
Azure Outage Post-Mortem
關於上週發生的Azure Outage,第一次官方Post-Mortems開始出現在微軟上面。第一個Azure Outage Post-Mortem專門解決Azure DevOps中斷問題(以前稱為Visual Studio Team Service或VSTS)。它為我們提供了一些關於中斷的廣度和深度的額外見解。它證實了停電的原因。它還讓我們深入了解了微軟在快速恢復在線狀態時所面臨的挑戰。此外,它暗示了微軟可能會考慮在未來更好地處理這種情況的一些特性/功能。正如我在上一篇文章中提到的,Azure中推出的新可用區等功能可能會最大限度地減少此次中斷的影響。在驗屍中,微軟確認了我之前所說的內容。
我們正在努力改進處理數據中心故障的主要解決方案是可用區,我們正在探索異步複製的可行性。
其他預防措施
在可用區域跨越更多區域推出唯一的災難恢復選項之前,您需要跨區域,混合雲甚至跨雲異步複製。目前可用的基於軟件的#SANless群集解決方案將實現此類配置。 提供非常強大的RTO和RPO,即使在復制很遠的距離時也是如此。借助SaaS / PaaS解決方案,您可以依靠雲服務提供商(CSP)來實施具有鐵的HA / DR解決方案。在這種情況下,似乎有一個非常重要的缺陷暴露。我們只能希望它能引導所有CSP仔細研究他們的SaaS / PaaS產品。以及解決可能存在的任何HA / DR差距。在此之前,消費者有責任了解風險。他們需要盡其所能來降低延長中斷的風險,或者只是在風險得到解決之前選擇不使用PaaS / SaaS。
RTO還是RPO?
驗屍確實是問題的根源……你更重視什麼,RTO或RPO?
我從根本上不想為客戶決定是否接受數據丟失。我有客戶告訴我他們會花費數據丟失來讓一個大型團隊再次快速生產,其他客戶告訴我他們不希望任何數據丟失,並且等待恢復時間不長。
CSP不可能為客戶做出決定。CSP不希望丟失客戶數據,除非原始數據完全丟失且無法恢復。在這種情況下,近乎實時的異步副本與您在意外故障中獲得的RPO一樣好。然而,這次停電是否真的出乎意料而且沒有任何警告?現代衛星圖像和天氣預報的改進給予了公平的警告,該地區將發生重大的天氣相關事件。當我寫這篇文章時,颶風佛羅倫薩正在美國東南部。如果數據中心位於路徑中,請採取主動措施將工作負載移出受影響的區域。主動災難恢復與反應式災難恢復的好處很多。沒有數據丟失,有足夠的時間來解決意外問題。它還包括管理人力資源,使員工可以擔心照顧家人,而不是工作。同樣,制定主動的災難恢復將是CSP代表其所有客戶做出的艱難決定。跨地區的計劃遷移將導致一定程度的停機。這個決定必須由客戶掌握。從Azure Outage Post-Mortem中吸取教訓,教育您的客戶。

得到保護
那麼您可以做些什麼來保護您的業務關鍵應用程序和數據?讓我們從Azure Outage Post-Mortem中汲取一些教訓。採用基於軟件的#SANless集群解決方案的跨區域,跨雲或混合雲模型將大大有助於解決您的HA / DR問題。此外,它還為基於雲的IaaS部署提供了出色的RTO和RPO。除應用程序特定解決方案外,還有其他選項。基於軟件的塊級卷複製解決方案(如SIOS DataKeeper和SIOS Protection Suite)可複制所有數據,並為Linux和Windows平台提供數據保護解決方案。我的大兒子剛剛在羅格斯大學開始他的氣象學本科學位。想像一下,人工智能(AI)和機器學習(ML)處理來自NOAA的天氣相關數據的那一天。他們可以在暴風雨襲擊前兩天觸發計劃的災難恢復遷移?我想我剛剛為他的碩士論文找到了一個完美的主題。或者更好的是,讓他和他在WeatherWatcher LLC的聰明的朋友獲得資金,為一家技術創業公司應用AI和ML來安排相關數據以控制主動災難恢復事件。我認為我們正處於IT分析解決方案的尖端。我們可以應用先進的機器學習技術來減少確保關鍵應用程序服務交付的時間和精力。 SIOS iQ是該領域領先的解決方案之一。壓扁艙口並做好準備。颶風季剛剛開始,我們已經開始瘋狂騎行了。如果您想在Twitter @daveberm上討論您的HA / DR策略,請與我聯繫。

 服務帳戶必須是每個節點上Local Admins組中的域帳戶一旦安裝DataKeeper並在每個節點上獲得許可,您將需要重新啟動服務器。
服務帳戶必須是每個節點上Local Admins組中的域帳戶一旦安裝DataKeeper並在每個節點上獲得許可,您將需要重新啟動服務器。 要創建DataKeeper Volume Resource,您需要啟動DataKeeper UI並連接到這兩個服務器。連接到SQL1 [/ caption] 連接到SQL2 [/ caption]連接到每個服務器後,即可創建DataKeeper卷。右鍵單擊Jobs並選擇“Creat
要創建DataKeeper Volume Resource,您需要啟動DataKeeper UI並連接到這兩個服務器。連接到SQL1 [/ caption] 連接到SQL2 [/ caption]連接到每個服務器後,即可創建DataKeeper卷。右鍵單擊Jobs並選擇“Creat e Job”為作業命名和描述。
e Job”為作業命名和描述。 選擇源服務器,IP和卷。IP地址是複制流量是否會傳播。
選擇源服務器,IP和卷。IP地址是複制流量是否會傳播。 選擇目標服務器。
選擇目標服務器。 選擇你的選擇。對於兩個VM位於同一地理區域的目的,我們將選擇同步複製。對於更長距離的複制,您將需要使用異步並啟用一些壓縮。
選擇你的選擇。對於兩個VM位於同一地理區域的目的,我們將選擇同步複製。對於更長距離的複制,您將需要使用異步並啟用一些壓縮。 通過在上次彈出窗口中單擊“是”,您將在故障轉移群集中的可用存儲中註冊新的DataKeeper卷資源。
通過在上次彈出窗口中單擊“是”,您將在故障轉移群集中的可用存儲中註冊新的DataKeeper卷資源。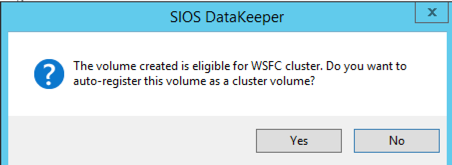 您將在可用存儲中看到新的DataKeeper卷資源。
您將在可用存儲中看到新的DataKeeper卷資源。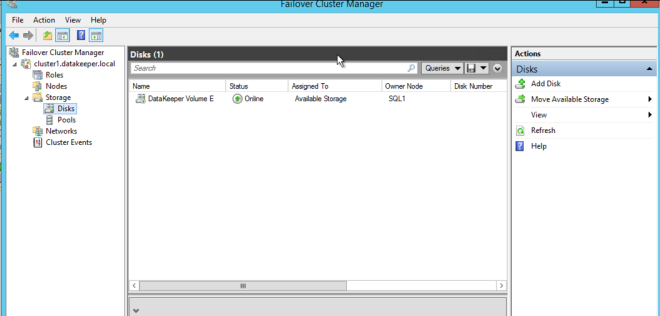
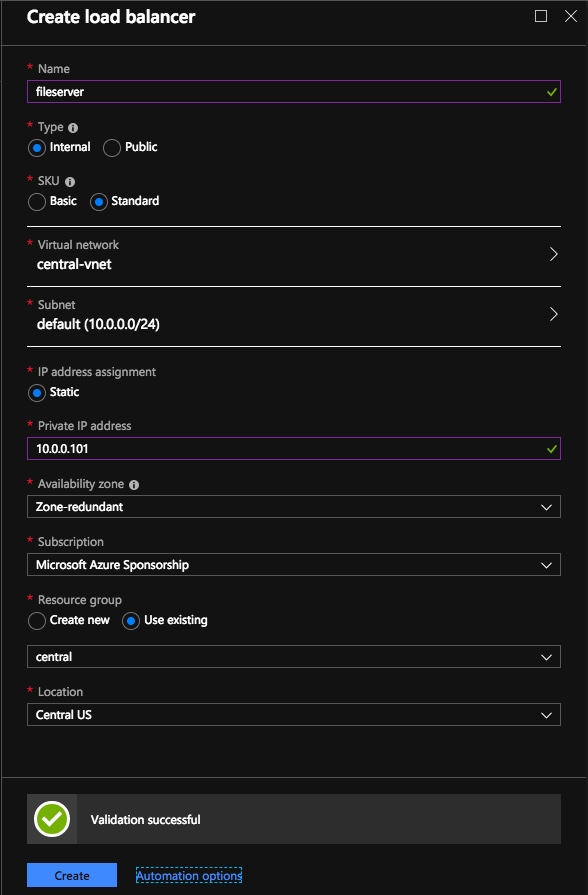 創建內部負載均衡器(ILB)後,您需要對其進行編輯。我們要做的第一件事就是添加一個後端池。通過此過程,您將選擇兩個群集節點。
創建內部負載均衡器(ILB)後,您需要對其進行編輯。我們要做的第一件事就是添加一個後端池。通過此過程,您將選擇兩個群集節點。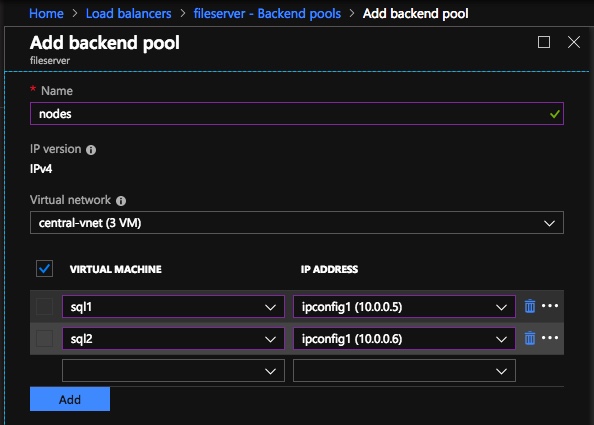 接下來我們要做的就是添加一個Probe。我們添加的探針將探測端口59999。此探針確定群集中哪個節點處於活動狀態。
接下來我們要做的就是添加一個Probe。我們添加的探針將探測端口59999。此探針確定群集中哪個節點處於活動狀態。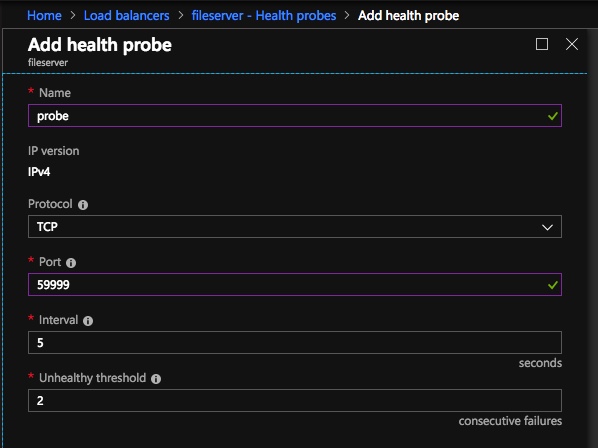 最後,我們需要一個負載平衡規則來重定向SMB流量,TCP端口445。在下面的屏幕截圖中需要注意的重要事項是直接服務器返回已啟用。確保你做出改變。
最後,我們需要一個負載平衡規則來重定向SMB流量,TCP端口445。在下面的屏幕截圖中需要注意的重要事項是直接服務器返回已啟用。確保你做出改變。




 時間上午7:12發布。回顧Twitter推文,似乎問題最初是在此之前的一兩個小時開始的。
時間上午7:12發布。回顧Twitter推文,似乎問題最初是在此之前的一兩個小時開始的。 很明顯,這次中斷的傳播影響比最初報導的美國中南部地區更廣泛。似乎依賴Azure Active Directory的服務也可能受到影響,並且嘗試配置新訂閱的客戶遇到了問題。
很明顯,這次中斷的傳播影響比最初報導的美國中南部地區更廣泛。似乎依賴Azure Active Directory的服務也可能受到影響,並且嘗試配置新訂閱的客戶遇到了問題。 24小時後問題還沒有完全解決,根據今天上午的最新更新…
24小時後問題還沒有完全解決,根據今天上午的最新更新… 那
那 麼你可以做些什麼來減少這種蔚藍雲停電的影響?沒有人可以責怪微軟發生雷擊等自然災害。但是在一天結束的時候,如果您唯一的災難恢復計劃是打電話,發推特並通過電子郵件發送電子郵件直到問題得到解決,那麼您剛剛收到了一個粗魯的覺醒。在您的災難恢復計劃中,您需要確保涵蓋所有基礎。
麼你可以做些什麼來減少這種蔚藍雲停電的影響?沒有人可以責怪微軟發生雷擊等自然災害。但是在一天結束的時候,如果您唯一的災難恢復計劃是打電話,發推特並通過電子郵件發送電子郵件直到問題得到解決,那麼您剛剛收到了一個粗魯的覺醒。在您的災難恢復計劃中,您需要確保涵蓋所有基礎。