Cara Memperpanjang Instans Failover Cluster SQL Server Anda yang Ada Ke Cloud Untuk Pemulihan Bencana
Biasanya saya mengarahkan mereka ke ini Dokumentasi DataKeeper ketika seseorang bertanya kepada saya bagaimana cara memperluas Instans SQL Server Failover Cluster yang ada ke Cloud for Disaster Recovery.
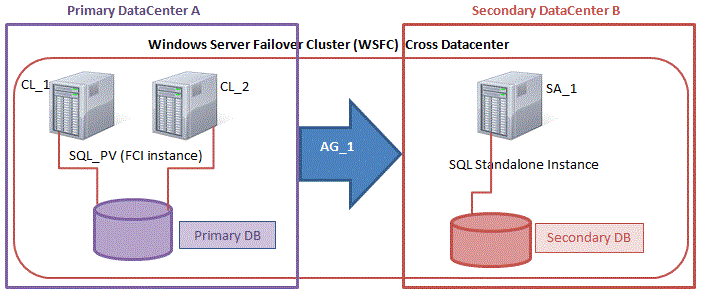
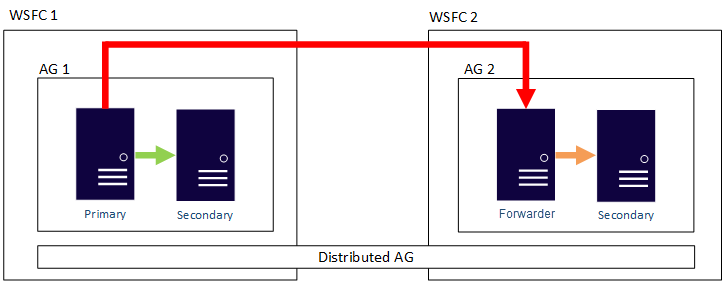
Dokumen pertama ini berbicara tentang memperluas cluster dan menambahkan node ke-3 ke cluster yang ada. Tidak apa-apa jika cluster Anda mendukung tiga node. Tetapi jika Anda menggunakan SQL Server Standard Edition, Microsoft membatasi Anda ke cluster 2-simpul. Dalam kasus cluster 2-simpul. Anda masih dapat mereplikasi ke simpul ke-3. Ingatlah bahwa pemulihan akan lebih merupakan proses manual. Proses ini dijelaskan sini .
Orang biasanya membaca petunjuk ini dan menjadi sedikit khawatir. Mereka merasa seperti akan melakukan operasi jantung terbuka di cluster mereka. Ini benar-benar lebih seperti mengganti baju Anda! Anda cukup mengganti sumber daya Cluster Disk dengan sumber daya Volume DataKeeper. Seperti yang akan Anda lihat dalam video di bawah, prosesnya hanya membutuhkan beberapa detik.

Kode yang ditunjukkan dalam video ditunjukkan di bawah ini.
Stop-ClusterGroup SQLServerGroup Hapus-ClusterResource -Nama "Cluster Disk 1" Set-Disk -Nomor 4 -IsOffline $False Set-Disk -Number 4 -IsReadOnly $False Import-Module -Name Storage Set-Partition -DiskNumber 4 -PartitionNumber 1 - NewDriveLetter X New-DataKeeperMirror -SourceIP 10.0.2.100 -SourceVolume X -TargetIP 10.0.1.10 -TargetVolume X -SyncType Sync New-DataKeeperJob -JobName "x drive" -JobDescription "sql data" -Node1Name primary.datakeeper.localIP 10.0. 2.100 -Node1Volume x -Node2Name dr.datakeeper.local -Node2IP 10.0.1.10 -Node2Volume X -SyncType Sync Add-ClusterResource -Name "DataKeeper Volume X" -ResourceType "DataKeeper Volume" -Group "SQLServerGroup" Get-ClusterResource "DataKeeper Volume X " | Set-ClusterParameter VolumeLetter X Get-ClusterResource -Nama 'SQLServer' | Add-ClusterResourceDependency -Penyedia 'DataKeeper Volume X' Start-ClusterGroup SQLServerGroup
Setelah Anda menjalankan kode itu jangan lupa Anda juga perlu mengklik Kelola Volume Bersama untuk menambahkan node cadangan ke pekerjaan DataKeeper seperti yang ditunjukkan dalam video.
Jika Anda memiliki SQL Server Enterprise Edition maka langkah terakhir adalah menginstal SQL Server di DR node dan pilih add node to existing cluster.
Jika Anda menggunakan SQL Server Standard Edition maka pekerjaan Anda selesai. Anda cukup mengikuti petunjuk ini untuk mengakses data Anda pada simpul ke-3 dan kemudian memasang basis data yang direplikasi.
Petunjuk ini berlaku baik node DR Anda ada di Cloud atau situs DR Anda sendiri.