| February 16, 2023 |
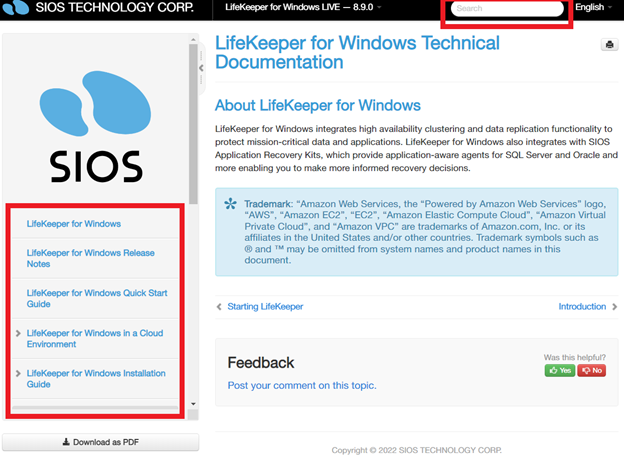
How to Get Started Successfully with SIOS Documentation |
| February 12, 2023 |
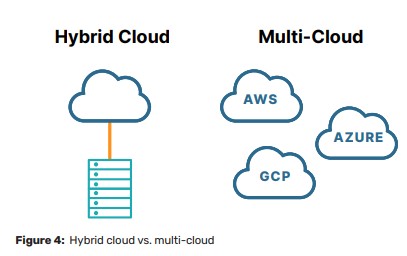
Multi-Cloud High Availability for Business-Critical Applications |
| February 8, 2023 |
Video: SIOS DataKeeperVideo: SIOS DataKeeper
Reproduced with permission from SIOS |
| February 4, 2023 |
Video: SIOS LifeKeeperVideo: SIOS LifeKeeper
Reproduced with permission from SIOS |
| January 28, 2023 |
Video: The SIOS AdvantageVideo: The SIOS Advantage
Reproduced with permission from SIOS |