| พฤษภาคม 11, 2024 |
อะไรทำให้เกิดความล้มเหลวเกิดขึ้น? |
||||||||||||
| พฤษภาคม 5, 2024 |
เคล็ดลับสามประการเพื่อการสนับสนุนที่ดียิ่งขึ้น |
||||||||||||
| เมษายน 30, 2024 |
SIOS LifeKeeper สำหรับการฝึกอบรมผู้ดูแลระบบ Linux พร้อมใช้งานบน Udemy |
||||||||||||
| เมษายน 24, 2024 |
เทคโนโลยี SIOS เข้าร่วมโครงการ Nutanix Elevate Partner |
||||||||||||
| เมษายน 22, 2024 |
ทีละขั้นตอน – SQL Server 2019 Failover Cluster Instance (FCI) ใน OCI |





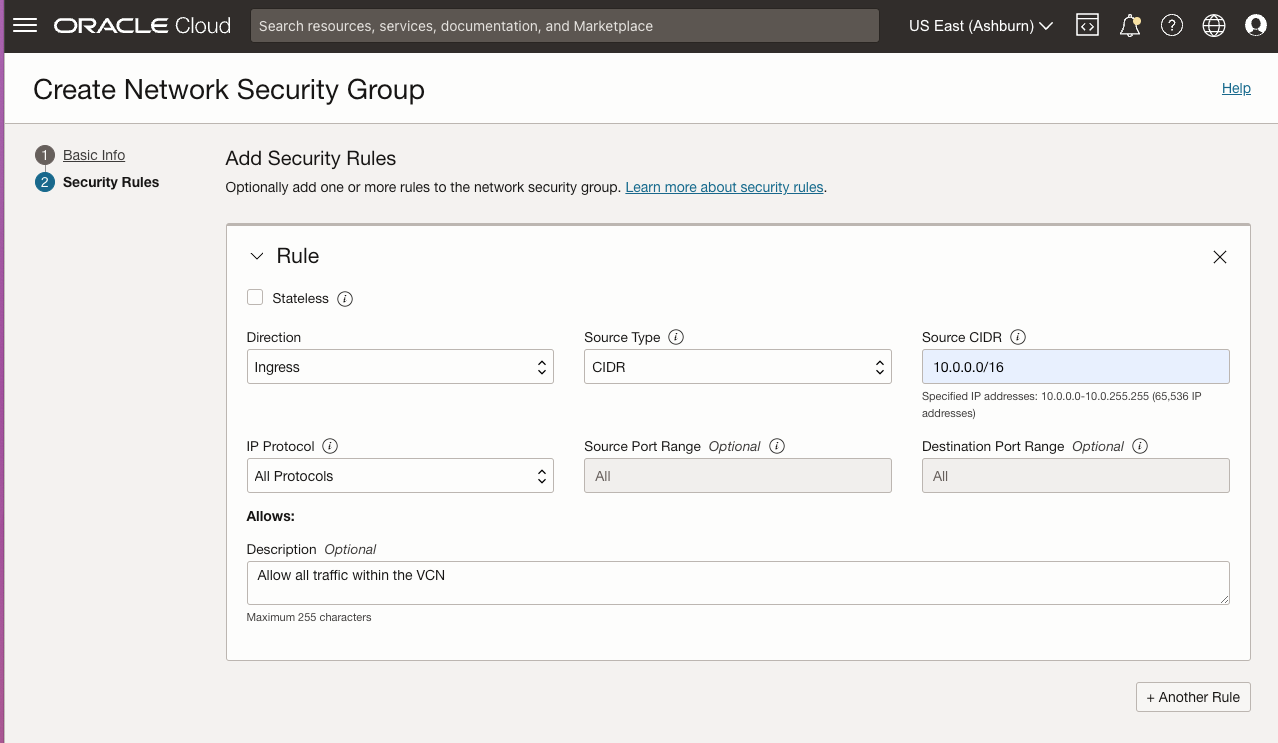
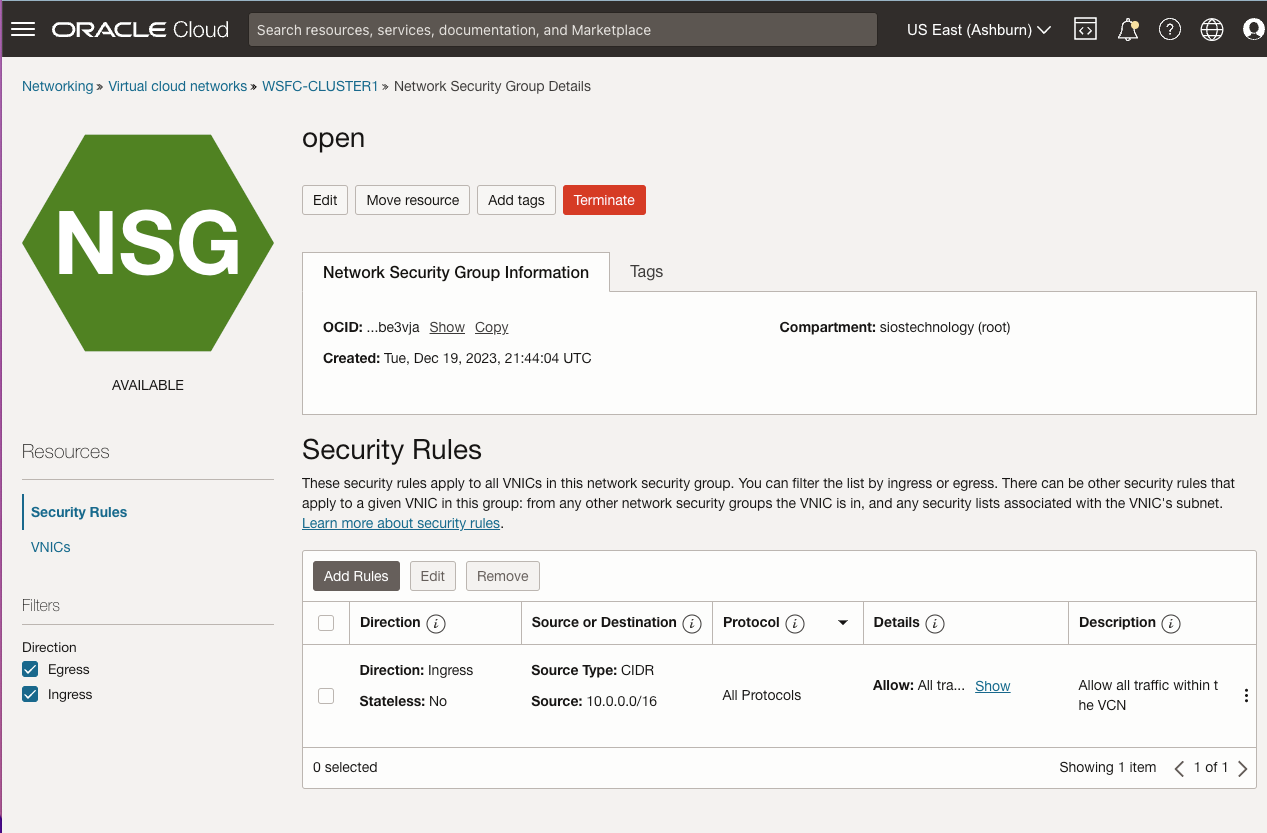
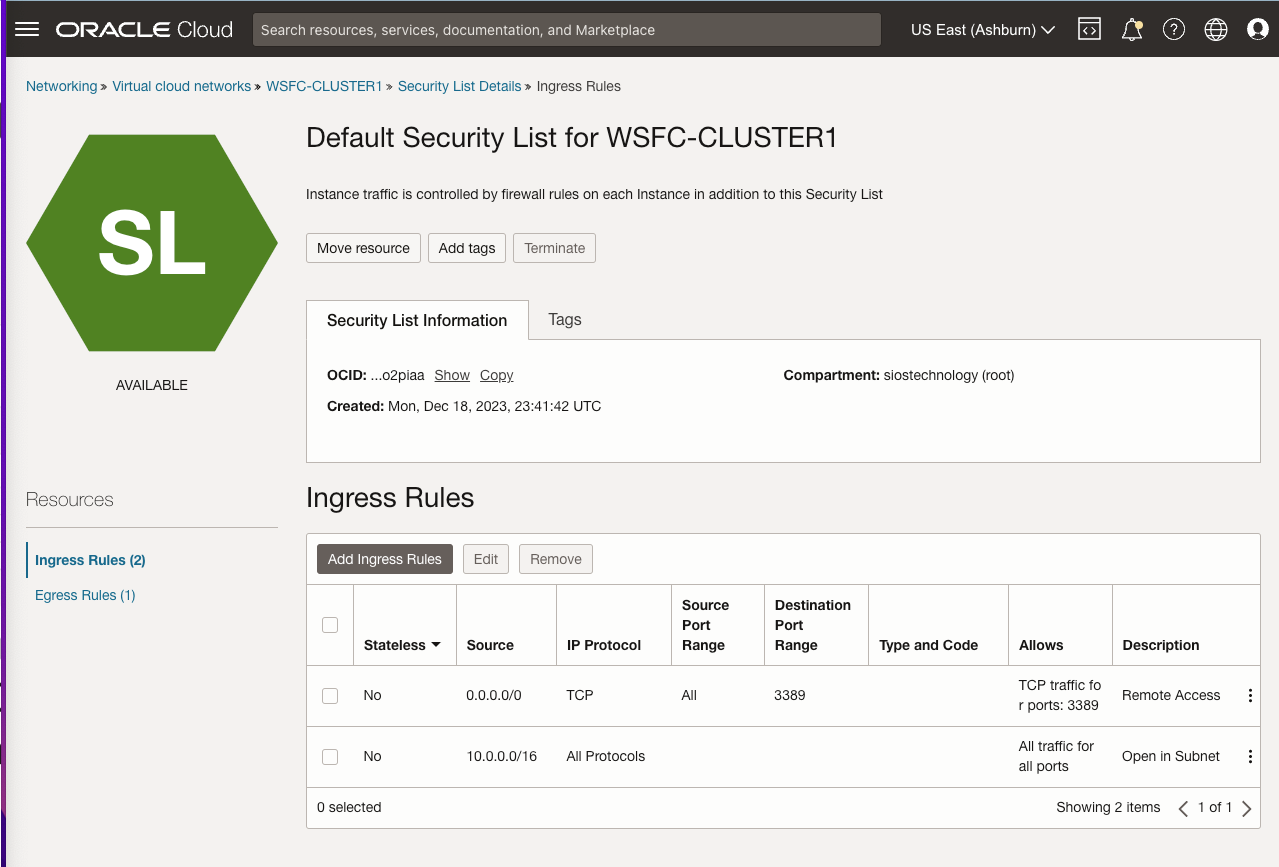
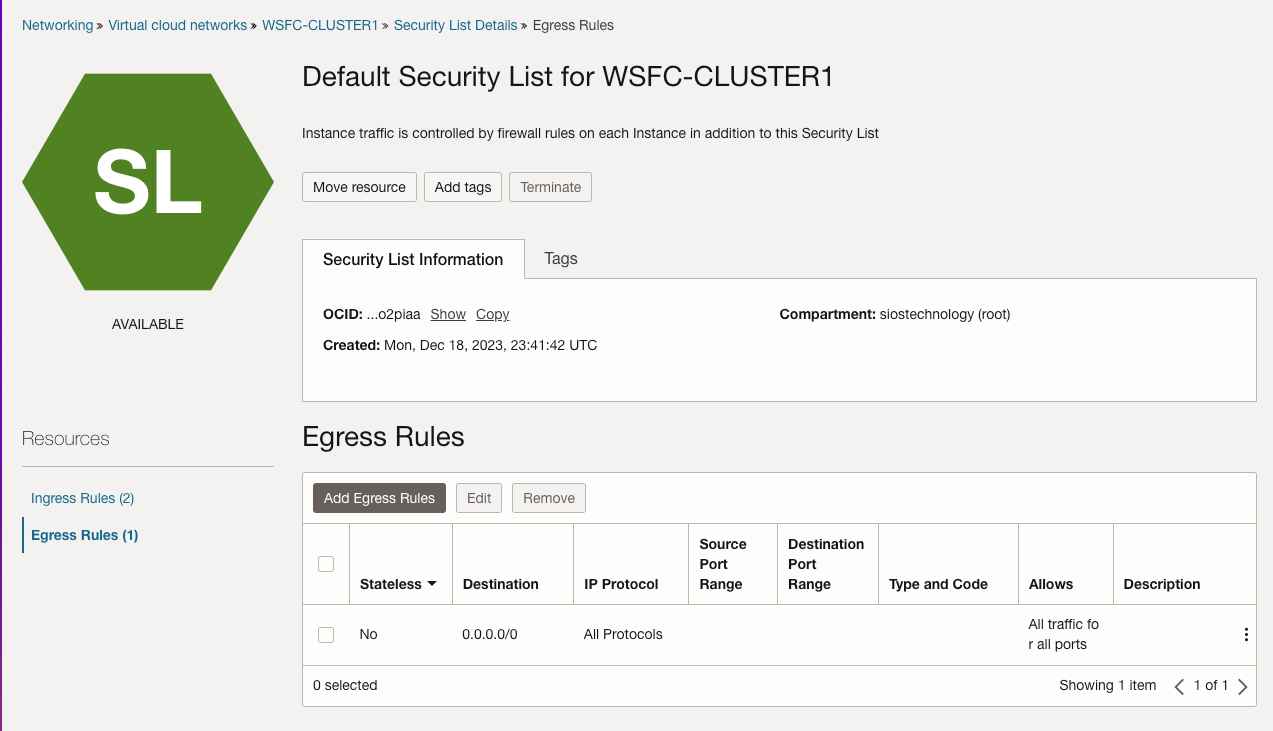
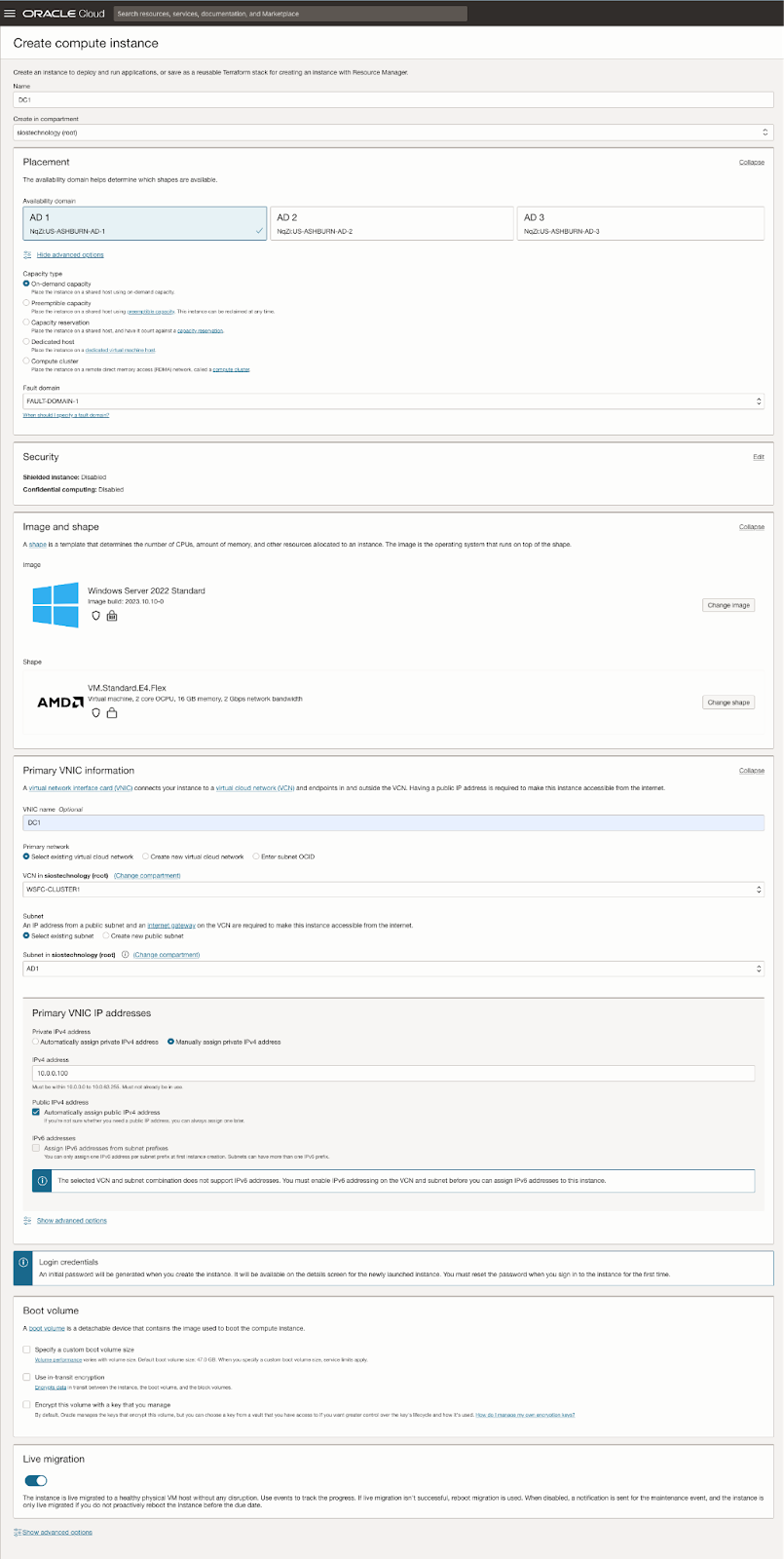
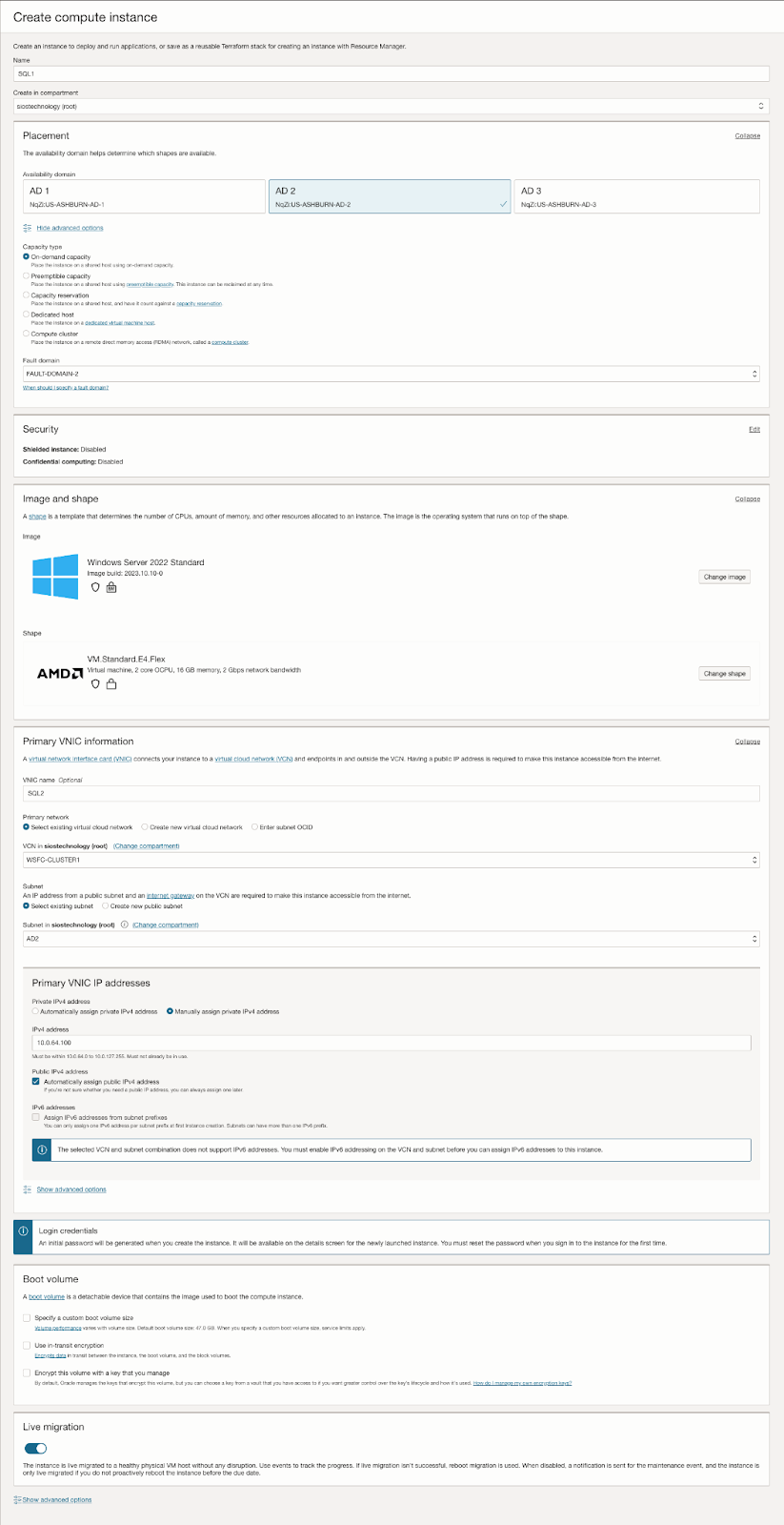
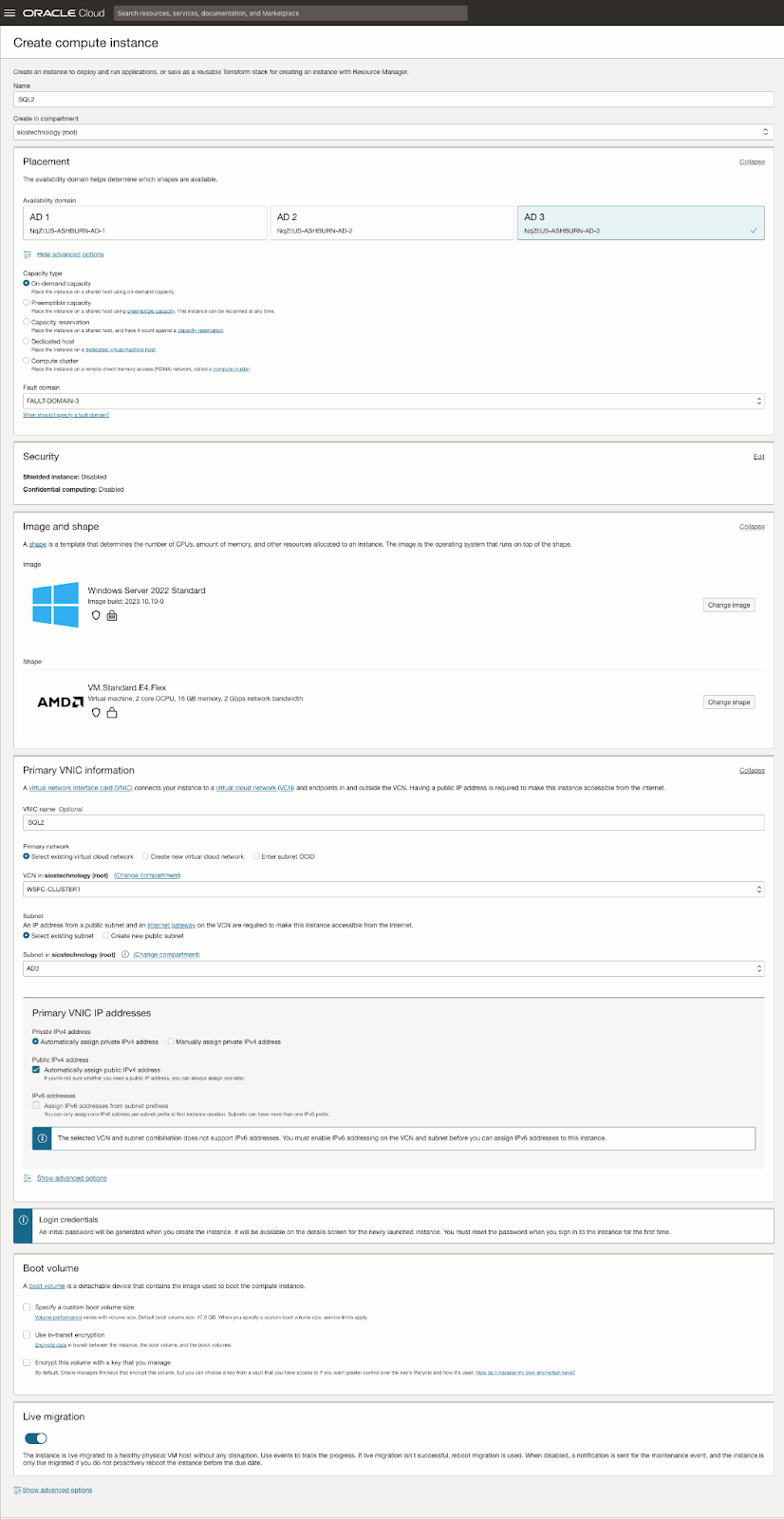
| SQL1 | SQL2 | |
| ที่อยู่หลัก | 10.0.64.100 | 10.0.128.100 |
| คลัสเตอร์ IP 1 (ทรัพยากรคลัสเตอร์หลัก) | 10.0.64.101 | 10.0.128.101 |
| IP คลัสเตอร์ 2(IP คลัสเตอร์เซิร์ฟเวอร์ SQL) | 10.0.64.102 | 10.0.128.102 |
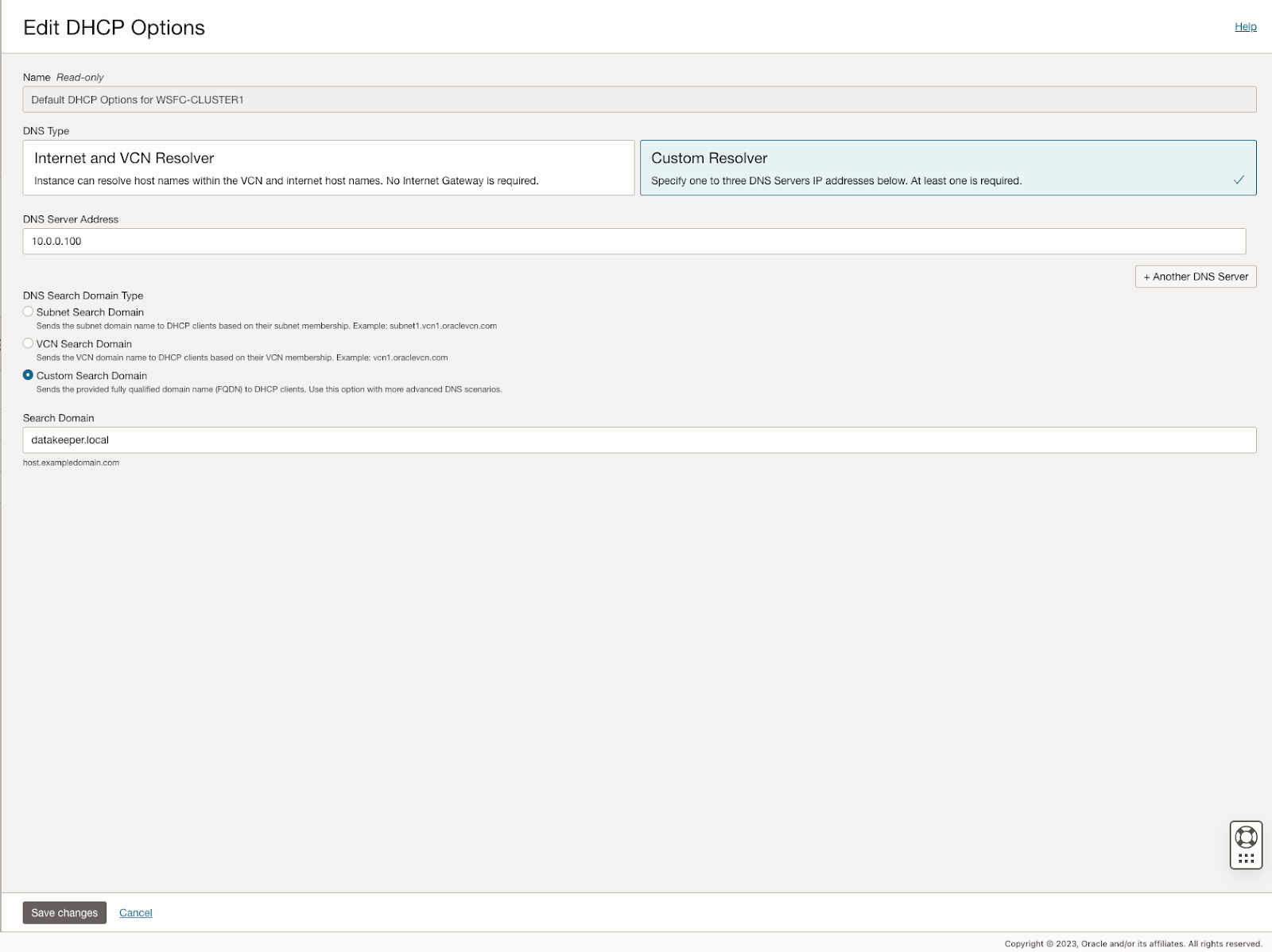
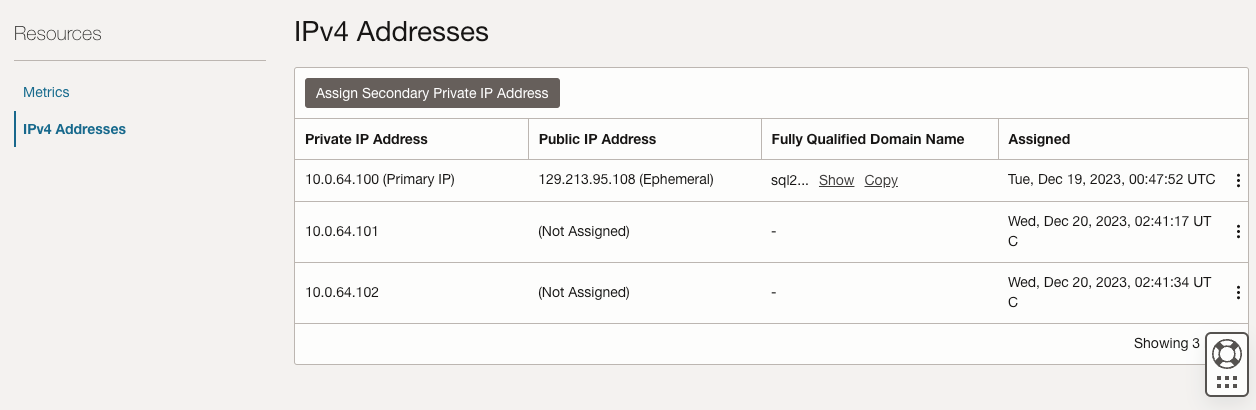
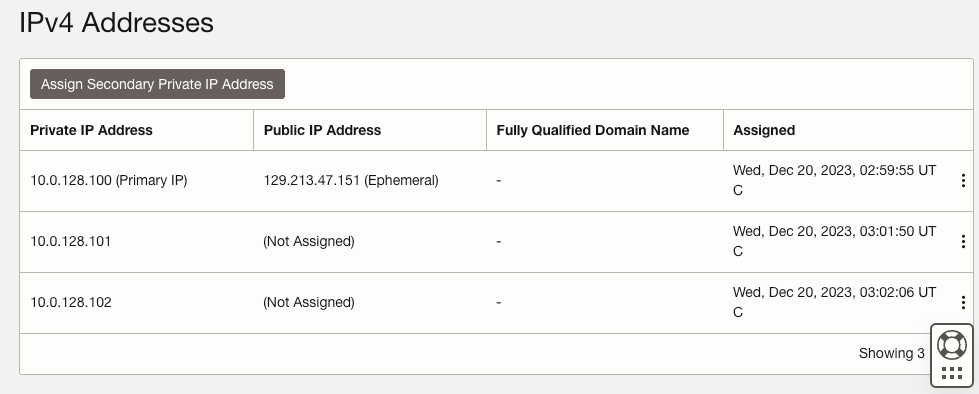
บนทั้ง SQL1 และ SQL2 ให้แก้ไข VNIC ที่แนบมาเพื่อเพิ่มที่อยู่รอง
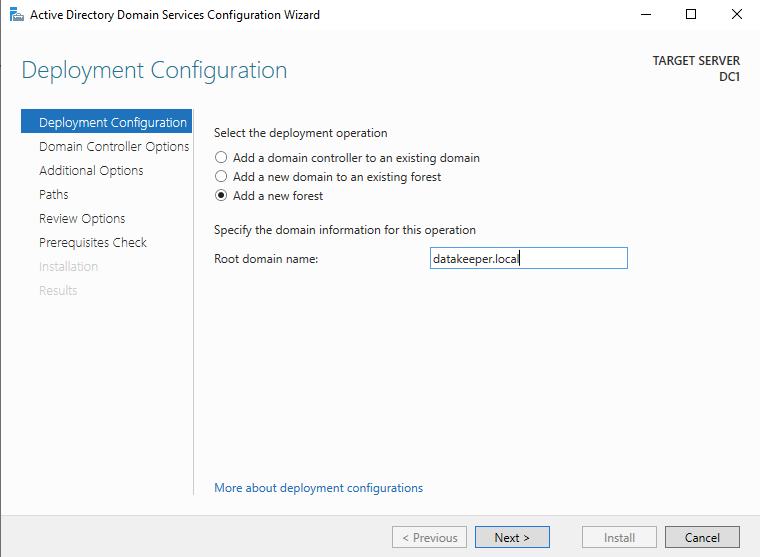
สร้างโดเมน
เพื่อความยืดหยุ่น คุณควรจัดเตรียมตัวควบคุม AD หลายตัวในโซนความพร้อมใช้งานที่แตกต่างกัน แต่เพื่อวัตถุประสงค์ของคู่มือนี้ เราจะจัดเตรียมตัวควบคุม AD เพียงตัวเดียว ทำตามภาพหน้าจอด้านล่างเพื่อกำหนดค่า AD บน DC1
เข้าสู่ระบบโดยใช้ข้อมูลประจำตัวที่แสดงอยู่ในส่วนรายละเอียดอินสแตนซ์ คุณจะได้รับแจ้งให้รีเซ็ตรหัสผ่านของคุณ
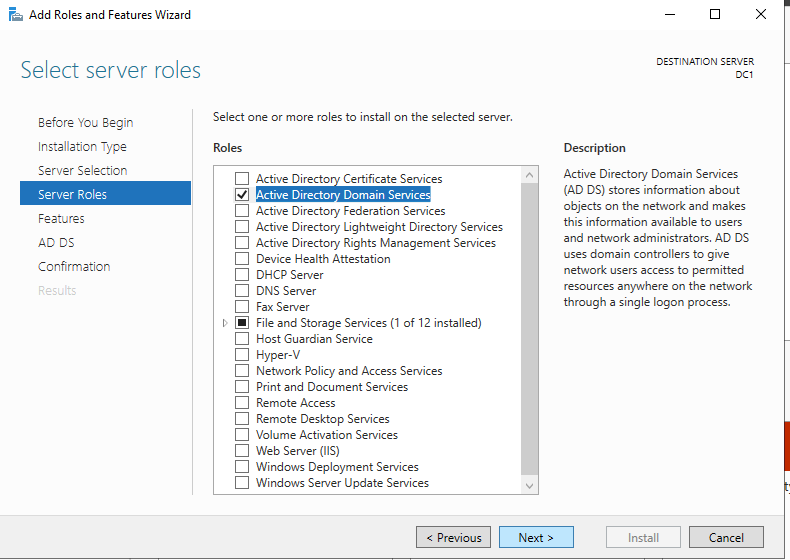
เปิดใช้งานบริการโดเมน Active Directory
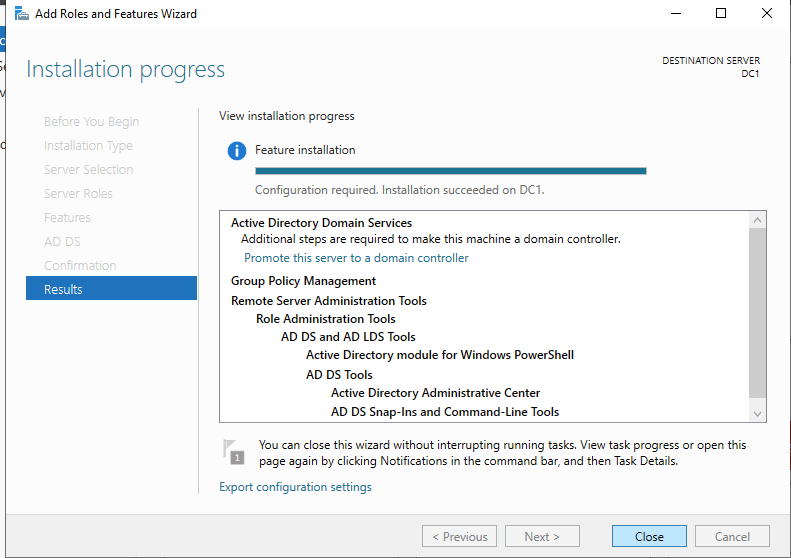
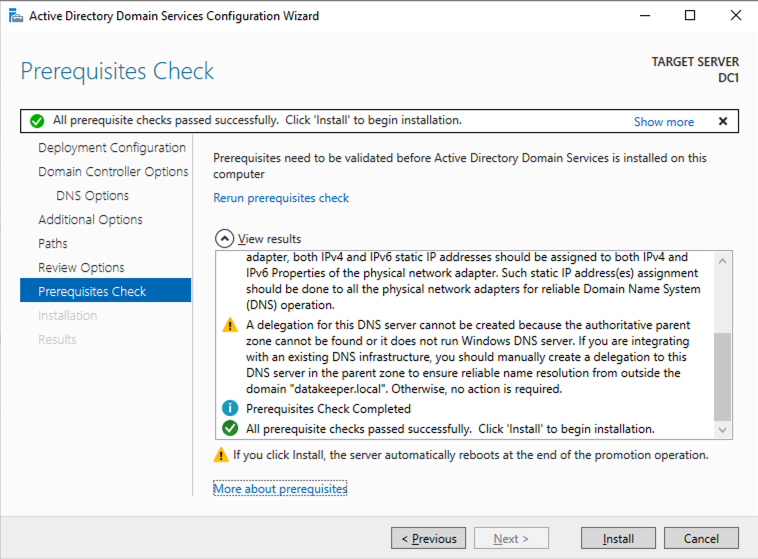
เลื่อนระดับเซิร์ฟเวอร์เป็นตัวควบคุมโดเมน
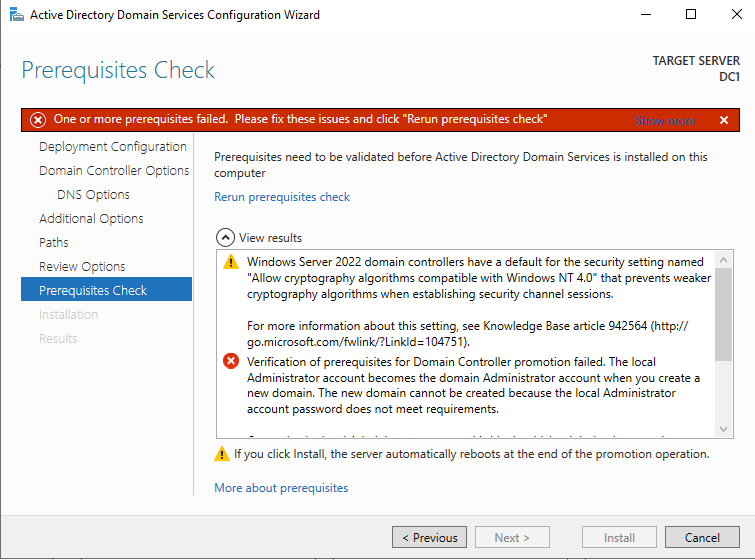
ก่อนที่คุณจะเริ่มกระบวนการนี้ ให้เปิดใช้งานบัญชีผู้ดูแลระบบภายในเครื่องบนเซิร์ฟเวอร์และตั้งรหัสผ่าน หากคุณไม่ทำเช่นนั้น คุณจะได้รับข้อความนี้เมื่อคุณพยายามเลื่อนระดับตัวควบคุมโดเมน
เมื่อคุณเปิดใช้งานบัญชีผู้ดูแลระบบและตั้งรหัสผ่านแล้ว ให้ดำเนินการกำหนดค่าหลังการปรับใช้งาน
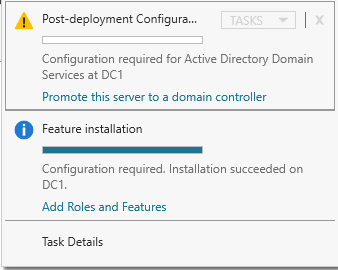
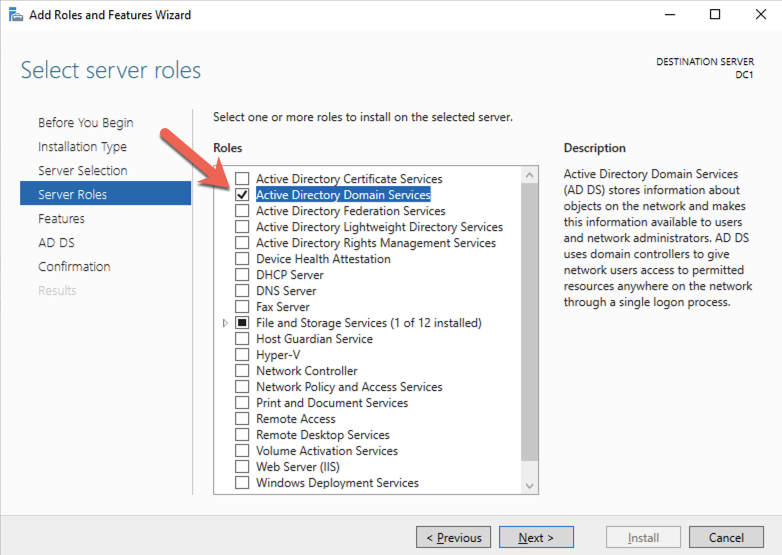
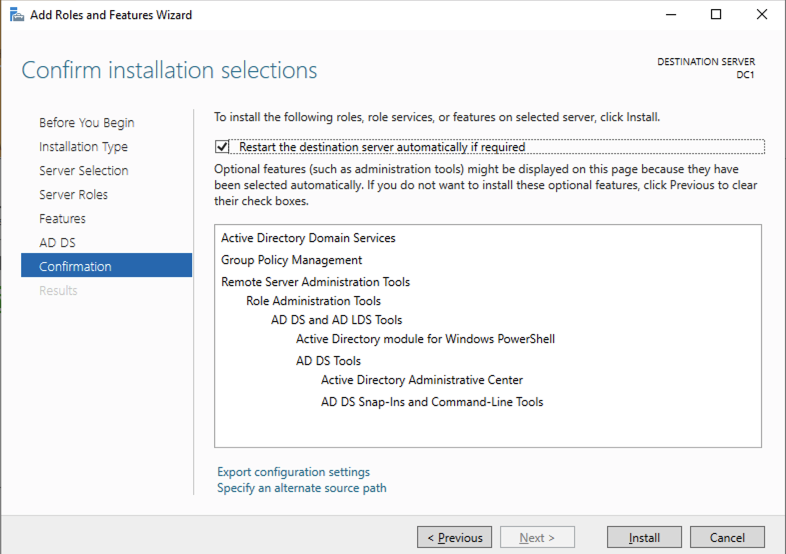
ก่อนที่จะเปิดใช้งานบริการโดเมน Active Directory คุณต้องเปิดใช้งานบัญชีผู้ดูแลระบบภายในและเข้าสู่ระบบด้วยบัญชีนั้น
ใช้โปรแกรม RDP ที่คุณชื่นชอบ เชื่อมต่อกับ DC1 โดยใช้ที่อยู่ IP สาธารณะที่เชื่อมโยงกับอินสแตนซ์ เพิ่มบทบาทบริการโดเมน Active Directory
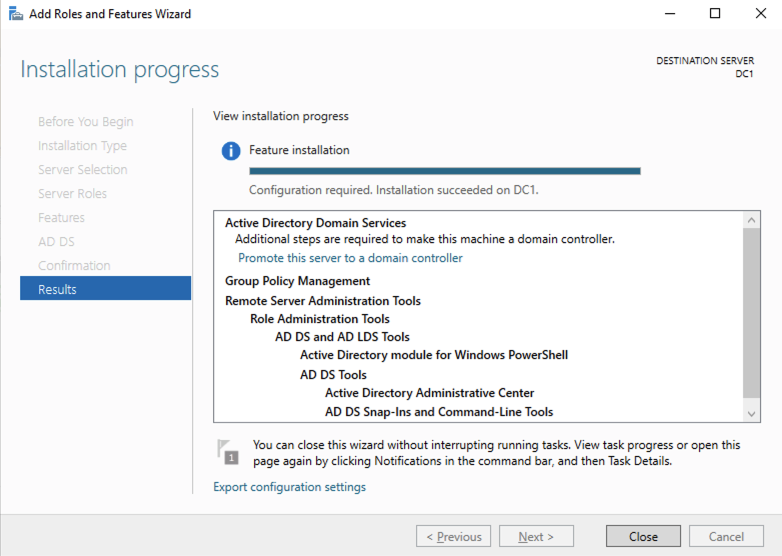
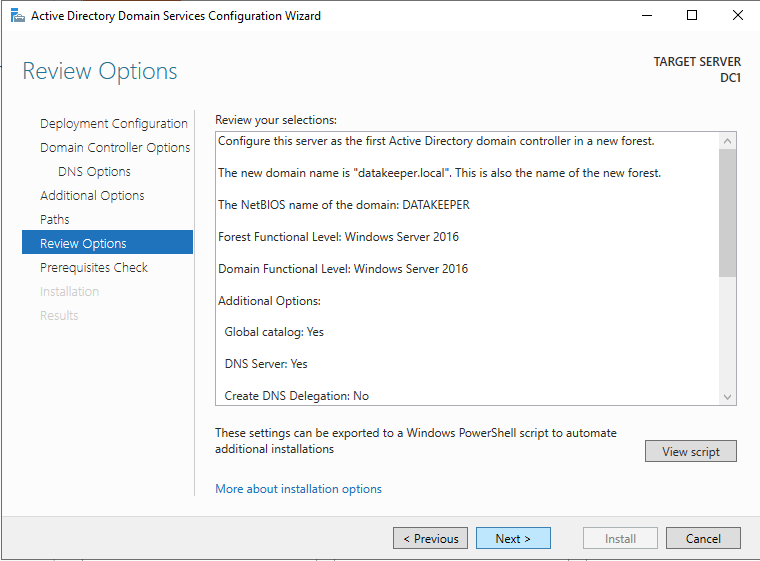
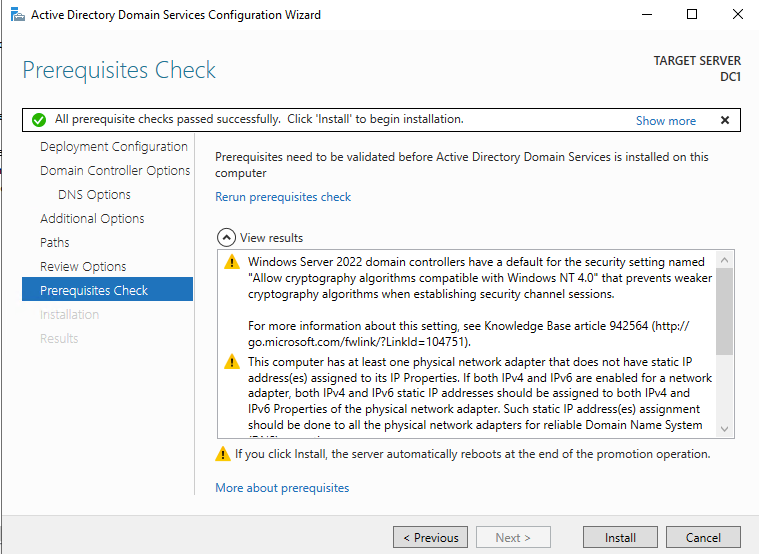
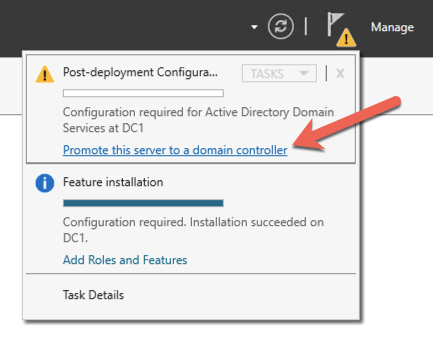
หลังจากการติดตั้งเสร็จสมบูรณ์ ให้เลื่อนระดับเซิร์ฟเวอร์นี้เป็นตัวควบคุมโดเมน
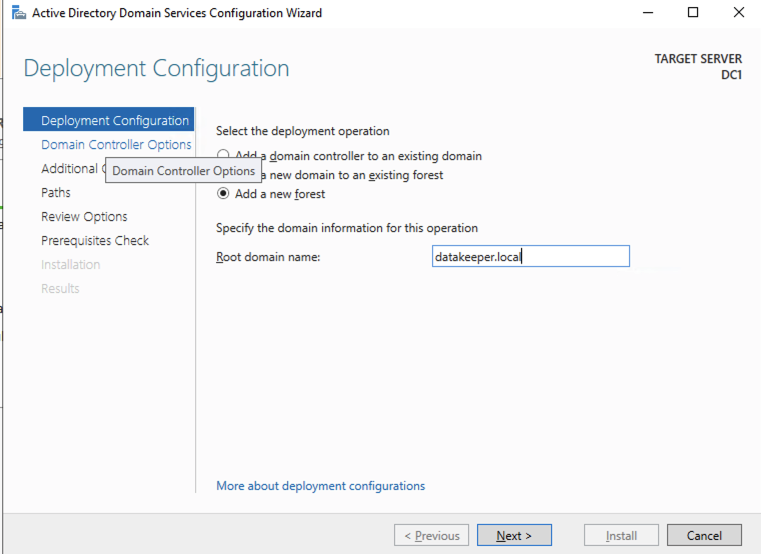
เพื่อจุดประสงค์ของเรา เราจะสร้างโดเมนใหม่
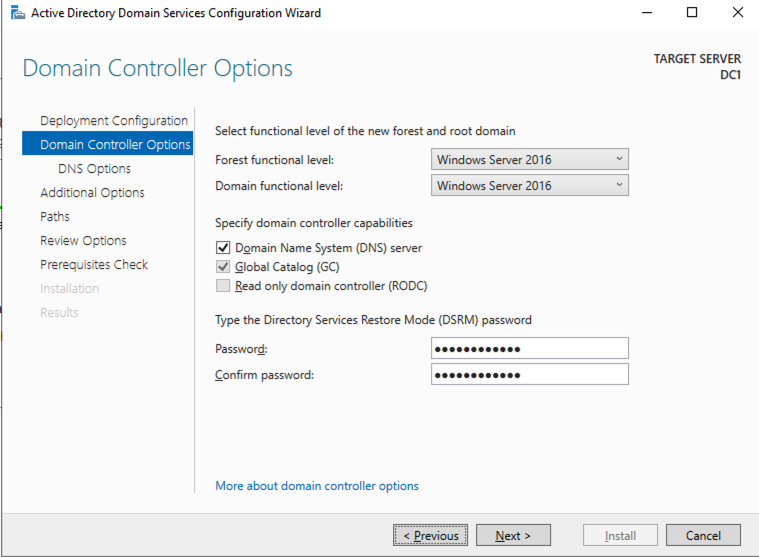
รีบูต DC1 และไปยังส่วนถัดไป
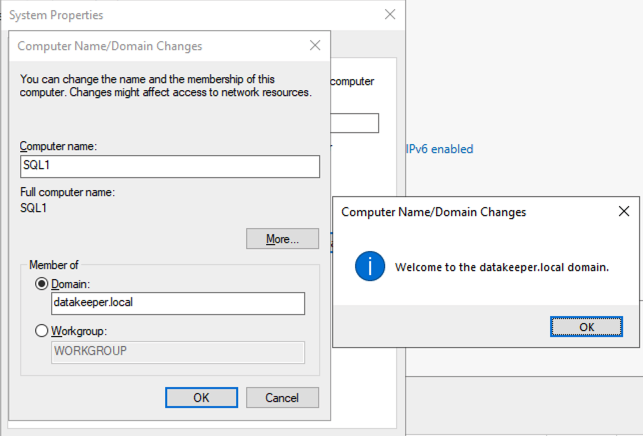
เข้าร่วม SQL1 และ SQL2 กับโดเมน
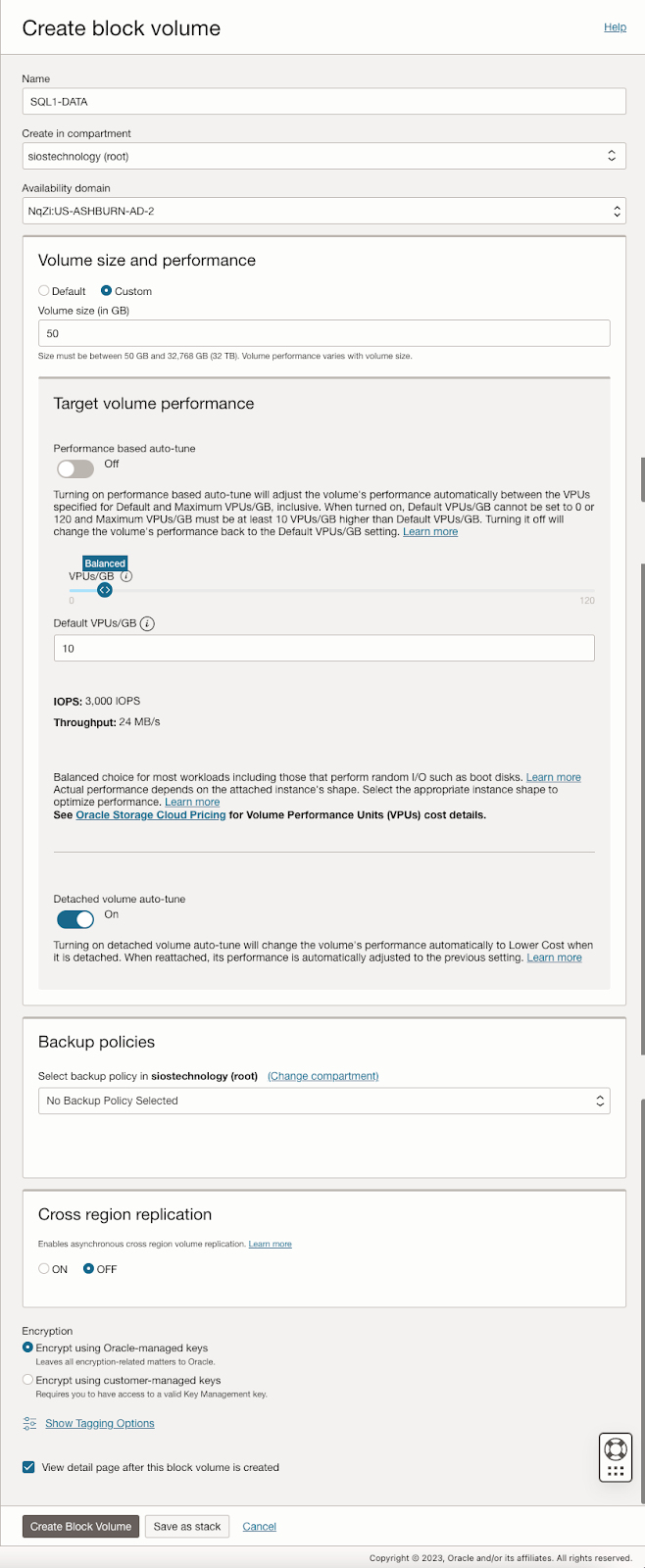
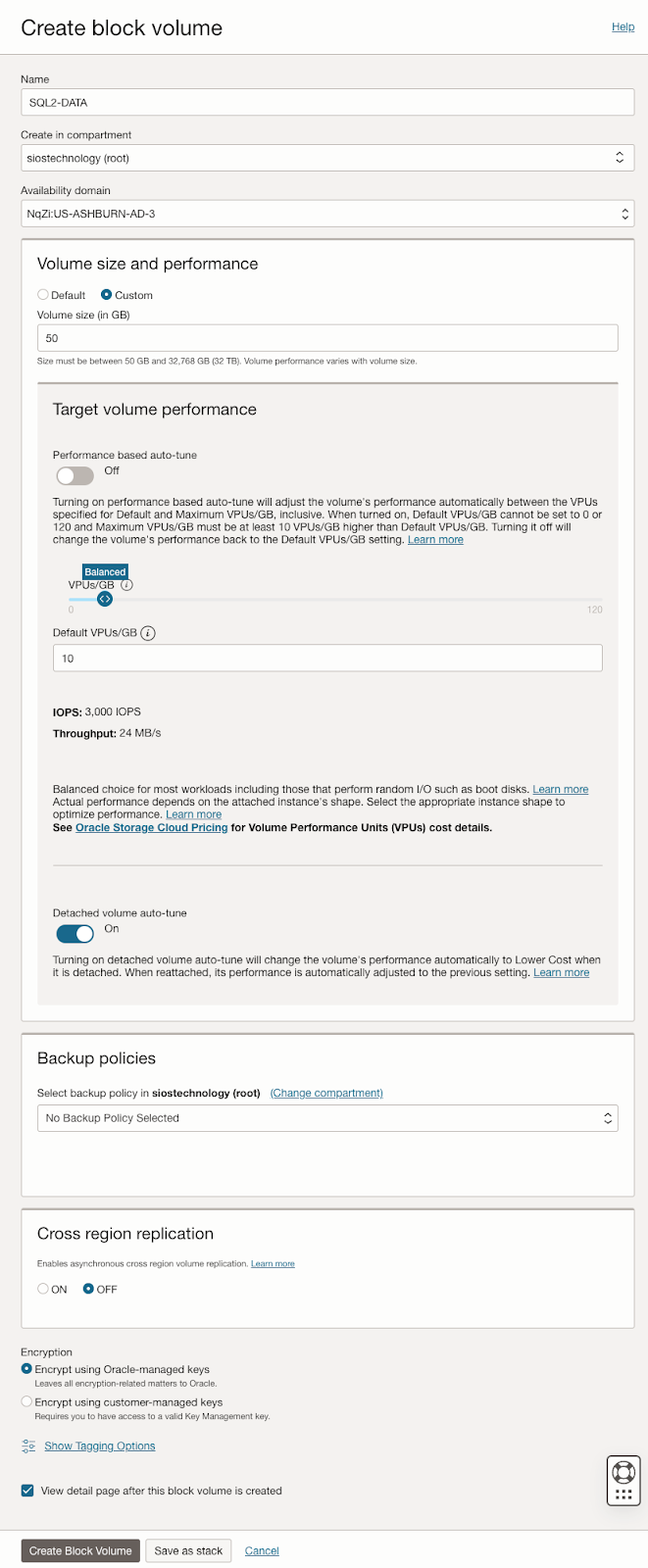
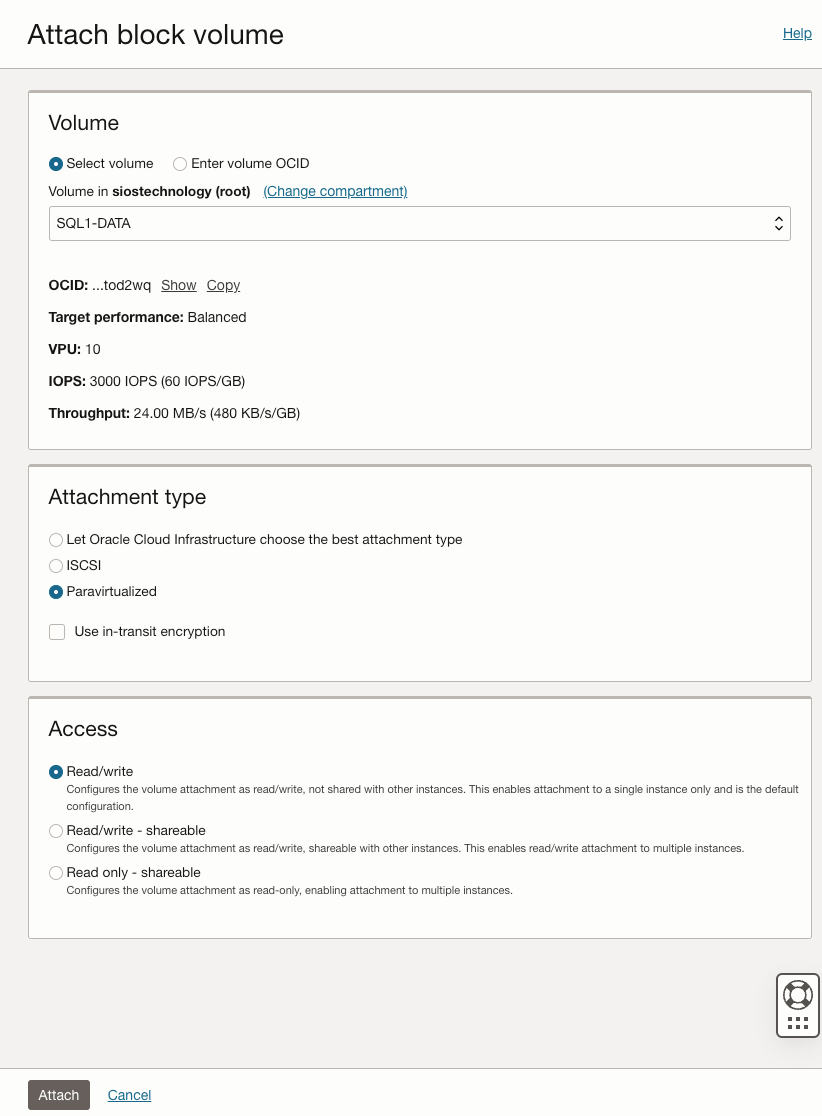
เตรียมที่จัดเก็บ
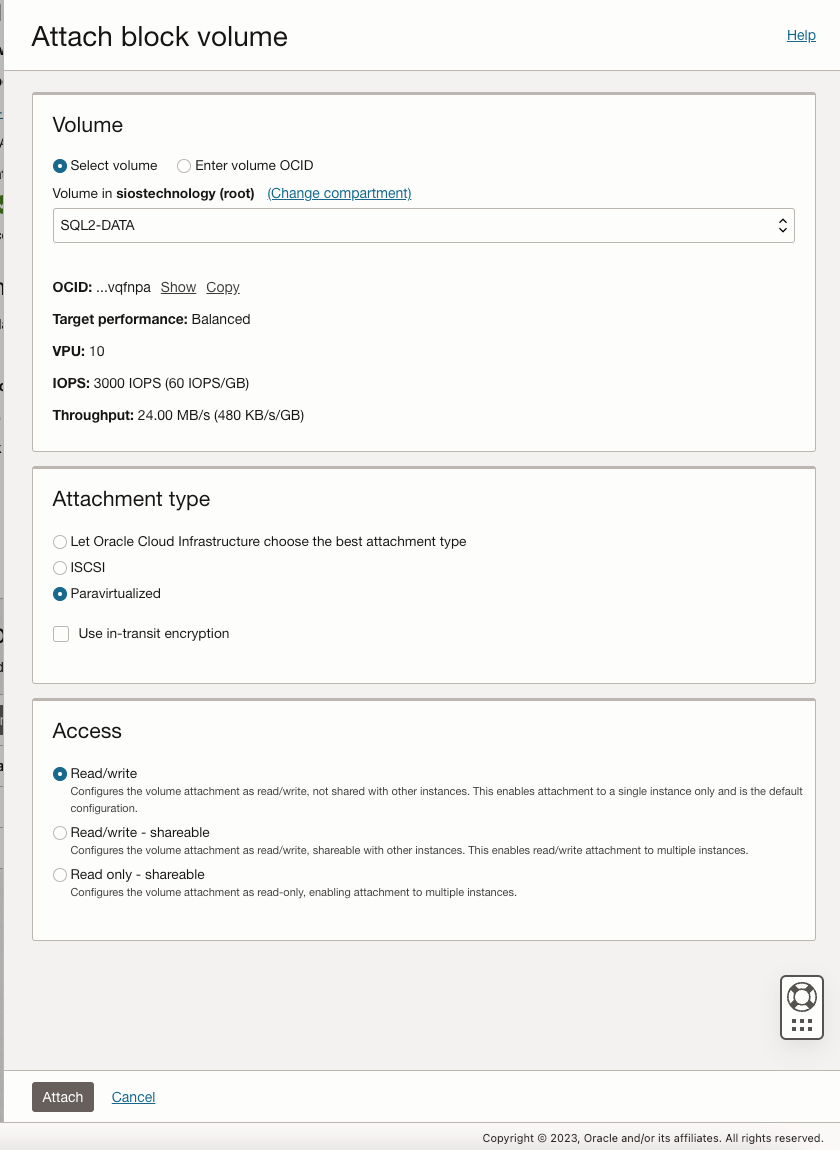
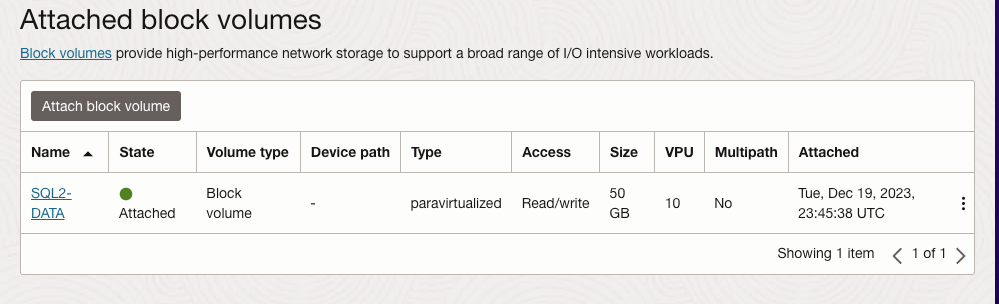
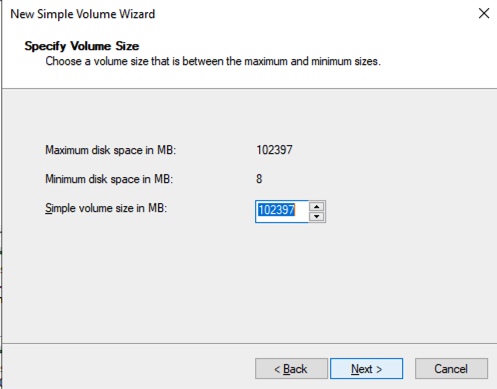
เมื่อเพิ่ม SQL1 และ SQL2 ลงในโดเมนแล้ว ให้เชื่อมต่อกับอินสแตนซ์ด้วยบัญชีผู้ดูแลระบบโดเมนที่คุณสร้างขึ้นเพื่อทำตามขั้นตอนการกำหนดค่าที่เหลือให้เสร็จสิ้น สิ่งแรกที่คุณต้องทำคือแนบและจัดรูปแบบไดรฟ์ข้อมูล EBS ที่เราเพิ่มลงใน SQL1 และ SQL2 ดังที่แสดงด้านล่าง
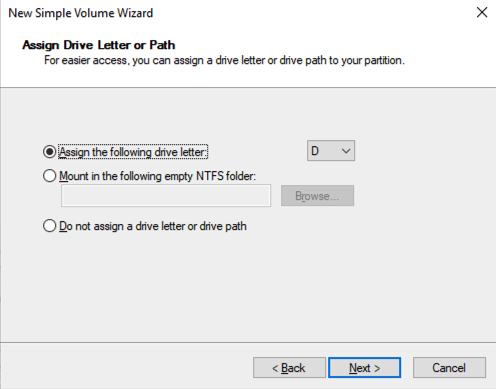
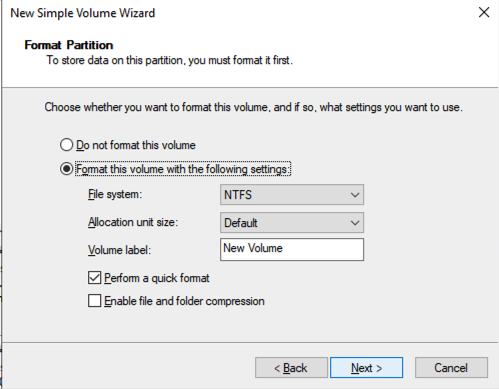
กำหนดค่าคุณสมบัติการทำคลัสเตอร์ล้มเหลว
เปิดใช้งานคุณลักษณะ Failover Clustering บนทั้ง SQL1 และ SQL2
เรียกใช้คำสั่ง PowerShell นี้บน SQL1 และ SQL2
ติดตั้ง WindowsFeature – ชื่อการทำคลัสเตอร์ล้มเหลว – รวม ManagementTools
ตรวจสอบคลัสเตอร์ของคุณ
เรียกใช้คำสั่ง PowerShell นี้จาก SQL1 หรือ SQL2
คลัสเตอร์ทดสอบ – โหนด sql1, sql2
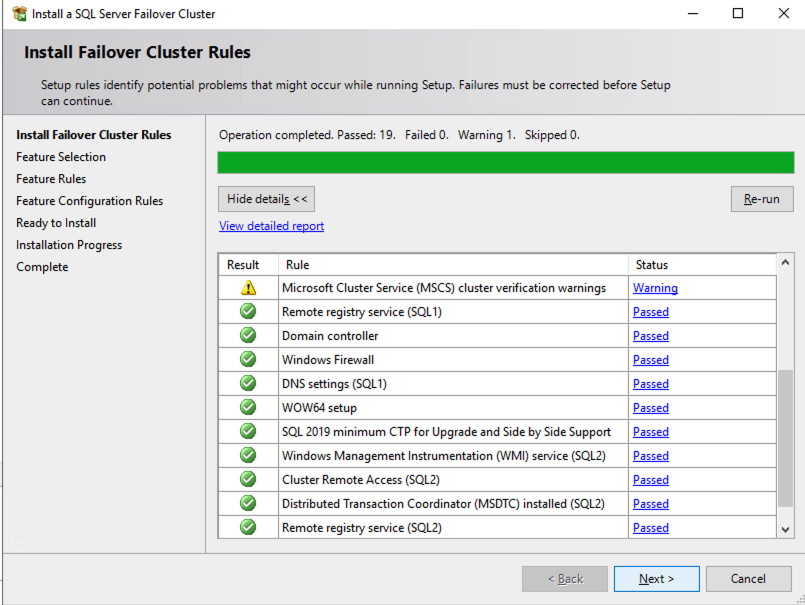
ขึ้นอยู่กับเวอร์ชันของ Windows Server ที่คุณใช้ คุณจะเห็นคำเตือนบางอย่างเกี่ยวกับเครือข่ายและที่เก็บข้อมูลที่อาจเกิดขึ้น คำเตือนเครือข่ายมีแนวโน้มที่จะบอกคุณว่าแต่ละโหนดคลัสเตอร์สามารถเข้าถึงได้ผ่านอินเทอร์เฟซเดียว Windows เวอร์ชันก่อนหน้าจะเตือนคุณเกี่ยวกับพื้นที่เก็บข้อมูลที่ใช้ร่วมกันไม่เพียงพอ
คุณสามารถละเว้นข้อผิดพลาดทั้งสองได้ตามที่คาดไว้ในคลัสเตอร์ที่โฮสต์บน OCI ตราบใดที่คุณไม่ได้รับข้อผิดพลาด คุณสามารถดำเนินการในส่วนถัดไปได้ หากคุณได้รับข้อผิดพลาด ให้แก้ไข จากนั้นเรียกใช้การตรวจสอบอีกครั้งและดำเนินการต่อในส่วนถัดไป
สร้างคลัสเตอร์
ต่อไป คุณจะสร้างคลัสเตอร์ ในตัวอย่างด้านล่าง คุณจะสังเกตเห็นว่าฉันใช้ที่อยู่ IP สองแห่งที่เราวางแผนจะใช้ คือ 10.0.64.101 และ 10.0.128.101 คุณสามารถเรียกใช้ Powershell นี้ได้จากโหนดคลัสเตอร์ใดก็ได้
คลัสเตอร์ใหม่ – ชื่อคลัสเตอร์ 1 – โหนด sql1, sql2 – ที่อยู่คงที่ 10.0.64.101, 10.0.128.101
โปรดทราบ:อย่าพยายามสร้างคลัสเตอร์ผ่าน WSFC GUI คุณจะพบว่าเนื่องจากอินสแตนซ์ใช้ DHCP GUI จะไม่ให้ตัวเลือกแก่คุณในการกำหนดที่อยู่ IP สำหรับคลัสเตอร์ แต่จะแจกที่อยู่ IP ที่ซ้ำกันแทน
เพิ่มพยานการแชร์ไฟล์
เพื่อรักษาองค์ประชุมคลัสเตอร์ คุณต้องเพิ่มพยาน ใน OCI ประเภทของพยานที่คุณต้องการใช้คือพยานการแชร์ไฟล์ พยานการแชร์ไฟล์ต้องอยู่บนเซิร์ฟเวอร์ที่อยู่ในโดเมนข้อบกพร่องที่แตกต่างจากโหนดคลัสเตอร์ทั้งสอง
ในตัวอย่างด้านล่าง พยานการแบ่งปันไฟล์จะถูกสร้างขึ้นบน DC1 ซึ่งอยู่ใน FD1
บน DC1 ให้สร้างการแชร์ไฟล์และกำหนดสิทธิ์การอ่าน-เขียนของวัตถุชื่อคลัสเตอร์ (CNO) ในโฟลเดอร์ เพิ่มสิทธิ์สำหรับ CNO บนแท็บ Share และ Security ของโฟลเดอร์ที่คุณสร้างขึ้น ในตัวอย่างด้านล่าง ฉันได้สร้างโฟลเดอร์ชื่อ “Witness”
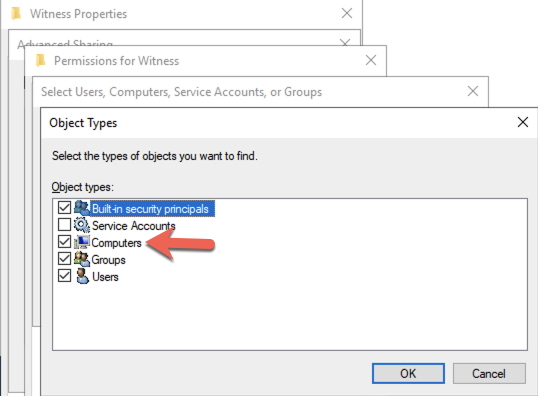
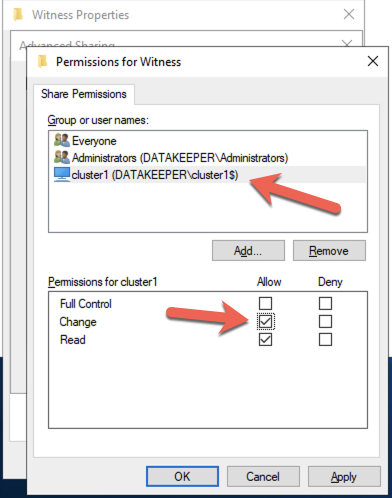
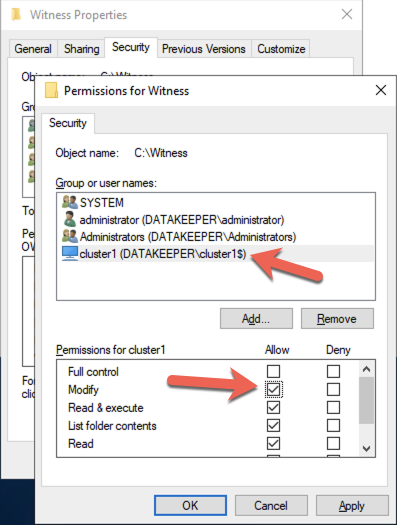
เมื่อสร้างโฟลเดอร์และกำหนดสิทธิ์ที่เหมาะสมให้กับ CNO แล้ว ให้รันคำสั่ง PowerShell ต่อไปนี้บน SQL1 หรือ SQL2
ชุด-ClusterQuorum -คลัสเตอร์คลัสเตอร์1 -FileShareWitness \\dc1\Witness
คลัสเตอร์ของคุณควรมีลักษณะดังนี้เมื่อคุณเปิดตัว Failover Cluster Manager บน SQL1 หรือ SQL2
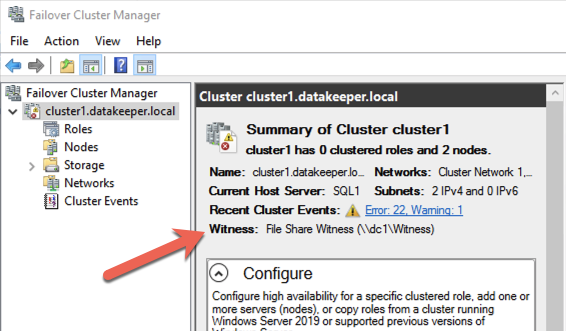
การสร้าง FCI เซิร์ฟเวอร์ SQL
ติดตั้ง DataKeeper Cluster Edition
ก่อนที่คุณจะดำเนินการขั้นตอนต่อไปได้ คุณจะต้องติดตั้ง DataKeeper Cluster Edition บนทั้ง SQL1 และ SQL2 ดาวน์โหลดไฟล์ปฏิบัติการการตั้งค่าและรันการตั้งค่า DataKeeper บนทั้งสองโหนด อ้างถึงเอกสาร SIOSสำหรับคำแนะนำเฉพาะเกี่ยวกับการติดตั้ง
สร้างทรัพยากรโวลุ่ม DataKeeper
เปิดใช้งาน DataKeeper UI บนโหนดคลัสเตอร์ใดโหนดหนึ่งและสร้าง DataKeeper Volume Resource ของคุณดังที่แสดงด้านล่าง
เชื่อมต่อกับเซิร์ฟเวอร์ทั้งสอง อันดับแรกคือ SQL1 และ SQL2
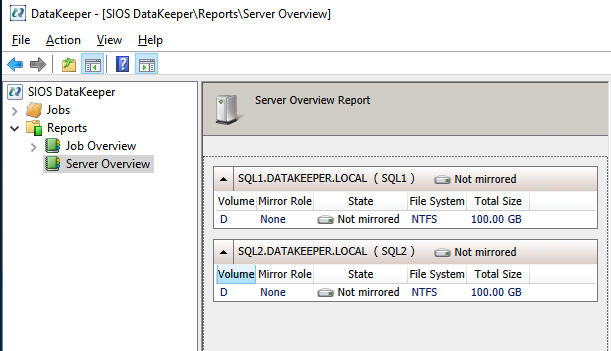
หากคุณเชื่อมต่อกับเซิร์ฟเวอร์ทั้งสองเครื่องและกำหนดค่าที่เก็บข้อมูลอย่างถูกต้อง รายงานภาพรวมเซิร์ฟเวอร์ควรมีลักษณะดังนี้
คลิกสร้างงานเพื่อเริ่มตัวช่วยสร้างงาน
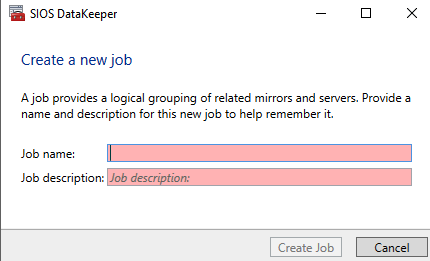
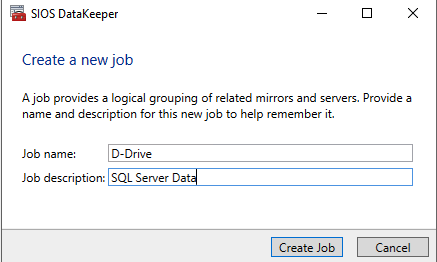
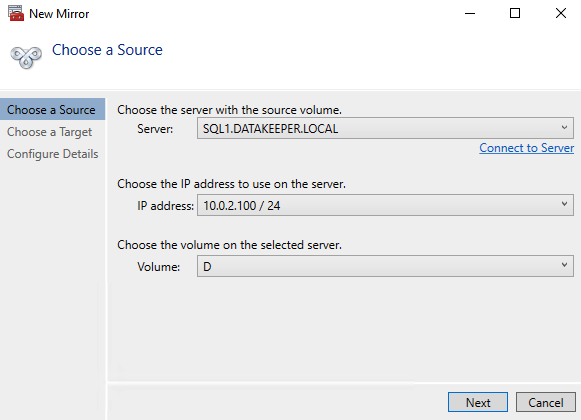
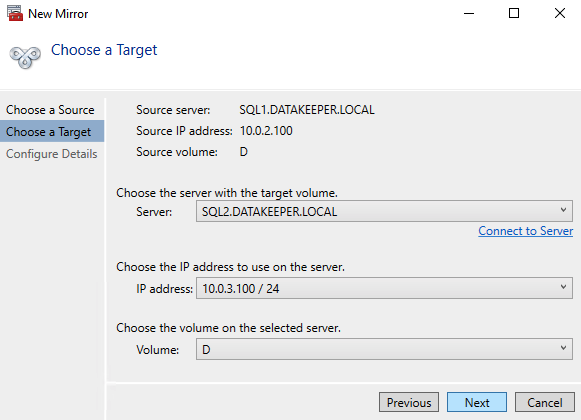
DataKeeper รองรับการจำลองทั้งแบบซิงโครนัสและอะซิงโครนัส สำหรับการจำลองระหว่างโซนความพร้อมใช้งานในภูมิภาคเดียวกัน ให้เลือกซิงโครนัส หากคุณต้องการจำลองแบบข้ามภูมิภาคหรือแม้แต่ข้ามผู้ให้บริการคลาวด์ ให้เลือกแบบอะซิงโครนัส
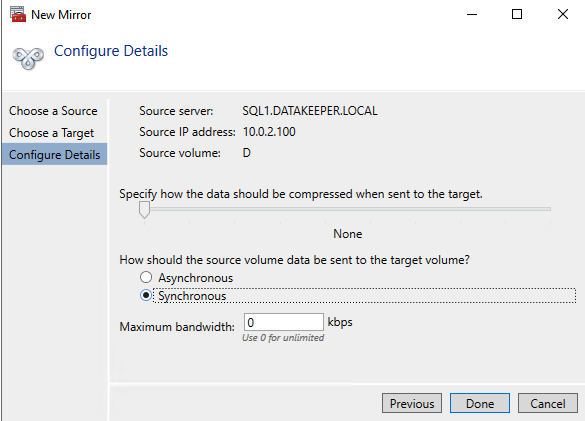
คลิก “ใช่” ที่นี่เพื่อลงทะเบียนทรัพยากร DataKeeper Volume ใน Available Storage
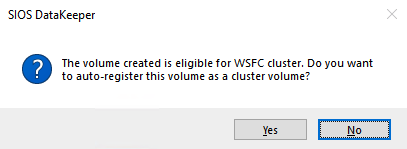
DataKeeper Volume D ปรากฏใน Failover Cluster Manager ในที่เก็บข้อมูลที่มีอยู่
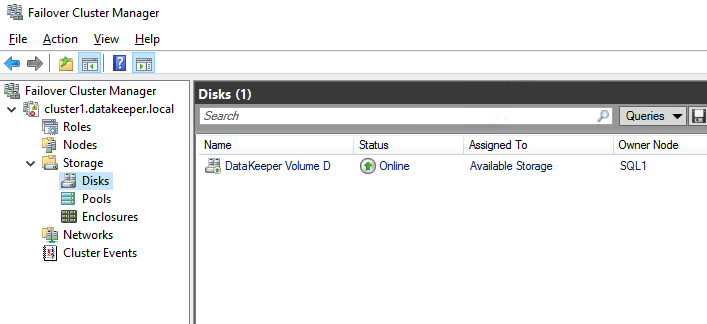
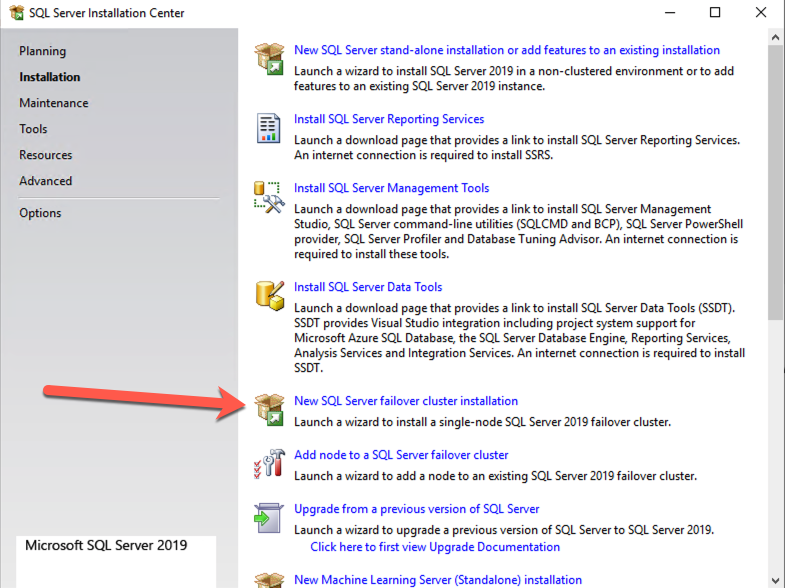
ติดตั้งโหนดแรกของ SQL Server FCI บน SQL1
หลังจากที่สร้างคลัสเตอร์หลักแล้วและทรัพยากรโวลุ่ม DataKeeper อยู่ใน Available Storage ก็ถึงเวลาติดตั้ง SQL Server บนโหนดคลัสเตอร์แรก ตามที่กล่าวไว้ก่อนหน้านี้ ตัวอย่างที่นี่แสดงการกำหนดค่าคลัสเตอร์โดยใช้ SQL 2019 และ Windows 2022 แต่ขั้นตอนทั้งหมดที่อธิบายไว้ในตัวอย่างนี้แทบจะเหมือนกัน ไม่ว่าคุณจะพยายามปรับใช้ Windows Server หรือ SQL Server เวอร์ชันใดก็ตาม
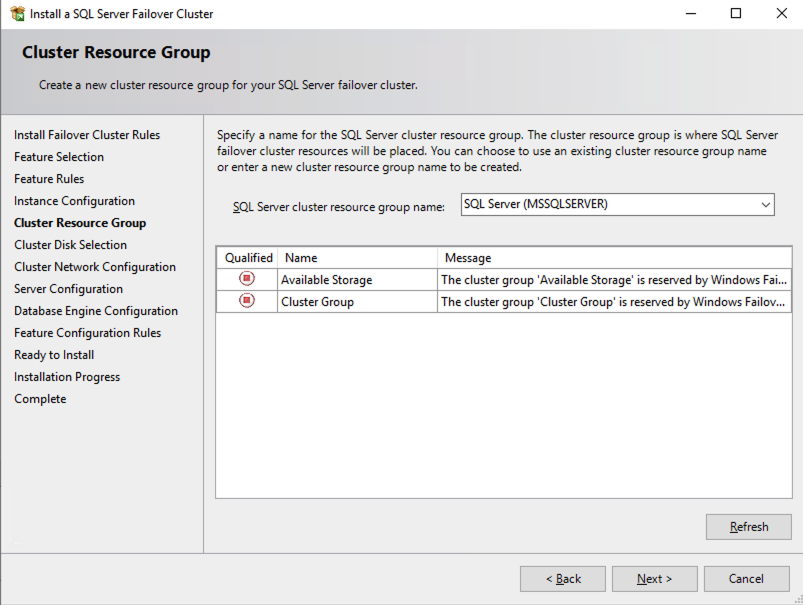
ทำตามตัวอย่างด้านล่างเพื่อติดตั้ง SQL Server บน SQL1
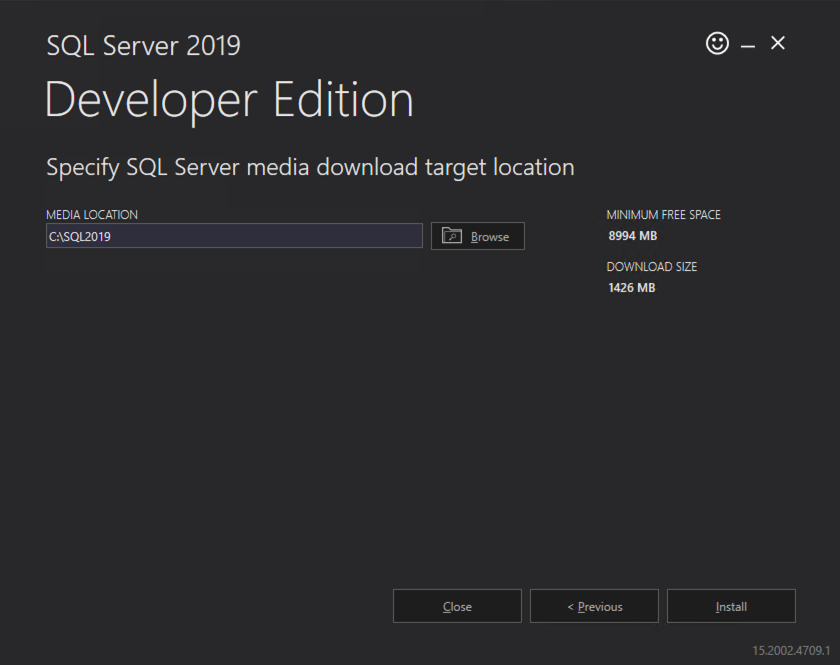
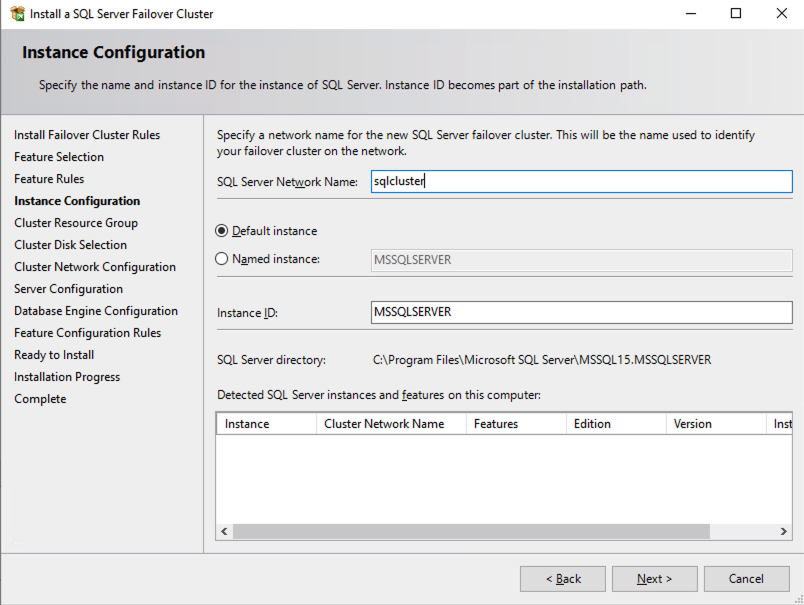
ชื่อที่คุณระบุด้านล่างคือจุดเข้าใช้งานไคลเอ็นต์ นี่คือชื่อที่แอปพลิเคชันเซิร์ฟเวอร์ของคุณจะใช้เมื่อต้องการเชื่อมต่อกับ SQL Server FCI
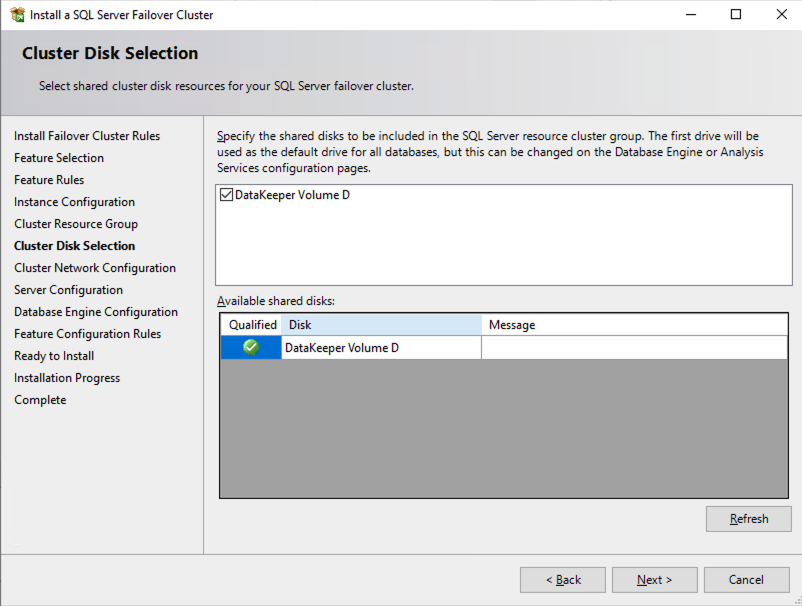
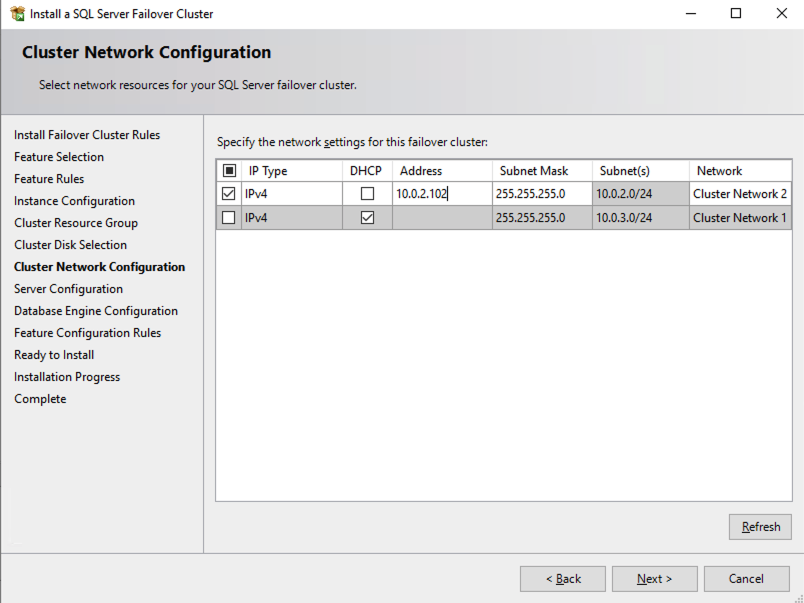
บนหน้าจอนี้ คุณจะเพิ่มที่อยู่ IP รองของ SQL1 ที่เราระบุไว้ก่อนหน้านี้ในส่วนการวางแผนของส่วนที่ 1ของซีรีย์นี้
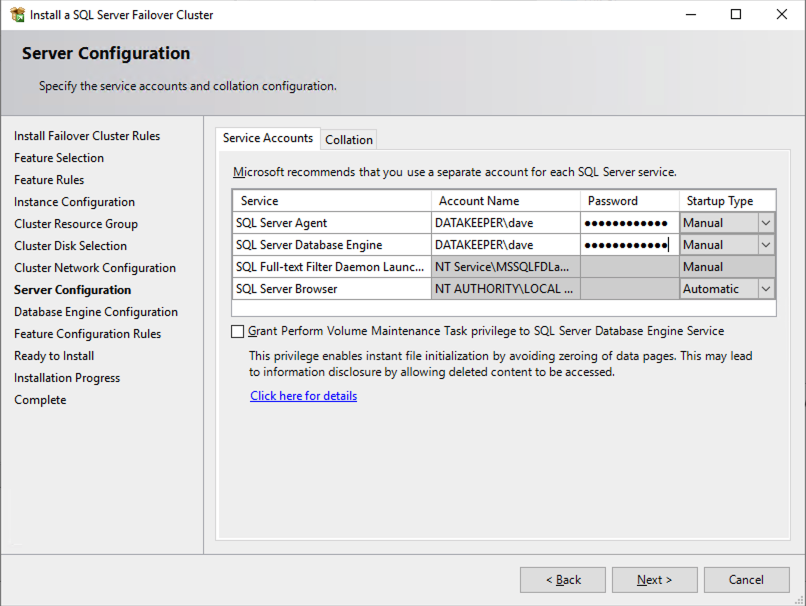
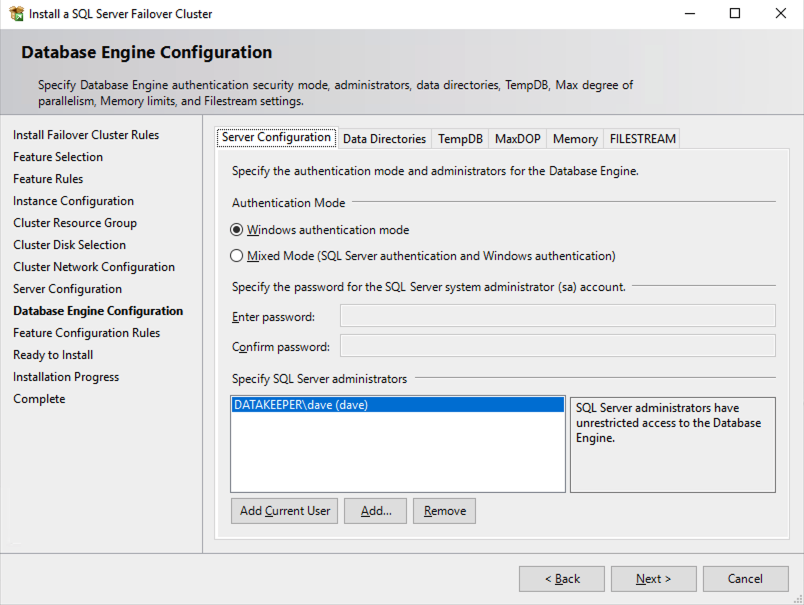
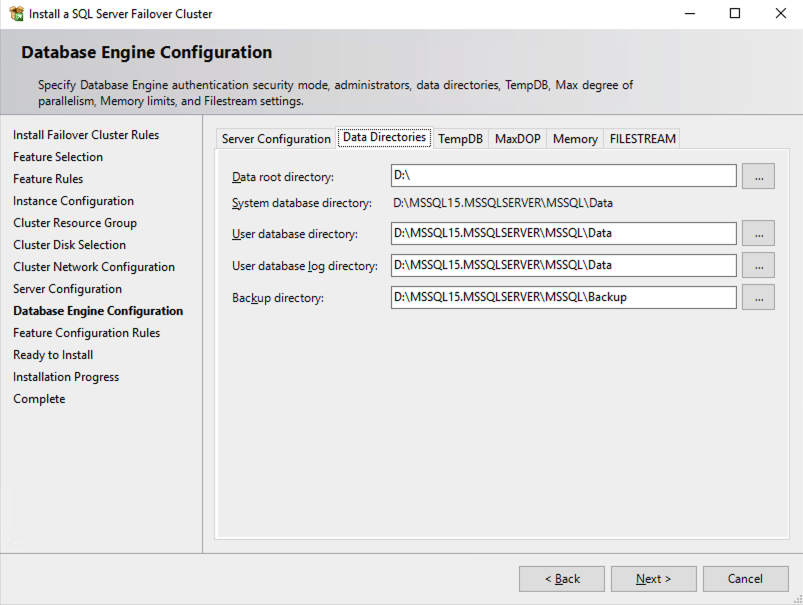
ในตัวอย่างนี้ เราทิ้ง tempdb ไว้บนไดรฟ์ D อย่างไรก็ตาม เพื่อประสิทธิภาพที่ดีที่สุด ขอแนะนำให้คุณค้นหาตำแหน่ง tempdb บนไดรฟ์ข้อมูลที่ไม่จำลองแบบ
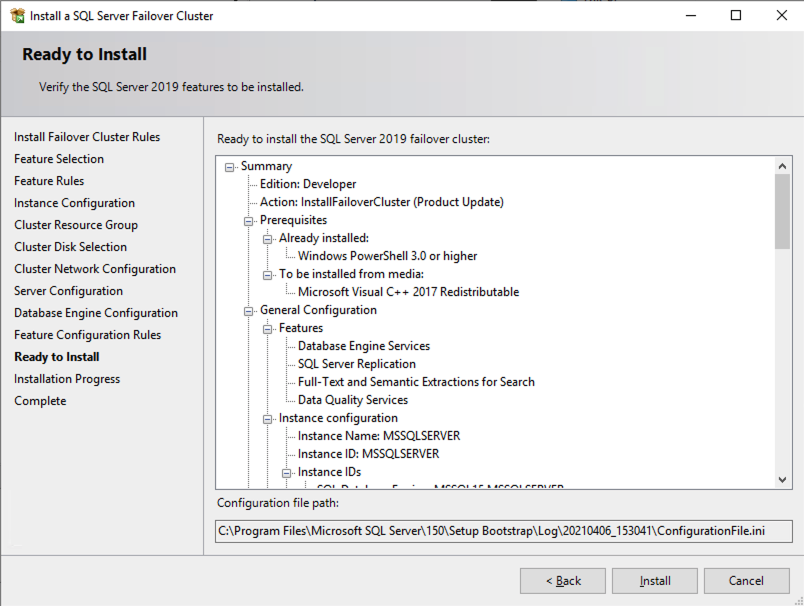
ติดตั้งโหนดที่สองของ SQL Server FCI บน SQL2
ถึงเวลาติดตั้ง SQL Server บน SQL2 แล้ว
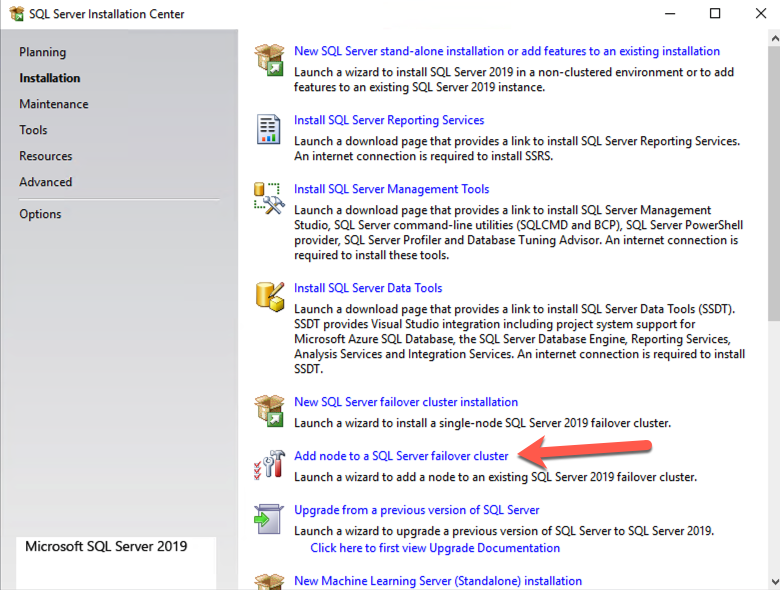
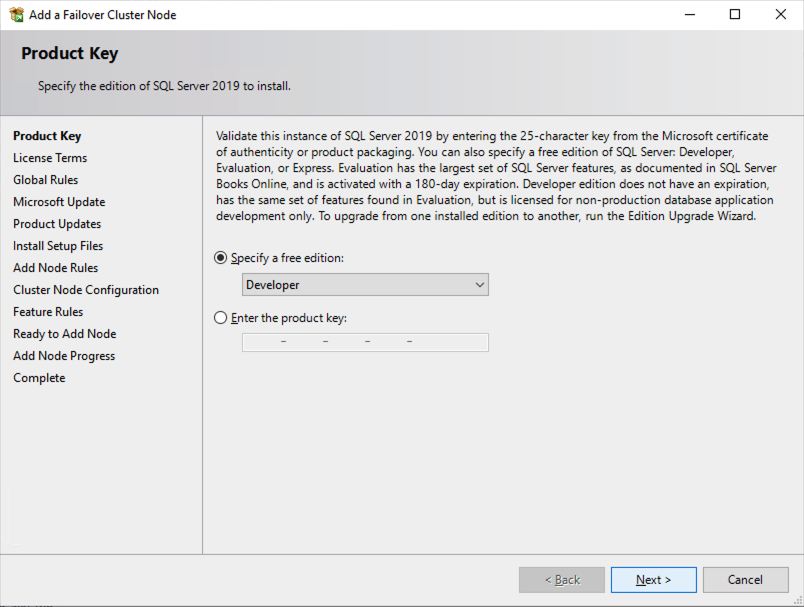
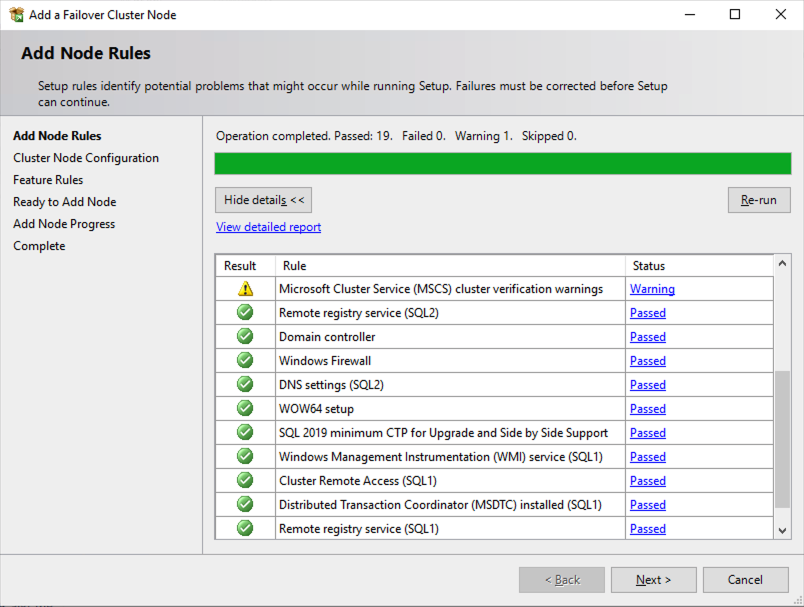
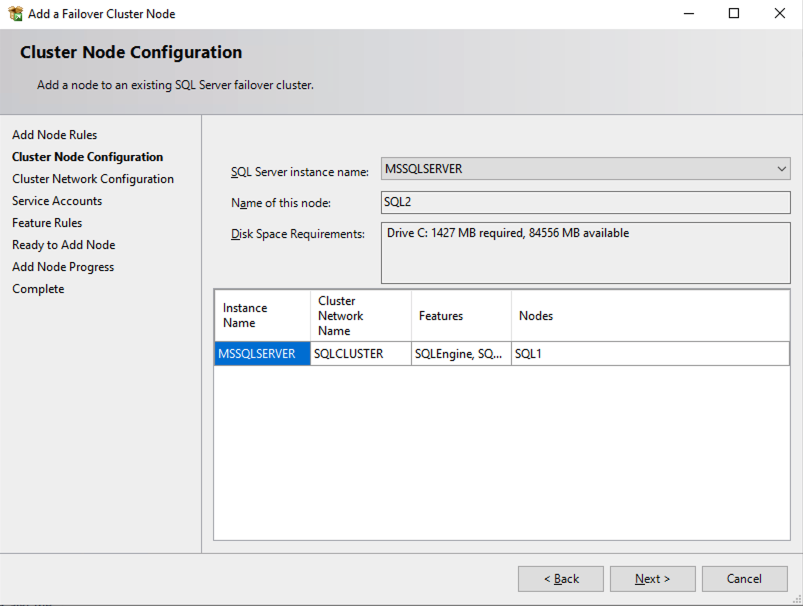
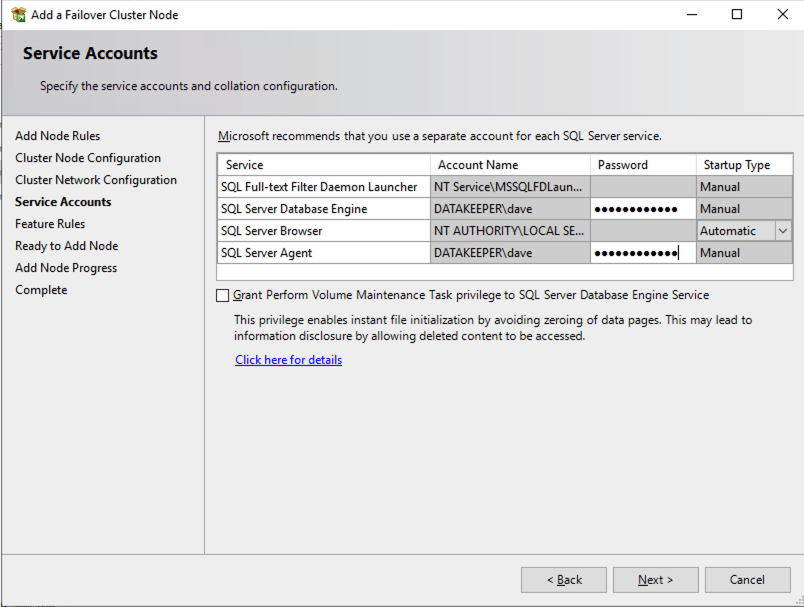
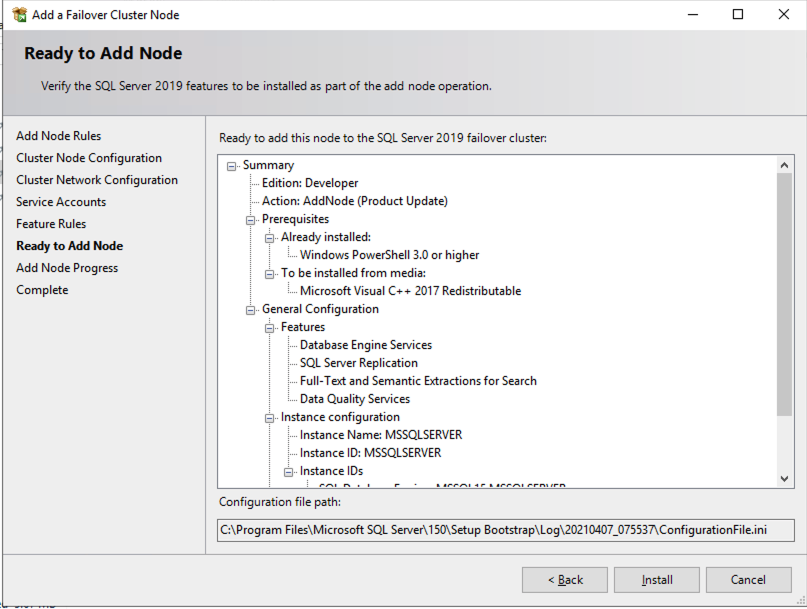
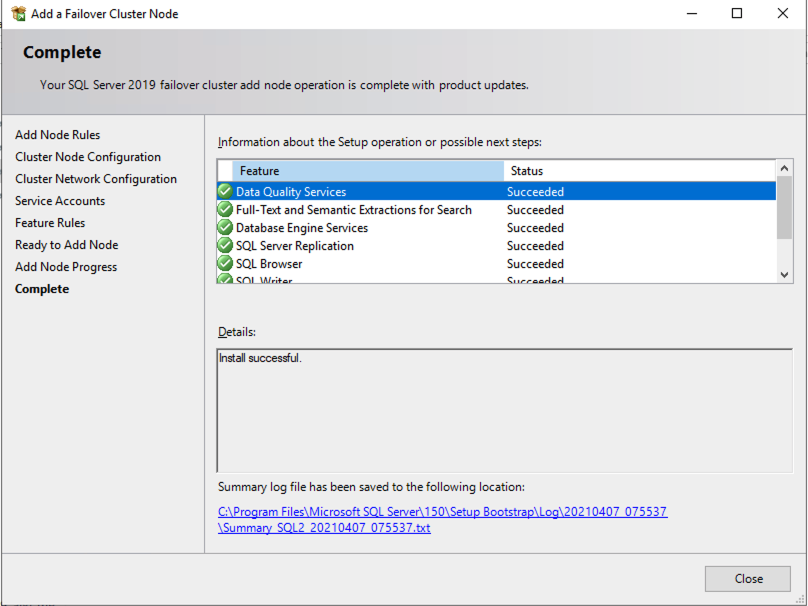
เมื่อคุณติดตั้ง SQL Server บนโหนดคลัสเตอร์ทั้งสองแล้ว Failover Cluster Manager ควรมีลักษณะเช่นนี้
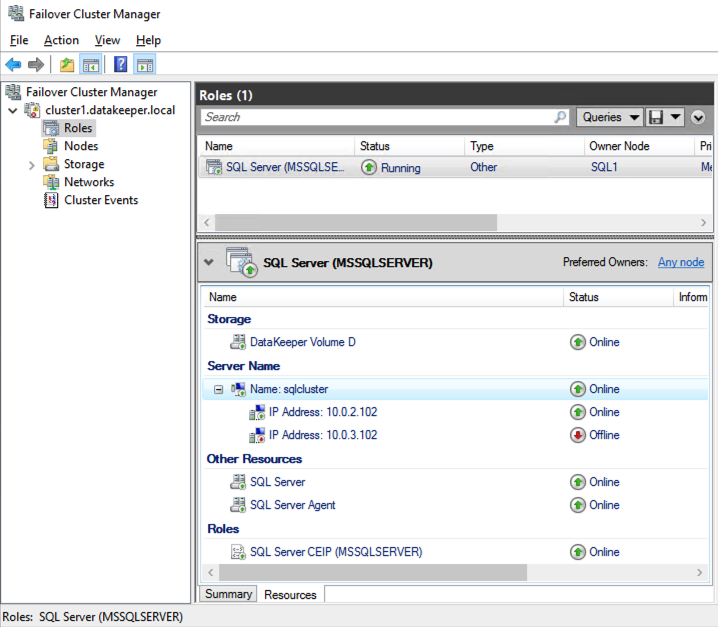
ติดตั้ง Studio จัดการเซิร์ฟเวอร์ SQL
ใน SQL Server เวอร์ชัน 2016 และใหม่กว่า คุณต้องดาวน์โหลดและติดตั้ง SSMS เป็นตัวเลือกแยกต่างหากดังที่แสดงด้านล่าง หมายเหตุ: ใน SQL Server เวอร์ชันก่อนหน้า SQL Server Management Studio (SSMS) เป็นตัวเลือกที่คุณสามารถเลือกติดตั้งระหว่างการติดตั้ง SQL

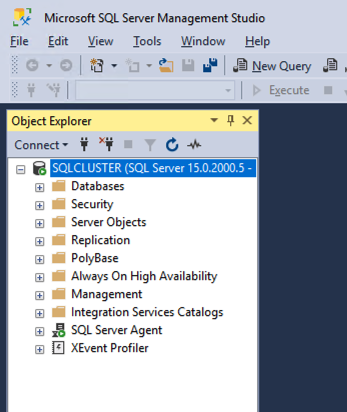
เมื่อติดตั้ง SSMS แล้ว ให้เชื่อมต่อกับคลัสเตอร์ผ่านจุดเข้าใช้งานไคลเอ็นต์ SQL Server FCI ของคุณควรมีลักษณะเช่นนี้
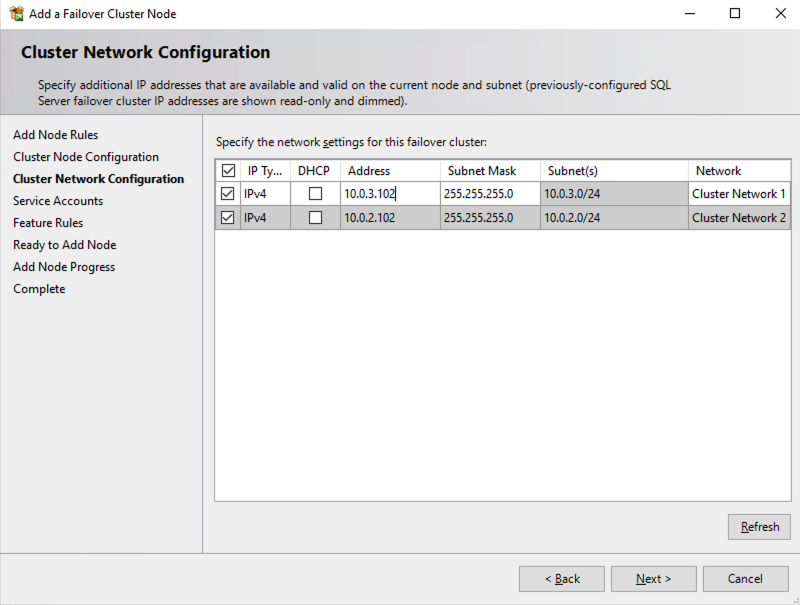
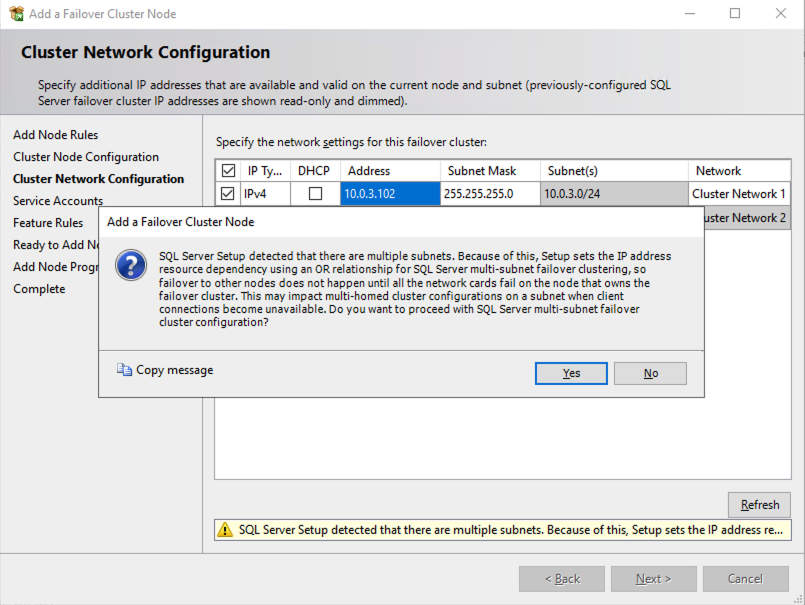
ข้อควรพิจารณาเกี่ยวกับหลายซับเน็ต
ข้อควรพิจารณาที่ใหญ่ที่สุดประการหนึ่งสำหรับการรัน SQL Server FCI ใน OCI คือข้อเท็จจริงที่ว่าโหนดคลัสเตอร์อยู่ในเครือข่ายย่อยที่แตกต่างกัน Microsoft เริ่มคำนึงถึงข้อเท็จจริงที่ว่าโหนดคลัสเตอร์อาจอยู่ในเครือข่ายย่อยที่แตกต่างกันโดยการเพิ่มฟังก์ชัน “OR” ใน Windows Server 2008 R2 ตามที่อธิบายไว้ใน Microsoftเอกสารประกอบ–
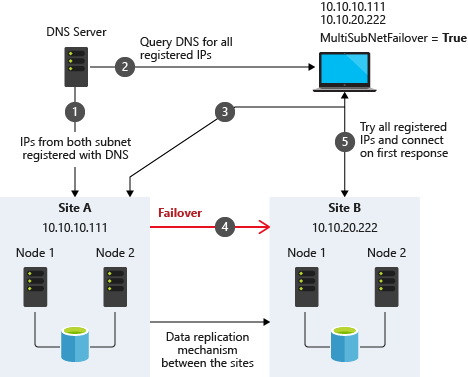
เอามาจากการทำคลัสเตอร์หลายซับเน็ตเซิร์ฟเวอร์ SQL (SQL Server)
สิ่งสำคัญที่อธิบายไว้ในเอกสารประกอบคือแนวคิดของ RegisterAllProvidersIP บนทรัพยากรชื่อเครือข่าย ซึ่งเปิดใช้งานตามค่าเริ่มต้นเมื่อคุณสร้าง SQL Server FCI ตามที่อธิบายไว้ เมื่อเปิดใช้งาน เรคคอร์ด A สองเรคคอร์ดจะถูกลงทะเบียนใน DNS พร้อมด้วยทรัพยากรชื่อเครือข่าย หนึ่งเรคคอร์ดสำหรับแต่ละที่อยู่ IP
การใช้ฟังก์ชัน “OR” เฉพาะที่อยู่ IP ที่เชื่อมโยงกับซับเน็ตที่ใช้งานอยู่เท่านั้นที่จะออนไลน์ และอีกอันหนึ่งจะแสดงเป็นออฟไลน์ หากไคลเอนต์ของคุณรองรับการเพิ่ม multisubnetfailover=true ให้กับสตริงการเชื่อมต่อ ที่อยู่ IP ทั้งสองจะถูกลองใช้พร้อมกัน และไคลเอนต์จะเชื่อมต่อกับโหนดที่ใช้งานอยู่โดยอัตโนมัติ นั่นเป็นวิธีที่ง่ายที่สุดและเป็นวิธีการเริ่มต้นของการเปลี่ยนเส้นทางไคลเอนต์ในคลัสเตอร์หลายซับเน็ต
เอกสารประกอบกล่าวต่อไปว่าหากไคลเอ็นต์ของคุณไม่รองรับฟังก์ชัน multisubnetfailover=true คุณควร “ลองปรับการหมดเวลาการเชื่อมต่อในสตริงการเชื่อมต่อไคลเอ็นต์ภายใน 21 วินาทีสำหรับที่อยู่ IP เพิ่มเติมแต่ละรายการ สิ่งนี้ทำให้แน่ใจได้ว่าความพยายามในการเชื่อมต่อใหม่ของไคลเอ็นต์จะไม่หมดเวลาก่อนที่จะสามารถวนผ่านที่อยู่ IP ทั้งหมดใน FCI แบบหลายซับเน็ตของคุณได้”
การปิดใช้งาน RegisterAllProvidersIP เป็นอีกตัวเลือกหนึ่งที่จะใช้งานได้ เมื่อปิดใช้งาน RegisterAllProvidersIP คุณจะมีระเบียน A เดียวใน DNS บันทึก DNS A จะได้รับการอัปเดตในแต่ละครั้งที่คลัสเตอร์ล้มเหลวด้วยที่อยู่ IP ของคลัสเตอร์ที่ใช้งานซึ่งเชื่อมโยงกับทรัพยากรชื่อ
ข้อเสียของการกำหนดค่าสถานการณ์นี้คือ ไคลเอนต์ของคุณจะแคชที่อยู่ IP เก่าจนกว่า time to live (TTL) จะหมดลง เพื่อลดความล่าช้าในการเชื่อมต่อใหม่ ขอแนะนำให้คุณเปลี่ยน TTL บนชื่อทรัพยากร กระบวนการนี้อธิบายไว้ที่นี่และตัวอย่างที่แสดงด้านล่างซึ่งตั้งค่า TTL เป็น 5 นาที
รับ ClusterResource – ชื่อ sqlcluster | ตั้งค่า ClusterParameter – ชื่อ HostRecordTTL – ค่า 300
โปรดทราบว่าอาจต้องใช้เวลาสักระยะก่อนที่การเปลี่ยนแปลงเซิร์ฟเวอร์ DNS ที่รวม AD ของคุณจะเผยแพร่ทั่วทั้งฟอเรสต์ของคุณ
สรุป
คู่มือทางเทคนิคนี้ให้ภาพรวมที่ครอบคลุมของการตั้งค่า SQL Server 2019 Failover Cluster Instance (FCI) ใน Oracle Cloud Infrastructure (OCI) เริ่มต้นด้วยการเน้นถึงความสำคัญของการทำความเข้าใจ SLA ความพร้อมใช้งานของ OCI ที่แตกต่างกันไปตามกลยุทธ์การปรับใช้: 99.99% สำหรับการปรับใช้ข้ามโดเมนความพร้อมใช้งาน, 99.95% สำหรับการปรับใช้ข้ามโดเมนข้อบกพร่อง และ 99.9% สำหรับการปรับใช้ VM เดี่ยว คู่มือนี้เน้นย้ำว่า SLA ครอบคลุมความพร้อมใช้งานของ VM ไม่ใช่แอปพลิเคชันหรือบริการที่ทำงานอยู่บนนั้น จึงจำเป็นต้องมีมาตรการเพิ่มเติมสำหรับความพร้อมใช้งานของแอปพลิเคชัน
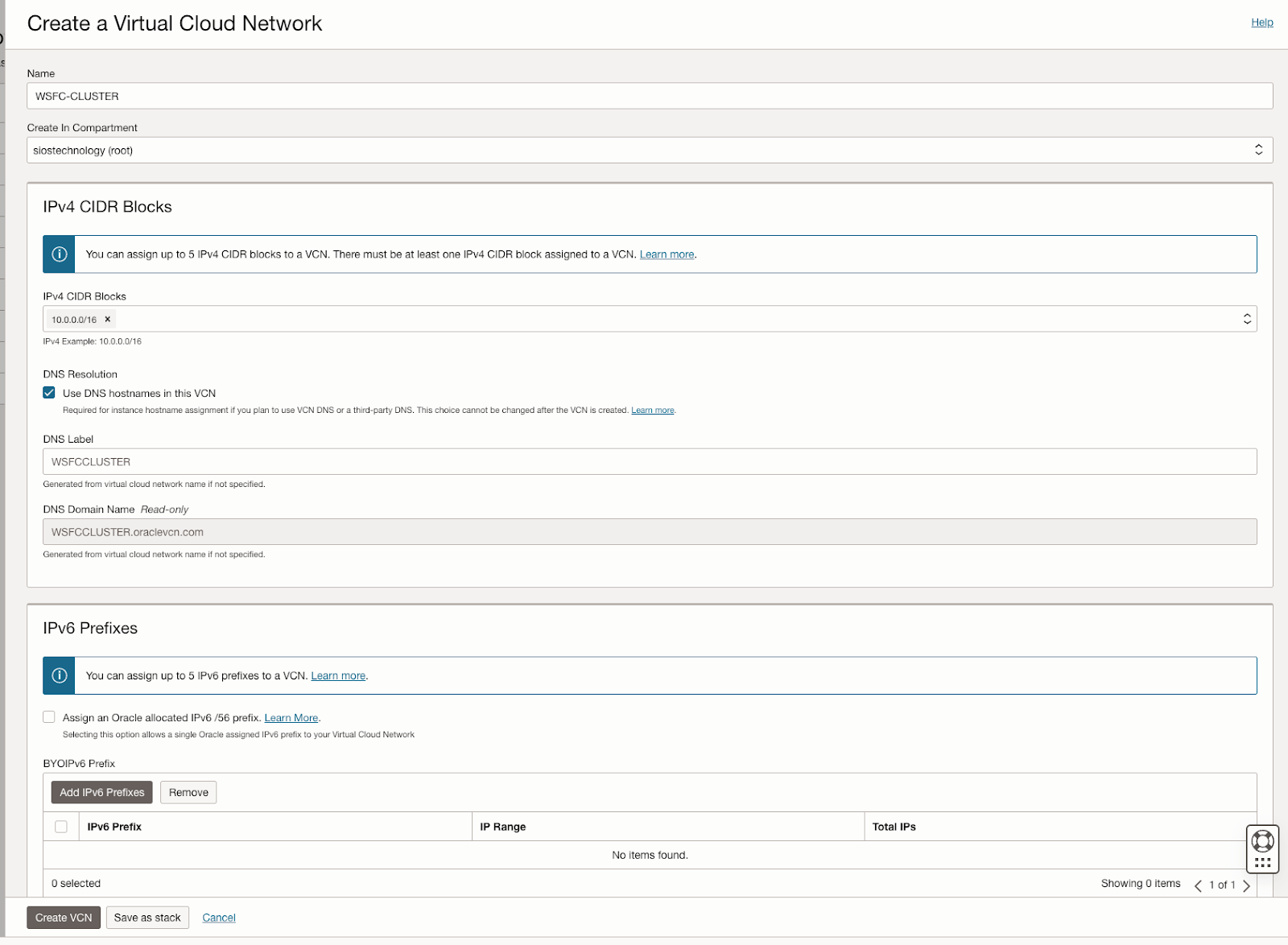
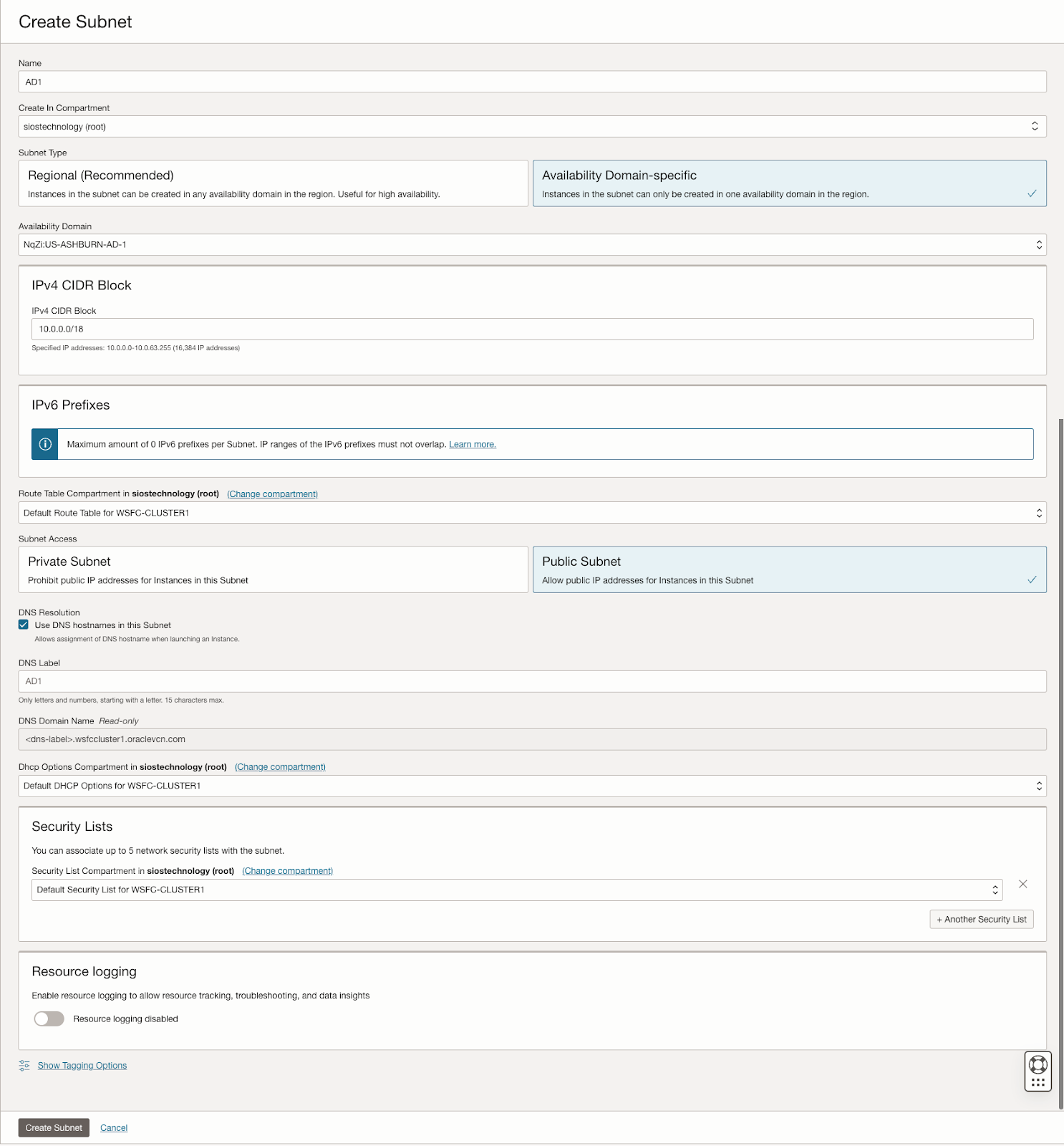
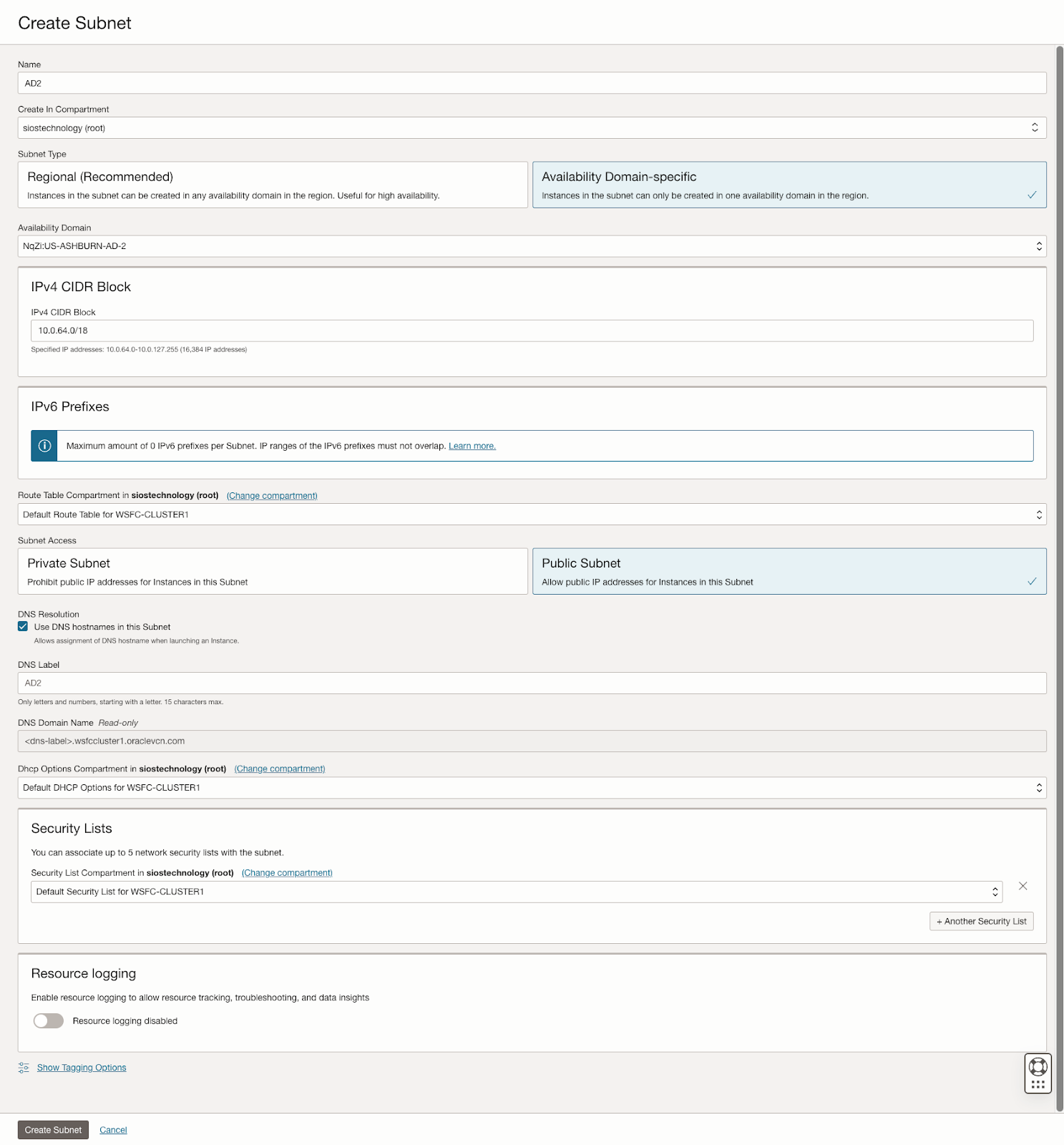
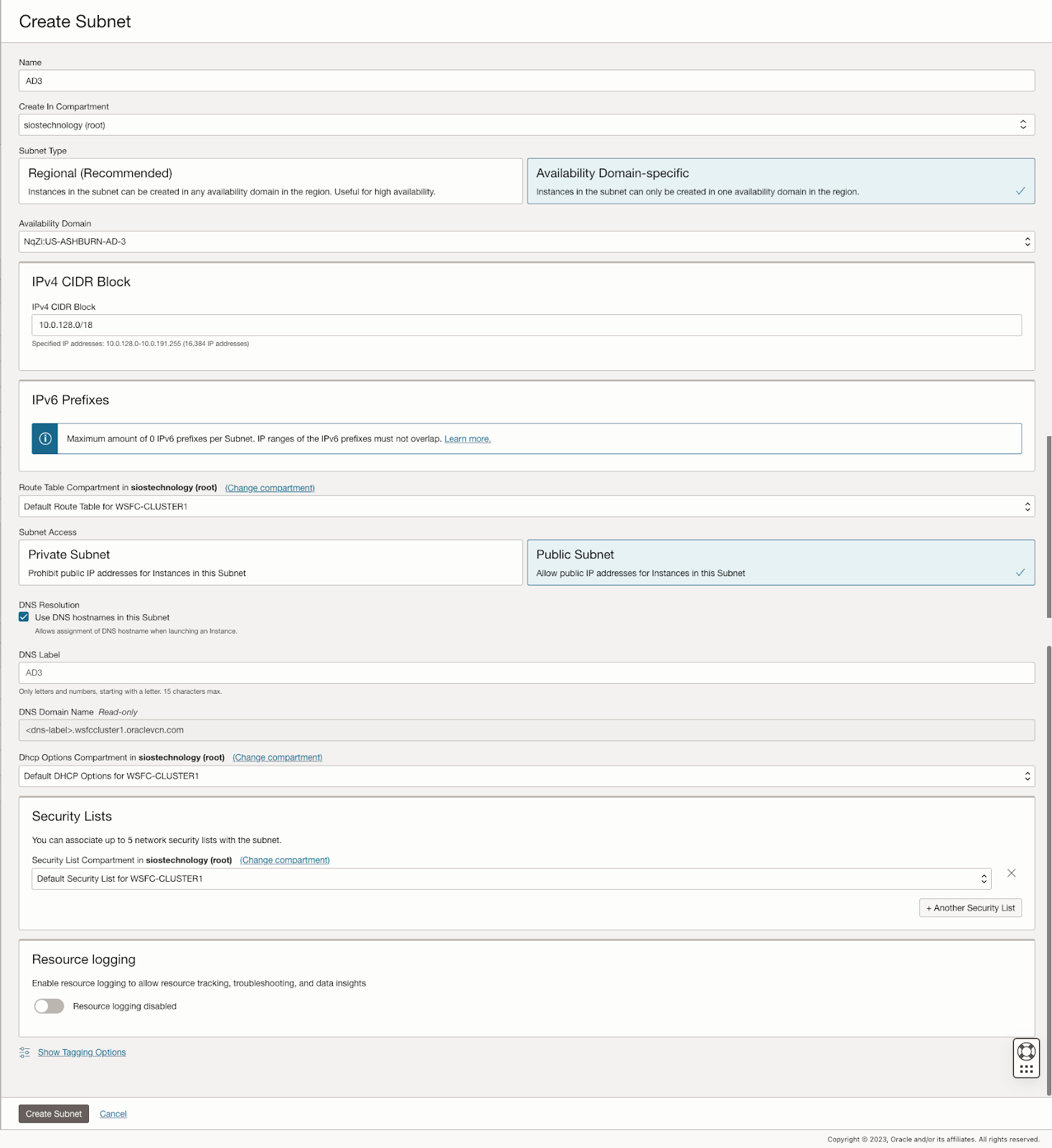
คู่มือนี้ให้รายละเอียดเกี่ยวกับขั้นตอนเริ่มต้นของการสร้าง Virtual Cloud Network (VCN) และซับเน็ตใน OCI โดยเน้นถึงความจำเป็นในแผนเครือข่ายที่รองรับโดเมนความพร้อมใช้งานอย่างน้อยสามโดเมนเพื่อจุดประสงค์ในการทำคลัสเตอร์ โดเมนความพร้อมใช้งานแต่ละโดเมนต้องอยู่ในเครือข่ายย่อยที่แตกต่างกัน ซึ่งเป็นข้อกำหนดที่ใช้กับคลัสเตอร์ที่ขยาย Fault Domains เช่นกัน โดยให้การกำหนดค่าเฉพาะสำหรับการตั้งค่าเครือข่ายย่อยสามเครือข่ายในโดเมนความพร้อมใช้งานที่แตกต่างกันภายใน VCN เดียว
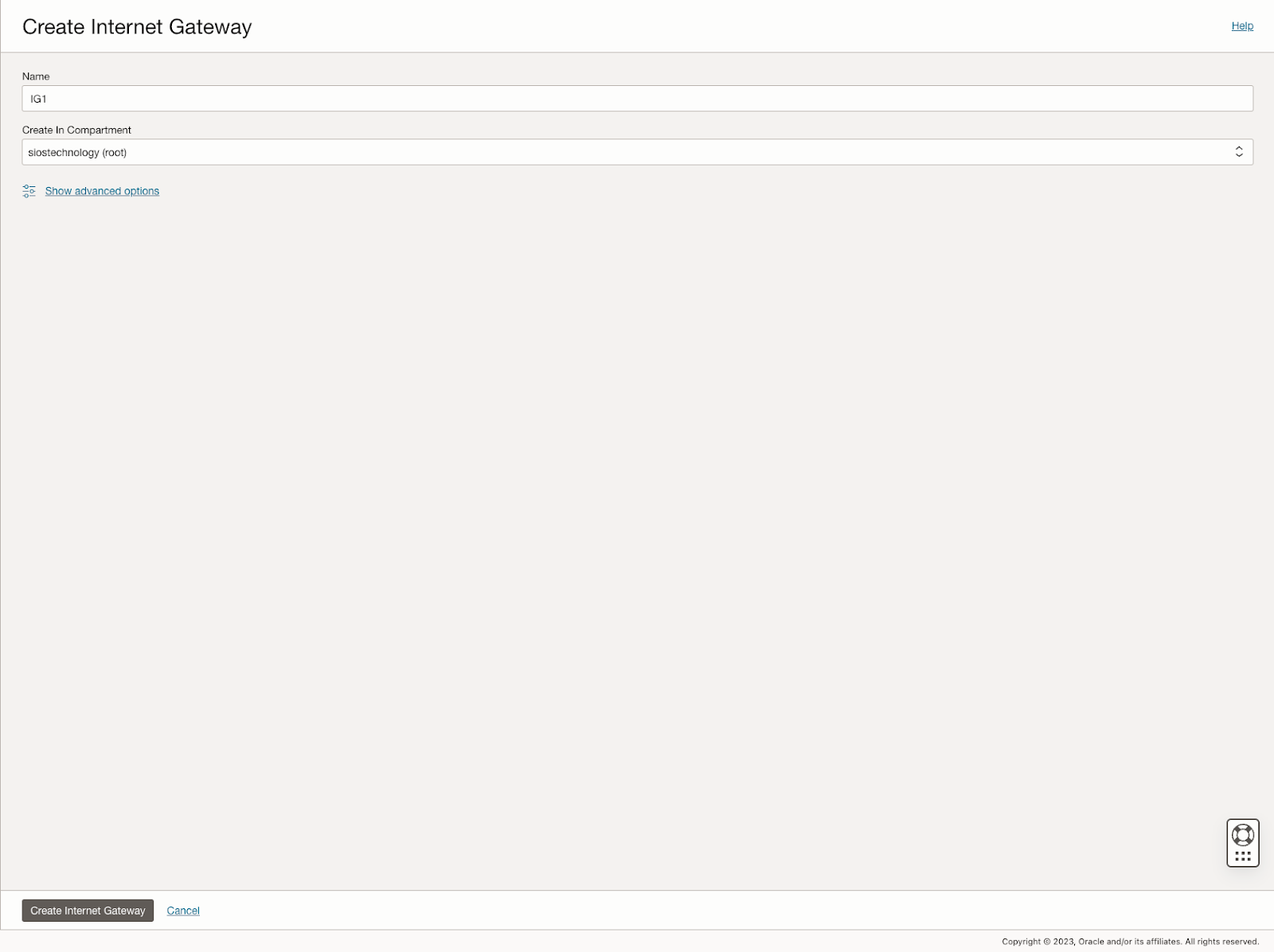
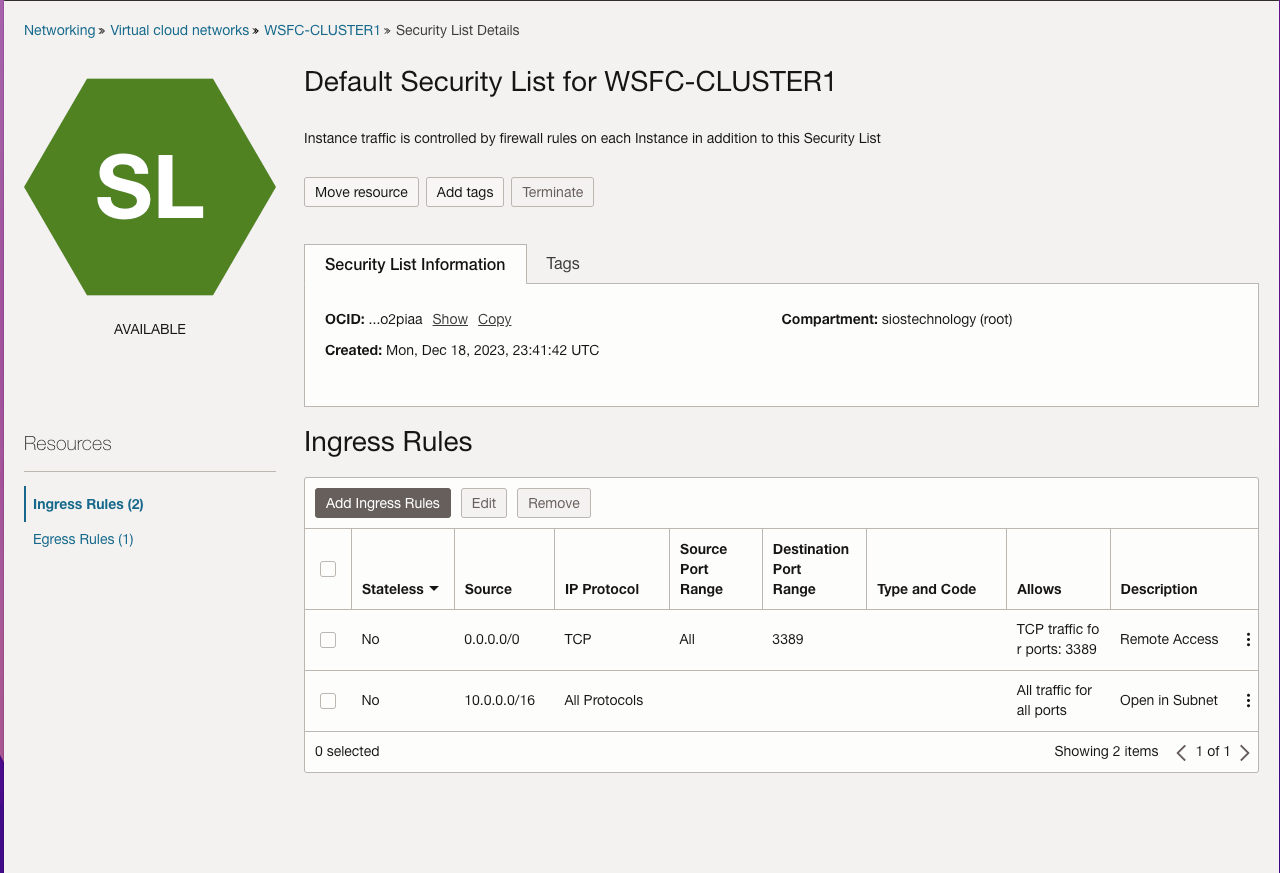
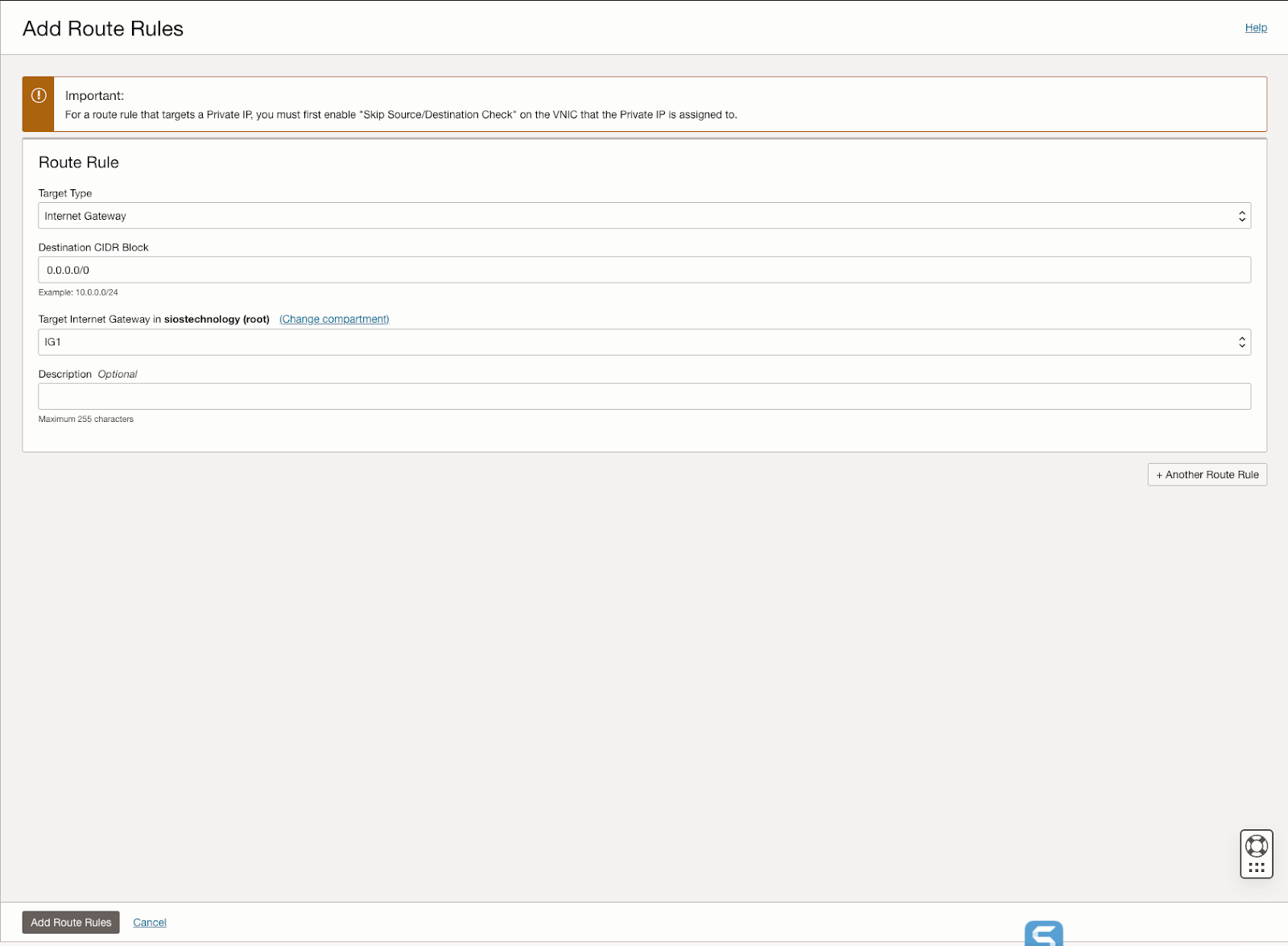
นอกจากนี้ คู่มือนี้ยังอธิบายกระบวนการสร้างอินเทอร์เน็ตเกตเวย์และการแก้ไขรายการความปลอดภัยเริ่มต้นและตารางเส้นทางเพื่ออำนวยความสะดวกในการเข้าถึงและการรักษาความปลอดภัยทั่วทั้งโดเมนความพร้อมใช้งาน นอกจากนี้ยังครอบคลุมการกำหนดค่าตัวเลือก DHCP สำหรับความเข้ากันได้ของ Active Directory และสรุปขั้นตอนสำหรับการจัดเตรียม VM ด้วย Windows Server 2022 และ SQL Server 2019 โดยเน้นความสำคัญของชื่อเซิร์ฟเวอร์การวางแผน ที่อยู่ IP และตำแหน่งโซนความพร้อมใช้งาน
จากนั้น คำแนะนำจะเจาะลึกในการเพิ่มวอลลุมเพิ่มเติมสำหรับความต้องการพื้นที่จัดเก็บข้อมูล SQL Server FCI โดยให้รายละเอียดกระบวนการสร้างและการแนบบล็อควอลลุมเข้ากับอินสแตนซ์ นอกจากนี้ยังแนะนำการกำหนดค่าที่อยู่ IP รองสำหรับ Windows Server Failover Clustering ใน OCI
ถัดไป คำแนะนำจะกล่าวถึงการตั้งค่าตัวควบคุมโดเมน รวมถึงการเปิดใช้งานบริการโดเมน Active Directory และการโปรโมตเซิร์ฟเวอร์ไปยังตัวควบคุมโดเมน โดยจะอธิบายขั้นตอนการเตรียมการจัดเก็บข้อมูลและการเปิดใช้งานคุณลักษณะ Failover Clustering บน SQL1 และ SQL2 พร้อมด้วยการตรวจสอบความถูกต้องของคลัสเตอร์และกระบวนการสร้าง
คู่มือนี้จะอธิบายเพิ่มเติมเกี่ยวกับการเพิ่ม File Share Witness เพื่อรักษาองค์ประชุมคลัสเตอร์และการติดตั้ง DataKeeper Cluster Edition สำหรับการจำลองโวลุ่ม โดยให้แนวทางทีละขั้นตอนในการติดตั้ง SQL Server บนโหนดคลัสเตอร์และ SQL Server Management Studio พร้อมด้วยข้อควรพิจารณาสำหรับการปรับใช้หลายซับเน็ต
โดยสรุป คู่มือนี้เสนอพิมพ์เขียวโดยละเอียดสำหรับการปรับใช้และกำหนดค่า SQL Server 2019 FCI ใน OCI ครอบคลุมแง่มุมต่างๆ ตั้งแต่การตั้งค่าเครือข่ายและการจัดเตรียม VM ไปจนถึงการทำคลัสเตอร์ การกำหนดค่าพื้นที่เก็บข้อมูล และการตั้งค่าการควบคุมโดเมน เพื่อให้มั่นใจถึงเวลาทำงานและความน่าเชื่อถือสูงสุดสำหรับแอปพลิเคชันที่สำคัญต่อธุรกิจ .
ดาวน์โหลดคำแนะนำทีละขั้นตอนที่นี่
ทำซ้ำโดยได้รับอนุญาตจากSIOS