วิธีป้องกันแอปพลิเคชันในแพลตฟอร์มคลาวด์ – คลัสเตอร์ SANless สำหรับสภาพแวดล้อมคลาวด์
ทำซ้ำโดยได้รับอนุญาตจาก SIOS
SIOS SANless clusters High-availability Machine Learning monitoring
ทำซ้ำโดยได้รับอนุญาตจาก SIOS

เว้นแต่คุณจะอยู่ใต้ก้อนหินหรือถูกแช่แข็งในเวลาที่คุณน่าจะเคยได้ยินจากแหล่งใดแหล่งหนึ่งว่านายจ้างและพนักงานอยู่ท่ามกลางกระแสที่เรียกว่า "การลาออกครั้งใหญ่"ตามที่รายงานใน US News and World Report “ตามรายงานของสำนักงานสถิติแรงงานสหรัฐ ชาวอเมริกัน 4 ล้านคนลาออกจากงานในเดือนกรกฎาคม พ.ศ. 2564 และแนวโน้มก็ไม่ชะลอตัวลง” ไม่ว่าขนาดบริษัทของคุณหรือกระแสรายได้ในปัจจุบัน หากยังไม่มี แนวโน้มนี้จะส่งผลกระทบต่อทีมไอทีของคุณในอนาคตอันใกล้ใช่ ปล่อยให้มันจมลงไปทีมเดียวกันที่รับผิดชอบในการตรวจสอบความพร้อมของแอปพลิเคชันที่สำคัญต่อภารกิจของคุณมีความเสี่ยงไม่ทางใดก็ทางหนึ่งต่อผลกระทบของ "The Great Resignation" แล้วคุณจำสัญญาณเตือนได้อย่างไร มาตกลงกับความเป็นจริงและนำทางด้วยความเอาใจใส่และชัดเจนผ่าน “การลาออกครั้งใหญ่” เพื่อไม่ให้เกิด “ภัยพิบัติครั้งใหญ่” สำหรับการใช้งานที่สำคัญของคุณ?
อย่าเลิก.อย่างจริงจัง!ในขณะที่เพื่อนร่วมงานและคนดี ๆ กำลังเลือกที่จะเปลี่ยนงาน อาชีพ หรือเลิกจ้างงาน การเลิกจ้างอาจเป็นสิ่งที่น่าดึงดูดใจโดยเฉพาะอย่างยิ่งเมื่อคุณเริ่มพิจารณาถึงโอกาสในการแบกภาระงานที่หนักอยู่แล้วด้วยม้านั่งที่สั้นลงแต่อย่าเลิก
แน่นอนว่ากระบวนการระบุความเสี่ยงนี้เป็นแบบสองง่าม หลังจากการลาออก ทีมของคุณมีความเสี่ยงจากการเปลี่ยนแปลงบุคลากรเพิ่มเติมแต่ความพร้อมใช้งานสูงของคุณก็มีความเสี่ยงเช่นกันเนื่องจากสูญเสียความสามารถ ความรู้ด้านเทคนิค หรือความเชี่ยวชาญเพื่อป้องกันไม่ให้องค์กรของคุณประสบปัญหาการหยุดทำงานโดยไม่ได้วางแผนหลังจากการลาออกของทีมใหม่ คุณจะต้องระบุความเสี่ยงที่สำคัญความเสี่ยงทางเทคนิคบางประการ ได้แก่:
หลายครั้งที่ผู้คนเริ่มออกจากบริษัท มันง่ายมากที่จะพูดว่า "พวกเขา ไม่ใช่เรา!" เราต้องการเน้นที่เหตุผลทั้งหมดว่าทำไมปัญหาจึงทำให้พวกเขาลาออก ลาออก หรือเลือกอาชีพหรืองานอื่นค่อนข้างเป็นไปได้ที่เหตุผลในการจากไปเป็นเรื่องส่วนตัว แต่บางครั้ง ปัญหาก็อยู่ที่กระจกเงาและไม่ใช่พวกเขา แต่เป็นเราเหตุใดการค้นหาว่าเป็นปัญหากับพวกเขาหรือคุณมีความสำคัญต่อ HA หรือไม่ถ้าปัญหาอยู่ที่บริษัทของคุณ เช่น พันธกิจ วิสัยทัศน์ วัฒนธรรมเกี่ยวกับ HA และ IT หรือปัญหาการว่าจ้างและการจัดพนักงานสำหรับการจัดการระบบ IT และ HA เพียงแค่เพิ่มจำนวนพนักงานก็จะเป็นการแก้ไขชั่วคราวนอกจากนี้ ความเสี่ยงต่อขวัญกำลังใจของทีม ความมุ่งมั่น และการถ่ายทอดความรู้อาจถูกลดทอนลงไปอีก เนื่องจากยังคงให้ความสำคัญกับการเปลี่ยนโทษและการแก้ปัญหา
เกือบทุกบริษัทมีคนลาออกจากทีมในช่วงสองปีที่ผ่านมาไม่ว่าพวกเขาจะแสวงหาค่าจ้างที่สูงขึ้น อยู่บ้านเพื่อดูแลสมาชิกในครอบครัว เกษียณอายุ หรือแสวงหาทางเลือกอื่น ๆ พวกเขาก็ต้องจากไปหากคุณสูญเสียสมาชิกในทีม การประเมินทีมที่เหลืออยู่เป็นสิ่งสำคัญการประเมินนี้จะมีลักษณะทางเทคนิคและไม่ใช่ทางเทคนิคในทางเทคนิค คุณจะต้อง: ก. ระบุทักษะ ความสามารถ และช่องว่างความรู้ในปัจจุบัน ทักษะใดที่เหลืออยู่ในทีม และความเชี่ยวชาญทางเทคนิคและความสามารถระดับใด ช่องว่างความรู้ระหว่าง โดยเฉพาะระหว่างทฤษฎีกับการปฏิบัติอยู่ที่ไหน
ข. ทำความเข้าใจทั้งบทบาทที่มีอยู่และที่ขาดหายไปสมาชิกในทีมของคุณหลายคนอาจมีหน้าที่และความรับผิดชอบหลายอย่างการสูญเสียสมาชิกในทีมคนเดียวอาจหมายถึงการสูญเสียความคุ้มครองในหลายบทบาทและความรับผิดชอบ
ค. ประเมินความต้องการการฝึกอบรมหรือเสริมทันที คุณได้รับการคุ้มครองที่ใด แต่ต้องการการฝึกอบรมเพิ่มเติมเพื่อให้ทีมมีเสถียรภาพและมั่นคง? พื้นที่ใดที่คุณขาดความคุ้มครองที่สามารถบรรเทาได้ด้วยการฝึกอบรมบุคลากรที่มีอยู่หรือรูปแบบบริการมืออาชีพด้านสัญญาบางรูปแบบ?ในฐานะ VP of Customer Experience ดูสิ่งนี้โดยตรง เมื่อเร็วๆ นี้ ทีมงานของเราทำงานร่วมกับบริษัทที่ต้องการบริการอย่างมืออาชีพหลังจากสูญเสียสมาชิกในทีมหลักที่รับผิดชอบต่อสภาพแวดล้อม HA ของพวกเขาไป
ที่ไม่ใช่ทางเทคนิค คุณจะต้อง: ก. เข้าใจว่าสมาชิกในทีมที่เหลือรู้สึกอย่างไร แม้กระทั่งก่อนเกิดการระบาดของโควิด-19 และช่วง “การลาออกครั้งใหญ่” หลายทีมต่างก็วิ่งหนีควัน โลกแห่ง HA ที่เปิดตลอด 24 ชั่วโมงทุกวันทิ้งงานมากมายที่ต้องทำให้เสร็จด้วยหมายเลขทีม บรรทัดฐาน และงานตามปกติหากทีมของคุณได้รับผลกระทบ การเช็คอินและฟังเรื่องราวของสมาชิกในทีมที่เหลืออยู่นั้นมีความสำคัญพอๆ กับเซิร์ฟเวอร์ที่ใช้งานจริงค้นหาว่าใครกำลังหมดแรง หมดไฟ สับสน ใกล้จะพังหรือในทางกลับกัน เต็มไปด้วยชีวิตชีวาและพร้อมสำหรับความท้าทายครั้งใหม่ อย่าลืมฟังสัญญาณด้วยวาจาและอวัจนภาษา เห็นอกเห็นใจ (ไม่ใช่แค่กับการสูญเสียเพื่อนร่วมงาน แต่ด้วยอารมณ์ ความกังวล และความกลัวของพวกเขา)
ข. ทำความเข้าใจเหตุผลที่สมาชิกในทีมที่เหลืออยู่ยังคงอยู่บนเรือ การรู้ว่าสมาชิกในทีมรู้สึกอย่างไรเป็นทั้งความจำเป็นทางเทคนิคและไม่ใช่ทางเทคนิค แต่เกือบเท่ากับงานนี้คือการหาเหตุผลที่ทำให้พวกเขาอยู่ต่อแน่นอน เหตุผลบางอย่างอาจทำให้คุณประหลาดใจผู้เขียนและวิทยากร Carey Nieuwhof กล่าวว่าสมาชิกในทีมบางคนอยู่เพียงเพราะพวกเขา “รู้สึกติดอยู่กับทีมเพราะพวกเขาไม่ได้ออกไปก่อน” เหตุผลอื่นๆ ที่สมาชิกในทีมอยู่ต่ออาจไม่ทำให้คุณประหลาดใจ แต่ไม่ว่าจะด้วยเหตุผลใดก็ตาม ความสะดวกสบาย โอกาส เงินเดือน สถานที่ ทางเลือกหุ้น ความหลงใหล การทำงานเป็นทีม วัฒนธรรม เหตุผลทั้งหมดที่สมาชิกในทีมของคุณอยู่นั้นมีความสำคัญ
ค. ประเมินผลกระทบของการเป็นคนมือสั้น เห็นได้ชัดว่ามีองค์ประกอบทางเทคนิคของการถูกกล่าวถึงก่อนหน้านี้ การประเมินช่องว่างทักษะ ฯลฯ แต่มีข้อบ่งชี้ในการประเมินทางเทคนิคของการเป็นคนถนัดมือสั้น และนั่นไม่ใช่เทคนิคให้แน่ใจว่าได้ประเมินและประเมินผลกระทบที่จะมีผลกระทบต่อจิตใจ อารมณ์ และสุขภาพส่วนบุคคลของสมาชิกในทีมที่เหลืออยู่แม้เพียงชั่วครู่เท่านั้นในช่วงเริ่มต้นอาชีพการเป็นผู้จัดการ ทีมงานของเราจัดการกับเหตุการณ์ที่ลดขนาดลงซึ่งทำให้พนักงานหลายคนอ่อนแอทางอารมณ์และเหนื่อยล้าทางจิตใจสิ่งนี้นำไปสู่ความเหนื่อยล้าที่สูงขึ้น มีหมอกในจิตใจมากขึ้น และเพิ่มอัตราข้อบกพร่องและข้อผิดพลาดของสมาชิกในทีมเหล่านั้นหากทีมของคุณได้รับผลกระทบอย่างรุนแรงทั้งทางร่างกายและจิตใจจากการมีสมาธิสั้น ความเสี่ยงต่อ HA ของคุณอาจเพิ่มขึ้นทีมของคุณอาจแย่งชิงเพื่อเอาตัวหย่อน และพวกเขาอาจชุมนุมอย่างรวดเร็วเพื่อครอบคลุมสำหรับหัวหน้าหรือสมาชิกในทีมที่ลาออก แต่สิ่งสำคัญคือคุณต้องเข้าใจว่าผู้ที่ยังคงอยู่นั้นหมดแรง รู้สึกติดกับดัก หรือมีความเสี่ยงที่จะ ออกจาก.
หลายปีก่อน ผู้บริหารระดับสูงลาออกจากบริษัทแม้จะเปลี่ยนบทบาทและงานตลอดเกือบหนึ่งปีของการเปลี่ยนแปลง แต่ก็ยังมีบทบาทและงานที่สร้างความประหลาดใจให้กับพนักงานที่เหลืออยู่ในการลาออกในปัจจุบันนี้ คุณไม่มีช่วงเปลี่ยนผ่านทั้งปีนอกจากนี้ หากทีมของคุณมีประสบการณ์การลาออกมากกว่าหนึ่งครั้ง คุณอาจยังวิเคราะห์และเปลี่ยนบุคคลแรกไม่เสร็จ ดังนั้นจึงเป็นสิ่งสำคัญมากในการระบุและจัดลำดับความสำคัญของงานที่สำคัญที่สุด และมอบหมายความรับผิดชอบ อย่าลืมแสดงรายการงานต่างๆ เช่น การสแกนความปลอดภัย การอัปเดต การบำรุงรักษา การสำรองข้อมูล การทดสอบ การปรับใช้แอปพลิเคชันใหม่ การวิเคราะห์ต้นทุน การโคลนและการปรับใช้อิมเมจใหม่ แอปพลิเคชันแพตช์ และการแก้ไขช่องโหว่งานเหล่านี้ทั้งหมดยังคงมีความจำเป็นแม้ว่าจะสูญเสียไปและอาจส่งผลร้ายแรงได้หากปล่อยทิ้งไว้
งาน บทบาท และความรับผิดชอบยังคงต้องได้รับการคุ้มครองปัญหาวิกฤตจะต้องได้รับการแก้ไขการหยุดทำงานโดยไม่ได้วางแผนจะไม่รอที่จะเกิดขึ้นหลังจากที่คุณสร้างพนักงานของคุณขึ้นใหม่ ฝึกอบรมบุคลากรที่มีอยู่ และติดตั้งบริษัทของคุณให้มีความยืดหยุ่นมากขึ้นต่อการเปลี่ยนแปลงและการเปลี่ยนแปลงของการลาออกครั้งใหญ่เพื่อนำทางในระยะสั้น คุณจะต้องพัฒนาแผนระยะสั้นที่ชาญฉลาดและบรรลุผลได้จริงแผนนี้ควรจัดทำแผนผังขั้นตอน งาน และกระบวนการที่ระบุเพื่อให้การบำรุงรักษาและการดำเนินการสามารถดำเนินต่อไปได้นอกจากนี้ ควรกำหนดวิธีการจัดการนโยบายโครงสร้างพื้นฐานที่สำคัญที่มีอยู่อย่างรอบคอบตลอดฤดูกาลที่วุ่นวายที่จะมาถึง
ขั้นตอนก่อนหน้านี้นำไปสู่สิ่งนี้ด้วยการประเมินทีมปัจจุบัน และการระบุความเสี่ยงที่สำคัญของคุณ และแผนการเปลี่ยนแปลงในขั้นตอนต่อไปคือการมุ่งเน้นไปที่อนาคต คุณยังคงมีภารกิจคุณยังมีแอปพลิเคชันที่สำคัญซึ่งจำเป็นต้องมีความพร้อมใช้งานสูงคุณยังมีข้อมูลที่จำเป็นต้องได้รับการปกป้อง ขุด จำลอง และพร้อมใช้งานสำหรับธุรกิจของคุณเริ่มวางแผนสำหรับทีมในอนาคต
ไม่ใช่ข่าวทั้งหมดที่เกี่ยวกับ “การลาออกครั้งใหญ่” จะเป็นข่าวร้ายสำหรับทีมและ HA ของคุณหลังจากที่สมาชิกในทีมออกจากตำแหน่งและโอกาสใหม่หรือแตกต่างกัน คุณมีโอกาสที่แท้จริงและหายากที่จะนำข้อมูลทั้งหมดของการประเมินของคุณมาเปลี่ยนเป็นเครื่องมือสำหรับการเติบโตและการจัดตำแหน่งและอนาคต HA ที่ดีขึ้นการสร้างอนาคตที่สดใสนี้รวมถึงการกำหนดหน้าที่ บทบาท และทักษะที่จำเป็น การปรับปรุงสถาปัตยกรรมและการออกแบบ การวางแผนสำหรับการว่าจ้างใหม่และการบริการ และการมุ่งเน้นที่การสร้างทีมที่มีสุขภาพดีขึ้น
ฉันได้พูดถึงเรื่องนี้โดยละเอียดมากขึ้นในครั้งล่าสุดนี้ สัมภาษณ์ ทีเอฟ.-Cassius Rhue, VP, ประสบการณ์ลูกค้าทำซ้ำจาก SIOS

เวลาหยุดทำงานมีราคาแพงกว่าที่เคยเป็นมาสำหรับธุรกิจสมัยใหม่ การสำรวจค่าใช้จ่ายรายชั่วโมงของการหยุดทำงานของ ITIC 2021 พบว่า 91% ขององค์กร การหยุดทำงานหนึ่งชั่วโมงในระบบ ฐานข้อมูล หรือแอปพลิเคชันที่สำคัญต่อธุรกิจมีค่าใช้จ่ายเฉลี่ยมากกว่า 300,000 ดอลลาร์ และสำหรับองค์กรขนาดใหญ่ 18% ต้นทุนของ เวลาหยุดทำงานหนึ่งชั่วโมงเกิน 5 ล้านเหรียญ
ความพร้อมใช้งานสูง (HA) เป็นคุณลักษณะของระบบ ฐานข้อมูล หรือแอปพลิเคชันที่ออกแบบมาให้ทำงานอย่างต่อเนื่องและเชื่อถือได้เป็นระยะเวลานาน เป้าหมายของ HA คือการลดหรือขจัดการหยุดทำงานโดยไม่ได้วางแผนไว้สำหรับแอปพลิเคชันที่สำคัญ ซึ่งทำได้โดยการกำจัดจุดล้มเหลวเพียงจุดเดียวด้วยการผสมผสานส่วนประกอบที่ซ้ำซ้อนและเทคโนโลยีอื่นๆ เข้ากับการออกแบบระบบ ฐานข้อมูล หรือแอปพลิเคชันที่มีความสำคัญต่อธุรกิจ
ข้อตกลงระดับบริการ (SLA) ถูกใช้โดยผู้ให้บริการเพื่อรับประกันว่าระบบ ฐานข้อมูล หรือแอปพลิเคชันที่มีความสำคัญต่อธุรกิจของลูกค้าจะพร้อมใช้งานเมื่อธุรกิจต้องการ
IDC ได้สร้างแบบจำลอง SLA ที่กำหนดความต้องการเวลาทำงานที่ห้าระดับดังนี้:
จากข้อมูลของ ITIC 89% ขององค์กรที่ทำการสำรวจต้องการความพร้อมใช้งาน "สี่เก้า" สำหรับระบบ ฐานข้อมูล และแอปพลิเคชันที่มีความสำคัญต่อธุรกิจของพวกเขา และ 35% ขององค์กรเหล่านั้นพยายามที่จะบรรลุความพร้อมใช้งาน "ห้าเก้า"
นอกจากเวลาทำงานและความพร้อมใช้งานแล้ว ตัวชี้วัด HA ที่สำคัญอีกสองรายการคือ วัตถุประสงค์เวลาพักฟื้น (RTO) และ วัตถุประสงค์ของจุดพักฟื้น (RPO) RTO คือระยะเวลาสูงสุดที่ยอมรับได้ของการหยุดทำงาน และ RPO คือจำนวนการสูญเสียข้อมูลสูงสุดที่สามารถยอมรับได้เมื่อเกิดความล้มเหลวขึ้น ไม่เหมือนกับตัววัด RTO และ RPO สำหรับการกู้คืนจากความเสียหายซึ่งโดยทั่วไปกำหนดไว้เป็นชั่วโมงและวัน ตัววัด RTO และ RPO สำหรับระบบ ฐานข้อมูล และแอปพลิเคชันที่มีความสำคัญต่อธุรกิจมักใช้เวลาเพียงไม่กี่วินาที (RTO) และศูนย์ (RPO)
การทำคลัสเตอร์ HA โดยทั่วไปประกอบด้วยโหนดเซิร์ฟเวอร์ ที่เก็บข้อมูล และซอฟต์แวร์การทำคลัสเตอร์
คลัสเตอร์ HA ภายในองค์กรแบบดั้งเดิมคือกลุ่มของโหนดเซิร์ฟเวอร์ตั้งแต่สองโหนดขึ้นไปที่เชื่อมต่อกับที่เก็บข้อมูลที่ใช้ร่วมกัน (โดยทั่วไปคือ เครือข่ายพื้นที่จัดเก็บ หรือ SAN) ที่ได้รับการกำหนดค่าด้วยระบบปฏิบัติการ ฐานข้อมูล และแอปพลิเคชันเดียวกัน (ดู รูปที่ 1 ).
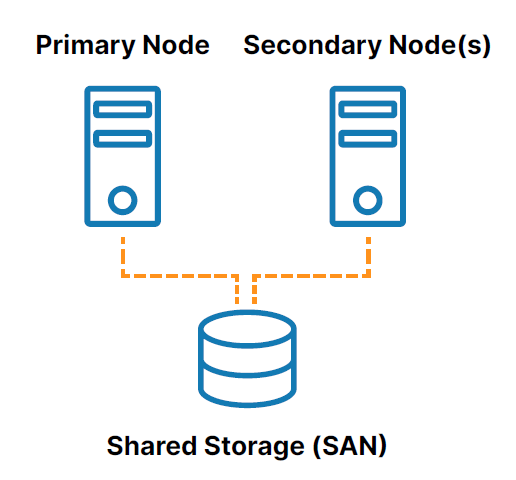
โหนดหนึ่งถูกกำหนดให้เป็นโหนดหลัก (หรือแอ็คทีฟ) และโหนดอื่น ๆ ถูกกำหนดให้เป็นโหนดรอง (หรือสแตนด์บาย) หากโหนดหลักล้มเหลว การทำคลัสเตอร์จะช่วยให้ระบบ ฐานข้อมูล หรือแอปพลิเคชันสามารถข้ามไปยังโหนดรองอย่างน้อยหนึ่งโหนดได้โดยอัตโนมัติ และทำงานต่อไปโดยมีการหยุดชะงักน้อยที่สุด เนื่องจากโหนดรองเชื่อมต่อกับที่เก็บข้อมูลเดียวกัน การดำเนินการจึงดำเนินต่อไปโดยที่ข้อมูลสูญหายเป็นศูนย์
อย่างไรก็ตาม การใช้พื้นที่จัดเก็บแบบแบ่งใช้ในรูปแบบการทำคลัสเตอร์แบบเดิมสร้างความท้าทายหลายประการ ได้แก่:
SANless หรือคลัสเตอร์ "ไม่แชร์อะไร" (ดู รูปที่ 2 ) จัดการกับความท้าทายที่เกี่ยวข้องกับการจัดเก็บข้อมูลที่ใช้ร่วมกัน ในการกำหนดค่าเหล่านี้ ทุกโหนดคลัสเตอร์มีที่เก็บข้อมูลในเครื่องของตัวเอง การจำลองแบบระดับบล็อกตามโฮสต์ที่มีประสิทธิภาพใช้เพื่อซิงโครไนซ์หน่วยเก็บข้อมูลบนโหนดคลัสเตอร์ โดยคงไว้ซึ่งความเหมือนกัน ในกรณีเกิดเฟลโอเวอร์ โหนดรองจะเข้าถึงสำเนาที่เหมือนกันของหน่วยเก็บข้อมูลที่ใช้โดยโหนดหลัก
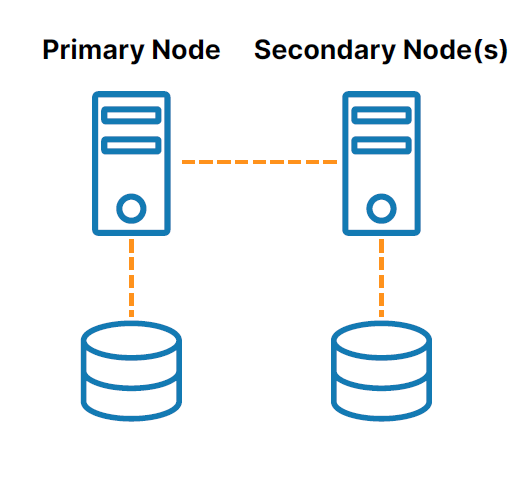
ซอฟต์แวร์การทำคลัสเตอร์ช่วยให้คุณกำหนดค่าเซิร์ฟเวอร์ของคุณเป็นคลัสเตอร์เพื่อให้เซิร์ฟเวอร์หลายเครื่องสามารถทำงานร่วมกันเพื่อจัดหา HA และป้องกันการสูญหายของข้อมูล โซลูชันซอฟต์แวร์การทำคลัสเตอร์ที่หลากหลายพร้อมใช้งานสำหรับ Windows, Linux distribution และ virtual machine hypervisors ต่างๆ อย่างไรก็ตาม โซลูชันแต่ละอย่างจำกัดความยืดหยุ่นและตัวเลือกการปรับใช้ของคุณ และนำเสนอความท้าทายต่างๆ เช่น ความซับซ้อนทางเทคนิคและการให้สิทธิ์ใช้งานที่มีราคาแพง
HA มีความสำคัญต่อระบบ ฐานข้อมูล และแอปพลิเคชันที่มีความสำคัญต่อธุรกิจ แต่ด้วยแพลตฟอร์มที่มีอยู่มากมาย ความซับซ้อนก็เพิ่มขึ้นอย่างมาก นั่นเป็นเหตุผลที่โซลูชันที่รับรู้แอปพลิเคชันนั้นสมเหตุสมผลมาก สิ่งที่คุณต้องการคือพันธมิตรที่เชื่อถือได้ซึ่งมีความเชี่ยวชาญอย่างกว้างขวางในด้านความพร้อมใช้งานสูง—พันธมิตรเช่น SIOS ซึ่งมีความรู้ทางเทคโนโลยีเพื่อให้แน่ใจว่าธุรกิจของคุณจะดำเนินต่อไป
อย่ารอให้ไฟดับหรือภัยพิบัติเพื่อดูว่าคุณมีความยืดหยุ่นที่ธุรกิจของคุณต้องการหรือไม่ กำหนดเวลาการสาธิตส่วนบุคคลวันนี้ที่ https://us.sios.com เพื่อดูว่า SIOS สามารถทำอะไรกับธุรกิจของคุณได้บ้าง
สืบพันธุ์จาก SIOS

คลัสเตอร์ล้มเหลวเป็นวิธีหนึ่งในการมอบการป้องกันความพร้อมใช้งานสูงสำหรับแอปพลิเคชันโดยกำจัดจุดล้มเหลวเพียงจุดเดียวด้วยการเรียกใช้ระบบปฏิบัติการและฐานข้อมูลและแอปพลิเคชันเดียวกันบนเซิร์ฟเวอร์หลายเครื่องซึ่งทั้งหมดใช้ที่เก็บข้อมูลเดียวกันหรือเชื่อมต่อกับที่เก็บข้อมูลที่มีการซิงโครไนซ์อย่างต่อเนื่อง Oracle ทำงานบนหนึ่งในเซิร์ฟเวอร์เหล่านี้ ซึ่งเรียกว่าเซิร์ฟเวอร์หลัก หากล้มเหลว ซอฟต์แวร์การจัดการแอปพลิเคชัน (ซอฟต์แวร์การจัดกลุ่ม) จะย้ายการดำเนินการไปยังเซิร์ฟเวอร์สำรองอย่างน้อยหนึ่งเครื่องในกระบวนการที่เรียกว่าเฟลโอเวอร์ เนื่องจากเซิร์ฟเวอร์หลักและเซิร์ฟเวอร์ระยะไกลเข้าถึงที่เก็บข้อมูลเดียวกันหรือเหมือนกัน การทำงานของ Oracle จึงสามารถดำเนินการต่อได้โดยใช้เวลากู้คืนน้อยที่สุดหรือข้อมูลสูญหาย หลายองค์กรถือว่า Oracle เป็นแกนหลักของการดำเนินงาน โดยเฉพาะอย่างยิ่งหากพวกเขาใช้ระบบ SAP ที่ใช้ Oracle หรือ Oracle ERP System
ซอฟต์แวร์การทำคลัสเตอร์ของ Oracle เรียกว่า Oracle Real Application Clusters (RAC) RAC "ช่วยให้คุณสามารถรวมเซิร์ฟเวอร์สินค้าโภคภัณฑ์ที่มีขนาดเล็กลงในคลัสเตอร์เพื่อสร้างสภาพแวดล้อมที่ปรับขนาดได้ซึ่งสนับสนุนแอปพลิเคชันทางธุรกิจที่สำคัญต่อภารกิจ"[1] ด้วย Oracle RAC คุณสามารถจัดคลัสเตอร์ฐานข้อมูล Oracle และใช้ Oracle Clusterware เพื่อเชื่อมต่อหลายเซิร์ฟเวอร์ เพื่อให้ทำงานเป็นระบบเดียว
ในขณะที่ RAC ถูกรวมเข้ากับ Oracle Database Standard Edition ก่อนหน้านี้ (โดยไม่มีค่าใช้จ่ายเพิ่มเติม) ตอนนี้ Oracle ได้นำคุณลักษณะ RAC ออกจาก Standard Edition จากเวอร์ชัน 19c เป็นต้นไป คุณสามารถซื้อ Oracle RAC ได้โดยมีค่าใช้จ่ายเพิ่มเติมด้วย Oracle Database Enterprise Edition น่าเสียดาย นี่หมายความว่าลูกค้าที่ต้องการใช้ RAC จะต้องอัปเกรดเป็น Oracle Database Enterprise หรือย้ายไปยัง Oracle Cloud ซึ่งทั้งสองวิธีนี้เป็นโซลูชันที่มีราคาแพงกว่า Standard Edition อย่างมาก
SIOS มอบโซลูชันการทำคลัสเตอร์ Oracle ที่มีความพร้อมใช้งานสูงโดยไม่ต้องอัปเกรดเป็น Enterprise Edition ซึ่งช่วยประหยัดค่าใช้จ่ายในการออกใบอนุญาตได้มากถึง 70 เปอร์เซ็นต์
ดิ SIOS Protection Suite สำหรับ Linux ให้การผสานรวมอย่างแน่นหนาของคลัสเตอร์เฟลโอเวอร์ที่มีความพร้อมใช้งานสูง การตรวจสอบแอปพลิเคชันอย่างต่อเนื่อง การจำลองข้อมูล และนโยบายการกู้คืนที่กำหนดค่าได้ ปกป้องฐานข้อมูล Oracle และแอปพลิเคชันของคุณจากการหยุดทำงานและภัยพิบัติ ไม่เหมือนกับโซลูชันการทำคลัสเตอร์อื่นๆ ที่ตรวจสอบเฉพาะการทำงานของเซิร์ฟเวอร์ SIOS LifeKeeper จะตรวจสอบความสมบูรณ์ของเซิร์ฟเวอร์ การเชื่อมต่อเครือข่าย ที่เก็บข้อมูล กระบวนการของ Oracle ทั้งหมด และแอปพลิเคชันที่เกี่ยวข้อง ปัญหาจะได้รับการแก้ไขทันทีด้วยชุดการดำเนินการที่กำหนดนโยบายเพื่อให้มั่นใจว่าจะกู้คืนได้อย่างรวดเร็วโดยไม่รบกวนผู้ใช้ปลายทาง
SIOS Protection Suite สามารถทำงานในสภาพแวดล้อมที่จัดเก็บข้อมูลที่ใช้ร่วมกัน (SAN) เพื่อรองรับคลัสเตอร์ HA แบบเดิม หรือในการกำหนดค่าพื้นที่จัดเก็บข้อมูลที่ไม่มีการแชร์ (SANless) ในระบบคลาวด์ ไฮบริด และสภาพแวดล้อมอื่นๆ ที่พื้นที่จัดเก็บข้อมูลที่ใช้ร่วมกันทำไม่ได้หรือเป็นไปไม่ได้ นำเสนอคลัสเตอร์ที่แข็งแกร่ง หลากหลาย และกำหนดค่าได้ง่าย พร้อมนโยบายการกู้คืนระบบเฟลโอเวอร์/เฟลแบ็คแบบอัตโนมัติและด้วยตนเองสำหรับฐานข้อมูลและแอปพลิเคชัน Oracle ของคุณ
SIOS Protection Suite สำหรับ Linux ประกอบด้วย:
SIOS LifeKeeper รองรับการกระจาย Linux ที่สำคัญทั้งหมด รวมถึง Red Hat Enterprise Linux, SUSE Linux Enterprise Server, CentOS และ Oracle Linux และรองรับสถาปัตยกรรมการจัดเก็บข้อมูลที่หลากหลาย ซอฟต์แวร์ SIOS ได้รับการปรับและปรับให้เหมาะสมเพื่อให้ทำงานบนระบบปฏิบัติการเหล่านี้ และส่วนประกอบได้รับการทดสอบเพื่อให้แน่ใจว่าโซลูชันคลัสเตอร์ SANless จะทำงานในแต่ละระบบปฏิบัติการ
ด้วย SIOS Protection Suite สำหรับ Linux คุณสามารถเรียกใช้แอปพลิเคชัน Oracle ของคุณในสภาพแวดล้อมคลาวด์สาธารณะที่ยืดหยุ่นและปรับขนาดได้ เช่น Amazon Web Services (AWS) หรือ Microsoft Azure โดยไม่ต้องล็อกอินจากผู้ขายหรือลดประสิทธิภาพการทำงาน ความพร้อมใช้งานสูง หรือการป้องกันภัยพิบัติ .
SIOS Protection Suite สำหรับ Linux บน AWS หรือ Azure มีองค์ประกอบที่คุณต้องการเพื่อสร้างคลัสเตอร์ Linux ที่มีความพร้อมใช้งานสูงทั่วทั้ง Fault Domains บนระบบคลาวด์และ Availability Zone ที่ให้คุณแยกพื้นที่ทางภูมิศาสตร์สำหรับการป้องกันจากภัยพิบัติและการหยุดทำงานทั่วทั้งไซต์และระดับภูมิภาค
ในสภาพแวดล้อม Windows Server Failover Clustering (WSFC) คุณสามารถใช้ SIOS DataKeeper Cluster Edition เพื่อซิงโครไนซ์ที่เก็บข้อมูลในเครื่องโดยใช้การจำลองแบบโฮสต์ที่มีประสิทธิภาพสำหรับการทำคลัสเตอร์ SANlessSIOS DataKeeper Cluster Edition ซอฟต์แวร์ปกป้องสภาพแวดล้อม Windows ที่มีความสำคัญต่อธุรกิจของคุณ รวมถึง Oracle จากการหยุดทำงานและการสูญหายของข้อมูล
ซอฟต์แวร์คลัสเตอร์ SIOS SANless ให้ความพร้อมใช้งาน ความน่าเชื่อถือ และความยืดหยุ่นสูงระดับองค์กรที่จำเป็นสำหรับฐานข้อมูลและแอปพลิเคชัน Oracle เมื่อทำงานในสภาพแวดล้อม VMware, Hyper-V, KVM และ XenServer
SIOS Protection Suite สำหรับ Linux ปกป้องฐานข้อมูล Oracle และแอปพลิเคชันที่ทำงานบน Linux ในสภาพแวดล้อมเสมือน หากคุณใช้งาน Oracle บน Windows ในสภาพแวดล้อมเสมือน SIOS DataKeeper Cluster Edition จะปกป้องสภาพแวดล้อม Windows ที่มีความสำคัญต่อธุรกิจของคุณ รวมถึงฐานข้อมูลและแอปพลิเคชัน Oracle ของคุณ
SIOS เสนอการจำลองข้อมูลแบบบูรณาการ ความพร้อมใช้งานสูง การจัดกลุ่มและ การกู้คืนระบบ โซลูชันที่สนับสนุน Oracle บนทั้ง Linux และ Windows เพื่อให้การป้องกันแบบยืดหยุ่นต่อข้อผิดพลาดสำหรับองค์กรขนาดเล็กและขนาดใหญ่ โดยมีค่าใช้จ่ายเพียงเล็กน้อยเมื่อเทียบกับโซลูชันการทำคลัสเตอร์ของ Oracle อื่นๆ ด้วยคลัสเตอร์ SIOS SANless คุณไม่จำเป็นต้องมีที่จัดเก็บข้อมูลที่ใช้ร่วมกันที่มีราคาแพง เพื่อให้ได้แอปพลิเคชันที่มีความพร้อมใช้งานสูงและการปกป้องฐานข้อมูลอย่างเต็มรูปแบบ แต่คุณสามารถเรียกใช้ฐานข้อมูลและแอปพลิเคชัน Oracle ในระบบคลาวด์ที่ไม่มี SAN ได้และ SIOS สามารถปกป้องฐานข้อมูล Oracle และแอปพลิเคชันของคุณภายในองค์กรและในสภาพแวดล้อมเสมือนและไฮบริดได้เช่นกัน
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีที่ SIOS สามารถปกป้องฐานข้อมูลและแอปพลิเคชัน Oracle ของคุณ คลิกที่นี่หรือเดโมส่วนตัว .
[1]https://docs.oracle.com/cd/B28359_01/rac.111/b28254/admcon.htm#RACAD7148 ทำซ้ำโดยได้รับอนุญาตจาก SIOS

ระบบ SAP ของคุณเป็นสัดส่วนหลักขององค์กร และหากระบบล่ม การดำเนินการของคุณจะหยุดลง เพื่อรองรับความพร้อมใช้งานสูงของระบบ SAP ของคุณ ทีมไอทีของคุณสามารถติดตั้ง SAP ในสภาพแวดล้อมคลัสเตอร์ได้
คลัสเตอร์คือกลุ่มของเซิร์ฟเวอร์ที่เชื่อมต่อตั้งแต่สองเครื่องขึ้นไปซึ่งกำหนดค่าด้วยระบบปฏิบัติการ ฐานข้อมูล และแอปพลิเคชันเดียวกัน เซิร์ฟเวอร์ที่เชื่อมต่อเหล่านี้เรียกว่า "โหนด" โหนดใดโหนดหนึ่งถูกกำหนดให้เป็นโหนดหลัก หากโหนดหลักล้มเหลว การจัดกลุ่มจะช่วยให้องค์กรของคุณล้มเหลวโดยอัตโนมัติผ่านการทำงานของแอปพลิเคชันไปยังโหนดรองอย่างน้อยหนึ่งโหนด ลดการหยุดทำงาน ขจัดข้อมูลสูญหาย และรักษาความสมบูรณ์ของข้อมูล
โซลูชันการทำคลัสเตอร์ SAP ความพร้อมใช้งานสูงพร้อมใช้งานสำหรับเซิร์ฟเวอร์ที่ทำงานใน Linux หรือในสภาพแวดล้อม Windows
แอปพลิเคชันส่วนหน้าต้องการ ความพร้อมใช้งานสูง เช่น S/4 HANA เช่นเดียวกับแอปอื่นๆ ที่ขึ้นอยู่กับ HANA
มีโซลูชัน HA แบบโอเพ่นซอร์สมากมายสำหรับ SAP จากผู้จำหน่าย Linux เช่น SUSE และ RedHat ที่มีส่วนขยาย HA พร้อมการสมัครสมาชิก "Enterprise for SAP" ผู้จำหน่ายเหล่านี้รวมกลุ่มในซอฟต์แวร์โอเพ่นซอร์สที่คุณสามารถใช้เพื่อสร้างคลัสเตอร์ที่มีความพร้อมใช้งานสูงสำหรับฐานข้อมูล HANA, ABAP SAP Central Service (ASCS), Evaluated Receipt Settlement (ERS) และส่วนประกอบ SAP อื่นๆ[1]
SUSE HAE (และตัวเลือกการทำคลัสเตอร์โอเพนซอร์สอื่นๆ) เป็นแบบใช้มือและปกป้องเฉพาะส่วนประกอบเท่านั้น ตัวอย่างเช่น การผสานรวม SUSE HAE และโซลูชันโอเพ่นซอร์สอื่นๆ กับ SAP หรือ SAP HANA อาจใช้เวลานานและซับซ้อน ซึ่งต้องใช้ความระมัดระวัง การเขียนสคริปต์ด้วยตนเอง และขั้นตอนการยืนยันที่น่าเบื่อ จำเป็นต้องมีความเชี่ยวชาญเฉพาะด้านอย่างลึกซึ้งในแอปพลิเคชันและฐานข้อมูลเพื่อสร้างโซลูชัน HA ที่รับรู้แอปพลิเคชัน
SAP ยังเสนอ HANA System Replication ซึ่งเป็นคุณสมบัติที่มาพร้อมกับซอฟต์แวร์ HANA มันให้การซิงโครไนซ์อย่างต่อเนื่องของฐานข้อมูล SAP HANA ไปยังตำแหน่งรองทั้งในศูนย์ข้อมูลเดียวกัน ไซต์ระยะไกล หรือในคลาวด์ ข้อมูลถูกจำลองแบบไปยังไซต์รองและโหลดไว้ล่วงหน้าในหน่วยความจำ เมื่อเกิดความล้มเหลว ไซต์รองจะเข้ายึดครองโดยไม่ต้องรีสตาร์ทฐานข้อมูล ซึ่งช่วยลด Recovery Time Objective (RTO) ขออภัย การย้อนกลับไปยังโหนดหลักต้องถูกทริกเกอร์ด้วยตนเองโดยใช้คำสั่งแยกต่างหาก นอกจากนี้ยังไม่มีการประสานการล้มเหลว HA แบบบูรณาการร่วมกับส่วนประกอบ SAP Central Services ฯลฯ[2]ซอฟต์แวร์การทำคลัสเตอร์ SIOS HA ให้การป้องกันที่ได้รับการรับรองจาก SAP สำหรับแอปพลิเคชันและข้อมูลของคุณ ซึ่งรวมถึงความพร้อมใช้งานสูง การจำลองข้อมูล และ การกู้คืนระบบ ในโซลูชันที่ง่าย ประหยัดต้นทุน ซอฟต์แวร์ SIOS ช่วยให้คุณปกป้อง SAP ในสภาพแวดล้อม Windows หรือ Linux โดยใช้ฮาร์ดแวร์เซิร์ฟเวอร์ที่คุณเลือกในการผสมผสานระหว่างสภาพแวดล้อมทางกายภาพ เสมือน คลาวด์ (สาธารณะ ส่วนตัว และไฮบริด) และสภาพแวดล้อมที่เก็บข้อมูลแฟลชประสิทธิภาพสูง ซอฟต์แวร์ SIOS ได้รับการกำหนดค่าอย่างง่ายดายและให้การจำลองที่รวดเร็ว การตรวจสอบที่ครอบคลุม และการปกป้องสภาพแวดล้อมแอปพลิเคชัน SAP ทั้งหมด นำเสนอความพร้อมใช้งานของข้อมูลอย่างต่อเนื่องในที่เก็บข้อมูลที่ใช้ร่วมกัน (SAN) หรือสภาพแวดล้อมการจัดเก็บข้อมูลที่ใช้ร่วมกัน (SANless)
สำหรับฐานข้อมูล SAP S/4HANA และ SAP HANA นั้น SIOS สามารถใช้เพื่อเสริมสิ่งที่ SAP กำลังทำอยู่แล้วกับการจำลองระบบ HANA เพื่อให้มีความพร้อมใช้งานสูงโดยอัตโนมัติอย่างสมบูรณ์ – การตรวจสอบอัตโนมัติของกระบวนการแอปพลิเคชัน SAP HANA ที่สำคัญ และการเฟลโอเวอร์และความล้มเหลวอัตโนมัติ[3]
SIOS Protection Suite สำหรับ Linux ให้การผสานรวมที่มีความพร้อมใช้งานสูงอย่างแน่นหนา การจัดคลัสเตอร์ล้มเหลว การตรวจสอบแอปพลิเคชัน SAP อย่างต่อเนื่อง การจำลองข้อมูล และนโยบายการกู้คืนที่กำหนดค่าได้ ปกป้องแอปพลิเคชัน SAP ของคุณจากการหยุดทำงานและภัยพิบัติ แม้ว่า SIOS Protection Suite จะทำงานในสภาพแวดล้อม SAN เพื่อรองรับคลัสเตอร์ที่ใช้ฮาร์ดแวร์ HA แบบดั้งเดิม แต่สถาปัตยกรรมใช้วิธีการแบบไม่มีส่วนร่วมในการจัดคลัสเตอร์เซิร์ฟเวอร์ทำให้สามารถรัน SANless ได้ นำเสนอโซลูชันที่มีประสิทธิภาพ หลากหลาย และกำหนดค่าได้ง่ายด้วยนโยบายการกู้คืนระบบเฟลโอเวอร์/เฟลแบ็คแบบอัตโนมัติและด้วยตนเองสำหรับแอปพลิเคชันที่หลากหลาย
SIOS Protection Suite สำหรับ Linux รองรับ SAP Clustering ดังนี้:
ARK ให้การรับรู้เฉพาะแอปพลิเคชันและเชื่อมต่อสแต็กแอปพลิเคชันกับโซลูชัน HA ในบริบท รวมถึงส่วนประกอบที่ขึ้นต่อกันทั้งหมด ตัวอย่างเช่น SIOS นำเสนอ SAP HANA Application Recovery Kit ซึ่งมีการเฟลโอเวอร์อัตโนมัติของโฮสต์ การจำลองที่เก็บข้อมูล และการจำลองระบบเพื่อเพิ่มความพร้อมใช้งาน
สุดท้ายนี้ ด้วย SIOS Protection Suite สำหรับ Linux คุณสามารถเรียกใช้แอปพลิเคชันที่มีความสำคัญต่อธุรกิจของคุณในสภาพแวดล้อมคลาวด์ที่ยืดหยุ่นและปรับขนาดได้ เช่น Amazon Web Services (AWS) และ Azure โดยไม่สูญเสียประสิทธิภาพ ความพร้อมใช้งานสูง หรือการป้องกันภัยพิบัติ
SIOS DataKeeper Cluster Edition เป็นซอฟต์แวร์เสริมที่ผสานรวมกับ WSFC ได้อย่างราบรื่นและราบรื่นเพื่อเพิ่มการจำลองแบบซิงโครนัสหรือแบบอะซิงโครนัสที่ปรับให้เหมาะสมกับประสิทธิภาพ ด้วย DataKeeper คุณสามารถสร้างคลัสเตอร์ SANless ได้อย่างง่ายดายเพื่อให้มีความพร้อมใช้งานสูงและการกู้คืนความเสียหายสำหรับแอปพลิเคชัน SAP ของคุณ ไม่ว่าจะทำงานในระบบคลาวด์ ในสภาพแวดล้อมเสมือนจริง เช่น VMware หรือบนเซิร์ฟเวอร์จริงโดยใช้ที่เก็บข้อมูลในเครื่องเท่านั้น เพิ่มการจำลองแบบที่มีประสิทธิภาพเพื่อซิงโครไนซ์ที่เก็บข้อมูลในเครื่องบนโหนดคลัสเตอร์แต่ละโหนด สร้างคลัสเตอร์ SANless ที่ปรากฏต่อ WSFC เช่นเดียวกับที่เก็บข้อมูลแบบเดิม ด้วยสิ่งนี้ คุณสามารถสร้างคลัสเตอร์ Windows ในระบบคลาวด์ ไฮบริดคลาวด์ หรือขยายคลัสเตอร์แบบใช้ SAN ในสถานที่แบบดั้งเดิมด้วยโหนดในระบบคลาวด์สำหรับการกู้คืนจากความเสียหาย
เมื่อใช้ SIOS DataKeeper Cluster Edition คุณสามารถป้องกันความพร้อมใช้งานสูงสำหรับส่วนประกอบ SAP ที่สำคัญ รวมถึงอินสแตนซ์ ABAP SAP Central Service (ASCS) ฐานข้อมูลส่วนหลัง (Microsoft SQL Server, Oracle, DB2, MaxDB, MySQL และ PostgreSQL) SAP Central อินสแตนซ์บริการ (SCS)
SIOS DataKeeper ไม่เพียงแต่ช่วยลดต้นทุน ความซับซ้อน และความเสี่ยงจุดเดียวของความล้มเหลวของ SAN เท่านั้น แต่ยังช่วยให้คุณใช้ PCIe Flash และ SSD ที่รวดเร็วล่าสุดในที่จัดเก็บข้อมูลในเครื่องของคุณเพื่อประสิทธิภาพและการป้องกันในราคาประหยัดเพียงจุดเดียว สารละลาย.
SIOS DataKeeper ยังมีให้ SAP ความพร้อมใช้งานสูง และการกู้คืนความเสียหายในสภาพแวดล้อมระบบคลาวด์ เช่น Amazon Web Services (AWS), Microsoft Azure และ Google Cloud Services โดยไม่ลดทอนประสิทธิภาพ
หากองค์กรของคุณไม่ได้ใช้ WSFC SIOS จะเสนอ Protection Suite สำหรับ Windows ซึ่งรวมถึง SIOS DataKeeper, SIOS LifeKeeper และ Application Recovery Kits (ARK) ที่เป็นตัวเลือกสำหรับแอปพลิเคชันชั้นนำ เช่น SAP และการดำเนินงานด้านโครงสร้างพื้นฐาน เป็นโซลูชันการทำคลัสเตอร์ SAP ที่ผสานรวมอย่างแน่นหนา ซึ่งรวมการทำคลัสเตอร์ล้มเหลวที่มีความพร้อมใช้งานสูง การตรวจสอบแอปพลิเคชันอย่างต่อเนื่อง การจำลองข้อมูล และนโยบายการกู้คืนที่กำหนดค่าได้ เพื่อปกป้องแอปพลิเคชันและข้อมูล SAP ที่มีความสำคัญต่อธุรกิจของคุณจากการหยุดทำงานและภัยพิบัติ
องค์กรทั่วโลกใช้โซลูชัน SIOS HA เพื่อปกป้องแอปพลิเคชัน SAP ไม่ว่าจะทำงานในสภาพแวดล้อม Windows หรือ Linux นี่เป็นเพียงตัวอย่างบางส่วน:
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการทำคลัสเตอร์ SAP ความพร้อมใช้งานสูง คลิกที่นี่ .
อ้างอิง https://blogs.sap.com/2020/05/03/high-availability-and-dr-for-sap-hana-sap-s-4hana-and-sap-central-services/[1] อ้าง[2] https://blogs.sap.com/2020/05/03/high-availability-and-dr-for-sap-hana-sap-s-4hana-and-sap-central-services/[3] อ้าง ทำซ้ำโดยได้รับอนุญาตจาก SIOS