如何保護雲平台中的應用程序 – 雲環境的 SANless 集群
經授權轉載西歐
SIOS SANless clusters High-availability Machine Learning monitoring
經授權轉載西歐

除非你一直處於困境或時間凍結,否則你很可能從一個或另一個消息來源聽說雇主和僱員正處於一種被稱為“大辭職”的趨勢之中。據報導美國新聞與世界報導, “根據美國勞工統計局的數據,2021 年 7 月有 400 萬美國人辭職,而且趨勢並未放緩。”無論您的公司規模或當前的收入來源如何,如果還沒有,這種趨勢將在不久的將來影響您的 IT 團隊。是的,讓它沉入其中。負責確保您的關鍵任務應用程序可用性的同一團隊以某種方式容易受到“大辭職”的影響。那麼,你如何識別警告標誌,接受現實,並以同理心和清晰的態度通過“大辭職”,以便它不會對您的關鍵應用程序造成“大災難”?
不要放棄。嚴重地!當同事和好人選擇換工作、職業或以其他方式離開勞動力市場時,辭職可能很誘人。尤其是當您開始考慮用更短的板凳來承載已經很繁重的工作量時。但不要放棄。
當然,識別風險的過程是兩方面的。 辭職後,您的團隊將面臨進一步人事變動的風險。但是,由於容量、技術知識或專業知識的損失,您的高可用性也面臨風險。為了防止您的企業在新團隊辭職後出現計劃外停機,您需要識別關鍵風險領域。一些技術風險包括:
很多時候,當人們開始離開一家公司時,很容易說這是“他們,而不是我們!”我們希望關注他們的問題導致他們離開、辭職或選擇不同職業或工作的所有原因。他們離開的原因很可能完全是個人的,但有時,問題就在鏡子裡,不是他們,而是我們。為什麼弄清楚這是他們的問題還是你對 HA 很重要?好吧,如果問題在於您的公司,例如它的使命、願景、圍繞 HA 和 IT 的文化,或者 IT 和 HA 系統管理的招聘和人員配備問題,那麼簡單地增加額外的員工人數將是一個臨時解決方案。此外,團隊士氣、承諾和知識轉移的風險可能會進一步受到侵蝕,因為重點仍然是責任轉移與問題解決。
在過去的兩年裡,幾乎每家公司都有人退出了他們的團隊。無論他們是尋求更高的薪水、留在家裡照顧家人、退休還是尋求其他選擇,他們都離開了。如果您失去了一名團隊成員,則必須評估剩餘的團隊。該評估在本質上將是技術性的和非技術性的。從技術上講,您需要:一個。 確定當前的技能、能力和知識差距團隊中還剩下哪些技能,技術專長和能力水平如何? 知識差距在哪裡,尤其是理論和實踐之間的差距?
灣。 了解現有和缺失的角色。您的許多團隊成員可能涉及多個角色和職責。失去一個團隊成員實際上可能意味著失去多個角色和職責的覆蓋範圍。
C。 評估即時培訓或增強需求你在哪裡,但需要額外的培訓來穩定和鞏固團隊? 您在哪些領域缺乏可以通過培訓現有人員或某種形式的合同專業服務來緩解的問題?作為客戶體驗副總裁,請親眼目睹這一點。 在失去了負責 HA 環境的關鍵團隊成員後,我們的團隊最近與一家需要專業服務的公司合作。
非技術上,您將需要:一個。 了解剩餘團隊成員的感受甚至在 COVID 大流行和“大辭職”時期之前,許多團隊都在氣喘吁籲地奔跑。 一個 24/7 的 HA 世界留下了很多工作需要處理正常的團隊人數、規範和任務。如果您的團隊受到影響,那麼檢查並聽取剩餘團隊成員的故事與停機生產服務器一樣重要。找出誰精疲力盡、精疲力盡、困惑、瀕臨崩潰,或者相反,誰充滿活力並準備好迎接新的挑戰。 一定要傾聽口頭和非口頭的暗示,同情(不僅僅是失去同事,還有他們的情緒、擔憂和恐懼)。
灣。 了解其餘團隊成員仍在船上的原因了解團隊成員的感受既是技術上的又是非技術上的必要性,但與這項任務幾乎同等重要的是發現他們留下來的理由。當然,有些原因可能會讓您大吃一驚。作者兼演講者 Carey Nieuwhof 表示,一些團隊成員之所以留下來只是因為他們“因為沒有先離開而感到被困在團隊中”。團隊成員留下的其他原因可能不會讓您感到驚訝,但無論出於何種原因,舒適度、機會、薪水、地點、股票期權、激情、團隊合作、文化,您的團隊成員留下的所有原因都很重要。
C。 評估人手不足的影響顯然,前面討論過的人手不足的技術成分;評估技能差距等。但是,人手不足的技術評估有一個推論,那就是非技術性的。請務必評估和評估人手不足(即使只是暫時的)對剩餘團隊成員的心理、情感和個人健康的影響。在我擔任經理的早期職業生涯中,我們的團隊處理了一次裁員事件,該事件使幾名員工情緒脆弱,精神疲憊。這導致這些團隊成員更加疲勞、更多的精神迷霧以及更高的缺陷和錯誤率。如果您的團隊因人手不足而在精神和身體上受到嚴重影響,您的 HA 面臨的風險可能會增加。您的團隊可能正在爭先恐後地收拾殘局,他們可能會迅速團結起來為已辭職的領導或團隊成員提供保障,但您必須了解那些留下來的人是否也筋疲力盡、感到被困或有風險離開。
多年前,一位高管離開了公司。儘管在近一年的過渡期中,他的角色和任務發生了轉變,但仍有一些角色和任務令其餘員工感到驚訝。在今天的辭職浪潮中,您沒有一整年的過渡期。此外,如果您的團隊經歷了不止一次的辭職,那麼您可能還沒有完成第一人的分析和過渡,因此確定最關鍵的任務並確定其優先級並分配責任非常關鍵。 請務必列出以下任務:安全掃描、更新、維護、備份、測試、新應用程序部署、成本分析、鏡像的克隆和重新部署、補丁應用程序和漏洞修復。儘管有損失,這些任務仍然是必要的,如果任其發展,可能會產生毀滅性的影響。
仍然需要涵蓋任務、角色和責任。需要解決關鍵問題。在您重建員工、培訓現有人員並讓您的公司更能適應大辭職的過渡和變化之後,計劃外的停機時間不會等著發生。為了在短期內導航,您需要製定一個明智的、切實可行的短期計劃。該計劃應列出已確定的程序、任務和流程,以便可以繼續進行維護和操作。此外,它應該定義如何在未來動蕩的季節中仔細管理現有的關鍵基礎設施政策。
前面的步驟導致了這一點。通過對當前團隊的評估、關鍵風險的識別以及過渡計劃的到位,下一步就是著眼於未來。 你還有使命。您仍然有需要高度可用的關鍵應用程序。您仍然有需要保護、挖掘、複製並可供您的業務使用的數據。開始為未來的團隊制定計劃。
並非所有關於“大辭職”的消息對您的團隊和 HA 來說都是壞消息。在團隊成員離開前往新的或不同的職位和機會之後,您有一個真實而難得的機會來獲取您評估的所有信息,並將它們轉化為增長和調整的工具以及更美好的 HA 未來。建設這個更光明的未來包括定義所需的職責、角色和技能,更新架構和設計,規劃新員工和服務參與,以及專注於建立更健康的團隊。

對於現代企業來說,停機時間變得比以往任何時候都更加昂貴。 ITIC 2021 年每小時停機成本調查發現,在 91% 的組織中,關鍵業務系統、數據庫或應用程序停機一小時的平均成本超過 300,000 美元,而對於 18% 的大型企業來說,一小時的停機時間超過 500 萬美元。
高可用性(HA) 是系統、數據庫或應用程序的屬性,旨在長時間連續可靠地運行。 HA 的目標是減少或消除關鍵應用程序的計劃外停機時間。 這是通過在關鍵業務系統、數據庫或應用程序的設計中結合冗餘組件和其他技術來消除單點故障來實現的。
服務提供商使用服務級別協議 (SLA) 來保證客戶的關鍵業務系統、數據庫或應用程序在業務需要時啟動並運行。
IDC 創建了一個 SLA 模型,該模型定義了以下五個級別的正常運行時間要求:
據 ITIC 稱,89% 的受訪組織現在要求其關鍵業務系統、數據庫和應用程序具有“四個九”的可用性,其中 35% 的組織進一步努力實現“五個九”的可用性。
除了正常運行時間和可用性之外,另外兩個重要的 HA 指標是恢復時間目標(RTO)和恢復點目標(RPO)。 RTO 是任何中斷的最大可容忍持續時間,RPO 是發生故障時可以容忍的最大數據丟失量。 與通常以小時和天定義的災難恢復 RTO 和 RPO 指標不同,關鍵業務系統、數據庫和應用程序的 RTO 和 RPO 指標通常只有幾秒鐘 (RTO) 和零 (RPO)。
HA 集群通常由服務器節點、存儲和集群軟件組成。
傳統的本地 HA 集群是一組連接到共享存儲(通常是存儲區域網絡或 SAN)的兩個或多個服務器節點,這些節點配置有相同的操作系統、數據庫和應用程序(請參閱圖1 )。
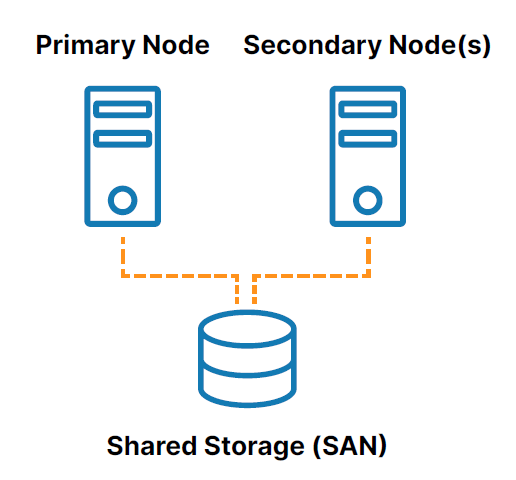
其中一個節點被指定為主(或活動)節點,其他(或多個)被指定為輔助(或備用)節點。 如果主節點發生故障,集群允許系統、數據庫或應用程序自動故障轉移到一個或多個輔助節點,並以最小的中斷繼續運行。 由於輔助節點連接到同一個存儲,因此操作繼續進行,數據丟失為零。
然而,在傳統集群模型中使用共享存儲帶來了一些挑戰,包括:
無 SAN 或“無共享”集群(請參閱圖 2 ) 解決與共享存儲相關的挑戰。 在這些配置中,每個集群節點都有自己的本地存儲。 高效的基於主機的塊級複製用於同步集群節點上的存儲,保持它們相同。 如果發生故障轉移,輔助節點會訪問主節點使用的存儲的相同副本。
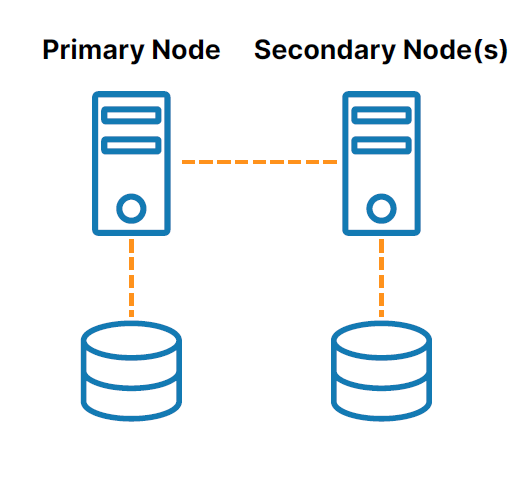
集群軟件允許您將服務器配置為集群,以便多台服務器可以協同工作以提供 HA 並防止數據丟失。 各種集群軟件解決方案可用於 Windows、Linux 發行版和各種虛擬機管理程序。 但是,這些解決方案中的每一個都限制了您的靈活性和部署選項,並帶來了各種挑戰,例如技術複雜性和昂貴的許可費用。
HA 對於關鍵業務系統、數據庫和應用程序至關重要。 但是隨著無數平台的可用,複雜性顯著增加。 這就是為什麼應用程序感知解決方案如此有意義的原因。 您需要的是一個在高可用性方面擁有豐富專業知識的值得信賴的合作夥伴——像 SIOS 這樣的合作夥伴,它擁有確保您的業務保持正常運行的技術知識。
不要等待中斷或災難來確定您是否具備業務所需的彈性。 立即在以下位置安排個性化演示https://us.sios.com了解 SIOS 可以為您的業務做些什麼。
轉載自西歐

故障轉移集群是一種為應用程序提供高可用性保護的方法,它通過在多台服務器上運行相同的操作系統、數據庫和應用程序來消除單點故障,所有這些服務器都共享相同的存儲或連接到持續同步的存儲。 Oracle 在其中一台服務器上運行,稱為主服務器。 如果失敗,應用程序編排軟件(集群軟件)將在稱為故障轉移的過程中將操作轉移到一個或多個輔助服務器。 由於主服務器和遠程服務器訪問相同或相同的存儲,因此 Oracle 操作可以以最少的恢復時間或數據丟失繼續進行。 許多組織將 Oracle 視為其運營的支柱,尤其是當他們使用基於 Oracle 的 SAP 系統或 Oracle ERP 系統時。
Oracle 的集群軟件稱為 Oracle Real Application Clusters (RAC)。 RAC “使您能夠將較小的商用服務器組合到一個集群中,以創建支持關鍵業務應用程序的可擴展環境。”[1]借助 Oracle RAC,您可以對 Oracle 數據庫進行集群並使用 Oracle Clusterware 連接多個服務器,從而使它們作為一個系統運行。
雖然 RAC 以前與 Oracle 數據庫標準版捆綁在一起(不收取額外費用),但 Oracle 現在已從 19c 版的標準版中刪除了 RAC 功能。 您可以通過 Oracle 數據庫企業版支付額外費用購買 Oracle RAC。 不幸的是,這意味著任何想要使用 RAC 的客戶都必須升級到 Oracle Database Enterprise 或遷移到 Oracle 雲,這兩種解決方案都比標準版昂貴得多。
SIOS 無需升級到企業版即可提供高可用性 Oracle 集群解決方案,最多可節省 70% 的許可成本。
這適用於 Linux 的 SIOS 保護套件提供高可用性故障轉移集群、連續應用程序監控、數據複製和可配置恢復策略的緊密集成組合,保護您的 Oracle 數據庫和應用程序免受停機和災難的影響。 與僅監控服務器運行的其他集群解決方案不同,SIOS LifeKeeper 監控服務器、網絡連接、存儲、所有 Oracle 進程和任何相關應用程序的運行狀況。 通過一組策略定義的操作立即糾正問題,確保快速恢復而不會中斷最終用戶。
SIOS 保護套件可以在共享存儲 (SAN) 環境中運行以支持傳統的 HA 集群,或者在雲、混合和其他共享存儲不切實際或不可能的環境中的無共享 (SANless) 存儲配置中運行。 它為您的 Oracle 數據庫和應用程序提供了具有自動和手動故障轉移/故障恢復策略的強大、多功能且易於配置的集群。
適用於 Linux 的 SIOS 保護套件包括:
SIOS LifeKeeper 支持所有主要的 Linux 發行版,包括 Red Hat Enterprise Linux、SUSE Linux Enterprise Server、CentOS 和 Oracle Linux,並適應各種存儲架構。 SIOS 軟件已經過調整和優化,可以在這些操作系統上運行,並且對組件進行了測試,以確保 SANless 集群解決方案可以在每個操作系統上運行。
借助適用於 Linux 的 SIOS 保護套件,您可以在靈活、可擴展的公共雲環境(例如 Amazon Web Services (AWS) 或 Microsoft Azure)中運行您的 Oracle 應用程序,而無需鎖定供應商或犧牲性能、高可用性或災難保護.
適用於 AWS 或 Azure 上的 Linux 的 SIOS 保護套件提供了跨雲故障域和可用區創建高可用性 Linux 集群所需的元素,為您提供地理隔離,以防止站點範圍內和區域性的災難和中斷。
在 Windows Server 故障轉移集群 (WSFC) 環境中,您可以使用 SIOS DataKeeper Cluster Edition 來同步本地存儲,並使用基於主機的高效複製進行 SANless 集群。SIOS DataKeeper 集群版軟件可保護您的業務關鍵型 Windows 環境(包括 Oracle)免於停機和數據丟失。
SIOS SANless 集群軟件為您的 Oracle 數據庫和應用程序在 VMware、Hyper-V、KVM 和 XenServer 環境中運行時提供所需的企業級高可用性、可靠性和靈活性。
適用於 Linux 的 SIOS 保護套件可保護您在虛擬環境中的 Linux 上運行的 Oracle 數據庫和應用程序。 如果您在虛擬環境中在 Windows 上運行 Oracle,SIOS DataKeeper Cluster Edition 可以保護您的業務關鍵型 Windows 環境,包括您的 Oracle 數據庫和應用程序。
SIOS 提供集成的數據複製,高可用性聚類和災難恢復在 Linux 和 Windows 上支持 Oracle 的解決方案可以為小型和大型組織提供容錯保護,而成本僅為其他 Oracle 集群解決方案的一小部分。 使用 SIOS SANless 集群,您不需要昂貴的共享存儲來實現完全的高可用性應用程序和數據庫保護。 相反,您可以在沒有 SAN 的雲中運行您的 Oracle 數據庫和應用程序。此外,SIOS 還可以在本地以及虛擬和混合環境中保護您的 Oracle 數據庫和應用程序。
有關 SIOS 如何保護您的 Oracle 數據庫和應用程序的更多信息,單擊此處或個性化演示.
[1]https://docs.oracle.com/cd/B28359_01/rac.111/b28254/admcon.htm#RACAD7148經授權轉載西歐

您的 SAP 系統是您組織的命脈,如果系統出現故障,您的運營就會停止。 為了支持 SAP 系統的高可用性,您的 IT 團隊可以在集群環境中安裝 SAP。
集群是一組兩個或多個連接的服務器,它們配置有相同的操作系統、數據庫和應用程序。 這些連接的服務器被稱為“節點”。其中一個節點被指定為主節點。 如果主節點發生故障,集群允許您的組織自動將應用程序操作故障轉移到一個或多個輔助節點,從而減少停機時間、消除數據丟失並保持數據完整性。
高可用性 SAP 集群解決方案可用於在 Linux 或 Windows 環境中運行的服務器。
前端應用需求高可用性,即 S/4 HANA,與任何其他依賴於 HANA 的應用程序一樣。
Linux 供應商(例如 SUSE 和 RedHat)為 SAP 提供了幾種開源 HA 解決方案,其中包括 HA 擴展及其“Enterprise for SAP”訂閱。 這些供應商捆綁了開源軟件,您可以使用這些軟件為 HANA 數據庫、ABAP SAP 中央服務 (ASCS)、評估收據結算 (ERS) 和其他 SAP 組件構建高可用性集群。[1]
SUSE HAE(和其他開源集群選項)是高度手動的,只保護單個組件。 例如,將 SUSE HAE 和其他開源解決方案與 SAP 或 SAP HANA 集成可能既耗時又復雜,需要仔細的手動腳本編寫和繁瑣的確認步驟。 創建應用程序感知 HA 解決方案還需要在應用程序和數據庫方面具有特定的深厚專業知識。
SAP 還提供 HANA 系統複製,這是 HANA 軟件附帶的一項功能。 它提供 SAP HANA 數據庫到同一數據中心、遠程站點或云中的輔助位置的持續同步。 數據被複製到輔助站點並預加載到內存中。 發生故障時,輔助站點將接管而無需重新啟動數據庫,這有助於減少恢復時間目標 (RTO)。 不幸的是,必須手動觸發到主節點的故障回复,並發出單獨的命令。 也沒有集成的 HA 故障轉移編排以及 SAP 中央服務等組件。[2]SIOS HA 集群軟件為您的應用程序和數據提供全面的 SAP 認證保護,包括高可用性、數據複製和災難恢復在一個簡單、經濟高效的解決方案中。 SIOS 軟件可讓您在 Windows 或 Linux 環境中保護 SAP,在物理、虛擬、雲(公共、私有和混合)和高性能閃存存儲環境的任意組合中使用您選擇的服務器硬件。 SIOS 軟件易於配置,並提供對整個 SAP 應用程序環境的快速復制、全面監控和保護。 它在共享 (SAN) 存儲或無共享 (SANless) 存儲環境中提供持續的數據可用性。
對於 SAP S/4HANA 和 SAP HANA 數據庫,SIOS 可用於補充 SAP 已經在 HANA 系統複製中所做的工作,以提供完整的自動化高可用性——自動化監控關鍵 SAP HANA 應用程序流程,以及自動化故障轉移和故障恢復。[3]
適用於 Linux 的 SIOS 保護套件提供了高可用性的緊密集成組合故障轉移集群、持續的 SAP 應用程序監控、數據複製和可配置的恢復策略,保護您的 SAP 應用程序免受停機和災難的影響。 雖然 SIOS Protection Suite 可以在 SAN 環境中運行以支持傳統的基於 HA 硬件的集群,但該架構採用無共享的服務器集群方法,使其能夠運行 SANless。 它提供了一個強大、通用且易於配置的解決方案,具有適用於各種應用程序的自動和手動故障轉移/故障恢復策略。
適用於 Linux 的 SIOS 保護套件支持 SAP 集群,如下所示:
ARK 提供特定於應用程序的感知,並將應用程序堆棧連接到上下文中的 HA 解決方案,包括所有相關組件。 例如,SIOS 提供了一個 SAP HANA 應用程序恢復工具包,它提供主機自動故障轉移、存儲複製和系統複製以提高可用性。
最後,借助適用於 Linux 的 SIOS 保護套件,您可以在靈活、可擴展的雲環境(例如 Amazon Web Services (AWS) 和 Azure)中運行關鍵業務應用程序,而不會犧牲性能、高可用性或災難保護。
SIOS DataKeeper Cluster Edition 是一個軟件插件,它與 WSFC 簡單無縫地集成,以添加性能優化的、基於主機的同步或異步複製。 使用 DataKeeper,您可以輕鬆創建無 SAN 集群,為您的 SAP 應用程序實現高可用性和災難恢復,無論是在雲中、在 VMware 等虛擬化環境中運行,還是在僅使用本地存儲的物理服務器上運行。 它增加了高效的複制以同步每個集群節點上的本地存儲,創建一個在 WSFC 看來就像傳統存儲一樣的無 SAN 集群。 有了它,您可以在雲、混合雲中創建 Windows 集群,或者在雲中擴展一個基於 SAN 的傳統本地集群,以實現災難恢復。
使用 SIOS DataKeeper Cluster Edition,您可以實現對關鍵 SAP 組件的高可用性保護,包括 ABAP SAP Central Service (ASCS) 實例、後端數據庫(Microsoft SQL Server、Oracle、DB2、MaxDB、MySQL 和 PostgreSQL)、SAP Central服務實例 (SCS)。
SIOS DataKeeper 不僅消除了 SAN 的成本、複雜性和單點故障風險,還允許您在本地存儲中使用最新的快速 PCIe 閃存和 SSD,以實現單一經濟高效的性能和保護解決方案。
SIOS DataKeeper 還提供SAP 高可用性和雲環境中的災難恢復,例如 Amazon Web Services (AWS)、Microsoft Azure 和 Google Cloud Services,而不會犧牲性能。
如果您的組織不使用 WSFC,SIOS 提供適用於 Windows 的保護套件,其中包括 SIOS DataKeeper、SIOS LifeKeeper 和可選的應用程序恢復工具包 (ARK),用於 SAP 等領先應用程序和基礎設施操作。 它是一個緊密集成的 SAP 集群解決方案,結合了高可用性故障轉移集群、持續應用程序監控、數據複製和可配置的恢復策略,以保護您的業務關鍵型 SAP 應用程序和數據免受停機和災難的影響。
全球各地的組織都使用 SIOS HA 解決方案來保護其 SAP 應用程序,無論是在 Windows 還是 Linux 環境中運行。 這裡只是幾個例子:
有關高可用性 SAP 集群的更多信息,點擊這裡.
參考https://blogs.sap.com/2020/05/03/high-availability-and-dr-for-sap-hana-sap-s-4hana-and-sap-central-services/[1]同上。[2] https://blogs.sap.com/2020/05/03/high-availability-and-dr-for-sap-hana-sap-s-4hana-and-sap-central-services/[3]同上。經授權轉載西歐