
How to Eliminate Single Points of Failure in the Cloud with High Availability Clustering
When providing high availability protection, it is a general principle to ensure all components are redundant to avoid Single Points of Failure (SPOF). That is, ensure that no single element causes the entire system to stop if it fails. However, it is important to note that the operational infrastructure is hard to access in the public cloud.
In a cloud-based high availability cluster, there is a possibility that the standby node(s) will be located on the same host server, in the same rack, and using the same network switch as the operating node. Unless you configure these elements with redundancy, any of them could be a SPOF and put the application at risk for catastrophic failure.
It is necessary to ensure cluster nodes are on different cloud “regions” and “availability zones” that physically separate the data center and operational infrastructure in different geographic locations.
What are the main principles for ensuring availability?
You cannot expect the various components that make up a physical IT infrastructure to operate according to specifications forever. Parts wear out, systems become incompatible, and settings change. Although regular maintenance can reduce the risk of downtime, it’s likely that something will fail over the course of the product lifecycle.
In some rare cases, you may have a serious bug that is latent in the OS or embedded software that causes the application to stop working.
As you may have already noticed, the High Availability cluster configuration is exactly in line with this principle, and a single point of failure is eliminated by making the important server and its resources redundant to the active system (production system). However, it is important to remember two things. One, the server hardware is not the only critical component. The second point, other critical SPOF components may be invisible to you in a public cloud infrastructure.
Beware of the pitfalls of a single point of failure hidden in the cloud’s invisible infrastructure
Most public clouds operate in a so-called “multi-tenant” mode. That is, they run the VMs of multiple companies on the same physical host server. And with a regular contract, you can’t specify which host server your system runs on. This may cause problems as the standby node in your cloud cluster may be placed on the same host server that operates the active node. Even if you configure an HA cluster configuration, if the host server goes down, the operating node and the standby node will both go down too. In this scenario, your cloud operator decides when and how your system will be restored.
The host server that operates the active node and the host server that operates the standby node may be in the same rack. In this case, the rack becomes a SPOF, so if a failure occurs there both the active and standby nodes under it will also fail.
Furthermore, in the upper layers of your infrastructure such as network switches that bundle multiple racks, gateways and routers, and power supply units in data centers, the operating system node and the standby system node may coexist in the same system. And if these key components aren’t redundant, then you have an inescapable single point of failure. Again, for a company that is a public cloud user, such a data center infrastructure is a black box. It may impossible to see into the detailed configuration to identify SPOFs.
Public cloud availability zones and regions should be leveraged for availability
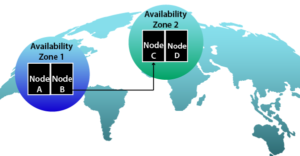
How can we explicitly avoid hidden single points of failures in the public cloud? The most robust method is to use the “Availability Zones” and “Regions” prepared on the cloud side.
An Availability Zone is an independent physical separation of the infrastructure within your data center. And regions are independent data centers that are geographically separated. Some public clouds allow you to deliberately use these Availability Zones or regions for different purposes.
For example, Amazon Web Service (AWS) has 12 regions worldwide. In addition, Microsoft Azure has 22 regions. By constructing an HA cluster configuration in which operating nodes and standby nodes are distributed in different availability zones across these two or more regions, almost all SPOFs can be avoided with certainty. If you adhere to these best practices, you can confidently ensure availability, DR (Disaster Recovery) and BCP (Business Continuity Planning).





