New SIOS Documentation Site
Features New Easy-to-Use Site Layout and Improved Navigation
The SIOS Product Management, Product Marketing, and Technical Documentation teams are excited to announce our new documentation site on a new, easier-to-use platform. Check out the new site here: docs.us.sios.com.
The new layout of our documentation site has improved the following functionalities:
- Quick and easy navigation with HTML anchor buttons
- Topic descriptions with HTML title tags for easier searching
- Navigational tips and instruction for enhanced navigation within our documentation
We’d love to hear your feedback!
Within our documentation, please provide feedback by posting a comment on specific topics to help us keep our content as up-to-date and relevant as possible.
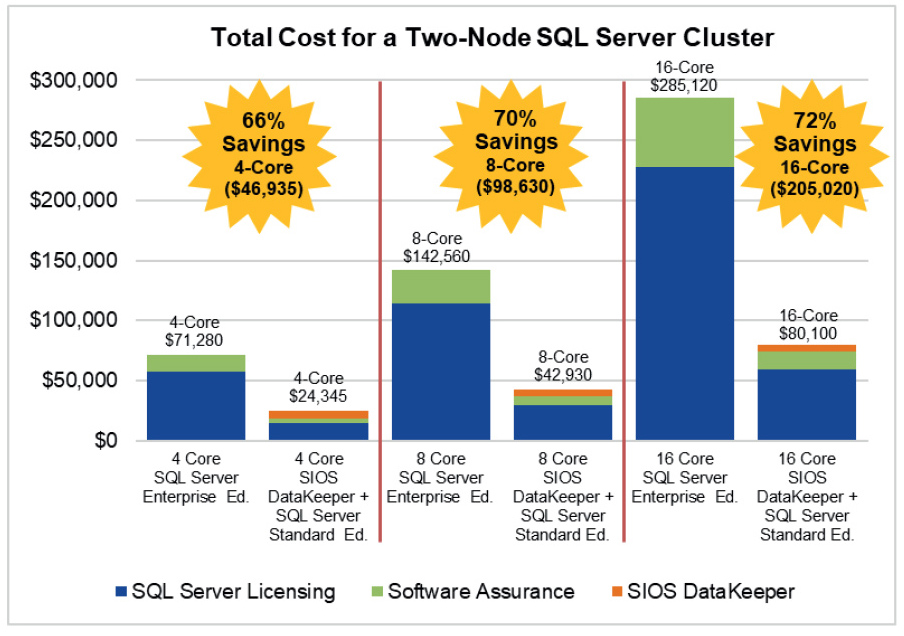
Please see our improved “Solutions” sections for answers to common questions or concerns by searching “Solutions” within our documentation pages.
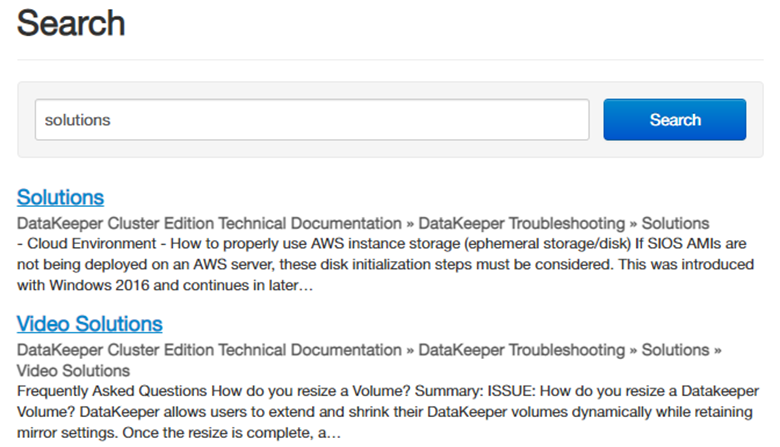
Overall Navigation: When it comes to the new navigation, most of the items on the new page are “anchored”; so by selecting a button you will be taken to the selected section. We can first start off by selecting our operating system.

This will bring us to products offered within the operating system Windows/Linux.
After selecting our operating system, we will now select our product. Below each product (Datakeeper/LifeKeeper/Evaluation Guides/Step-by-Step Guides) are short descriptions of each solution within each product. To see the description of each product, hover over the Product Information dropdown.



Once a product is selected, we will now see the most commonly used topics for the solutions within a product.
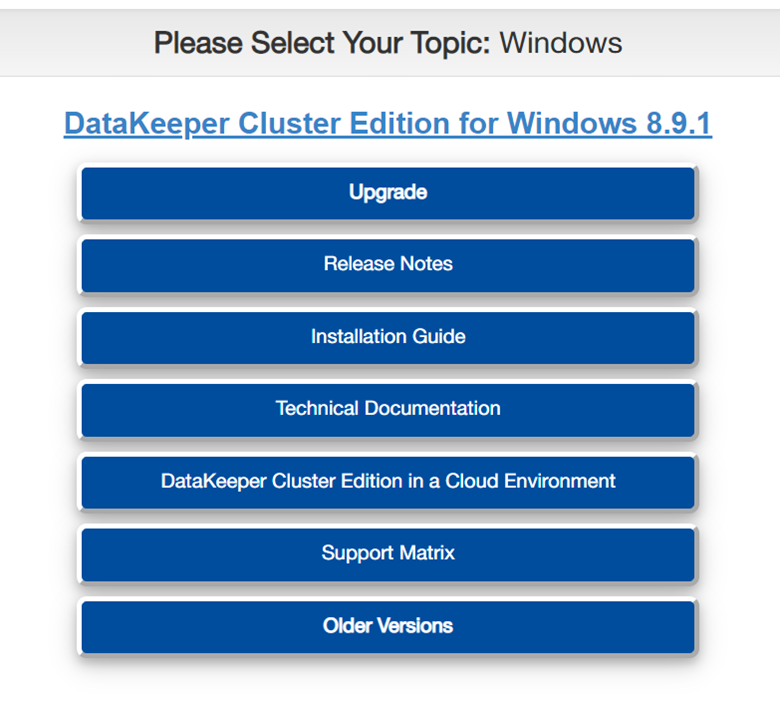
By hovering over a topic for a few moments, you will see a brief description of what each topic is about.

After a topic is selected, you will land on the most recent version number of the topic selected. If the most recent version is NOT the version you are running, please utilize the dropdown menu in the top to reach the version you are looking for. SIOS recommends upgrading to the latest version for the newest features, bug fixes, and overall improvements in our product.
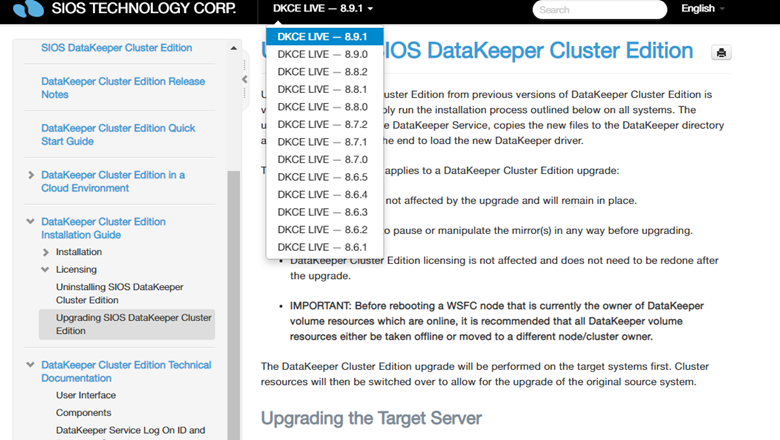
Navigational Tips: Let’s scroll back up to the top of our new documentation page layout. Below selecting your operating system we have a link to navigation tips to keep in mind when using the new documentation site for better ease of use. Here you will see a list of general terms of what each topic is about as well as information on how to view the general terms by hovering over a topic for a few moments.
Below General Terms we have Navigations Tips:
- Navigating to a specific “version number” within our documentation.
- Finding Older Versions – If you were not able to locate your version in the dropdown list within our documentation, click the Older Versions topic on our new page in order to see all versions both supported and unsupported.
- For Upgrade instructions, please see the first topic in our list. SIOS recommends upgrading to our latest software so that you will have the most up to date fixes and features of our product.
You can always get back to our main documentation page from the navigational tips page by selecting the home or back button.

Below the Operating System text, you can follow the link to the versions via “Product Support Schedule”.
(Note: After a product is released, it is supported for at least 3 years.)
For support assistance, please follow “support.us.sios.com” for information in contacting support. This will lead up to the new documentation page.
For our customers in Japan, please click the link here in order to view our new page in Japanese.


I hope this helped in learning how to better navigate our new documentation site. Thank you for choosing SIOS!
Reproduced with permission from SIOS