เอกสารทางเทคนิค: การนำความพร้อมใช้งานสูงมาใช้ในสภาพแวดล้อม Linux โดยไม่ทำให้ประสิทธิภาพหรือความปลอดภัยลดลง
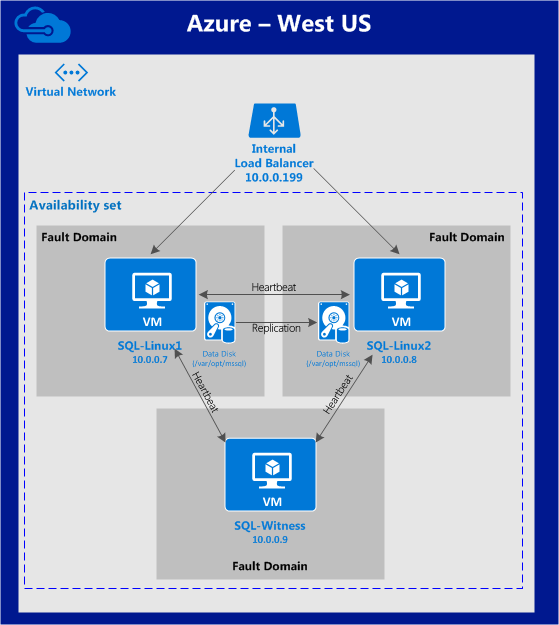
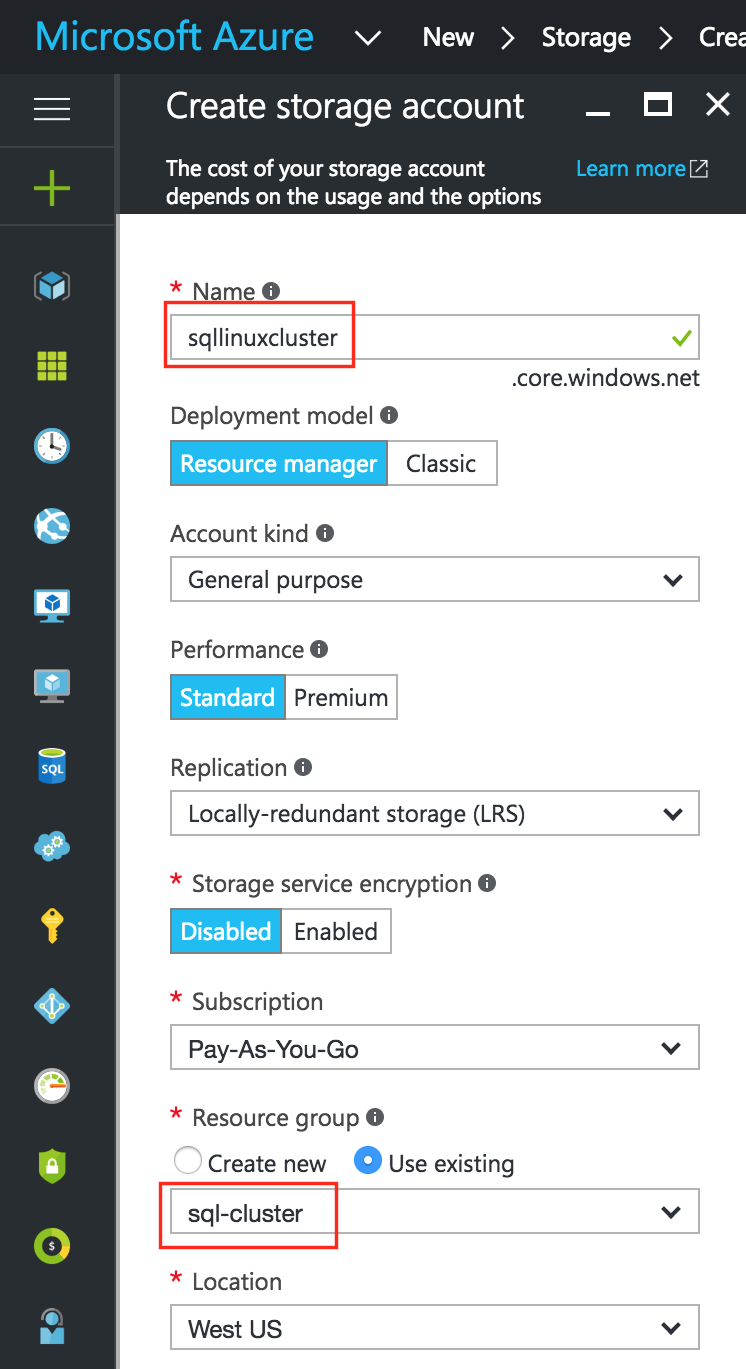
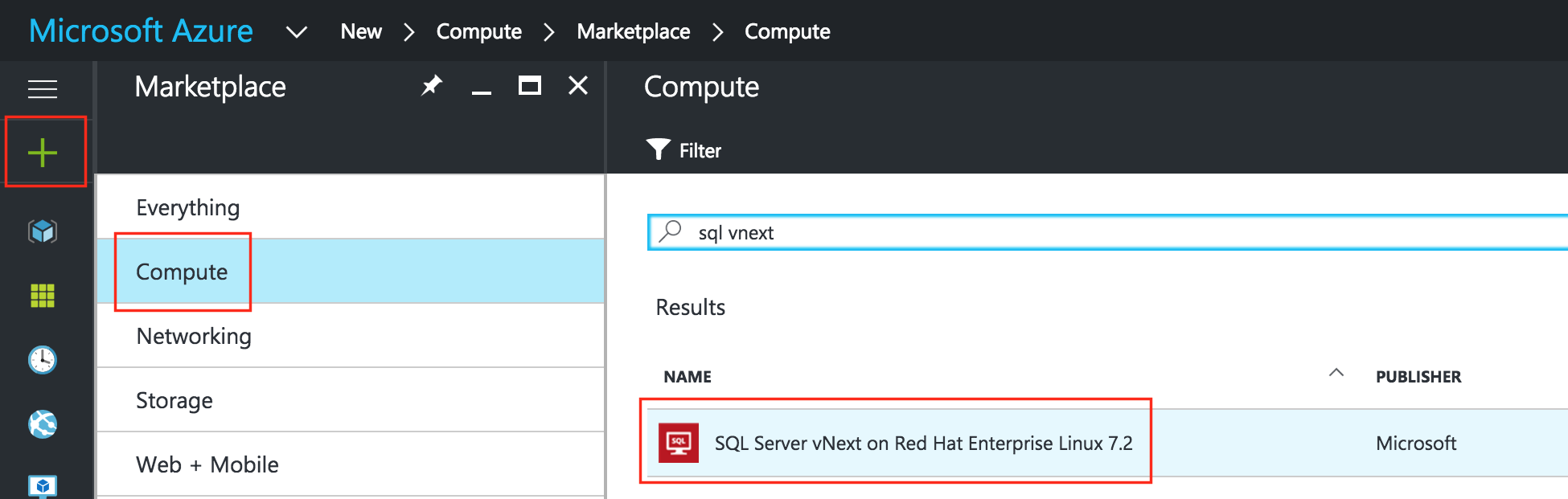
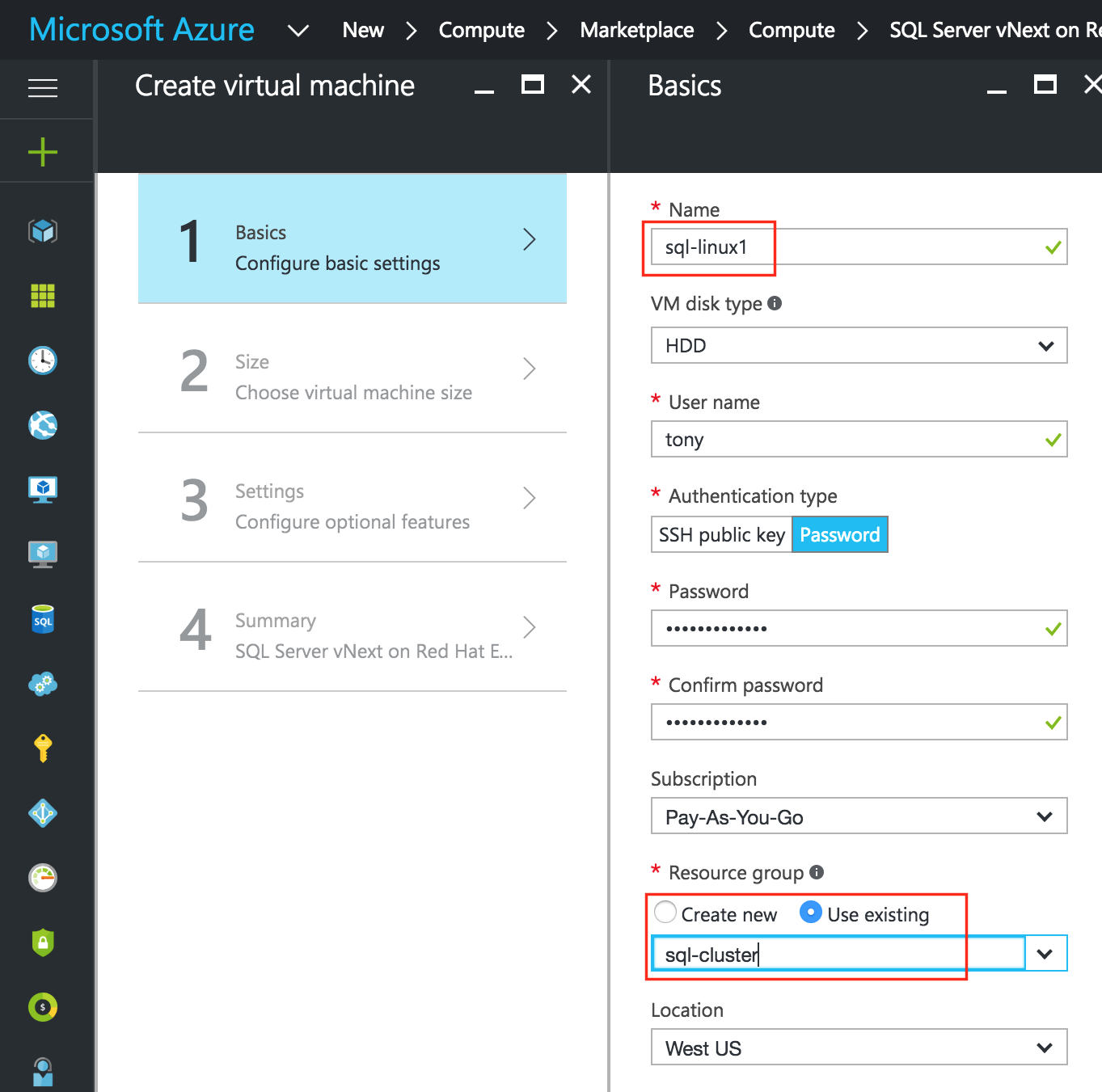
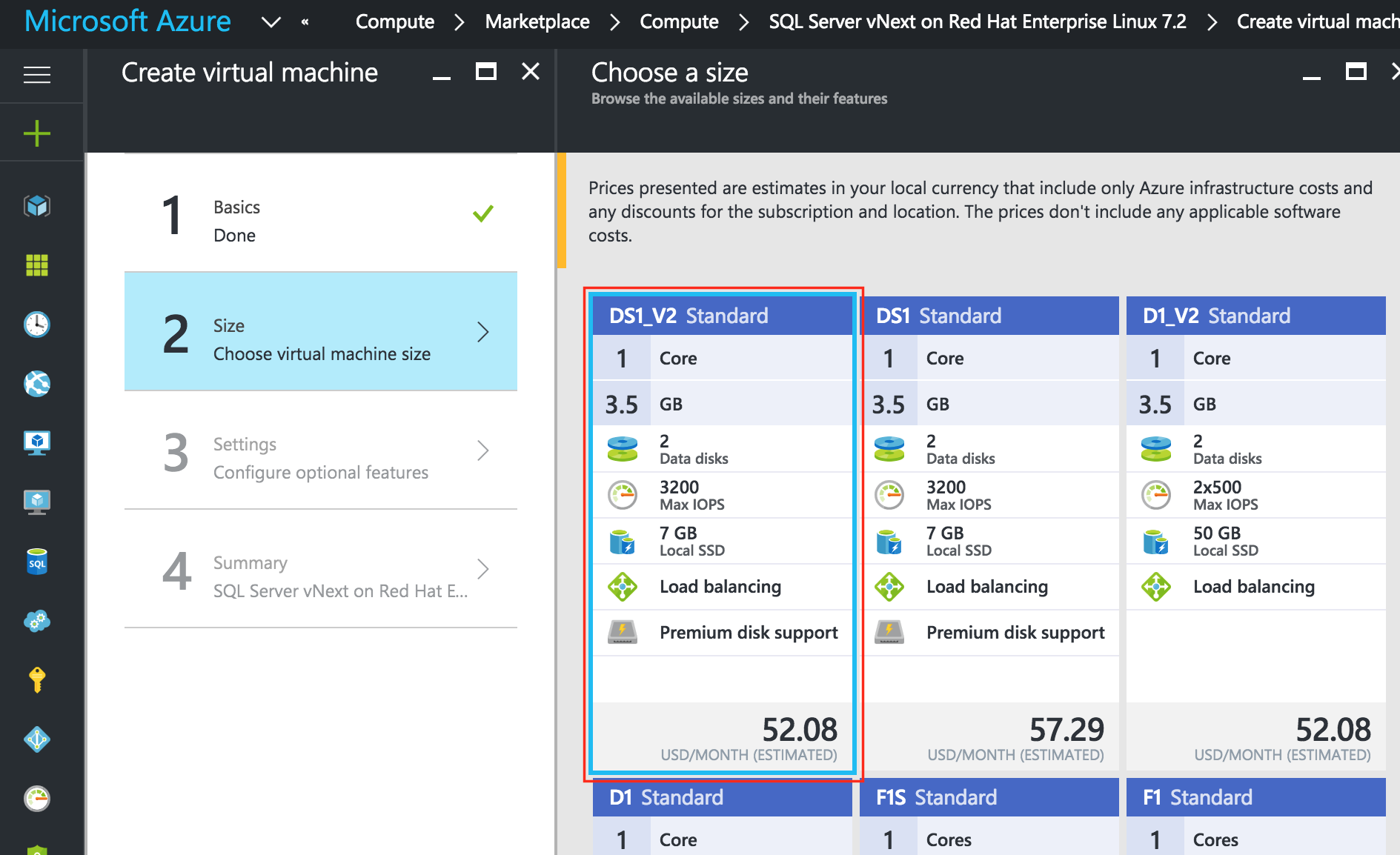
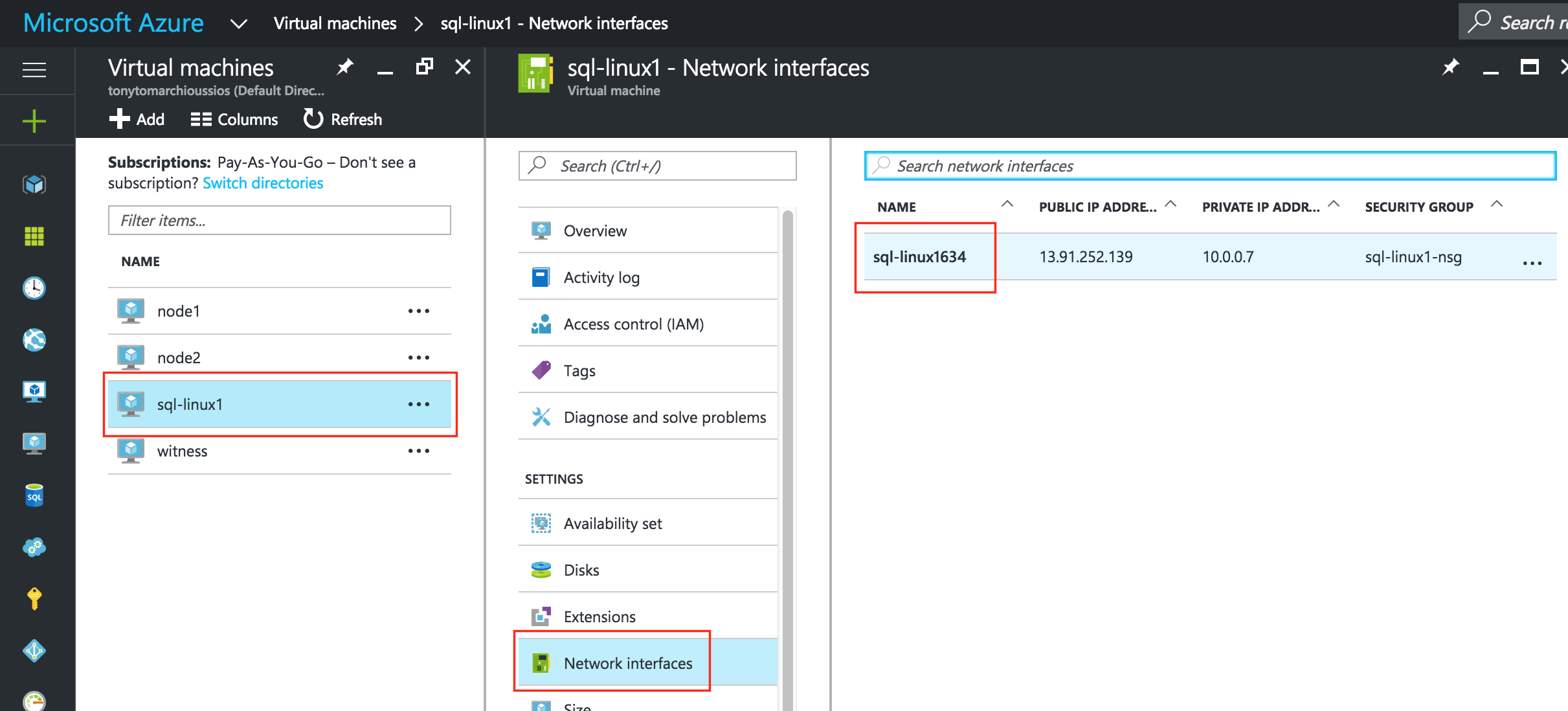
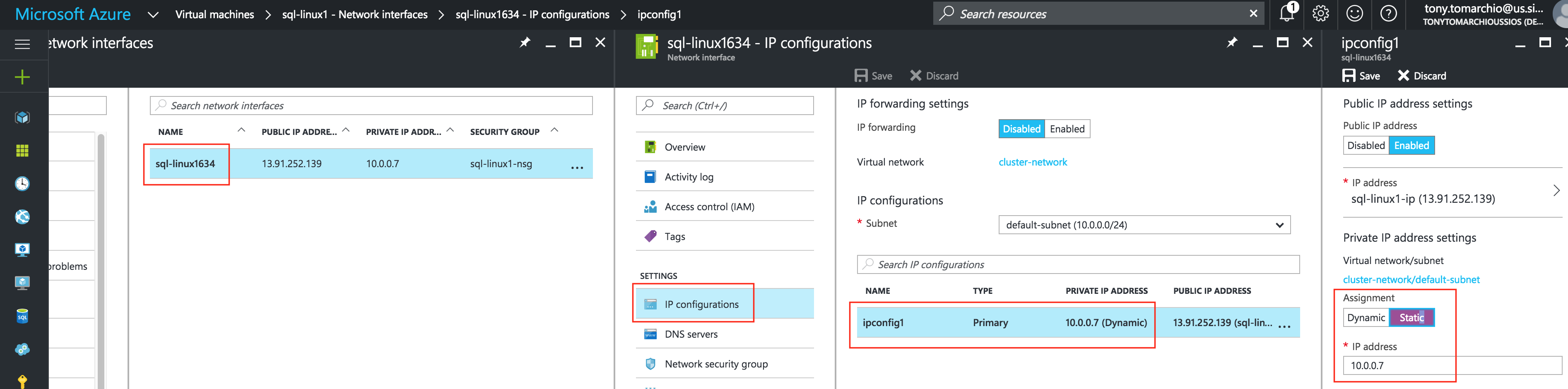
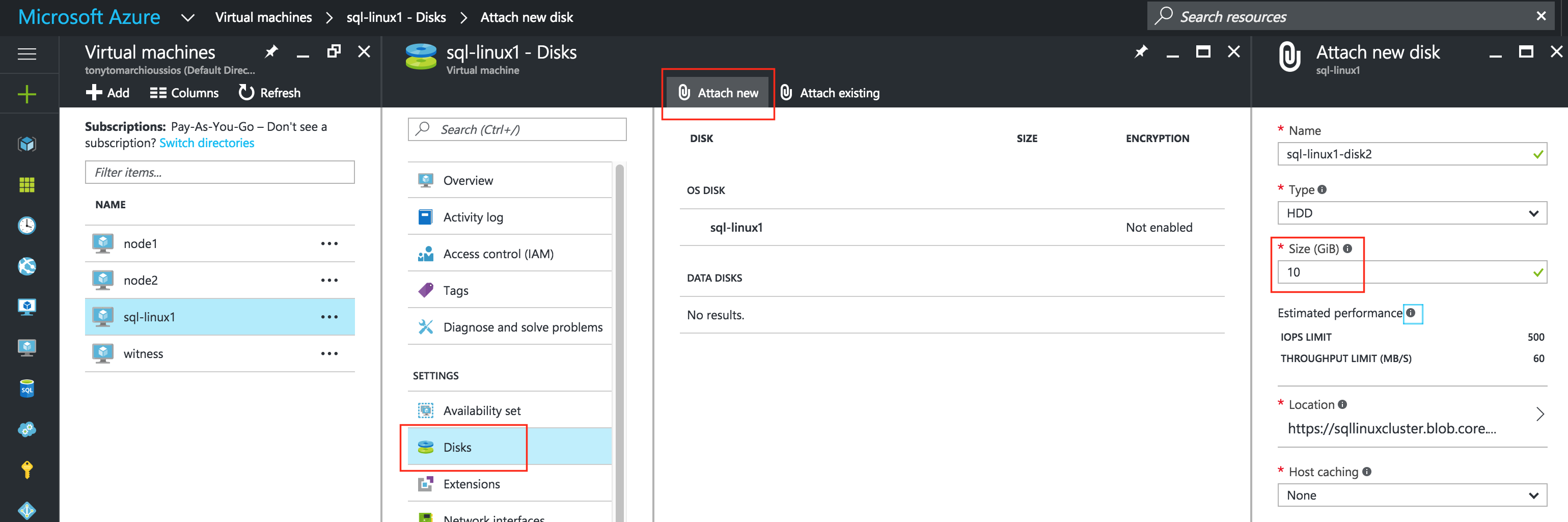
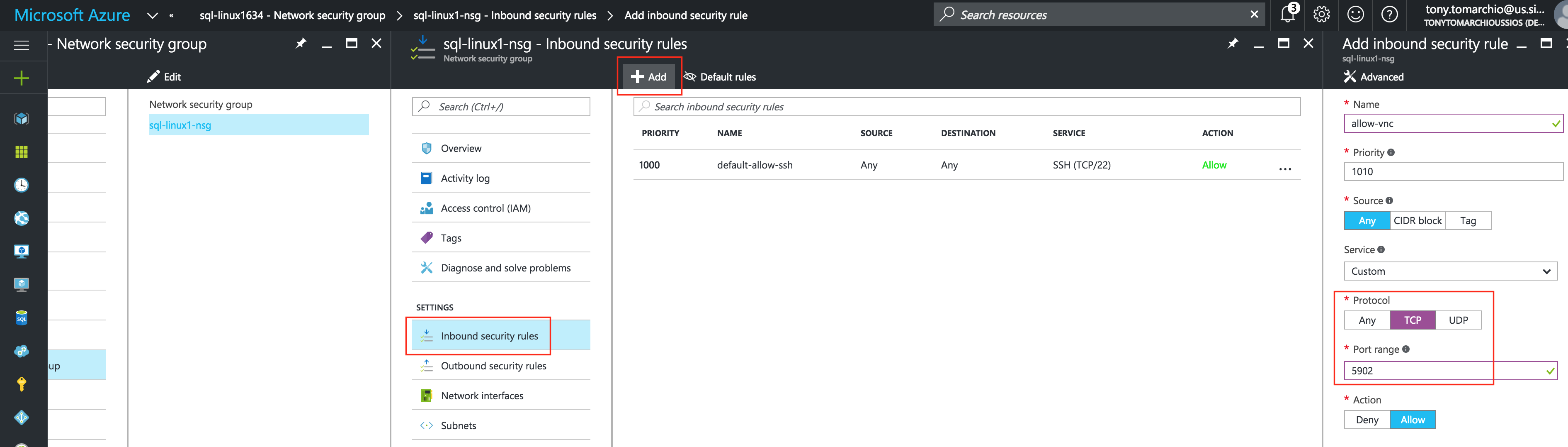
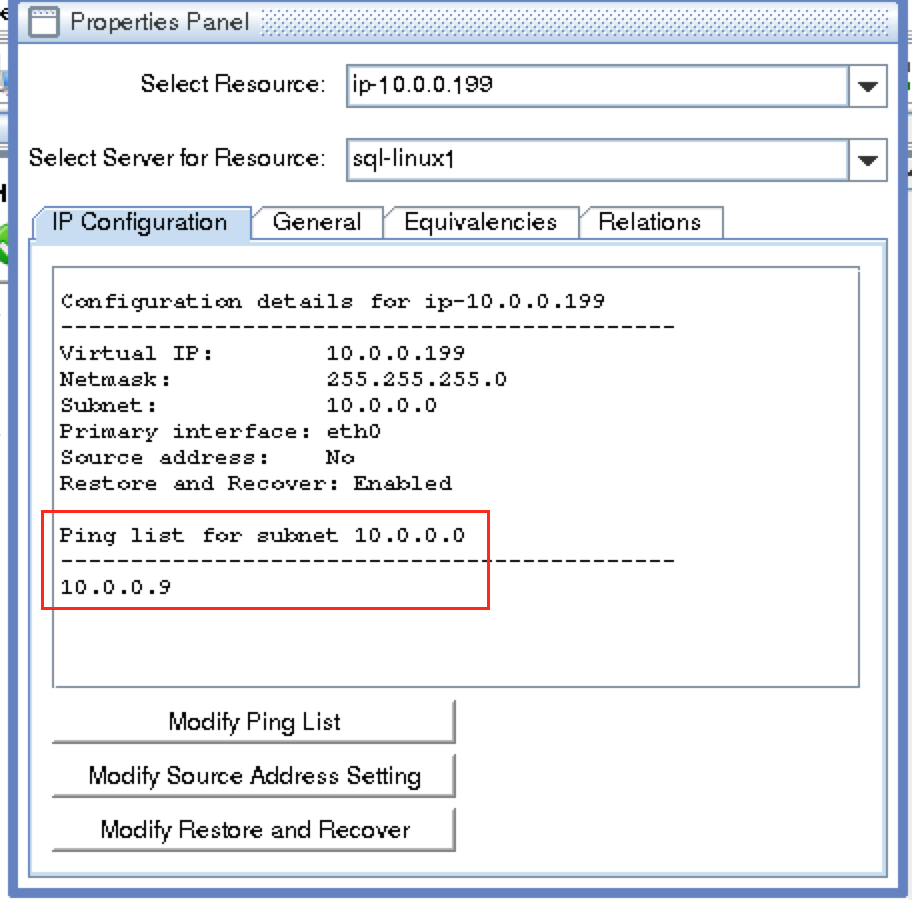
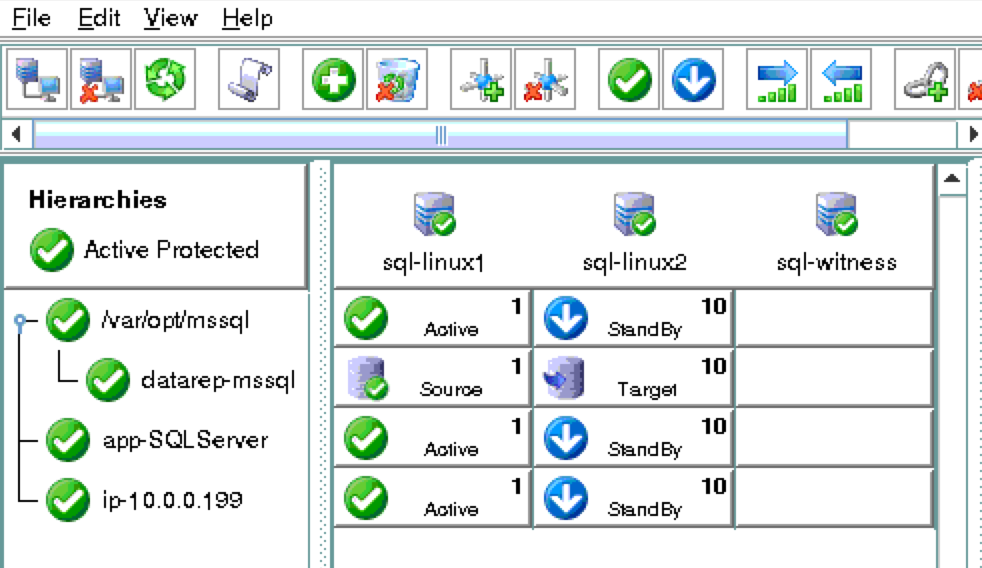
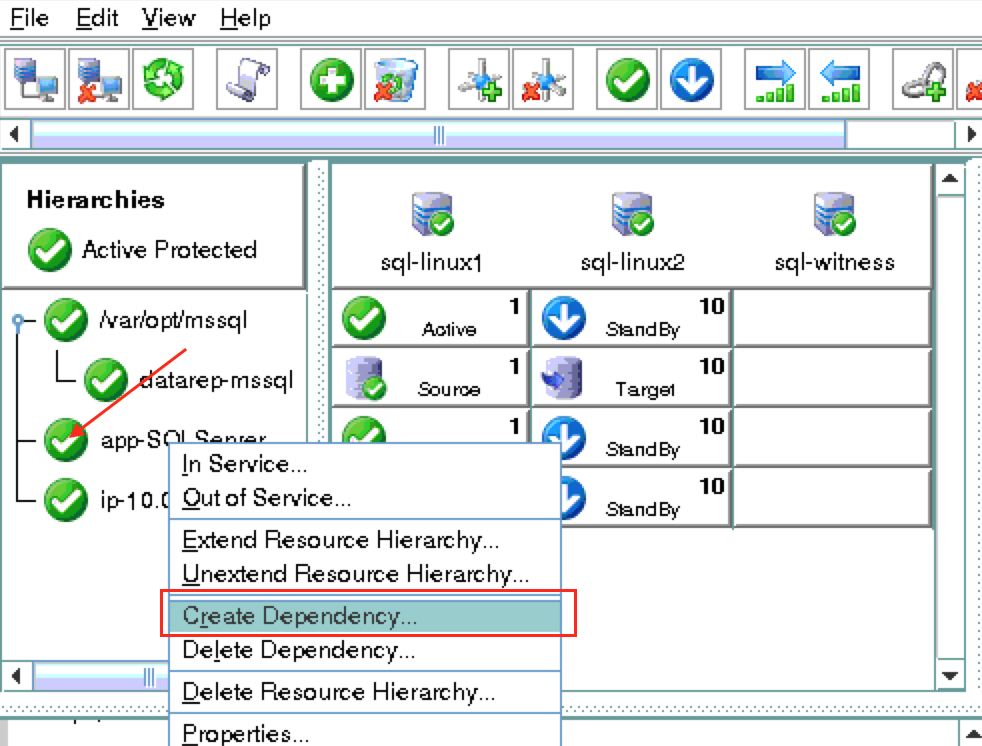
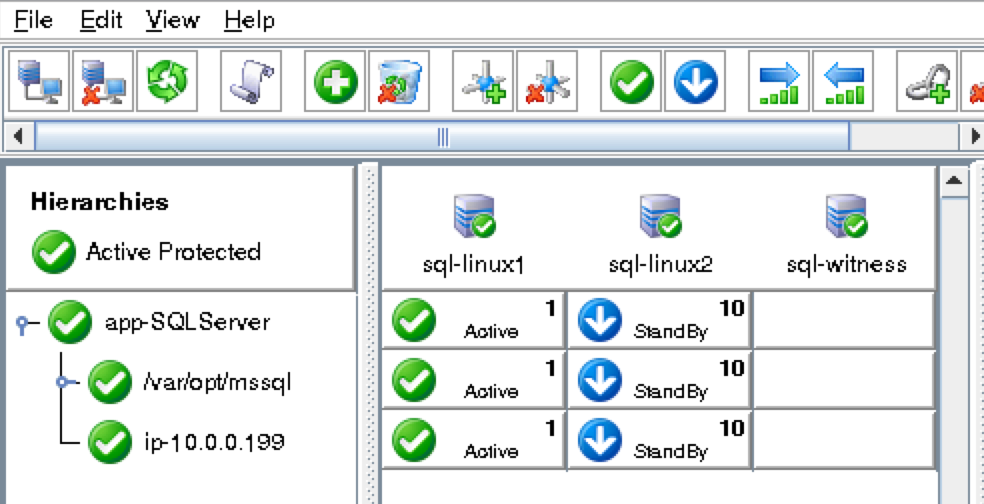
การใช้โซลูชันโอเพนซอร์ซสามารถลดค่าใช้จ่ายด้านทุนได้อย่างมากโดยเฉพาะค่าธรรมเนียมการออกใบอนุญาตซอฟต์แวร์ แต่องค์กรส่วนใหญ่ก็เข้าใจว่าซอฟต์แวร์โอเพ่นซอร์สต้องการ "การดูแลและให้อาหาร" มากกว่าซอฟต์แวร์เชิงพาณิชย์ซึ่งบางครั้งอาจทำให้ค่าใช้จ่ายในการดำเนินงานเพิ่มขึ้นสูงกว่าการประหยัดที่มีศักยภาพใน CapEx เอกสารทางเทคนิคนี้สำรวจว่าองค์กรต่างๆสามารถลดทั้ง CapEx และ OpEx ในการใช้งานแอพพลิเคชั่นที่มีความพร้อมใช้งานสูงในสภาพแวดล้อม Linux โดยไม่ทำให้ประสิทธิภาพหรือความปลอดภัยลดลง
เรียนรู้เพิ่มเติมเกี่ยวกับ SIOS Protection Suite สำหรับ Linux ซึ่งมีองค์ประกอบทั้งหมดที่คุณต้องการในการสร้างคลัสเตอร์ Linux ที่มีความพร้อมใช้งานสูงอย่างรวดเร็วและง่ายดาย
ดาวน์โหลดเอกสารข้อมูลทางเทคนิคบนกระดาษสีขาว: ปรับใช้ความพร้อมใช้งานสูงในสภาพแวดล้อม Linux