Langkah-demi-Langkah: Cara Mengkonfigurasi Instance Failover Cluster SQL Server 2008 R2 di Azure
Jika Anda memerlukan panduan Mengkonfigurasi Instance Cluster Failover SQL Server di Azure, Anda mungkin masih menggunakan SQL Server 2008/2008 R2. Dan, ingin mengambil keuntungan dari pembaruan keamanan yang diperluas yang ditawarkan Microsoft jika Anda memindahkan SQL Server 2008/2008 R2 ke Azure. Saya sebelumnya menulis tentang topik ini di posting blog ini. Anda mungkin bertanya-tanya bagaimana memastikan contoh SQL Server Failover Cluster Anda tetap tersedia begitu Anda pindah ke Azure. Saat ini, kebanyakan orang memiliki bisnis kritis SQL Server 2008/2008 R2 dikonfigurasi sebagai contoh berkerumun (SQL Server FCI) di pusat data mereka. Saat melihat Azure, Anda mungkin menyadari bahwa karena kurangnya penyimpanan bersama, tampaknya Anda tidak dapat membawa SQL Server FCI ke cloud Azure. Namun, bukan itu masalahnya berkat SIOS DataKeeper. SIOS DataKeeper memungkinkan Anda untuk membangun contoh SQL Server Failover Cluster di Azure, AWS, Google Cloud, atau di mana pun di mana penyimpanan bersama tidak tersedia atau di mana Anda ingin mengonfigurasi cluster multi-situs di mana penyimpanan bersama tidak masuk akal. DataKeeper telah mengaktifkan kluster SANless untuk Windows dan Linux sejak 1999. Microsoft mendokumentasikan penggunaan SIOS DataKeeper untuk contoh SQL Server Failover Cluster dalam dokumentasi mereka: Ketersediaan tinggi dan pemulihan bencana untuk SQL Server di Mesin Virtual Azure. Saya sudah menulis tentang SQL Server FCI yang berjalan di Azure sebelumnya, Tapi saya tidak pernah menerbitkan Panduan Langkah-demi-Langkah khusus untuk SQL Server 2008/2008 R2. Berita baiknya adalah ini berfungsi sama baiknya dengan SQL 2008/2008 R2 seperti halnya dengan SQL 2012/2014/2016/2017 dan segera dirilis 2019. Selain itu, terlepas dari versi Windows Server (2008/2012/2016/2019) atau SQL Server (2008/2012/2014/2016/2017) proses konfigurasinya cukup mirip sehingga panduan ini harus cukup memadai untuk membantu Anda melalui konfigurasi. Jika rasa Anda SQL atau Windows tidak tercakup dalam salah satu panduan saya, jangan takut untuk melompat dan membangun FCI SQL Server dan referensi panduan ini, saya pikir Anda akan mengetahui perbedaan dan jika Anda pernah terjebak hanya menjangkau saya di Twitter @daveberm dan saya akan dengan senang hati membantu Anda. Panduan ini menggunakan SQL Server 2008 R2 dengan Windows Server 2012 R2. Pada saat penulisan ini saya tidak melihat gambar Azure Marketplace dari SQL 2008 R2 pada Windows Server 2012 R2, jadi saya harus mengunduh dan menginstal SQL 2008 R2 secara manual. Secara pribadi saya lebih suka kombinasi ini, tetapi jika Anda perlu menggunakan Windows Server 2008 R2 atau Windows 212 itu bagus. Jika Anda menggunakan Windows Server 2008 R2 jangan lupa untuk menginstal Pembaruan Rollup kb3125574Convenience untuk Windows Server 2008 R2 SP1. Atau jika Anda terjebak dengan Server 2012 (bukan R2), Anda memerlukan perbaikan terbaru di kb2854082. Jangan tertipu oleh artikel ini yang mengatakan Anda harus menginstal kb2854082 pada contoh SQL Server 2008 R2 Anda. Jika Anda mulai mencari pembaruan untuk Windows Server 2008 R2 Anda akan menemukan bahwa hanya versi untuk Server 2012 yang tersedia. Perbaikan terbaru khusus itu untuk Server 2008 R2 yang termasuk dalam rollup pembaruan kenyamanan Rollup untuk Windows Server 2008 R2 SP1.
INSTAN AZURE KETENTUAN
Saya tidak akan membahas detail di sini dengan banyak tangkapan layar, terutama karena Azure Portal UI cenderung berubah cukup sering, sehingga tangkapan layar yang saya ambil akan menjadi sangat cepat. Sebagai gantinya, saya hanya akan membahas topik-topik penting yang harus Anda ketahui.
DOMAIN KESALAHAN ATAU KETERSEDIAAN ZONA?
Untuk memastikan instance SQL Server Anda sangat tersedia, Anda harus memastikan node cluster Anda berada di berbagai Domain Kesalahan (FD) atau di Zona Ketersediaan yang berbeda (AZ). Instance Anda tidak hanya perlu berada di FD atau AZ yang berbeda, tetapi File Share Witness Anda (lihat di bawah) juga perlu berada di FD atau AZ yang berbeda dari yang ada di mana node cluster Anda berada. Ini pendapat saya. AZ adalah fitur Azure terbaru, tetapi mereka hanya didukung di beberapa wilayah sejauh ini. AZ memberi Anda SLA yang lebih tinggi (99,99%) kemudian FD (99,95%), dan melindungi Anda terhadap jenis pemadaman awan yang saya jelaskan dalam posting saya Azure Outage Post-Mortem. Jika Anda dapat menggunakan di wilayah yang mendukung AZ maka saya sarankan Anda menggunakan AZ. Dalam panduan ini saya menggunakan AZ yang akan Anda lihat ketika Anda sampai pada bagian tentang mengkonfigurasi penyeimbang beban. Namun, jika Anda menggunakan FD, semuanya akan persis sama, kecuali konfigurasi penyeimbang beban akan merujuk pada Kumpulan Ketersediaan daripada Zona Ketersediaan.
APA ITU FILE SHARE SAKSI YANG ANDA TANYAKAN?
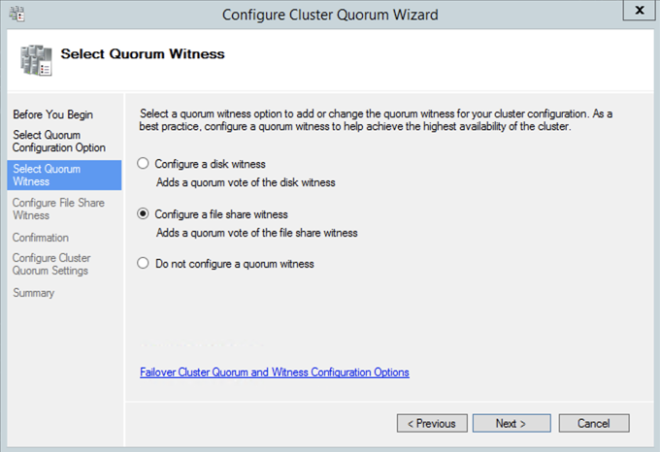
Tanpa merinci lebih jauh, Windows Server Failover Clustering (WSFC) mengharuskan Anda mengonfigurasi "Witness" untuk memastikan bahwa failover berperilaku baik. Windows Server Failover Clustering mendukung tiga jenis saksi: Disk, File Share, Cloud. Karena kita berada di Azure, Saksi Disk tidak mungkin. Cloud Witness hanya tersedia dengan Windows Server 2016 dan yang lebih baru, sehingga meninggalkan kami dengan File Share Witness. Jika Anda ingin mempelajari lebih lanjut tentang kuorum klaster, lihat pos saya di Microsoft Press Blog, Dari MVP: Memahami Kuorum Cluster Failover Server Windows di Windows Server 2012 R2
TAMBAHKAN PENYIMPANAN KEPADA INSTAN SQL SERVER ANDA
Saat Anda menyediakan instance SQL Server Anda, Anda akan ingin menambahkan disk tambahan untuk setiap instance. Minimal Anda akan memerlukan satu disk untuk Data SQL dan file Log, satu disk untuk Tempdb. Apakah Anda harus memiliki disk terpisah untuk file log dan data agak diperdebatkan saat berjalan di cloud. Di bagian belakang, penyimpanan semua berasal dari tempat yang sama dan ukuran instance Anda membatasi total IOPS Anda. Menurut pendapat saya benar-benar tidak ada nilai dalam memisahkan log dan file data Anda karena Anda tidak dapat memastikan bahwa mereka berjalan pada dua set fisik disk. Saya akan membiarkan itu untuk Anda putuskan, tetapi saya menaruh log dan data semua pada volume yang sama. Biasanya SQL Server 2008 R2 FCI akan meminta Anda untuk meletakkan tempdb pada disk berkerumun. Namun, SIOS DataKeeper memiliki fitur yang sangat bagus ini disebut DataKeeper Non-Mirrored Volume Resource. Panduan ini tidak mencakup memindahkan tempdb ke sumber daya volume yang tidak dicerminkan ini, tetapi untuk kinerja yang optimal Anda harus melakukan ini. Sebenarnya tidak ada alasan yang baik untuk mereplikasi tempdb karena itu diciptakan pada saat failover. Sejauh penyimpanan terkait Anda dapat menggunakan jenis penyimpanan apa pun, tetapi tentu saja menggunakan Managed Disk kapan pun memungkinkan. Pastikan setiap node dalam gugus memiliki konfigurasi penyimpanan yang identik. Setelah Anda meluncurkan instance, Anda ingin melampirkan disk ini dan memformatnya NTFS. Pastikan setiap instance menggunakan huruf drive yang sama.
JARINGAN
Ini bukan persyaratan yang sulit, tetapi jika mungkin gunakan ukuran instance yang mendukung jaringan yang dipercepat. Juga, pastikan Anda mengedit antarmuka jaringan di portal Azure sehingga instance Anda menggunakan alamat IP statis. Agar pengelompokan berfungsi dengan baik, Anda ingin memastikan Anda memperbarui pengaturan untuk server DNS sehingga menunjuk ke Windows AD / DNS server Anda dan bukan hanya beberapa server DNS publik.
KEAMANAN
Secara default, komunikasi antara node dalam jaringan virtual yang sama terbuka lebar, tetapi jika Anda telah mengunci Grup Keamanan Azure Anda, Anda perlu tahu port apa yang harus terbuka antara node cluster dan menyesuaikan grup keamanan Anda. Dalam pengalaman saya, hampir semua masalah yang akan Anda temui ketika membangun sebuah cluster di Azure disebabkan oleh port yang diblokir. DataKeeper memiliki beberapa port yang harus dibuka antara instance clustered. Port-port itu adalah sebagai berikut: UDP: 137, 138 TCP: 139, 445, 9999, plus port dalam rentang 10000 hingga 10025 Failover cluster memiliki serangkaian persyaratan port sendiri yang bahkan tidak akan saya coba dokumentasikan di sini. Artikel ini sepertinya sudah dibahas. http://dsfnet.blogspot.com/2013/04/windows-server-clustering-sql-server.html Selain itu, Load Balancer yang dijelaskan nanti akan menggunakan port probe yang harus mengizinkan lalu lintas masuk pada setiap node. Port yang umum digunakan dan dijelaskan dalam panduan ini adalah 59999. Dan akhirnya jika Anda ingin klien Anda dapat mencapai contoh SQL Server Anda, Anda ingin memastikan port SQL Server Anda terbuka, yang secara default adalah 1433. Ingat, port ini dapat diblokir oleh Windows Firewall atau Azure Security Groups, jadi pastikan untuk memeriksa keduanya untuk memastikan mereka dapat diakses.
GABUNGKAN DOMAIN
Persyaratan untuk SQL Server 2008 R2 FCI adalah bahwa instance harus berada di Windows Server Domain yang sama. Jadi, jika Anda belum melakukannya, pastikan Anda telah bergabung dengan instance ke domain Windows Anda
AKUN LAYANAN LOKAL
Ketika Anda menginstal DataKeeper, ia akan meminta Anda untuk memberikan akun layanan. Anda harus membuat akun pengguna domain dan kemudian menambahkan akun pengguna itu ke Grup Administrator Lokal pada setiap node. Ketika ditanya selama instalasi DataKeeper, tentukan akun itu sebagai akun layanan DataKeeper. Catatan – Jangan menginstal DataKeeper dulu!
KELOMPOK KEAMANAN DOMAIN GLOBAL
Anda akan diminta untuk menentukan dua Grup Keamanan Domain Global saat Anda menginstal SQL 2008 R2. Anda mungkin ingin melihat ke depan pada petunjuk instalasi SQL dan membuat grup tersebut sekarang. Juga, buat akun pengguna domain dan letakkan di masing-masing akun keamanan ini. Anda akan menentukan akun ini sebagai bagian dari instalasi SQL Server Cluster.
PERSYARATAN LAINNYA
Anda harus mengaktifkan Failover Clustering dan .Net 3.5 pada setiap instance dari dua instance cluster. Ketika Anda mengaktifkan Failover Clustering, pastikan juga untuk mengaktifkan "Server Failover Cluster Automation" opsional. Ini diperlukan untuk SQL Server 2008 R2 cluster di Windows Server 2012 R2.
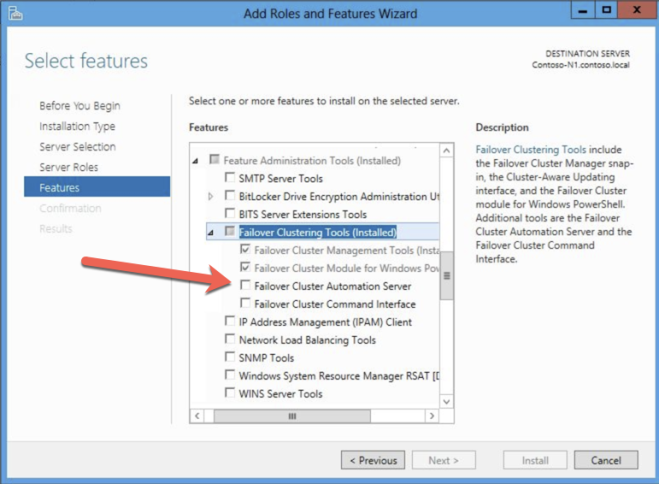
BUAT SUMBER DAYA CLUSTER DAN DATAKEEPER
Kami sekarang siap untuk mulai membangun cluster. Langkah pertama adalah membuat basis cluster. Karena cara Azure menangani DHCP, kami HARUS membuat cluster menggunakan Powershell dan bukan Cluster UI. Kami menggunakan Powershell karena itu akan memungkinkan kami menentukan alamat IP statis sebagai bagian dari proses pembuatan. Jika kami menggunakan UI, itu akan melihat bahwa VM menggunakan DHCP dan itu akan secara otomatis menetapkan alamat IP duplikat. Karena itu untuk menghindari situasi itu, mari kita gunakan Powershell seperti yang ditunjukkan di bawah ini.
New-Cluster -Name cluster1 -Node sql1, sql2 -StaticAddress 10.0.0.100 -NoStorage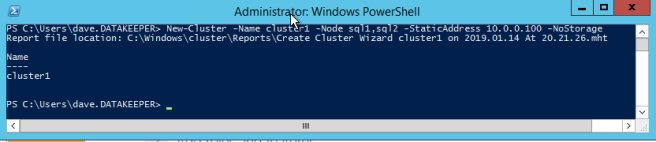
Setelah cluster membuat, jalankan Test-Cluster. Ini diperlukan sebelum SQL Server akan menginstal.
Test-Cluster
Anda akan mendapatkan peringatan tentang Penyimpanan dan Jaringan. Untungnya, Anda dapat mengabaikannya seperti yang diharapkan pada kluster SANless di Azure. Namun, atasi peringatan atau kesalahan lainnya sebelum melanjutkan. Setelah cluster dibuat, Anda perlu menambahkan File Share Witness. Pada server ketiga kami tentukan sebagai saksi berbagi file, buat berbagi file dan berikan izin Baca / Tulis ke objek komputer cluster yang baru saja kita buat di atas. Dalam hal ini $ Cluster1 akan menjadi nama objek komputer yang membutuhkan izin Baca / Tulis di tingkat keamanan berbagi dan NTFS. Setelah berbagi dibuat, Anda dapat menggunakan panduan kuorum konfigurasi Cluster seperti yang ditunjukkan di bawah ini untuk mengkonfigurasi File Share Witness.




INSTAL DATAKEEPER
Penting untuk menunggu hingga klaster dasar dibuat sebelum kita menginstal DataKeeper, karena instalasi DataKeeper mendaftarkan tipe Sumber Daya Volume DataKeeper dalam kluster failover. Jika Anda melompat pistol dan sudah menginstal DataKeeper tidak apa-apa. Cukup jalankan pengaturan lagi dan pilih Perbaiki Instalasi. Screenshot di bawah ini memandu Anda melalui instalasi dasar. Mulai dengan menjalankan Pengaturan DataKeeper.






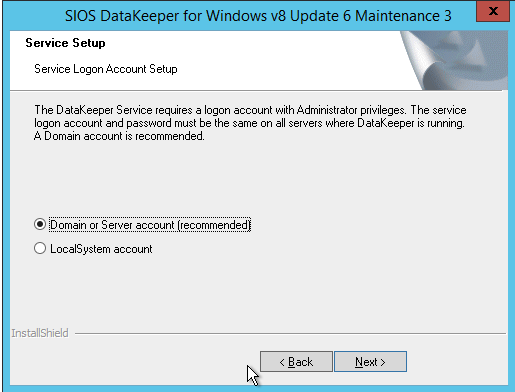
Akun yang Anda tentukan di bawah ini harus akun domain. Itu harus menjadi bagian dari grup Administrator Lokal pada setiap node cluster.
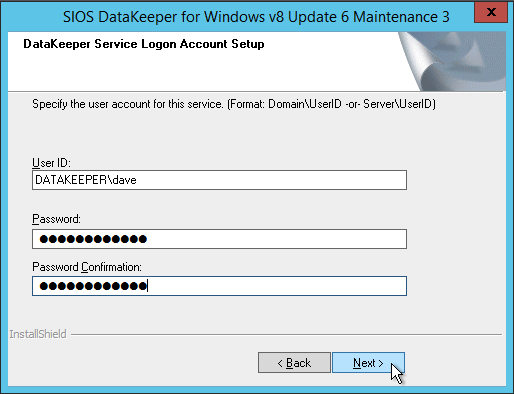
Ketika disajikan dengan manajer Kunci Lisensi SIOS, Anda dapat menelusuri kunci sementara Anda. Atau jika Anda memiliki kunci permanen, Anda dapat menyalin ID Host Sistem dan menggunakannya untuk meminta lisensi permanen Anda. Jika Anda perlu menyegarkan kunci, SIOS License Key Manager adalah program yang akan diinstal yang dapat Anda jalankan secara terpisah untuk menambahkan kunci baru.

BUAT SUMBER DATAKEEPER VOLUME
Setelah DataKeeper diinstal pada setiap node, Anda siap membuat Sumber Daya Volume DataKeeper pertama Anda. Langkah pertama adalah membuka UI DataKeeper dan menghubungkan ke masing-masing node cluster.

Jika semuanya dilakukan dengan benar, Laporan Ikhtisar Server akan terlihat seperti ini.

Anda sekarang dapat membuat Pekerjaan pertama Anda seperti yang ditunjukkan di bawah ini.
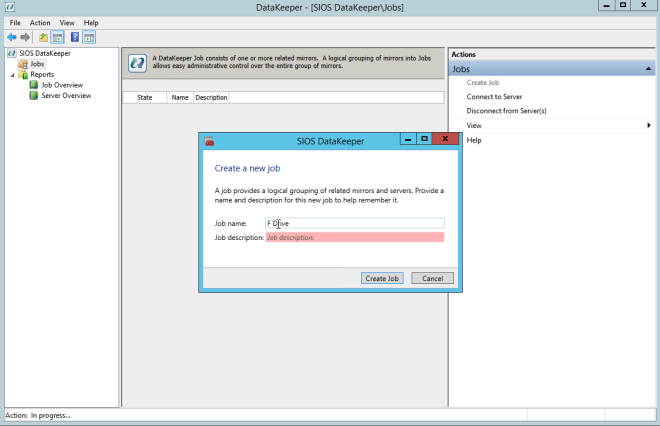


Setelah Anda memilih Sumber dan Target, Anda akan diberikan opsi berikut. Untuk target lokal di wilayah yang sama, satu-satunya yang perlu Anda pilih adalah Sinkron.


Pilih Ya dan daftarkan otomatis volume ini sebagai sumber daya klaster.

Setelah Anda menyelesaikan proses ini, buka Failover Cluster Manager dan cari di Disk. Anda harus melihat sumber daya Volume DataKeeper di Penyimpanan yang Tersedia. Pada titik ini WSFC memperlakukan ini seolah-olah itu adalah sumber daya disk cluster yang normal.

SLIPSTREAM SP3 ONTO SQL 2008 R2 INSTALL MEDIA
SQL Server 2008 R2 hanya didukung pada Windows Server 2012 R2 dengan SQL Server SP2 atau yang lebih baru. Sayangnya, Microsoft tidak pernah merilis media instalasi SQL Server 2008 R2 yang menyertakan SP2 atau SP3. Sebagai gantinya, Anda harus memasukkan paket layanan ke media instalasi sebelum Anda melakukan instalasi. Jika Anda mencoba melakukan instalasi dengan media SQL Server 2008 R2 standar, Anda akan mengalami semua jenis masalah. Saya tidak ingat kesalahan pasti yang akan Anda lihat. Tapi saya ingat mereka tidak benar-benar menunjukkan masalah yang sebenarnya. Anda akan menghabiskan banyak waktu untuk mencari tahu apa yang salah. Pada tanggal penulisan ini, Microsoft tidak memiliki Windows Server 2012 R2 dengan penawaran SQL Server 2008 R2 di Azure Marketplace. Jangan membawa lisensi SQL Anda sendiri jika Anda ingin menjalankan SQL 2008 R2 pada Windows Server 2012 R2 di Azure. Jika mereka menambahkan gambar itu nanti, atau jika Anda memilih untuk menggunakan SQL 2008 R2 pada gambar Windows Server 2008 R2, Anda harus terlebih dahulu menghapus instalan contoh mandiri SQL Server yang ada sebelum melanjutkan. Saya mengikuti panduan dalam Opsi 1 artikel ini untuk memasukkan SP3 ke media instalasi SQL 2008 R2 saya. Anda tentu saja harus menyesuaikan beberapa hal karena artikel ini merujuk SP2 daripada SP3. Pastikan Anda memasukkan SP3 pada media instalasi yang akan kami gunakan untuk kedua node cluster. Setelah selesai, lanjutkan ke langkah berikutnya.
INSTAL SQL SERVER PADA NODE PERTAMA
Menggunakan media SQL Server 2008 R2 dengan SP3 slipstream, jalankan setup dan instal node pertama dari cluster seperti yang ditunjukkan di bawah ini.






Jika Anda menggunakan selain dari contoh Default SQL Server, Anda akan memiliki beberapa langkah tambahan yang tidak tercakup dalam panduan ini. Perbedaan terbesar adalah Anda harus mengunci port yang digunakan SQL Server karena secara default contoh bernama SQL Server TIDAK menggunakan 1433. Setelah Anda mengunci port, Anda juga perlu menentukan port itu alih-alih 1433 setiap kali kami merujuk port 1433 dalam panduan ini, termasuk pengaturan firewall dan pengaturan Load Balancer.
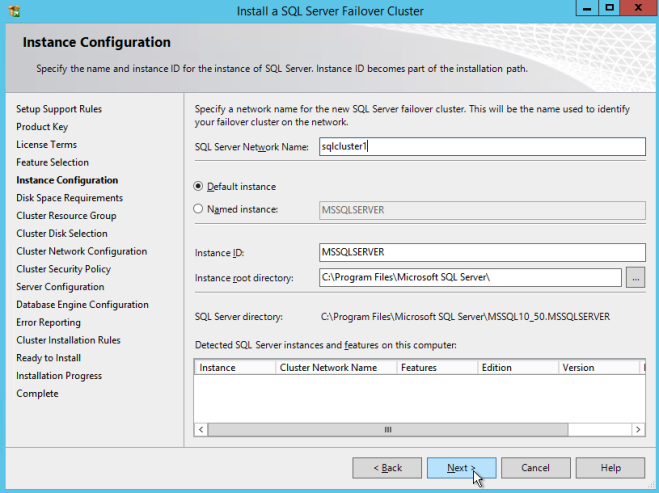


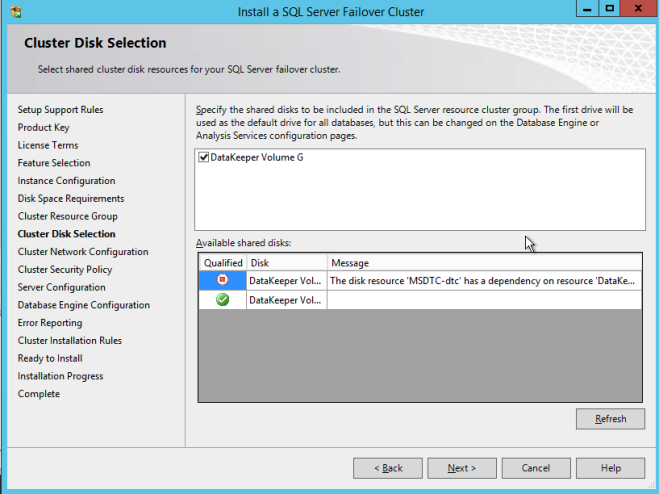
Di sini pastikan untuk menentukan alamat IP baru yang tidak digunakan. Ini adalah alamat IP yang sama yang akan kita gunakan nanti ketika kita mengkonfigurasi Internal Load Balancer nanti.

Seperti yang saya sebutkan sebelumnya, SQL Server 2008 R2 menggunakan Grup Keamanan AD. Jika Anda belum membuatnya, silakan dan buat sekarang seperti yang ditunjukkan di bawah ini sebelum Anda melanjutkan ke langkah berikutnya dalam instalasi SQL

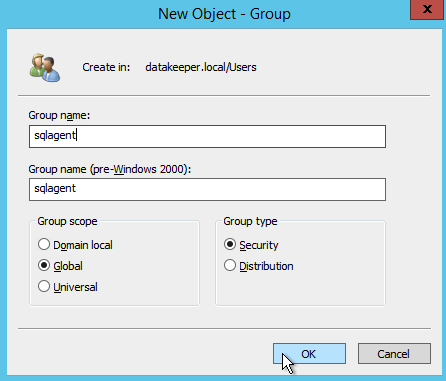
Tentukan Grup Keamanan yang Anda buat sebelumnya.
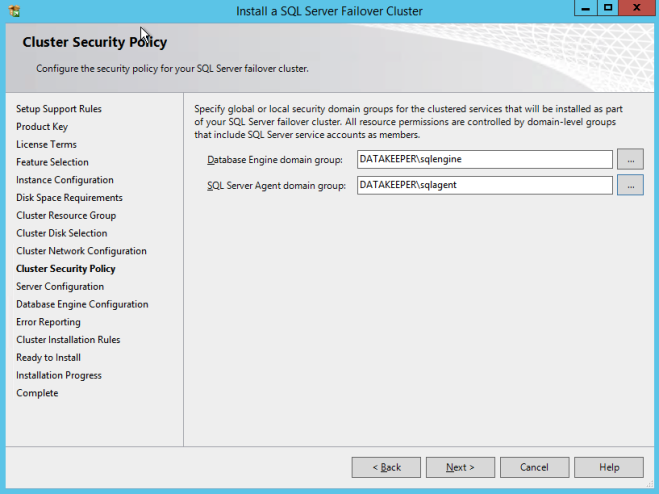
Pastikan akun layanan yang Anda tentukan adalah anggota Grup Keamanan terkait.

Tentukan administrator SQL Server Anda di sini.
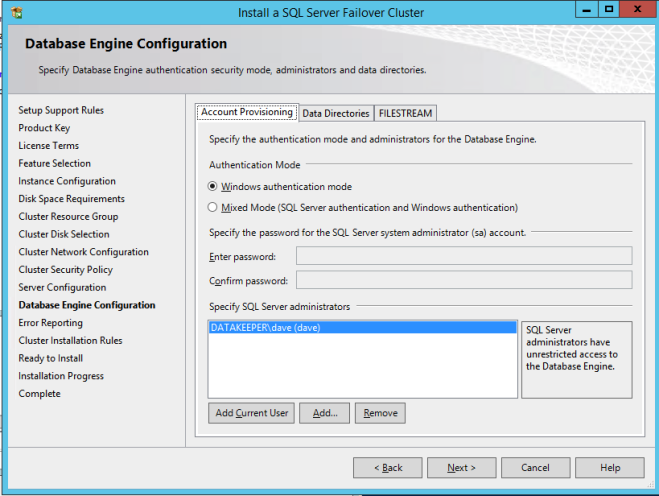

Jika semuanya berjalan dengan baik, Anda sekarang siap untuk menginstal SQL Server pada node kedua cluster.
INSTAL SQL SERVER PADA DATA KEDUA
Satu simpul kedua, jalankan SQL Server 2008 R2 dengan SP3 instal dan pilih Add Node ke SQL Server Failover Clustering Instance.

Lanjutkan dengan instalasi seperti yang ditunjukkan pada tangkapan layar berikut.



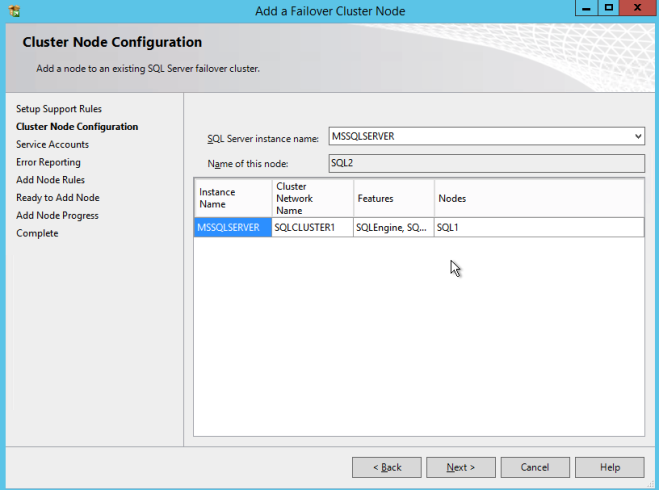



Dengan asumsi semuanya berjalan dengan baik, Anda sekarang harus memiliki dua node SQL Server 2008 R2 cluster yang dikonfigurasi yang terlihat seperti berikut ini.

Namun, Anda mungkin akan melihat bahwa Anda hanya bisa menyambungkan ke contoh SQL Server dari node cluster aktif. Masalahnya adalah bahwa Azure tidak mendukung ARP serampangan. Klien Anda mungkin tidak dapat terhubung langsung ke Alamat IP Cluster. Sebagai gantinya, klien harus terhubung ke Azure Load Balancer, yang akan mengarahkan ulang koneksi ke node aktif. Untuk membuat ini bekerja ada dua langkah: Buat Load Balancer dan Perbaiki SQL Server Cluster IP untuk menanggapi Load Balancer Probe dan gunakan subnet mask 255.255.255.255. Langkah-langkah tersebut dijelaskan di bawah ini.
BUAT BALANCER LOAD AZURE
Saya akan menganggap klien Anda dapat berkomunikasi langsung ke alamat IP internal SQL cluster. Mari kita lanjutkan untuk membuat Internal Load Balancer (ILB) dalam panduan ini. Jika Anda perlu mengekspos Instance SQL Anda di internet publik, gunakan Public Load Balancer sebagai gantinya. Di portal Azure, buat Load Balancer baru mengikuti tangkapan layar seperti yang ditunjukkan di bawah ini. UI portal Azure berubah dengan cepat. Tapi tangkapan layar ini akan memberi Anda informasi yang cukup untuk melakukan apa yang perlu Anda lakukan. Saya akan memanggil pengaturan penting saat kita melanjutkan. Di sini kita membuat ILB. Yang penting untuk dicatat pada layar ini adalah Anda harus memilih "Penugasan alamat IP statis". Tentukan alamat IP yang sama yang kami gunakan selama instalasi SQL Cluster juga. Karena saya menggunakan Zona Ketersediaan, saya melihat Zone Redundant sebagai opsi. Jika Anda menggunakan Set Ketersediaan, pengalaman Anda akan sedikit berbeda.

Di kolam Backend pastikan untuk memilih dua contoh SQL Server. Anda TIDAK ingin menambahkan File Share Witness Anda di pool.
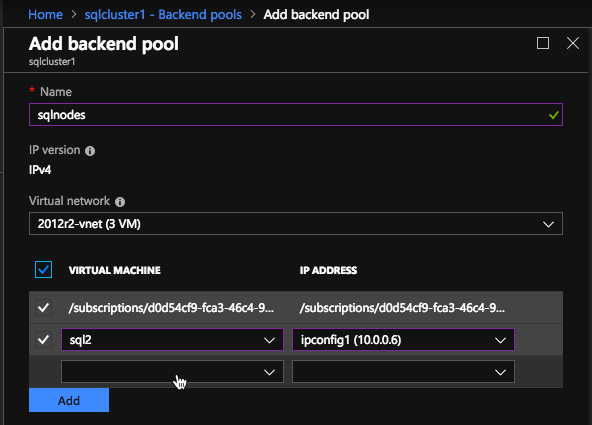
Di sini kita mengkonfigurasi Probe Kesehatan. Sebagian besar dokumentasi Azure menggunakan port 59999, jadi kami akan tetap menggunakan port itu untuk konfigurasi kami.

Kemudian kita akan menambahkan aturan load balancing. Dalam kasus kami, kami ingin mengarahkan semua lalu lintas SQL Server ke port TCP 1433 dari simpul aktif. Penting juga bahwa Anda memilih Floating IP (Direct Server Return) sebagai Diaktifkan.

JALANKAN POWERSHELL SCRIPT UNTUK MEMPERBARUI POINT AKSES KLIEN SQL
Sekarang kita harus menjalankan skrip Powershell di salah satu node cluster untuk memungkinkan Load Balancer Probe mendeteksi node mana yang aktif. Script juga menetapkan Subnet Mask dari SQL Cluster IP Address ke 255.255.255.255.255 sehingga ia menghindari konflik alamat IP dengan Load Balancer yang baru saja kita buat.
# Tentukan variabel
$ ClusterNetworkName = ""
nama jaringan kluster (Gunakan Get-ClusterNetwork di Windows Server 2012 of
lebih tinggi untuk menemukan nama)
$ IPResourceName = ""
# nama sumber daya Alamat IP
$ ILBIP = ""
# Alamat IP Internal Load Balancer (ILB) dan SQL Cluster
Impor-Modul FailoverClusters
# Jika Anda menggunakan Windows Server 2012 atau lebih tinggi:
Dapatkan-ClusterResource $ IPResourceName | Set-ClusterParameter
-Multiple @ {Alamat = $ ILBIP; ProbePort = 59999; SubnetMask = "255.255.255.255";
Network = $ ClusterNetworkName; EnableDhcp = 0}
# Jika Anda menggunakan Windows Server 2008 R2 gunakan ini:
#cluster res $ IPResourceName / priv enabledhcp = 0 address = $ ILBIP probeport = 59999
subnetmask = 255.255.255.255Ini akan terlihat seperti apa hasil jika dijalankan dengan benar.

Anda mungkin memperhatikan bahwa akhir skrip itu memiliki baris kode komentar untuk digunakan jika Anda menjalankan Windows Server 2008 R2. Menjalankan Windows Server 2008 R2? Pastikan Anda menjalankan kode khusus untuk Windows Server 2008 R2 pada prompt perintah, itu bukan Powershell.
LANGKAH SELANJUTNYA
Anda bukan yang pertama jika Anda sampai pada titik ini dan Anda masih tidak dapat terhubung ke cluster dari jarak jauh. Ada banyak hal yang bisa salah dalam hal keamanan, load balancer, port SQL, dll. Saya menulis panduan ini untuk membantu memecahkan masalah koneksi. Bahkan, saya mengalami beberapa masalah aneh dalam hal SQL Server TCP / IP Properties di SQL Server Configuration Manager. Ketika saya melihat properti saya tidak melihat alamat IP SQL Server Cluster sebagai salah satu alamat yang didengarkan. Karena itu saya harus menambahkannya secara manual. Saya tidak yakin apakah itu anomali. Meskipun itu tentu saja merupakan masalah yang harus saya selesaikan sebelum saya bisa terhubung ke cluster dari klien jarak jauh. Seperti yang saya sebutkan sebelumnya, satu perbaikan lain yang dapat Anda lakukan untuk instalasi ini adalah dengan menggunakan DataKeeper Non-Mirrored Volume Resource untuk TempDB. Jika Anda mengaturnya, harap perhatikan dua masalah konfigurasi berikut yang biasa dialami orang. Masalah pertama adalah jika Anda memindahkan tempdb ke folder pada simpul ke-1, Anda harus yakin untuk membuat struktur folder yang sama persis pada simpul kedua. Jika Anda tidak melakukan itu, ketika Anda mencoba untuk gagal SQL Server akan gagal untuk online karena tidak dapat membuat TempDB. Masalah kedua terjadi kapan saja Anda menambahkan Sumber Daya Volume DataKeeper lain ke SQL Cluster setelah cluster dibuat. Anda harus masuk ke properti sumber daya gugusan SQL Server dan membuatnya tergantung pada sumber daya Volume DataKeeper baru yang Anda tambahkan. Ini berlaku untuk volume TempDB dan volume lainnya yang dapat Anda putuskan untuk ditambahkan setelah cluster dibuat. Jika Anda memiliki pertanyaan tentang konfigurasi ini atau konfigurasi cluster lainnya, jangan ragu untuk menghubungi saya di Twitter @DaveBerm.






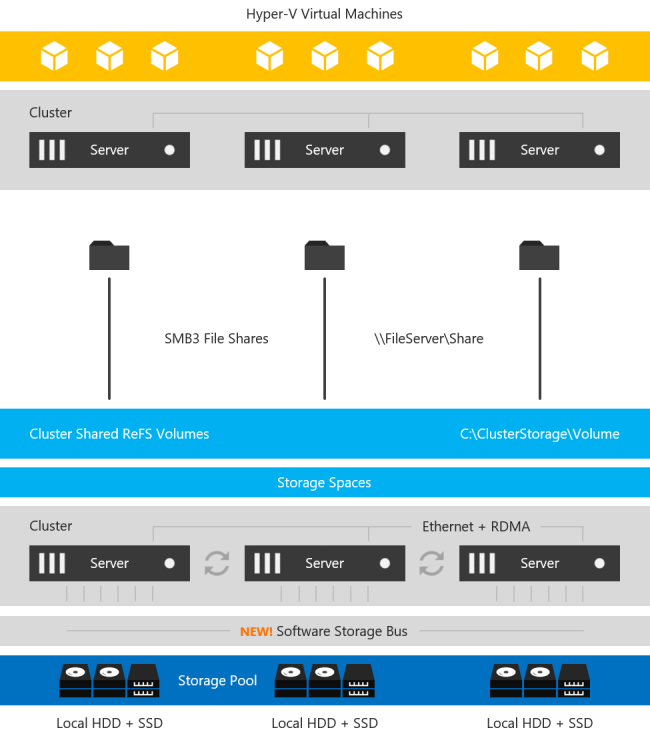

 Jika kita melihat grafik ini, kita melihat bahwa SIOS DataKeeper jelas memiliki beberapa keuntungan yang signifikan. Untuk satu, DataKeeper mendukung berbagai platform yang lebih luas, akan kembali ke Windows Server 2008 R2 dan SQL Server 2008 R2. Solusi S2D hanya mendukung rilis terbaru Windows dan SQL Server 2016/2017. S2D juga membutuhkan Edisi Datacenter Windows, yang dapat menambah biaya penyebaran Anda secara signifikan. Selain itu, SIOS memberikan sol
Jika kita melihat grafik ini, kita melihat bahwa SIOS DataKeeper jelas memiliki beberapa keuntungan yang signifikan. Untuk satu, DataKeeper mendukung berbagai platform yang lebih luas, akan kembali ke Windows Server 2008 R2 dan SQL Server 2008 R2. Solusi S2D hanya mendukung rilis terbaru Windows dan SQL Server 2016/2017. S2D juga membutuhkan Edisi Datacenter Windows, yang dapat menambah biaya penyebaran Anda secara signifikan. Selain itu, SIOS memberikan sol