| June 27, 2022 |
New Options for High Availability Clusters, SIOS Cements its Support for Microsoft Azure Shared Disk |
| June 23, 2022 |
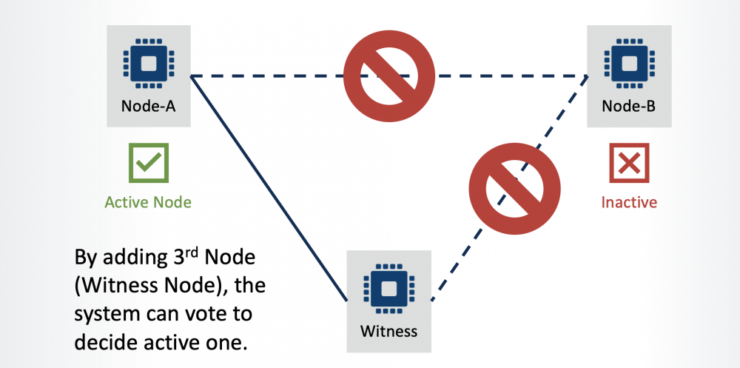
What is “Split Brain” and How to Avoid It |
| June 19, 2022 |
How does Data Replication between Nodes Work? |
| June 15, 2022 |
How a Client Connects to the Active Node |
| June 11, 2022 |
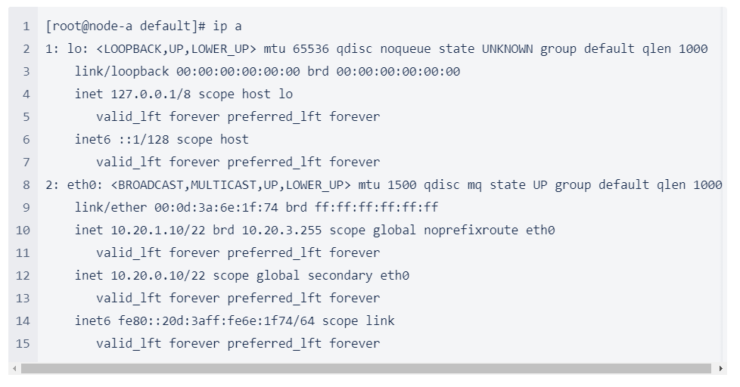
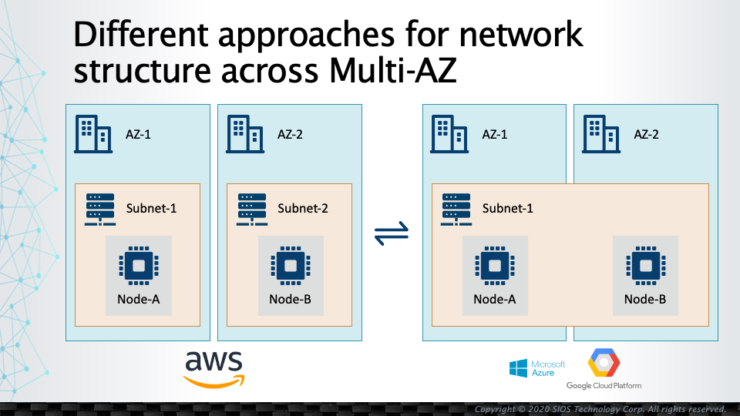
Public Cloud Platforms and their Network Structure Differences |