主要的雲中斷影響谷歌計算引擎 – 您準備好了嗎?
谷歌首次在2019年6月2日太平洋時間12:25報導了一個“問題”。現在在任何類型的災難中都很常見,有關此次停機的報告首次出現在社交媒體上。社交媒體現在似乎是在災難早期獲取任何類型信息的最可靠的地方。
許多依賴Google Compute Engine的服務都受到了影響。我家裡有三個十幾歲的孩子。當所有三個孩子從他們的洞穴(又稱臥室)出現時,他們的臉上出現了擔憂的表情。Snapchat,Youtube和Discord都離線了!他們一定認為這肯定是天啟的第一個跡象。我向他們保證,這不是新黑暗時代的開始。相反,他們應該去外面做一些碼頭工作。這讓他們害怕回到現實狀態,他們很快就趕緊跑去找別的東西來佔用他們的時間。除了開玩笑之外,有許多服務被報告為關閉或僅在某些地區可用。塵埃仍然在停電的原因,廣度和範圍。但肯定的是,中斷在規模和範圍上都非常重要,影響了許多客戶和服務,包括Gmail和其他G-Suite服務,Vimeo等。
在我們等待最新谷歌計算引擎停機的官方根本原因分析時,谷歌報告稱“美國東部的高水平網絡擁堵”導致停機。我們將不得不等待他們確定導致網絡問題的原因。是人為錯誤,網絡攻擊,硬件故障還是其他什麼?
您是否為此云中斷做好了準備?
我在上一次重大雲停運期間寫道。如果您在雲中運行業務關鍵型工作負載,無論云服務提供商如何,您都有責任為不可避免的中斷做好計劃。2018年9月4日的多天Azure停電與次級HVAC系統在與電風暴相關的電湧期間啟動失敗有關。雖然故障只發生在一個數據中心內,但是中斷暴露了多個依賴於這個數據中心的服務。這使得數據中心本身成為單點故障。
有一個健全的災難恢復計劃
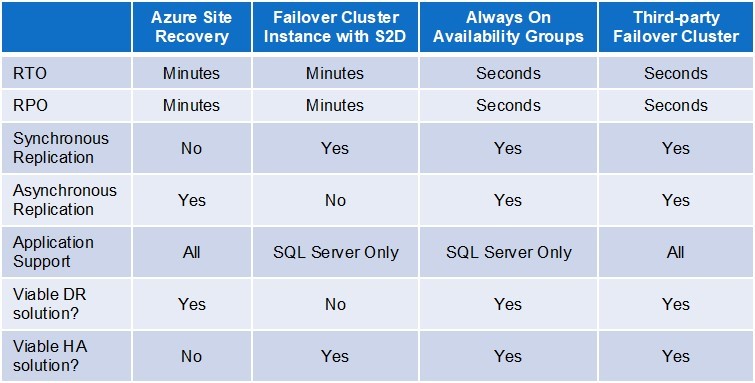
利用雲的基礎架構,通過在可用區,區域甚至雲服務提供商之間不斷複製關鍵數據來最大限度地降低風險。除了數據保護之外,制定快速恢復關鍵業務應用程序的程序是任何災難恢復計劃的重要組成部分。有各種複制和恢復選項可用。這包括雲供應商自己提供的服務,如Azure Site Recovery,SQL Server Always On Availability Groups等特定於應用程序的解決方案,以及SIOS DataKeeper等第三方解決方案,可保護在Windows和Linux上運行的各種應用程序。擁有完全依賴於單個雲提供商的災難恢復策略會使您容易受到可能影響單個雲中多個區域的情況的影響。多數據中心或多地區災難不太可能發生。但是,正如我們在去年秋天看到的最近這次中斷和Azure中斷一樣,即使單個數據中心本地出現故障,影響也可以在多個數據中心甚至雲中的區域內實現。要最大限度地降低風險,請考慮災難恢復站點位於主雲平台之外的多雲或混合雲方案。雲與您自己的數據中心一樣容易中斷。你必須採取措施為災難做準備。我建議您首先查看最關鍵的業務應用程序。如果他們離線並且管理它們的雲門戶甚至不可用,你會怎麼做?你能恢復嗎?你會滿足你的RTO和RPO目標嗎?如果沒有,也許是時候重新評估您的災難恢復策略了。
“由於沒準備好,你準備失敗。” – 本傑明富蘭克林