
循序漸進:如何使用Windows Server 2016從包含事件詳細信息的Windows事件觸發電子郵件警報
介紹
從Windows事件觸發電子郵件警報使用Windows Server 2016只需要幾個步驟。指定觸發該任務時將發生的操作。由於Microsoft已決定棄用“發送電子郵件”選項,因此我們唯一的選擇是啟動程序。在我們的例子中,該程序將是一個Powershell腳本,用於收集事件日誌信息並對其進行解析。這樣,我們就可以發送包含重要日誌事件詳細信息的電子郵件。此工作已在Windows Server 2016上得到驗證。但我懷疑它應該適用於Windows Server 2012 R2和Windows Server 2019。如果您在任何其他平台上工作,請發表評論,如果您需要更改任何內容,請告訴我們。
步驟1-編寫Powershell腳本
首先要做的是寫一個Powershell腳本,運行時可以發送電子郵件。在研究這個問題時,我發現了很多方法來完成這項任務,所以我要向您展示的只是一種方式,但您可以隨意嘗試並使用適合您環境的方法。在我的實驗室中,我沒有運行自己的SMTP服務器,因此我必須編寫一個可以利用我的Gmail帳戶的腳本。您將在我的Powershell腳本中看到,對SMTP服務器進行身份驗證的電子郵件帳戶的密碼是純文本格式。如果您擔心某人可能有權訪問您的腳本並發現您的密碼,請加密您的憑據。Gmail需要和SSL連接。 您的密碼應該是安全的,就像任何其他電子郵件客戶端一樣。我有一個Powershell腳本的例子。與任務計劃程序一起使用時,它將在Windows事件日誌中記錄任何指定的事件時自動發送電子郵件警報。在我的環境中,我將此腳本保存到C: Alerts DataKeeper.ps1
$ EventId = 16,20,23,150,219,220
$ A = Get-WinEvent -MaxEvents 1 -FilterHashTable @ {Logname =“System”; ID = $ EventId}
$ Message = $ A.Message
$ EventID = $ A.Id
$ MachineName = $ A.MachineName
$ Source = $ A.ProviderName
$ EmailFrom =“sios@medfordband.com”
$ EmailTo =“sios@medfordband.com”
$ Subject =“來自$ MachineName的警報”
$ Body =“EventID:$ EventID`nSource:$ Source`nMachineName:$ MachineName`nMessage:$ Message”
$ SMTPServer =“smtp.gmail.com”
$ SMTPClient = New-Object Net.Mail.SmtpClient($ SmtpServer,587)
$ SMTPClient.EnableSsl = $ true
$ SMTPClient.Credentials = New-Object System.Net.NetworkCredential
(“sios@medfordband.com”,“mySMTPP @ 55w0rd”);
$ SMTPClient.Send($ EmailFrom,$ EmailTo,$ Subject,$ Body)
從Powershell腳本生成的電子郵件示例如下所示。 您可能已經註意到,此Powershell腳本使用Get-WinEvent cmdlet根據指定的LogName,Source和eventID獲取最新的Event Log條目。然後它解析事件並將EventID,Source,MachineName和Message分配給將用於撰寫電子郵件的變量。您將看到指定的LogName,Source和eventID與您在步驟2中設置計劃任務時指定的ID相同。
您可能已經註意到,此Powershell腳本使用Get-WinEvent cmdlet根據指定的LogName,Source和eventID獲取最新的Event Log條目。然後它解析事件並將EventID,Source,MachineName和Message分配給將用於撰寫電子郵件的變量。您將看到指定的LogName,Source和eventID與您在步驟2中設置計劃任務時指定的ID相同。
第2步 – 設置計劃任務
在任務計劃程序中創建一個任務,如以下屏幕截圖所示。
- 創建任
 務確保將任務設置為“運行”,無論用戶是否已登錄。
務確保將任務設置為“運行”,無論用戶是否已登錄。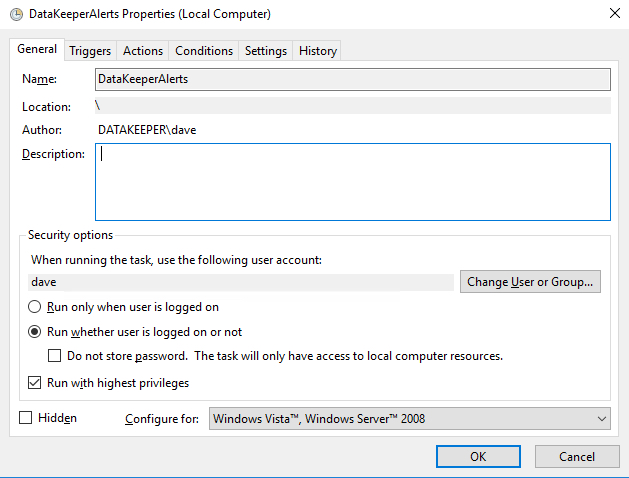
- 在“觸發器”選項卡上,選擇“新建”以創建將啟動“在事件上”任務的觸發器。在我的示例中,我將創建一個事件,觸發任何時候DataKeeper(extmirr)將重要事件記錄到系統日誌。
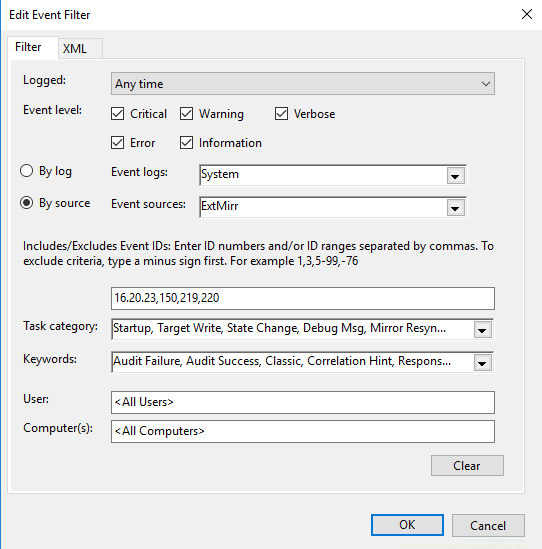
 創建一個自定義事件和新事件過濾器,如下所示…對於我的觸發器,
創建一個自定義事件和新事件過濾器,如下所示…對於我的觸發器, 我觸發通常受監控的SIOS DataKeeper(ExtMirr)EventIDs 16,20,23,150,219,220。您需要設置事件以觸發要監視的特定事件。如果要通知來自不同日誌或來源的事件,可以將多個觸發器放在同一個任務中。
我觸發通常受監控的SIOS DataKeeper(ExtMirr)EventIDs 16,20,23,150,219,220。您需要設置事件以觸發要監視的特定事件。如果要通知來自不同日誌或來源的事件,可以將多個觸發器放在同一個任務中。
創建一個新的事件過濾器 - 配置事件觸發器後,您將需要配置事件運行時發生的操作。在我們的例子中,我們將運行我們在步驟1中創建的Powershell腳本。


- 默認的Condition參數應該足夠了。
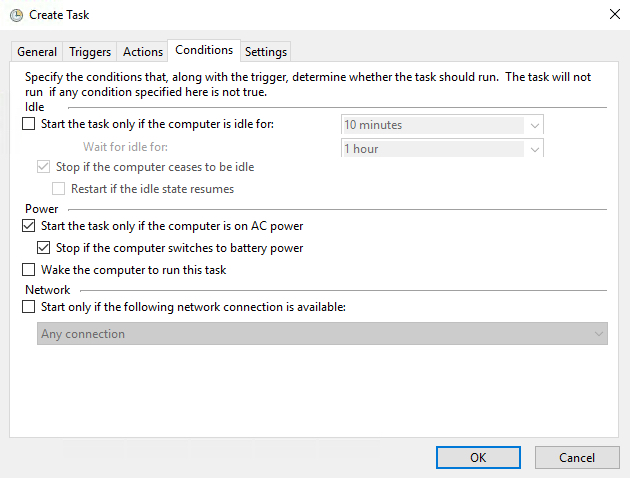
- 最後,在“設置”選項卡上,確保允許按需運行任務,並在任務已在運行時“排隊新實例”。

步驟3(如有必要) – 修復Microsoft Windows DistributedCOM事件ID:10016錯誤
理論上,如果您正確地執行了所有操作,您應該能夠使用Windows Server 2016從Windows事件觸發電子郵件警報。但是,我在我的一台服務器上遇到了一個奇怪的權限問題。這是我解決問題的方法。希望它也會對你有所幫助。在我手動觸發事件的情況下,或者如果我直接運行Powershell腳本,一切都按預期工作,我會收到一封電子郵件。但是,如果正在監視的某個EventID被記錄到事件日誌中,則不會導致發送電子郵件。我唯一的線索是事件ID:10016。每次我希望任務觸發器檢測到記錄的事件時,它都記錄在我的系統事件日誌中。
日誌名稱:系統
來源:Microsoft-Windows-DistributedCOM
日期:10/27/2018 5:59:47 PM
事件ID:10016
任務類別:無
等級:錯誤
關鍵詞:經典
用戶:DATAKEEPER dave
電腦:sql1.datakeeper.local
描述:
特定於應用程序的權限設置不授予“本地激活”權限
對於具有CLSID的COM Server應用程序
{D63B10C5-BB46-4990-A94F-E40B9D520160}
和APPID
{9CA88EE3-ACB7-47C8-AFC4-AB702511C276}
給用戶DATAKEEPER dave SID(S-1-5-21-25339xxxxx-208xxx580-6xxx06984-500)
來自地址LocalHost
(使用LRPC)在應用程序容器中運行不可用SID(不可用)。
可以使用組件服務管理工具修改此安全權限。
許多針對該錯誤的Google搜索結果表明該錯誤是良性的。它包含有關如何抑制錯誤而不是修復錯誤的說明。但是,我很確定這個錯誤是我目前失敗的原因。如果我沒有正確解決問題,使用Windows Server 2016從Windows事件觸發電子郵件警報將很困難。經過多次搜索,我偶然發現了這個新聞組的討論。 Marc Whittlesey的回應使我指出了正確的方向。這是他寫的……
在轉到組件服務中的DCOM配置之前,您必須設置2個註冊表項:CLSID密鑰和APPID密鑰。
我建議你按照一些步驟解決問題:
1。 按Windows + R鍵並鍵入regedit,然後按Enter鍵。2。 轉到HKEY_Classes_Root CLSID * CLSID *。3。 右鍵單擊它然後選擇權限。4。 單擊“高級”並將所有者更改為管理員。同時單擊將顯示在所有者行下方的框。5。 適用完全控制。6。 關閉選項卡,然後轉到HKEY_LocalMachine Software Classes AppID * APPID *。7。 右鍵單擊它然後選擇權限。8。 單擊“高級”並將所有者更改為管理員。9。 單擊將顯示在所有者行下方的框。10。 單擊“應用”並向管理員授予完全控制權。11。 關閉所有選項卡,然後轉到管理工具。12。 開放組件服務。13。 單擊“計算機”,單擊“我的電腦”,然後單擊“DCOM”。14。 查找錯誤查看器上顯示的相應服務。15。 右鍵單擊它,然後單擊屬性。16。 單擊安全選項卡,然後單擊添加用戶,添加系統,然後應用 17。 勾選激活本地框。因此,請在此處使用相關密鑰,DCOM配置應該可以訪問灰色區域:CLSID {D63B10C5-BB46-4990-A94F-E40B9D520160} APPID {9CA88EE3-ACB7-47C8-AFC4-AB702511C276}
我幾乎可以逐字逐句地遵循步驟1-15。然而,當我到達第16步時,我真的無法確切地說出他希望我做什麼。起初我將DATAKEEPER dave用戶帳戶完全控制權授予了RuntimeBroker,但這並沒有解決問題。最後我只是在所有三個權限上選擇了“使用默認值”並修復了問題。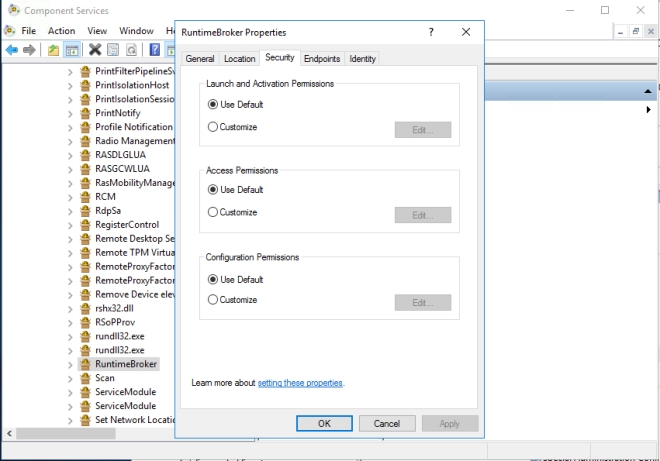 我不確定這是怎麼發生的。我想我最好把它全部寫下去,以防它再次發生,因為我花了一段時間來弄清楚它。
我不確定這是怎麼發生的。我想我最好把它全部寫下去,以防它再次發生,因為我花了一段時間來弄清楚它。
第4步 – 自動部署
如果需要在多個系統上啟用相同的警報,請將任務導出到XML文件並將其導入其他系統。
 或者甚至更好。 在文件共享上提供XML文件後,通過Powershell腳本自動執行導入作為構建過程的一部分,如以下示例所示。
或者甚至更好。 在文件共享上提供XML文件後,通過Powershell腳本自動執行導入作為構建過程的一部分,如以下示例所示。
PS C:> Register-ScheduledTask -Xml(get-content '\ myfileshare tasks DataKeeperAlerts.xml'|出弦) -TaskName“DataKeeperAlerts” - 用戶數據管理員 dave -Password MyDomainP @ 55W0rd -Force
使用Windows Server 2016從Windows事件觸發電子郵件警報
在我的下一篇文章中,我將向您展示如何在指定的服務啟動或停止時收到通知。當然,您只需從Service Control Monitor監視EventID 7036即可。但是,只要任何服務開始或停止,這都會通知您。我們需要深入挖掘,以確保只有在我們關心的服務開始或停止時才會收到通知。如果您對我們的操作方法文章感興趣,例如使用Windows Server 2016從Windows事件觸發電子郵件警報,請單擊此處。從Clusteringformeremortals.com轉載


 除了最極端的情況之外,在可用區之間複製數據應該足以用於數據保護。某些應用程序(如SQL Server)內置了複製技術。但是,對於廣泛的應用程序,操作系統和數據類型,請研究塊級複製SANless群集解決方案。SANless集群解決方案傳統上用於多站點集群。但是,相同的技術也可以在可用區,區域或混合雲中的雲中使用,以實現高可用性和災難恢復。無論是Azu
除了最極端的情況之外,在可用區之間複製數據應該足以用於數據保護。某些應用程序(如SQL Server)內置了複製技術。但是,對於廣泛的應用程序,操作系統和數據類型,請研究塊級複製SANless群集解決方案。SANless集群解決方案傳統上用於多站點集群。但是,相同的技術也可以在可用區,區域或混合雲中的雲中使用,以實現高可用性和災難恢復。無論是Azu




 服務帳戶必須是每個節點上Local Admins組中的域帳戶一旦安裝DataKeeper並在每個節點上獲得許可,您將需要重新啟動服務器。
服務帳戶必須是每個節點上Local Admins組中的域帳戶一旦安裝DataKeeper並在每個節點上獲得許可,您將需要重新啟動服務器。 要創建DataKeeper Volume Resource,您需要啟動DataKeeper UI並連接到這兩個服務器。連接到SQL1 [/ caption] 連接到SQL2 [/ caption]連接到每個服務器後,即可創建DataKeeper卷。右鍵單擊Jobs並選擇“Creat
要創建DataKeeper Volume Resource,您需要啟動DataKeeper UI並連接到這兩個服務器。連接到SQL1 [/ caption] 連接到SQL2 [/ caption]連接到每個服務器後,即可創建DataKeeper卷。右鍵單擊Jobs並選擇“Creat e Job”為作業命名和描述。
e Job”為作業命名和描述。 選擇源服務器,IP和卷。IP地址是複制流量是否會傳播。
選擇源服務器,IP和卷。IP地址是複制流量是否會傳播。 選擇目標服務器。
選擇目標服務器。 選擇你的選擇。對於兩個VM位於同一地理區域的目的,我們將選擇同步複製。對於更長距離的複制,您將需要使用異步並啟用一些壓縮。
選擇你的選擇。對於兩個VM位於同一地理區域的目的,我們將選擇同步複製。對於更長距離的複制,您將需要使用異步並啟用一些壓縮。 通過在上次彈出窗口中單擊“是”,您將在故障轉移群集中的可用存儲中註冊新的DataKeeper卷資源。
通過在上次彈出窗口中單擊“是”,您將在故障轉移群集中的可用存儲中註冊新的DataKeeper卷資源。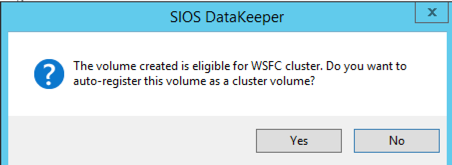 您將在可用存儲中看到新的DataKeeper卷資源。
您將在可用存儲中看到新的DataKeeper卷資源。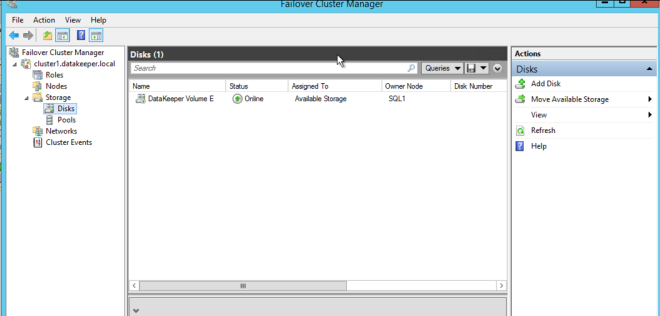
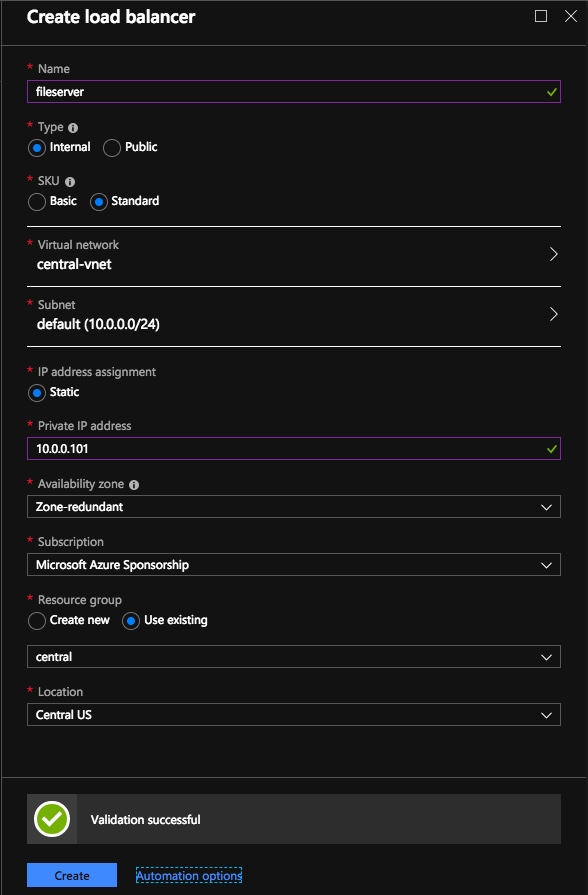 創建內部負載均衡器(ILB)後,您需要對其進行編輯。我們要做的第一件事就是添加一個後端池。通過此過程,您將選擇兩個群集節點。
創建內部負載均衡器(ILB)後,您需要對其進行編輯。我們要做的第一件事就是添加一個後端池。通過此過程,您將選擇兩個群集節點。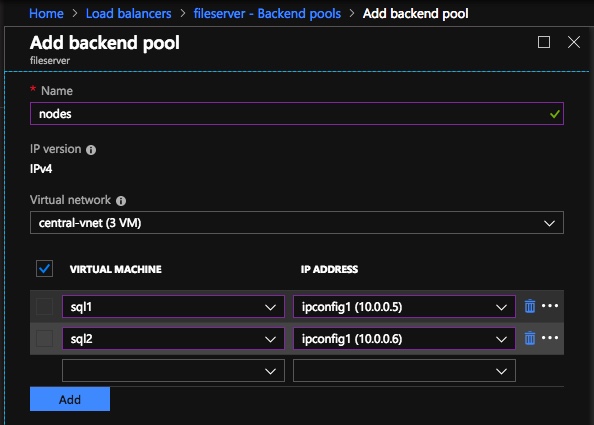 接下來我們要做的就是添加一個Probe。我們添加的探針將探測端口59999。此探針確定群集中哪個節點處於活動狀態。
接下來我們要做的就是添加一個Probe。我們添加的探針將探測端口59999。此探針確定群集中哪個節點處於活動狀態。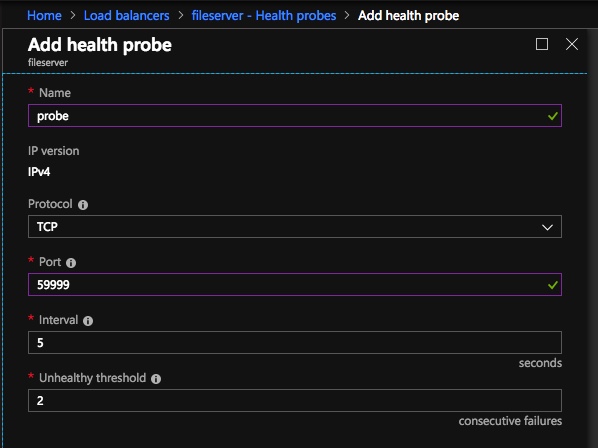 最後,我們需要一個負載平衡規則來重定向SMB流量,TCP端口445。在下面的屏幕截圖中需要注意的重要事項是直接服務器返回已啟用。確保你做出改變。
最後,我們需要一個負載平衡規則來重定向SMB流量,TCP端口445。在下面的屏幕截圖中需要注意的重要事項是直接服務器返回已啟用。確保你做出改變。