Dampak Pemadaman Awan Besar Mempengaruhi Mesin Hitung Google – Apakah Anda Siap?
Google pertama kali melaporkan "Masalah" pada 2 Juni 2019 pukul 12:25 PDT. Seperti sekarang umum dalam semua jenis bencana, laporan pemadaman ini pertama kali muncul di media sosial. Media sosial tampaknya merupakan tempat yang paling dapat diandalkan untuk mendapatkan semua jenis informasi di awal bencana sekarang.
Banyak layanan yang mengandalkan Google Compute Engine terkena dampaknya. Saya punya tiga anak remaja di rumah. Sesuatu naik ketika ketiga anak itu muncul dari gua-gua mereka, alias, kamar tidur, pada saat yang sama dengan ekspresi khawatir di wajah mereka. Snapchat, Youtube dan Discord semuanya offline! Mereka pasti berpikir bahwa ini adalah tanda pertama dari kiamat. Saya meyakinkan mereka bahwa ini bukanlah awal dari zaman kegelapan yang baru. Dan sebaliknya mereka harus pergi keluar dan melakukan pekerjaan halaman. Itu membuat mereka takut kembali ke dunia nyata dan mereka dengan cepat pergi mencari sesuatu yang lain untuk mengisi waktu mereka. Semua bercanda samping, ada banyak layanan yang dilaporkan turun, atau hanya tersedia di daerah-daerah tertentu. Debu masih menempel pada penyebab, luasnya dan cakupan pemadaman. Tetapi jelas bahwa pemadaman itu cukup signifikan dalam ukuran dan ruang lingkup, berdampak pada banyak pelanggan dan layanan termasuk Gmail dan layanan G-Suite lainnya, Vimeo dan banyak lagi.
 Banyak layanan terkena dampak dari penghentian ini, Gmail, YouTube dan SnapChat hanya untuk beberapa nama. [/ caption]
Banyak layanan terkena dampak dari penghentian ini, Gmail, YouTube dan SnapChat hanya untuk beberapa nama. [/ caption]Sementara kami menunggu analisis akar penyebab resmi pada pemadaman Google Compute Engine terbaru ini, Google melaporkan "tingkat kemacetan jaringan yang tinggi di AS bagian timur" yang menyebabkan downtime. Kami harus menunggu untuk melihat apa yang mereka tentukan menyebabkan masalah jaringan. Apakah itu kesalahan manusia, serangan cyber, kegagalan perangkat keras, atau sesuatu yang lain?
Apakah Anda Siap untuk Pemadaman Awan Ini?
Saya menulis selama pemadaman awan besar terakhir. Jika Anda menjalankan beban kerja kritis bisnis di cloud, terlepas dari penyedia layanan cloud, Anda berkewajiban untuk merencanakan pemadaman yang tak terhindarkan. Pemadaman multi-hari Azure pada 4 September 2018 terkait dengan kegagalan sistem HVAC sekunder untuk menendang selama lonjakan daya yang terkait dengan badai listrik. Sementara kegagalan itu hanya dalam satu pusat data, pemadaman listrik itu memaparkan beberapa layanan yang memiliki ketergantungan pada pusat data tunggal ini. Ini membuat pusat data itu sendiri titik kegagalan tunggal.
Memiliki Rencana Pemulihan Bencana yang Baik
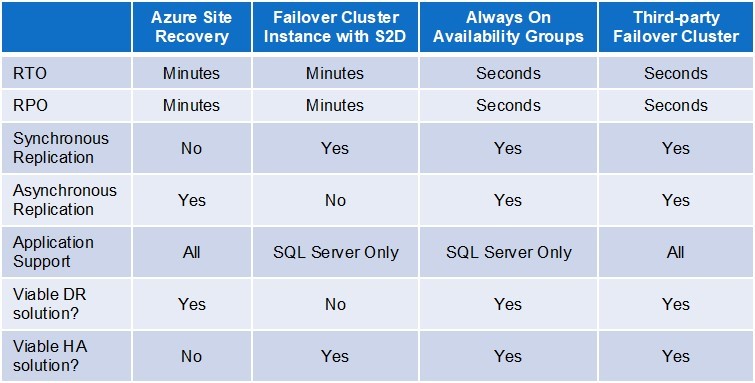
Memanfaatkan infrastruktur cloud, meminimalkan risiko dengan terus menerus mereplikasi data penting antara Zona Ketersediaan, Wilayah, atau bahkan penyedia layanan cloud. Selain perlindungan data, memiliki prosedur untuk memulihkan aplikasi penting bisnis dengan cepat adalah bagian penting dari setiap rencana pemulihan bencana. Ada berbagai opsi replikasi dan pemulihan yang tersedia. Ini termasuk layanan yang disediakan oleh vendor cloud itu sendiri seperti Azure Site Recovery, untuk solusi spesifik aplikasi seperti SQL Server Always On Availability Groups, untuk solusi pihak ketiga seperti SIOS DataKeeper yang melindungi berbagai aplikasi yang berjalan pada Windows dan Linux. Memiliki strategi pemulihan bencana yang sepenuhnya tergantung pada penyedia cloud tunggal membuat Anda rentan terhadap skenario yang mungkin berdampak pada banyak wilayah dalam satu cloud. Bencana multi-pusat data atau multi-wilayah tidak mungkin terjadi. Namun, seperti yang kita lihat dengan pemadaman baru-baru ini dan pemadaman Azure musim gugur yang lalu, bahkan jika kegagalan bersifat lokal untuk pusat data tunggal, dampaknya dapat luas menjangkau beberapa pusat data atau bahkan wilayah dalam awan. Untuk meminimalkan risiko Anda, pertimbangkan skenario multi-cloud atau cloud hybrid di mana situs pemulihan bencana berada di luar platform cloud utama Anda. Cloud sama rentan terhadap pemadaman seperti pusat data Anda sendiri. Anda harus mengambil langkah-langkah untuk bersiap menghadapi bencana. Saya sarankan Anda mulai dengan melihat aplikasi paling penting bisnis Anda terlebih dahulu. Apa yang akan Anda lakukan jika mereka offline dan portal cloud untuk mengelolanya bahkan tidak tersedia? Bisakah kamu pulih? Apakah Anda memenuhi tujuan RTO dan RPO Anda? Jika tidak, mungkin sekarang saatnya untuk mengevaluasi kembali strategi Disaster Recovery Anda.
"Dengan gagal mempersiapkan, Anda bersiap untuk gagal." – Benjamin Franklin