
재해 복구를 위해 기존 SQL Server 장애 조치 클러스터 인스턴스를 클라우드로 확장하는 방법
일반적으로 나는 이것을 가리킨다. DataKeeper 문서 누군가가 기존 SQL Server 장애 조치 클러스터 인스턴스를 재해 복구를 위해 클라우드로 확장하는 방법을 물을 때.
이 첫 번째 문서에서는 클러스터를 확장하고 기존 클러스터에 세 번째 노드를 추가하는 방법에 대해 설명합니다. 클러스터가 3 개의 노드를 지원한다면 괜찮습니다. 그러나 SQL Server Standard Edition을 사용하는 경우 Microsoft는 2 노드 클러스터로 제한합니다. 2- 노드 클러스터의 경우. 여전히 세 번째 노드로 복제 할 수 있습니다. 복구는 수동 프로세스에 가깝다는 점을 명심하십시오. 이 프로세스는 여기 .
사람들은 일반적으로이 지침을 읽고 약간 걱정합니다. 그들은 클러스터에서 열린 심장 수술을 수행하는 것처럼 느낍니다. 정말 셔츠를 갈아 입는 것과 같습니다! 단순히 클러스터 디스크 리소스를 DataKeeper 볼륨 리소스로 바꾸는 것입니다. 아래 비디오에서 볼 수 있듯이 프로세스는 몇 초 밖에 걸리지 않습니다.

비디오에서 보여주는 코드는 다음과 같습니다.
Stop-ClusterGroup SQLServerGroup Remove-ClusterResource -Name "Cluster Disk 1"Set-Disk -Number 4 -IsOffline $ False Set-Disk -Number 4 -IsReadOnly $ False Import-Module -Name Storage Set-Partition -DiskNumber 4 -PartitionNumber 1- NewDriveLetter X New-DataKeeperMirror -SourceIP 10.0.2.100 -SourceVolume X -TargetIP 10.0.1.10 -TargetVolume X -SyncType Sync New-DataKeeperJob -JobName "x drive"-JobDescription "sql data"-Node1Name primary.datakeeper.local -Node1IP 10.0. 2.100 -Node1Volume x -Node2Name dr.datakeeper.local -Node2IP 10.0.1.10 -Node2Volume X -SyncType Sync Add-ClusterResource -Name "DataKeeper Volume X"-ResourceType "DataKeeper Volume"-Group "SQLServerGroup"Get-ClusterResource "DataKeeper Volume X "| Set-ClusterParameter VolumeLetter X Get-ClusterResource -Name 'SQLServer'| Add-ClusterResourceDependency -Provider 'DataKeeper Volume X'Start-ClusterGroup SQLServerGroup
해당 코드를 실행 한 후에는 공유 볼륨 관리를 클릭하여 비디오에 표시된대로 DataKeeper 작업에 백업 노드를 추가해야합니다.
SQL Server Enterprise Edition이있는 경우 마지막 단계는 DR 노드에 SQL Server를 설치하고 기존 클러스터에 노드 추가를 선택하는 것입니다.
SQL Server Standard Edition을 사용하는 경우 작업이 완료된 것입니다. 당신은 단순히 따라갈 것입니다 이 지침 세 번째 노드의 데이터에 액세스 한 다음 복제 된 데이터베이스를 마운트합니다.
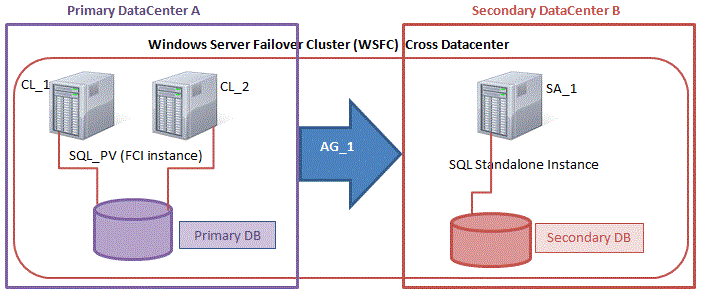
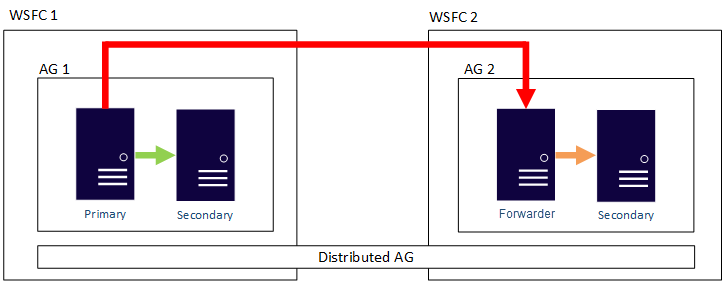
이러한 지침은 DR 노드가 클라우드에 있든 자체 DR 사이트에 있든 적용됩니다.



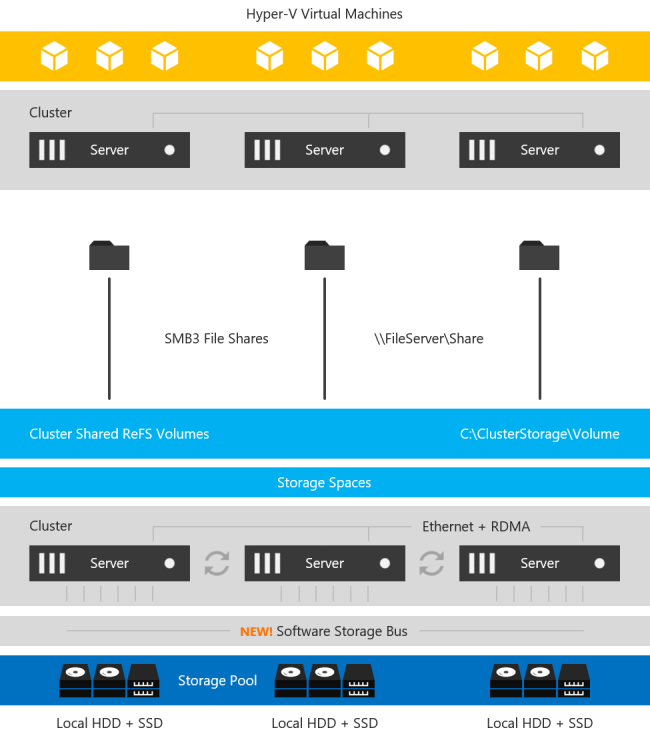

 이 차트를 살펴보면 SIOS DataKeeper에는 몇 가지 중요한 이점이 있음을 알 수 있습니다. 그 중 하나 인 DataKeeper는 Windows Server 2008 R2 및 SQL Server 2008 R2로 다시 돌아가는 훨씬 다양한 플랫폼을 지원합니다. S2D 솔루션은 Windows 및 SQL Server 2016/2017의 최신 릴리스 만 지원합니다. 또한 S2D는 Windows Datacenter Edition을 필요로하므로 배포 비용이 크게 추가 될 수 있습니다. 또한 SIOS는 온 – 프레미엄과 클
이 차트를 살펴보면 SIOS DataKeeper에는 몇 가지 중요한 이점이 있음을 알 수 있습니다. 그 중 하나 인 DataKeeper는 Windows Server 2008 R2 및 SQL Server 2008 R2로 다시 돌아가는 훨씬 다양한 플랫폼을 지원합니다. S2D 솔루션은 Windows 및 SQL Server 2016/2017의 최신 릴리스 만 지원합니다. 또한 S2D는 Windows Datacenter Edition을 필요로하므로 배포 비용이 크게 추가 될 수 있습니다. 또한 SIOS는 온 – 프레미엄과 클