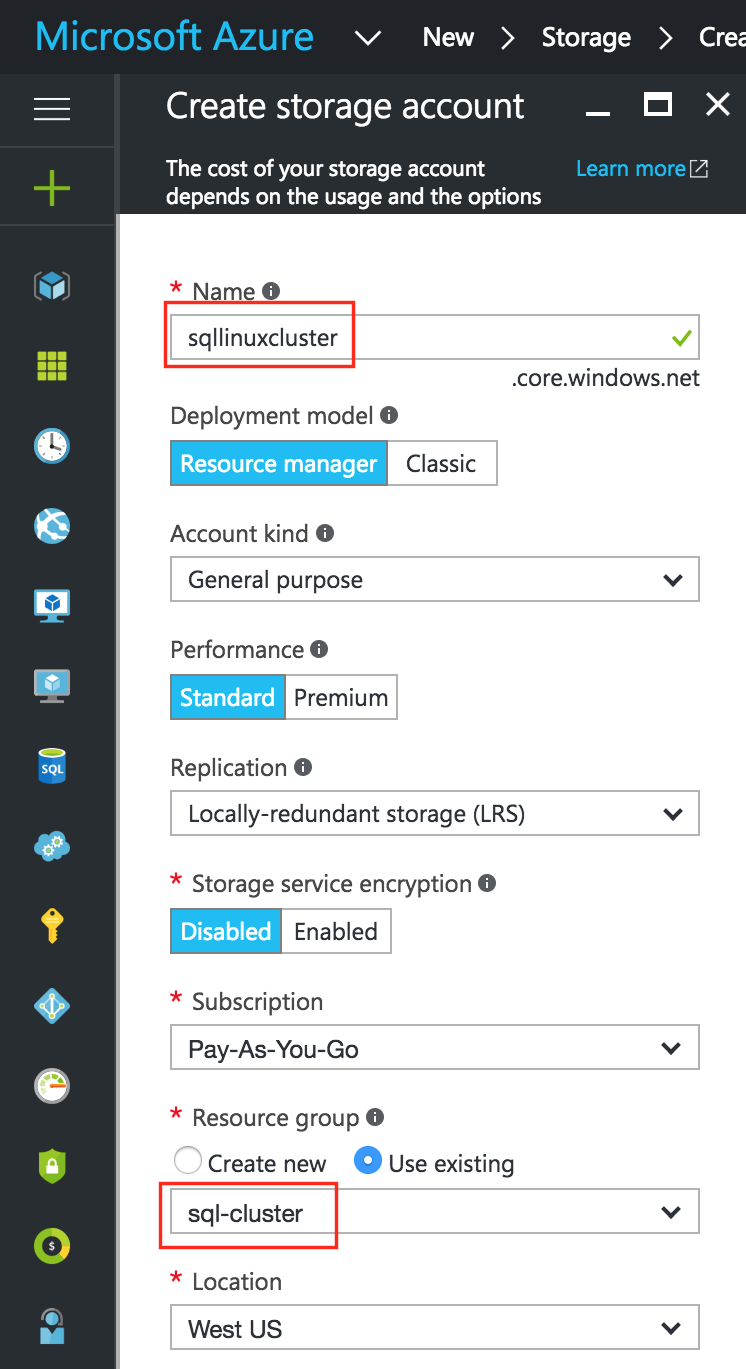
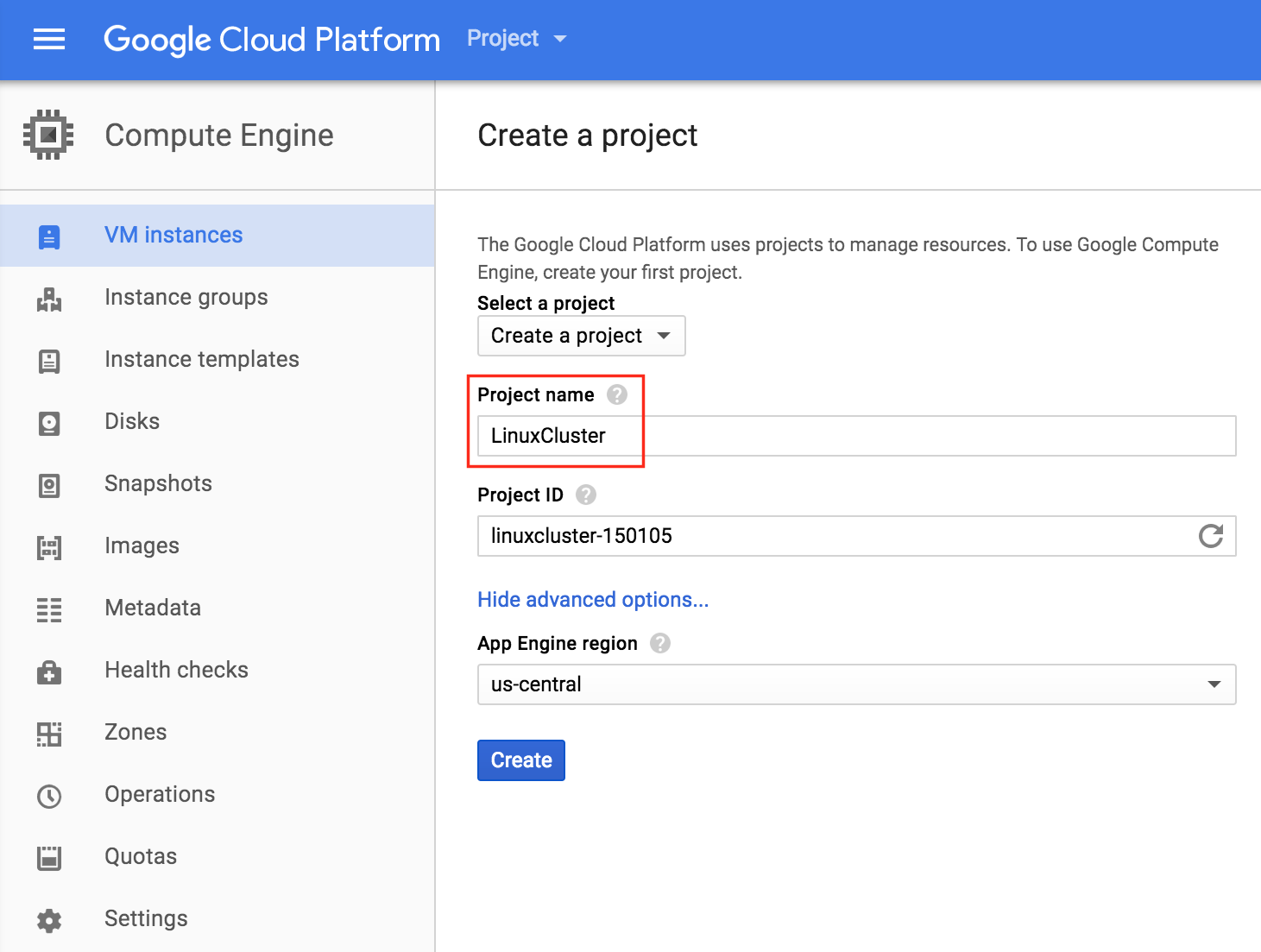
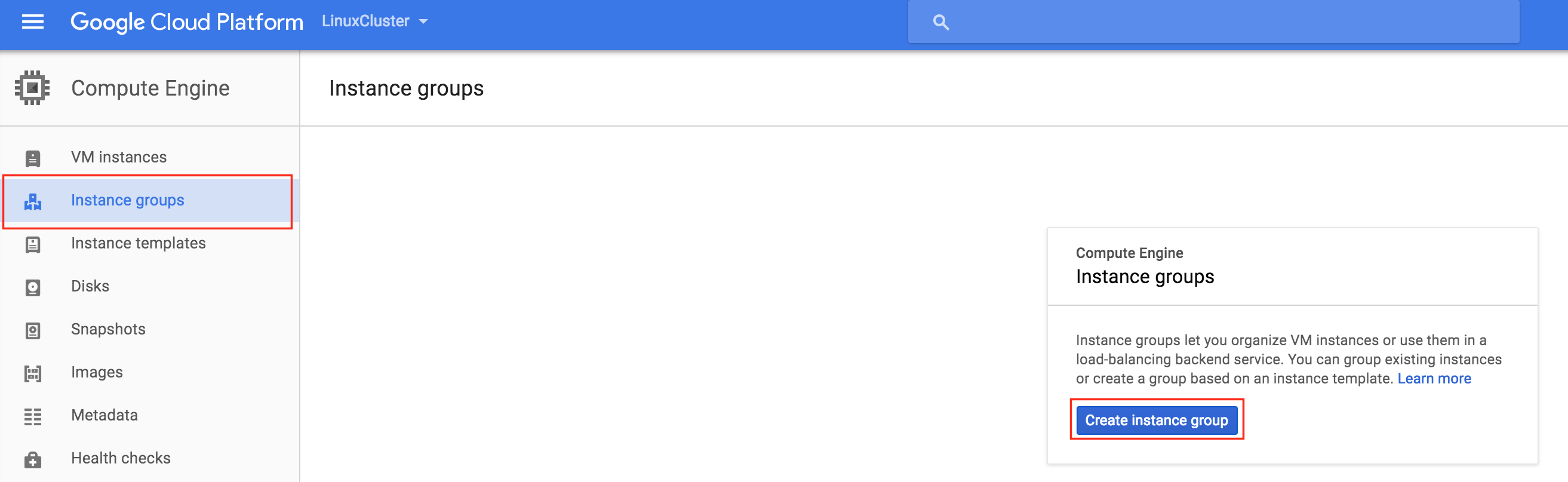
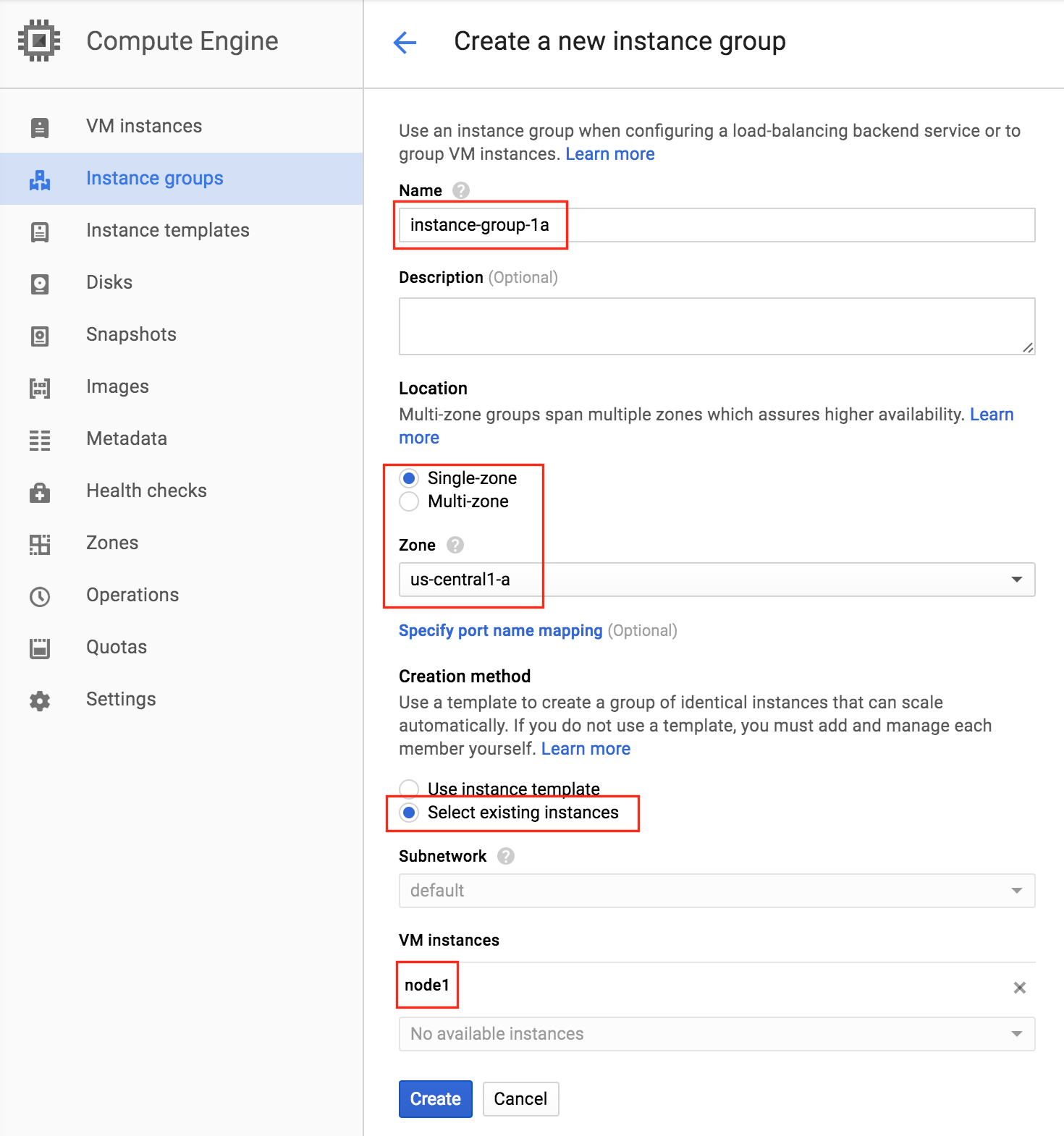
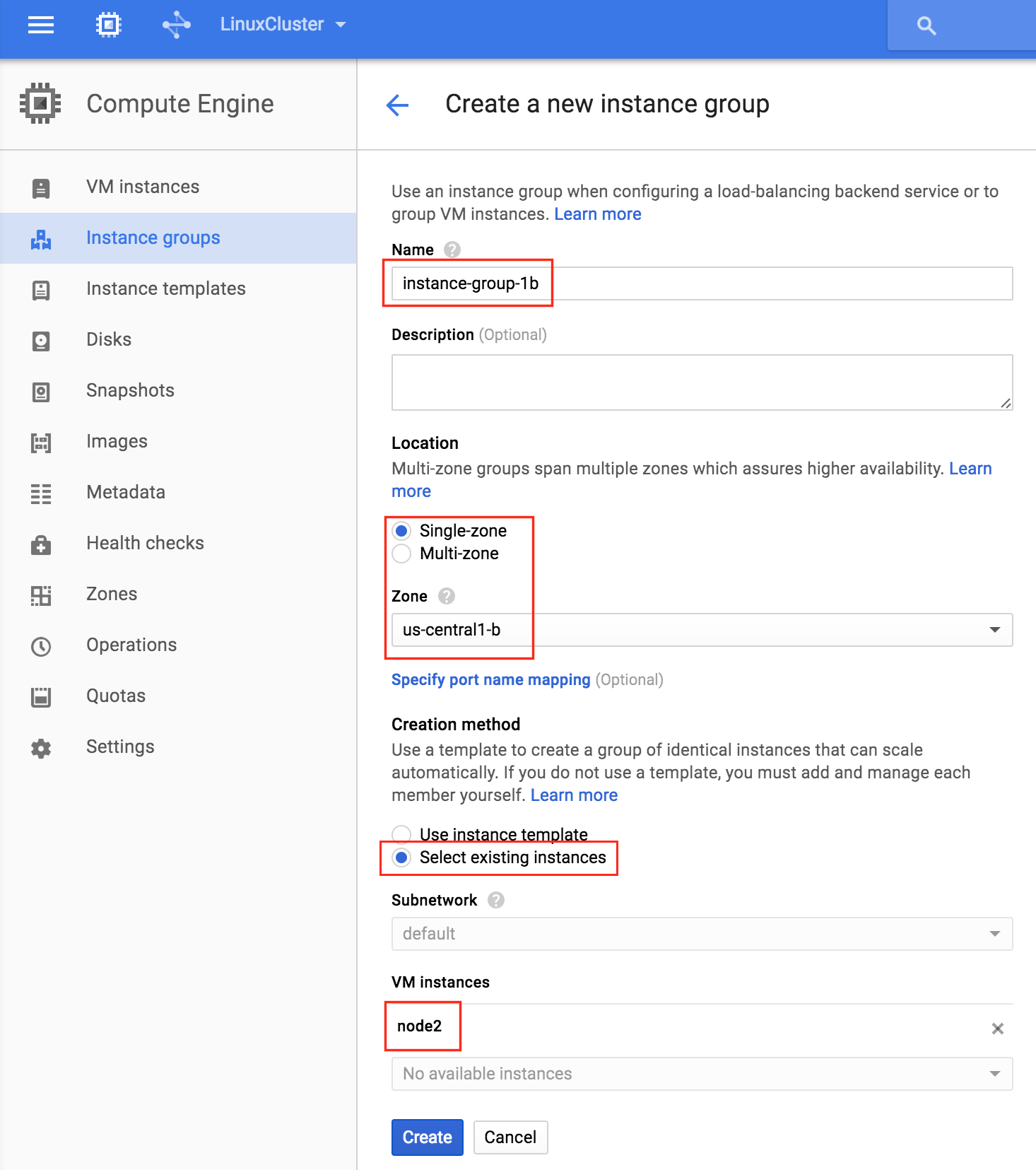
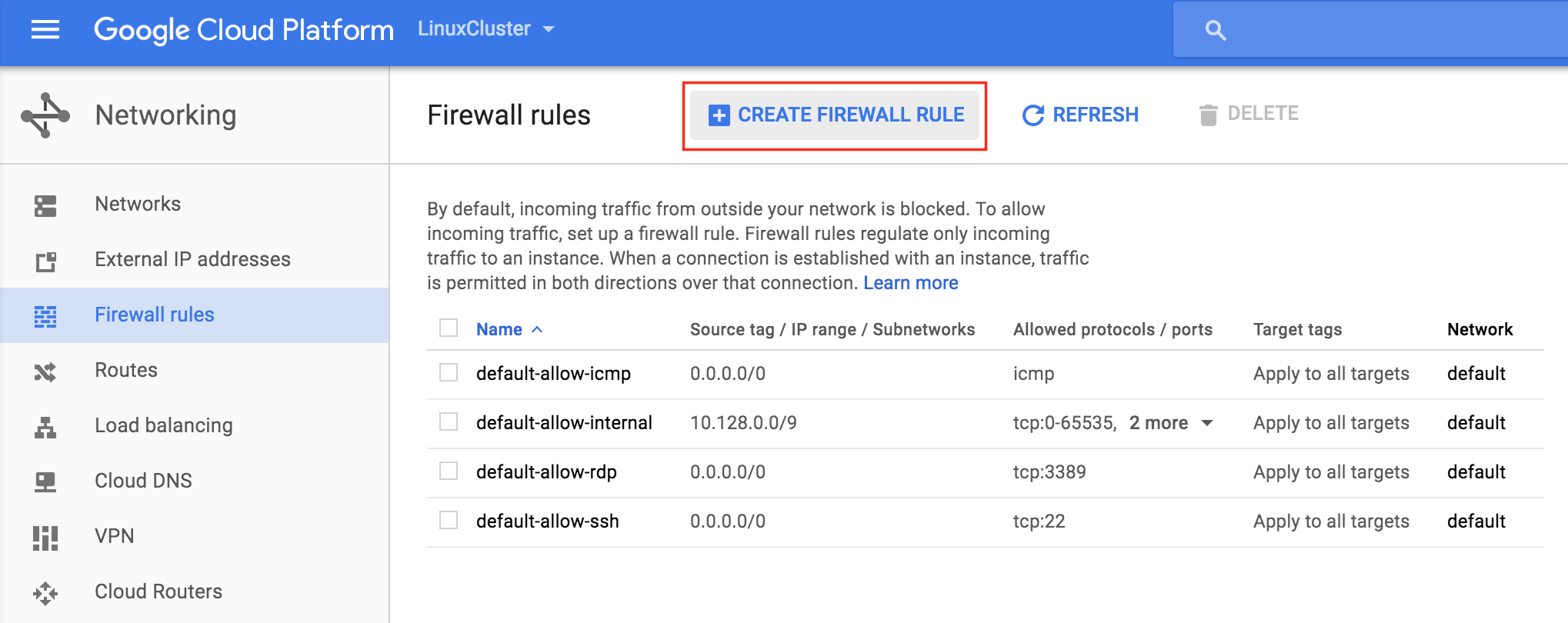
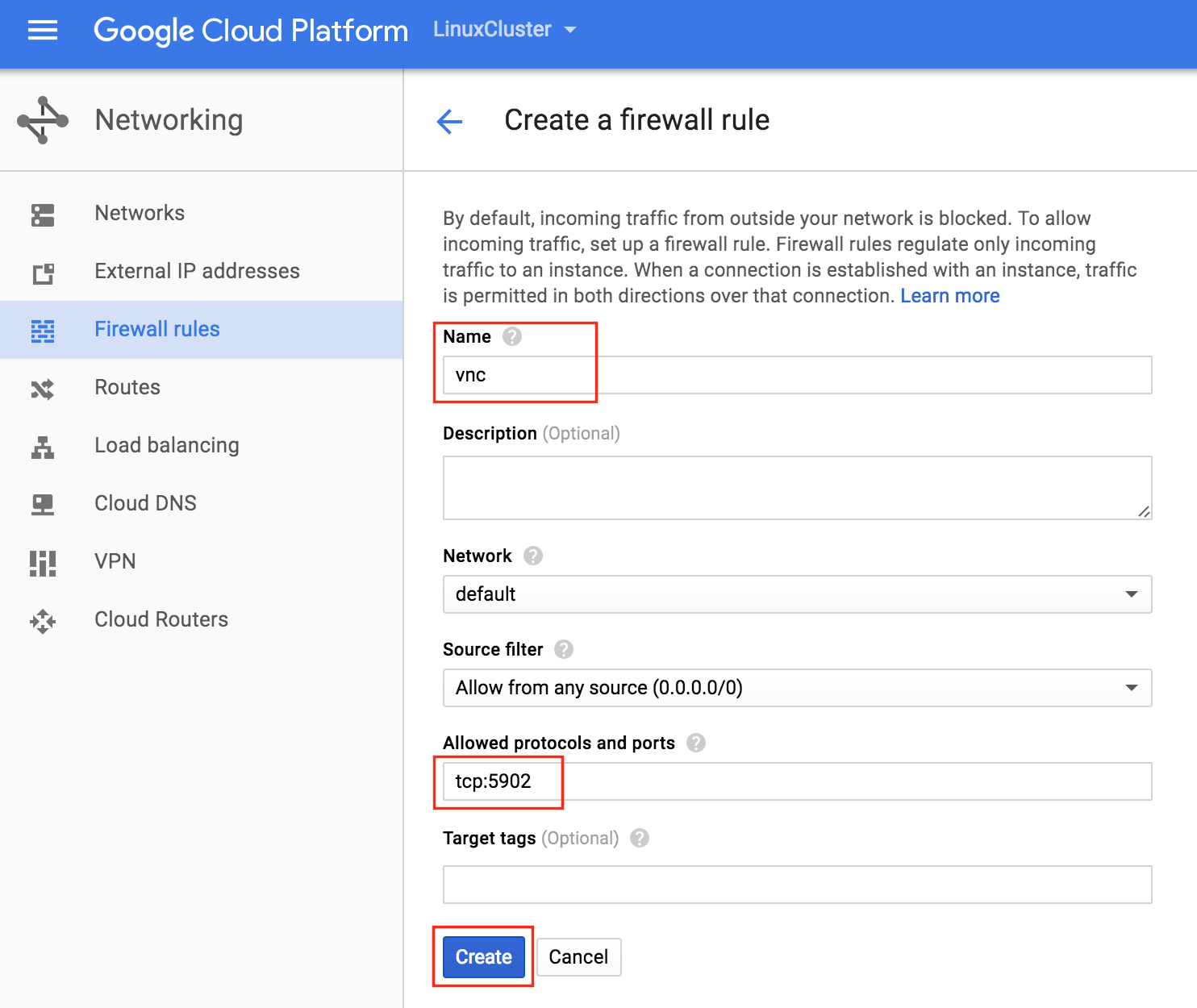
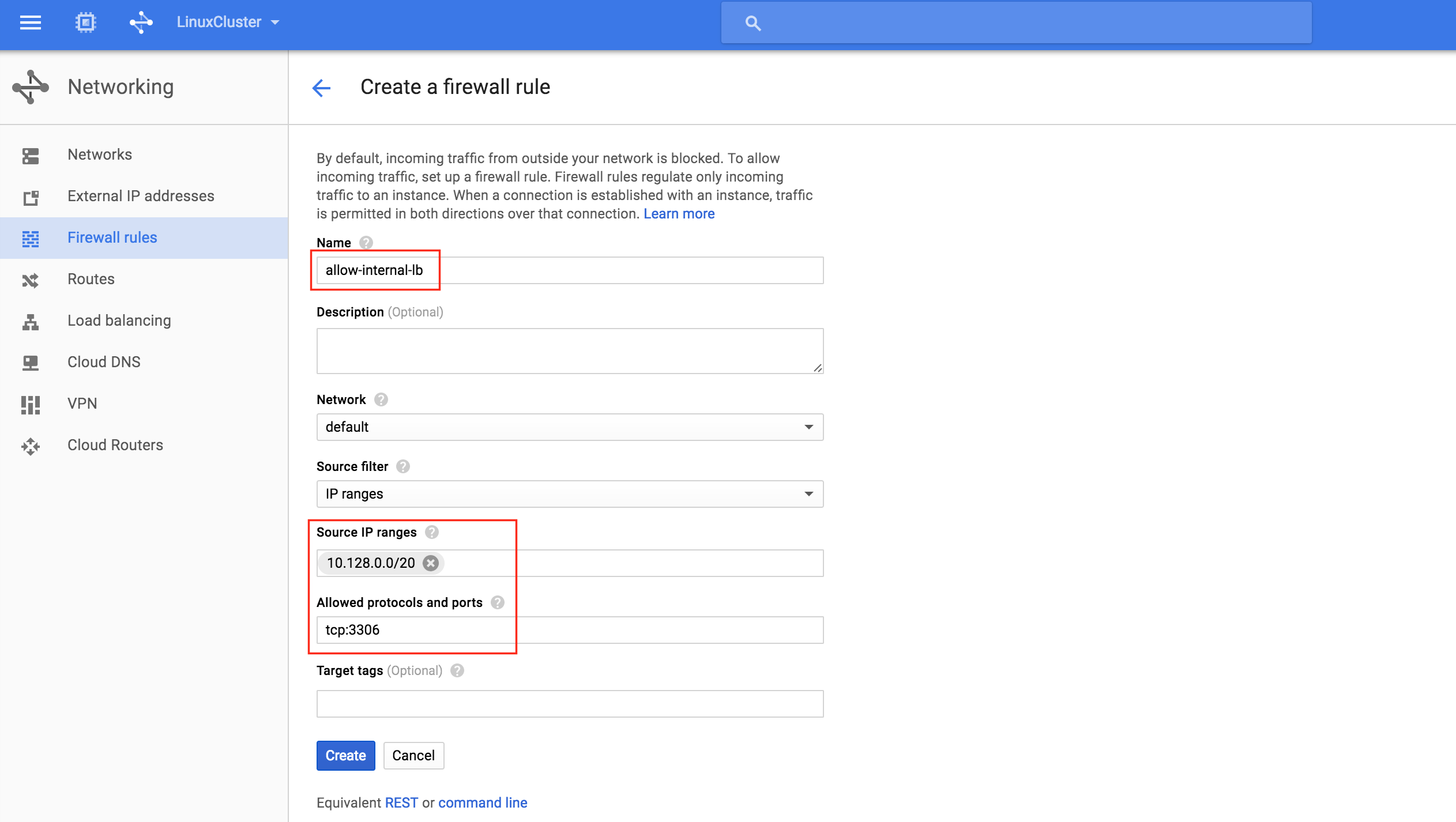
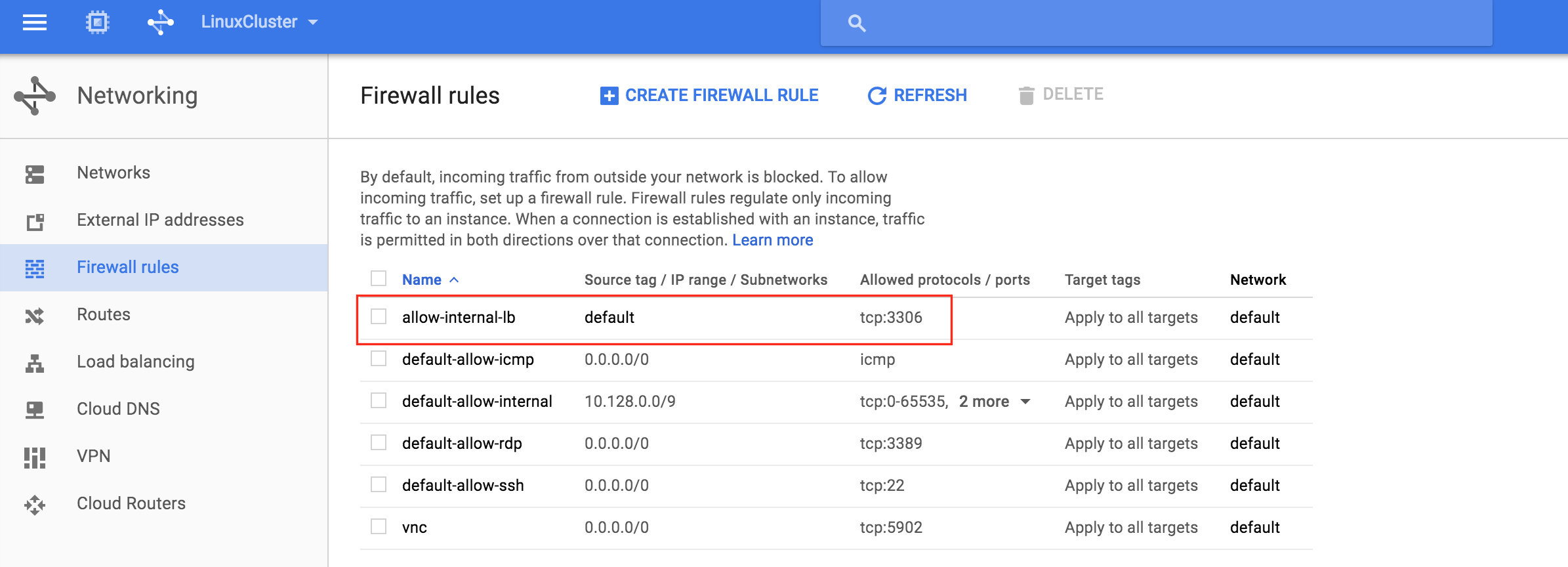
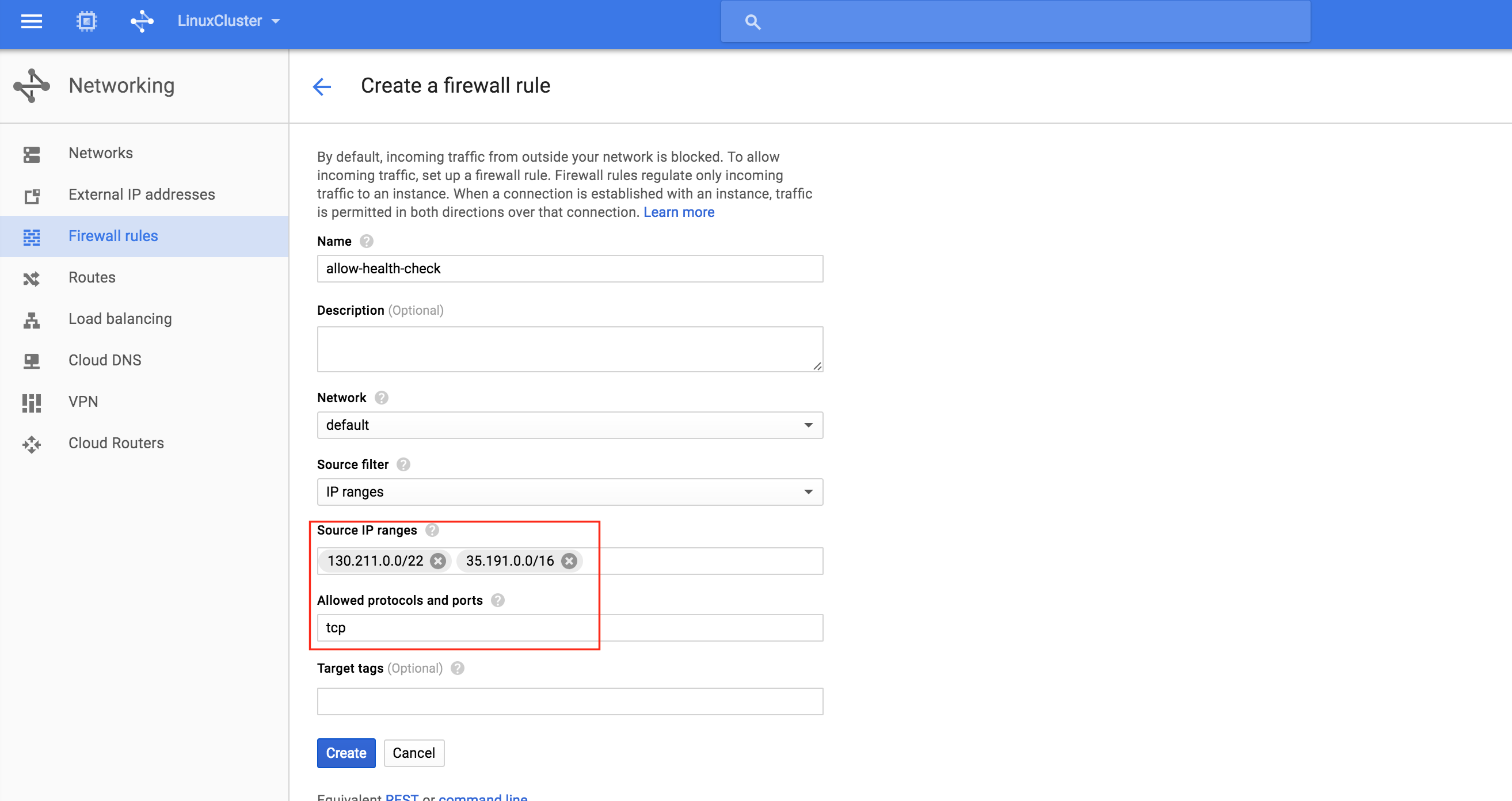
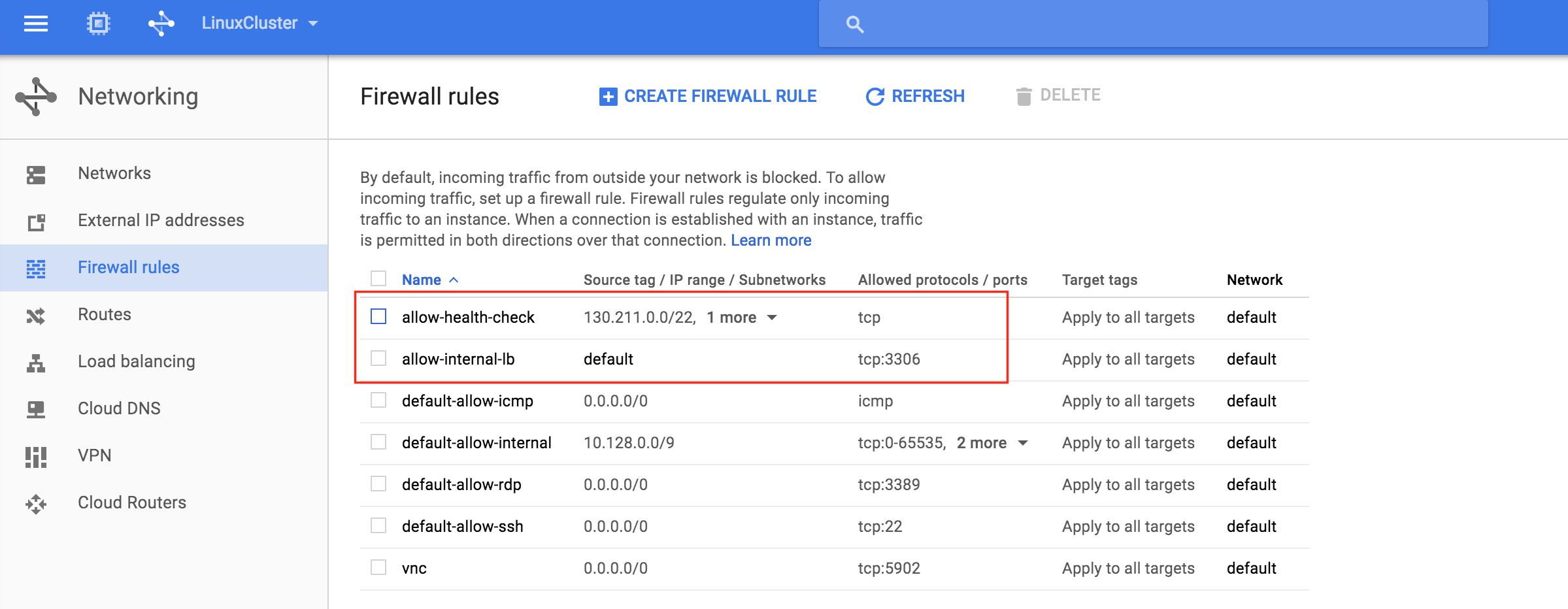
通過混合使用永遠在線的可用性組和SANless SQL Server故障轉移群集實例實現SQL Server高可用性,災難恢復
介紹
將SQL Server故障轉移群集實例(FCI)與Always On Availability Groups(AG)混合的主題已有詳細記錄。但是,大多數可用的文檔文檔配置假定解決方案的SQL Server FCI部分使用共享存儲。如果我想使用Storage Spaces Direct(S2D)構建SANless SQL Server FCI,我還能添加一個SQL Server AG嗎?不幸的是,這個問題的答案是否定的。截至今天,不支持基於S2D的SQL Server FCI和Always On AG的組合。我之前在博客上寫過這個S2D限制。然而,好消息是你可以使用SIOS DataKeeper構建一個SANless SQL Server FCI,並且仍然可以利用Always On AG來處理可讀的輔助數據庫。在混合傳統的基於SAN的SQL Server FCI和Always On AG時,您仍然必須遵守相同的規則,但大多數情況下實現SQL Server的高可用性大致相同。DataKeeper同步複製通常用於同一數據中心或云區域中的節點之間,但您可能希望異步複製到不同區域中的其他節點以進行災難恢復。在這種情況下,如果您在意外故障後必須將DR節點聯機,則必須廢棄Always On AG配置並重新配置它們。此要求與Microsoft在此處發布的有關恢復在VM內運行的SQL Server Always On AG的異步快照的要求非常相似。
可用性組
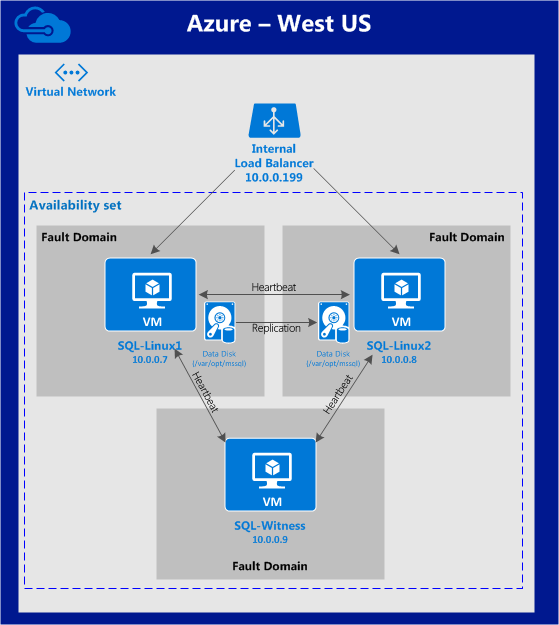
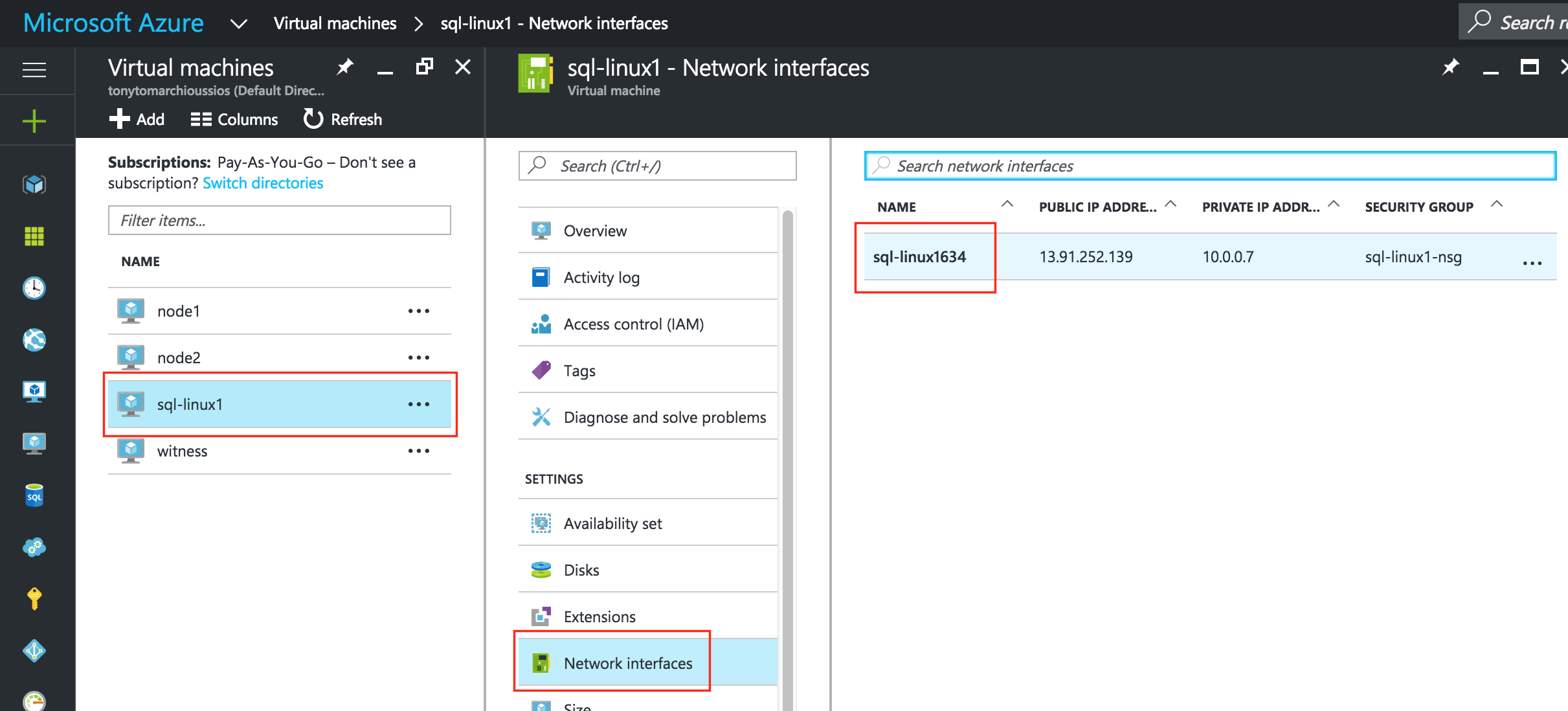
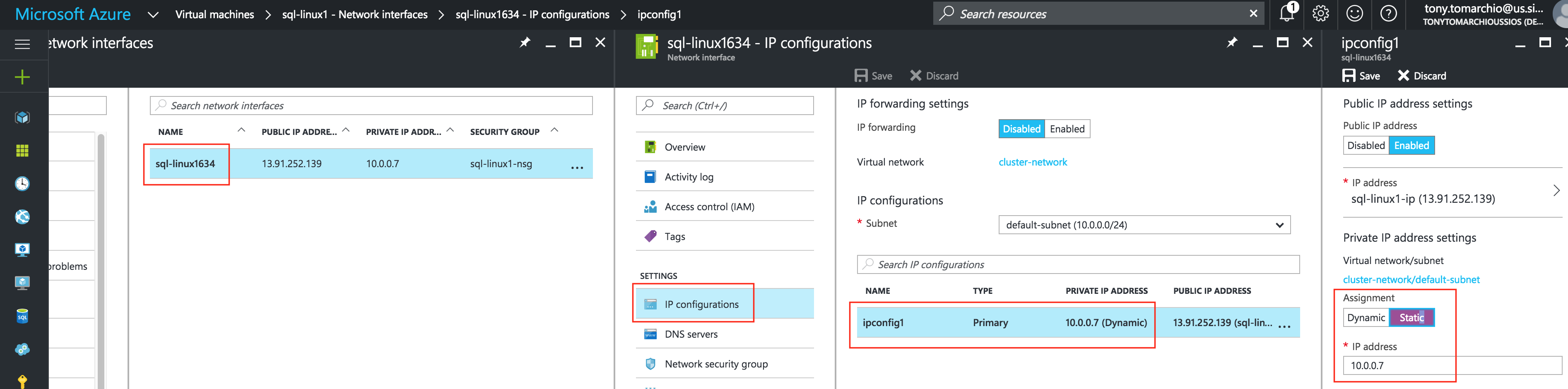
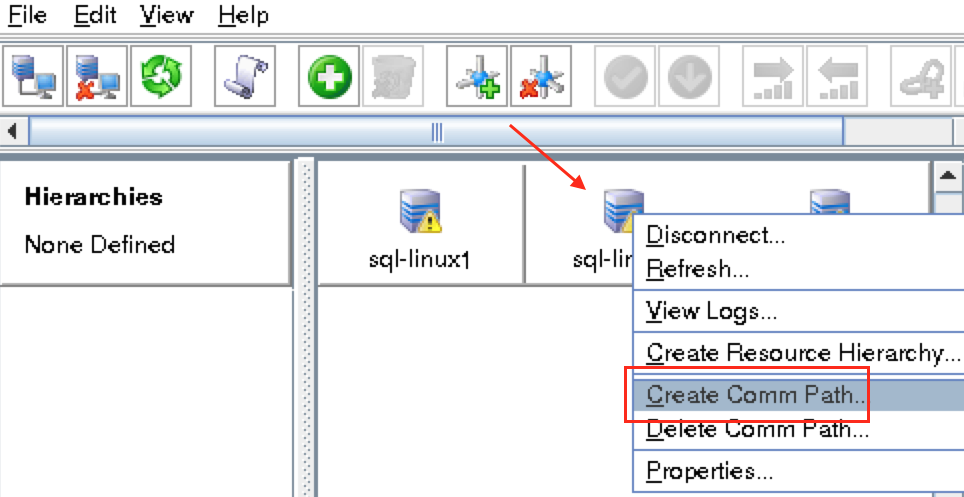
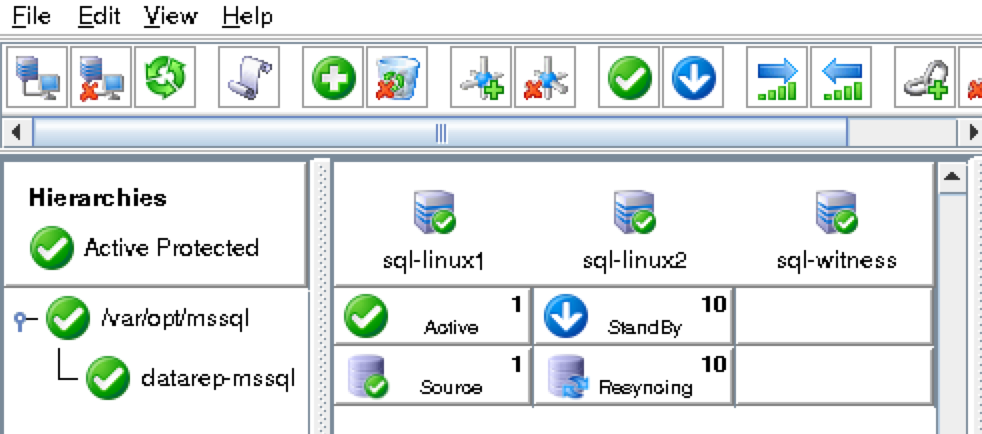
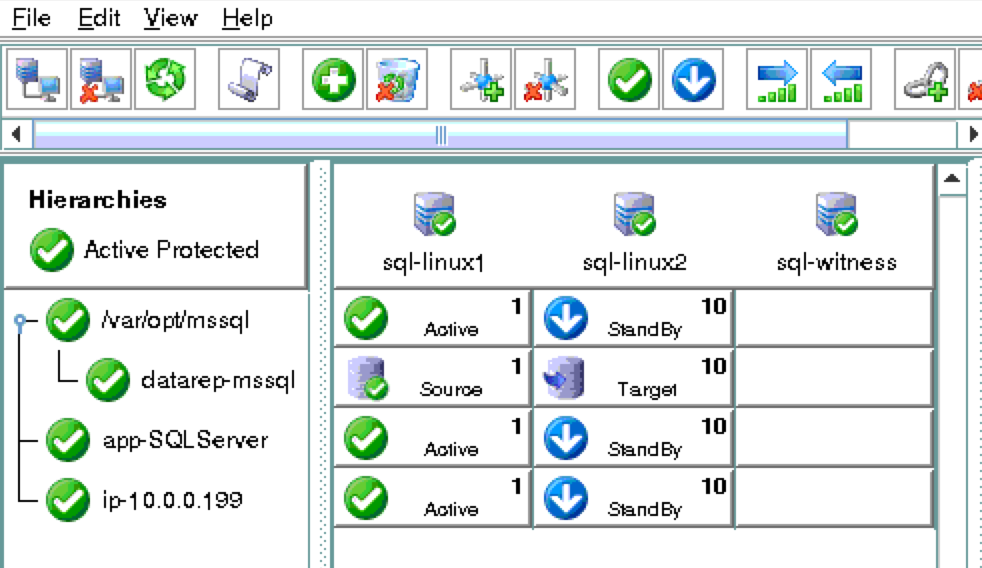
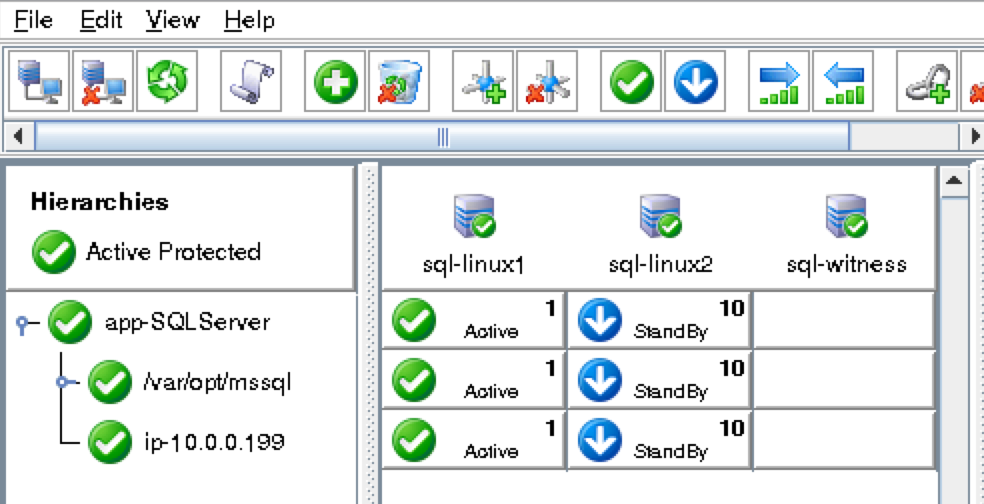
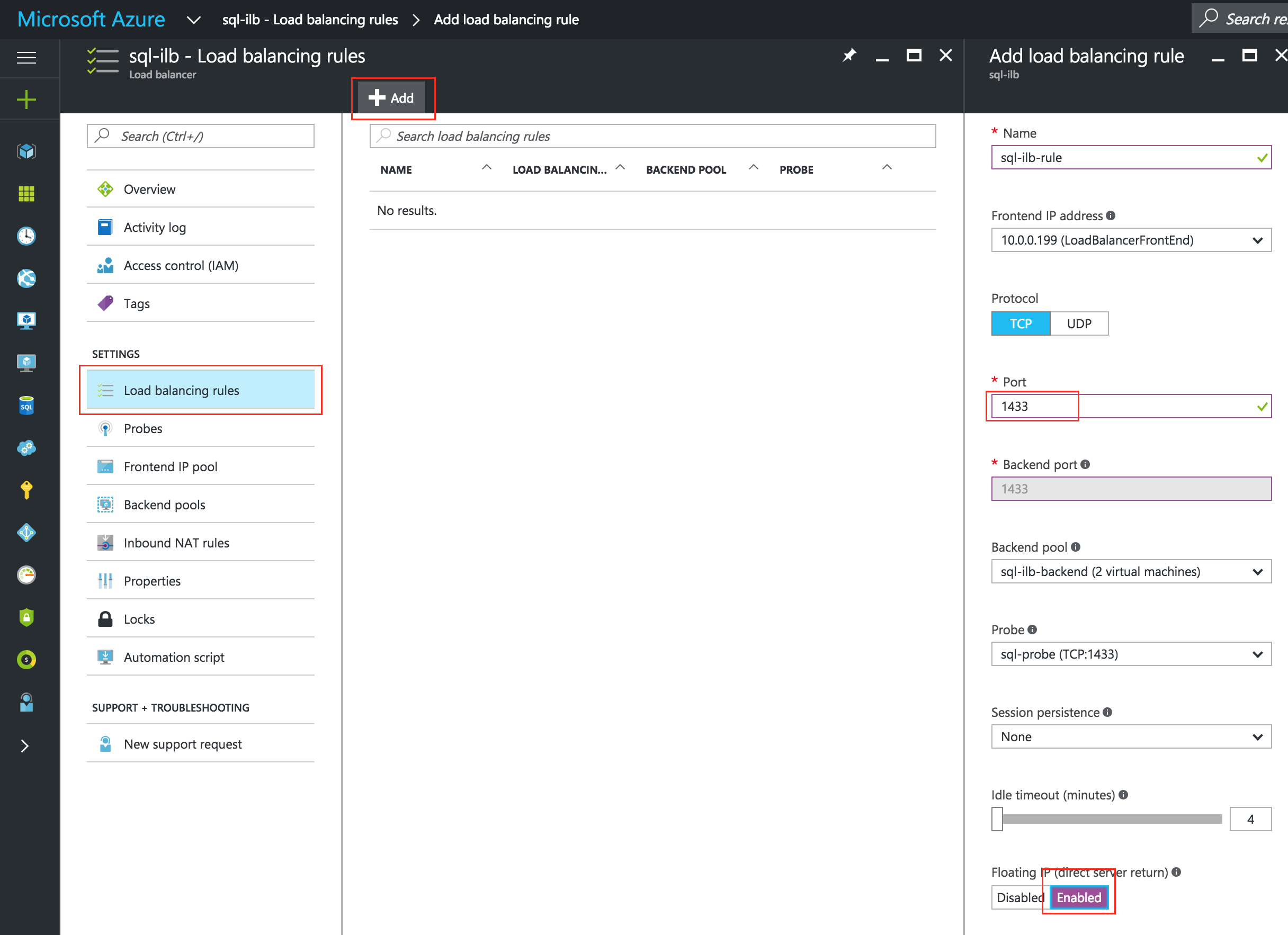
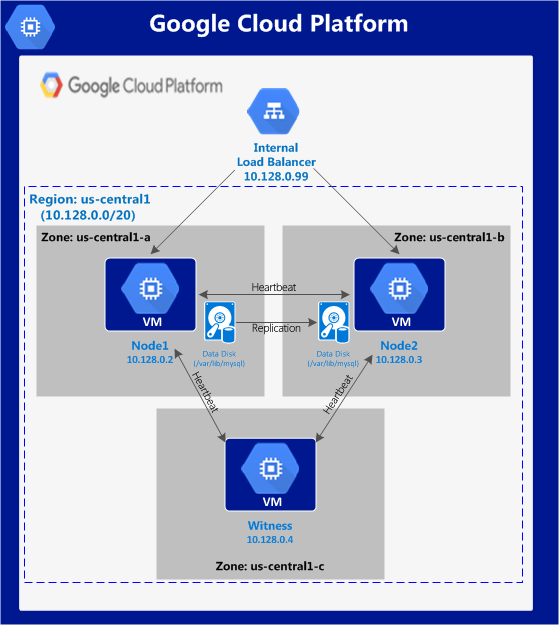
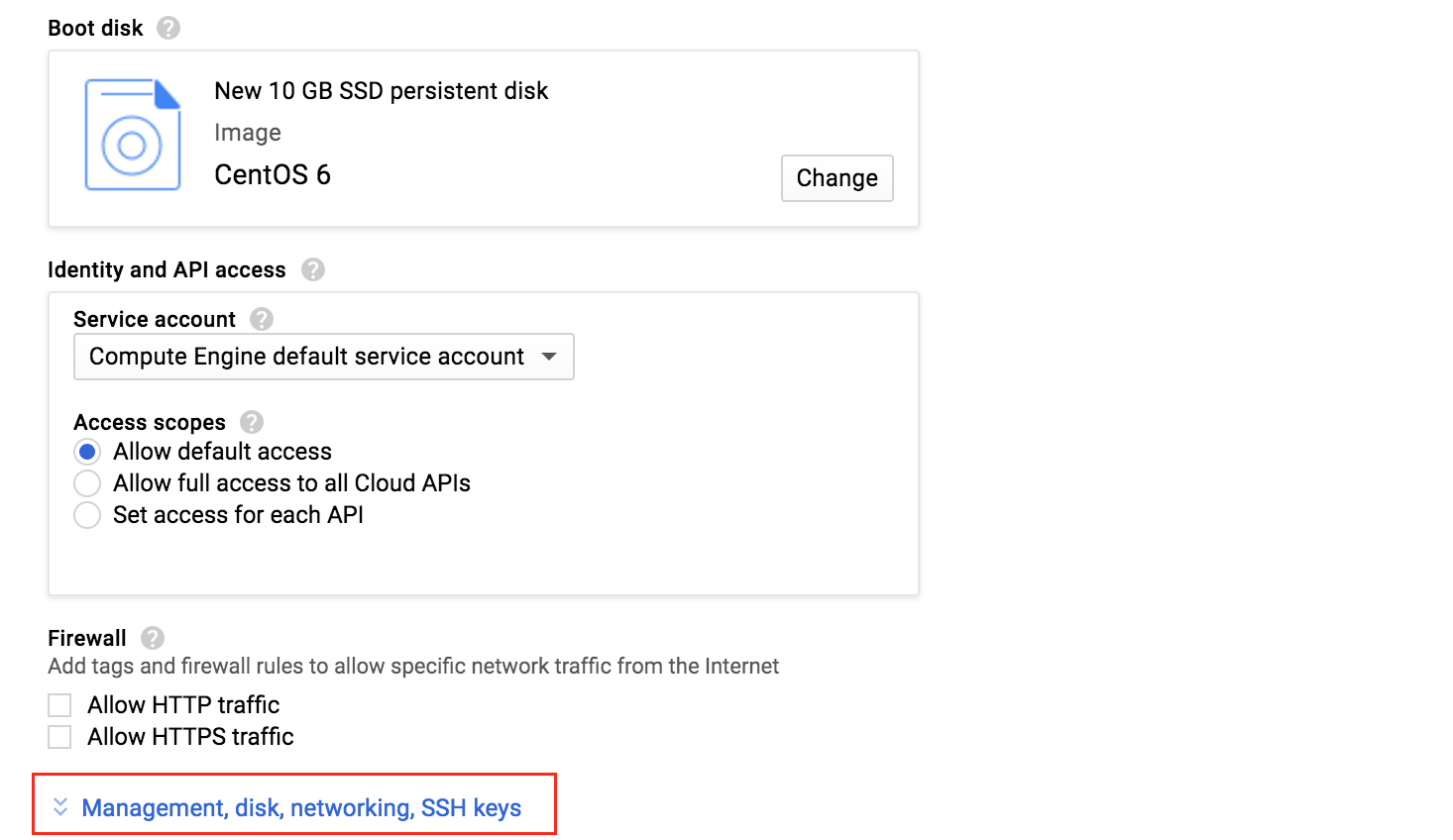
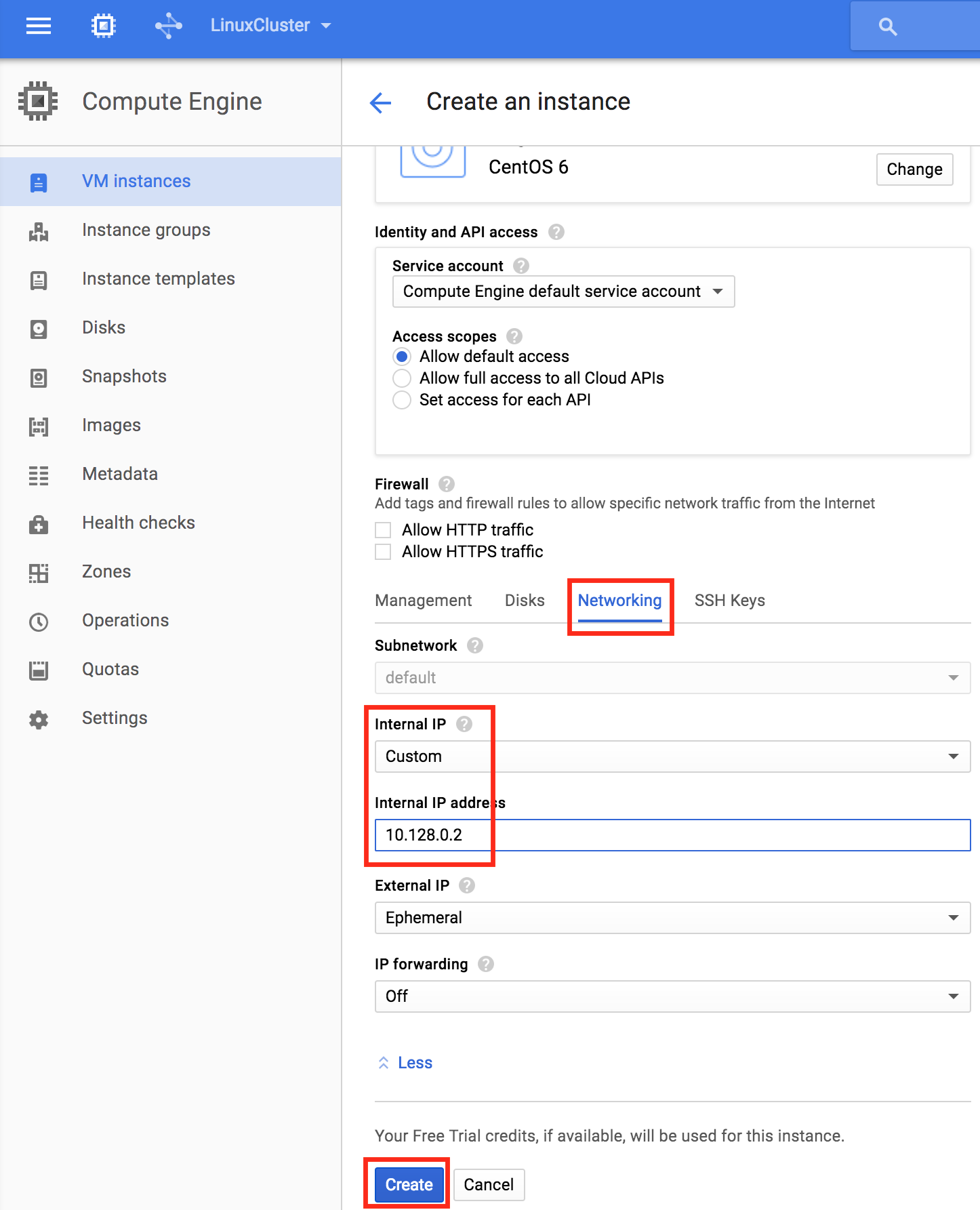
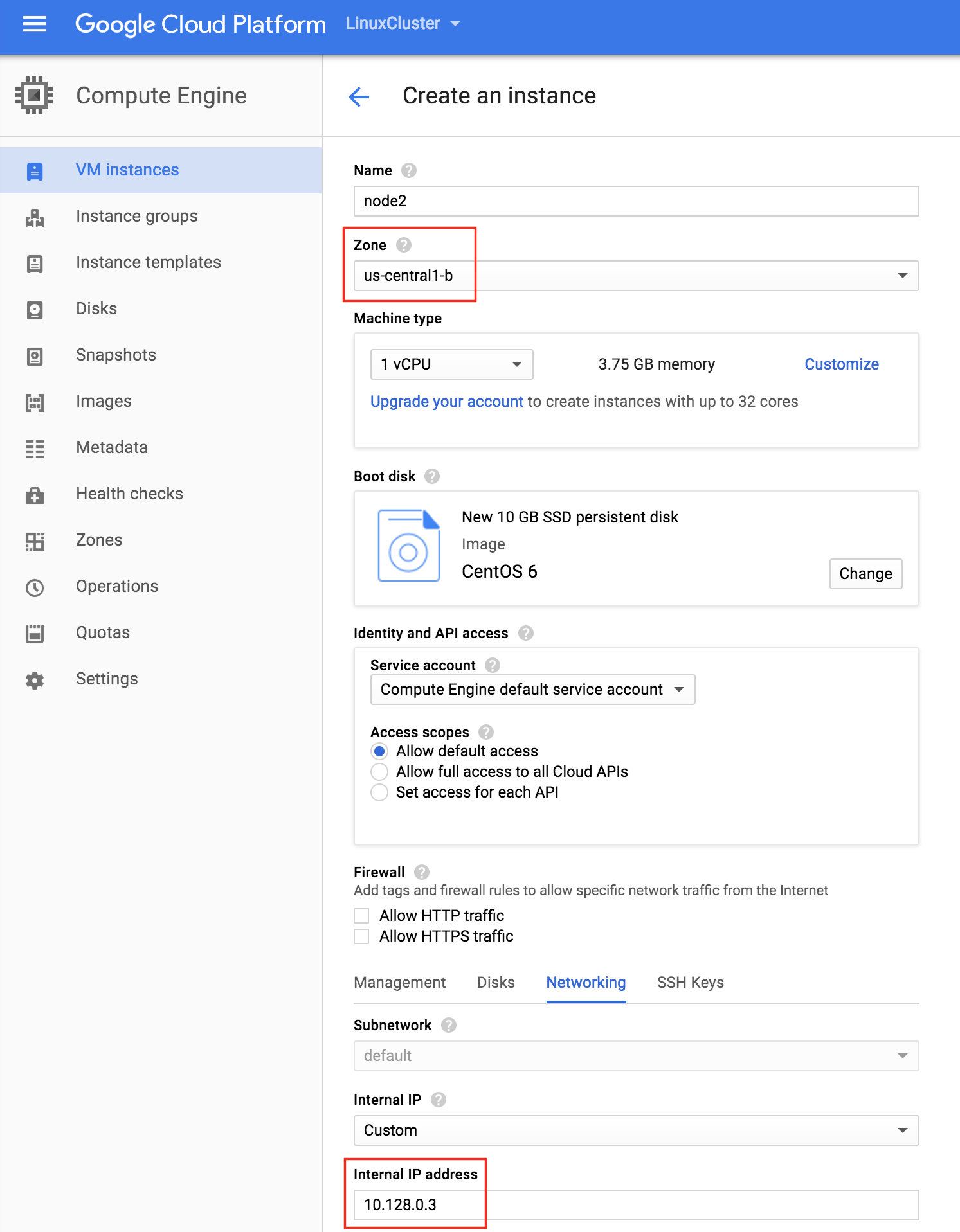
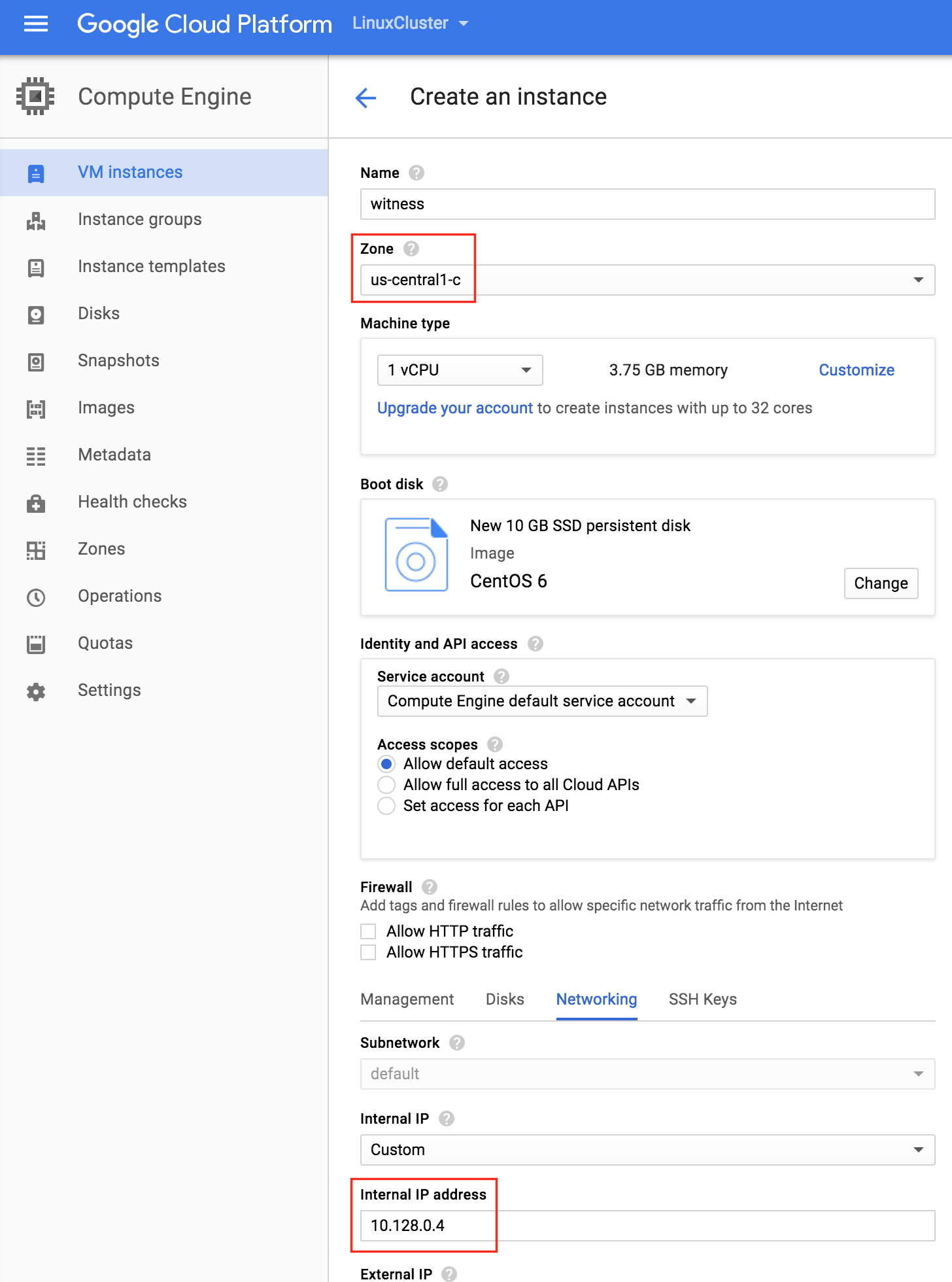
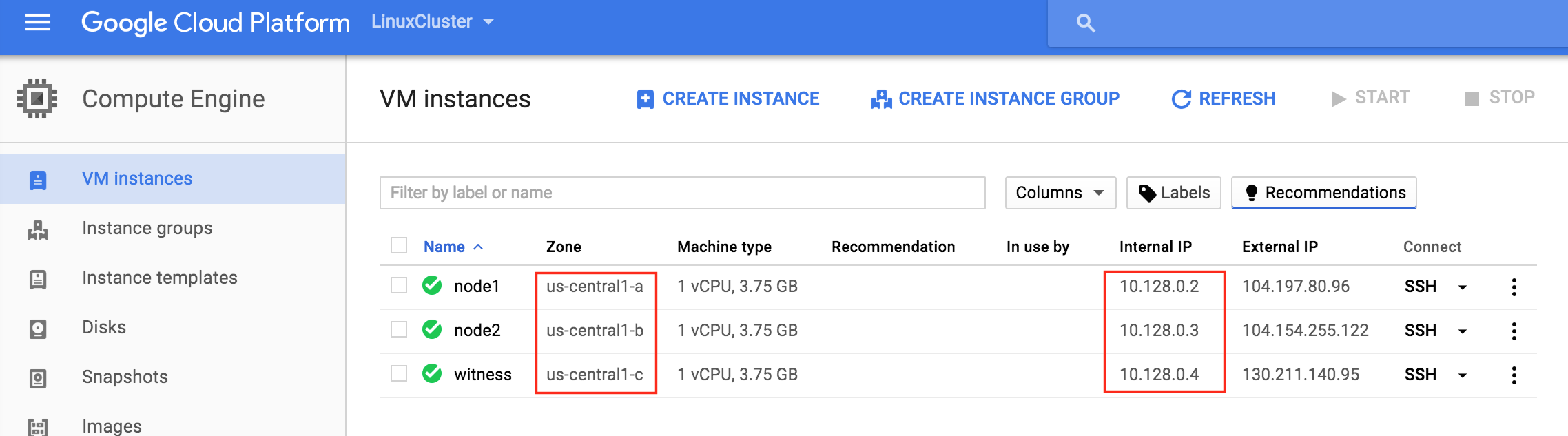
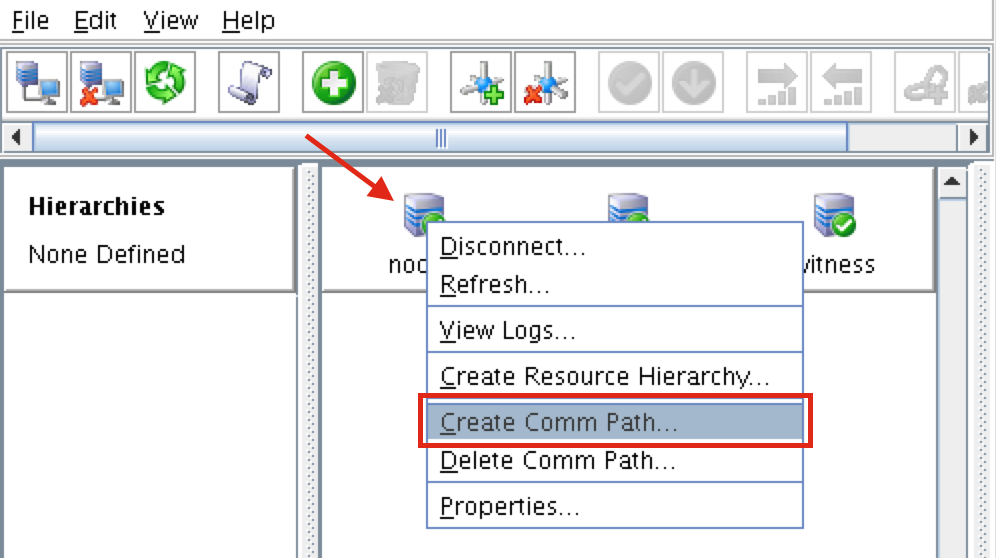
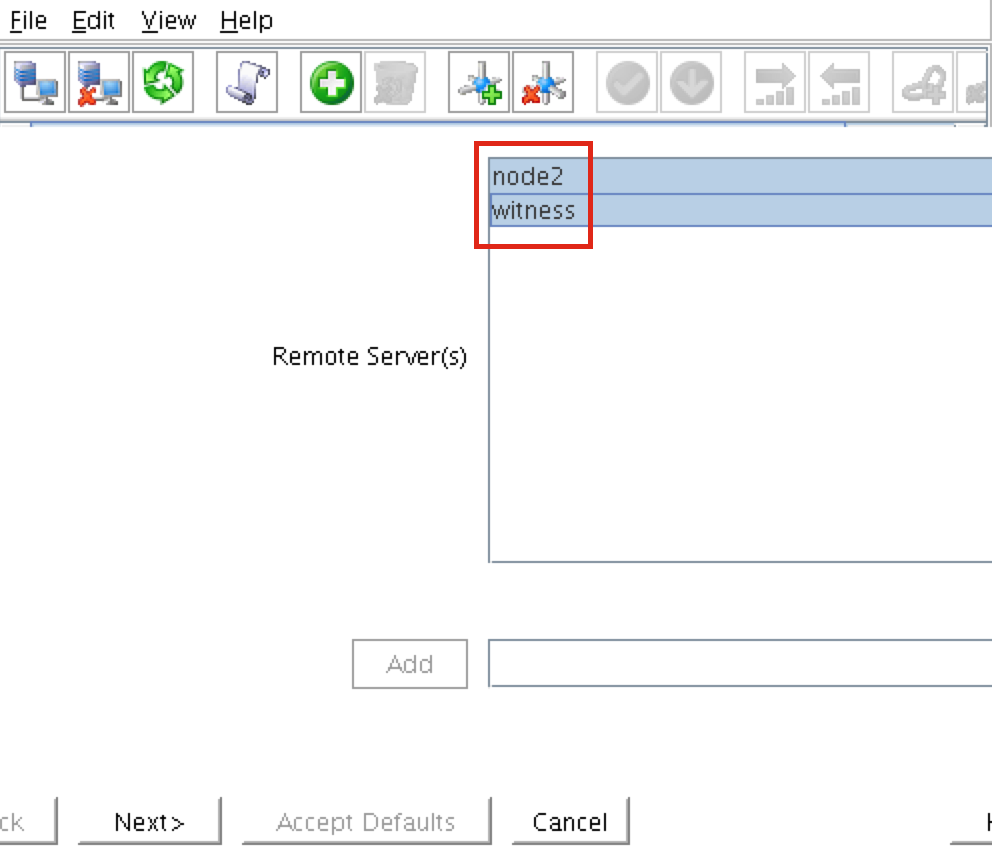
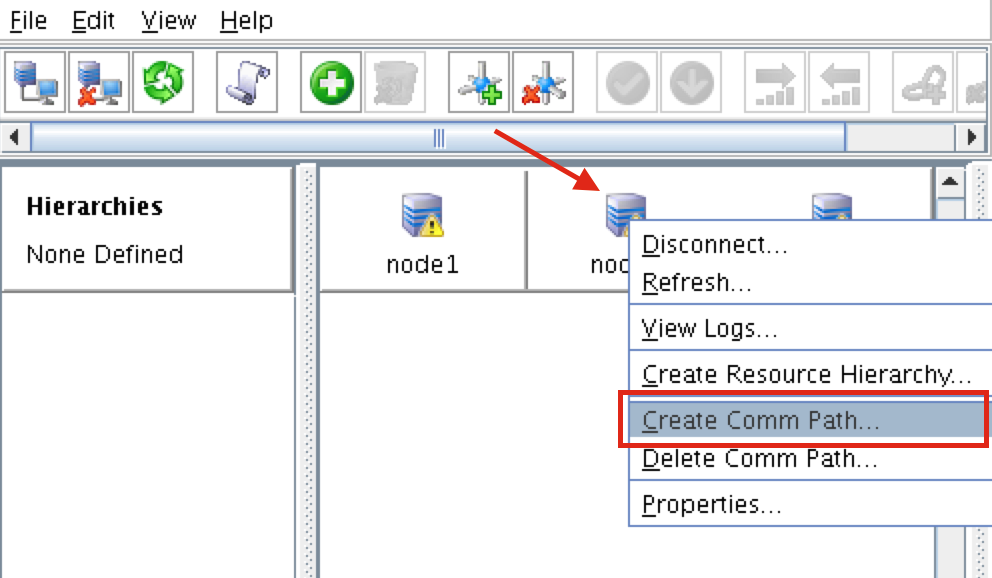
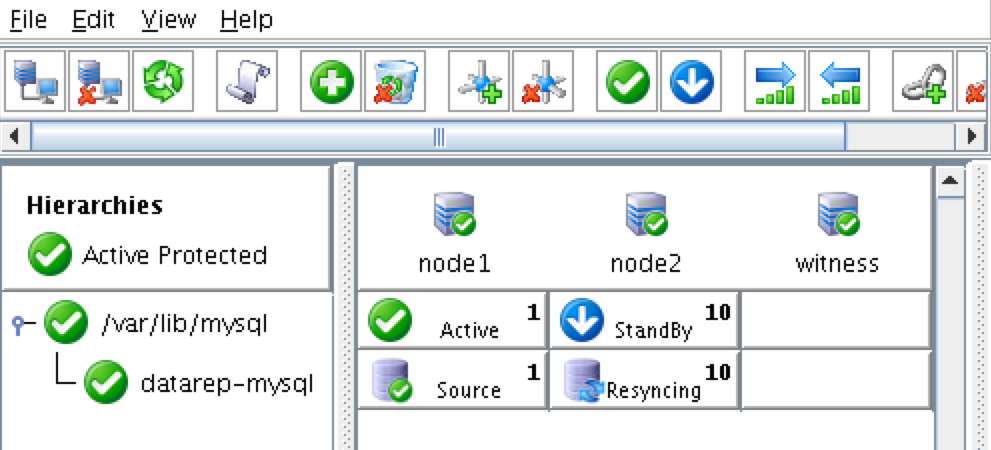
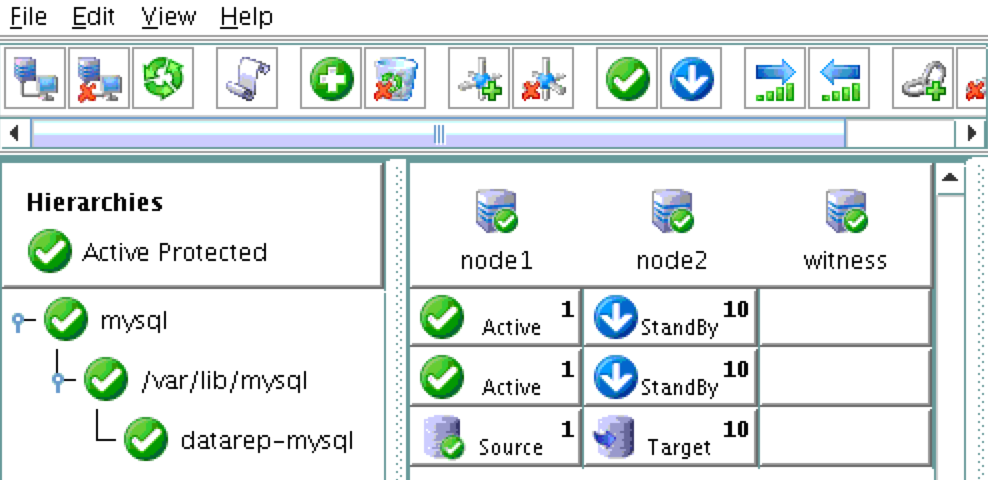
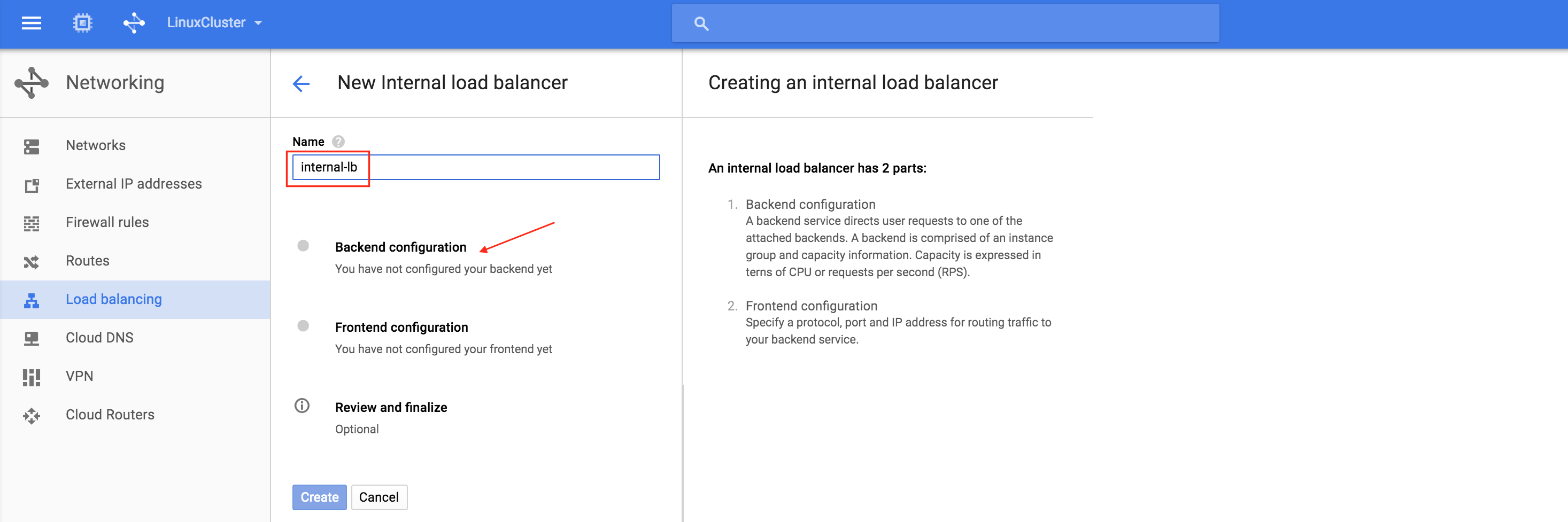
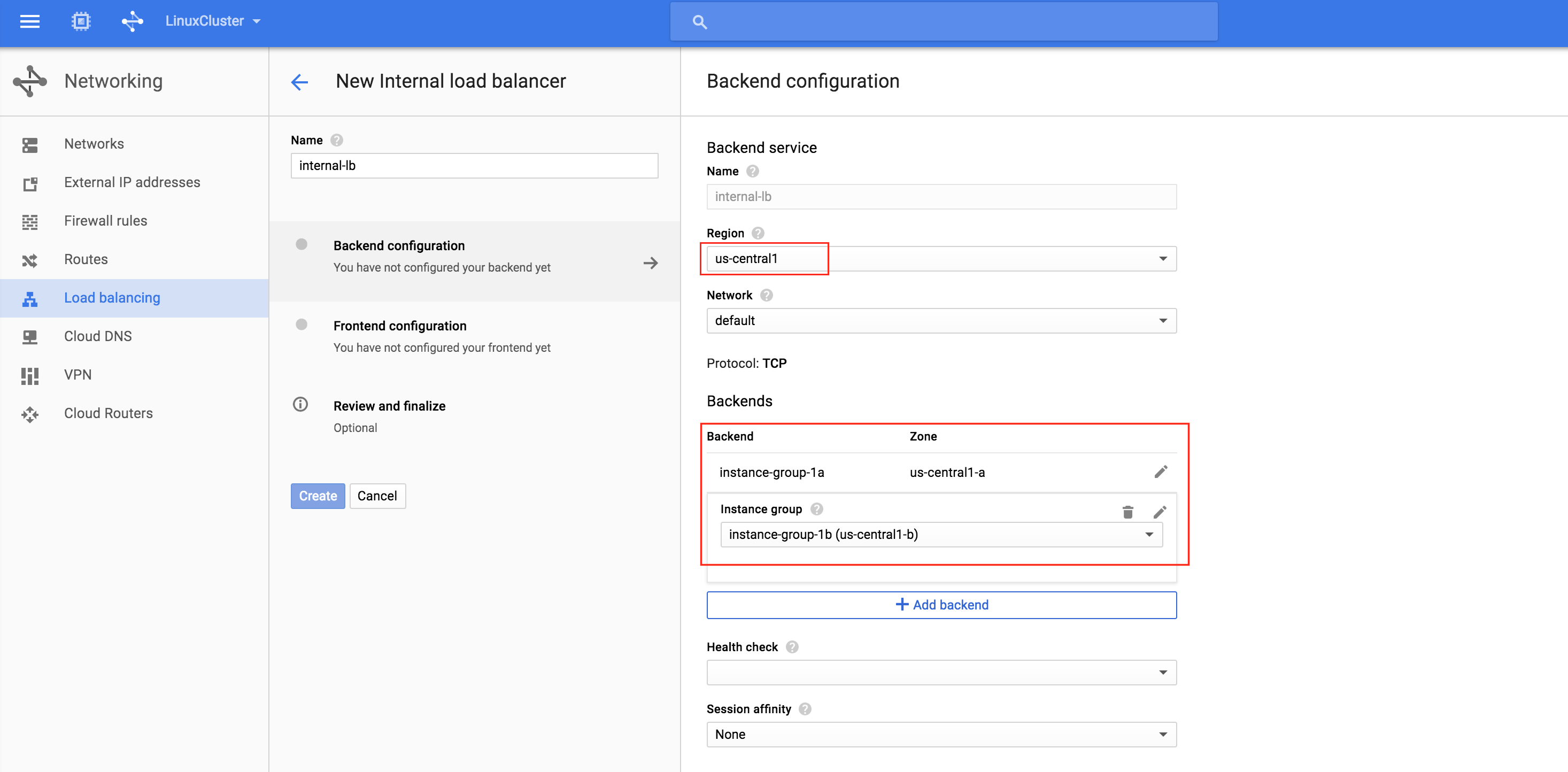
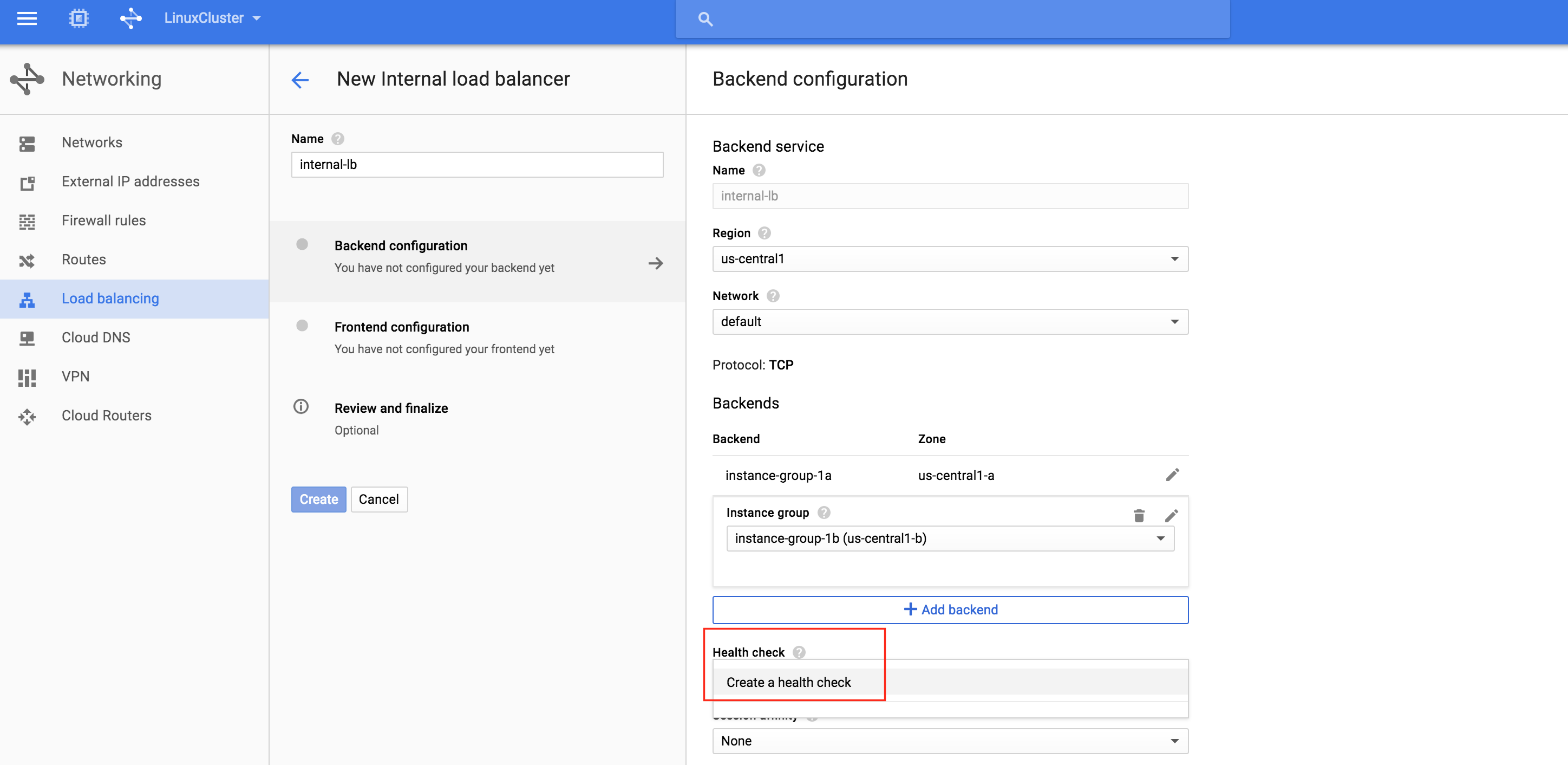
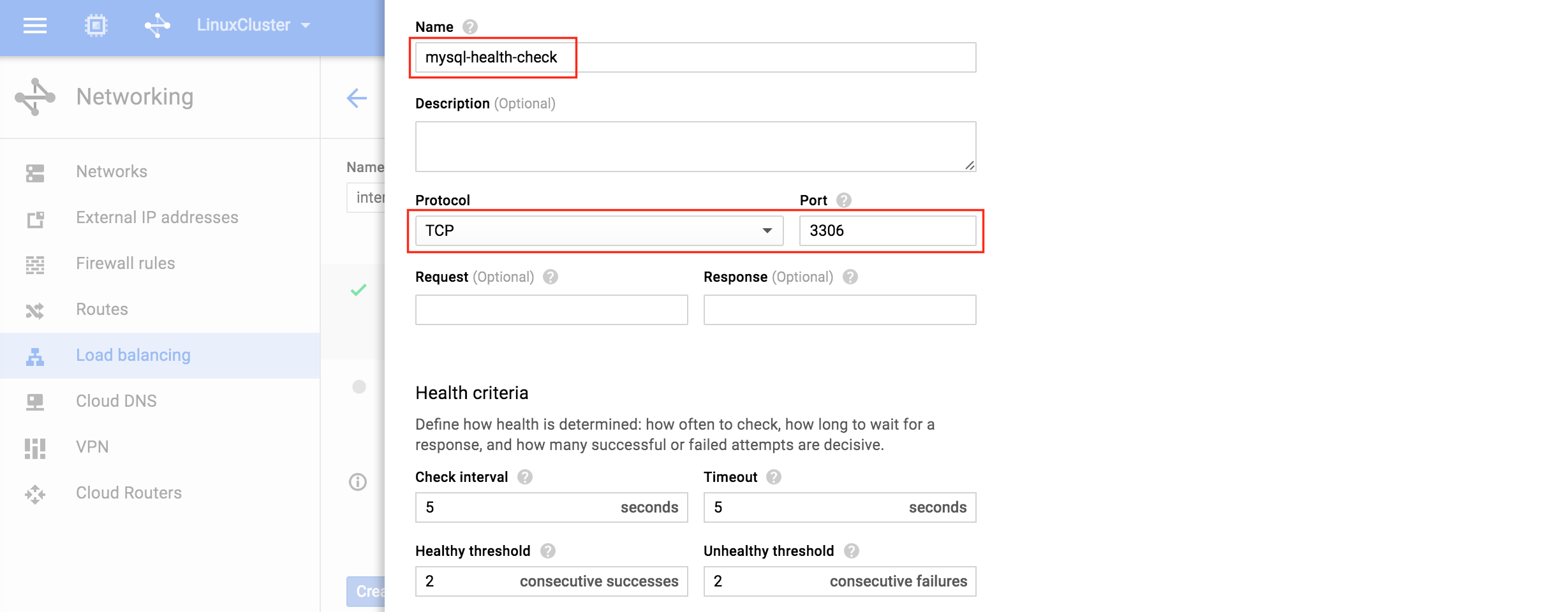
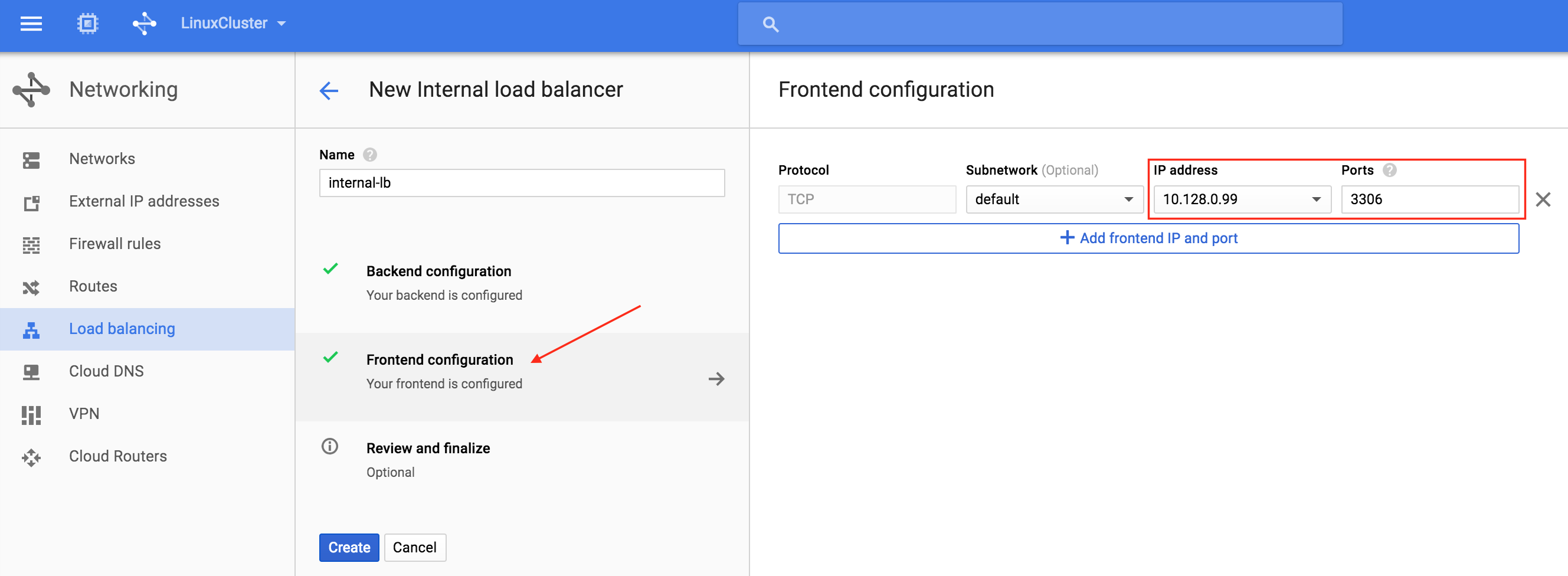
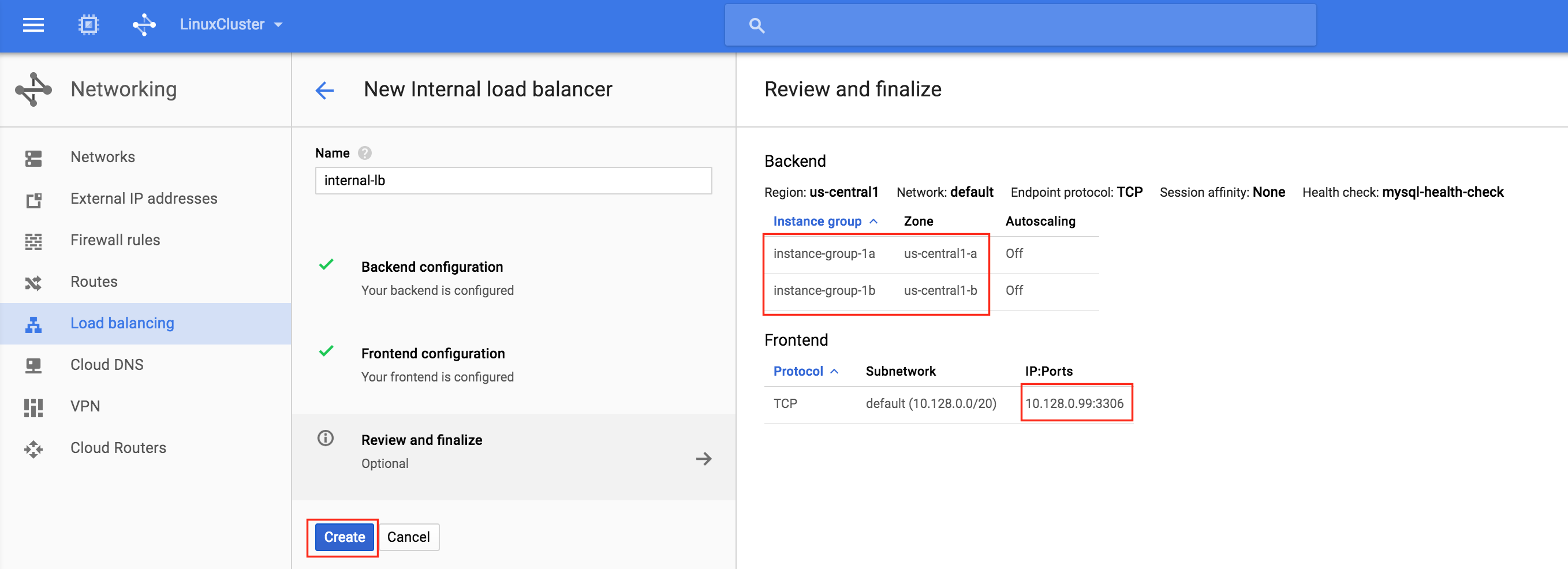
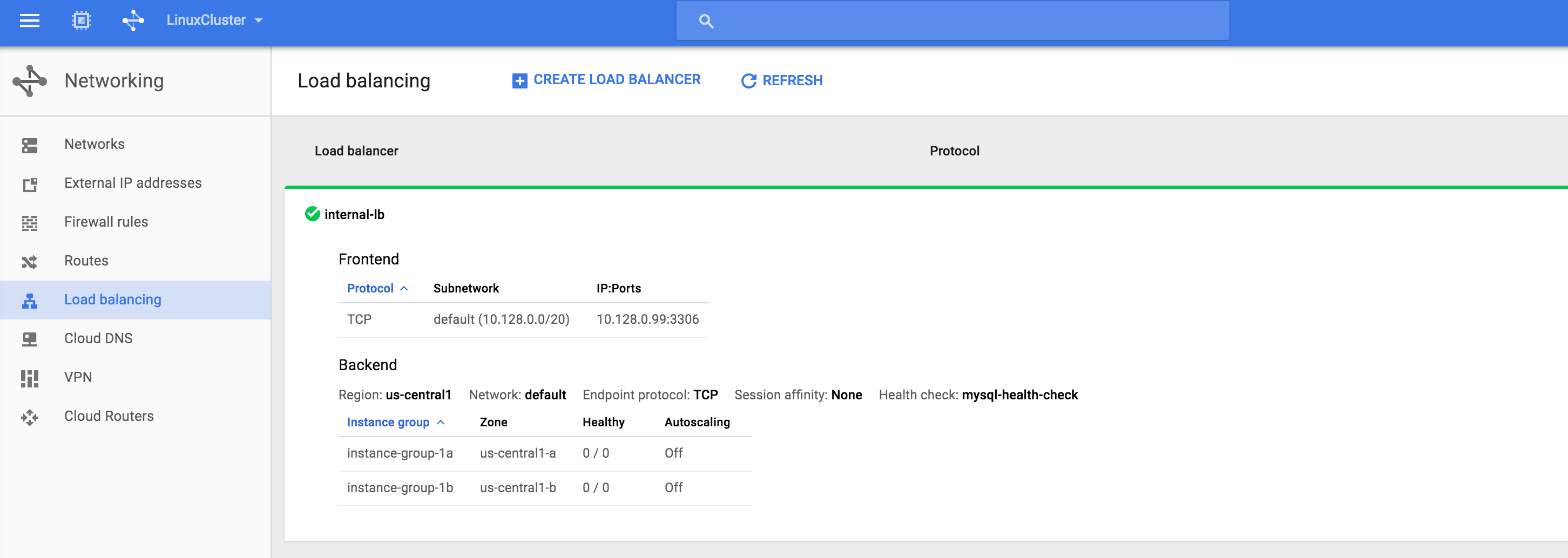
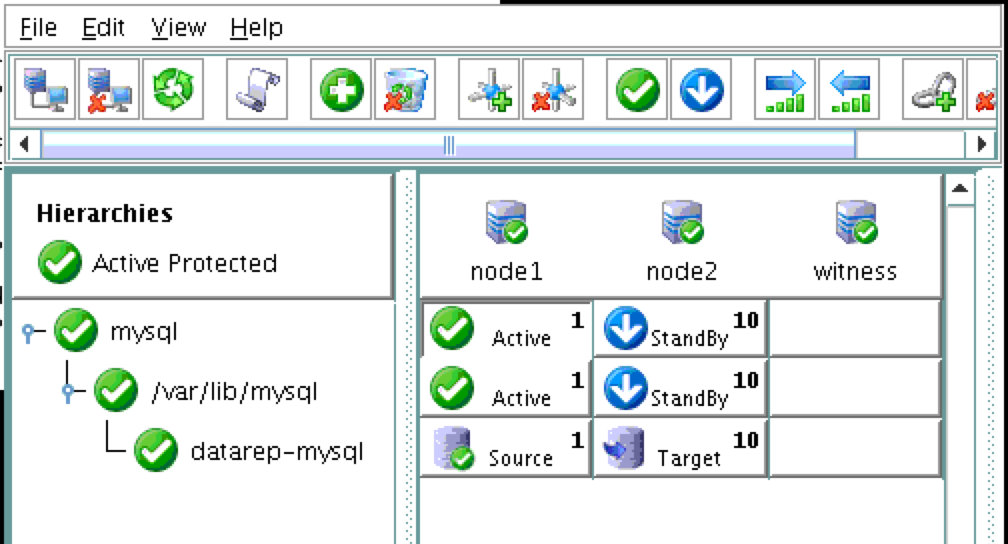
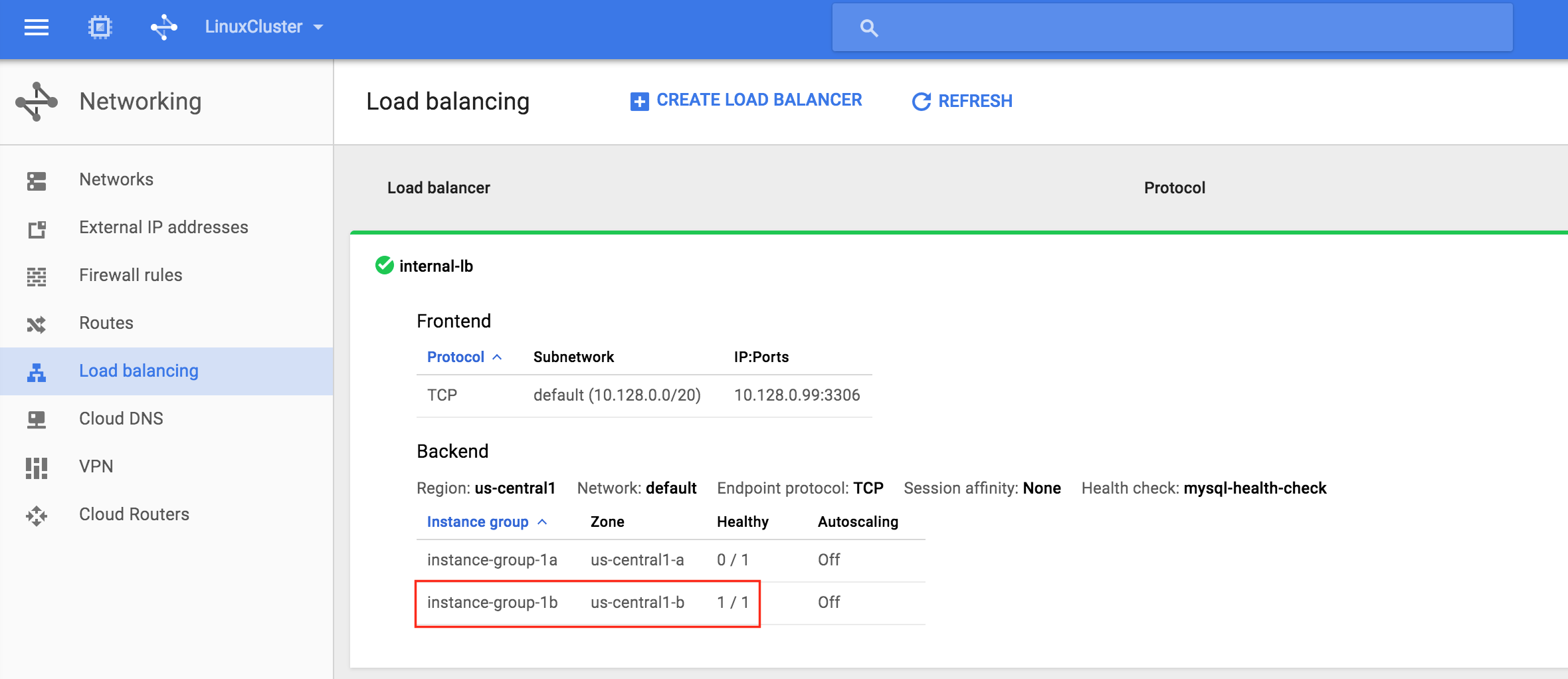
從本質上講,就Always On可用性組嚮導而言,具有DataKeeper的SANLess SQL Server故障轉移群集實例看起來像SQL Server的單個實例。Always On AG的配置與在兩個獨立(非群集)SQL Server實例之間僅創建Always On AG的配置完全相同。真正的困惑在於,在此配置中,所有服務器都駐留在同一故障轉移群集中。但SQL Server FCI僅配置為僅在作為群集SQL Server實例安裝SQL Server的群集節點上運行。其他節點位於同一群集中。但是,SQL在這些節點上安裝為獨立SQL Server實例,而不是群集實例。這有點令人困惑。基本上正在發生的事情是Always On AG利用WSFC仲裁模型和聽眾。因此,所有AG副本都需要駐留在同一個WSFC中,即使它們通常不運行SQL Server的群集實例。如果你完全感到困惑,那麼大多數人在第一次嘗試圍繞這種混合配置時會感到困惑。這樣的配置的真正好處是,在許多情況下,SQL Server故障轉移群集實例可以比Always On AG更好,更具成本效益(在後面的*上更多)高可用性解決方案,但它缺乏提供可讀的輔助副本。添加Always On AG可讀輔助副本成為滿足此需求的可行選項。使用SIOS DataKeeper消除了對SQL Server FCI的SAN的需求,這開闢了配置SQL Server FCI的可能性,其中節點位於不同的數據中心,這也意味著支持跨Azure和ASP.NET中的可用區的SQL Server FCI。AWS。請注意,下圖僅是一種可能的配置。支持多個FCI集群節點,多個AG和多個副本。您只受限於您的SQL Server版本所施加的限制。本文似乎很好地記錄了設置步驟。當然,我將使用SIOS DataKeeper來構建FCI,而不是SQL FCI的共享存儲。
基本可用性組
從SQL Server 2016開始,縮小的“基本可用性組”在SQL Server標準版中可用,即使在SQL Server標準版中也可以進行此配置。基本AG僅限於每個可用性組的單個數據庫,單個副本(2個節點)。但是,它們不支持可讀的輔助副本,因此它們在此混合配置中的用例非常有限。
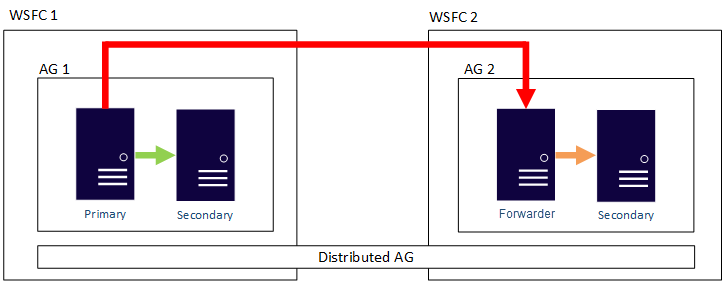
分佈式可用性組
此混合配置也支持SQL Server 2016中引入的分佈式AG。分佈式AG與常規AG非常相似,但副本不需要駐留在同一個集群中,甚至不需要駐留在同一個Windows域中。Microsoft記錄了分佈式可用性組的主要用例,如下所示:
- 災難恢復和更輕鬆的多站點配置
- 遷移到新硬件或配置,可能包括使用新硬件或更改底層操作系統
- 通過跨多個可用性組,在單個可用性組中將可讀副本的數量增加到八個以上
摘要
如果您喜歡SQL Server FCI的SQL Server高可用性的想法,但想要只讀輔助副本的靈活性,這種混合解決方案可能就是您正在尋找的東西。傳統的基於SAN的SQL Server FCI,甚至基於存儲空間直接(S2D)的FCI,都將您限制在單個數據中心。SIOS DataKeeper使您擺脫SAN的限制,並支持跨越可用區域或云區域的SQL Server FCI等配置。它還消除了對SAN的依賴,允許您利用本地連接的高速存儲設備,而無需放棄SQL Server故障轉移群集實例。
*如何省錢
早些時候我答應過,我會告訴你如何通過SQL Server標準版來實現這一切。如果您可以使用基於時間點的快照的可讀副本,則可以完全跳過Always On AG並僅使用SIOS DataKeeper目標端快照功能定期獲取目標服務器上卷的應用程序一致性快照,而不會影響正在進行的複制或可用性。這是如何做…

使用SQL Server Standard Edition創建一個雙節點SQL Server FCI,並在SQL許可證上節省大量資金。然而,仍然會將數據複製到群集外的第3個節點,以用於報告或DR目的。如果您拍攝第三台服務器上的捲快照,則可以直接訪問這些快照。 這樣,您可以從SQL Server的獨立實例安裝這些數據庫以運行月末報告,複製到存檔,或者您甚至可能希望使用這些快照使用最新的SQL快速輕鬆地更新QA和測試/開發環境數據。我希望您找到了創建指南以實現SQL Server高可用性,災難恢復與Always On Availability Groups和SANless SQL Server故障轉移群集實例的混合使用。