การสร้างกลุ่มและการกำหนดค่าคอนเทนเนอร์: โหนดและส่วนแบ่งที่สำคัญของไฟล์
บทนำ
ยินดีต้อนรับสู่ส่วนที่ 1 ของชุดข้อมูลของฉัน "ทีละขั้นตอน: การกำหนดค่าคลัสเตอร์ multi-site 2 โหนดใน Windows Server 2008 R2" ก่อนที่เราจะก้าวเข้าไปในรายละเอียดให้ใช้เวลาสักครู่เพื่อปรึกษาว่ากลุ่มไซต์หลายไซต์คืออะไรและทำไมฉันต้องการใช้งานกลุ่มนี้ Microsoft มีหน้าเว็บที่ยอดเยี่ยมและกระดาษสีขาวที่คุณต้องการดาวน์โหลดเพื่อให้ได้รายละเอียดทั้งหมดดังนั้นฉันจะไม่ทำซ้ำทุกอย่างที่นี่ แต่โดยทั่วไปกลุ่มไซต์หลายแห่งคือโซลูชันการกู้คืนระบบและโซลูชันที่พร้อมใช้งานที่มีประสิทธิภาพสูงทั้งหมดจะรวมเข้าด้วยกัน คลัสเตอร์หลายไซต์ช่วยให้คุณมีเป้าหมายการกู้คืนข้อมูลสูงสุด (RTO) และวัตถุประสงค์การกู้เวลา (RTO) สำหรับแอพพลิเคชันที่สำคัญของคุณ ด้วยการเปิดตัว Windows Server 2008 failover การจัดกลุ่มคลัสเตอร์แบบ multi-site ได้กลายเป็นเรื่องที่ทำได้มากขึ้นด้วยการแนะนำ failover subnet subnet และรองรับการสื่อสารเครือข่ายแฝงสูง
ฉันกล่าวถึง "cross-subnet failover" เป็นคุณลักษณะใหม่ที่ยอดเยี่ยมของ Windows Server 2008 Failover Clustering และเป็นคุณลักษณะใหม่ที่ยอดเยี่ยม อย่างไรก็ตาม SQL Server ยังไม่ได้ใช้ฟังก์ชันนี้ซึ่งหมายความว่าคุณจะต้องขยายเครือข่ายย่อยของคุณข้ามไซต์ต่างๆในคลัสเตอร์ SQL Server หลายไซต์ ในขณะที่ Tech-Ed 2009 ทีม SQL Server รายงานว่าพวกเขาวางแผนที่จะสนับสนุนคุณลักษณะนี้ แต่พวกเขากล่าวว่าจะเกิดขึ้นในช่วงหลัง SQL Server 2008 R2 ในอนาคตอันใกล้คุณจะติดอยู่กับการขยายเครือข่ายย่อยของคุณข้ามไซต์ในคลัสเตอร์ SQL Server หลายไซต์ มีปัญหาเกี่ยวกับเครือข่ายอื่น ๆ ที่คุณต้องพิจารณาด้วยเช่นเส้นทางการสื่อสารที่ซ้ำซ้อนแบนด์วิดท์และตำแหน่งการแชร์ไฟล์
การพิจารณาเครือข่าย
กลุ่ม failover ทั้งหมดของ Microsoft ต้องมีเส้นทางการสื่อสารเครือข่ายซ้ำซ้อน เพื่อให้แน่ใจว่าเส้นทางการสื่อสารใด ๆ ที่ล้มเหลวจะไม่ส่งผลให้เกิด failover เท็จและช่วยให้คลัสเตอร์ของคุณสามารถใช้งานได้ กลุ่มไซต์หลายแห่งมีความต้องการเช่นกันดังนั้นคุณจึงควรวางแผนเครือข่ายของคุณด้วยใจ โดยทั่วไปมีสองสิ่งที่จะต้องเดินทางระหว่างโหนดคือการรับส่งข้อมูลการจำลองแบบและ heartbeat ของคลัสเตอร์ นอกจากนี้คุณยังต้องพิจารณาการเชื่อมต่อไคลเอ็นต์และกิจกรรมการจัดการคลัสเตอร์ คุณจะต้องการให้แน่ใจว่าเครือข่ายใดก็ตามที่คุณมีอยู่คุณไม่ได้ครอบงำเครือข่ายหรือคุณจะมีพฤติกรรมที่ไม่น่าเชื่อถือ การเข้าชมการจำลองแบบของคุณน่าจะต้องการแบนด์วิดท์ที่มากที่สุด คุณจะต้องทำงานร่วมกับผู้ให้บริการการจำลองแบบของคุณเพื่อกำหนดจำนวนแบนด์วิดท์ที่ต้องการ
ด้วยเส้นทางการสื่อสารที่ซ้ำซ้อนของคุณในสถานที่สิ่งสุดท้ายที่คุณต้องพิจารณาคือรูปแบบองค์ประชุมของคุณ สำหรับการกำหนดค่าคลัสเตอร์แบบหลายไซต์แบบ 2 โหนดการกำหนดค่าที่แนะนำของ Microsoft คือองค์ประชุมและส่วนแบ่งข้อมูลส่วนใหญ่เป็นกลุ่ม สำหรับคำอธิบายโดยละเอียดเกี่ยวกับจำนวนองค์ประชุมโปรดดูบทความนี้
สาเหตุส่วนใหญ่ที่ทำให้เกิดความสับสนกับองค์ประชุมและโควรัม File Share Majority คือตำแหน่งของ Share Share Witness ฉันควรวางเซิร์ฟเวอร์ที่เป็นโฮสต์การแชร์ไฟล์ไว้ที่ใด ลองดูที่ตัวเลือก
ตัวเลือกที่ 1 – วางตำแหน่งไฟล์ไว้ในเว็บไซต์หลัก
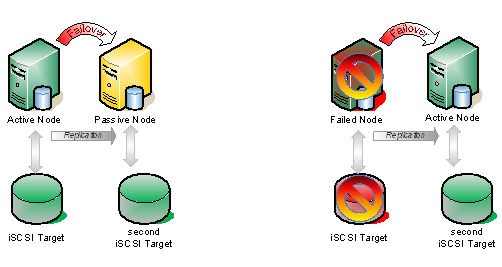
นี่เป็นทางเลือกที่ถูกต้องสำหรับการกู้คืนระบบ แต่ไม่มากนักสำหรับความพร้อมใช้งานที่สูง หากทั้งไซต์ไม่ทำงาน (รวมถึงโหนดหลักและพยานร่วมกันของไฟล์) โหนดรองในไซต์รองจะไม่เข้าสู่บริการโดยอัตโนมัติคุณจะต้องบังคับองค์ประชุมออนไลน์ด้วยตนเอง นี่เป็นเพราะคะแนนจะเหลือเพียงอย่างเดียวในกลุ่ม หนึ่งในสามไม่ได้ให้เสียงข้างมาก! ตอนนี้ถ้าคุณสามารถอยู่กับขั้นตอนด้วยตนเองที่เกี่ยวข้องกับการกู้คืนในกรณีภัยพิบัติแล้วการกำหนดค่านี้อาจเป็นประโยชน์สำหรับคุณ
ตัวเลือกที่ 2 – วางตำแหน่งแฟ้มในไซต์รอง
นี่ไม่ใช่ความคิดที่ดี แม้ว่าจะแก้ปัญหาการกู้คืนอัตโนมัติในกรณีที่เกิดการสูญหายของไซต์โดยสมบูรณ์ แต่จะทำให้คุณเสี่ยงต่อการเกิด failover เท็จ พิจารณาเรื่องนี้ … จะเกิดอะไรขึ้นหากไซต์รองของคุณเสียลง ในกรณีนี้เซิร์ฟเวอร์หลักของคุณ (Node1) จะไปแบบออฟไลน์เนื่องจากตอนนี้เป็นโหนดเดียวในไซต์หลักและจะไม่มีส่วนใหญ่ของโหนดอีกต่อไป ฉันไม่มีเหตุผลที่จะใช้การกำหนดค่านี้เนื่องจากมีความเสี่ยงมากเกินไป
ตัวเลือกที่ 3 – วางไฟล์แชร์การแสดงตัวในตำแหน่งทางภูมิศาสตร์ 3RD
นี่คือการกำหนดค่าที่ต้องการเนื่องจากช่วยให้สามารถทำงาน failover อัตโนมัติในกรณีที่เกิดการสูญเสียไซต์โดยสมบูรณ์และลดความเป็นไปได้ที่จะเกิดความล้มเหลวของไซต์รองที่ทำให้โหนดหลักไปออฟไลน์ การมีโฮสต์ไซต์ที่ 3 เป็นพยานร่วมกันของไฟล์คุณได้ตัดไซต์ใดไซต์หนึ่งออกเป็นจุดล้มเหลวดังนั้นตอนนี้คลัสเตอร์จะทำหน้าที่ตามที่คุณคาดหวังและระบบเปลี่ยนเส้นทางอัตโนมัติในกรณีที่เกิดการสูญเสียไซต์ การระบุสถานที่ตั้งทางภูมิศาสตร์ที่ 3 อาจเป็นสิ่งที่ท้าทายสำหรับบาง บริษัท แต่ด้วยการมาถึงการใช้คอมพิวเตอร์ยูทิลิตีเช่น Amazon EC2 และ GoGrid จะช่วยให้ บริษัท ต่างๆสามารถเข้าถึงพยานหลักฐานในกลุ่มเมฆได้อย่างเต็มที่และมีความยืดหยุ่นเพียงพอ สำหรับกลุ่มไซต์หลายแห่งที่มีประสิทธิภาพ ในความเป็นจริงคุณอาจพิจารณาเมฆตัวเองเป็นศูนย์ข้อมูลสำรองของคุณและเปลี่ยนไปใช้ระบบคลาวด์เพียงอย่างเดียวในกรณีเกิดภัยพิบัติ ผมคิดว่าความเป็นไปได้ของการใช้ระบบคลาวด์และการกู้คืนระบบที่เกิดขึ้นจะล่อลวงอย่างมากและในความเป็นจริงผมวางแผนที่จะทำโพสต์บล็อกทั้งหมดในแบบที่ในอนาคตอันใกล้นี้
กำหนดค่า CLUSTER
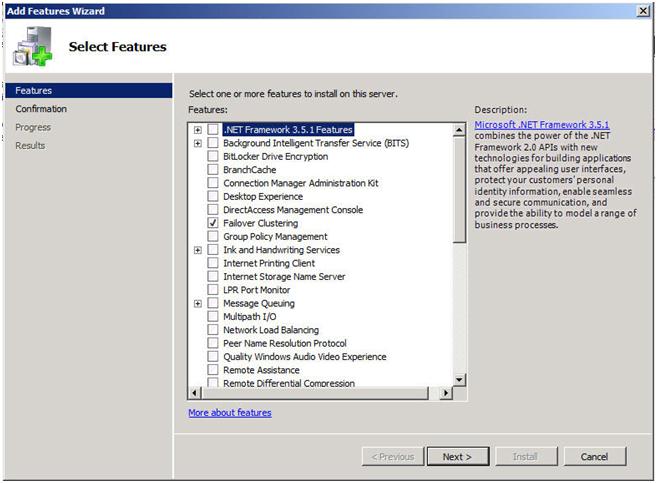
ตอนนี้เรามีพื้นฐานอยู่แล้วลองเริ่มต้นใช้งานการกำหนดค่าจริงของคลัสเตอร์ คุณต้องการเพิ่มคุณลักษณะ Failover Clustering ไปยังโหนดทั้งสองของคลัสเตอร์ของคุณ เพื่อความเรียบง่ายฉันได้เรียกโหนดของฉันเป็นหลักและ SECONDARY ทำได้โดยง่ายผ่าน Add Features Wizard ตามที่แสดงด้านล่าง
ถัดไปคุณจะต้องการดูการเชื่อมต่อเครือข่ายของคุณ เป็นการดีที่สุดถ้าคุณเปลี่ยนชื่อการเชื่อมต่อในแต่ละเซิร์ฟเวอร์เพื่อให้สอดคล้องกับเครือข่ายที่แสดง นี่จะทำให้ง่ายต่อการจดจำในภายหลัง

คุณยังต้องการไปที่การตั้งค่าขั้นสูงของการเชื่อมต่อเครือข่ายของคุณ (กด Alt เพื่อดูเมนูการตั้งค่าขั้นสูง) ของแต่ละเซิร์ฟเวอร์และตรวจสอบว่าเครือข่ายสาธารณะเป็นอันดับแรกในรายการ
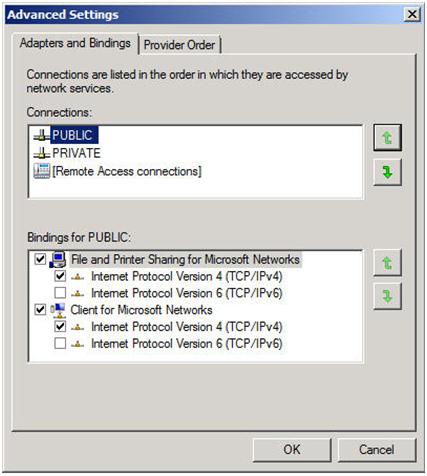
เครือข่ายส่วนตัวของคุณควรมีที่อยู่ IP และซับเน็ตมาสก์เท่านั้น ไม่ควรกำหนดเกตเวย์หรือเซิร์ฟเวอร์ DNS เริ่มต้น โหนดของคุณต้องสามารถสื่อสารผ่านเครือข่ายนี้ได้ดังนั้นให้แน่ใจว่าเซิร์ฟเวอร์สามารถสื่อสารผ่านเครือข่ายนี้ได้ เพิ่มเส้นทางแบบคงที่ถ้าจำเป็น
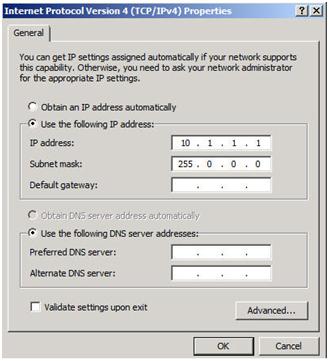
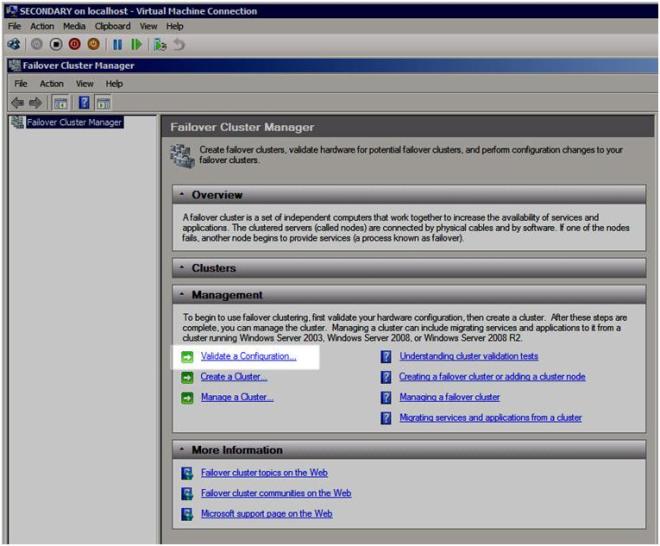
เมื่อคุณกำหนดค่าเครือข่ายแล้วคุณก็พร้อมที่จะสร้างคลัสเตอร์แล้ว ขั้นตอนแรกคือ "Validate a Configuration" เปิด Failover Cluster Manager แล้วคลิก Validate a Configuration
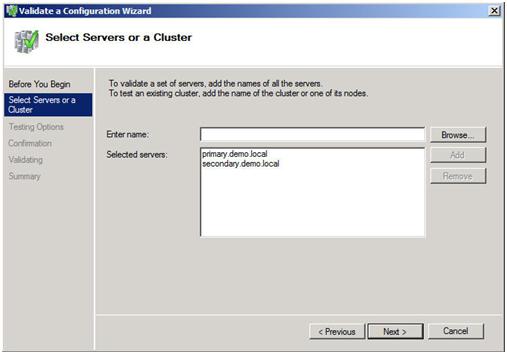
ตัวช่วยสร้างการตรวจสอบความถูกต้องจะเปิดขึ้นและแสดงหน้าจอแรกดังภาพด้านล่าง เพิ่มเซิร์ฟเวอร์สองเครื่องในคลัสเตอร์ของคุณและคลิกถัดไปเพื่อดำเนินการต่อ
คลัสเตอร์หลายไซต์ไม่จำเป็นต้องผ่านการตรวจสอบพื้นที่เก็บข้อมูล (โปรดดูบทความของ Microsoft) ดำเนินการขั้นตอนการตรวจสอบพื้นที่เก็บข้อมูลคลิกที่ "เรียกใช้เฉพาะการทดสอบที่ฉันเลือก" และคลิกดำเนินการต่อ
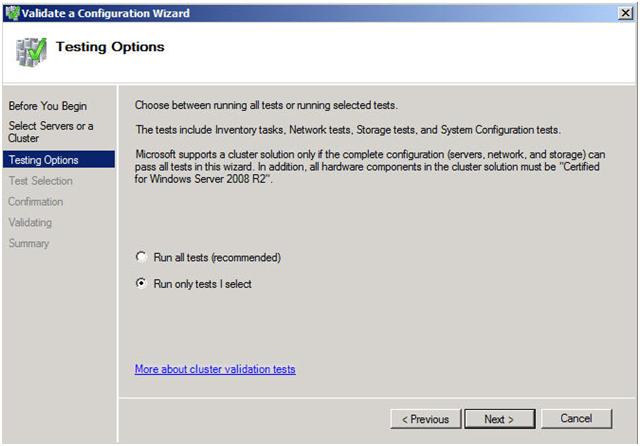
ในหน้าจอการทดสอบเลือก unselect Storage และคลิก Next
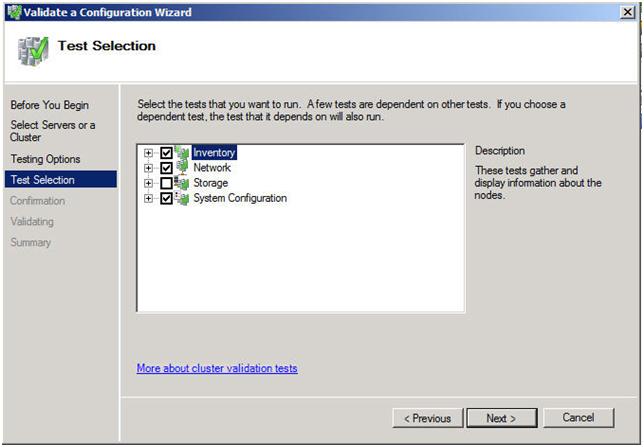
คุณจะเห็นหน้าจอยืนยันต่อไปนี้ คลิกถัดไปเพื่อดำเนินการต่อ
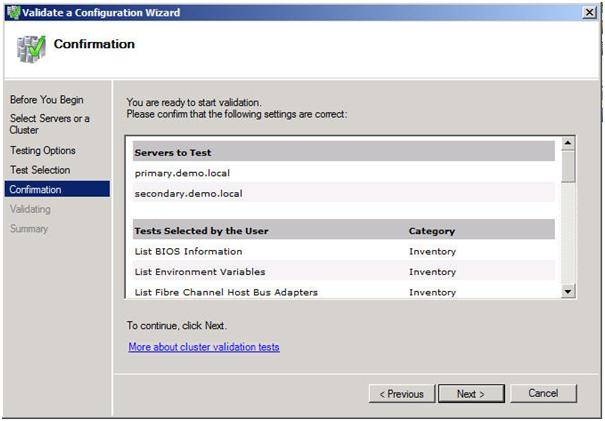
หากคุณทำทุกอย่างถูกต้องคุณจะเห็นหน้าสรุปที่มีลักษณะดังนี้ สังเกตว่าเครื่องหมายอัศเจรีย์สีเหลืองบ่งชี้ว่าไม่ได้ทดสอบทั้งหมด นี่เป็นที่คาดหวังในกลุ่มไซต์หลายแห่งเนื่องจากการทดสอบพื้นที่เก็บข้อมูลถูกข้ามไป ตราบเท่าที่ทุกสิ่งทุกอย่างตรวจสอบออกตกลงคุณสามารถดำเนินการต่อได้ หากรายงานระบุข้อผิดพลาดอื่น ๆ ให้แก้ไขปัญหาเรียกใช้การทดสอบอีกครั้งและดำเนินการต่อ
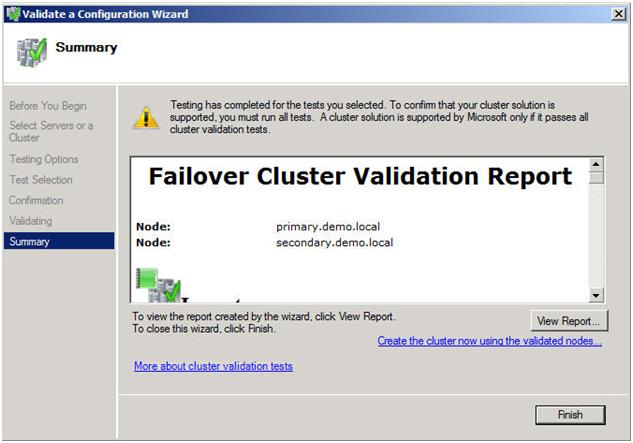
ขณะนี้คุณพร้อมที่จะสร้างกลุ่มแล้ว ในตัวจัดการ Failover Cluster คลิกที่ Create a Cluster
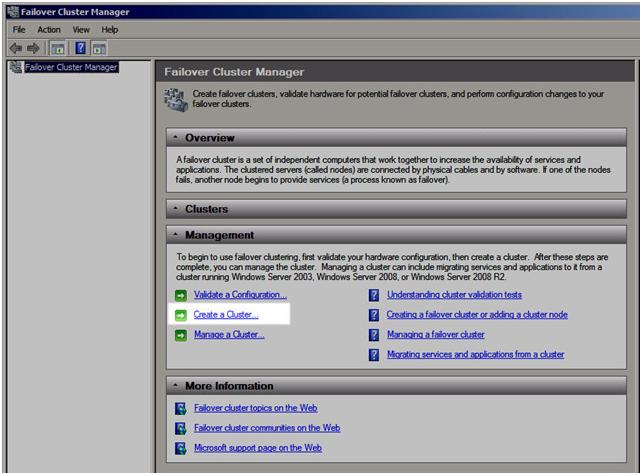
ขั้นตอนถัดไปจะถามว่าคุณต้องการตรวจสอบความถูกต้องของคลัสเตอร์หรือไม่ เนื่องจากคุณได้ดำเนินการแล้วคุณสามารถข้ามขั้นตอนนี้ได้ โปรดทราบว่านี่จะก่อให้เกิดปัญหาเล็กน้อยในภายหลังหากติดตั้ง SQL เนื่องจากจะต้องให้คลัสเตอร์ผ่านการตรวจสอบความถูกต้องก่อนที่จะดำเนินการต่อ เมื่อเราไปถึงจุดนี้ฉันจะแสดงให้คุณเห็นวิธีการผ่านการตรวจสอบนี้โดยใช้ตัวเลือกบรรทัดคำสั่งในการตั้งค่า SQL Server ตอนนี้ให้เลือก No และ Next
ขั้นตอนต่อไปคือคุณต้องสร้างชื่อสำหรับคลัสเตอร์นี้และ IP สำหรับการจัดการคลัสเตอร์นี้ นี่จะเป็นชื่อที่คุณจะใช้ในการจัดการคลัสเตอร์ไม่ใช่ชื่อของทรัพยากรคลัสเตอร์ SQL ที่คุณจะสร้างในภายหลัง ป้อนชื่อเฉพาะและที่อยู่ IP แล้วคลิกถัดไป
หมายเหตุ: นี่เป็นชื่อคอมพิวเตอร์ที่จะต้องได้รับการอนุญาตให้ใช้ File Share Witness ตามที่อธิบายไว้ในเอกสารนี้
ยืนยันตัวเลือกของคุณและคลิกถัดไป
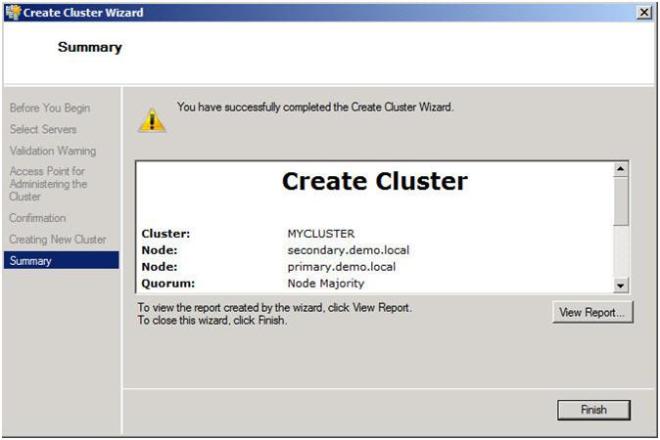
แสดงความยินดีหากคุณได้ทำทุกอย่างถูกต้องคุณจะเห็นหน้าสรุปต่อไปนี้ สังเกตเห็นเครื่องหมายอัศเจรีย์สีเหลือง ชัดบางอย่างไม่สมบูรณ์แบบ คลิกที่ดูรายงานเพื่อดูว่าปัญหาอาจเกิดขึ้นได้อย่างไร
หากคุณดูรายงานคุณจะเห็นบรรทัดที่มีลักษณะเช่นนี้

ไม่หงุดหงิด; นี้จะเป็นที่คาดหวังในกลุ่มหลายไซต์ จำไว้ว่าเราได้กล่าวก่อนหน้านี้ว่าเราจะดำเนินการองค์ประชุมและส่วนแบ่งไฟล์ส่วนใหญ่ครบถ้วน เราจะเปลี่ยนสถานะองค์ประชุมจาก Node Majority Cluster ปัจจุบัน (ไม่ใช่ความคิดที่ดีในโหนดคลัสเตอร์ 2 โหนด) เป็นโควรัม Node และ File Share Majority
การดำเนินการแบบย่อส่วนของไฟล์และโหนด
ขั้นแรกเราต้องระบุเซิร์ฟเวอร์ที่จะเป็นพยานใน File Share ของเรา โปรดจำไว้ว่าที่เราได้กล่าวไว้ก่อนหน้านี้พยานแชร์ไฟล์แชร์นี้ควรอยู่ในตำแหน่งที่ 3 สามารถเข้าถึงได้โดยโหนดทั้งสองของคลัสเตอร์ เมื่อคุณระบุเซิร์ฟเวอร์แชร์โฟลเดอร์ตามปกติแล้วจะแชร์โฟลเดอร์ ในกรณีของฉันฉันจะสร้างส่วนแบ่งที่เรียกว่า MYCLUSTER บนเซิร์ฟเวอร์ชื่อ DEMODC
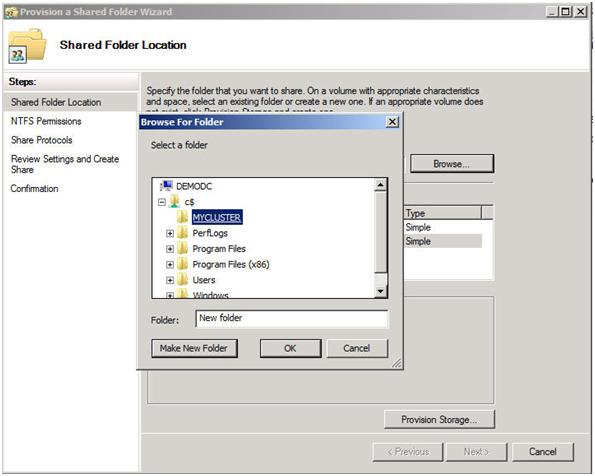
สิ่งสำคัญที่ต้องจำเกี่ยวกับส่วนแบ่งนี้คือคุณต้องให้ชื่อคอมพิวเตอร์คลัสเตอร์สิทธิ์ในการอ่าน / เขียนเพื่อแชร์ในระดับแชร์และสิทธิ์ระดับ NTFS ถ้าคุณเรียกคืนกลับไปที่รูปที่ 13 ฉันได้สร้างคลัสเตอร์ของฉันและระบุชื่อ "MYCLUSTER" คุณจะต้องตรวจสอบให้แน่ใจว่าคุณได้ให้สิทธิ์ในการอ่าน / เขียนบัญชีคอมพิวเตอร์คลัสเตอร์ดังที่แสดงในภาพหน้าจอต่อไปนี้
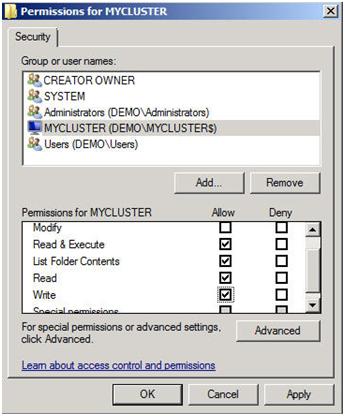
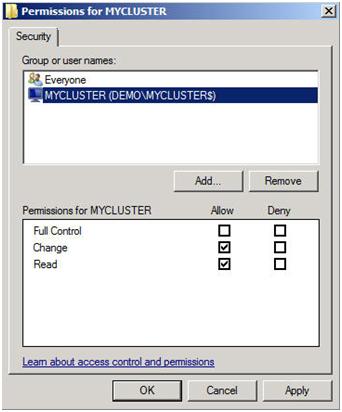
ขณะนี้มีโฟลเดอร์ที่ใช้ร่วมกันและได้รับสิทธิ์ที่เหมาะสมแล้วคุณก็พร้อมที่จะเปลี่ยนประเภทองค์ประชุมแล้ว จากตัวจัดการคลัสเตอร์ Failover คลิกขวาที่คลัสเตอร์เลือกการดำเนินการเพิ่มเติมและกำหนดค่าการตั้งค่า Quorum Cluster
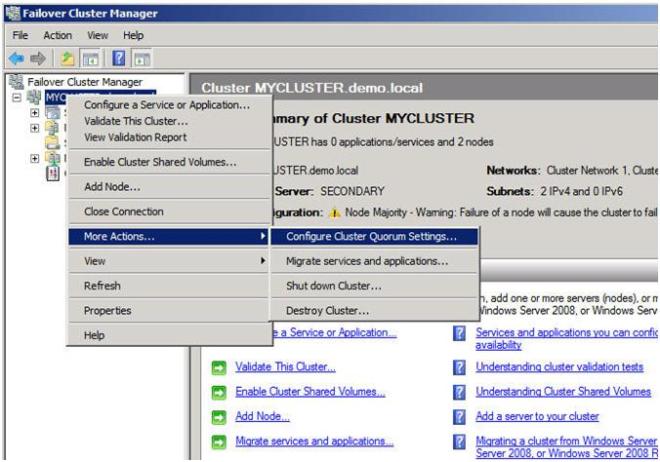
ในหน้าจอถัดไปให้เลือกโหนดและส่วนแบ่งไฟล์ส่วนใหญ่แล้วคลิกถัดไป
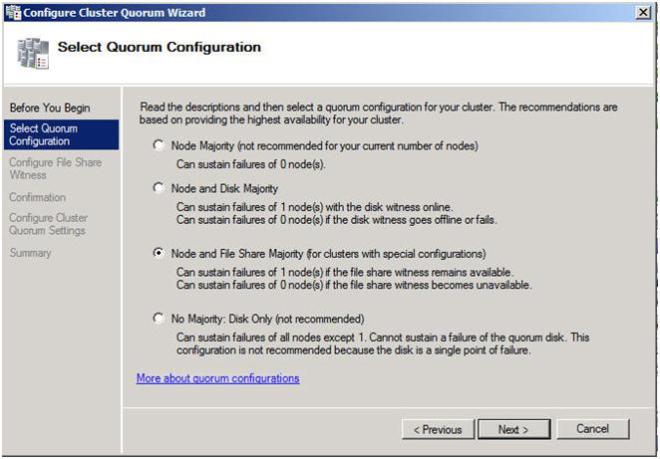
ในหน้าจอนี้ให้ป้อนเส้นทางไปยังส่วนแชร์ไฟล์ที่คุณสร้างขึ้นก่อนหน้านี้และคลิกถัดไป
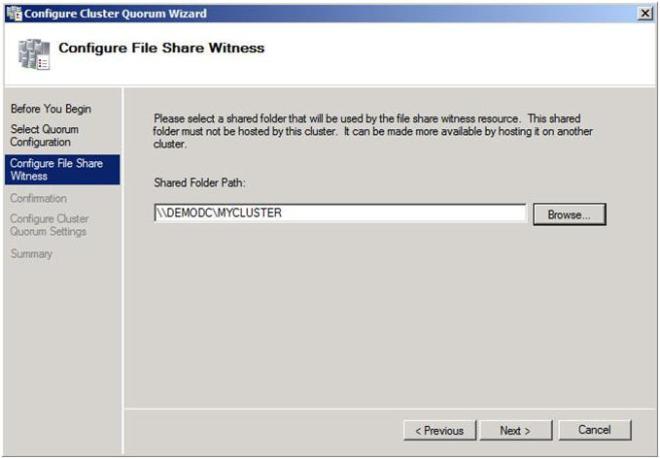
ยืนยันว่าข้อมูลถูกต้องและคลิกถัดไป
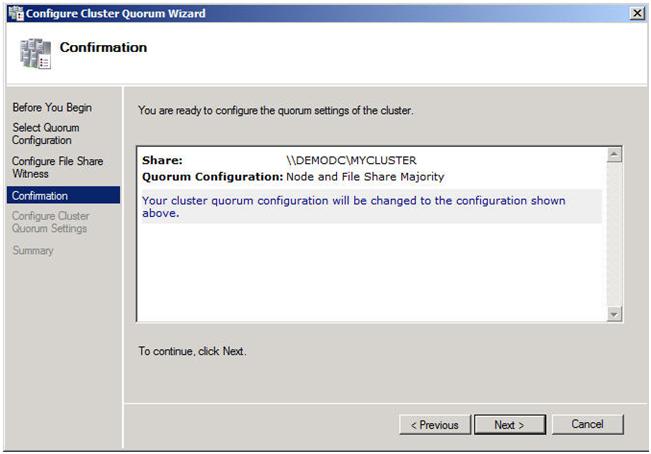
สมมติว่าคุณทำทุกอย่างถูกต้องคุณควรเห็นหน้าสรุปต่อไปนี้
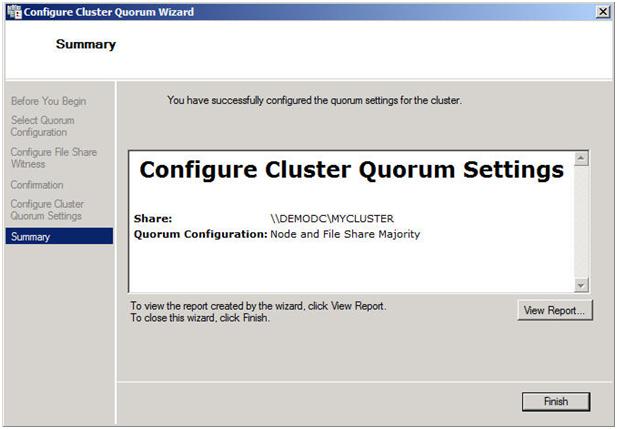
ขณะนี้เมื่อคุณดูกลุ่มของคุณการกำหนดค่ารัมจะระบุว่า "โหนดและส่วนแบ่งไฟล์ส่วนใหญ่" ดังที่แสดงด้านล่าง

ขั้นตอนที่ฉันได้ระบุไว้จนถึงจุดนี้ใช้กับคลัสเตอร์แบบหลายไซต์ไม่ว่าจะเป็น SQL, Exchange, File Server หรือ failover cluster อื่น ๆ ขั้นตอนถัดไปในการสร้างคลัสเตอร์แบบหลายไซต์เกี่ยวข้องกับการผสานรวมโซลูชันการจัดเก็บและการจำลองแบบเข้ากับคลัสเตอร์ failover ขั้นตอนนี้จะแตกต่างกันไปขึ้นอยู่กับโซลูชันการจำลองแบบของคุณดังนั้นคุณจำเป็นต้องติดต่อกับตัวแทนจำหน่ายการจำลองแบบของคุณอย่างใกล้ชิดเพื่อให้ถูกต้อง ในส่วนที่ 2 ของซีรีส์ของฉันฉันจะอธิบายว่า SteelEye DataKeeper Cluster Edition ทำงานร่วมกับ Windows Server Failover Clustering เพื่อให้คุณทราบว่าโซลูชันของผู้ให้บริการการจำลองแบบทำงานได้ดีเพียงใด
ส่วนอื่น ๆ ของชุดนี้จะอธิบายรายละเอียดวิธีการติดตั้ง SQL, File Servers และ Hyper-V ในกลุ่มไซต์หลายแห่ง ฉันยังจะมีโพสต์ในการพิจารณาสำหรับกลุ่มหลายโหนดของสามหรือมากกว่าโหนด
ทำซ้ำโดยได้รับอนุญาตจาก https://clusteringformeremortals.com/2009/09/15/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2 % 80% 93 ส่วน-1 /