
IO 병목 현상을 방지하는 방법: Windows 클라우드 배포를 위한 DataKeeper 인텐트 로그 배치 지침
최적의 애플리케이션 성능을 보장하기 위해 배포 시 SIOS 데이터 키퍼 배치하는 것이 중요합니다 의도 로그 (비트맵 파일)을 사용 가능한 가장 낮은 대기 시간 디스크에 저장하여 IO 병목 현상을 방지합니다. AWS, GCP 및 Azure에서 사용 가능한 가장 짧은 지연 시간 디스크는 임시 드라이브입니다. 그러나 Azure에서는 임시 드라이브를 사용하는 것과 Premium SSD를 사용하는 것의 차이가 최소화되므로 Azure에서 DataKeeper를 실행할 때 임시 드라이브를 사용할 필요가 없습니다. 그러나 AWS 및 GCP에서는 의도 로그를 임시 드라이브로 재배치하는 것이 필수적입니다. 그렇지 않으면 쓰기 처리량이 크게 영향을 받습니다.
비트맵 파일에 임시 디스크를 활용할 때 절충점이 있습니다. 임시 드라이브의 특성은 이 드라이브에 저장된 데이터의 지속성이 보장되지 않는다는 것입니다. 실제로 클라우드 인스턴스가 콘솔에서 중지되면 인스턴스에 연결된 임시 드라이브는 폐기되고 새 드라이브가 인스턴스에 연결됩니다. 이 프로세스에서 비트맵 파일은 삭제되고 비어 있는 새 비트맵 파일이 그 자리에 놓입니다.
비트맵 파일이 손실되면 완전한 재동기화가 발생하는 특정 시나리오가 있습니다. 예를 들어 주 서버가 SANless 클러스터 r이 콘솔에서 종료되면 장애 조치가 발생하지만 서버가 다시 온라인 상태가 되면 미러의 새 소스에서 이전 소스로 완전한 재동기화가 발생합니다. 이것은 자동으로 발생하므로 사용자는 어떤 조치도 취할 필요가 없으며 활성 노드는 이 재동기화 기간 동안 온라인 상태를 유지합니다.
비트맵 파일 배치가 성능에 영향을 줄 수 있는 다른 시나리오도 있습니다. 예를 들어 NVMe 드라이브를 복제하는 경우 NVMe 드라이브에 비트맵 파일을 보관할 작은 파티션을 만들고 싶을 것입니다. 일반적으로 비트맵 파일은 인스턴스에서 사용 가능한 가장 빠르고 대기 시간이 짧은 디스크에 있어야 합니다. 또한 다른 IO 작업으로 과도하게 부담되지 않는 디스크에 있어야 합니다.
의도 로그를 재배치하는 방법에 대한 정보는 다음에서 찾을 수 있습니다. DataKeeper 문서 . 의도 로그가 사용되는 방법에 대한 추가 정보는 DataKeeper 문서 .
의 허가를 받아 재생산 시오스




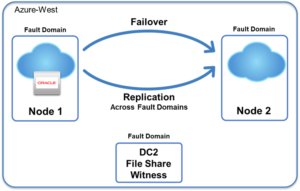
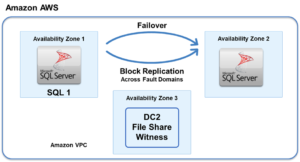

 일반 클러스터 환경에서 보호된 애플리케이션은 클러스터의 기본 노드에서 실행됩니다.해당 기본 노드의 애플리케이션 오류가 발생하는 경우 클러스터링 소프트웨어는 애플리케이션 작업을 기본 노드의 역할을 가정하는 보조 또는 원격 노드로 이동합니다. 주어진 시간에 하나의 기본 노드만 있습니다.
일반 클러스터 환경에서 보호된 애플리케이션은 클러스터의 기본 노드에서 실행됩니다.해당 기본 노드의 애플리케이션 오류가 발생하는 경우 클러스터링 소프트웨어는 애플리케이션 작업을 기본 노드의 역할을 가정하는 보조 또는 원격 노드로 이동합니다. 주어진 시간에 하나의 기본 노드만 있습니다.