음 .
- 선택하다 내가 선택한 테스트만 실행 클릭 다음 .
- 에서 테스트 선택 화면, 선택 해제 저장 클릭 다음 .
- 결과 확인 화면에서 다음 .
- 검토 검증 요약 보고서 그런 다음 클릭 마치다 .
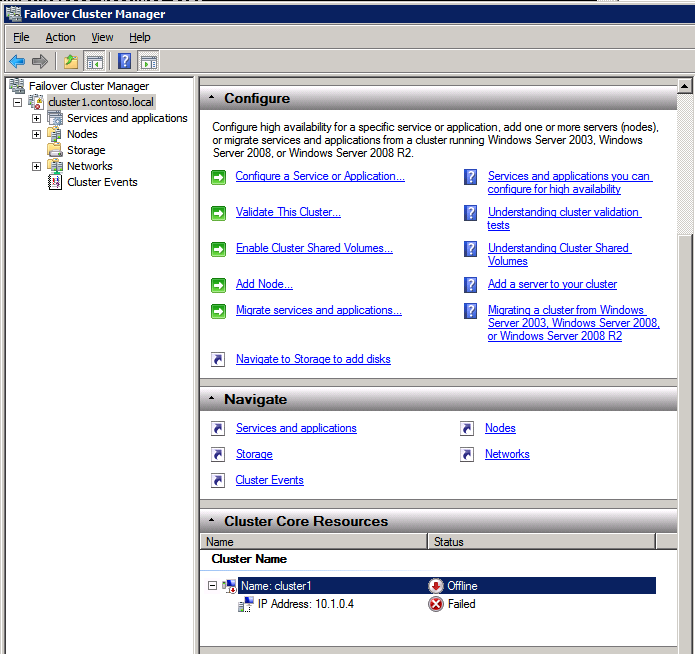
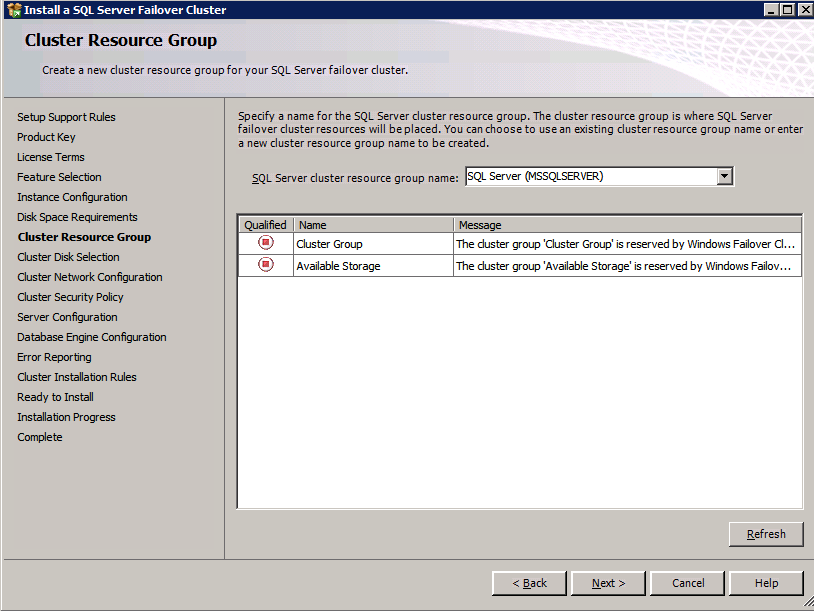
클러스터 생성
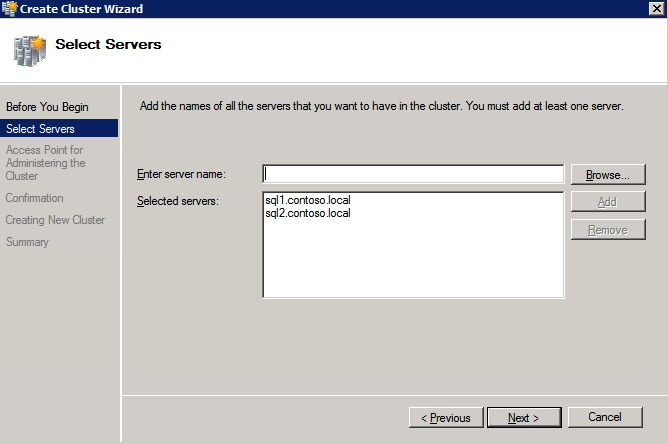
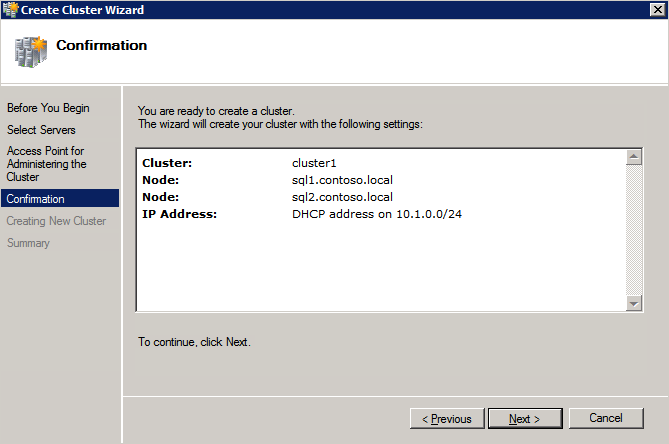
- 에 장애 조치 클러스터 관리자 , 클릭 클러스터 생성 그런 다음 클릭 다음 .
- 두 개를 입력하세요 SQL 인스턴스 .
- 에 검증 경고 페이지, 선택 아니요 그런 다음 클릭 다음 .
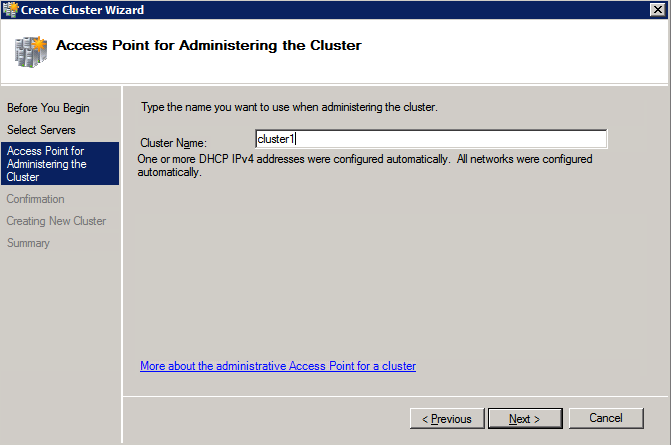
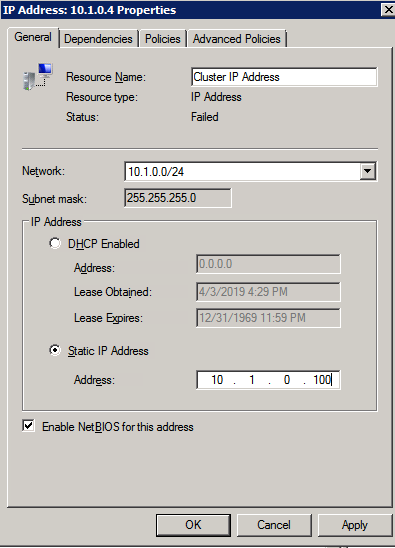
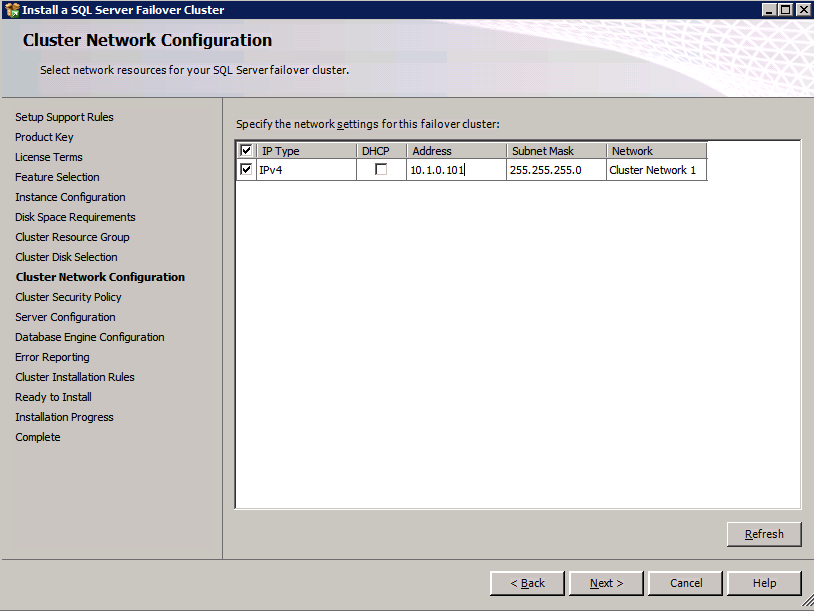
- 에 클러스터 관리를 위한 액세스 포인트 페이지에서 WSFC 클러스터의 고유한 이름을 입력합니다. 그런 다음 입력 장애 조치 클러스터링 IP 주소 클러스터에 관련된 각 노드에 대해 이것은 3가지 중 첫 번째 보조 IP 주소 각 인스턴스에 이전에 추가되었습니다.
- 중요! “클러스터에 사용 가능한 모든 스토리지 추가” 확인란의 선택을 취소하십시오. DataKeeper 미러링 드라이브는 기본적으로 클러스터에서 관리하면 안 됩니다. DataKeeper 볼륨으로 관리됩니다.
- 딸깍 하는 소리 다음 에 확인
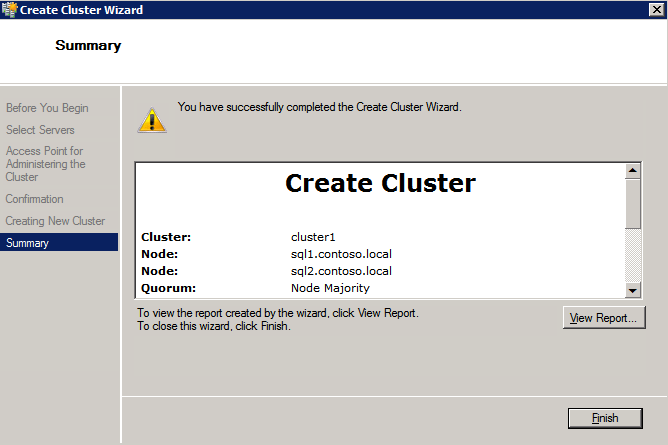
- 에 요약 페이지에서 경고를 검토한 다음 선택 마치다 .
쿼럼/감시 구성
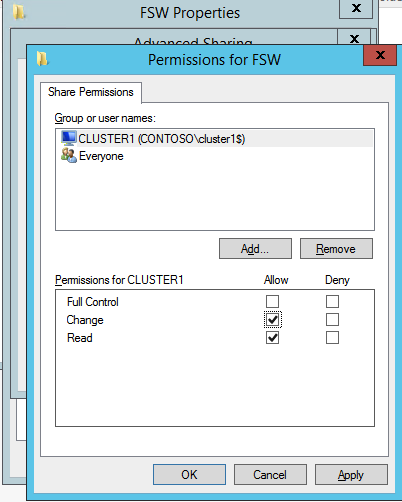
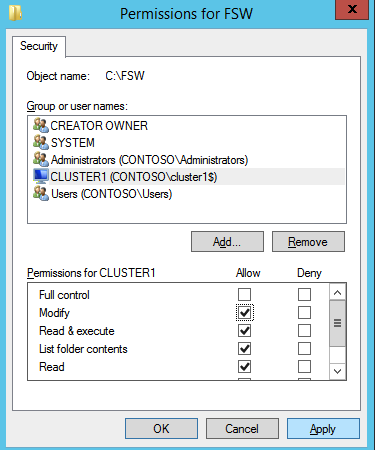
- 쿼럼/감시 인스턴스(감시)에 폴더를 만듭니다.
- 폴더를 공유합니다.
- 폴더를 마우스 오른쪽 버튼으로 클릭하고 선택 공유/특정 사람들과 공유 ….
- 드롭다운에서 모든 사람 클릭 추가하다 .
- 아래에 권한 수준 , 선택하다 읽기/쓰기 .
- 딸깍 하는 소리 공유하다 , 그 다음에 완료 . (아래에서 사용할 이 파일 공유의 경로를 기록해 두십시오.)
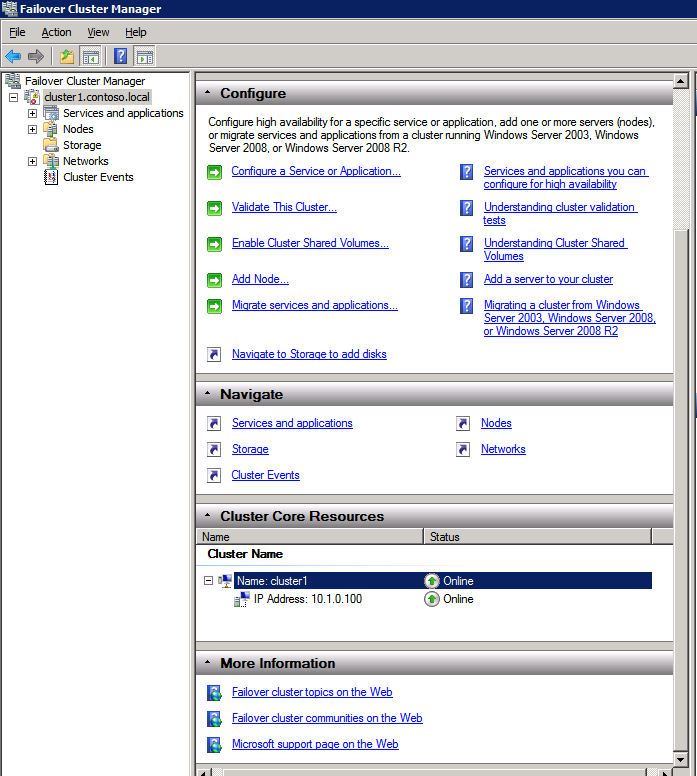
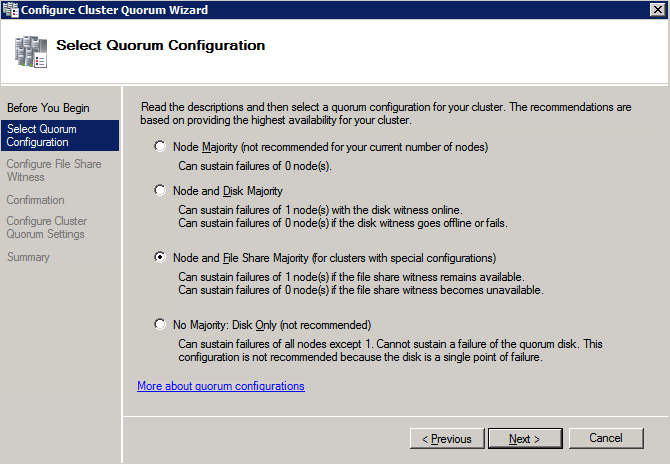
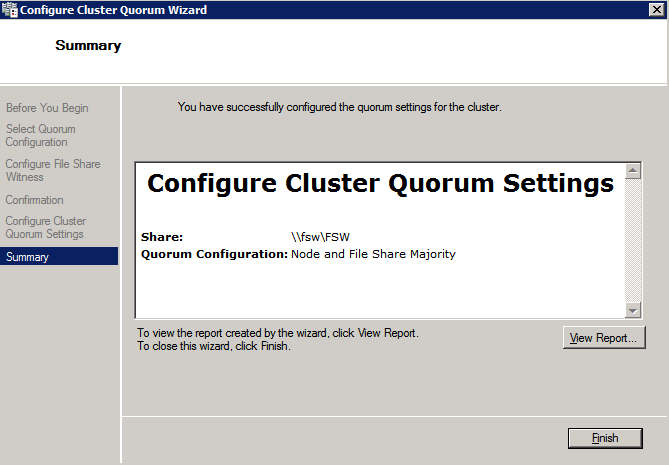
- 에 장애 조치 클러스터 관리자 , 클러스터를 마우스 오른쪽 버튼으로 클릭하고 더 많은 행동 그리고 클러스터 쿼럼 설정 구성 . 딸깍 하는 소리 다음 .
- 에 쿼럼 구성 선택 , 선택하다 노드 및 파일 공유 과반수 클릭 다음 .
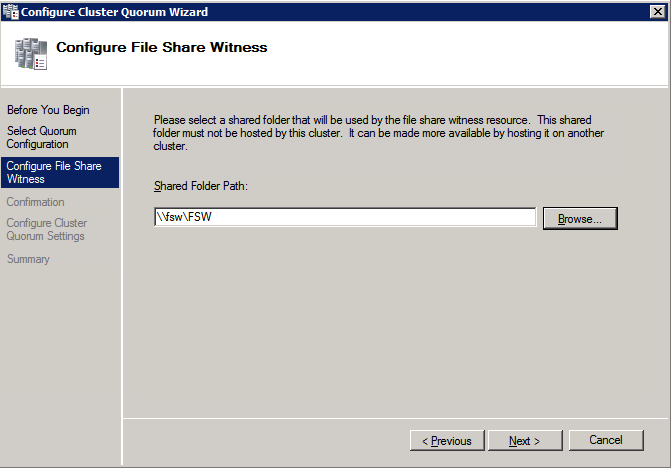
- 에 파일 공유 감시 구성 화면에서 이전에 생성한 파일 공유 경로를 입력하고 다음 .
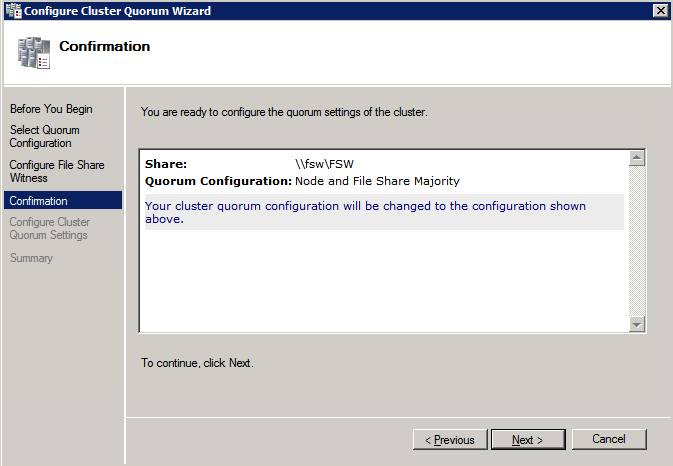
- 에 확인 페이지, 클릭 다음 .
- 에 요약 페이지, 클릭 마치다 .
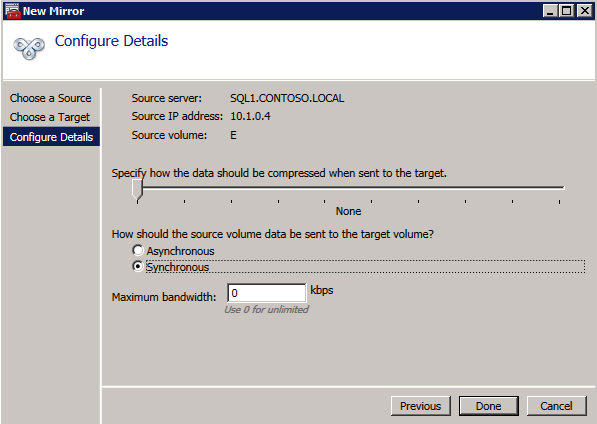
DataKeeper 설치 및 구성 기본 클러스터가 구성된 후 클러스터 리소스가 생성되기 전에 설치하고 라이선스를 부여합니다. DataKeeper 클러스터 에디션 모든 클러스터 노드에서. 참조 DataKeeper 클러스터 에디션 설치 가이드 자세한 지침은.
- 운영 데이터 키퍼 설정 설치하기 위해서 DataKeeper 클러스터 에디션 두 SQL 인스턴스 모두에서.
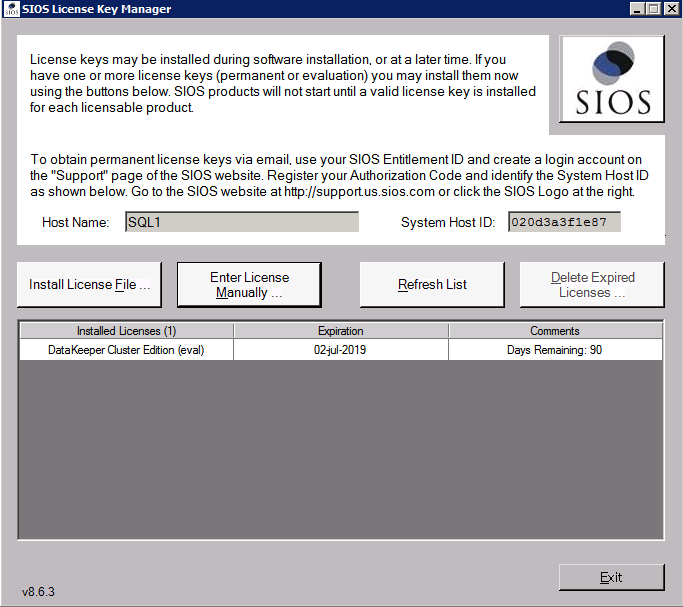
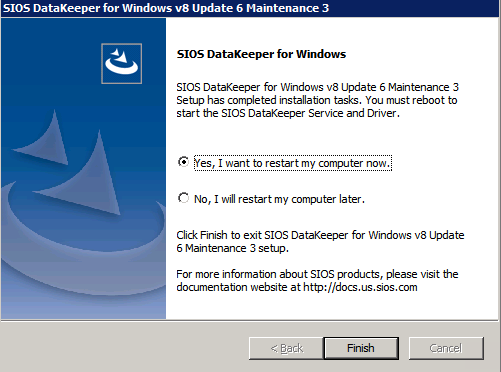
- 귀하의 라이센스 키 메시지가 표시되면 재부팅합니다.
- 시작 데이터키퍼 GUI 그리고 서버에 연결 .
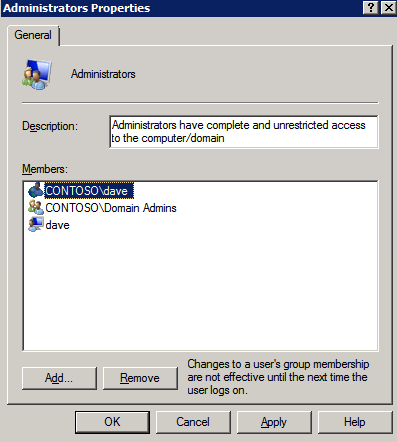
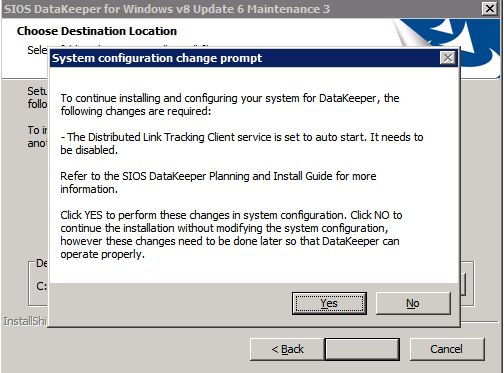
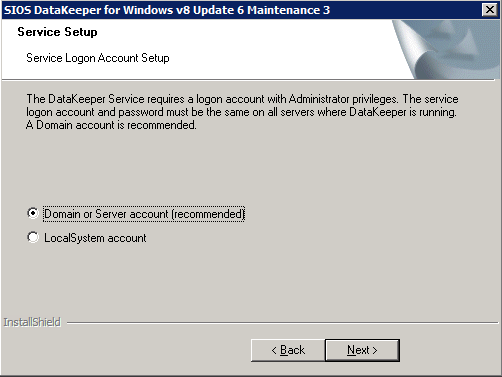
* 메모 : 사용된 도메인 또는 서버 계정은 로컬 시스템 관리자 그룹에 추가되어야 합니다. 계정에는 DataKeeper가 설치된 각 서버에 대한 관리자 권한이 있어야 합니다. 인용하다 DataKeeper 서비스 로그온 ID 및 비밀번호 선택 추가 정보를 위해.
- 오른쪽 클릭 채용정보 두 SQL 서버에 모두 연결합니다.
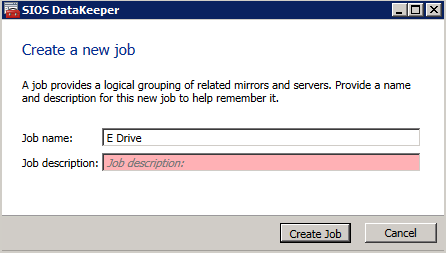
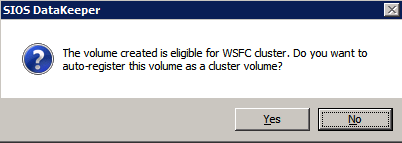
- 작업 만들기 생성할 각 미러에 대해 하나는 DTC 리소스용이고 다른 하나는 SQL 리소스용입니다.
- 볼륨을 클러스터 볼륨으로 자동 등록할지 묻는 메시지가 표시되면 예 .
* 메모: Windows “Core”(GUI가 없는 Windows)에 DataKeeper Cluster Edition을 설치하는 경우 다음을 읽으십시오. Windows 2008R2/2012 Server Core 플랫폼에 DataKeeper 설치 및 사용 자세한 지침은.
MSDTC 구성
- Windows Server 2012 및 2016의 경우 장애 조치 클러스터 관리자 GUI , 선택하다 역할 , 선택 역할 구성 .
- 선택하다 분산 트랜잭션 코디네이터(DTC) , 클릭 다음 .
* Windows Server 2008의 경우 장애 조치 클러스터 관리자 GUI , 선택하다 서비스 및 애플리케이션 , 선택 서비스 또는 애플리케이션 구성 클릭 다음 .
- 에 클라이언트 액세스 포인트 화면에서 이름을 입력한 다음 MSDTC IP 주소 클러스터에 관련된 각 노드에 대해 이것은 셋 중 두 번째다. 보조 IP 주소 각 인스턴스에 이전에 추가되었습니다. 딸깍 하는 소리 다음 .
- 선택 MSDTC 볼륨 클릭 다음 .
- 에 확인 페이지, 클릭 다음 .
- 일단 요약 페이지 표시, 클릭 마치다 .
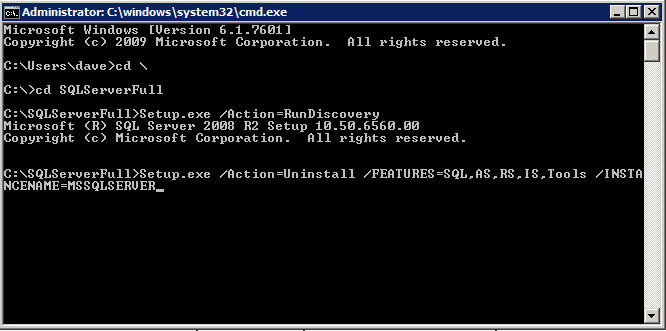
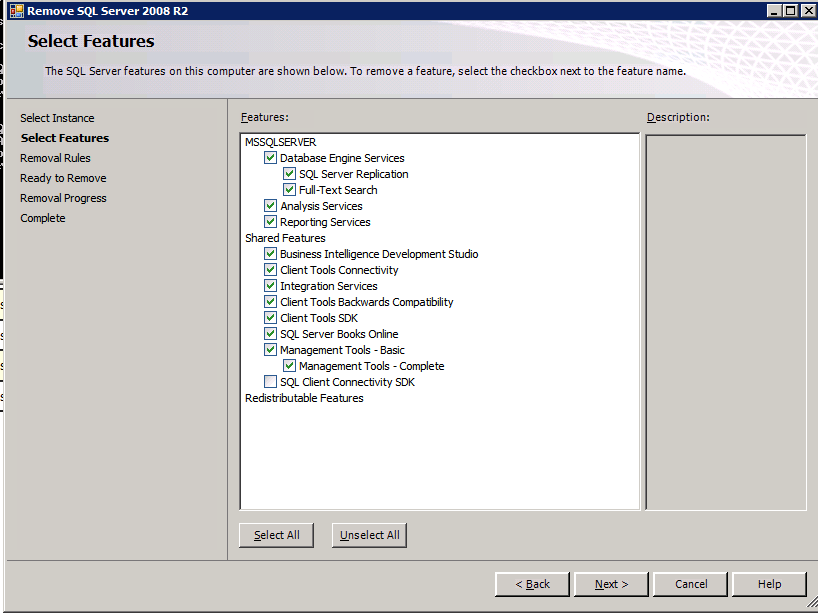
첫 번째 SQL 인스턴스에 SQL 설치
- 도메인 컨트롤러 서버에서 폴더를 만들고 공유합니다..
- 예를 들어 모든 사람 권한이 있는 “TEMPSHARE”입니다.
- “SQL” 하위 폴더를 만들고 SQL .iso 설치 프로그램을 해당 하위 폴더에 복사합니다.
- SQL 서버에서 네트워크 드라이브를 만들고 도메인 컨트롤러의 공유 폴더에 연결합니다.
- . 예: “net use S: \TEMPSHARE
- SQL 서버에 S: 드라이브가 나타납니다. CD를 SQL 폴더에 넣고 SQL .iso 설치 프로그램을 찾습니다. .iso 파일을 마우스 오른쪽 버튼으로 클릭하고 산 . setup.exe 설치 프로그램이 SQL .iso 설치 프로그램과 함께 나타납니다.
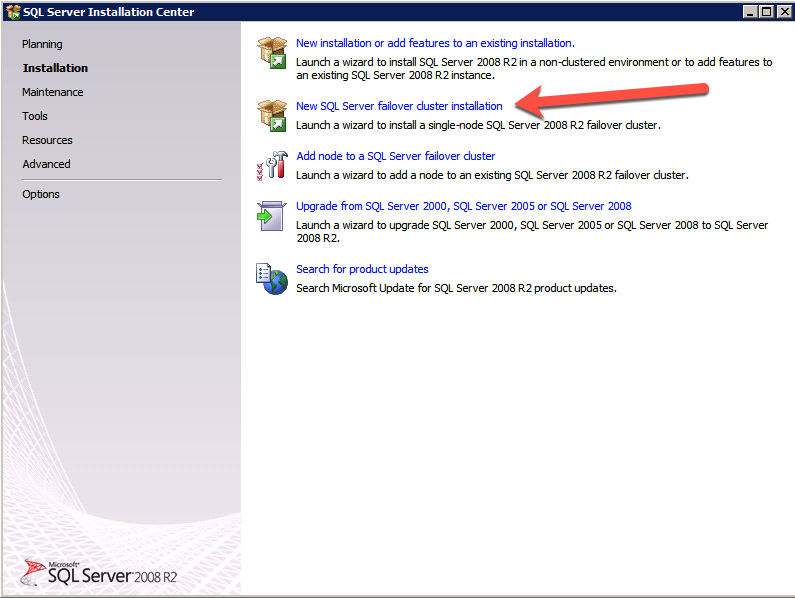
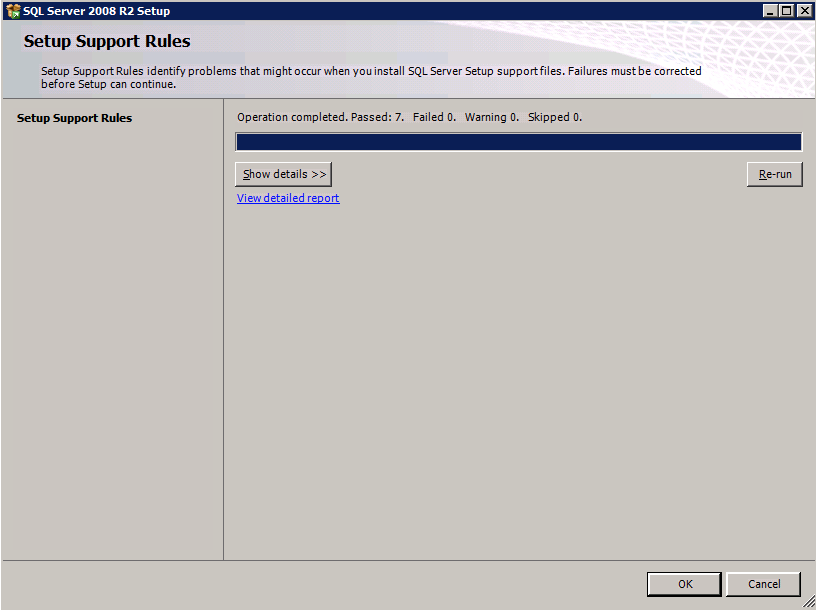
F:>설정 /SkipRules=Cluster_VerifyForErrors /Action=InstallFailoverCluster
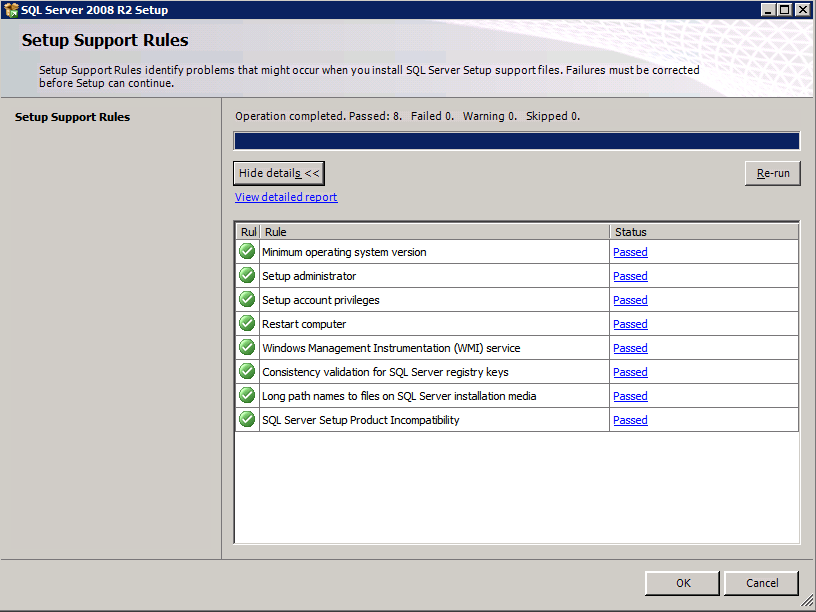
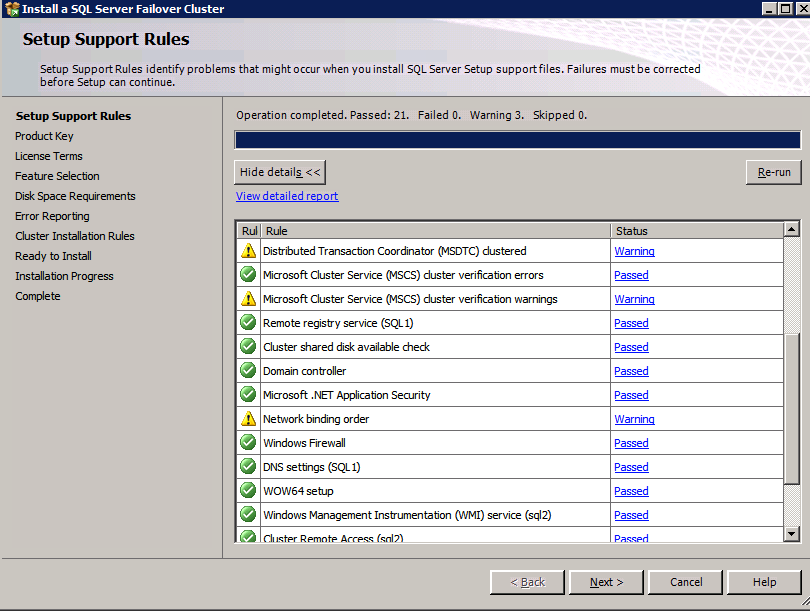
- 에 지원 규칙 설정 , 클릭 좋아요 .
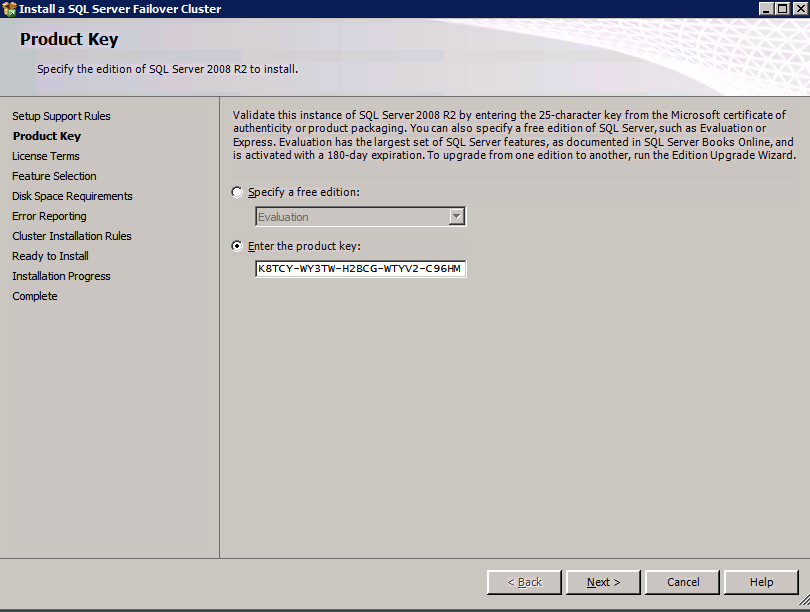
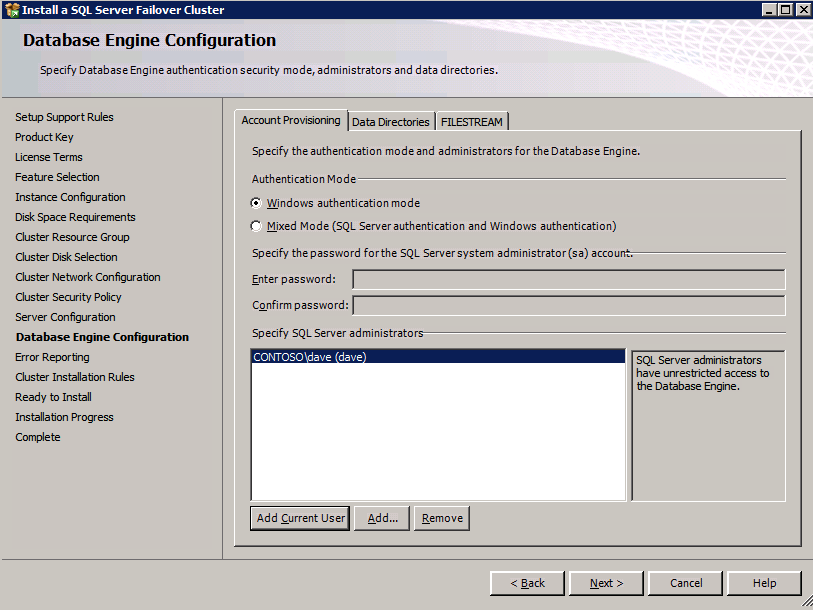
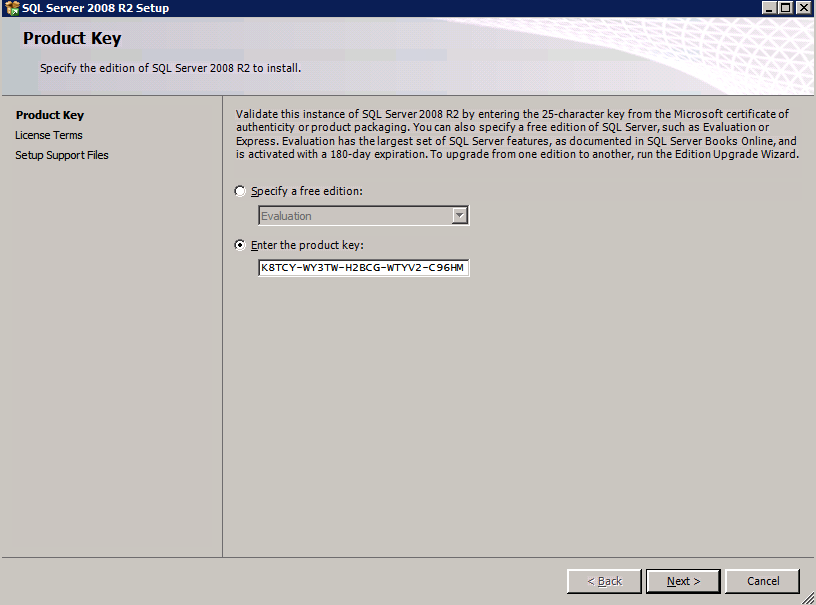
- 에 제품 키 대화 상자에서 제품 키 클릭 다음 .
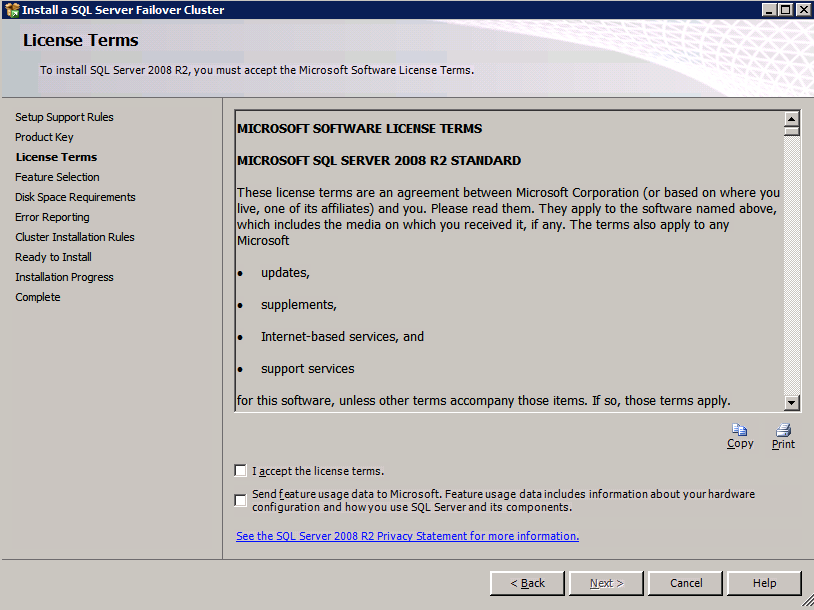
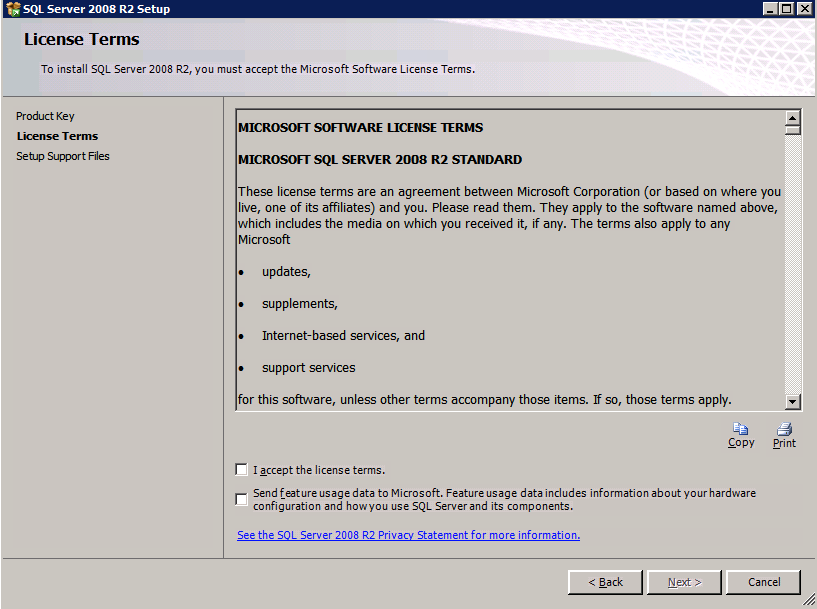
- 에 라이선스 조건 대화 상자, 수락 라이센스 계약 클릭 다음 .
- 에 제품 업데이트 대화 상자, 클릭 다음 .
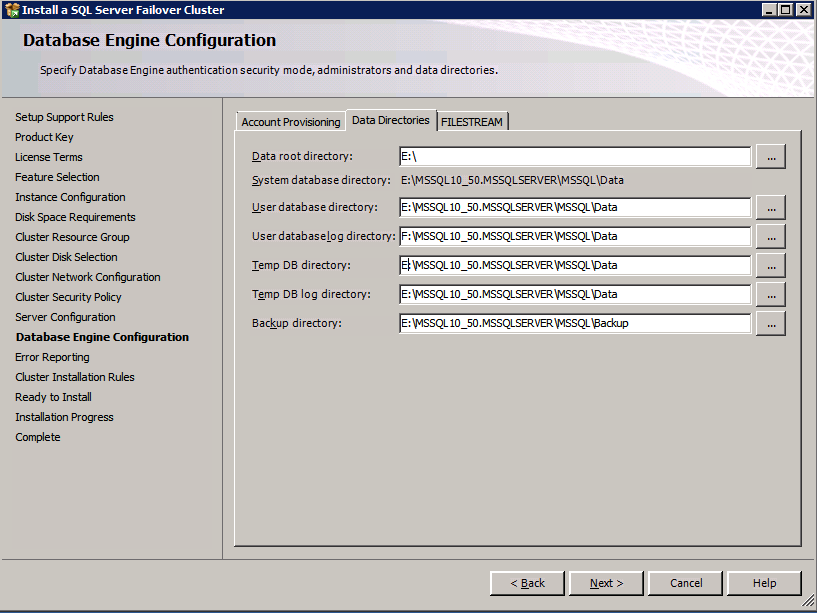
- 에 설정 지원 파일 대화 상자, 클릭 설치 .
- 에 지원 규칙 설정 대화 상자에서 경고를 받게 됩니다. 딸깍 하는 소리 다음 , 이 메시지는 다중 사이트 또는 비공유 스토리지 클러스터에서 예상되므로 무시합니다.
- 검증 클러스터 노드 구성 클릭 다음 .
- 구성 클러스터 네트워크 SQL 인스턴스에 대한 “세 번째” 보조 IP 주소를 추가하고 다음 . 딸깍 하는 소리 예 다중 서브넷 구성을 진행합니다.
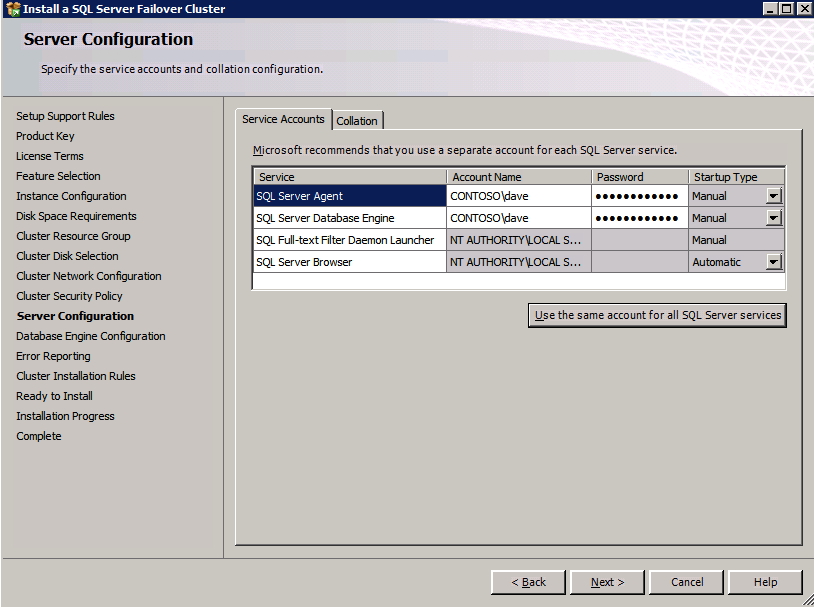
- 입력하다 비밀번호 서비스 계정에 대해 클릭하고 다음 .
- 에 오류 보고 대화 상자, 클릭 다음 .
- 에 노드 규칙 추가 대화 상자에서 건너뛴 작업 경고는 무시할 수 있습니다. 딸깍 하는 소리 다음 .
- 기능 확인 및 클릭 설치 .
- 딸깍 하는 소리 닫다 설치 프로세스를 완료합니다.
두 번째 SQL 인스턴스에 SQL 설치 두 번째 SQL 인스턴스를 설치하는 것은 첫 번째 인스턴스와 유사합니다.
- SQL 서버에서 네트워크 드라이브를 만들고 첫 번째 SQL 서버에 대해 위에서 설명한 대로 도메인 컨트롤러의 공유 폴더에 연결합니다.
- .iso 설치 프로그램이 마운트되면 다음을 실행하십시오. SQL 설정 건너 뛰기 위해 명령 줄에서 다시 한 번 확인 열기 명령 창에서 귀하의 SQL 설치 디렉토리 다음 명령을 입력하십시오.
설정 /SkipRules=Cluster_VerifyForErrors /Action=AddNode /INSTANCENAME=”MSSQLSERVER”( 메모 : 이것은 첫 번째 노드에 기본 인스턴스를 설치했다고 가정합니다)
- 에 지원 규칙 설정 , 클릭 좋아요 .
- 에 제품 키 대화 상자에서 제품 키 클릭 다음 .
- 에 라이선스 조건 대화 상자, 수락 라이센스 계약 클릭 다음 .
- 에 제품 업데이트 대화 상자, 클릭 다음 .
- 에 설정 지원 파일 대화 상자, 클릭 설치 .
- 에 지원 규칙 설정 대화 상자에서 경고를 받게 됩니다. 딸깍 하는 소리 다음 , 이 메시지는 다중 사이트 또는 비공유 스토리지 클러스터에서 예상되므로 무시합니다.
- 검증 클러스터 노드 구성 클릭 다음 .
- 구성 클러스터 네트워크 SQL 인스턴스에 대한 “세 번째” 보조 IP 주소를 추가하고 다음 . 딸깍 하는 소리 예 다중 서브넷 구성을 진행합니다.
- 입력하다 비밀번호 서비스 계정에 대해 클릭하고 다음 .
- 에 오류 보고 대화 상자, 클릭 다음 .
- 에 노드 규칙 추가 대화 상자에서 건너뛴 작업 경고는 무시할 수 있습니다. 딸깍 하는 소리 다음 .
- 기능 확인 및 클릭 설치 .
- 딸깍 하는 소리 닫다 설치 프로세스를 완료합니다.
공통 클러스터 구성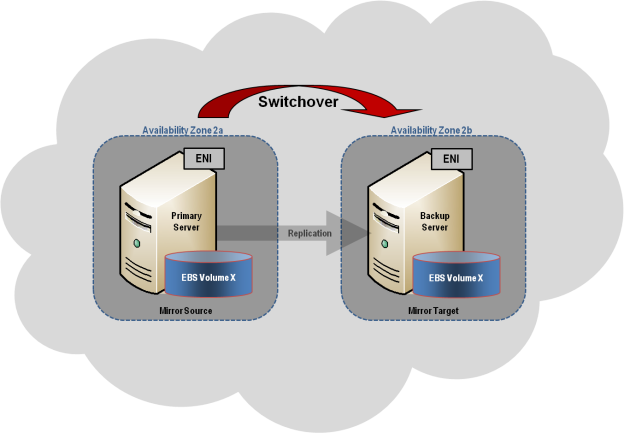 이 섹션에서는 다음을 설명합니다. 일반적인 2노드 복제 클러스터 구성 .
이 섹션에서는 다음을 설명합니다. 일반적인 2노드 복제 클러스터 구성 .
- 초기 구성은 다음에서 수행해야 합니다. 데이터키퍼 UI 클러스터 노드 중 하나에서 실행 중입니다. Windows Core 전용 서버에서 DataKeeper를 실행할 때와 같이 클러스터 노드에서 DataKeeper UI를 실행할 수 없는 경우 Windows XP 이상을 실행하는 컴퓨터에 DataKeeper UI를 설치하고 다음 지침을 따르십시오. 코어만 미러를 만들고 명령줄을 통해 클러스터 리소스를 등록하는 섹션을 참조하세요.
- DataKeeper UI가 실행되면 각 노드에 연결 클러스터에서.
- 작업 만들기 DataKeeper UI를 사용하여 이 프로세스는 미러를 만들고 사용 가능한 저장소에 DataKeeper 볼륨 리소스를 추가합니다.
! 중요한: 확인 가상 네트워크 이름 ~을위한 NIC 연결 모든 클러스터 노드에서 동일합니다.
- 추가 미러가 필요한 경우 다음을 수행할 수 있습니다. 작업에 미러 추가 .
- 이랑 DataKeeper 볼륨 지금에 사용 가능한 스토리지 , 클러스터에 공유 디스크 리소스가 있는 것과 동일한 방식으로 클러스터 리소스(SQL, 파일 서버 등)를 생성할 수 있습니다. 위의 단계별 클러스터 구성 지침 외에 추가 정보는 Microsoft 설명서를 참조하십시오.
클러스터(가상) IP에 대한 연결 기본 IP 및 보조 IP 외에도 Huawei Cloud에서 가상 IP 주소를 구성하여 활성 노드로 라우팅할 수 있도록 해야 합니다.
- 로부터 서비스 목록 드롭다운, 선택 탄력적 클라우드 서버 .
- 클러스터 가상 IP 주소를 추가하려는 SQL 인스턴스 중 하나를 클릭합니다(MSDTC용 하나, SQL 장애 조치 클러스터용 하나).
- 선택하다 NIC > 가상 IP 주소 관리 .
- 클릭 가상 IP 주소 할당 그리고 선택 설명서 인스턴스의 서브넷 범위 내에 있는 IP 주소를 입력합니다(예: 15.0.1.25의 경우 15.0.1.26을 입력합니다. 딸깍 하는 소리 확인 .
- 클릭 더 IP 주소 행에서 드롭다운을 선택하고 서버에 바인딩 , IP 주소를 바인딩할 서버와 NIC 카드를 모두 선택합니다.
- MSDTC 및 SQLFC 가상 IP에 대해 동일한 4. 및 5단계를 사용합니다.
- 딸깍 하는 소리 좋아요 작업을 저장합니다.
관리 DataKeeper 볼륨이 Windows Server 장애 조치 클러스터링에 등록되면 해당 볼륨의 모든 관리는 Windows Server 장애 조치 클러스터링 인터페이스를 통해 수행됩니다. DataKeeper에서 일반적으로 사용 가능한 모든 관리 기능 비활성화됩니다 클러스터 제어하에 있는 모든 볼륨에서. 대신 DataKeeper 볼륨 클러스터 리소스가 미러 방향을 제어하므로 DataKeeper 볼륨이 노드에서 온라인 상태가 되면 해당 노드가 미러 소스가 됩니다. DataKeeper Volume 클러스터 리소스의 속성은 미러의 소스, 대상, 유형 및 상태와 같은 기본 미러링 정보도 표시합니다.
문제 해결 다음 리소스를 사용하여 문제를 해결하세요.
- 문제 해결 문제 섹션
- 지원 계약을 맺은 고객의 경우 – http://us.sios.com/support/overview/
- 평가판 고객 전용 – 사전 판매 지원
추가 리소스: 단계별: Windows Server 2008 R2에서 2노드 다중 사이트 클러스터 구성 – 1부 — http://clusteringformeremortals.com/2009/09/15/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2%80%93 -1 부/ 단계별: Windows Server 2008 R2에서 2노드 다중 사이트 클러스터 구성 – 파트 3 — http://clusteringformeremortals.com/2009/10/07/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2%80%93 -파트-3/

 이르는 모든 정보에 대한 첫 번째 정보원이되었습니다. [/ caption] Gmail, YouTube, SnapChat 등 많은 서비스가 영향을 받았습니다. [/ caption]
이르는 모든 정보에 대한 첫 번째 정보원이되었습니다. [/ caption] Gmail, YouTube, SnapChat 등 많은 서비스가 영향을 받았습니다. [/ caption]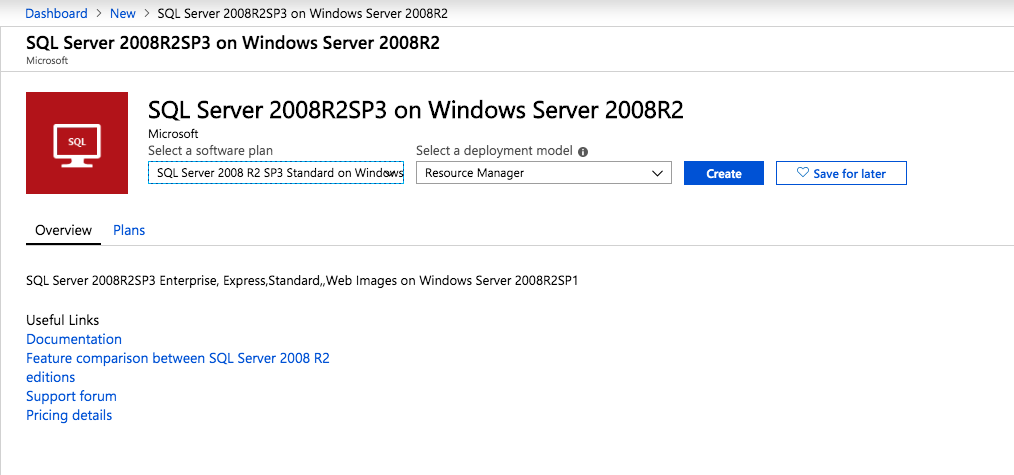

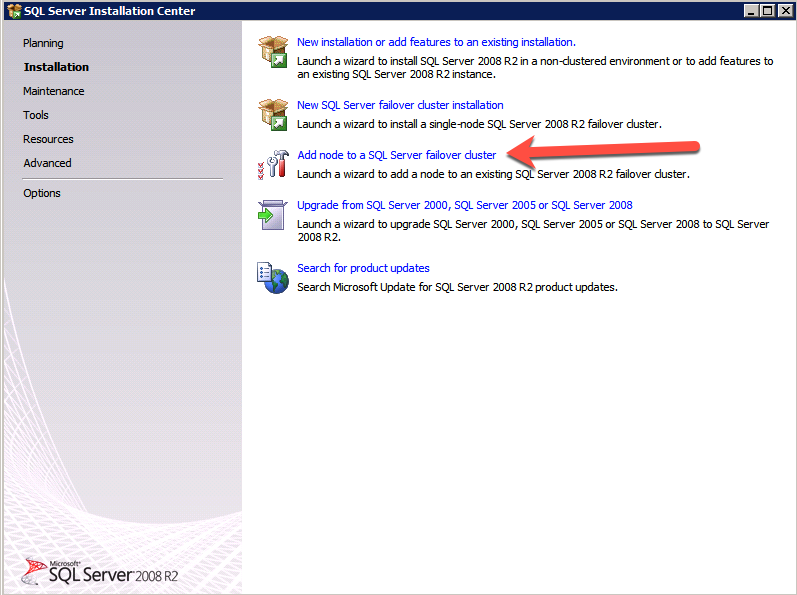
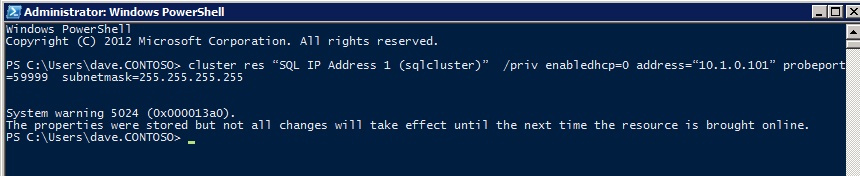
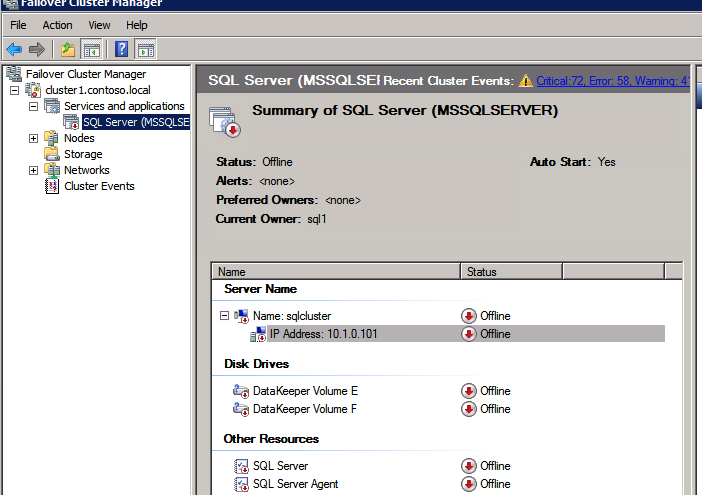
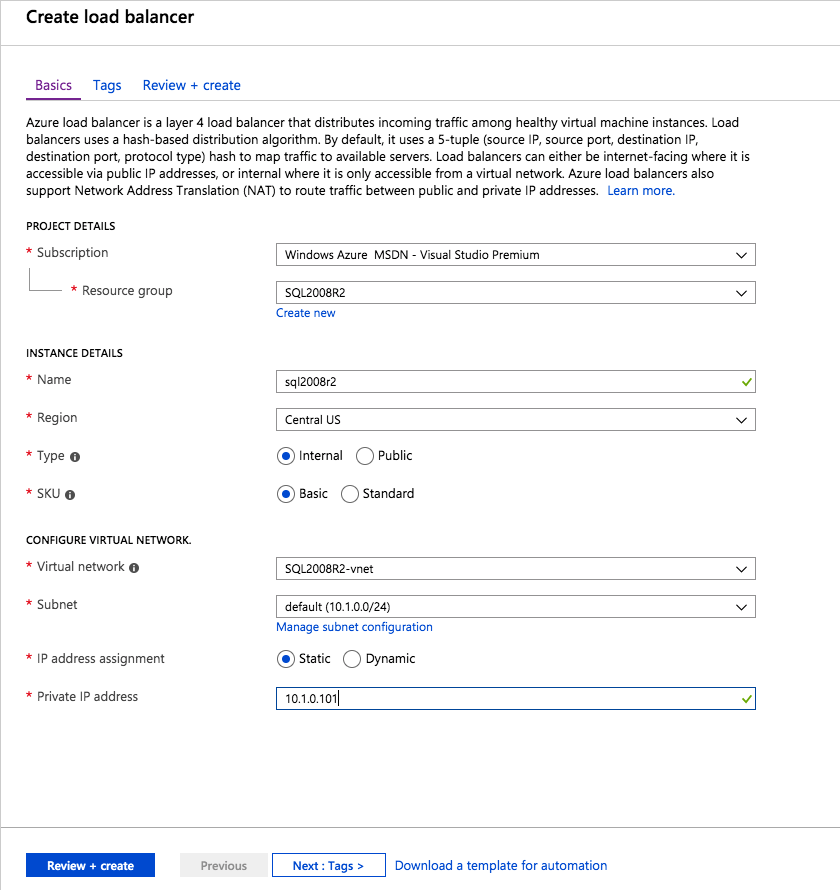
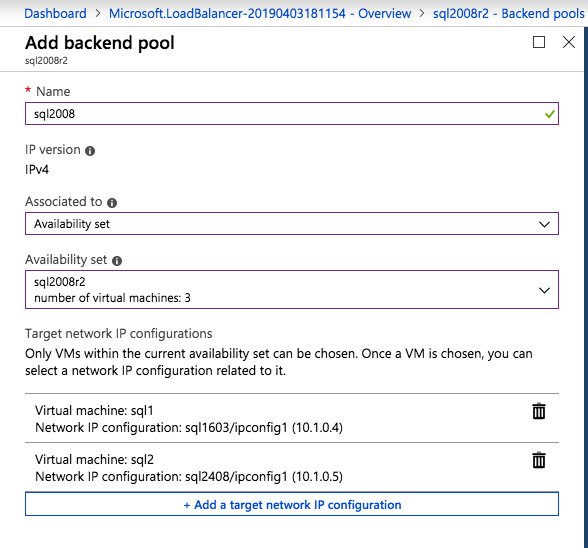
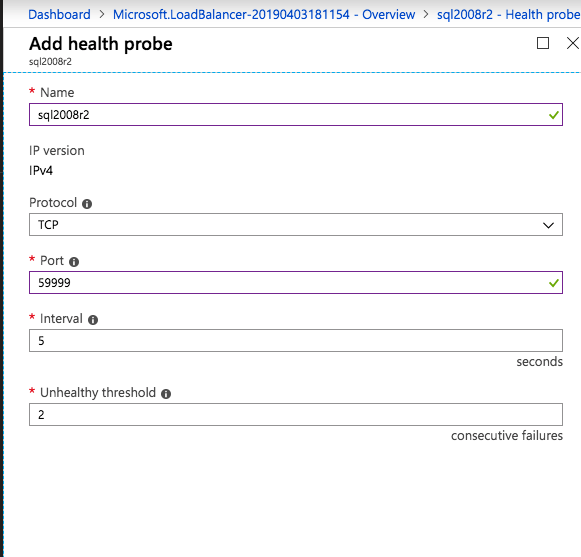
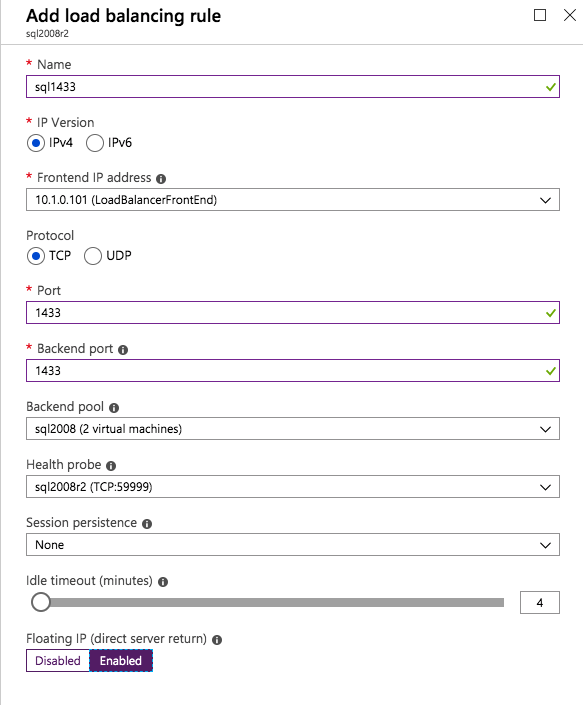
 다음으로 인스턴스가 다른 서버에서 실행될 수 있으므로 다른 프로브를 추가해야합니다. 아래 그림과 같이 포트 59998 (보통 59999 대신)을 프로브하는 프로브를 추가했습니다. 새 규칙이이 조사를 참조하는지 확인해야합니다. 또한이 프로세스의 마지막 단계에서이 인스턴스와 연결된 IP 주소를 업데이트해야하므로 포트 번호를 기억해야합니다.
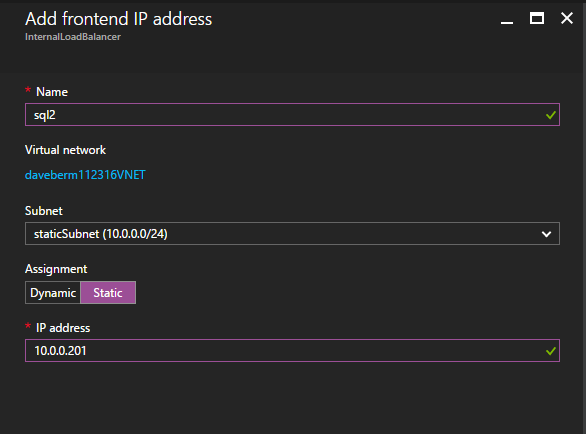
다음으로 인스턴스가 다른 서버에서 실행될 수 있으므로 다른 프로브를 추가해야합니다. 아래 그림과 같이 포트 59998 (보통 59999 대신)을 프로브하는 프로브를 추가했습니다. 새 규칙이이 조사를 참조하는지 확인해야합니다. 또한이 프로세스의 마지막 단계에서이 인스턴스와 연결된 IP 주소를 업데이트해야하므로 포트 번호를 기억해야합니다.  이제 ILB에 두 개의 새로운 규칙을 추가하여이 두 번째 SQL 인스턴스로 향하는 트래픽을 지정해야합니다. 물론 TCP 포트 1440 (명명 된 SQL 인스턴스에 사용 된 포트)을 리디렉션하는 규칙을 추가해야하지만 이제는 명명 된 인스턴스를 사용하기 때문에 SQL Server Browser Service를 지원하는 포트가 있어야합니다. UDP 포트 1434. SQL Server Browser Service에 대한 규칙을 묘사하는 아래 그림에서 프런트 엔드 IP 주소가 새 프런트 엔드 IP 주소 (10.0.0.201), UDP 포트 1434 (포트 및 백 엔드 포트 모두)를 참조합니다. 풀에서 클러스터의 두 서버를 지정하고 마지막으로 방금 만든 새 상태 프로브를 선택해야합니다.
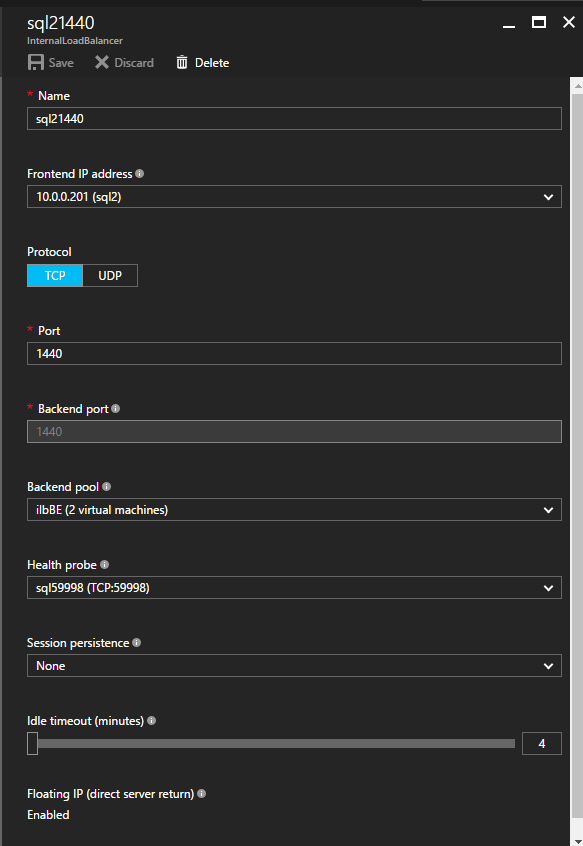
이제 ILB에 두 개의 새로운 규칙을 추가하여이 두 번째 SQL 인스턴스로 향하는 트래픽을 지정해야합니다. 물론 TCP 포트 1440 (명명 된 SQL 인스턴스에 사용 된 포트)을 리디렉션하는 규칙을 추가해야하지만 이제는 명명 된 인스턴스를 사용하기 때문에 SQL Server Browser Service를 지원하는 포트가 있어야합니다. UDP 포트 1434. SQL Server Browser Service에 대한 규칙을 묘사하는 아래 그림에서 프런트 엔드 IP 주소가 새 프런트 엔드 IP 주소 (10.0.0.201), UDP 포트 1434 (포트 및 백 엔드 포트 모두)를 참조합니다. 풀에서 클러스터의 두 서버를 지정하고 마지막으로 방금 만든 새 상태 프로브를 선택해야합니다. 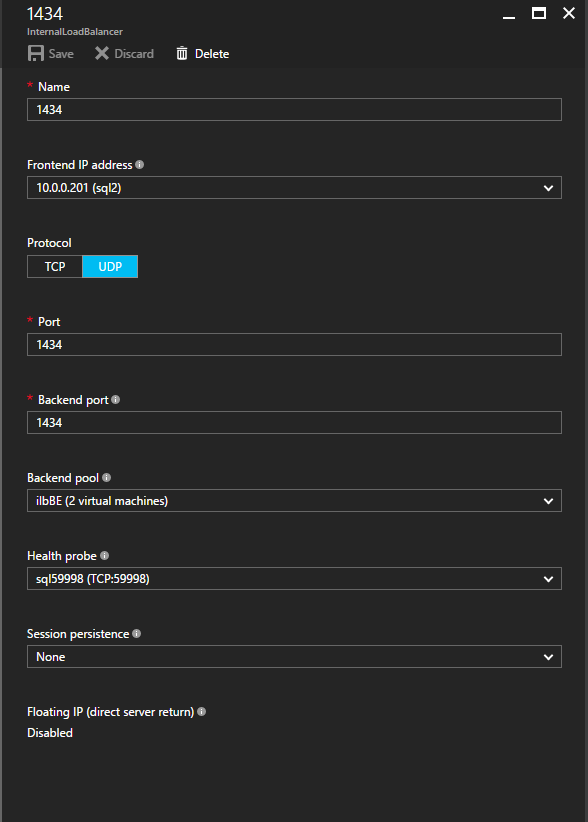 이제 TCP / 1440에 대한 규칙을 추가 할 것입니다. 아래 그림과 같이 포트 TCP 1440에 대한 새 규칙을 추가하거나 명명 된 SQL Server 인스턴스에 대해 잠긴 포트를 추가합니다. 다시 한 번, 새 FrontEnd IP 주소와 새 상태 프로브 (59998)를 선택하십시오. 또한 Floating IP (직접 서버 리턴)가 사용 가능한지 확인하십시오.
이제 TCP / 1440에 대한 규칙을 추가 할 것입니다. 아래 그림과 같이 포트 TCP 1440에 대한 새 규칙을 추가하거나 명명 된 SQL Server 인스턴스에 대해 잠긴 포트를 추가합니다. 다시 한 번, 새 FrontEnd IP 주소와 새 상태 프로브 (59998)를 선택하십시오. 또한 Floating IP (직접 서버 리턴)가 사용 가능한지 확인하십시오.