| Maret 7, 2019 |
Rumah Sakit ALYN Memastikan Ketersediaan Tinggi Dan Perlindungan Pemulihan BencanaRumah Sakit ALYN Memastikan Ketersediaan Tinggi Dan Perlindungan Pemulihan Bencana Untuk Aplikasi Pentingnya dengan SIOS DataKeeperSIOS Terpilih untuk Efektivitas Biaya dan Desain Aplikasi-agnostiknya SAN MATEO, CA – 5 Maret 2019 – SIOS Technology Corp, pelopor industri dalam menyediakan ketersediaan aplikasi cerdas untuk beban kerja kritis, hari ini mengumumkan bahwa Rumah Sakit ALYN menggunakan perangkat lunak SIOS DataKeeper untuk menyediakan ketersediaan tinggi dan perlindungan pemulihan bencana untuk semua Rumah Sakit ALYN. aplikasi mission-critical. Ini termasuk catatan medis elektronik, manajemen hubungan pelanggan, database SQL Server, Exchange dan Office. Rumah Sakit ALYN diakui di seluruh dunia sebagai rumah sakit rehabilitasi anak utama di Israel. ALYN berspesialisasi dalam mendiagnosis dan merehabilitasi bayi, anak-anak, dan remaja dengan cacat fisik, baik yang bawaan maupun yang didapat. Departemen TI di Rumah Sakit ALYN mengoperasikan berbagai aplikasi dalam lingkungan Microsoft Windows Server yang tervirtualisasi. "Sebagai rumah sakit, kami tunduk pada beberapa peraturan pemerintah yang cukup ketat, jadi kami perlu menerapkan ketentuan kesinambungan bisnis yang kuat untuk banyak aplikasi kami," jelas Uri Inbar, Direktur IT ALYN. Replika Hyper-V, yang merupakan bagian integral dari hypervisor Hyper-V Microsoft, adalah pilihan yang jelas untuk kebutuhan kelangsungan bisnis ALYN. Departemen TI mengoperasikan dua ruang server yang terpisah secara fisik di lokasi, yang memungkinkan semua mesin virtual kritis yang berjalan pada server host Hyper-V dapat direplikasi ke ruangan lain di ruangan lain. “Kami benar-benar berjuang untuk memuaskan titik pemulihan kami dan sasaran waktu pemulihan dengan pengaturan ini, jadi kami mulai menyelidiki opsi lain,” kenang Inbar. Kriteria EvaluasiUntuk mengevaluasi perangkat lunak cluster failover pihak ketiga, Inbar menetapkan tiga kriteria: Solusinya harus bekerja dengan perangkat keras yang ada; itu harus memberikan perlindungan ketersediaan tinggi (HA) dan pemulihan bencana (DR) semua aplikasi penting rumah sakit, dan total biaya harus sesuai dengan anggaran terbatas departemen. Staf TI dengan cepat mempersempit opsi pihak ketiga menjadi dua, dan setelah mengevaluasi keduanya dengan cermat, menemukan bahwa hanya satu yang memenuhi semua kriteria: DataKeeper dari SIOS Technologies. “Sementara kami membutuhkan solusi yang hemat biaya, kami bertekad untuk tidak mengorbankan kualitas atau kemampuan,” Inbar menekankan. “Dengan SIOS kami menemukan solusi yang menghadirkan kemampuan kelas operator dengan total biaya kepemilikan yang sangat rendah. Bagi kami, itu adalah pilihan yang jelas. ” HasilSIOS DataKeeper sangat ideal untuk kebutuhan Rumah Sakit ALYN untuk ketersediaan tinggi dan perlindungan pemulihan bencana. Karena dibuat khusus untuk memberikan perlindungan HA dan DR dalam satu solusi tunggal yang hemat biaya. Kemampuan untuk membuat kluster failover SAN-node 3-simpul dengan satu instance aktif dan dua siaga telah terbukti sangat berharga untuk kebutuhan ALYNN. “Kami memperbarui sistem dan perangkat lunak secara terus-menerus, dan dengan DataKeeper kami dapat melakukannya tanpa ada gangguan pada operasi,” kata Inbar. Karena replikasi data mendukung beberapa standar dan memungkinkan penugasan manual dan dinamis dari instance aktif dan siaga, instance aktif dapat dipindahkan ke server mana pun dalam kluster 3-simpul dan tetap sepenuhnya terlindungi selama periode pemeliharaan perangkat keras dan perangkat lunak yang direncanakan. Fitur SIOS DataKeeper lain yang penting untuk kebutuhan ALYN meliputi kemampuan untuk bekerja dengan semua jenis penyimpanan dan replikasi data WAN yang dioptimalkan. "Cluster SIOS secara mulus mendukung volume penyimpanan yang dikenali oleh Windows, dan ini secara substansial menyederhanakan operasi sembari memungkinkan kami untuk memanfaatkan semua sumber daya penyimpanan kami," jelas Inbar. Selain itu, optimisasi WAN akan terbukti bermanfaat karena Inbar dan timnya mengimplementasikan situs pemulihan bencana jarak jauh. Inbar yakin SIOS SANless failover cluster akan berfungsi sesuai keinginan saat dibutuhkan: “Kami menguji konfigurasi secara rutin dan secara rutin mengubah peruntukan aktif dan siaga sambil mengarahkan replikasi data sebagaimana diperlukan selama pembaruan perangkat lunak yang direncanakan, dan aplikasi selalu terus berjalan tanpa gangguan . Itu hanya bekerja dan itu sangat meyakinkan. " "Apakah aplikasi penting perusahaan Anda beroperasi di lingkungan server fisik, cloud pribadi, cloud publik atau cloud hybrid, mereka harus dilindungi dari downtime dan kehilangan data," kata Jerry Melnick, presiden dan CEO, SIOS Technology. “ALYN menggunakan SIOS untuk menyediakan solusi ketersediaan tinggi yang cepat, hemat biaya untuk aplikasi dalam lingkungan tervirtualisasi. Saya memuji mereka untuk kasus penggunaan dan inovasi mereka dan berharap untuk terus memberikan nilai pada strategi HA dan DR mereka. ” Tentang SIOS Technology Corp.SIOS Technology Corp. membuat produk-produk perangkat lunak yang memberikan wawasan dan panduan yang dibutuhkan manajer TI untuk mengelola dan melindungi aplikasi yang penting bagi bisnis di pusat data yang besar dan kompleks. SIOS iQ perusahaan adalah perangkat lunak analitik pembelajaran mesin yang membantu manajer TI mengoptimalkan kinerja, efisiensi, keandalan, dan pemanfaatan kapasitas dalam lingkungan tervirtualisasi. SIOS SAN dan perangkat lunak SANLess adalah bagian penting dari setiap solusi cluster yang memberikan fleksibilitas untuk membangun Clusters Your Way ™ untuk melindungi pilihan Anda terhadap lingkungan Windows atau Linux dalam konfigurasi (atau kombinasi) fisik, virtual, dan cloud (publik, pribadi, dan hybrid) tanpa mengorbankan kinerja atau ketersediaan. Didirikan pada tahun 1999, SIOS Technology Corp (http://us.sios.com) berkantor pusat di San Mateo, California, dan memiliki kantor di seluruh Amerika Serikat, Inggris, dan Jepang. SIOS, SIOS Technology, SIOS iQ, SIOS DataKeeper, SIOS Protection Suite, Clusters Your Way, SIOS PERC Dashboard, dan logo terkait adalah merek dagang terdaftar atau merek dagang dari SIOS Technology Corp. dan / atau afiliasinya di Amerika Serikat dan / atau negara lain . Semua merek dagang lain adalah properti dari pemiliknya masing-masing. Kontak Media:Beth Winkowski Winkowski Public Relations, LLC untuk SIOS 978-649-7189 bethwinkowski@US.SIOS.com Untuk melihat bagaimana perusahaan lain menikmati ketersediaan tinggi dan perlindungan pemulihan bencana yang serupa, baca kisah sukses SIOS kami Baca tentang bagaimana SIOS membantu Alyn, buka di sini |
Teknologi SIOS Menerima Penghargaan Cloud Computing Excellence 2018 |
|
| Februari 1, 2019 |
Aplikasi Ketersediaan Tinggi Untuk Operasi Bisnis – Wawancara |
| Januari 30, 2019 |
Pastikan Ketersediaan Tinggi untuk SQL Server di Amazon Web Services
Pastikan Ketersediaan Tinggi untuk SQL Server di Amazon Web ServicesAdministrator basis data dan sistem telah lama memiliki berbagai pilihan untuk memastikan bahwa aplikasi basis data yang sangat penting tetap tersedia. Infrastruktur cloud publik, seperti yang disediakan oleh Amazon Web Services, menawarkan sendiri, opsi ketersediaan tinggi tambahan yang didukung oleh perjanjian tingkat layanan. Tetapi konfigurasi yang berfungsi baik di cloud pribadi mungkin tidak dimungkinkan di cloud publik. Pilihan yang buruk dalam layanan AWS yang digunakan dan / atau bagaimana ini dikonfigurasikan dapat menyebabkan ketentuan failover gagal ketika sebenarnya dibutuhkan. Artikel ini menguraikan berbagai opsi yang tersedia untuk memastikan Ketersediaan Tinggi untuk SQL Server di cloud AWS. PilihanUntuk aplikasi basis data, AWS memberi administrator dua pilihan dasar. Masing-masing memiliki ketentuan ketersediaan tinggi (HA) dan pemulihan bencana (DR) yang berbeda: Amazon Relational Database Service (RDS) dan Amazon Elastic Compute Cloud (EC2). RDSRDS adalah layanan yang dikelola sepenuhnya cocok untuk aplikasi mission-critical. Ini menawarkan pilihan enam mesin database yang berbeda, tetapi dukungannya untuk SQL Server tidak sekuat itu untuk pilihan lain seperti Amazon Aurora, My SQL dan MariaDB. Berikut adalah beberapa masalah umum yang dimiliki administrator tentang penggunaan RDS untuk aplikasi SQL Server yang sangat penting:
Cloud Hitung ElastikPilihan dasar lainnya adalah Elastic Compute Cloud dengan kemampuannya yang jauh lebih besar. Ini menjadikannya pilihan yang lebih disukai ketika HA dan DR sangat penting. Keuntungan utama EC2 adalah kontrol penuh yang diberikannya kepada admin atas konfigurasi, dan yang memberi admin beberapa pilihan tambahan. Memilih Sistem OperasiMungkin pilihan yang paling penting adalah sistem operasi mana yang akan digunakan: Windows atau Linux. Windows Server Failover Clustering adalah kemampuan yang kuat, terbukti dan populer yang datang standar dengan Windows. Tetapi WSFC membutuhkan penyimpanan bersama, dan itu tidak tersedia di EC2. Karena Multi-AZ, dan bahkan Multi-Wilayah, konfigurasi diperlukan untuk perlindungan HA / DR yang kuat, perangkat lunak khusus komersial atau kustom diperlukan untuk mereplikasi data di seluruh cluster instance server. Ruang Penyimpanan Langsung Microsoft (S2D) bukanlah opsi di sini, karena tidak mendukung konfigurasi yang menjangkau Zona Ketersediaan. Kebutuhan akan ketentuan HA / DR tambahan bahkan lebih besar untuk Linux, yang tidak memiliki kemampuan pengelompokan mendasar seperti WSFC. Linux memberikan admin dua pilihan yang sama buruknya untuk ketersediaan tinggi: Entah membayar lebih untuk SQL Server Enterprise Edition yang lebih mahal untuk mengimplementasikan Grup Selalu Ada Ketersediaan; atau berjuang untuk membuat konfigurasi HA Linux do-it-yourself yang rumit menggunakan perangkat lunak sumber terbuka bekerja dengan baik. PerbandinganKedua pilihan ini merusak alasan penghematan biaya untuk menggunakan perangkat lunak open source pada perangkat keras komoditas dalam layanan cloud publik. SQL Server untuk Linux hanya tersedia untuk versi yang lebih baru (dan lebih mahal), mulai tahun 2017. Dan alternatif HA DIY bisa sangat mahal bagi sebagian besar organisasi. Memang, membuat Distributed Replicated Block Device, Corosync, Pacemaker dan, secara opsional, perangkat lunak open source lainnya berfungsi seperti yang diinginkan pada level aplikasi di bawah semua skenario kegagalan yang mungkin bisa menjadi sangat sulit. Itulah sebabnya hanya organisasi yang sangat besar yang memiliki sarana (keahlian dan staf) yang diperlukan untuk mempertimbangkan untuk mengambil tugas. Karena kesulitan yang terlibat dalam mengimplementasikan ketentuan HA / DR yang sangat penting untuk Linux, AWS merekomendasikan menggunakan kombinasi Penimbangan Beban Elastis dan Penskalaan Otomatis untuk meningkatkan ketersediaan. Tetapi layanan ini memiliki keterbatasan sendiri yang serupa dengan yang ada di Layanan Database Relasional yang dikelola. Semua ini menjelaskan mengapa admin semakin memilih untuk menggunakan solusi cluster failover yang dirancang khusus untuk memastikan perlindungan HA dan DR di lingkungan cloud. Tujuan Clustering Failover-Dibangun untuk CloudSemakin populernya awan privat, publik dan hibrida telah menyebabkan munculnya solusi pengelompokan failover yang dibangun khusus untuk lingkungan cloud. Solusi HA / DR ini sepenuhnya diimplementasikan dalam perangkat lunak yang menciptakan, seperti tersirat dengan nama, sekelompok server dan penyimpanan dengan failover otomatis untuk memastikan ketersediaan tinggi di tingkat aplikasi. Sebagian besar solusi ini menyediakan solusi HA / DR lengkap yang mencakup kombinasi replikasi data tingkat blok waktu-nyata, pemantauan aplikasi terus-menerus dan kebijakan pemulihan failover / failback yang dapat dikonfigurasi. Beberapa solusi yang lebih canggih juga menawarkan kemampuan canggih seperti dukungan untuk Mesin Virtual Selalu di Failover Cluster dalam Edisi Standar SQL Server yang lebih murah untuk Windows dan Linux. Mereka juga menawarkan optimasi WAN untuk memaksimalkan kinerja multi-wilayah. Ada juga peralihan manual tugas server primer dan sekunder untuk memfasilitasi pemeliharaan yang direncanakan. Termasuk kemampuan untuk melakukan backup reguler tanpa gangguan ke aplikasi. Sebagian besar perangkat lunak failover clustering adalah agnostik aplikasi, yang memungkinkan organisasi memiliki solusi HA / DR tunggal universal. Kemampuan yang sama ini juga memberikan perlindungan untuk seluruh aplikasi SQL Server. Dan itu termasuk basis data, log masuk, pekerjaan agen, dll., Semuanya terintegrasi. Meskipun solusi ini umumnya juga agnostik penyimpanan, memungkinkan mereka untuk bekerja dengan jaringan area penyimpanan bersama, pengelompokan failover SANless yang tidak dibagi biasanya lebih disukai karena kemampuannya untuk menghilangkan titik kegagalan tunggal yang potensial. Dukungan untuk Mesin Virtual Cluster Selalu Aktif (FCI) dalam SQL Server Edisi Standar yang lebih murah, tanpa kompromi terhadap ketersediaan atau kinerja, adalah keuntungan utama. Dalam lingkungan Windows, sebagian besar perangkat lunak pengelompokan failover mendukung FCI dengan memanfaatkan fitur WSFC bawaan. Itu membuat implementasi cukup mudah untuk administrator database dan sistem. Linux menjadi semakin populer untuk SQL Server dan banyak aplikasi perusahaan lainnya. Beberapa solusi cluster failover sekarang membuat penerapan ketentuan HA / DR semudah itu untuk Windows dengan menawarkan integrasi khusus aplikasi. Cluster Failover Tiga Node SANless KhasContoh konfigurasi EC2 dalam diagram menunjukkan kluster failover SANless tiga simpul yang dikonfigurasikan sebagai Virtual Private Cloud (VPC) dengan ketiga instance SQL Server di Zona Ketersediaan yang berbeda. Untuk menghilangkan potensi pemadaman dalam bencana lokal yang mempengaruhi seluruh wilayah, salah satu AZ terletak di wilayah AWS yang berbeda. 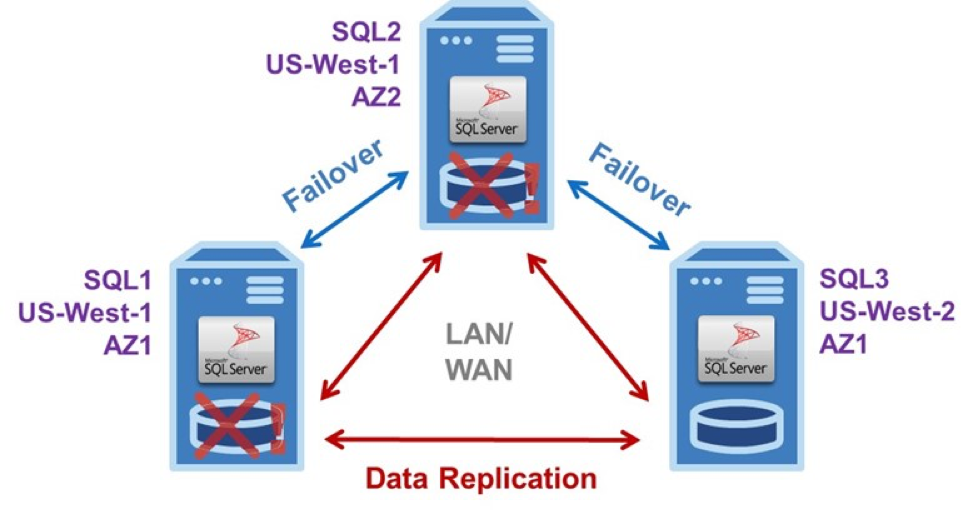
Tiga-simpul SANless failover cluster ini, dengan satu instance server aktif dan dua siaga, dapat menangani dua kegagalan bersamaan dengan downtime minimal dan tanpa kehilangan data. Tiga-simpul SANless failover cluster memberikan perlindungan HA dan DR kelas carrier. Operasi dasarnya sama di LAN dan / atau WAN untuk Windows atau Linux. Server # 1 pada awalnya adalah instance primer atau aktif yang mereplikasi data terus menerus ke kedua server # 2 dan # 3. Itu mengalami masalah. Kemudian memicu failover otomatis ke server # 2, yang sekarang menjadi data replikasi utama ke server # 3. Kegagalan TerdeteksiJika kegagalan itu disebabkan oleh pemadaman infrastruktur, staf AWS akan segera mulai mendiagnosis dan memperbaiki apa pun yang menyebabkan masalah. Setelah diperbaiki, itu dapat dikembalikan sebagai primer, atau server # 2 dapat melanjutkan dalam kapasitas mereplikasi data ke server # 1 dan # 3. Jika server # 2 gagal sebelum server # 1 dikembalikan ke operasi, seperti yang ditunjukkan, server # 3 akan menjadi yang utama setelah kegagalan manual. Tentu saja, jika kegagalan itu disebabkan oleh perangkat lunak aplikasi atau aspek lain dari konfigurasi, terserah kepada pelanggan untuk menemukan dan memperbaiki masalah. Cluster failover SANless dapat dikonfigurasi hanya dengan satu instance standby, tentu saja. Tetapi konfigurasi minimal seperti itu membutuhkan simpul ketiga untuk berfungsi sebagai saksi. Saksi diperlukan untuk mencapai kuorum untuk menentukan penugasan primer. Tugas penting ini biasanya dilakukan oleh pengontrol domain di AZ terpisah. Mempertahankan ketiga simpul (primer, sekunder, dan saksi) di AZ yang berbeda menghilangkan kemungkinan kehilangan lebih dari satu suara jika ada zona yang offline. Juga dimungkinkan untuk memiliki kluster failover SAN dua dan tiga simpul dalam konfigurasi cloud hybrid untuk tujuan HA dan / atau DR. Salah satu konfigurasi tiga simpul tersebut adalah klaster HA dua simpul yang terletak di pusat data perusahaan dengan replikasi data asinkron ke AWS atau layanan cloud lain untuk perlindungan DR — atau sebaliknya. Dalam kelompok dalam satu wilayah, di mana replikasi data sinkron, kegagalan biasanya dikonfigurasi untuk terjadi secara otomatis. Untuk cluster dengan node yang menjangkau beberapa wilayah, di mana replikasi data asinkron, failover biasanya dikontrol secara manual untuk menghindari potensi kehilangan data. Cluster tiga-node, terlepas dari wilayah yang digunakan, juga dapat memfasilitasi pemeliharaan perangkat keras dan perangkat lunak yang direncanakan untuk ketiga server sambil memberikan perlindungan DR berkelanjutan untuk aplikasi dan datanya. Maksimalkan Ketersediaan Tinggi untuk SQL ServerDengan menawarkan 55 zona Ketersediaan yang tersebar di 18 Wilayah geografis, Infrastruktur Global AWS memberi peluang besar untuk memaksimalkan Ketersediaan Tinggi untuk SQL Server dengan mengonfigurasi kluster failover SANless dengan banyak, redundansi yang tersebar secara geografis. Jejak global ini juga memungkinkan semua aplikasi dan data SQL Server berada di dekat pengguna akhir untuk memberikan kinerja yang memuaskan. Dengan solusi yang dibangun khusus, ketersediaan tinggi kelas-operator tidak perlu berarti membayar biaya tinggi seperti-carrier. Karena perangkat lunak failover clustering yang dibuat khusus membuat penggunaan sumber daya komputasi, penyimpanan, dan jaringan EC2 yang efektif dan efisien, sementara mudah diimplementasikan dan dioperasikan, solusi ini meminimalkan modal dan semua pengeluaran operasional, sehingga ketersediaan tinggi menjadi lebih kuat dan lebih terjangkau daripada pernah sebelumnya. Direproduksi dari TheNewStack |
| Januari 27, 2019 |
Opsi untuk Saat Tingkat Layanan Cloud Publik Gagal |



