단계별 : Azure에서 SQL Server 2008 R2 장애 조치 (Failover) 클러스터 인스턴스를 구성하는 방법
Azure에서 SQL Server 장애 조치 (failover) 클러스터 인스턴스를 구성하는 데 필요한 가이드가 필요하면 SQL Server 2008/2008 R2를 사용하고있는 것입니다. SQL Server 2008/2008 R2를 Azure로 전환하면 Microsoft에서 제공하는 확장 보안 업데이트를 활용하고 싶습니다. 이전에이 블로그 게시물에이 주제에 관해 썼습니다. Azure로 이동 한 후에도 SQL Server 장애 조치 (Failover) 클러스터 인스턴스의 고 가용성을 유지하는 방법을 궁금해하실 수 있습니다. 오늘날 대부분의 사람들은 업무상 중요한 SQL Server 2008/2008 R2를 데이터 센터에 클러스터 된 인스턴스 (SQL Server FCI)로 구성합니다. Azure를 살펴볼 때 공유 저장 장치가 부족하여 Azure 클라우드에 SQL Server FCI를 가져올 수없는 것처럼 보일 수도 있습니다. 그러나 SIOS DataKeeper 덕분에 그렇지 않습니다. SIOS DataKeeper를 사용하면 Azure, AWS, Google Cloud 또는 공유 저장소를 사용할 수 없거나 공유 저장소가 적합하지 않은 다중 사이트 클러스터를 구성하려는 경우 SQL Server 장애 조치 (Failover) 클러스터 인스턴스를 구축 할 수 있습니다. DataKeeper는 1999 년 이래로 Windows 및 Linux 용 SANless 클러스터를 지원하고 있습니다. Microsoft는 Azure Virtual Machines에서 SQL Server의 고 가용성 및 재해 복구와 같은 설명서에서 SQL Server Failover Cluster 인스턴스 용 SIOS DataKeeper를 사용하고 있습니다. 이전에 Azure에서 실행중인 SQL Server FCI에 대해 작성했지만 SQL Server 2008/2008 R2 관련 단계별 안내서는 게시하지 않았습니다. 좋은 소식은 SQL 2008/2008/2016/2017 및 2019 년 곧 출시 될 SQL 2008/2008 R2와 마찬가지로 훌륭하게 작동한다는 것입니다. 또한 Windows Server 버전 (2008/2012/2016/2019) 또는 SQL Server (2008/2012/2014/2016/2017)에 관계없이 구성 프로세스가 유사하기 때문에이 가이드로 인해 구성. SQL이나 Windows의 맛이 제 가이드에서 다루지 않는 경우 SQL Server FCI를 작성하고이 가이드를 참조하기를 두려워하지 마십시오. 차이점을 파악하고 방금 막혔다면 트위터 @daveberm에서 나에게 다가 가라. 나는 너에게 손을 뻗어 기뻐할 것이다. 이 가이드에서는 Windows Server 2012 R2와 함께 SQL Server 2008 R2를 사용합니다. 이 글을 쓰는 시점에서 필자는 Windows Server 2012 R2에서 Azure Marketplace의 SQL 2008 R2 이미지를 보지 못했습니다. 따라서 SQL 2008 R2를 수동으로 다운로드하여 설치해야했습니다. 개인적으로 필자는이 조합을 선호하지만 Windows Server 2008 R2 또는 Windows 212를 사용해야하는 경우에는 문제가 없습니다. Windows Server 2008 R2를 사용하는 경우 Windows Server 2008 R2 SP1 용 kb3125574 편의 롤업 업데이트를 설치하는 것을 잊지 마십시오. 또는 Server 2012 (R2가 아님)가 붙어있는 경우 kb2854082의 핫픽스가 필요합니다. SQL Server 2008 R2 인스턴스에 kb2854082를 설치해야한다는 내용의이 기사에 속지 마십시오. Windows Server 2008 R2에 대한 해당 업데이트 검색을 시작하면 Server 2012 버전 만 사용할 수 있습니다. Server 2008 R2의 특정 핫픽스는 대신 Windows Server 2008 R2 SP1 용 롤업 편의 롤업 업데이트에 포함되어 있습니다.
규정 AZURE INSTANCES
Azure Portal UI가 꽤 자주 변경되는 경향이 있기 때문에 특히 스크린 샷을 많이 사용하지는 않겠다. 그래서 찍은 모든 스크린 샷은 꽤 빨리 사라질 것이다. 대신, 나는 당신이 알고 있어야하는 중요한 주제들을 다룰 것입니다.
결함이있는 도메인 또는 가용성 영역?
SQL Server 인스턴스의 가용성을 높이려면 클러스터 노드가 다른 오류 도메인 (FD) 또는 다른 가용 영역 (AZ)에 있는지 확인해야합니다. 인스턴스가 다른 FD 또는 AZ에 있어야 할뿐만 아니라 File Share Witness (아래 참조)도 클러스터 노드가있는 FD 또는 AZ와 다른 FD 또는 AZ에 있어야합니다. 여기에 그것이있다. AZ는 최신 Azure 기능이지만 지금까지 소수의 지역에서만 지원됩니다. AZ는 당신에게 더 높은 SLA (99.99 %)를주고 FDs (99.95 %)를 제공하며, Azure Postage에 게시 된 클라우드 중단의 종류로부터 당신을 보호합니다. AZ를 지원하는 지역에 배포 할 수 있다면 AZ를 사용하는 것이 좋습니다. 이 가이드에서는로드 밸런서 구성에 관한 절을 읽었을 때 표시되는 AZ를 사용했습니다. 그러나 FD를 사용하는 경우로드 밸런서 구성이 가용 영역보다는 가용 세트를 참조한다는 점을 제외하면 모든 것이 정확히 동일합니다.
당신이 묻는 증분 몫은 무엇입니까?
WSFC (Windows Server Failover Clustering)를 사용하면 장애 조치 (failover)가 올바르게 수행되도록 "감시 (Witness)"를 구성해야합니다. Windows Server 장애 조치 (Failover) 클러스터링은 디스크, 파일 공유, 클라우드의 세 가지 종류의 증인을 지원합니다. 우리가 Azure에 있기 때문에 디스크 증인은 불가능합니다. Cloud Witness는 Windows Server 2016 이상에서만 사용할 수 있으므로 File Share Witness가 필요합니다. 클러스터 쿼럼에 대한 자세한 내용은 Microsoft Press 블로그의 MVP : Windows Server 2012 R2의 Windows Server 장애 조치 (failover) 클러스터 쿼럼 이해 (영문)를 참조하십시오.
SQL Server 인스턴스에 저장소를 추가하십시오.
SQL Server 인스턴스를 프로비저닝 할 때 각 인스턴스에 디스크를 추가해야합니다. 최소한 SQL 데이터 및 로그 파일 용으로 하나의 디스크, Tempdb 용으로 하나의 디스크가 필요합니다. 클라우드에서 실행할 때 로그 및 데이터 파일 용으로 별도의 디스크를 사용해야하는지 여부는 다소 논쟁의 여지가 있습니다. 백엔드에서 저장소는 모두 같은 위치에서 나오며 인스턴스 크기는 총 IOPS를 제한합니다. 내 의견으로는 실제로 두 개의 물리적 디스크 세트에서 실행 중인지 확인할 수 없으므로 로그 파일과 데이터 파일을 분리 할 때 가치가 없습니다. 내가 결정할 수 있도록 남겨두고 싶지만 로그와 데이터를 모두 같은 볼륨에 넣습니다. 일반적으로 SQL Server 2008 R2 FCI에서는 클러스터 된 디스크에 tempdb를 넣어야합니다. 그러나, SIOS DataKeeper는 DataKeeper Non-Mirrored Volume Resource라는 정말 멋진 기능을 가지고 있습니다. 이 가이드에서는 미러되지 않은 볼륨 리소스로 tempdb를 이동하는 방법에 대해서는 설명하지 않지만 최적의 성능을 위해서는이 작업을 수행해야합니다. 어쨌든 장애 조치시에 다시 작성되기 때문에 tempdb를 복제 할 충분한 이유가 없습니다. 스토리지에 관한 한 모든 스토리지 유형을 사용할 수 있지만 가능할 때마다 Managed Disks를 사용하십시오. 클러스터의 각 노드가 동일한 스토리지 구성을 갖고 있는지 확인하십시오. 인스턴스를 실행하면 이러한 디스크를 연결하고 NTFS로 포맷 할 수 있습니다. 각 인스턴스가 동일한 드라이브 문자를 사용하는지 확인하십시오.
네트워킹
어려운 요구 사항은 아니지만 가능하면 가속화 된 네트워킹을 지원하는 인스턴스 크기를 사용하십시오. 또한 인스턴스가 고정 IP 주소를 사용하도록 Azure 포털에서 네트워크 인터페이스를 편집해야합니다. 클러스터링이 제대로 작동하려면 일부 공용 DNS 서버가 아니라 Windows AD / DNS 서버를 가리 키도록 DNS 서버의 설정을 업데이트해야합니다.
보안
기본적으로 동일한 가상 네트워크의 노드 간 통신은 활발하지만 Azure 보안 그룹을 잠근 경우 클러스터 노드간에 열려야하는 포트를 확인하고 보안 그룹을 조정해야합니다. Azure에 클러스터를 구축 할 때 발생하는 거의 모든 문제는 저의 경험으로 포트 차단으로 인한 것입니다. DataKeeper에는 클러스터 된 인스턴스간에 열려야하는 일부 포트가 있습니다. 이러한 포트는 다음과 같습니다. UDP : 137, 138 TCP : 139, 445, 9999 및 10000 – 10025 범위의 포트 장애 조치 (failover) 클러스터에는 여기에 문서화하지 않는 자체 포트 요구 사항 세트가 있습니다. 이 기사에는이 내용이 포함되어있는 것으로 보입니다. http://dsfnet.blogspot.com/2013/04/windows-server-clustering-sql-server.html 또한로드 밸 랜서는 각 노드에서 인바운드 트래픽을 허용해야하는 프로브 포트를 사용합니다. 이 가이드에서 일반적으로 사용되는 포트는 59999입니다. 마지막으로 클라이언트가 SQL Server 인스턴스에 연결할 수있게하려면 SQL Server 포트가 열려 있는지 확인해야합니다.이 포트는 기본적으로 1433입니다. 이 포트는 Windows 방화벽이나 Azure 보안 그룹에 의해 차단 될 수 있으므로 둘 모두를 확인하여 액세스가 가능한지 확인하십시오.
도메인에 가입하십시오.
SQL Server 2008 R2 FCI에 대한 요구 사항은 인스턴스가 동일한 Windows Server 도메인에 있어야한다는 것입니다. 그래서 그렇게하지 않았다면 인스턴스를 Windows 도메인에 가입 시켰는지 확인하십시오.
지역 서비스 계정
DataKeeper를 설치하면 서비스 계정을 제공하라는 메시지가 나타납니다. 도메인 사용자 계정을 만든 다음 해당 사용자 계정을 각 노드의 로컬 관리자 그룹에 추가해야합니다. DataKeeper 설치 중에 질문을 받으면 해당 계정을 DataKeeper 서비스 계정으로 지정하십시오. 참고 – DataKeeper를 아직 설치하지 마십시오!
도메인 글로벌 보안 그룹
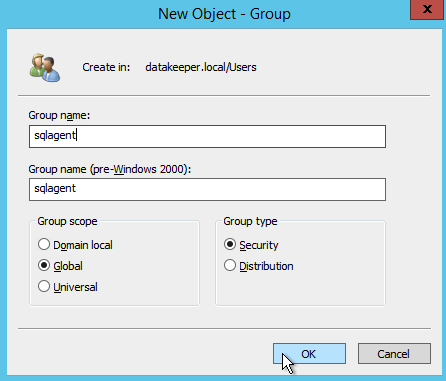
SQL 2008 R2를 설치할 때 두 개의 전역 도메인 보안 그룹을 지정하라는 메시지가 표시됩니다. SQL 설치 지침을보고 해당 그룹을 작성하는 것이 좋습니다. 또한 도메인 사용자 계정을 만들어 각 보안 계정에 배치하십시오. 이 계정을 SQL Server 클러스터 설치의 일부로 지정합니다.
기타 사전 요청
두 클러스터 인스턴스의 각 인스턴스에서 장애 조치 클러스터링과 .Net 3.5를 모두 사용해야합니다. 장애 조치 (Failover) 클러스터링을 사용하도록 설정하면 선택적 "장애 조치 (Failover) 클러스터 자동화 서버"도 사용하도록 설정해야합니다. 이는 Windows Server 2012 R2의 SQL Server 2008 R2 클러스터에 필요합니다.
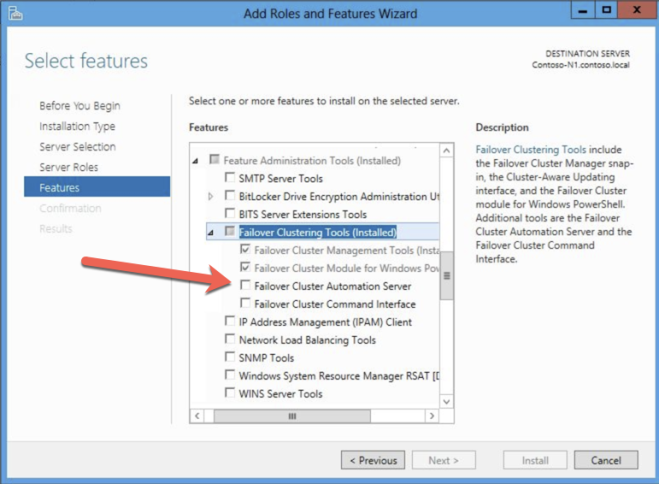
클러스터 및 데이터 키퍼 볼륨 자원 만들기
이제 클러스터 구축을 시작할 준비가되었습니다. 첫 번째 단계는 기본 클러스터를 만드는 것입니다. Azure가 DHCP를 처리하는 방식 때문에 우리는 클러스터 UI가 아닌 Powershell을 사용하여 클러스터를 만들어야합니다. Powershell은 생성 프로세스의 일부로 고정 IP 주소를 지정할 수 있도록하기 때문에 Powershell을 사용합니다. UI를 사용하면 VM이 DHCP를 사용하며 중복 된 IP 주소가 자동으로 할당됩니다. 그러므로 이러한 상황을 피하기 위해 아래와 같이 Powershell을 사용하십시오.
새 클러스터 -Name cluster1 -Node sql1, sql2 -StaticAddress 10.0.0.100 -NoStorage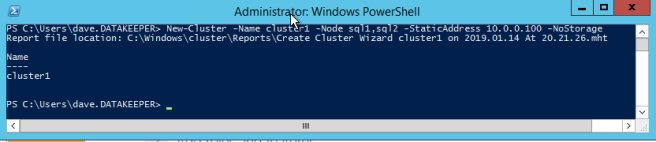
클러스터가 생성 된 후 Test-Cluster를 실행하십시오. 이는 SQL Server를 설치하기 전에 필요합니다.
테스트 클러스터
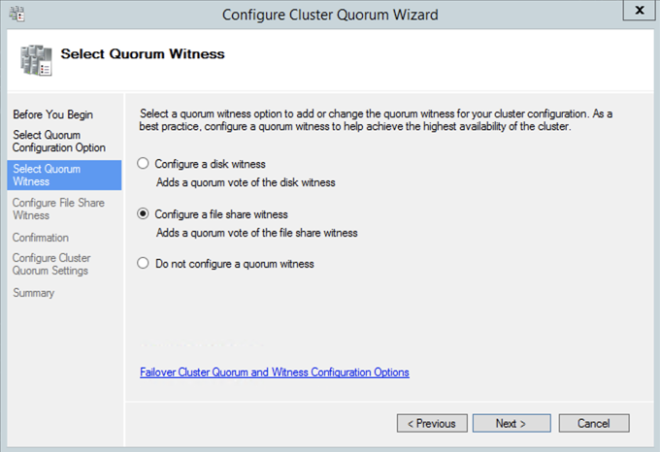
저장 및 네트워킹에 대한 경고가 표시됩니다. 고맙게도 Azure의 SANless 클러스터에서 예상대로 무시할 수 있습니다. 그러나 계속 진행하기 전에 다른 경고 또는 오류를 해결하십시오. 클러스터를 만든 후에는 파일 공유 감시를 추가해야합니다. 파일 공유 감시로 지정한 세 번째 서버에서 파일 공유를 만들고 위의 방금 만든 클러스터 컴퓨터 개체에 읽기 / 쓰기 권한을 부여합니다. 이 경우 $ Cluster1은 공유 및 NTFS 보안 수준에서 읽기 / 쓰기 권한이 필요한 컴퓨터 개체의 이름입니다. 공유가 만들어지면 아래와 같이 클러스터 쿼럼 구성 마법사를 사용하여 파일 공유 감시를 구성 할 수 있습니다.




데이터 키퍼 설치
DataKeeper 설치시 DataKeeper 볼륨 리소스 유형이 장애 조치 클러스터링에 등록되므로 DataKeeper를 설치하기 전에 기본 클러스터가 만들어 질 때까지 기다리는 것이 중요합니다. 총을 들고 DataKeeper를 이미 설치했다면 괜찮습니다. 설치를 다시 실행하고 설치 복구를 선택하기 만하면됩니다. 아래의 스크린 샷은 기본적인 설치 과정을 안내합니다. DataKeeper 설치 프로그램을 실행하여 시작하십시오.






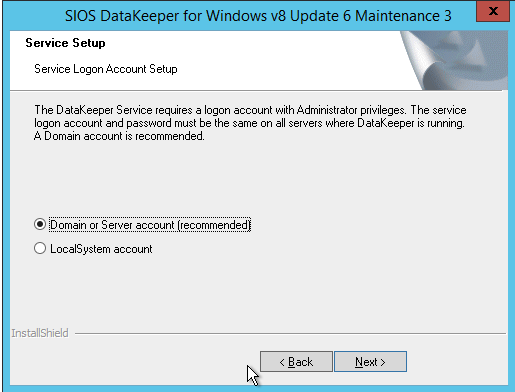
아래에서 지정하는 계정은 도메인 계정이어야합니다. 각 클러스터 노드의 로컬 관리자 그룹에 속해야합니다.
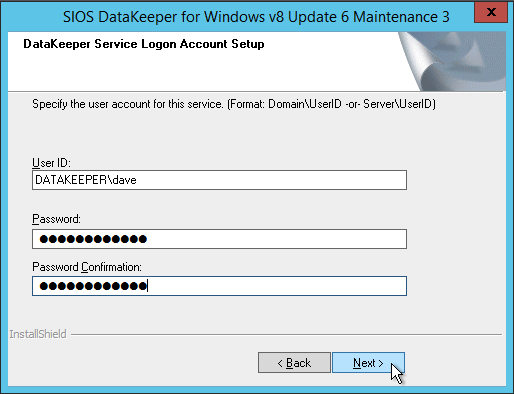
SIOS 라이센스 키 관리자가 나타나면 임시 키를 찾아 볼 수 있습니다. 또는 영구 키가있는 경우 시스템 호스트 ID를 복사하여 영구 키를 요청할 수 있습니다. 키를 새로 고침해야하는 경우 SIOS License Key Manager는 별도로 실행하여 새 키를 추가 할 수있는 프로그램입니다.

데이터 키퍼 볼륨 자원 만들기
DataKeeper가 각 노드에 설치되면 첫 번째 DataKeeper 볼륨 리소스를 만들 준비가 된 것입니다. 첫 번째 단계는 DataKeeper UI를 열고 각 클러스터 노드에 연결하는 것입니다.

모든 것이 올바르게 완료되면 서버 개요 보고서는 다음과 같아야합니다.

이제 아래와 같이 첫 번째 작업을 만들 수 있습니다.
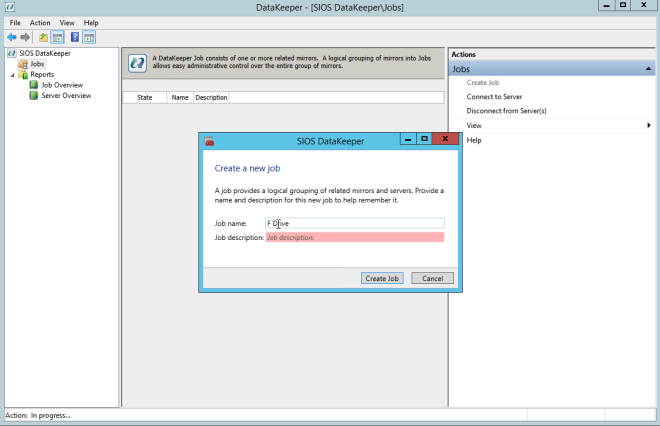


소스 및 대상을 선택하면 다음과 같은 옵션이 제공됩니다. 같은 지역에있는 지역 타겟의 경우, 선택해야하는 것은 동기식입니다.


예를 선택하고이 볼륨을 클러스터 리소스로 자동 등록하십시오.

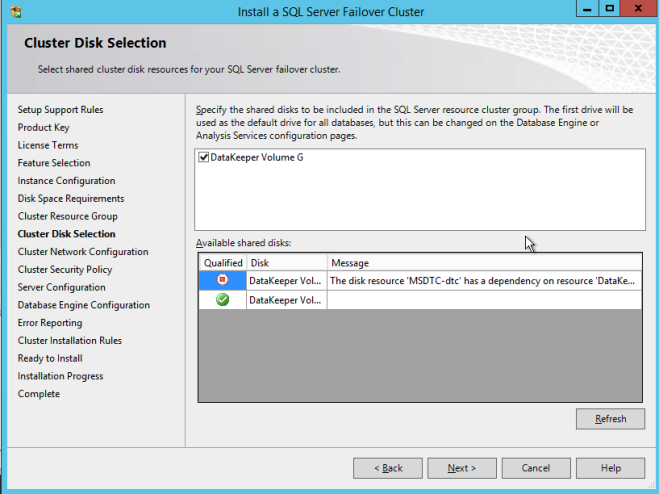
이 프로세스를 완료하면 장애 조치 (failover) 클러스터 관리자를 열고 디스크를 살펴보십시오. 사용 가능한 저장소에 DataKeeper 볼륨 리소스가 표시되어야합니다. 이 시점에서 WSFC는 정상적인 클러스터 디스크 리소스 인 것처럼 처리합니다.

SLIPSTREAM SP3에서 SQL 2008 R2 설치 미디어로 이동
SQL Server 2008 R2는 SQL Server SP2 이상이 설치된 Windows Server 2012 R2에서만 지원됩니다. 불행히도 Microsoft는 SP2 또는 SP3이 포함 된 SQL Server 2008 R2 설치 미디어를 출시하지 않았습니다. 대신 설치하기 전에 서비스 팩을 설치 미디어에 설치해야합니다. 표준 SQL Server 2008 R2 미디어를 사용하여 설치를 시도하면 모든 종류의 문제가 발생합니다. 정확한 오류를 기억하지 못합니다. 그러나 나는 그들이 정확히 정확한 문제를 지적하지 않았던 것을 기억한다. 무엇이 잘못되었는지 알아 내려고 많은 시간을 낭비 할 것입니다. 이 글을 쓰는 시점 현재, Microsoft는 Azure 마켓 플레이스에 SQL Server 2008 R2를 제공하는 Windows Server 2012 R2가 없습니다. Azure의 Windows Server 2012 R2에서 SQL 2008 R2를 실행하려면 자신의 SQL 라이센스를 가져 오십시오. 나중에 이미지를 추가하거나 Windows Server 2008 R2에서 SQL 2008 R2 이미지를 사용하도록 선택한 경우 먼저 이동하기 전에 SQL Server의 기존 독립 실행 형 인스턴스를 제거해야합니다. SP3을 SQL 2008 R2 설치 미디어에 적용하기 위해이 기사의 옵션 1에 대한 지침을 따랐습니다. 이 기사에서는 SP3 대신 SP2를 참조하므로 몇 가지 사항을 조정해야합니다. 클러스터의 두 노드에 사용할 설치 미디어에서 SP3을 슬립 스트림으로 만듭니다. 완료되면 다음 단계로 진행합니다.
첫 번째 노드에 SQL Server 설치
슬립 스트리밍 된 SP3과 함께 SQL Server 2008 R2 미디어를 사용하여 다음과 같이 설치 프로그램을 실행하고 클러스터의 첫 번째 노드를 설치합니다.


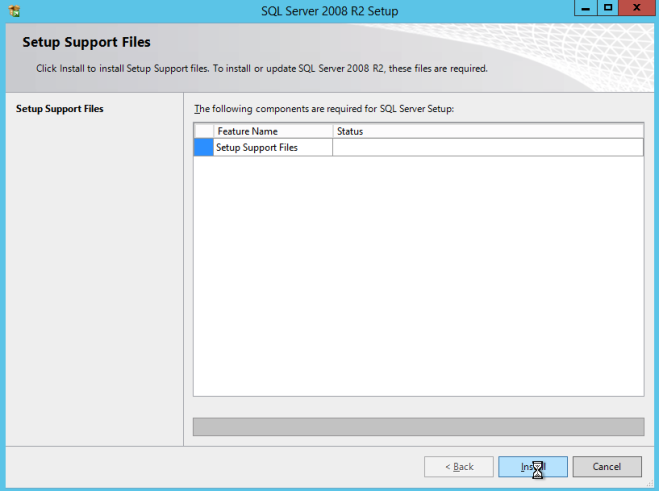




SQL Server의 기본 인스턴스 이외의 다른 것을 사용하는 경우이 가이드에서 다루지 않은 몇 가지 추가 단계가 있습니다. 가장 큰 차이점은 기본적으로 SQL Server의 명명 된 인스턴스는 1433을 사용하지 않으므로 SQL Server에서 사용하는 포트를 잠그지 않아야한다는 것입니다. 포트를 잠그면 방화벽 설정 및 Load Balancer 설정을 포함하여이 가이드에서 포트 1433을 참조 할 때마다 포트를 1433 대신 지정해야합니다.
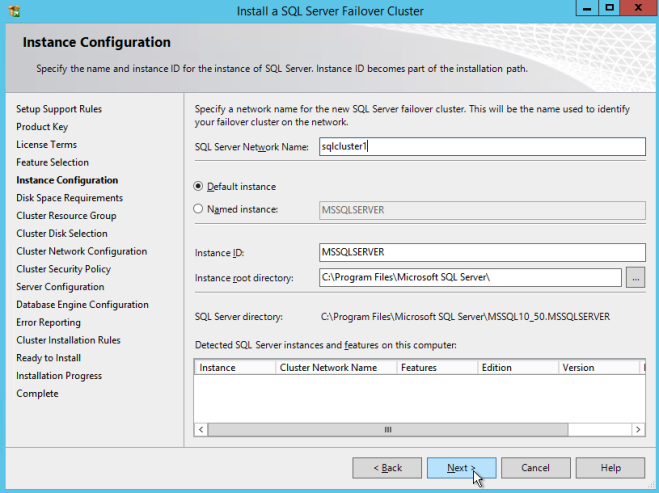


여기서 사용되지 않는 새 IP 주소를 지정하십시오. 나중에 나중에 내부로드 밸런서를 구성 할 때 사용할 동일한 IP 주소입니다.

앞에서 언급했듯이 SQL Server 2008 R2는 AD 보안 그룹을 사용합니다. 아직 작성하지 않았다면 SQL 설치의 다음 단계를 계속하기 전에 아래에 표시된대로 지금 작성하십시오.

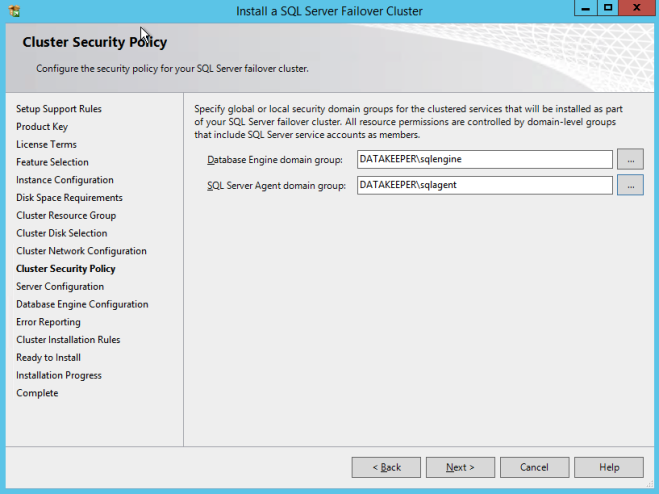
앞서 작성한 보안 그룹을 지정하십시오.
지정한 서비스 계정이 연관된 보안 그룹의 구성원인지 확인하십시오.

여기서 SQL Server 관리자를 지정하십시오.
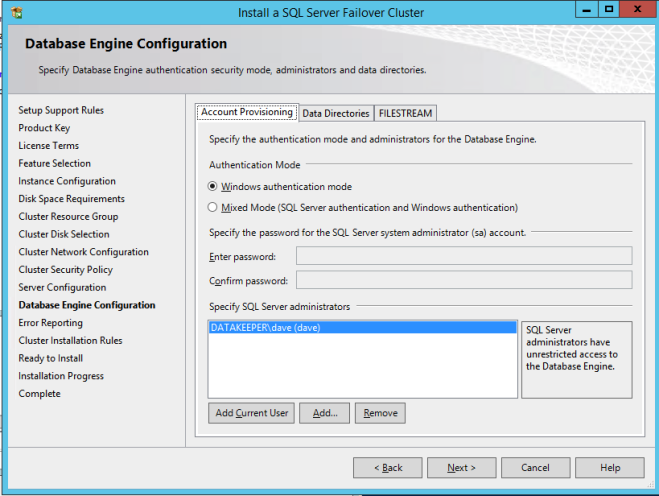

모든 것이 잘되면 이제 클러스터의 두 번째 노드에 SQL Server를 설치할 준비가되었습니다.
두 번째 노드에 SQL Server 설치
하나는 두 번째 노드로 SQL Server 2008 R2 SP3 설치를 실행하고 SQL Server 장애 조치 (Failover) 클러스터링 인스턴스에 노드 추가를 선택합니다.

다음 스크린 샷과 같이 설치를 진행하십시오.



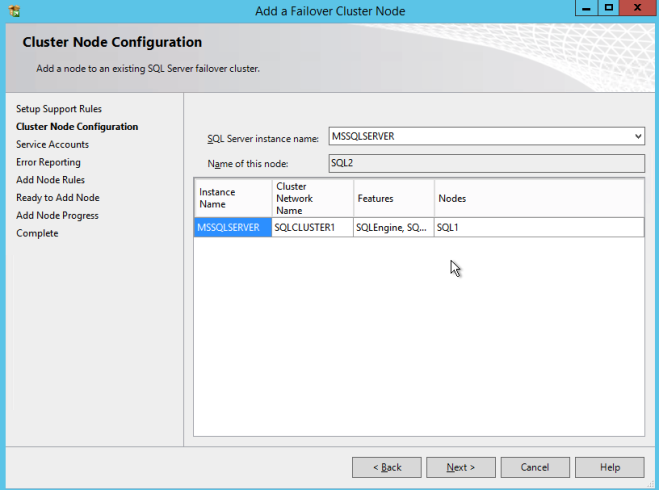



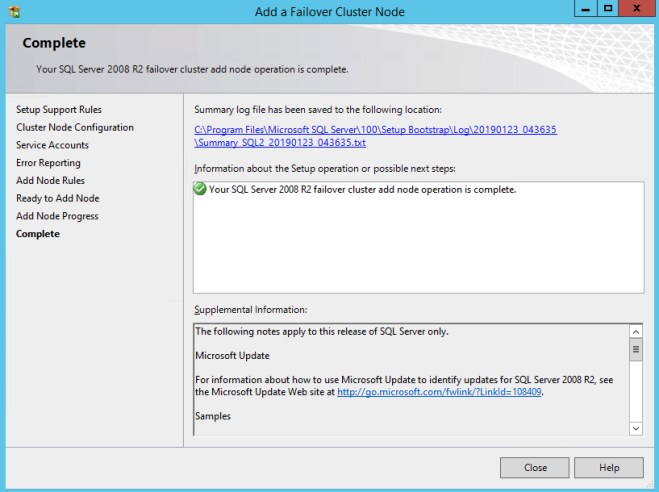
모든 것이 잘되었다고 가정하면 이제 다음과 같은 두 노드의 SQL Server 2008 R2 클러스터가 구성되어 있어야합니다.

그러나 활성 클러스터 노드의 SQL Server 인스턴스에만 연결할 수 있습니다.









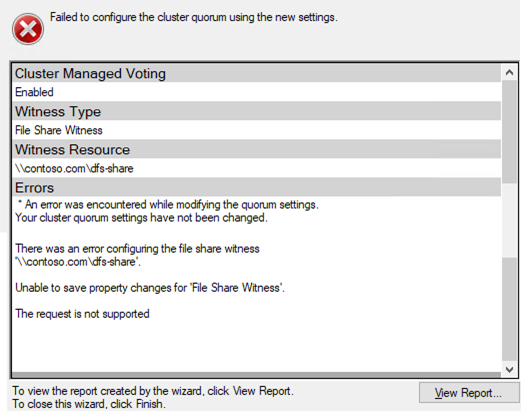 로그 게시물 "장애 조치 (Failover) 클러스터 파일 공유 감시 및 DFS [캡션]"캡션 ID = ""align = "alignnone"width = "529"
로그 게시물 "장애 조치 (Failover) 클러스터 파일 공유 감시 및 DFS [캡션]"캡션 ID = ""align = "alignnone"width = "529"

 이 차트를 살펴보면 SIOS DataKeeper에는 몇 가지 중요한 이점이 있음을 알 수 있습니다. 그 중 하나 인 DataKeeper는 Windows Server 2008 R2 및 SQL Server 2008 R2로 다시 돌아가는 훨씬 다양한 플랫폼을 지원합니다. S2D 솔루션은 Windows 및 SQL Server 2016/2017의 최신 릴리스 만 지원합니다. 또한 S2D는 Windows Datacenter Edition을 필요로하므로 배포 비용이 크게 추가 될 수 있습니다. 또한 SIOS는 온 – 프레미엄과 클
이 차트를 살펴보면 SIOS DataKeeper에는 몇 가지 중요한 이점이 있음을 알 수 있습니다. 그 중 하나 인 DataKeeper는 Windows Server 2008 R2 및 SQL Server 2008 R2로 다시 돌아가는 훨씬 다양한 플랫폼을 지원합니다. S2D 솔루션은 Windows 및 SQL Server 2016/2017의 최신 릴리스 만 지원합니다. 또한 S2D는 Windows Datacenter Edition을 필요로하므로 배포 비용이 크게 추가 될 수 있습니다. 또한 SIOS는 온 – 프레미엄과 클