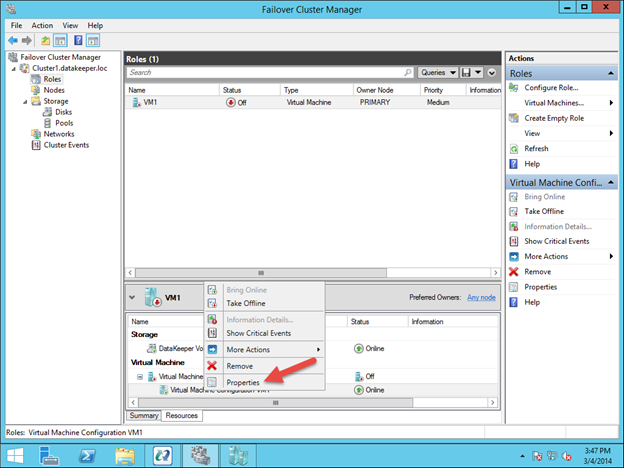
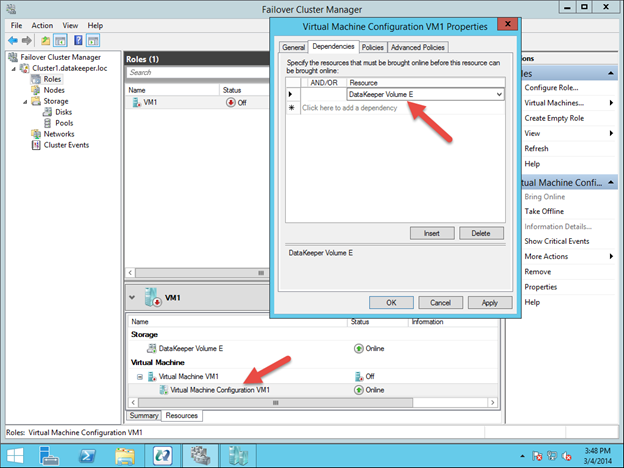
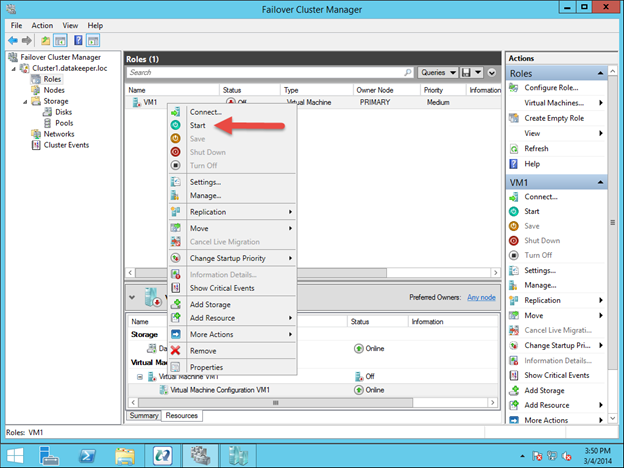
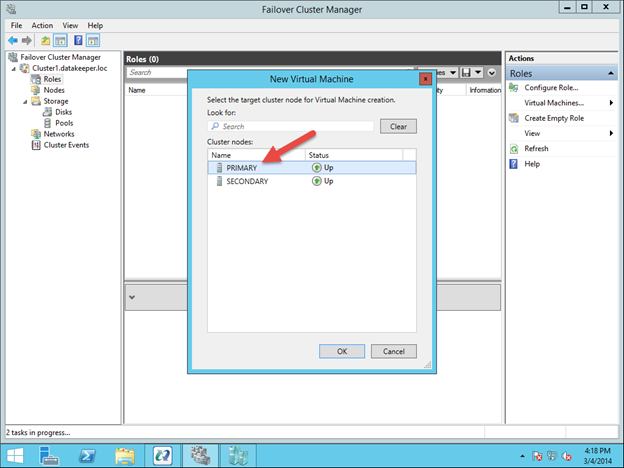
Google Cloud Platform에서 무자비한 SQL Server 장애 조치 (failover) 클러스터 인스턴스를 구축하는 방법
Google Cloud Platform (GCP)에서 SQL Server를 호스팅하려면 높은 가용성을 유지해야합니다. Google Cloud Platform에서 Sanless SQL Server 장애 조치 (Failover) 클러스터 인스턴스를 구축하는 것이 가장 경제적이며 경제적 인 방법 중 하나입니다.
비용 효과적
SQL Server Standard Edition은 장애 조치 (Failover) 클러스터링을 지원하므로 항상 가용성 그룹에 필요한 SQL Server Enterprise Edition과 관련된 비용을 피할 수 있습니다. 또한 SQL Server 장애 조치 클러스터링은 SQL Server의 전체 인스턴스를 보호하므로 훨씬 강력한 솔루션입니다. DTC (Distributed Transaction Coordinator) 지원 측면에서 제한이 없으며 관리가 더 쉽습니다. 또한 SQL 2012와 최신 SQL 2017과 같은 이전 버전의 SQL Server를 여전히 지원할 수 있습니다. 불행히도 SQL 2008 R2는 교차 서브넷 장애 조치에 대한 지원이 부족하기 때문에 지원되지 않습니다.
SIOS Datakeeper와 다른 점은 무엇입니까?
전통적으로 SQL Server FCI를 사용하려면 SAN 또는 일부 유형의 공유 저장 장치가 있어야합니다. 클라우드에는 클러스터 인식 공유 저장 장치가 없습니다. SAN 대신에 우리는 SIOS DataKeeper Cluster Edition (DKCE)을 사용하여 SANless 클러스터를 구축 할 것입니다. DKCE는 블록 수준 복제를 사용하여 각 인스턴스의 로컬로 연결된 저장소가 다른 인스턴스와 동기화되도록합니다. 또한 물리적 디스크 리소스를 대체하는 DataKeeper 볼륨이라는 자체 저장소 클래스 리소스를 통해 Windows Server 장애 조치 (Failover) 클러스터링과 통합됩니다. 클러스터에 관한 한, SIOS DataKeeper 볼륨은 SCSI 디스크를 제어하는 대신 실제 디스크처럼 보입니다. 미러 서버는 미러 서버의 방향을 제어하여 활성 서버 만 디스크에 기록하고 수동 서버가 모든 변경 사항을 동 기적 또는 비동기 적으로 수신하도록합니다.
Google Cloud Platform에서 Sanless SQL Server 장애 조치 (Failover) 클러스터 인스턴스 시작하기
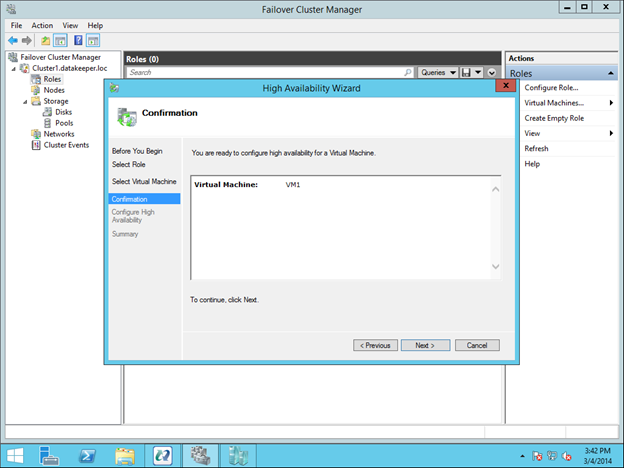
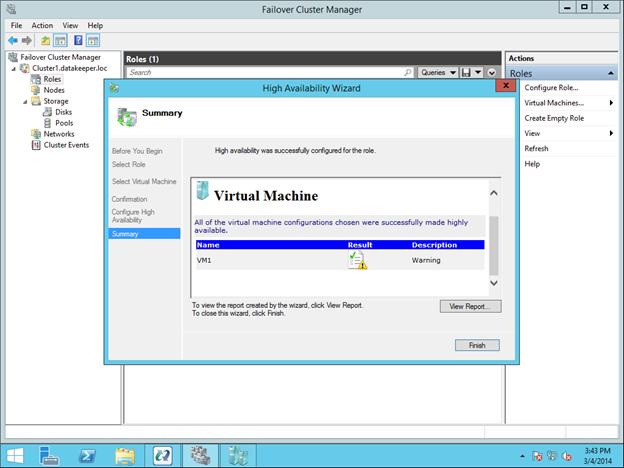
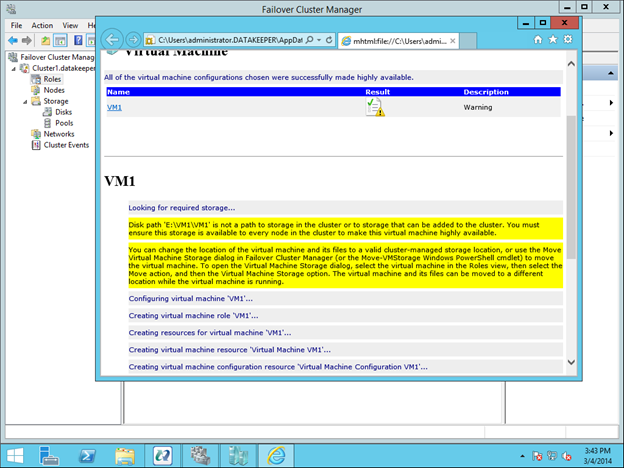
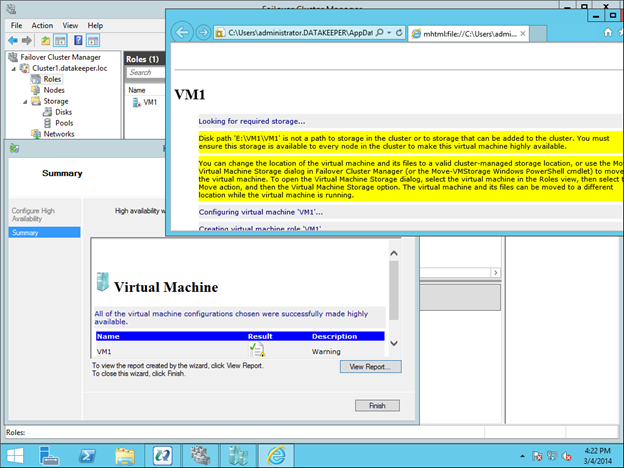
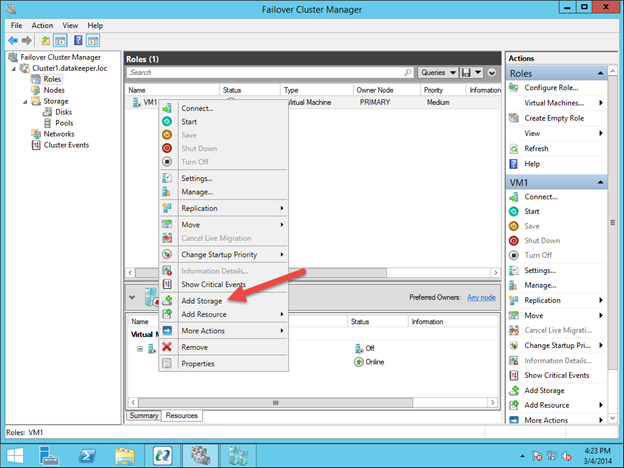
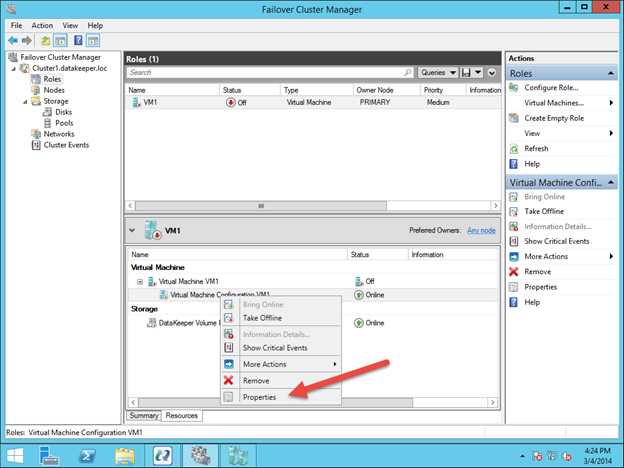
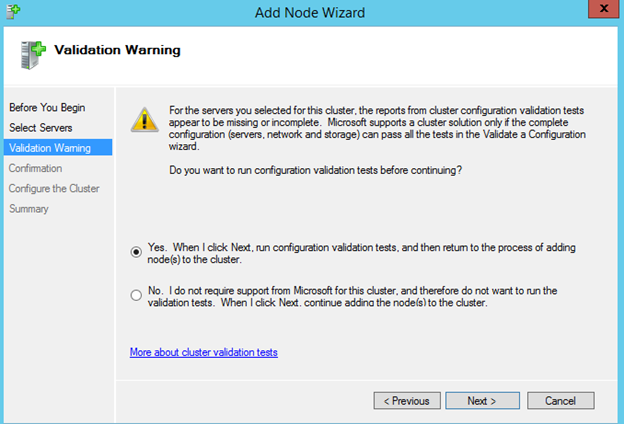
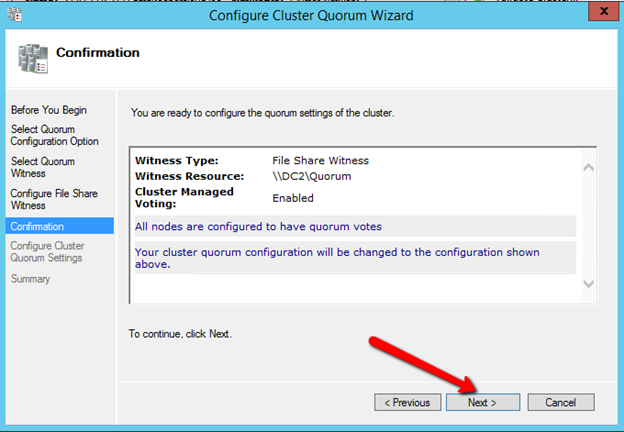
이 가이드에서는 동일한 영역의 두 인스턴스간에 두 노드 간 장애 조치 (failover) 클러스터를 구축하는 단계를 거치지 만 그림 1과 같이 GCP 내의 다른 영역에 있습니다. 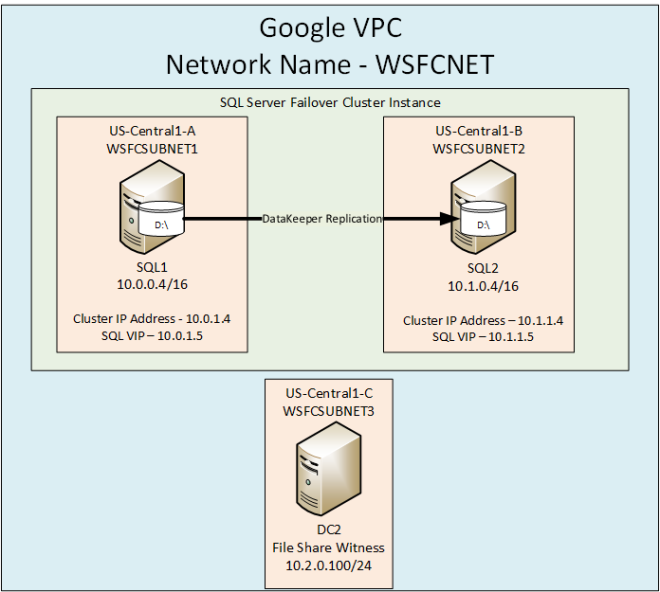 Sanless SQL Server 장애 조치 (Failover) 클러스터 인스턴스에 대해 자세히 알아 보려면 Google Cloud Platform에서 전체 백서 (https://us.sios.com/sios-resources/white-paper-build-sql-server-failover-cluster-gcp/ SIOS DataKeeper에 대해 자세히 알아보기 Clusteringformeremortals.com의 허가를 받아 복제했습니다.
Sanless SQL Server 장애 조치 (Failover) 클러스터 인스턴스에 대해 자세히 알아 보려면 Google Cloud Platform에서 전체 백서 (https://us.sios.com/sios-resources/white-paper-build-sql-server-failover-cluster-gcp/ SIOS DataKeeper에 대해 자세히 알아보기 Clusteringformeremortals.com의 허가를 받아 복제했습니다.

 그림 3 – 클러스터 노드와 파일 공유 감시 서버를 모두 동일한 가용성 집합에 추가해야합니다.
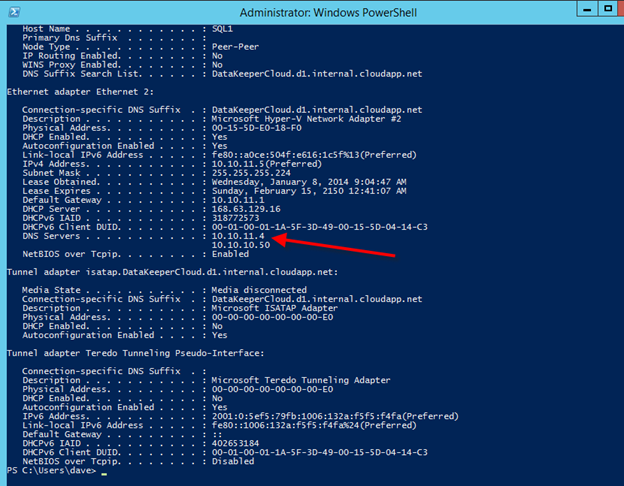
그림 3 – 클러스터 노드와 파일 공유 감시 서버를 모두 동일한 가용성 집합에 추가해야합니다. 그림 4 – 각 클러스터 노드가 고정 IP를 사용하는지 확인
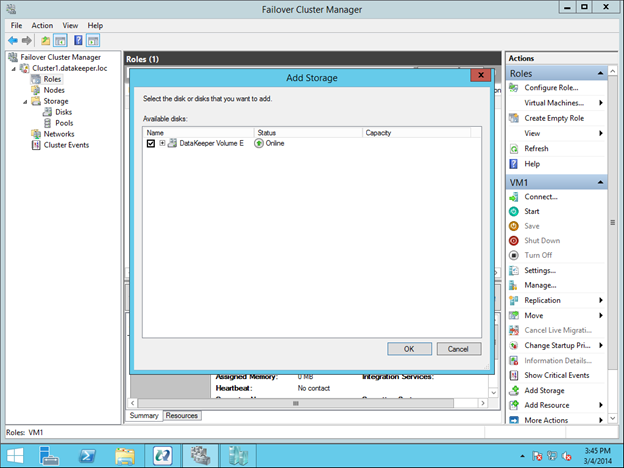
그림 4 – 각 클러스터 노드가 고정 IP를 사용하는지 확인 그림 5 – 각 클러스터 노드에 저장소를 추가해야합니다.
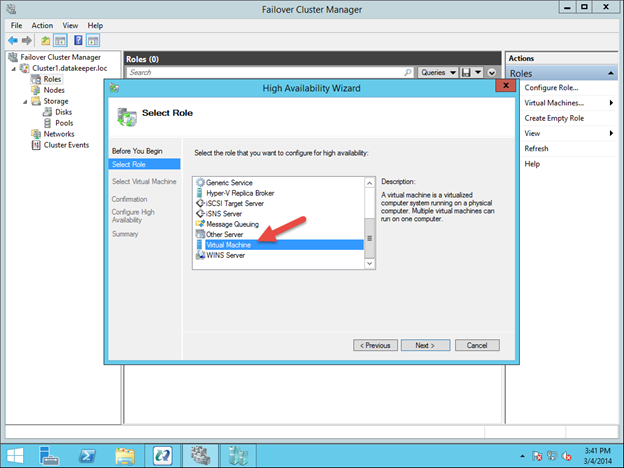
그림 5 – 각 클러스터 노드에 저장소를 추가해야합니다. 그림 6 – .Net Framework 3.5 및 장애 조치 (Failover) 클러스터링 기능과 두 클러스터 노드의 파일 서버를 사용하도록 설정 역할 및 해당 기능을 사용하도록 설정하면 클러스터를 구축 할 수 있습니다. PowerShell과 GUI를 통해 수행 할 수있는 대부분의 단계가 나와 있습니다. 그러나이 첫 번째 단계에서는 PowerShell을 사용하여 클러스터를 만드는 것이 좋습니다. 장애 조치 (Failover) 클러스터 관리자 GUI를 사용하여 클러스터를 만들면 클러스터가 중복 IP 주소를 발행하면서 퇴사한다는 것을 알게 될 것입니다.
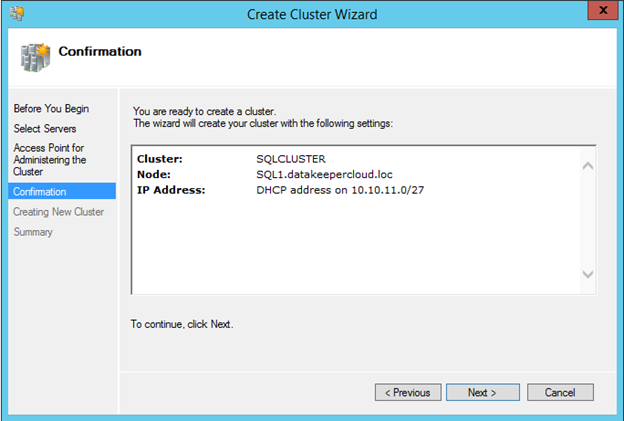
그림 6 – .Net Framework 3.5 및 장애 조치 (Failover) 클러스터링 기능과 두 클러스터 노드의 파일 서버를 사용하도록 설정 역할 및 해당 기능을 사용하도록 설정하면 클러스터를 구축 할 수 있습니다. PowerShell과 GUI를 통해 수행 할 수있는 대부분의 단계가 나와 있습니다. 그러나이 첫 번째 단계에서는 PowerShell을 사용하여 클러스터를 만드는 것이 좋습니다. 장애 조치 (Failover) 클러스터 관리자 GUI를 사용하여 클러스터를 만들면 클러스터가 중복 IP 주소를 발행하면서 퇴사한다는 것을 알게 될 것입니다. 그림 7 – 클러스터 생성 및 클러스터 유효성 검사 명령의 출력
그림 7 – 클러스터 생성 및 클러스터 유효성 검사 명령의 출력 그림 8 – 클러스터 생성 후 DataKeeper 설치 설치 중에 모든 기본 옵션을 사용할 수 있습니다. 사용하는 서비스 계정은 도메인 계정이어야하며 클러스터의 각 노드에있는 로컬 관리자 그룹에 있어야합니다.
그림 8 – 클러스터 생성 후 DataKeeper 설치 설치 중에 모든 기본 옵션을 사용할 수 있습니다. 사용하는 서비스 계정은 도메인 계정이어야하며 클러스터의 각 노드에있는 로컬 관리자 그룹에 있어야합니다.  그림 9 – 서비스 계정은 각 노드의 로컬 관리자 그룹에있는 도메인 계정이어야합니다. DataKeeper를 각 노드에 설치하고 라이센스를 부여한 후에는 서버를 다시 부팅해야합니다.
그림 9 – 서비스 계정은 각 노드의 로컬 관리자 그룹에있는 도메인 계정이어야합니다. DataKeeper를 각 노드에 설치하고 라이센스를 부여한 후에는 서버를 다시 부팅해야합니다. SQL1에 연
SQL1에 연 결 SQL2에
결 SQL2에  연결 각 서버에 연결되면 DataKeeper 볼륨을 만들 준비가 된 것입니다. 작업을 마우스 오른쪽 단추로 클릭하고 "작업 작성"을
연결 각 서버에 연결되면 DataKeeper 볼륨을 만들 준비가 된 것입니다. 작업을 마우스 오른쪽 단추로 클릭하고 "작업 작성"을  선택하십시오. 작업 이름과 설명을 입력하십시오.
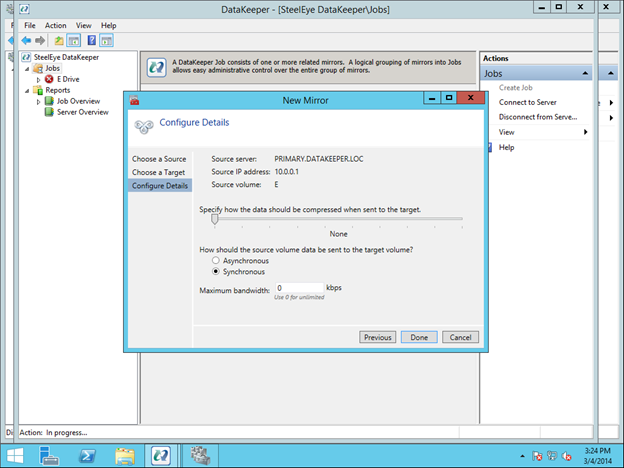
선택하십시오. 작업 이름과 설명을 입력하십시오.  원본 서버, IP 및 볼륨을 선택하십시오. IP 주소는 복제 트래픽이 이동할지 여부입니다.
원본 서버, IP 및 볼륨을 선택하십시오. IP 주소는 복제 트래픽이 이동할지 여부입니다.  대상 서버를 선택하십시오.
대상 서버를 선택하십시오.  옵션을 선택하십시오. 두 VM이 동일한 지리적 영역에있는 우리의 목적을 위해 우리는 동기식 복제를 선택할 것입니다. 장거리 복제의 경우 비동기를 사용하고 일부 압축을 사용하고자 할 것입니다.
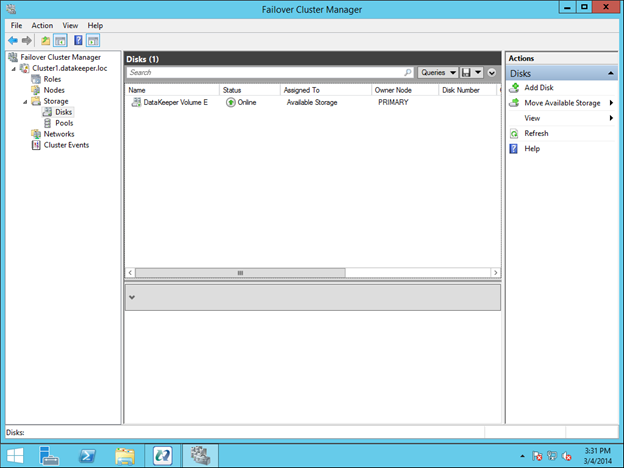
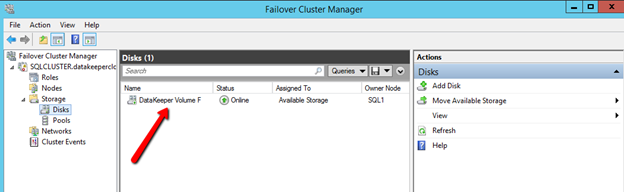
옵션을 선택하십시오. 두 VM이 동일한 지리적 영역에있는 우리의 목적을 위해 우리는 동기식 복제를 선택할 것입니다. 장거리 복제의 경우 비동기를 사용하고 일부 압축을 사용하고자 할 것입니다.  마지막 팝업에서 예를 클릭하면 장애 조치 클러스터링에서 사용 가능한 저장소에 새로운 DataKeeper 볼륨 리소스가 등록됩니다. 사용 가능한 저장소에 새 DataKeeper 볼륨 리소스가 표시됩니다.
마지막 팝업에서 예를 클릭하면 장애 조치 클러스터링에서 사용 가능한 저장소에 새로운 DataKeeper 볼륨 리소스가 등록됩니다. 사용 가능한 저장소에 새 DataKeeper 볼륨 리소스가 표시됩니다. 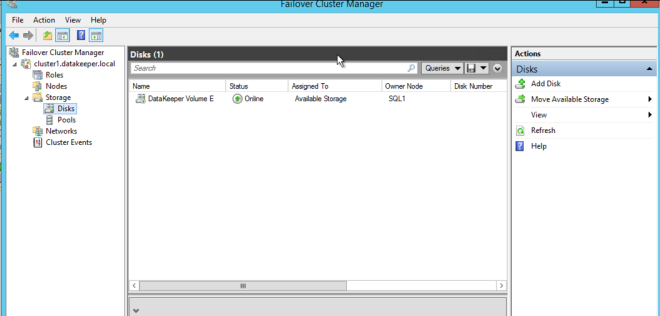
 다. 클라이언트가 공용 인터넷을 통해 연결하는 경우 공용로드 밸런서를 사용할 수 있지만 클라이언트가 동일한 vNet에 있다고 가정하면 내부로드 밸런서가 생성됩니다. 여기서 중요한 점은 가상 네트워크가 클러스터 노드가 상주하는 네트워크와 동일하다는 것입니다. 또한 지정한 개인 IP 주소는 SQL 클러스터 리소스를 만드는 데 사용한 주소와 정확히 동일합니다.
다. 클라이언트가 공용 인터넷을 통해 연결하는 경우 공용로드 밸런서를 사용할 수 있지만 클라이언트가 동일한 vNet에 있다고 가정하면 내부로드 밸런서가 생성됩니다. 여기서 중요한 점은 가상 네트워크가 클러스터 노드가 상주하는 네트워크와 동일하다는 것입니다. 또한 지정한 개인 IP 주소는 SQL 클러스터 리소스를 만드는 데 사용한 주소와 정확히 동일합니다.  내부 부하 분산 장치 (ILB)를 만든 후에는 편집해야합니다. 우리가 할 첫 번째 일은 백엔드 풀을 추가하는 것입니다. 이 프로세스를 통해 SQL 클러스터 VM이 상주하는 가용성 세트를 선택하게됩니다. 그러나 실제 VM을 선택하여 백 엔드 풀에 추가 할 때는 파일 공유 감시를 선택하지 마십시오. SQL 트래픽을 파일 공유 감시로 리디렉션하고 싶지는 않습니다.
내부 부하 분산 장치 (ILB)를 만든 후에는 편집해야합니다. 우리가 할 첫 번째 일은 백엔드 풀을 추가하는 것입니다. 이 프로세스를 통해 SQL 클러스터 VM이 상주하는 가용성 세트를 선택하게됩니다. 그러나 실제 VM을 선택하여 백 엔드 풀에 추가 할 때는 파일 공유 감시를 선택하지 마십시오. SQL 트래픽을 파일 공유 감시로 리디렉션하고 싶지는 않습니다. 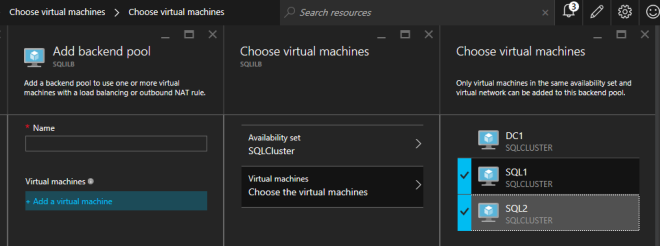
 다음으로 할 일은 프로브를 추가하는 것입니다. 우리가 추가 한 프로브는 포트 59999를 프로브합니다. 이 프로브는 클러스터에서 어떤 노드가 활성 상태인지 확인합니다.
다음으로 할 일은 프로브를 추가하는 것입니다. 우리가 추가 한 프로브는 포트 59999를 프로브합니다. 이 프로브는 클러스터에서 어떤 노드가 활성 상태인지 확인합니다.  마지막으로 SMB 트래픽 (TCP 포트 445)을 리디렉션하는로드 균형 조정 규칙이 필요합니다. 아래 스크린 샷에서 주목할 점은 Direct Server Return is Enabled입니다. 당신이 그 변화를 만들 었는지 확인하십시오.
마지막으로 SMB 트래픽 (TCP 포트 445)을 리디렉션하는로드 균형 조정 규칙이 필요합니다. 아래 스크린 샷에서 주목할 점은 Direct Server Return is Enabled입니다. 당신이 그 변화를 만들 었는지 확인하십시오.