什麼是虛擬化可用性選項?
Microsoft Windows Server 2008 R2和vSphere 4.0是最新發布的。 在考慮您的虛擬服務器及其上運行的應用程序的可用性時,我們來看看一些虛擬化可用性選項。
我也將藉此機會介紹一些啟用虛擬機可用性的功能。此外,我已將這些功能歸入其功能角色,以幫助突出其功能。
計劃停機
意外停機
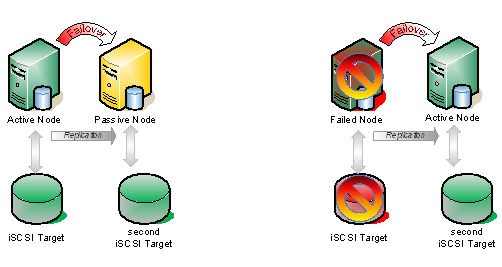
微軟的Windows服務器故障轉移群集和VMware的高可用性(HA)是在發生意外宕機時保護虛擬機的解決方案。兩種解決方案都很相似 他們監視虛擬機的可用性。如果發生故障,VM將移動到備用節點。然後,機器重新啟動以進行此恢復過程。在故障轉移之前沒有時間同步內存。
災難恢復
如果在完全丟失網站的情況下如何恢復我的虛擬機?好消息是虛擬化使這個過程變得更加簡單。虛擬機只是一個可以拾取並移動到另一台服務器的文件。到目前為止,VMware和微軟的可用性特性和功能非常相似。但是,這是微軟真正閃耀的地方。VMware提供Site Recovery Manager,這是一款很好的產品。但僅限於支持SRM認證的基於陣列的複制解決方案。另外,故障轉移和故障恢復過程並不是微不足道的,可以花費更多時間從災難恢復站點返回主要數據中心。它確實有一些很好的功能,如DR測試。 根據我使用Microsoft的災難恢復解決方案的經驗,在災難恢復方面他們有更好的解決方案。
微軟的Hyper-V DR解決方案
Microsoft Hyper-V DR解決方案是多站點群集配置中的Windows Server故障轉移群集(請參閱視頻演示)。在此配置中,性能和行為與局域集群相同,但它可以跨越數據中心。從本質上講,您實際上可以將您的虛擬機跨越數據中心,幾乎沒有可感知的停機時間。故障回復是相同的過程,只需點擊並點擊即可將虛擬機資源移回主數據中心。沒有內置的“DR測試”。儘管我認為最好在一兩分鐘內做一次實際的災難恢復測試,而不會發生意外的停機時間。
基於主機的複制供應商
我還喜歡WSFC多站點群集的另一件事是複制選項不僅包括基於陣列的複制供應商,還包括基於主機的複制供應商。這確實為您提供了各種價格範圍的複制解決方案,並且不需要升級現有的存儲基礎架構。
容錯
容錯功能基本上消除了在出現意外故障的情況下重新啟動虛擬機的需要。VMware在這方面具有優勢,因為它提供了VMware FT。還有一些其他的第三方硬件和軟件供應商也在這個領域發揮作用。實施FT系統時有很多限制和要求。如果您需要確保硬件組件故障導致零宕機時間與在標準HA配置中啟動VM時所需的一兩分鐘時間,這是一個選項。您可能希望確保現有服務器已滿載熱備用CPU,RAM,電源等。你有冗餘的路徑到網絡和存儲。否則,你可能會在糟糕的時候投入很多錢。容錯性對於防止硬件故障非常有用。如果您的應用程序或虛擬機的操作系統表現不佳,會發生什麼情況?這就是當你需要應用程序級集群時,如下所述。
應用可用性
到目前為止,我所討論的所有內容都只考慮了物理服務器和整個虛擬機的健康狀況。這一切都很好,但是,如果你的虛擬機藍屏?或者如果最新的SQL服務包破壞了你的應用程序?在這些情況下,這些解決方案都不會對你有一點幫助。對於那些最關鍵的應用程序,您確實必須在應用程序層進行集群。研究在虛擬機上操作系統內部與管理程序內部運行的群集解決方案。在微軟的世界裡,這意味著MSCS / WSFC或第三方集群解決方案。在虛擬機內進行群集時,您的存儲選項的範圍受到iSCSI目標或基於主機的複制解決方案的限制。 目前,VMware確實沒有解決這個問題的方法。它將遵循在虛擬機內運行的解決方案以進行應用程序層監視。
概要
隨著虛擬化的出現,這實際上不是您是否需要可用性的問題。還有更多關於什麼是虛擬化可用性選項將有助於滿足您的SLA和/或DR要求的問題。我希望這些信息可以幫助您了解可用的可用性選項。
轉載https://clusteringformeremortals.com/2009/08/14/making-sense-of-virtualization-availability-options-2/許可
閱讀我們的成功案例,了解SIOS如何為您提供幫助