雲遷移停滯的六個原因
越來越多的客戶正在尋求利用雲的靈活性,可擴展性和性能。 隨著做出這一轉變的應用程序,解決方案,客戶和合作夥伴的數量增加,請確保您的遷移不會停止。
避免以下六個原因導致雲遷移停滯
1.不完整的雲遷移項目計劃
人們普遍認為,項目計劃是項目成功的關鍵因素。 計劃在幫助指導利益相關者,多樣化的實施團隊和合作夥伴完成項目階段中起著至關重要的作用。 規劃可幫助確定所需目標,使資源和團隊與這些目標保持一致,降低風險,避免錯過最後期限,並最終在雲中提供高可用性解決方案。計劃不完整和計劃不完整通常是導致項目停滯的主要原因。在第九個小時,確定了關鍵依賴性。 在服務器意外重啟期間,將識別應用程序監視和HA漏洞(請參閱下文)。 確保您的雲遷移有一個計劃,然後執行該計劃。
2.在本地過度設計
“這就是我們在本地節點上做到的方式”,這是開始最近的客戶對話的短語。 當客戶嘗試遷移到雲時,他們與SIOS專業服務項目經理Edmond Melkomian進行了接觸。在一次發現會議中,Edmond能夠發現許多與內部部署和雲架構有關的過度設計的項目。 對於某些項目,複製在場所進行的操作可能會成為膨脹,複雜和延遲的簡歷。 分析您的架構和遷移計劃,並無情地消除過度設計的組件和設計,尤其是在網絡和存儲方面。
3.預留空間不足
控製成本和防止蔓延是雲遷移的重要和關鍵方面。但是,一些擔心每小時收費以及磁盤和帶寬相關成本的客戶陷入了配置不足的陷阱。在此陷阱中,資源的大小不正確,例如具有錯誤的速度特徵的磁盤,使用錯誤的CPU或內存佔用量來計算資源或具有錯誤數目的節點的群集。在這種配置不足的情況下,當用戶接受測試(UAT)開始並且預期/預期的工作負載在容量不足的資源上造成日誌阻塞時,就會出現問題。或者目標節點的成本優化無法在故障轉移方案中正確處理資源。 雖然在雲中調整虛擬機的大小是一個簡單的過程,但是在建築師和首席財務官試圖了解重新配置資源的影響時,這些大小調整問題通常會造成延遲。
4.內部IT流程
每個偉大的企業公司都有一套內部流程,您的團隊和公司也不例外。在流程中,IT流程通常是關鍵的,可能會對您的雲遷移策略的成功產生重大影響。 過去,許多公司的採購和採購流程都很漫長,包括投標,規模調整指南,訂單批准,服務器準備和配置以及最終部署。雲過程極大地改變了獲取,部署計算,存儲和網絡資源的方式。但是,如果您的流程跟不上雲的速度,那麼當計劃更改時,遷移可能會遇到障礙。
5.高可用性計劃不佳
雲遷移可能會停止的另一個原因涉及高可用性計劃。 高可用性不僅需要一捆工具或企業許可證。HA需要仔細,徹底和周到的系統設計。部署高可用性解決方案時,您的計劃將需要考慮容量,冗餘以及恢復和更正的要求。 通過計劃,可以正確識別需求,提出解決方案,考慮風險並管理部署和驗證的依賴性。 如果沒有計劃,項目和部署將容易受到風險,單點故障問題,安裝不當以及缺少應用程序保護或恢復策略的層次和級別的威脅。通常,在缺乏高可用性計劃的情況下,項目會停頓,而需求卻沒有得到解決。
6.不完整或無效的測試
羅恩(Ron)是將其最終客戶遷移到雲的合作夥伴,計劃在接下來的三天週末上線。 “執行/不執行”的最後決定點是在登台服務器上進行了一批用戶接受測試。第一次測試失敗。為了彌補由於其他遷移障礙而造成的時間浪費,Ron和團隊跳過了一些測試案例,這些測試案例與將最新的安全性和備份軟件最終集合集成到支持補丁的最新操作系統上有關。 這種模擬負載是新創建的服務器上的第一個負載,它解決了Ron體系結構中的一系列問題,包括內核錯誤,CPU和內存供應問題以及存儲佈局和容量問題。 該項目被推遲了四個多星期,以解決客戶的信心,正確的測試和驗證,調整大小和架構以及應用軟件和操作系統修復的問題。
雲的前景令人鼓舞,精心計劃的雲遷移將使您和您的團隊能夠利用這些優勢。 無論您是開始遷移還是正在進行雲遷移,我們希望本文可以幫助您更多地了解常見的陷阱,以期可以避免它們。
–客戶體驗副總裁Cassius Rhue
轉載自SIOS


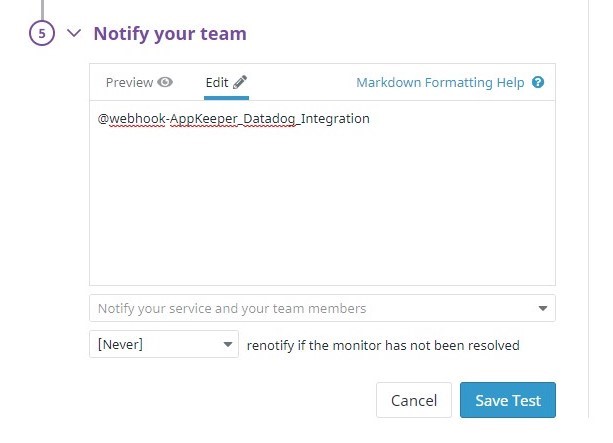
 5, 定義警報條件
5, 定義警報條件