다운타임으로부터 시스템 보호
오늘날의 비즈니스 환경에서 조직은 SAP, SQL Server, Oracle 등과 같은 애플리케이션, 데이터베이스 및 ERP 시스템에 의존합니다. 이러한 애플리케이션은 가장 중요한 비즈니스 운영을 통합하고 간소화합니다. 실패하면 돈보다 더 많은 비용이 듭니다. 이러한 복잡한 시스템을 다운타임으로부터 보호하는 것이 중요합니다.
입증된 고가용성 및 재해 복구
SIOS는 20년 이상의 경험을 가지고 있습니다. 고가용성 그리고 재해 복구 .SIOS는 모든 솔루션에 딱 맞는 사이즈가 없다는 것을 알고 있습니다. 오늘날의 데이터 시스템은 온프레미스, 퍼블릭 클라우드, 하이브리드 클라우드 및 멀티 클라우드 환경의 조합입니다. 애플리케이션 자체로 인해 훨씬 더 복잡해질 수 있습니다. 그러나 오픈 소스 클러스터 소프트웨어를 구성하는 것은 힘들고 시간이 많이 걸리며 인적 오류가 발생하기 쉽습니다.
SIOS는 중요한 애플리케이션을 위한 고가용성 및 재해 복구를 제공하는 솔루션을 보유하고 있습니다. 이러한 솔루션은 다양한 산업 및 사용 사례 전반에 걸쳐 당사의 실제 경험을 기반으로 개발되었습니다. 우리의 제품은 다음을 포함합니다 Windows용 SIOS DataKeeper 클러스터 에디션 그리고 Linux용 SIOS LifeKeeper 또는 Windows. 이러한 강력한 애플리케이션은 장애 조치 보호를 제공합니다. LifeKeeper에 포함된 애플리케이션 복구 키트는 구성을 자동화하고 입력을 검증하여 애플리케이션 구성 시간을 단축합니다.
온프레미스, 클라우드 또는 하이브리드 환경에서 시스템 보호
SIOS는 온프레미스, 클라우드 또는 하이브리드 클라우드 환경에서 비즈니스 크리티컬 애플리케이션에 필요한 보호 기능을 제공하고 관리 복잡성을 줄입니다. 아래 비디오에서 당사에 대해 자세히 알아보거나 문의하기 비즈니스 크리티컬 애플리케이션을 위한 고가용성 및 재해 복구에 대해 자세히 알아보십시오.

의 허가를 받아 재생산 시오스

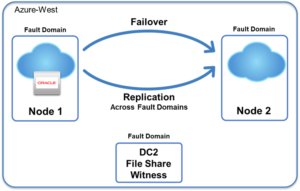
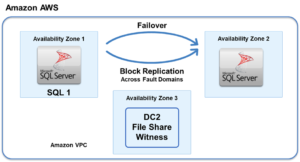

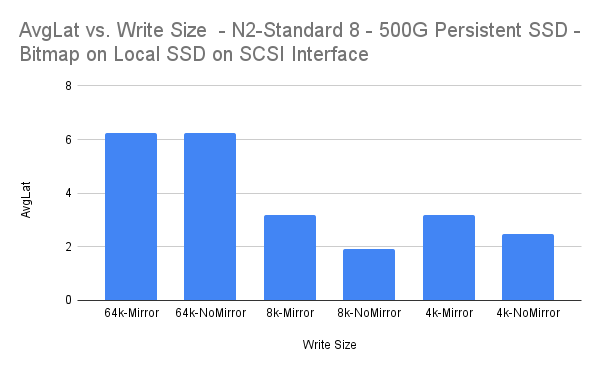
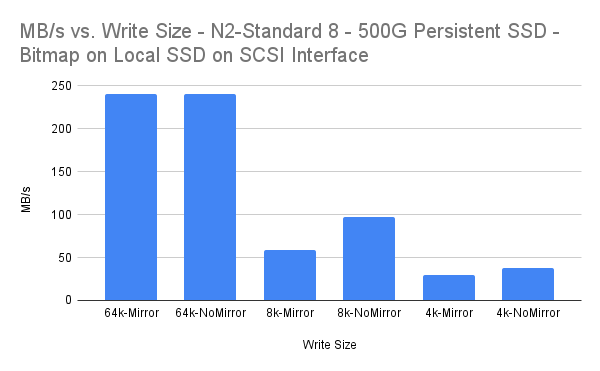
 일반 클러스터 환경에서 보호된 애플리케이션은 클러스터의 기본 노드에서 실행됩니다.해당 기본 노드의 애플리케이션 오류가 발생하는 경우 클러스터링 소프트웨어는 애플리케이션 작업을 기본 노드의 역할을 가정하는 보조 또는 원격 노드로 이동합니다. 주어진 시간에 하나의 기본 노드만 있습니다.
일반 클러스터 환경에서 보호된 애플리케이션은 클러스터의 기본 노드에서 실행됩니다.해당 기본 노드의 애플리케이션 오류가 발생하는 경우 클러스터링 소프트웨어는 애플리케이션 작업을 기본 노드의 역할을 가정하는 보조 또는 원격 노드로 이동합니다. 주어진 시간에 하나의 기본 노드만 있습니다.